
A Real-Time Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ Learning and Forgetting Effects


Abstract
1. Introduction
2. Related Work
2.1. Application of Learning and Forgetting Effects in Scheduling
2.2. Multi-Resource Collaborative Scheduling
3. A Collaborative Scheduling Framework for Human–Machine–Logistics Considering Workers’ LFE
3.1. Problem Description and Mathematical Model
- Jobs arrive randomly, and the deadlines vary.
- Each machine can only process one job at a time, and each job can only be processed on one machine at a time.
- Each AGV can only transport one job at a time, and the speed of AGVs is identical.
- Jobs’ arrival times and deadlines are only known upon their arrival.
- Each machine has a buffer zone with a capacity of 10 jobs.
- Each production unit provides loading and unloading areas for logistics units, and loading/unloading times are included in logistics time.
- Each worker can only operate one machine at a time.
- Each worker has a fixed location.
- Each worker has different learning and forgetting effects, and their learning capabilities and forgetting speeds vary.
- Workers’ efficiency fluctuations conform to the learning-forgetting mathematical model.
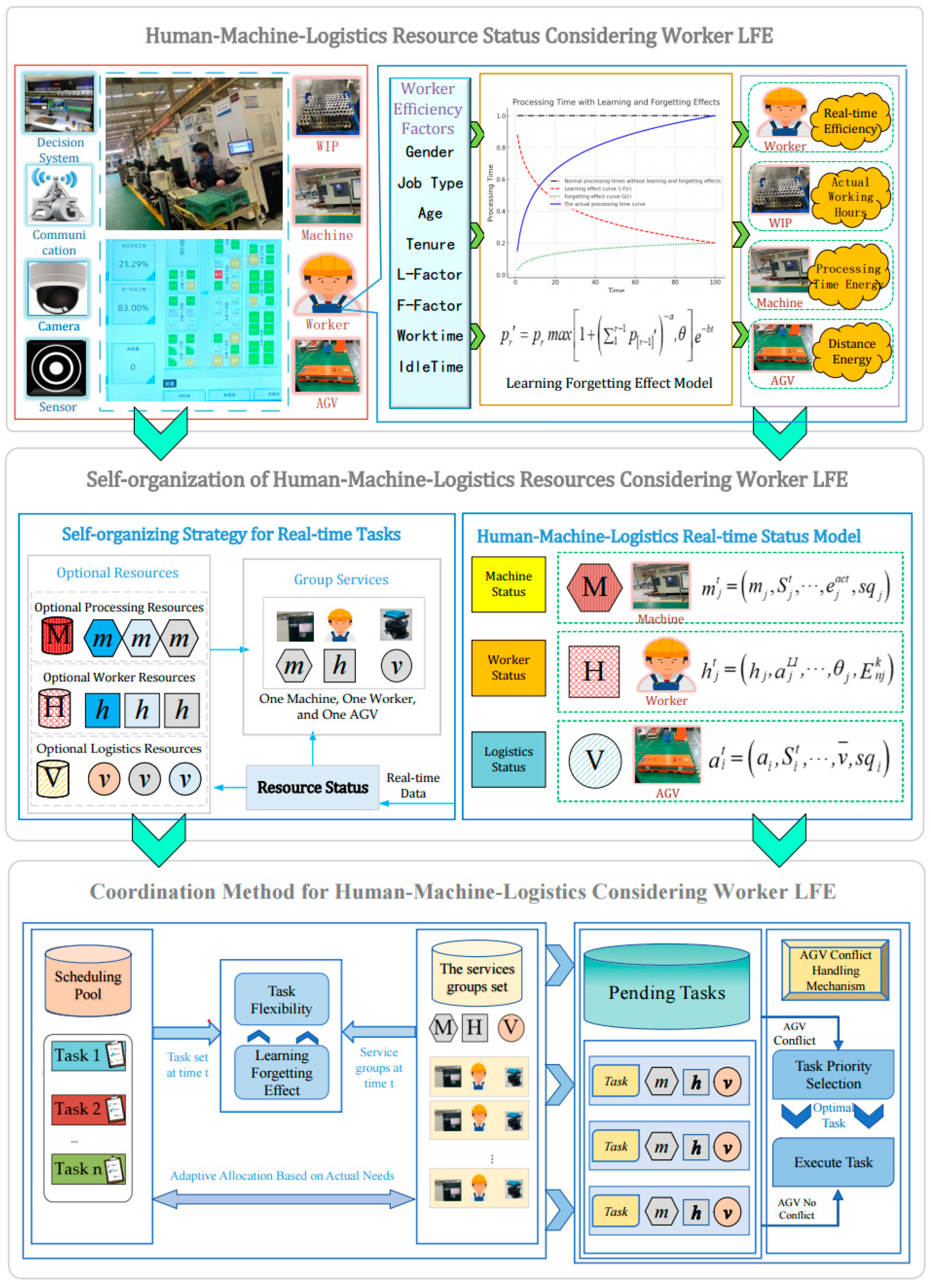
3.2. A Real-Time Human–Machine–Logistics Collaborative Scheduling Framework Considering Workers’ LFE
4. Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ LFE
4.1. Real-Time Status Model of Human–Machine–Logistics Resources
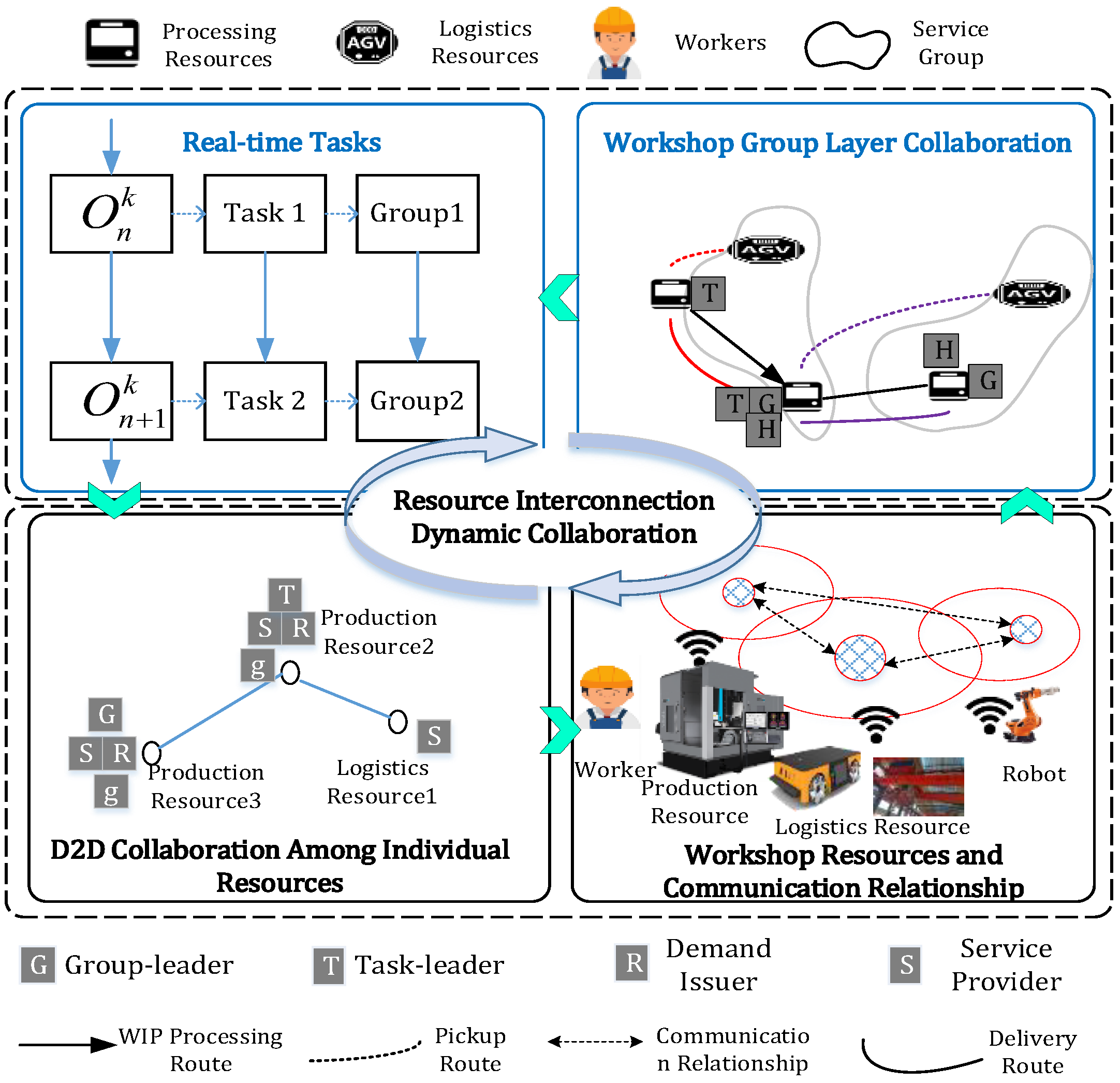
4.2. Real-Time Self-Organization of Human–Machine–Logistics Resources for Real-Time Tasks
4.3. Adaptive Real-Time Scheduling Considering Workers’ Learning and Forgetting Effects
4.3.1. Adaptive Real-Time Allocation Considering Workers’ Learning and Forgetting Effects
4.3.2. AGV Conflict-Handling Mechanism
4.3.3. Human–Machine–Logistics Collaborative Process
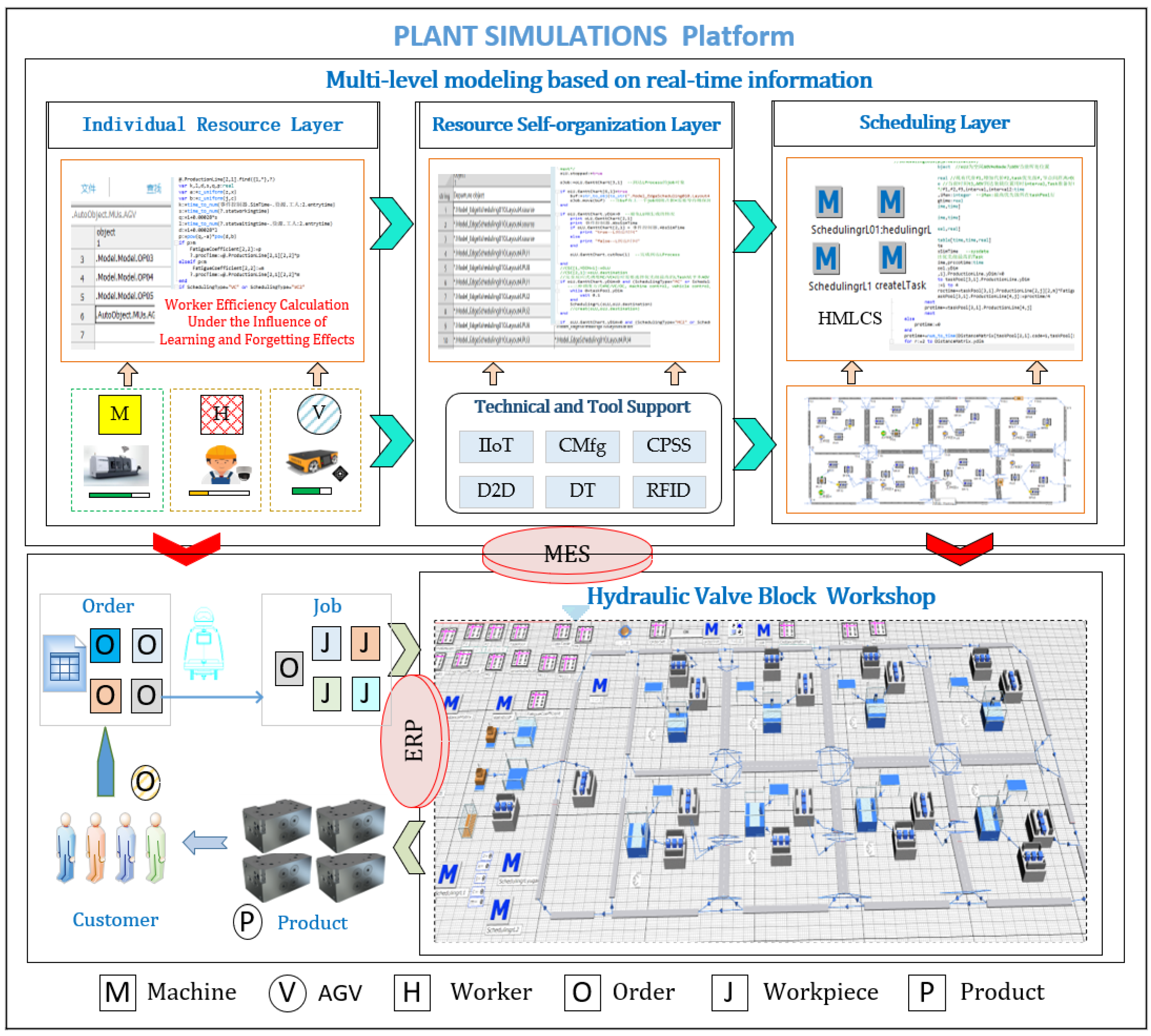
5. Case Study
5.1. Case Description
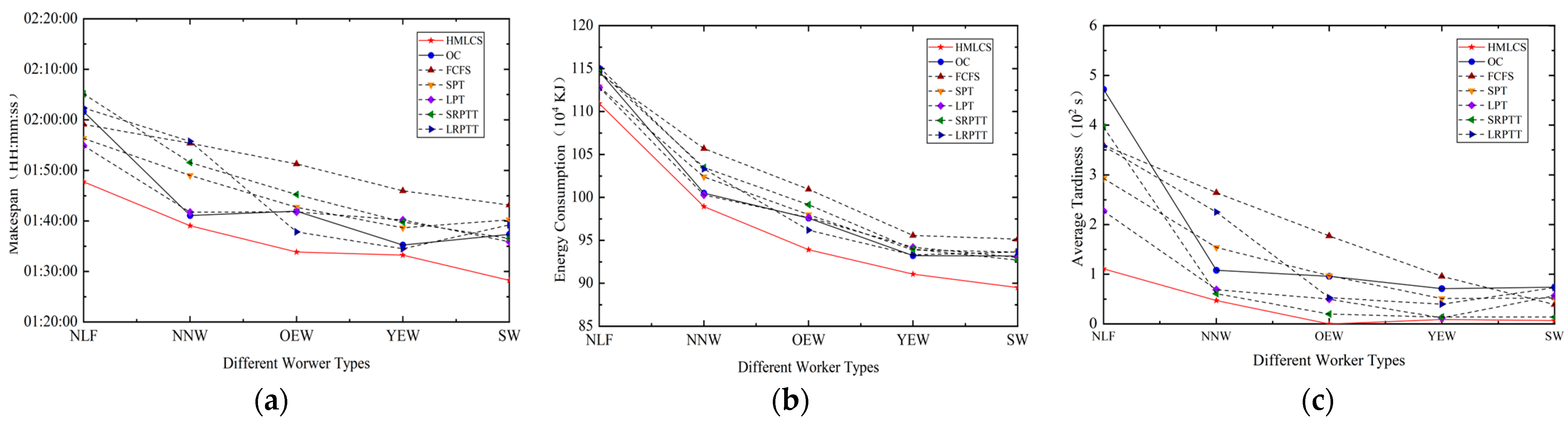
5.2. Effectiveness Analysis of the Proposed Method
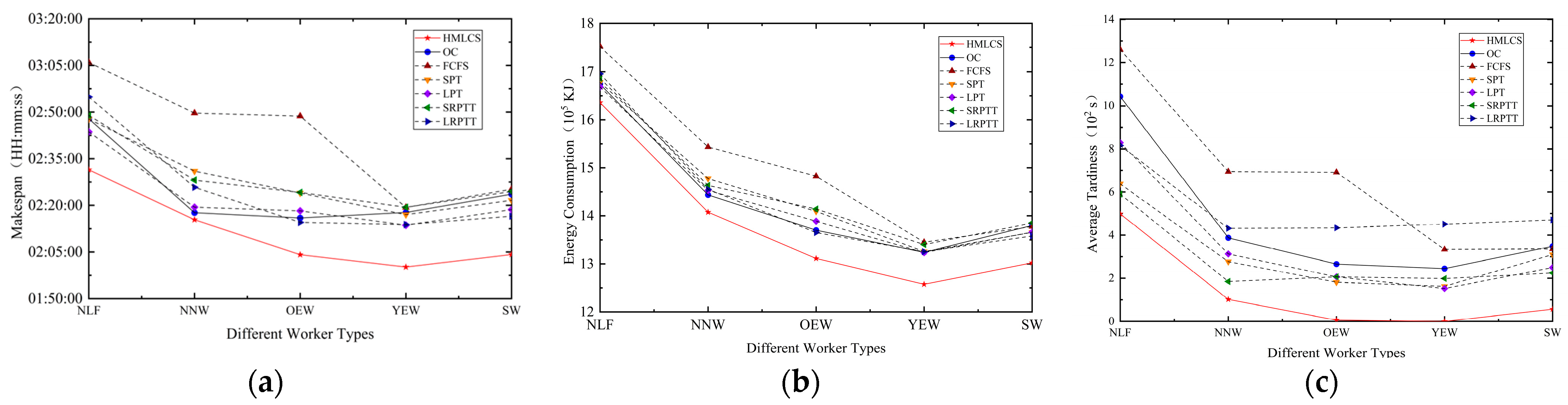
5.3. Analysis of the Impact of Learning and Forgetting Effects on Scheduling
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khan, M.; Haleem, A.; Javaid, M. Changes and improvements in Industry 5.0: A strategic approach to overcome the challenges of Industry 4.0. Green Technol. Sustain. 2023, 1, 100020. [Google Scholar] [CrossRef]
