
COVID-19 Detection from Radiographs: Is Deep Learning Able to Handle the Crisis?

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
- We present a review of the deep learning networks and summarize the most prominent components of each with focused block diagrams;
- We employ the deep learning algorithms for COVID-19 datasets to detect infection in the CT and X-ray images;
- Finally, we provide limitations, challenges, and future directions for the research community.
2. Related Work
3. Deep Learning Networks Review
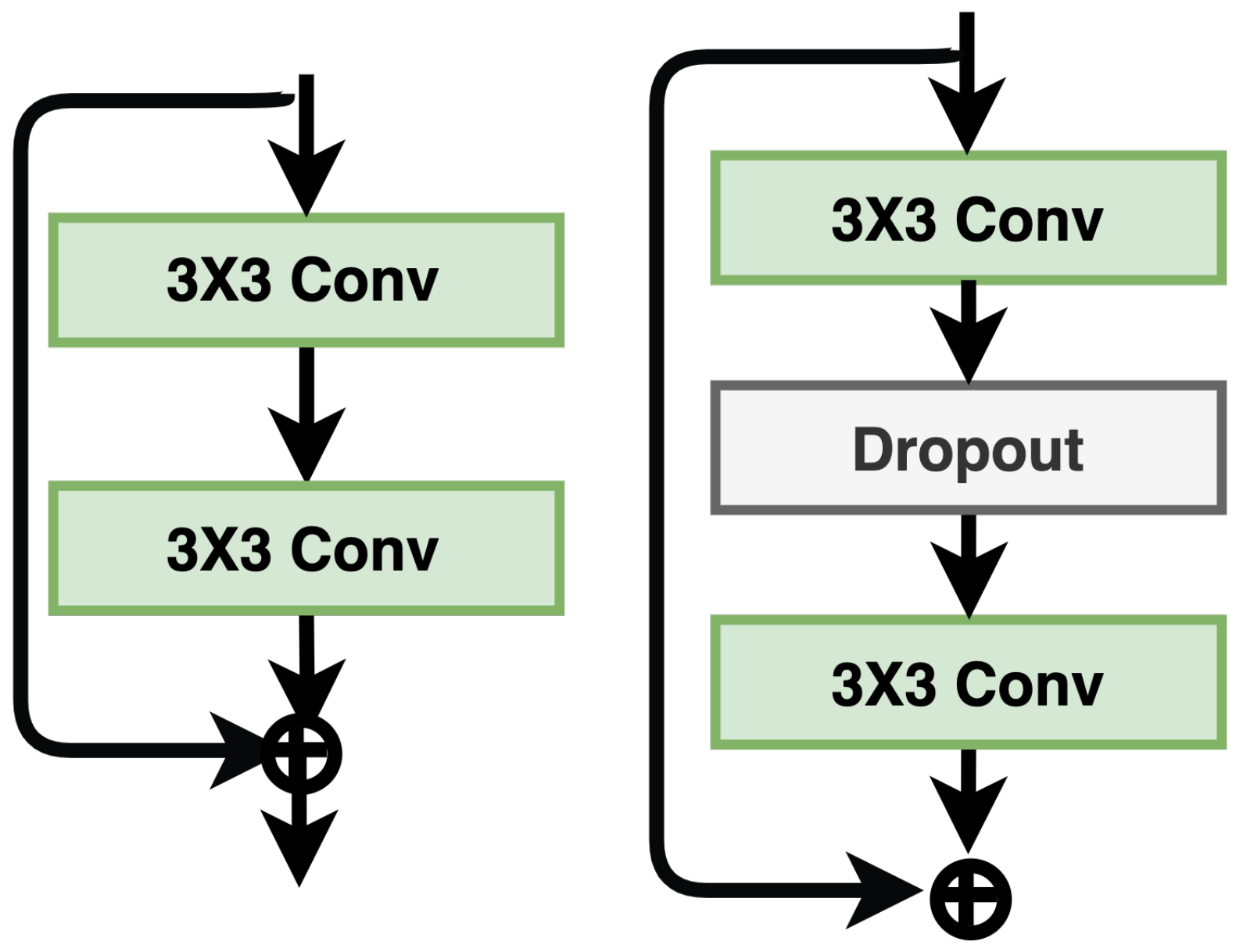
3.1. Plain Networks
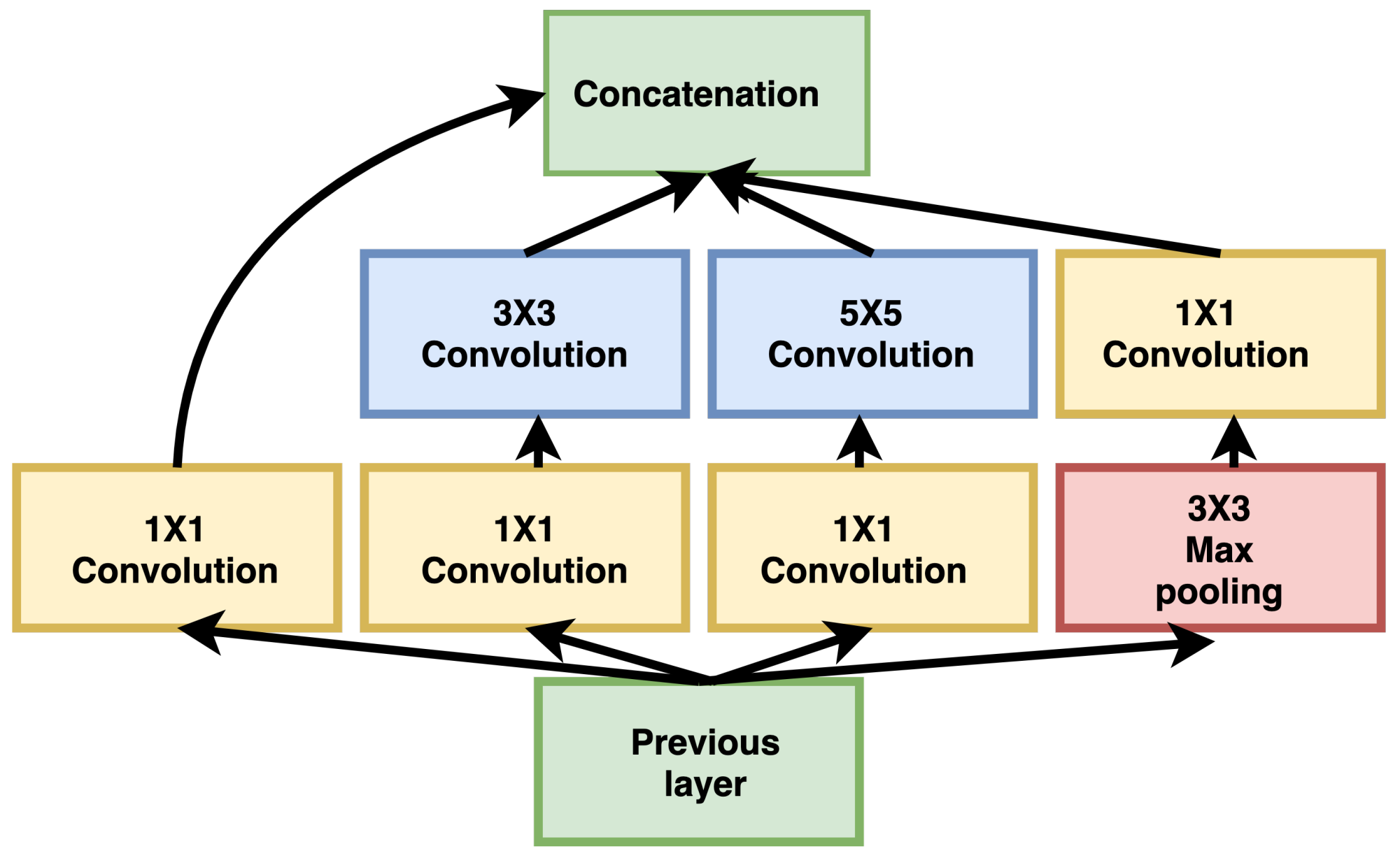
3.2. GoogleNet Inception Networks
