
Deep Learning with Convolutional Neural Networks: A Compact Holistic Tutorial with Focus on Supervised Regression


Abstract
1. Introduction
2. Motivation
3. Machine Learning
3.1. Learning Theory
3.2. Model Evaluation
- It does not use all the data at hand for training; a problem that is specially relevant for small datasets.
- In practice, there can be cases where the i.i.d. assumption does not hold. Therefore, the assessment is highly sensitive to the training/test split.
3.3. Statistics and Probability Theory
3.3.1. Maximum Likelihood Estimation
3.3.2. Maximum a Posteriori Estimation
3.4. Optimization and Regularization
3.4.1. Loss Function
3.4.2. Gradient-Based Learning
3.4.3. Regularization
4. Deep Forward Artificial Neural Networks
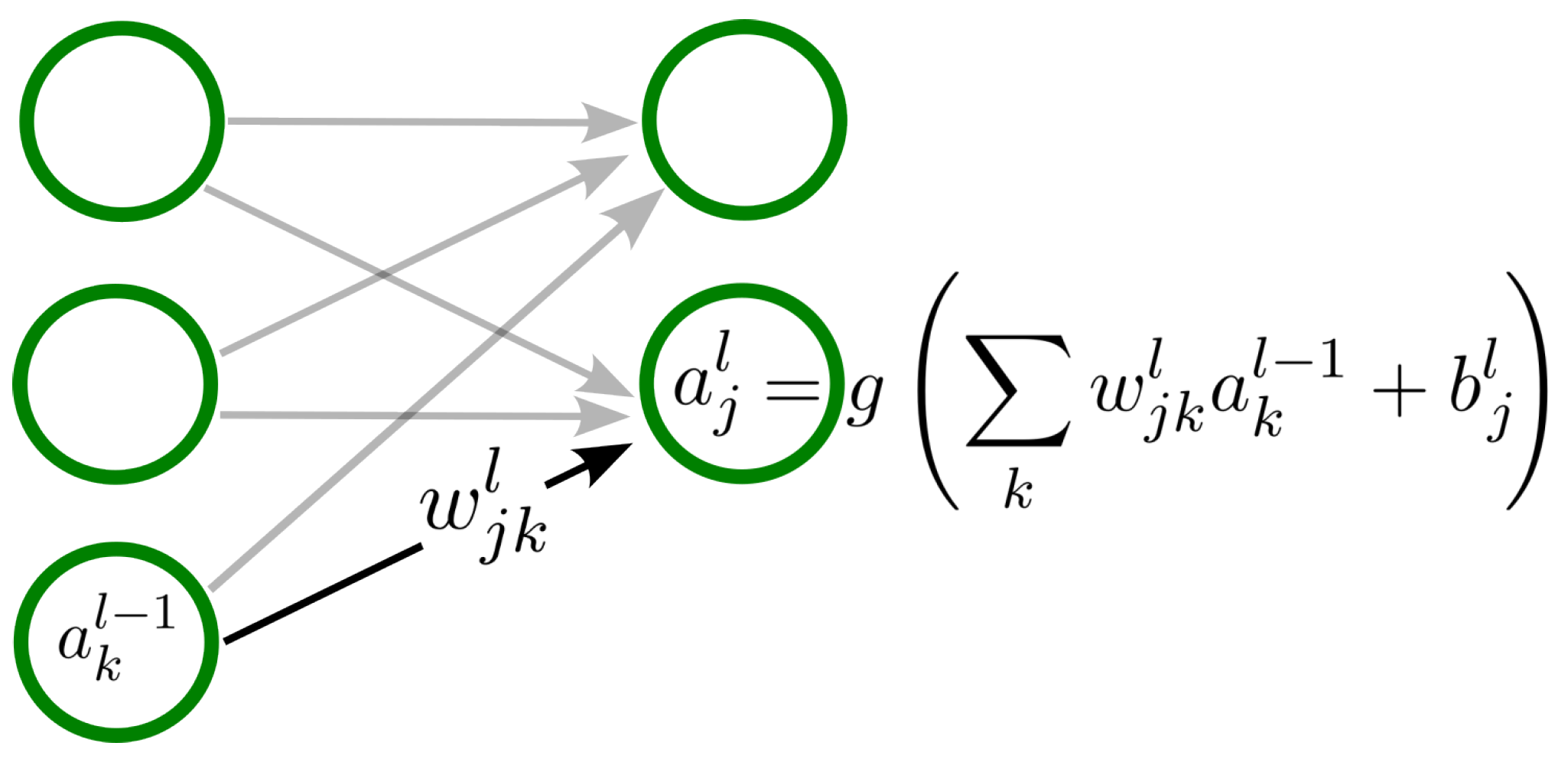
4.1. Artificial Neural Networks
4.1.1. Artificial Neurons
4.1.2. Deep Feedforward Networks
4.2. Training
4.2.1. Stochastic Gradient Descent
4.2.2. SGD with Momentum
4.2.3. Forward-Propagation and Back-Propagation
4.2.4. Hyperparameters
| Algorithm 1: Example ANN training algorithm. Here, we implement training by iterating over examples in a mini-batch. In practice, back-propagation is implemented to simultaneously compute the gradients of the entire mini-batch using matrices. |
 |
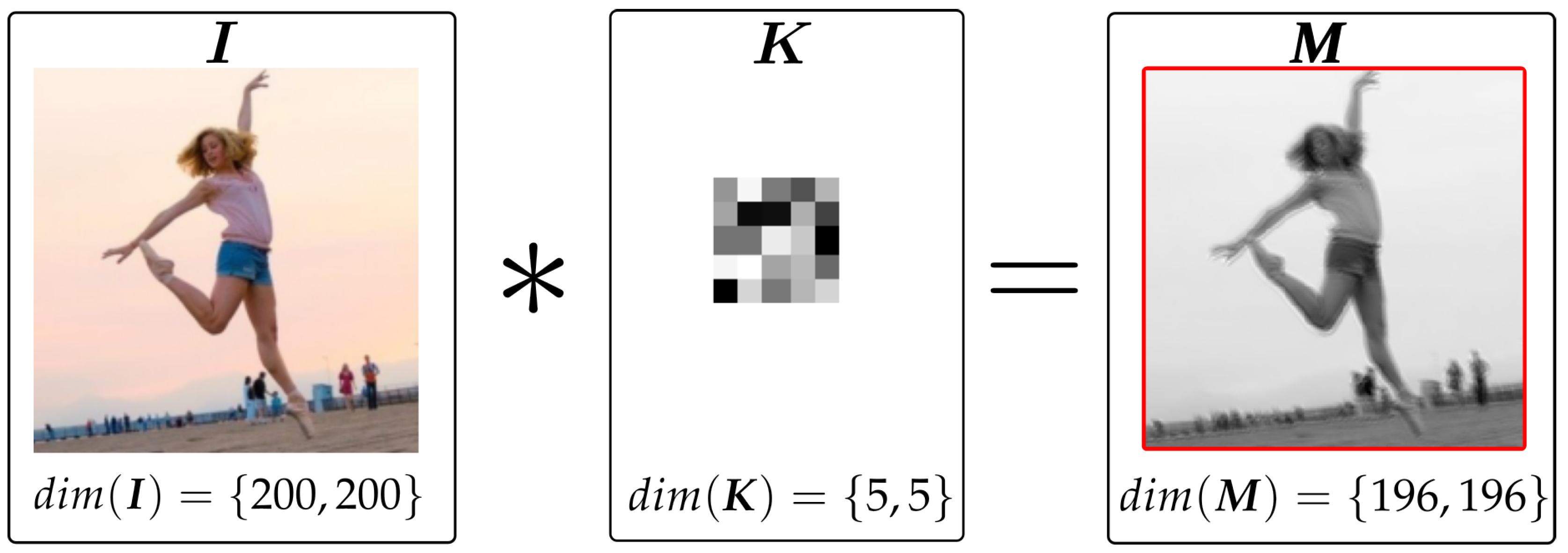
5. Convolutional Neural Networks
5.1. Convolutional Layer
5.2. Pooling Layer
5.3. ReLU Layer
5.4. CNN Training
Forward and Back-Propagation in CNNs
5.5. Batch Normalization
6. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Notation
| Number and Arrays | |
| a | A scalar (integer or real) |
| A vector | |
| A matrix | |
| A tensor | |
| a | A scalar random variable |
| A vector-value random variable | |
| A matrix-value random variable | |
| Sets | |
| A set | |
| The set of real numbers | |
| The set of all integers between 0 and n | |
| Indexing | |
| Element i of vector | |
| All elements of vector except for element i | |
| Element of matrix | |
| Row i of matrix | |
| Column i of matrix | |
| Element of a tensor | |
| 2D slice of a 3D tensor | |
| 3D slice of a 4D tensor | |
| Linear Algebra Operations | |
| Transpose of matrix | |
| Element-wise (Hadamard) product of and | |
| Calculus | |
| Derivative of y with respect to x | |
| Partial derivative of y with respect to x | |
| Gradient of y with respect to x | |
| Probability and Information Theory | |
| A probability distribution over a discrete variable | |
| A probability distribution over a continuous variable, | |
| or over a variable whose type has not been defined | |
| Random variable a with distribution P | |
| or | Expectation of with respect to |
| Kullback–Leibler divergence of P and Q | |