- Solano García, P.; Ramírez-Gutiérrez, A.G.; Morales Matamoros, O.; Coria Páez, A.L. Viable and Sustainable Model for Adoption of New Technologies in Industry 4.0 and 5.0: Case Study on Pellet Manufacturing. Appl. Syst. Innov. 2025, 8, 14. [Google Scholar] [CrossRef]
- Hozdić, E.; Makovec, I. Evolution of the Human Role in Manufacturing Systems: On the Route from Digitalization and Cybernation to Cognitization. Appl. Syst. Innov. 2023, 6, 49. [Google Scholar] [CrossRef]
- Akundi, A.; Euresti, D.; Luna, S.; Ankobiah, W.; Lopes, A.; Edinbarough, I. State of Industry 5.0—Analysis and Identification of Current Research Trends. Appl. Syst. Innov. 2022, 5, 27. [Google Scholar] [CrossRef]
- Coelho, D.A. Sustainable Design and Management of Industrial Systems—A Human Factors Perspective. Appl. Syst. Innov. 2022, 5, 95. [Google Scholar] [CrossRef]
- Anzanello, M.J.; Fogliatto, F.S. Learning curve models and applications: Literature review and research directions. Int. J. Ind. Ergon. 2011, 41, 573–583. [Google Scholar] [CrossRef]
- Shtub, A.; Levin, N.; Globerson, S. Learning and forgetting industrial skills: An experimental model. Int. J. Hum. Factors Manuf. 1993, 3, 293–305. [Google Scholar] [CrossRef]
- Xiong, H.; Shi, S.; Ren, D.; Hu, J. A survey of job shop scheduling problem: The types and models. Comput. Oper. Res. 2022, 142, 105731. [Google Scholar] [CrossRef]
- Bohacs, G.; Győrváry, Z.; Gaspar, D. Integrating scheduling and energy efficiency aspects in production logistics using AGV systems. IFAC Pap. 2021, 54, 294–299. [Google Scholar] [CrossRef]
- Nardo, M.D.; Gallo, M.; Madonna, M.; Santillo, L.C. A Conceptual Model of Human Behaviour in Socio-Technical Systems. In Communications in Computer and Information Science, Intelligent Software Methodologies, Tools and Techniques, SoMeT 2015; Fujita, H., Guizzi, G., Eds.; Springer: Cham, Switzerland, 2015; Volume 532. [Google Scholar] [CrossRef]
- Nardo, M.D.; Murino, T. The System Dynamics in the Human Reliability Analysis Through Cognitive Reliability and Error Analysis Method: A Case Study of an LPG Company. Int. Rev. Civ. Eng. 2021, 12, 56. [Google Scholar] [CrossRef]