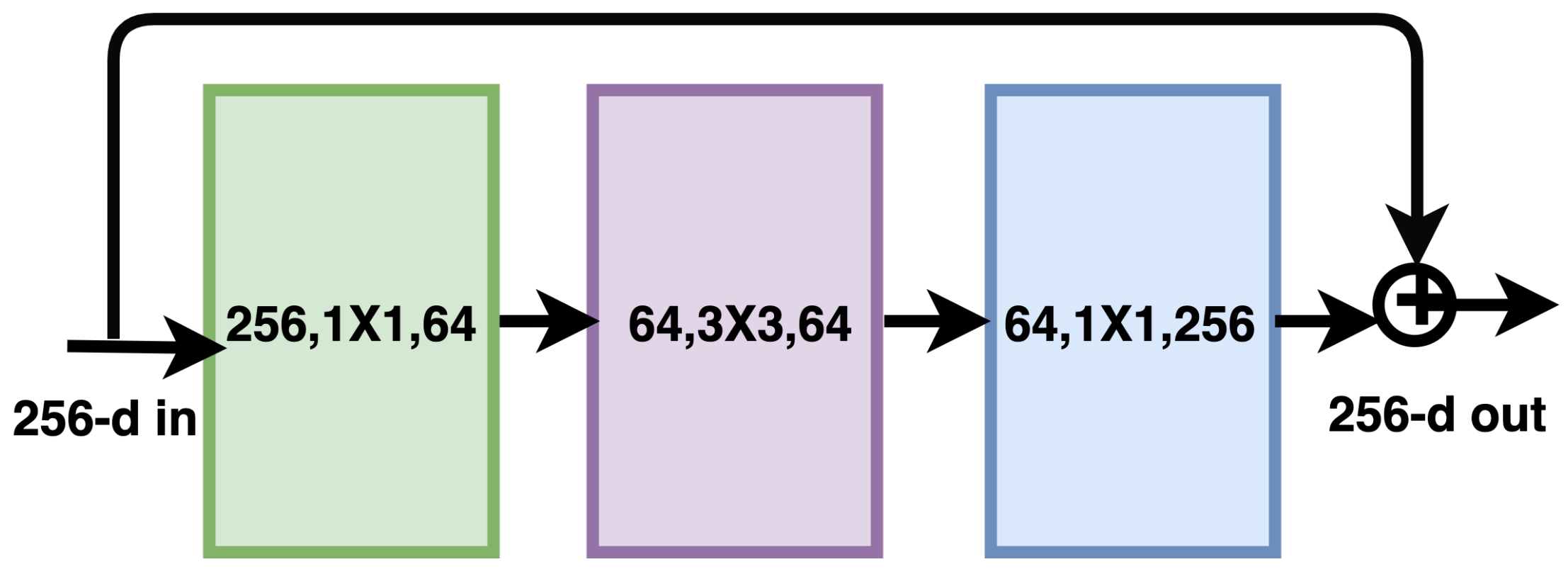
3.3. Residual Networks
3.4. Dense Networks
3.5. Efficient Networks
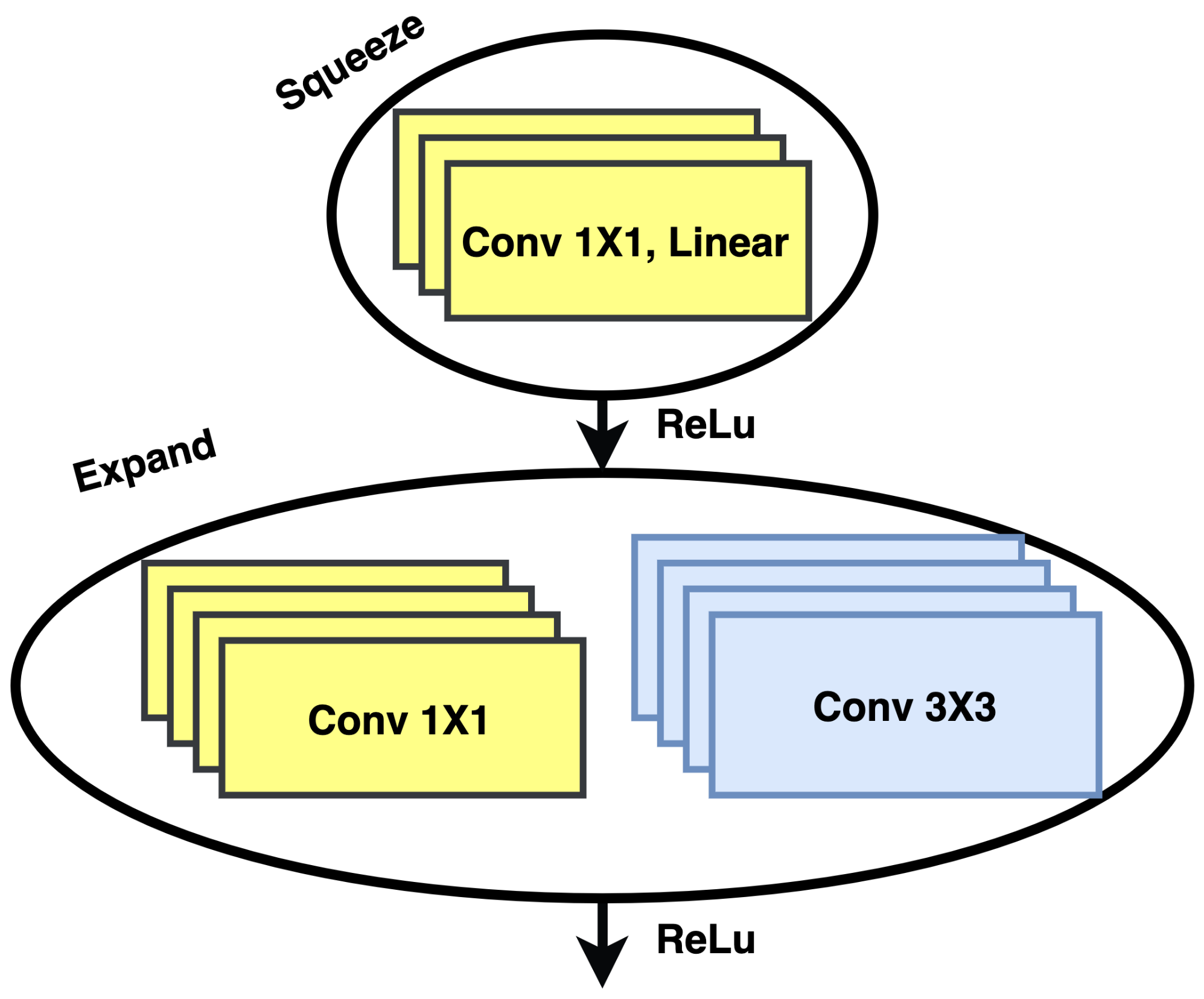
3.6. Squeeze Networks
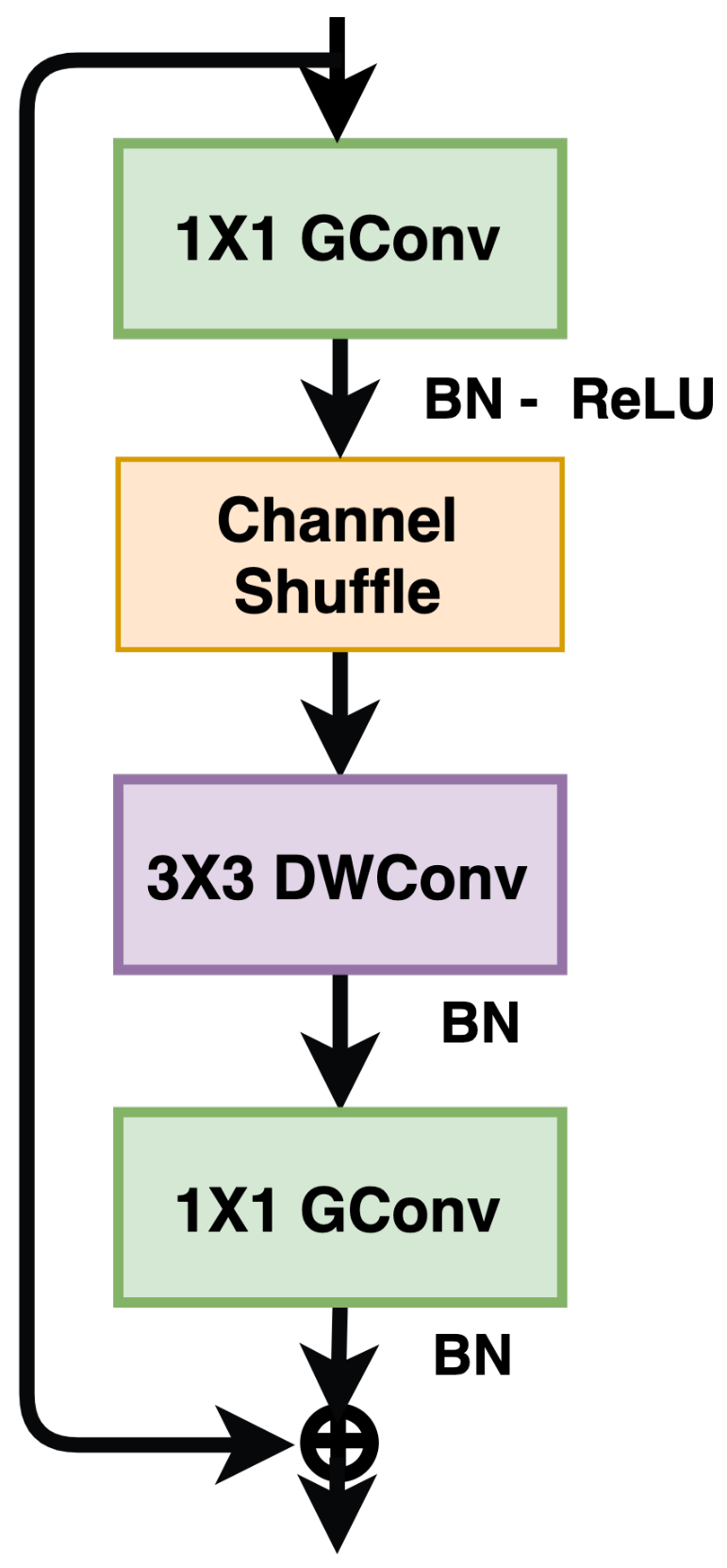
3.7. Shuffle Networks
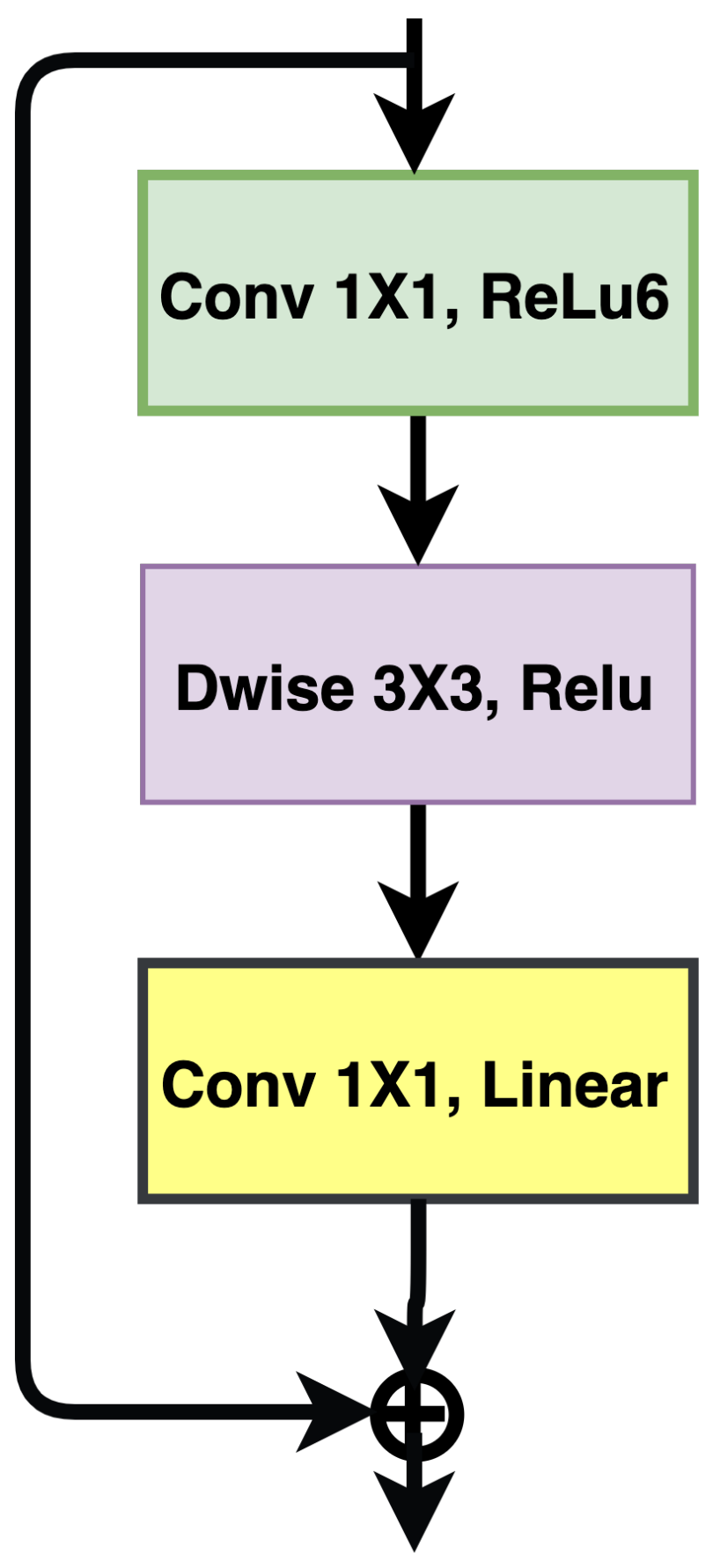
3.8. Mobile Networks
3.9. Neural Architecture Search NASNet
3.10. Wide ResNets
