1. Introduction
Optimization is a fundamental concept in various fields, including mathematics, computer science, engineering, economics, and operations research. It involves finding the best possible solution to a problem within a given set of constraints. The goal of optimization is to maximize or minimize an objective function, which represents the measure of performance or utility [
1].
In optimization, the objective is to find the optimal solution that achieves the highest possible value for a maximization problem or the lowest possible value for a minimization problem. The solution can be a single point in the search space or a set of values for multiple variables or parameters [
2]. The process of optimization typically involves defining the problem, specifying the objective function and constraints, selecting an appropriate optimization algorithm or method, and iteratively refining the solution to converge toward the optimal outcome [
3]. The optimization algorithm explores the search space, evaluating different candidate solutions and making adjustments based on specific rules or principles to improve the objective function value [
4]. Typically, a constrained optimization problem can be mathematically formulated as follows: Minimize (or maximize) the objective function
subject to a set of constraints
and
, where
is the vector of decision variables with a dimension of
D. Mathematically, it can be written as [
2]:
Here,
represents the objective function that needs to be minimized or maximized. The decision variables are represented by the vector
, which can be a single variable or a set of variables with a dimension of
D. The constraints are defined by the functions
and
. The inequality constraints
represent the conditions that must be satisfied, and the equality constraints
represent the equality relationships in the problem. The index
i ranges from 1 to
M for inequality constraints, and the index
j ranges from 1 to
N for equality constraints. If the problem does not have inequality and equality constraints, it is called an unconstrained optimization problem [
5]. The solution to the constrained optimization problem is a vector
that optimizes the objective function
while satisfying all the constraints. The goal is to find the values of the decision variables
that minimize or maximize the objective function while satisfying the given constraints.
Various optimization techniques and algorithms can be employed to solve constrained optimization problems, such as gradient-based methods, linear programming, nonlinear programming, and evolutionary algorithms, depending on the problem’s characteristics and complexity. Optimization algorithms can be classified into several categories based on their approach and characteristics [
6]. Four common categories are exact methods, approximation methods, metaheuristic methods, and derivative-based methods.
1.1. Exact Methods
Exact methods aim to find the optimal solution by exhaustively exploring the entire solution space. These algorithms guarantee that the solution obtained is the global optimum, but they may be computationally expensive and impractical for large-scale problems [
7]. Some examples of exact methods include:
Branch and bound: Divides the problem into smaller subproblems and prunes branches that are known to be suboptimal [
8].
Integer programming: Optimizes linear functions subject to linear equality and inequality constraints, with some or all variables restricted to integer values [
9].
Dynamic programming: Breaks down the problem into overlapping subproblems and solves them recursively, storing and reusing the intermediate results [
10].
1.2. Approximation Methods
Approximation methods focus on finding a solution that is close to the optimal solution without guaranteeing optimality. These algorithms often provide good-quality solutions within a reasonable time frame and are suitable for large-scale problems where finding the global optimum is computationally infeasible. Some examples of approximation methods include:
Greedy algorithms: Make locally optimal choices at each step to construct a solution incrementally [
11].
Randomized algorithms: Introduce randomness to explore the solution space and find near-optimal solutions [
12].
1.3. Metaheuristic Methods
Metaheuristic methods are general-purpose optimization algorithms that guide the search for solutions by iteratively exploring the solution space. They are often inspired by natural phenomena or analogies and are applicable to a wide range of problems. Some popular metaheuristics methods include:
Simulated annealing: Mimics the annealing process in metallurgy, allowing occasional uphill moves to escape local optima [
13].
Genetic algorithms: Inspired by the process of natural selection, genetic algorithms evolve a population of candidate solutions through selection, crossover, and mutation operations [
14].
Particle swarm optimization: Simulates the movement and interaction of a swarm of particles to find optimal solutions by iteratively updating their positions [
15].
Ant colony optimization: Mimics the foraging behavior of ants, where artificial ants deposit pheromones to guide the search for optimal paths or solutions [
16].
1.4. Derivative-Based Methods
Derivative-based methods, also known as gradient-based methods, utilize information about the derivative of the objective function to guide the search for the optimum. These methods are effective when the objective function is differentiable. In other words, derivative-based methods are particularly useful in continuous optimization problems where the objective function is smooth and the derivatives can be efficiently computed. Some derivative-based optimization algorithms include:
Gradient descent: Iteratively updates the solution in the direction of the steepest descent of the objective function [
17].
Newton’s method: Utilizes both the first and second derivatives of the objective function to approximate the optimum more efficiently [
18].
Quasi-Newton methods: Approximate the Hessian matrix (second derivatives) using a limited number of function and gradient evaluations to improve convergence speed [
19].
It is important to note that this classification is not exhaustive, and there are other specialized optimization algorithms and techniques available for different types of problems. The choice of optimization algorithm depends on the problem characteristics, computational resources, and desired trade-offs between solution quality and computational efficiency [
20]. In addition, optimization has diverse applications across various domains, such as engineering design, operations management, financial planning, scheduling, machine learning, and data analysis. It plays a crucial role in improving efficiency, resource allocation, decision making, and overall performance in a wide range of real-world problems. Here are some notable applications of optimization in our everyday lives:
Transportation and routing: Optimization algorithms are used in transportation systems to optimize routes, schedules, and logistics. Whether it involves finding the shortest path for navigation apps, optimizing traffic signal timings, or planning public transportation routes, optimization helps minimize travel time, reduce congestion, and enhance overall transportation efficiency [
21,
22,
23].
Resource management: Optimization techniques are employed in diverse areas of resource management. For instance, energy companies optimize power generation and distribution to meet demand while minimizing costs. Water management systems optimize water distribution to ensure equitable supply and minimize wastage. Optimization is also applied in inventory management, supply-chain logistics, and workforce scheduling to optimize resource allocation and improve operational efficiency [
24,
25,
26].