- Byeon, S.; Tian, D.; Ayoub, J.; Song, M.; Pari, E.M.; Hwang, I. Optimal Function and Attention Allocation for Human-AI Collaboration Using Computational Cognition-Work Model. In Proceedings of the 2024 IEEE 63rd Conference on Decision and Control (CDC), Milan, Italy, 16–19 December 2024; pp. 2269–2274. [Google Scholar] [CrossRef]
- Biskup, D. Single-machine scheduling with learning considerations. Eur. J. Oper. Res. 1999, 115, 173–178. [Google Scholar] [CrossRef]
- Biskup, D. A state-of-the-art review on scheduling with learning effects. Eur. J. Oper. Res. 2008, 188, 315–329. [Google Scholar] [CrossRef]
- John, G.C.; Alan, R.J. How much does forgetting cost? Ind. Eng. 1976, 8, 40–47. [Google Scholar]
- Lee, W. A note on deteriorating jobs and learning in single-machine scheduling problems. Appl. Math. Model. 2004, 3, 83–89. [Google Scholar]
- Jaber, M.Y.; Kher, H.V. Variant versus invariant time to total forgetting: The learn-forget curve model revisited. Comput. Ind. Eng. 2004, 46, 697–705. [Google Scholar] [CrossRef]
- Jaber, M.Y.; Bonney, M. Production breaks and the learning curve: The forgetting phenomenon. Appl. Math. Model. 1996, 20, 162–169. [Google Scholar] [CrossRef]
- Pan, E.; Wang, G.; Xi, L.; Chen, L.; Han, X. Single-machine group scheduling problem considering learning, forgetting effects and preventive maintenance. Int. J. Prod. Res. 2014, 52, 5690–5704. [Google Scholar] [CrossRef]
- Muştu, S.; Eren, T. The single machine scheduling problem with setup times under an extension of the general learning and forgetting effects. Optim. Lett. 2021, 15, 1327–1343. [Google Scholar] [CrossRef]
- Zhang, X.; Xia, T.; Pan, E.; Li, Y. Integrated optimization on production scheduling and imperfect preventive maintenance considering multi-degradation and learning-forgetting effects. Flex. Serv. Manuf. J. 2022, 34, 451–482. [Google Scholar] [CrossRef]
- Heuser, P.; Tauer, B. Single-machine scheduling with product category-based learning and forgetting effects. Omega 2023, 115, 102786. [Google Scholar] [CrossRef]
- Zhang, L.; Deng, Q.; Lin, R.; Gong, G.; Han, W. A combinatorial evolutionary algorithm for unrelated parallel machine scheduling problem with sequence and machine-dependent setup times, limited worker resources and learning effect. Expert Syst. Appl. 2021, 175, 114843. [Google Scholar] [CrossRef]
- Kurniawan, D.; Raja, A.; Suprayogi, S.; Halim, A. A flow shop batch scheduling and operator assignment model with time-changing effects of learning and forgetting to minimize total actual flow time. J. Ind. Eng. Manag. 2020, 13, 546–564. [Google Scholar] [CrossRef]