| Gaussian distribution over with mean and covariance | |
| Functions | |
| Function f with domain and range | |
| function i of an ordered set of functions | |
| Composition of functions f and g | |
| A function of parametrized by | |
| Natural logarithm of x | |
| Logistic sigmoid, | |
| Softplus, | |
| norm of | |
| norm of | |
| Datasets and Distributions | |
| The data-generating distribution | |
| The empirical distribution defined by the training set | |
| A set of training examples | |
| The i-th example (input) from a dataset | |
| , , or | The target associated with for supervised learning |
| The matrix with input example in row |
References
- Rusell, S.J.; Norvig, P. Artificial Intelligence. A Modern Approach; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- McElreath, R. Statistical Rethinking: A Bayesian Course with Examples in R and Stan; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Krogh, A.; Hertz, J. A Simple Weight Decay Can Improve Generalization. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1991; Moody, J., Hanson, S., Lippmann, R., Eds.; Morgan-Kaufmann: Burlington, MA, USA, 1991; Volume 4. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Hebb, D.O. The Organization of Behavior: A Neuropsychological Theory; Psychology Press: London, UK, 1949. [Google Scholar]
- Rosenblatt, F. The Perceptron—A Perceiving and Recognizing Automaton; Technical Report 85-460-1; Cornell Aeronautical Laboratory: Ithaca, NY, USA, 1957. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Minsky, M.; Papert, S. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Lu, Z.; Pu, H.; Wang, F.; Hu, Z.; Wang, L. The Expressive Power of Neural Networks: A View from the Width. Adv. Neural Inf. Process. Syst. 2017, 30, 6232–6240. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Gripenberg, G. Approximation by neural networks with a bounded number of nodes at each level. J. Approx. Theory 2003, 122, 260–266. [Google Scholar] [CrossRef]
- Maiorov, V.; Pinkus, A. Lower bounds for approximation by MLP neural networks. Neurocomputing 1999, 25, 81–91. [Google Scholar] [CrossRef]
- Hardt, M.; Recht, B.; Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. In Proceedings of the the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; Balcan, M.F., Weinberger, K.Q., Eds.; Proceedings of Machine Learning Research. Volume 48, pp. 1225–1234. [Google Scholar]
- Robbins, H.E. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Newton, D.; Yousefian, F.; Pasupathy, R. Stochastic Gradient Descent: Recent Trends. In Recent Advances in Optimization and Modeling of Contemporary Problems; INFORMS: Catonsville, MD, USA, 2018; pp. 193–220. [Google Scholar] [CrossRef]