Financial planning and investment: Optimization is widely used in financial planning and investment strategies. It helps investors optimize their portfolios by considering risk-return trade-offs. Optimization algorithms can determine the optimal allocation of funds across different assets or investment opportunities, aiming to maximize returns while managing risk within specified constraints [
27,
28].
Production and manufacturing: Optimization is crucial in production and manufacturing processes to improve efficiency, reduce costs, and maximize output. Production scheduling optimization algorithms help determine the optimal sequence and timing of manufacturing operations. Additionally, optimization is utilized in capacity planning, facility layout design, and supply-chain optimization to streamline operations and minimize waste [
29,
30,
31].
Energy optimization: Energy optimization plays a significant role in promoting sustainable practices and reducing environmental impact. Optimization techniques are employed in energy-efficient buildings, where they control heating, ventilation, and air-conditioning systems to optimize energy consumption while maintaining comfort levels. Smart grid technologies also leverage optimization algorithms to optimize power generation, distribution, and consumption, facilitating energy conservation [
32,
33,
34,
35].
Personal health and fitness: Optimization algorithms are increasingly being used in personal health and fitness applications. Fitness trackers and mobile apps employ optimization techniques to provide personalized exercise and diet plans, optimizing the balance between calorie intake and expenditure. These algorithms consider individual goals, preferences, and constraints to help users achieve desired health and fitness outcomes [
36,
37,
38,
39,
40].
Internet and e-commerce: Optimization algorithms are utilized in internet-based applications and e-commerce platforms to enhance the user experience and optimize various processes. From search engine algorithms that rank search results to recommendation systems that personalize product suggestions, optimization is employed to improve relevance, efficiency, and customer satisfaction [
41,
42,
43].
These are just a few examples that highlight the wide range of applications where optimization algorithms and techniques are utilized to improve efficiency, decision making, and resource allocation in our daily lives. Optimization continues to drive advancements and contribute to enhancing various aspects of our modern society.
Hybrid metaheuristic algorithms represent a critical and evolving frontier in optimization research, addressing the inherent limitations of individual algorithms by harnessing the collective strengths of diverse optimization techniques. In a complex and dynamic problem landscape where no single algorithm universally excels, hybridization offers a compelling approach to achieving enhanced performance, increased robustness, and superior convergence rates. By fusing different algorithms, these hybrids can adapt to various problem characteristics, balance exploration and exploitation, and efficiently navigate high-dimensional solution spaces. As real-world challenges become more intricate, the ability of hybrid metaheuristics to provide innovative solutions is paramount, driving the progress of optimization methodologies across domains ranging from engineering and finance to artificial intelligence and beyond. Over the past few years, numerous hybrid algorithms have emerged in the literature, and we will examine a selection of these. The study outlined in [
44] demonstrates two hybrid metaheuristic algorithms, specifically the genetic algorithm and the multiple population genetic algorithm, that are synergistically combined with variable neighborhood search to tackle some challenging NP-hard problems. The research highlighted in [
45] portrays an innovative hybrid algorithm that merges genetic algorithms with the spotted hyena algorithm to effectively address the complexities of the production shop scheduling problem. The research work showcased in [
46] describes an advanced hybrid metaheuristic approach for solving the traveling salesman problem with drones. This approach draws from two algorithms, namely the genetic algorithm and the ant colony optimization algorithm. The paper in [
47] establishes an innovative approach known as the hybrid muddy soil fish optimization-based energy-aware routing scheme, designed to enhance the efficiency of routing in wireless sensor networks, facilitated by the Internet of Things. The research discussed in [
48] introduces a novel metaheuristic approach, the hybrid brainstorm optimization algorithm, to effectively address the emergency relief routing problem. This innovative algorithm amalgamates concepts from the simulated annealing algorithm and the large neighborhood search algorithm into the foundation of the former, to significantly enhance its capacity to evade local optima and speed up the convergence process. The examination in [
49] exposes a groundbreaking hybrid metaheuristic algorithm, termed the chaotic sand-cat swarm optimization, as a potent solution for intricate optimization problems that exhibit constraints. This algorithm seamlessly merges the attributes of the newly introduced technique with the innovative concept of chaos, promising enhanced performance in handling complex scenarios. The inquiry described in [
50] introduces the hybridization of the particle swarm optimization with variable neighborhood search and simulated annealing to tackle permutation flow-shop scheduling problems. The findings detailed in [
51] highlight an original hybrid algorithm integrating principles from the particle swarm optimization and puffer fish algorithms, aiming to accurately estimate parameters related to fuel cells. The study in [
52] showcases the fusion of the brainstorm optimization algorithm with the chaotic accelerated particle swarm optimization algorithm. The purpose is to explore the potential enhancements that this amalgamated approach could offer over using the individual algorithms independently. The research elucidated in [
53] presents an innovative hybrid learning moth search algorithm. This algorithm uniquely integrates two distinct learning mechanisms: global-best harmony search learning and Baldwinian learning. The objective is to effectively address the multidimensional knapsack problem, harnessing the benefits of these combined learning approaches.
The research described in this paper proposes a novel contribution by integrating the opposition Nelder–Mead algorithm into the selection phase of genetic algorithms to address the premature convergence problem and enhance exploration capabilities. This integration offers several significant advantages and advancements to the field of optimization and evolutionary computation, including:
Prevention of premature convergence: Premature convergence is a common issue in genetic algorithms [
54,
55,
56], where the algorithm converges to suboptimal solutions without adequately exploring the search space. By incorporating the opposition Nelder–Mead algorithm into the selection phase, our research provides a solution to this problem. The opposition Nelder–Mead algorithm, known for its effectiveness in local search and optimization [
57], brings its exploratory power to the genetic algorithm. This integration ensures that the algorithm can avoid premature convergence by continuously exploring and exploiting promising regions of the search space.