- Zhang, Z.; Shao, Z.; Shao, W.; Chen, J.; Pi, D. MRLM: A meta-reinforcement learning-based metaheuristic for hybrid flow-shop scheduling problem with learning and forgetting effects. Swarm Evol. Comput. 2024, 85, 101479. [Google Scholar] [CrossRef]
- Lou, H.; Wang, X.; Dong, Z.; Yang, Y. Memetic algorithm based on learning and decomposition for multiobjective flexible job shop scheduling considering human factors. Swarm Evol. Comput. 2022, 75, 101204. [Google Scholar] [CrossRef]
- Renna, P. Flexible job-shop scheduling with learning and forgetting effect by multi-agent system. Int. J. Ind. Eng. Comput. 2019, 10, 521–534. [Google Scholar] [CrossRef]
- Burdett, R.L.; Corry, P.; Eustace, C.; Smith, S. Scheduling Pre-emptible Tasks with Flexible Resourcing Options and Auxiliary Resource Requirements. Comput. Ind. Eng. 2021, 151, 106939. [Google Scholar] [CrossRef]
- Pizoń, J.; Gola, A. Human–Machine Relationship—Perspective and Future Roadmap for Industry 5.0 Solutions. Machines 2023, 11, 203. [Google Scholar] [CrossRef]
- Wang, D.; Qiao, F.; Guan, L.; Liu, J.; Chen, D. Human–machine collaborative decision-making method based on confidence for smart workshop dynamic scheduling. IEEE Robot. Autom. Lett. 2022, 7, 7850–7857. [Google Scholar] [CrossRef]
- Wang, D.; Qiao, F.; Wang, J.; Liu, J.; Kong, W. Human-machine cooperation based adaptive scheduling for a smart shop floor. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Tokyo, Japan, 23 June 2022; pp. 788–793. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, H.; Gong, Q. Dynamics of human-machine task allocation in intelligent production processes: A case study. Comput. Ind. Eng. 2024, 194, 110354. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, Y. Role-oriented task allocation in human-machine collaboration system. In Proceedings of the IEEE 4th International Conference on Information Systems and Computer Aided Education (ICISCAE), Xi’an, China, 24–26 September 2021; pp. 243–248. [Google Scholar] [CrossRef]
- Wang, D.; Guan, L.; Liu, J.; Chen, D.; Qiao, F. Human–Machine Interactive Learning Method Based on Active Learning for Smart Workshop Dynamic Scheduling. IEEE Trans. Hum. Mach. Syst. 2023, 53, 1038–1047. [Google Scholar] [CrossRef]