- Goh, G. Why Momentum Really Works. Distill 2017, 2, e6. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics), 1st ed.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Nielsen, M.A. Neural Networks and Deep Learning; Springer: Cham, Switzerland, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Teh, Y.W., Titterington, M., Eds.; Chia Laguna Resort: Sardinia, Italy, 2010. Proceedings of Machine Learning Research. Volume 9, pp. 249–256. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: San Francisco, CA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (Eds.) Automated Machine Learning—Methods, Systems, Challenges; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- González Tejeda, Y.; Mayer, H.A. A Neural Anthropometer Learning from Body Dimensions Computed on Human 3D Meshes. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Virtual, 5–7 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Aggarwal, C.C. Neural Networks and Deep Learning. A Text book.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient BackProp. In Neural Networks: Tricks of the Trade; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Bach, F., Blei, D., Eds.; Proceedings of Machine Learning Research. Volume 37, pp. 448–456. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: San Francisco, CA, USA, 2018; Volume 31. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Interpretation | Section | Default or Common Values |
|---|---|---|---|
| Learning rate | Section 3.4.2 | , | |
| Regularization coefficient | Section 3.4.3 | ||
| Number of epochs | Section 4.2.1 | 5, 10, 100 | |
| n | Batch size (SGD) | Section 4.2.1 | 100 |
| Momentum | Section 4.2.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzalez Tejeda, Y.; Mayer, H.A. Deep Learning with Convolutional Neural Networks: A Compact Holistic Tutorial with Focus on Supervised Regression. Mach. Learn. Knowl. Extr. 2024, 6, 2753-2782. https://doi.org/10.3390/make6040132
Gonzalez Tejeda Y, Mayer HA. Deep Learning with Convolutional Neural Networks: A Compact Holistic Tutorial with Focus on Supervised Regression. Machine Learning and Knowledge Extraction. 2024; 6(4):2753-2782. https://doi.org/10.3390/make6040132
Chicago/Turabian StyleGonzalez Tejeda, Yansel, and Helmut A. Mayer. 2024. "Deep Learning with Convolutional Neural Networks: A Compact Holistic Tutorial with Focus on Supervised Regression" Machine Learning and Knowledge Extraction 6, no. 4: 2753-2782. https://doi.org/10.3390/make6040132
APA StyleGonzalez Tejeda, Y., & Mayer, H. A. (2024). Deep Learning with Convolutional Neural Networks: A Compact Holistic Tutorial with Focus on Supervised Regression. Machine Learning and Knowledge Extraction, 6(4), 2753-2782. https://doi.org/10.3390/make6040132