Enhanced exploration capabilities: The integration of the opposition Nelder–Mead algorithm into the selection phase enhances the exploration capabilities. Genetic algorithms traditionally rely on genetic operators such as crossover and mutation for exploration. However, these operators may not be sufficient to thoroughly explore complex search spaces [
58]. By incorporating the opposition Nelder–Mead algorithm, which excels in local exploration, our methodology enhances the exploration capabilities of genetic algorithms. This integration enables a more comprehensive search of the search space, leading to the discovery of diverse and potentially better solutions.
Improved convergence speed and solution quality: The integration of the opposition Nelder–Mead algorithm offers the potential for improved convergence speed and solution quality. The opposition Nelder–Mead algorithm is known for its efficiency in converging toward local optima. By utilizing this algorithm during the selection phase, our methodology aims to guide the genetic algorithm toward better solutions at a faster rate. This combination of global exploration from genetic algorithms and local optimization from the Nelder–Mead algorithm results in an algorithm that can converge faster and produce high-quality solutions. It is worth pointing out that the convergence speed in metaheuristics refers to the rate at which an algorithm approaches a solution of acceptable quality. It indicates how quickly an algorithm narrows down its search space and refines its solutions, ultimately aiming to find an optimal or near-optimal solution. A faster convergence speed implies that the algorithm reaches promising solutions in fewer iterations, whereas a slower convergence speed suggests that more iterations are needed to achieve comparable results. It is clear now that the integration of the iterative process of the Nelder–Mead algorithm into the iterative process of the genetic algorithm would improve its convergence speed.
Practical applicability and generalizability: The proposed methodology holds practical applicability and generalizability. Genetic algorithms are widely used in various fields and domains for optimization problems. By addressing the premature convergence problem and enhancing exploration capabilities, our research contributes to the broader applicability and effectiveness of genetic algorithms in real-world scenarios. The integration can potentially be applied to a wide range of optimization problems, providing practitioners and researchers with a valuable tool to improve their optimization processes.
In summary, our research paper makes a significant contribution by integrating the opposition Nelder–Mead algorithm into the selection phase of genetic algorithms. This integration addresses the premature convergence problem, enhances exploration capabilities, improves convergence speed and solution quality, and offers practical applicability and generalizability. The proposed approach has the potential to advance the field of optimization and evolutionary computation, empowering practitioners and researchers with an effective tool for solving complex optimization problems.
This paper is organized into four sections:
Section 2: Background;
Section 3: Proposed Methodology;
Section 4: Experimental Results and Discussion; and
Section 5: Conclusions and Future Scope.
Section 2 provides an overview of the relevant concepts used to establish the context for the research.
Section 3 outlines the specific approach used to integrate the opposition Nelder–Mead algorithm into the selection phase of genetic algorithms and highlights its potential benefits.
Section 4 presents the empirical evaluation of the proposed methodology, including the experimental setup, results, and analysis. Finally,
Section 5 summarizes the key findings, discusses the implications of the research, and suggests potential future directions for further exploration.
3. Proposed Methodology
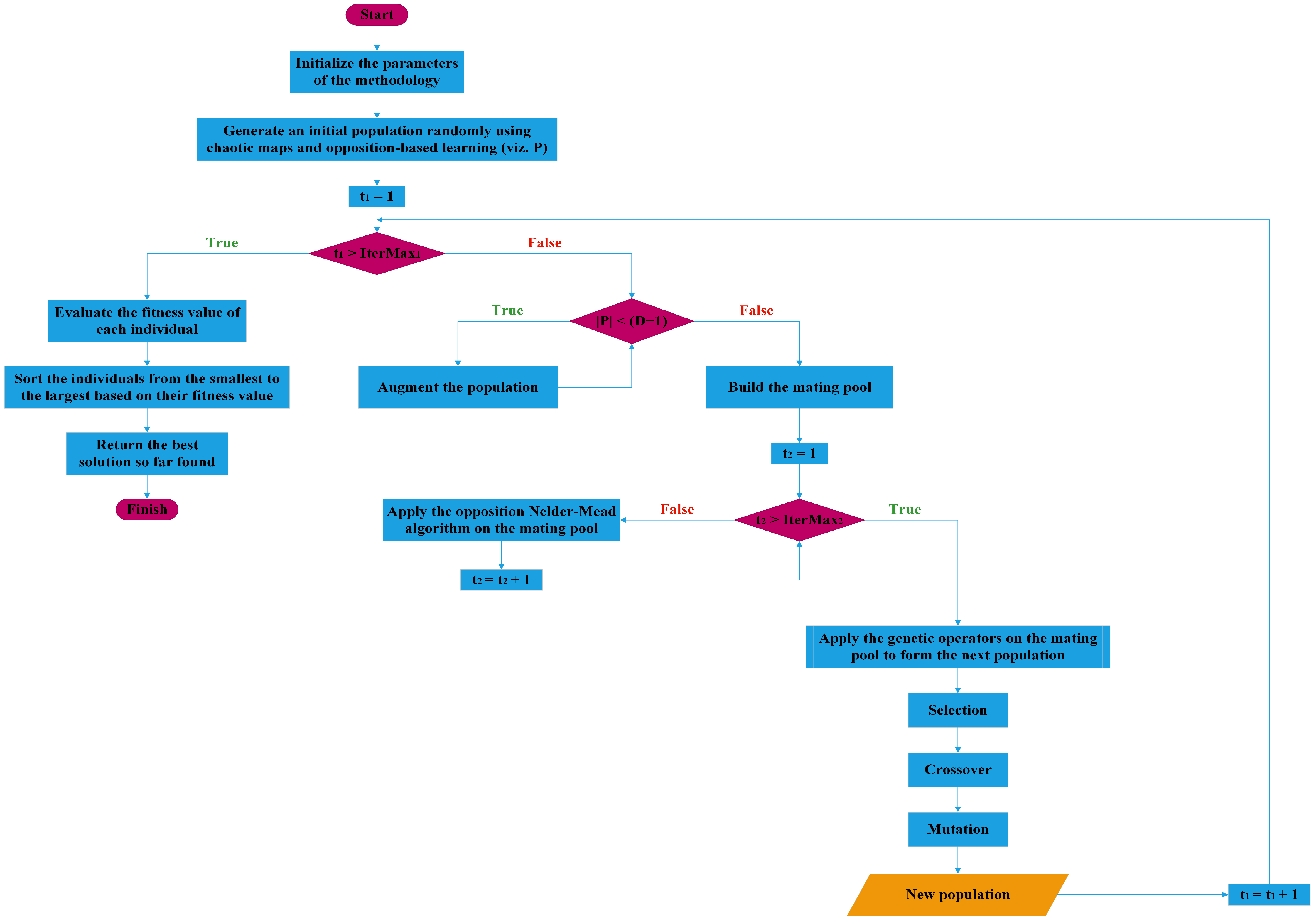
In this section, we provide a comprehensive and detailed description of the proposed methodology, which involves the integration of the Nelder–Mead algorithm into the selection phase of the genetic algorithm. We delve into the specific steps and procedures involved in this integration, elucidating how the two algorithms interact and complement each other. Furthermore, we present the mathematical formulations and algorithms employed, providing a clear and systematic explanation of the modified selection process. By providing a thorough and meticulous description, we aim to ensure that readers have a comprehensive understanding of the proposed methodology and its underlying mechanisms. The flowchart presented in