- Qu, T.; Pan, Y.; Liu, X.; Kang, K.; Li, C.; Thurer, M.; Huang, G.Q. Internet of Things-based real-time production logistics synchronization mechanism and method toward customer order dynamics. Trans. Inst. Meas. Control. 2017, 39, 429–445. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, Y.; Zhao, X.; Song, X. A Timed Colored Petri Net Simulation-Based Self-Adaptive Collaboration Method for Production-Logistics Systems. Appl. Sci. 2017, 7, 235. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Z.; Lv, J.; Liu, Y. A Framework for Smart Production-Logistics Systems Based on CPS and Industrial IoT. IEEE Trans. Ind. Inform. 2018, 14, 4019–4032. [Google Scholar] [CrossRef]
- Qu, T.; Lei, P.S.; Wang, Z.Z.; Nie, D.X.; Chen, X.; Huang, G.Q. IoT-based real-time production logistics synchronization system under smart cloud manufacturing. Int. J. Adv. Manuf. Technol. 2016, 84, 147–164. [Google Scholar] [CrossRef]
- Qu, T.; Thurer, M.; Wang, J.; Wang, Z.; Fu, H.; Li, C.; Huang, G.Q. System dynamics analysis for an Internet-of-Things-enabled production logistics system. Int. J. Prod. Res. 2017, 55, 2622–2649. [Google Scholar] [CrossRef]
- Luo, Y.; Li, W.F.; Yang, W.C.; Fortino, G. A Real-Time Edge Scheduling and Adjustment Framework for Highly Customizable Factories. IEEE Trans. Ind. Inform. 2021, 17, 5625–5634. [Google Scholar] [CrossRef]
- Lin, Y.; Qu, T.; Zhang, K.; Huang, G.Q. Cloud-based production logistics synchronisation service infrastructure for customised production processes. IET Collab. Intell. Manuf. 2020, 2, 115–122. [Google Scholar] [CrossRef]
- Guo, Z.G.; Zhang, Y.F.; Zhao, X.B.; Song, X. CPS-Based Self-Adaptive Collaborative Control for Smart Production-Logistics Systems. IEEE Trans. Cybern. 2020, 51, 188–198. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Zhu, Z.F.; Lv, J.X. CPS-based smart control model for shopfloor material handling. IEEE Trans. Ind. Inform. 2017, 14, 1764–1775. [Google Scholar] [CrossRef]
- Yang, W.C.; Li, W.F.; Cao, Y.L.; Luo, Y.; He, L. An Information Theory Inspired Real-Time Self-Adaptive Scheduling for Production-Logistics Resources: Framework, Principle, and Implementation. Sensors 2020, 20, 7007. [Google Scholar] [CrossRef]