Figure 1 depicts the main phases of the proposed methodology. In the subsequent sections, we provide a detailed description of each phase.
3.1. Phase 1: Initialization of Parameters
The initial phase of our methodology involves the crucial step of parameter initialization, which lays the foundation for the subsequent stages. In this phase, we meticulously define and set the values of the parameters that govern the different algorithms and techniques of the proposed methodology. These parameters act as the guiding principles and variables that influence its behavior and performance. It is essential to establish appropriate initial values for these parameters, as they significantly impact the overall effectiveness and accuracy of the subsequent computations. Thus, by conscientiously determining the initial values, we ensure a solid starting point for our methodology, enabling reliable and meaningful results throughout the entire process. The parameters and symbols used are:
D: The dimensionality of the search space.
N: The population size.
: The component of vector is bounded below by .
: The component of vector is bounded above by .
: The normal distribution with mean and variance .
: The beta distribution, where and are real numbers.
: The maximum number of iterations for the GA.
: The maximum number of iterations for the Nelder–Mead algorithm.
: The coefficients of reflection.
: The coefficients of expansion.
: The coefficients of contraction.
: The coefficients of shrinkage.
: The probability of performing crossover between pairs of selected individuals during reproduction.
: The probability of introducing random changes or mutations in the offspring to promote diversity.
3.2. Phase 2: Generation of the First Population
Chaotic maps are employed to initialize the first population in metaheuristics. These maps provide a stochastic and highly randomized approach to generating diverse and exploratory initial solutions within the search space. By leveraging the chaotic dynamics of these maps, initial population agents are assigned initial positions in a manner that ensures wide coverage and dispersion across the solution space. This initial diversity is essential for promoting exploration and preventing premature convergence, allowing the metaheuristic algorithm to effectively explore the search space and discover promising regions that may contain optimal or near-optimal solutions. By incorporating chaotic maps in the initialization process, our methodology can enhance its ability to escape local optima and improve the overall performance and convergence characteristics. Equation (
10) serves as a fundamental tool for generating the positions of individuals within the initial population.
We compare seven distinct chaotic schemes [
67], which are Tent (Equation (
11)), Sinusoidal (Equation (
12)), Iterative (Equation (
13)), Singer (Equation (
14)), Sine (Equation (
15)), Chebyshev (Equation (
16)), and Circle maps (Equation (
17)), to determine which one exhibits the best performance. The initial term
of the chaotic sequence
is a random number drawn from the interval
.
Although chaotic maps have proven to be useful in generating population members with higher diversity levels, they can lead to the initialization of candidate solutions that are far from the global optimum, particularly in real-world optimization problems where the global optimum is often unknown. This undesirable situation can impede the rapid convergence of solutions toward promising regions in the search space, compromising the algorithm’s convergence characteristics. To address these limitations of chaotic maps, an OBL strategy is incorporated into the initialization scheme of our methodology. The purpose of this strategy is to explore the broader coverage of the search space by searching for the opposite information of the chaotic population. The inclusion of OBL allows for the simultaneous evaluation of the original chaotic population and its opposite information, thereby increasing the probability of finding fitter solutions in the search space. We compare six distinct OBL strategies, named Strategy 1 [
65] (Equation (
18)), Strategy 2 [
68] (Equation (
19)), Strategy 3 [
69] (Equation (
20)), Strategy 4 [
70] (Equation (
21)), Strategy 5 [
71] (Equation (
22)), and Strategy 6 [
71] (Equation (
23)), to determine which one exhibits the best performance. Let
be a point in the
n-dimensional space, where
are real numbers and
. The opposite point of
is denoted by
and can be calculated using one of Equations (
18)–(
22), or (
23).