- Yang, W.C.; Li, W.F.; Cao, Y.L.; Luo, Y.; He, L. Real-Time Production and Logistics Self-Adaption Scheduling Based on Information Entropy Theory. Sensors 2020, 20, 4507. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Li, W.; Luo, Y.; He, L. Real-time scheduling simulation optimisation of job shop in a production-logistics collaborative environment. Int. J. Prod. Res. 2022, 61, 1373–1393. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, S.; Yang, B.; He, Y.; Pang, Z.; Gao, Y. A coupling optimization method of production scheduling and logistics planning for product processing-assembly workshops with multi-level job priority constraints. Comput. Ind. Eng. 2024, 190, 110014. [Google Scholar] [CrossRef]
- Pan, Y.; Zhong, R.Y.; Qu, T.; Zhang, X.; Huang, G.Q. Multi-Level Digital Twin-Driven Kitting-Synchronized Optimization for Production Logistics System. Int. J. Prod. Econ. 2024, 271, 109176. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, C.; Cheng, M.; Wu, Y.; Zhu, J.; Meng, Y.; Liu, X. Optimizing production logistics through advanced machine learning techniques: A study on resource allocation for small-batch and multi-variety challenges. Proc. Inst. Mech. Eng. Part E 2024. [Google Scholar] [CrossRef]
- Li, G.; Wang, X.Y.; Wang, J.B.; Sun, L.Y. Worst case analysis of flow shop scheduling problems with a time-dependent learning effect. Int. J. Prod. Econ. 2013, 142, 98–104. [Google Scholar] [CrossRef]
- Malone, A.A.; Bastian, A.J. Age-related forgetting in locomotor adaptation. Neurobiol. Learn. Mem. 2016, 128, 1–6. [Google Scholar] [CrossRef]
- Erol, R.; Sahin, C.; Baykasoglu, A.; Kaplanoglu, V. A multi-agent based approach to dynamic scheduling of machines and automated guided vehicles in manufacturing systems. Appl. Soft Comput. 2012, 12, 1720–1732. [Google Scholar] [CrossRef]
- Baruwa, O.T.; Piera, M.A. A Coloured Petri Net-Based Hybrid Heuristic Search Approach to Simultaneous Scheduling of Machines and Automated Guided Vehicles. Int. J. Prod. Res. 2016, 54, 4773–4792. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Description |
|---|---|
| The k_th workpiece | |
| The number of worker j | |
| The equipment number of machine j | |
| The number of AGV i | |
| The n_th operation of the | |
| Total energy consumption of | |
| Total energy consumption of | |
| Delay time of the | |
| Completion time of the | |
| Due date of the | |
| Human–machine collaborative production group | |
| Real-time state of at time t | |