Algorithm 1 serves as a valuable tool for demonstrating the operational principles of the initialization phase within our methodology. By presenting a step-by-step procedure, it effectively showcases how the initial population of candidate solutions is generated. Through Algorithm 1, we highlight the specific techniques and strategies employed to create a diverse and representative set of individuals at the beginning of the optimization process. It is worth pointing out that if a candidate solution exceeds the boundaries of the search space after undergoing an opposition operation, it is subsequently restored to within the valid range utilizing Equation (
24).
| Algorithm 1: The pseudocode for the initialization phase of our methodology. |
| | Input: D: The dimensionality of the search space.
|
| | Input: N: The population size.
|
| | Input: : The lower boundaries of entries .
|
| | Input: : The upper boundaries of entries .
|
| | Input: : The multivariate function to be minimized.
|
| 1 |
for to N do |
| 2 | |
for to D do |
| 3 | | |
if () then |
| 4 | | | | |
| 5 | | |
end |
| 6 | | |
else |
| 7 | | | |
is updated using the selected chaotic map (Equations (11)–(16) or (17);
|
| 8 | | |
end |
| 9 | |
end |
| 10 | | Compute using Equation (10); |
| 11 | |
Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23);
|
| 12 | |
;
|
| 13 |
end |
3.3. Phase 3: Augmentation of the Population
The Nelder–Mead algorithm requires the construction of a simplex with exactly vertices, where D represents the dimensionality of the problem. However, in some cases, the number of individuals available in the initial population is smaller than , i.e., . To overcome this limitation and enable the application of the Nelder–Mead algorithm, we augment the population size by generating additional individuals. By introducing these extra individuals, we ensure that the simplex can be properly formed, allowing the algorithm to proceed as intended. This augmentation step ensures that the optimization process can fully leverage the capabilities of the Nelder–Mead algorithm, even when the initial population size is insufficient to construct the required simplex.
In optimization, when the population size is insufficient or does not meet the requirements of certain algorithms, techniques can be employed to augment or expand the population. These techniques aim to increase the diversity, coverage, or exploration capabilities of the population to enhance the optimization process. Some common techniques used to augment a population in optimization include:
Scaling: Scaling a vector
in an
n-dimensional search space involves adjusting the magnitude of its components uniformly. Mathematically, the scaled vector
can be obtained by multiplying each component of the original vector
by a scaling factor
s (Equation (
25)) [
72].
where
represents the original vector in
n-dimensional space, and
represents the scaled vector. The scaling factor
s determines the magnitude of the scaling applied to the vector, allowing for the contraction (
) or expansion (
) of its length. In our methodology, the scaling factor
s is generated randomly from the normal distribution
.
Rotation: Rotating a vector
in an
n-dimensional search space involves changing its direction or orientation while preserving its magnitude. Mathematically, the rotated vector
can be obtained by multiplying the original vector
by a rotation matrix
R (Equation (
26)) [
72].
where
represents the original vector in the
n-dimensional space,
represents the rotated vector,
p and
q represent the spanned plane, and
is the rotation angle. The rotation matrix
R depends on the specific rotation operation being applied and is typically constructed using a combination of trigonometric functions, such as sine and cosine, to represent the desired rotation angles and axes in the
n-dimensional space. In our methodology, the rotation angle
is computed using the expression
, where the term
denotes the Bernoulli distribution with a probability of success equal to 0.5.
Translation: Translating a vector
in an
n-dimensional search space involves shifting its position without changing its direction or magnitude. Mathematically, the translated vector
can be obtained by adding a translation vector
to the original vector
(Equation (
27)) [
72].
where
represents the original vector in the
n-dimensional space,
represents the translated vector, and
represents the translation vector. The translation vector
contains the amounts by which each component of the original vector is shifted along its respective axes. In our methodology, the vector
is generated randomly from the normal distribution
.
Reflection: Reflecting a vector
in an
n-dimensional search space involves creating its mirror image across a specified line or plane while preserving its magnitude. Mathematically, the reflected vector
can be obtained by subtracting the original vector
from the double of the projection of
onto the reflection line or plane (Equation (
28)) [
72].
where
represents the original vector in the
n-dimensional space,
represents the reflected vector,
represents the normal vector of the reflection line or plane, and · denotes the dot product between two vectors. The reflection operation effectively flips the sign of the component along the reflection axis, resulting in the mirror image of the original vector. In our methodology, the vector
is generated randomly from the normal distribution
.
Similarity transformation: The similarity transformation of a vector
in an
n-dimensional search space involves scaling and rotating the vector while preserving its shape. Mathematically, the transformed vector
can be obtained by first scaling the original vector
by a scaling factor
s and then rotating it using a rotation matrix
R (Equation (
29)) [
72].
where
represents the original vector in the
n-dimensional space,
represents the transformed vector,
s is the scaling factor, and
R is the rotation matrix. The similarity transformation allows for modifications in size and orientation while preserving the relative positions of the vector’s components.
Algorithm 2 serves as a concise representation, capturing the key stages of the augmentation phase. This algorithm effectively distills the fundamental procedures and essential processes involved in augmenting a given population. By encapsulating the primary steps in a succinct form, Algorithm 2 enables a clear understanding of the augmentation phase, offering a compact yet comprehensive guide for implementing this crucial component of our methodology. It is worth mentioning that if the generated candidate solution exceeds the boundaries of the search space after undergoing a geometric transformation, it is subsequently restored to within the valid range utilizing Equation (
24).
| Algorithm 2: The pseudocode for the augmentation phase of our methodology. |
| | Input: D: The dimensionality of the search space.
|
| | Input: : The lower boundaries of entries .
|
| | Input: : The upper boundaries of entries .
|
| | Input: : The candidate solutions within the current population.
|
| 1 |
while do |
| 2 | | Select a random vector , where , using roulette-wheel selection; |
| 3 | | Compute the vector using the selected augmentation operation (Equations (25)–(28) or (29); |
| 4 | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 5 | | ; |
| 6 | | Add the new vector to the population P; |
| 7 |
end |
3.4. Phase 4: Building the Mating Pool
During this phase, the individuals within the population undergo a sorting process to identify the most promising candidates. The goal is to select candidate solutions, where D represents the dimensionality of the problem. These selected individuals will serve as the entry points for the subsequent application of the opposition Nelder–Mead algorithm. By carefully sorting and choosing these initial candidates, the mating pool is effectively formed, paving the way for further optimization and refinement through the proposed methodology. This critical phase ensures that the subsequent steps of our methodology are initiated with a set of highly competitive solutions, maximizing the potential for successful optimization and convergence.
In the process of building the mating pool, we employ the roulette-wheel selection method [
73]. The specific approach varies depending on the size of the population. In the case where the population size is equal to or less than
, we apply roulette-wheel selection to the augmented population. This augmented population includes additional individuals that have been generated to meet the minimum population size requirement. However, if the population size exceeds
, we solely utilize roulette-wheel selection on the current population without any augmentation.
3.5. Phase 5: Application of the Opposition Nelder–Mead Algorithm
Algorithm 3 serves as a demonstration of the working principle underlying the opposition Nelder–Mead algorithm, which plays a pivotal role in our methodology. By following the steps outlined in Algorithm 3, we can witness firsthand how the opposition Nelder–Mead algorithm operates to optimize a given objective function. This algorithm showcases the dynamic interplay between reflection, expansion, contraction, and shrinking, allowing us to iteratively refine and improve the selection phase of the GA. Algorithm 3 encapsulates the essence of the opposition Nelder–Mead algorithm’s working principle, providing a clear and practical illustration of its effectiveness in guiding the selection phase of the GA on the one hand, and the optimization process within our methodology on the other hand. It is worth mentioning that if a vertex exceeds the boundaries of the search space after undergoing the operations described in Algorithm 3, it is consequently restored to within the valid range using Equation (
24).
| Algorithm 3: The pseudocode for the opposition Nelder–Mead algorithm.
|
| | Input: : The lower boundaries of entries .
|
| | Input: : The upper boundaries of entries .
|
| | Input: : The candidate solutions within the mating pool.
|
| | Input: , , , and : The coefficients of reflection, expansion, contraction, and shrinkage, respectively.
|
| | Input: : The multivariate function to be minimized.
|
| 1 |
for to do |
| 2 | | Compute the best vertex using Equation (30); |
| 3 | | Compute the worst vertex using Equation (31); |
| 4 | | Compute the next-worst vertex using Equation (32); |
| 5 | | Compute the centroid excluding the worst vertex using Equation (33); |
| 6 | | Compute the reflection vertex using Equation (5); |
| 7 | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 8 | |
if then |
| 9 | | | ; |
| 10 | |
end |
| 11 | |
if then |
| 12 | | | Compute the expansion vertex using Equation (6); |
| 13 | | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 14 | | | if then |
| 15 | | | | |
| 16 | | |
end |
| 17 | | |
else |
| 18 | | | | |
| 19 | | |
end |
| 20 | |
end |
| 21 | |
if then |
| 22 | | | if then |
| 23 | | | | Compute the outside contraction vertex using Equation (7); |
| 24 | | | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 25 | | | | if then |
| 26 | | | | |
|
| 27 | | | |
end |
| 28 | | |
end |
| 29 | | | if then |
| 30 | | | | Compute the inside contraction vertex using Equation (8); |
| 31 | | | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 32 | | | | if then |
| 33 | | | | |
|
| 34 | | | |
end |
| 35 | | |
end |
| 36 | |
end |
| 37 | |
for do |
| 38 | | | Update the vertex using Equation (9); |
| 39 | | | Compute using the selected opposition-based learning strategy (Equations (18)–(22) or (23); |
| 40 | | | |
| 41 | |
end |
| 42 |
end |
3.6. Phase 6: Application of Genetic Operators
The presented study provides a comprehensive understanding of the GA by delineating its key components into distinct sections.
Section 3.6.1 elucidates the intricate details of the selection process, where individuals from the population are carefully chosen to pass on to the next generation.
Section 3.6.2 focuses on the reproduction process, outlining how the selected parents generate offspring through recombination operations. Lastly, in
Section 3.6.3, the mutation process takes center stage, elucidating the mechanisms through which the genetic material of the individuals undergoes random modifications to introduce novel genetic information. It is worth pointing out that if an individual exceeds the boundaries of the search space after undergoing the genetic operators, it is consequently restored to within the valid range using Equation (
24).
3.6.1. Selection
Genetic algorithms are a type of evolutionary algorithm that mimics the process of natural selection to solve optimization problems. In GAs, the selection mechanism determines which individuals from a given population will be passed to the next generation. The selection process is crucial in driving the search for better solutions over successive generations. Several common selection mechanisms are used in GAs [
74]. In our methodology, we use elitism [
75]. Elitism involves selecting a certain number of the best individuals from the current population and directly transferring them to the next generation without any changes. This ensures that the best solutions found so far are preserved across generations, preventing the loss of fitness during the evolution process.
3.6.2. Crossover
The crossover technique used to deal with continuous values in genetic algorithms is known as BLX-
(Blend Crossover) [
76]. BLX-
is a variation of the traditional crossover operator used in genetic algorithms, which is typically designed for binary or discrete variables. BLX-
allows for the combination of parent solutions that have continuous values.