| Real-time state of worker resource at time t | |
| Real-time state of machine resource at time t | |
| Real-time state of logistics resource at time t | |
| Time at which logistics task starts processing operation | |
| Time at which machine completes operation | |
| Time at which machine starts processing operation | |
| Time at which machine completes operation | |
| Time at which logistics task arrives at the location of operation | |
| The completion time of the last operation before processing by the machine |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| Workers | 8 | (Learning Index, Forgetting Index) | (0~1) |
| Production Equipment | 8 | Order Quantity | 20, 40, 60 |
| Processing Rate | 1 | Equipment Idle Power | 5 (KW) |
| Logistics Devices | 4 | Logistics Power | 4 (KW) |
| Logistics Speed | 1 (m/s) | Logistics Idle Power | 1 (KW) |
| Distance (m) | S/D | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| S/D | 0 | 16 | 24 | 32 | 40 | 48 | 40 | 56 | 48 |
| 40 | 0 | 8 | 16 | 24 | 32 | 24 | 40 | 32 | |
| 48 | 40 | 0 | 24 | 16 | 24 | 16 | 32 | 24 | |
| 56 | 24 | 16 | 0 | 16 | 24 | 32 | 32 | 40 | |
| 64 | 32 | 24 | 16 | 0 | 16 | 24 | 24 | 32 | |
| 24 | 40 | 32 | 24 | 16 | 0 | 16 | 16 | 24 | |
| 32 | 56 | 48 | 40 | 32 | 24 | 0 | 16 | 8 | |
| 40 | 48 | 40 | 32 | 24 | 16 | 24 | 0 | 16 | |
| 48 | 64 | 56 | 48 | 40 | 32 | 40 | 24 | 0 |
| Time [s] | ||||||||
|---|---|---|---|---|---|---|---|---|
| Job | 135 | 105 | 135 | 105 | 120 | 144 | 105 | 126 |
| 105 | 135 | 120 | 105 | 135 | 120 | 135 | 90 | |
| 105 | 135 | 120 | 105 | 135 | 105 | 120 | 90 | |
| 120 | 105 | 135 | 150 | 120 | 120 | 126 | 114 | |
| 132 | 135 | 102 | 120 | 90 | 114 | 120 | 126 | |
| 129 | 120 | 114 | 108 | 120 | 150 | 130 | 120 | |
| 180 | 195 | 165 | 150 | 195 | 225 | 180 | 165 | |
| 225 | 210 | 195 | 210 | 165 | 180 | 195 | 180 |
| Machine | ||||||||
|---|---|---|---|---|---|---|---|---|
| Operational Power [KW/h] | 22.5 | 13.0 | 24.1 | 24.5 | 23.5 | 22.8 | 23.4 | 24.0 |
| Without Learning and Forgetting Effects (NLF) | Considering Learning and Forgetting Effects (NNW) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Algorithm | Order Size | Makespan (s) | Energy Consumption (KJ) | Tardiness (s) | Algorithm | Order Size | Makespan (s) | Energy Consumption (KJ) | Tardiness (s) |
| HCML CS | 20 | 3558 | 573,172 | 40 | HCML CS | 20 | 3464 | 535,336 | 21 |