In the BLX- crossover, a new offspring is created by blending the values of corresponding variables from two parent solutions. The process involves selecting a random value within a defined range for each variable and using the blending factor to determine the range of values for the offspring. The blending factor, denoted as alpha (), controls the amount of exploration and exploitation during the crossover process. The following steps present a high-level description of the BLX- crossover technique used in our methodology. Steps 1, 2, and 3 are iteratively performed until the size of the next population becomes N. It is worth highlighting that two parent individuals will undergo a crossover process based on a specified crossover rate ():
The value of determines the extent of exploration and exploitation during crossover. A smaller value of encourages more exploration, allowing for a wider range of values in the offspring. Conversely, a larger value of encourages more exploitation, resulting in offspring closer to the parent solutions. The BLX- crossover technique enables the combination of continuous variables in genetic algorithms and provides a way to effectively explore and exploit the search space.
3.6.3. Mutation
The mutation technique, commonly used to deal with continuous values in genetic algorithms, is known as Gaussian mutation or normal distribution mutation [
77]. This technique introduces random perturbations to the values of the variables in a continuous search space, mimicking the behavior of a Gaussian or normal distribution. In Gaussian mutation, a random value is generated from a Gaussian distribution with a mean of zero and a predefined standard deviation. This random value is then added to each variable of an individual in the population, causing a small random change in its value. The standard deviation determines the magnitude of the mutation, controlling the exploration and exploitation trade-off during the search process. It is worth emphasizing that an individual will undergo a mutation process based on a designated mutation rate (
). The following steps introduce a high-level description of the Gaussian mutation technique used in our methodology:
For each variable in an individual, generate a random value from a Gaussian distribution with a mean of zero and a predefined standard deviation.
Generate a random number drawn from the uniform distribution. If the generated number is less than or equal to the specified mutation rate, then add the mutation amount to the current value of the variable to obtain the mutated value.
Repeat steps 1 and 2 for all individuals in the population.
The standard deviation parameter plays a crucial role in Gaussian mutation. A smaller standard deviation leads to smaller random perturbations, resulting in finer exploration and a higher likelihood of converging to a local optimum. Conversely, a larger standard deviation allows for larger random perturbations, promoting broader exploration and the potential to escape local optima. Gaussian mutation enables the exploration of the continuous search space in genetic algorithms by introducing random perturbations to the individuals. It provides a way to balance exploration and exploitation, aiding the algorithm’s ability to search for optimal or near-optimal solutions in continuous domains.
3.7. Time Complexity of the Proposed Methodology
In this section, we delve into the time complexity of the proposed methodology. The efficiency of the methodology is intricately tied to its various phases, namely Phase 2, Phase 3, Phase 4, Phase 5, and Phase 6. The time complexity analysis of each stage provides valuable insights into the overall performance of the methodology. By understanding the time complexities of these individual stages, we gain a comprehensive understanding of how the methodology scales with larger dimensions or more complex problems. Through this examination, we can assess the computational demands and make informed decisions regarding the feasibility and efficiency of implementing the proposed methodology in real-world scenarios.
Table 1 provides a comprehensive summary of the time complexity associated with each phase of the proposed methodology. Finally, by computing the complexities of all phases, we can determine the global complexity of the methodology. It is worth mentioning that the time complexity of a function evaluation is
.
4. Experimental Results and Discussion
The workstation utilized for conducting the experimental study is equipped with a well-suited hardware and software configuration to support the required tasks. The workstation runs on a Windows 11 Home operating system, providing a user-friendly interface and compatibility with a wide range of software applications. The hardware configuration features an Intel(R) Core(TM) i7-9750H CPU, with a base frequency of 2.60 GHz and a maximum turbo frequency of 4.50 GHz. This high-performance processor ensures the efficient execution of computational tasks and data processing. Additionally, the workstation includes 16.0 GB of RAM, enabling the handling of complex calculations with ease. The software suite installed on the workstation consists of Matlab R2020b, a powerful programming language and environment for numerical computing and algorithm development. Furthermore, the IBM SPSS Statistics 26 software is also installed on the workstation, providing a comprehensive platform for statistical analysis and conducting various statistical tests. This combination of hardware and software configurations offers a robust and capable environment for conducting the experimental study, effectively facilitating data analysis, statistical modeling, and computational tasks.
The effectiveness of the proposed methodology was assessed through rigorous testing on the CEC 2022 (
https://github.com/P-N-Suganthan/2022-SO-BO (accessed on 28 June 2023)) benchmark, which comprises a set of 12 hard and challenging test functions. Among these functions, one is unimodal in nature, whereas four are multimodal. Additionally, three functions are designed as hybrid, and the remaining four functions are composite. The use of the unimodal function aims to evaluate the methodology’s exploitation capability, as it requires focusing on refining solutions within a simple search space. The inclusion of multimodal functions allows for assessing the methodology’s exploration capability, as it necessitates exploring a complex search space with multiple optima. Furthermore, the hybrid and composite functions were employed to evaluate the methodology’s ability to strike a balance between exploration and exploitation, as they combine different characteristics and complexities. The comprehensive testing on this diverse set of test functions provided valuable insights into the performance and robustness of the proposed methodology across various optimization scenarios.
Table 2 depicts the features of the test problems suite.
To thoroughly assess the effectiveness of the proposed methodology, it was subjected to a comparative analysis against 11 highly influential and powerful algorithms, specifically:
Co-PPSO: Performance of Composite PPSO on Single Objective Bound Constrained Numerical Optimization Problems of CEC 2022 [
78].
EA4eigN100-10: Eigen Crossover in Cooperative Model of Evolutionary Algorithms applied to CEC 2022 Single Objective Numerical Optimization [
79].
IMPML-SHADE: Improvement of Multi-Population ML-SHADE [
80].
IUMOEAII: An improved IMODE algorithm based on Reinforcement Learning [
81].
jSObinexpEig: An adaptive variant of jSO with multiple crossover strategies employing Eigen transformation [
82].
MTT-SHADE: Multiple Topology SHADE with a tolerance-based composite framework for CEC 2022 Single Objective Bound Constrained Numerical Optimization [
83].
NL-SHADE-LBC: NL-SHADE-LBC algorithm with linear parameter adaptation bias change for CEC 2022 Numerical Optimization [
84].
NL-SHADE-RSP-MID: A version of the NL-SHADE-RSP algorithm with Midpoint for CEC 2022 Single Objective Bound Constrained Problems [
85].
OMCSOMA: Opposite Learning and Multi-Migrating Strategy-Based Self-Organizing Migrating algorithm with a convergence monitoring mechanism [
86].
S-LSHADE-DP: Dynamic Perturbation for Population Diversity Management in Differential Evolution [
87].
NLSOMACLP: NL-SOMA-CLP for Real Parameter Single Objective Bound Constrained Optimization [
88].
Each of these algorithms represents a significant approach in the field of optimization. The comparison was conducted by measuring and reporting the average and standard deviation values for each algorithm. This comprehensive evaluation allowed for a comprehensive understanding of the proposed methodology’s performance in relation to other well-established algorithms. By considering a diverse range of state-of-the-art algorithms, we were able to gain valuable insights into the strengths, weaknesses, and comparative performance of the proposed methodology. To enhance clarity, the algorithms originally labeled Co-PPSO are renamed , and the algorithms originally labeled EA4eigN100-10 are renamed . This renaming convention was also used for the remaining algorithms. By utilizing the new nomenclature (), the presentation and interpretation of the results are more straightforward and unambiguous. Finally, our methodology is renamed .
Table 3 presents the diversity measurements (
) calculated using Equation (
35) during the initialization of the initial population. The diversity values were examined for two different dimensions,
and
. For
, it was observed that the highest diversity value was achieved when employing the chaotic map outlined in Equation (
13) in conjunction with the opposition-based learning technique provided in Equation (
23). On the other hand, for
, the maximum diversity value was obtained when utilizing the chaotic map described in Equation (
11) and the opposition-based learning technique provided in Equation (
20). Consequently, these specific parameters were chosen to conduct the comparative study, as they demonstrated superior diversity in the initial population.
Table 4 presents the initial values selected for the various parameters of the proposed methodology. This table serves as a comprehensive reference for the parameter configurations utilized during the initial stages of the study. Additionally, it is important to note that the initialization of the parameters for the algorithms employed in the comparative study was derived from their respective papers. By incorporating the parameters outlined in the original research papers, we ensure consistency and comparability between our study and previous works. This approach allows for a fair evaluation and unbiased comparison of the performance and effectiveness of the proposed methodology against existing algorithms. The proposed methodology was executed 30 times in order to facilitate the application of the Friedman statistical test. The Cayley–Menger determinant is a determinant that provides the volume of a simplex in
D dimensions. If
S is a
D-simplex in
with vertices
and
denotes the
matrix modeled in Equation (
36), then the volume of the simplex
S, denoted by
, is computed using Equation (
37).
where
is the
matrix obtained from
B by bordering
B with a top vector
and a left column
. Here, the vector L2-norms
are the edge lengths, and the determinant in Equation (
37) is the Cayley–Menger determinant [
89,
90].
Table 5 and
Table 6 report the mean and standard deviation values derived using our methodology and the algorithms employed in our comparative study. These values were calculated for the 12 test functions outlined in
Table 2, providing a comprehensive analysis of their performance and reliability. The computed values were based on
and
, representing the dimensions considered in our analysis. It is worth emphasizing that as the standard deviation value approaches 0, it signifies better algorithm performance, indicating that the algorithm has discovered a solution that is close to optimal. The optimal scenario occurs when the standard deviation value is exactly 0, indicating that the algorithm has successfully identified the optimal solution reported in
Table 2. Moreover, to assess the behavior of the algorithms, the standard deviation values underwent a comprehensive analysis. Following a Friedman test, which evaluated the statistical significance of the differences among the multiple algorithms, Dunn’s post hoc test was applied. This post hoc test allows for further examination of pairwise comparisons, enabling a more detailed understanding of the variations in the performance of the algorithms and identifying significant differences between specific algorithms. The significance level used for the statistical analysis was set at 0.05, indicating that any observed differences between algorithms must have a
p-value less than 0.05 to be considered statistically significant. Additionally, a confidence interval of
was employed, which means that there is a
probability that the true population parameter falls within the calculated interval. This level of confidence provides a reliable estimation of the performance of the algorithms and allows for robust conclusions to be drawn from the analysis.
Friedman’s two-way analysis of variance by ranks test conducted on related samples yielded
p-values of
for
and
for
. These
p-values indicate the statistical significance of differences in the performance of the algorithms across the tested dimensions. Specifically, for
, the obtained
p-value of
suggests a highly significant difference in the performance of the algorithms, whereas for
, the
p-value of
indicates that the observed differences were not statistically significant at the chosen significance level. The obtained ranks are reported in the final rows of
Table 5 and
Table 6. Notably, our methodology achieved the second rank for
, indicating its strong performance compared to the other algorithms considered. In the case of
, our methodology secured the first rank, demonstrating its superior performance relative to the other algorithms in this dimension. These rankings highlight the effectiveness and competitiveness of our methodology across different problem complexities.
For
, the comparison of the performance of the algorithms is presented, highlighting the differences between the algorithms (
). Since for
, there was no observed difference in performance (
), the focus is solely on showcasing the variations in performance among the algorithms for
. In
Table 7, the
p-values obtained using Dunn’s test for
are presented, illustrating the pairwise comparisons of the performance of the algorithms. A value in bold signifies that the algorithm listed in the row outperformed the algorithm listed in the corresponding column. Conversely, a value not in bold indicates that there was no statistically significant difference in terms of performance between the compared algorithms. The values in bold provide a clear indication of the superior performers within the set of algorithms analyzed.




{kind=link}