| 40 | 6464 | 1,109,272 | 111 | 40 | 5944 | 989,220 | 47 | ||
| 60 | 9087 | 1,635,784 | 499 | 60 | 8121 | 1,407,748 | 102 | ||
| OC | 20 | 3967 | 590,400 | 99 | OC | 20 | 3553 | 538,448 | 37 |
| 40 | 7299 | 1,146,788 | 472 | 40 | 6065 | 1,004,932 | 108 | ||
| 60 | 10,071 | 1,674,104 | 1043 | 60 | 8257 | 1,443,756 | 388 | ||
| FCFS | 20 | 3977 | 590,216 | 90 | FCFS | 20 | 3755 | 552,464 | 78 |
| 40 | 7146 | 1,144,348 | 360 | 40 | 6923 | 1,056,896 | 264 | ||
| 60 | 11,158 | 1,751,944 | 1261 | 60 | 10,180 | 1,543,460 | 695 | ||
| SPT+ STT | 20 | 3703 | 575,264 | 62 | SPT+ STT | 20 | 3826 | 550,168 | 29 |
| 40 | 6980 | 1,129,000 | 293 | 40 | 6540 | 1,024,008 | 154 | ||
| 60 | 10,066 | 1,677,836 | 638 | 60 | 9061 | 1,477,712 | 277 | ||
| LPT+ LTT | 20 | 3851 | 577,984 | 95 | LPT+ LTT | 20 | 3461 | 503,136 | 47 |
| 40 | 6893 | 1,128,296 | 227 | 40 | 6104 | 1,002,832 | 69 | ||
| 60 | 9818 | 1,668,320 | 829 | 60 | 8365 | 1,453,240 | 313 | ||
| SRP TT | 20 | 3912 | 586,904 | 49 | SRP TT | 20 | 3736 | 548,532 | 28 |
| 40 | 7508 | 1,147,084 | 396 | 40 | 6695 | 1,034,884 | 61 | ||
| 60 | 10,135 | 1,686,340 | 591 | 60 | 8887 | 1,463,496 | 185 | ||
| LRP TT | 20 | 3963 | 591,972 | 147 | LRP TT | 20 | 3618 | 544,396 | 49 |
| 40 | 7343 | 1,151,672 | 358 | 40 | 6945 | 1,033,268 | 225 | ||
| 60 | 10,493 | 1,695,692 | 816 | 60 | 8748 | 1,455,264 | 432 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Li, S.; Luo, G.; Li, H.; Wen, X. A Real-Time Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ Learning and Forgetting Effects. Appl. Syst. Innov. 2025, 8, 40. https://doi.org/10.3390/asi8020040
Yang W, Li S, Luo G, Li H, Wen X. A Real-Time Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ Learning and Forgetting Effects. Applied System Innovation. 2025; 8(2):40. https://doi.org/10.3390/asi8020040
Chicago/Turabian StyleYang, Wenchao, Sen Li, Guofu Luo, Hao Li, and Xiaoyu Wen. 2025. "A Real-Time Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ Learning and Forgetting Effects" Applied System Innovation 8, no. 2: 40. https://doi.org/10.3390/asi8020040
APA StyleYang, W., Li, S., Luo, G., Li, H., & Wen, X. (2025). A Real-Time Human–Machine–Logistics Collaborative Scheduling Method Considering Workers’ Learning and Forgetting Effects. Applied System Innovation, 8(2), 40. https://doi.org/10.3390/asi8020040