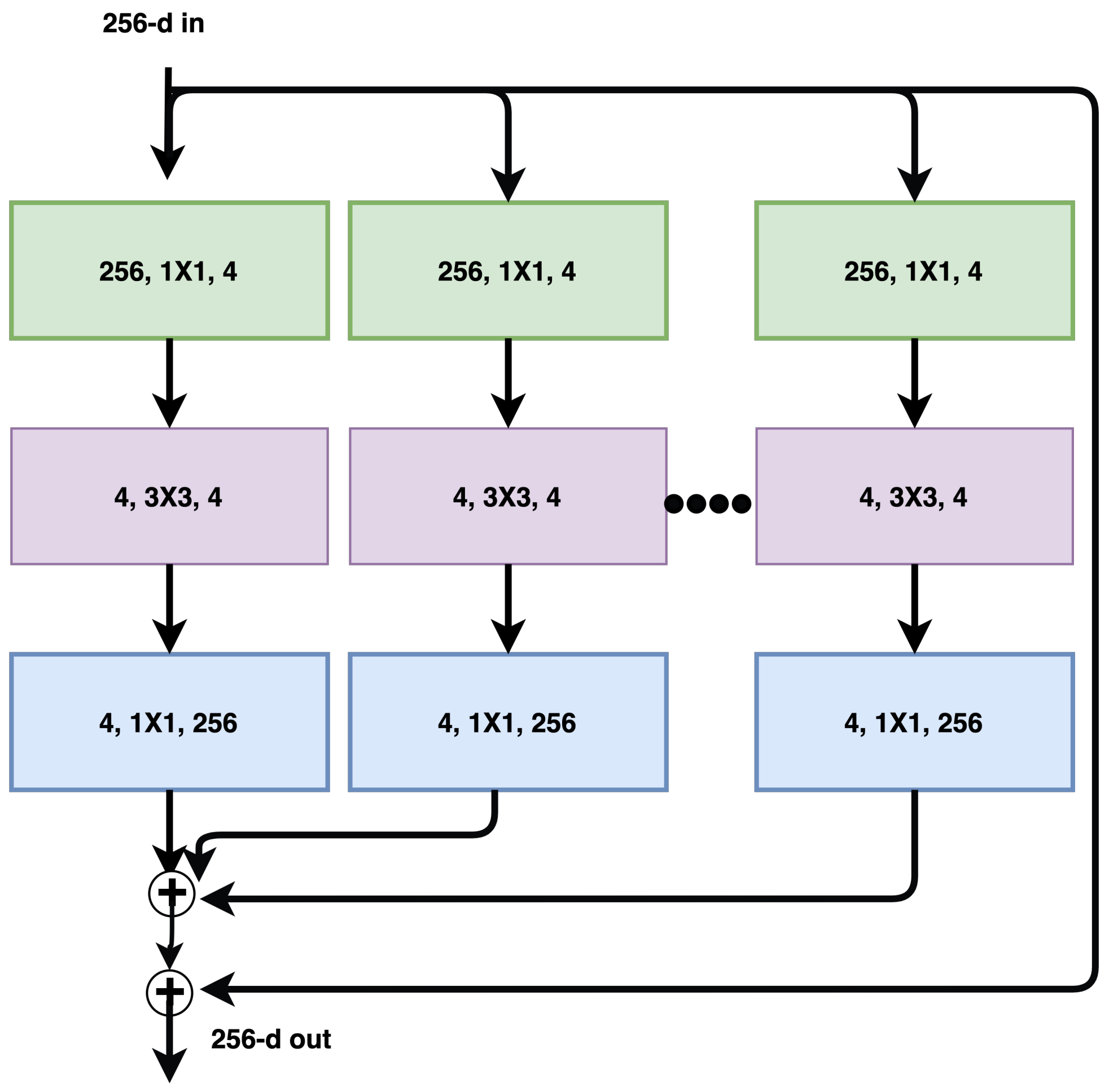
3.11. ResNeXt
4. Results
4.1. Experimental Set-Up
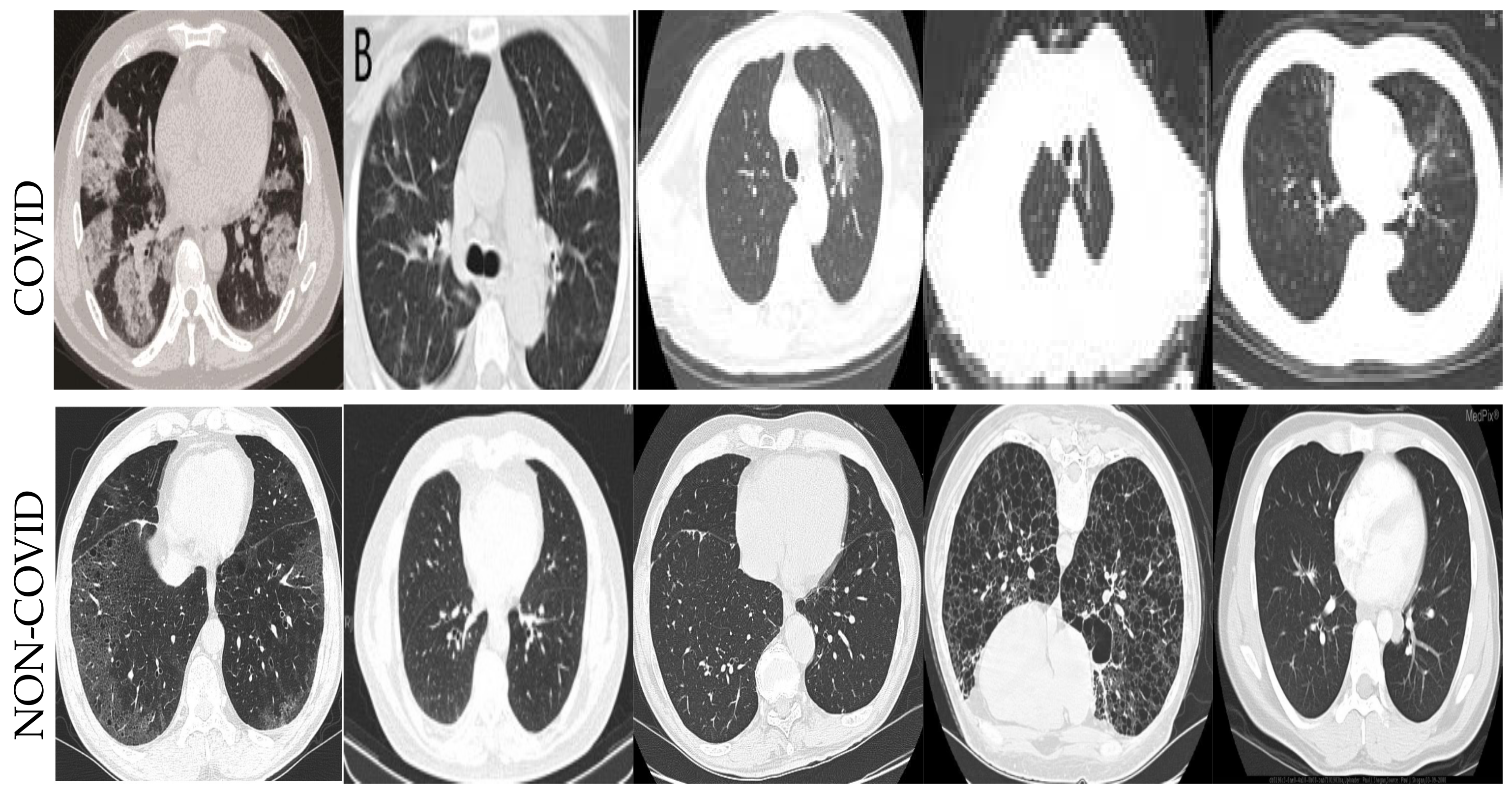
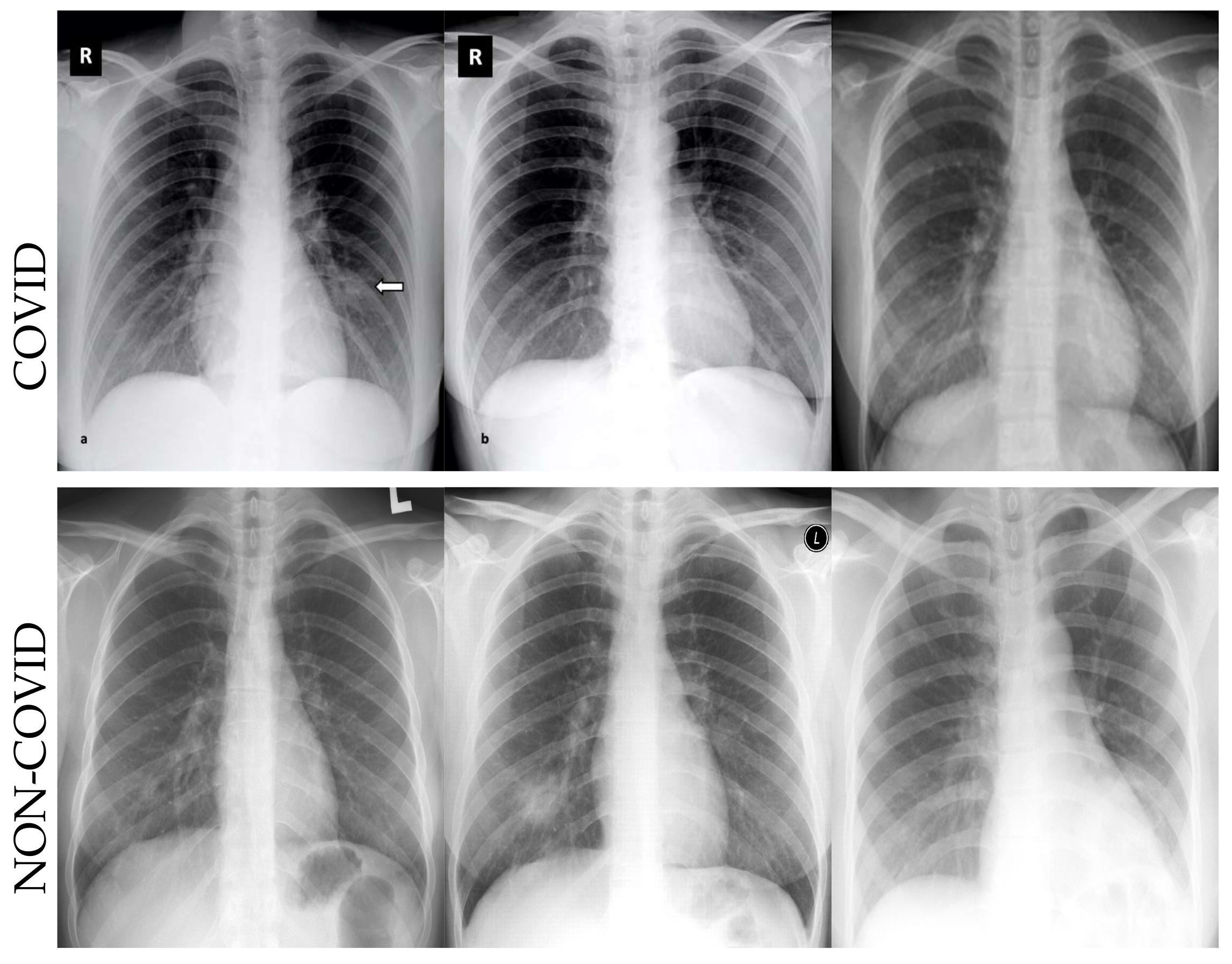
4.2. Datasets
4.3. Metrics
- Precision is the ratio of correctly predicted positive COVID-19 patients to the total positive predictions (i.e., true positives and false positives). This metric gives an algorithm the ability to determine the rate of false positives. The higher rate is for precision, and the lower rate is for false positives.
- Recall is also known as the sensitivity of the algorithm, and it is the ratio of correctly predicted positive outcomes (i.e., true positives) to the actual class observations (i.e., true positives and false negatives).
- F1 Score assesses the false positives and false negatives by taking the weighted average of the earlier-mentioned metrics. The F1 score is helpful in cases where class distribution is uneven.
- Accuracy is the most used and intuitive measure in classification. Accuracy is defined as the ratio of correct predictions to the total number of samples. Although high accuracy may be a good measure, it may not be the best in certain situations where the class distribution is not symmetric. Hence, we used other metrics to evaluate the performance of the algorithms.
- AUC stands for area under the curve and is the second-most-used metric for classification. It represents the degree of separability. The aim here is to model the network’s capability while distinguishing between classes. A higher value for the AUC means the model is better at predicting correct values; in other words, it can predict positive as positives and negatives as negatives.
4.4. Evaluations
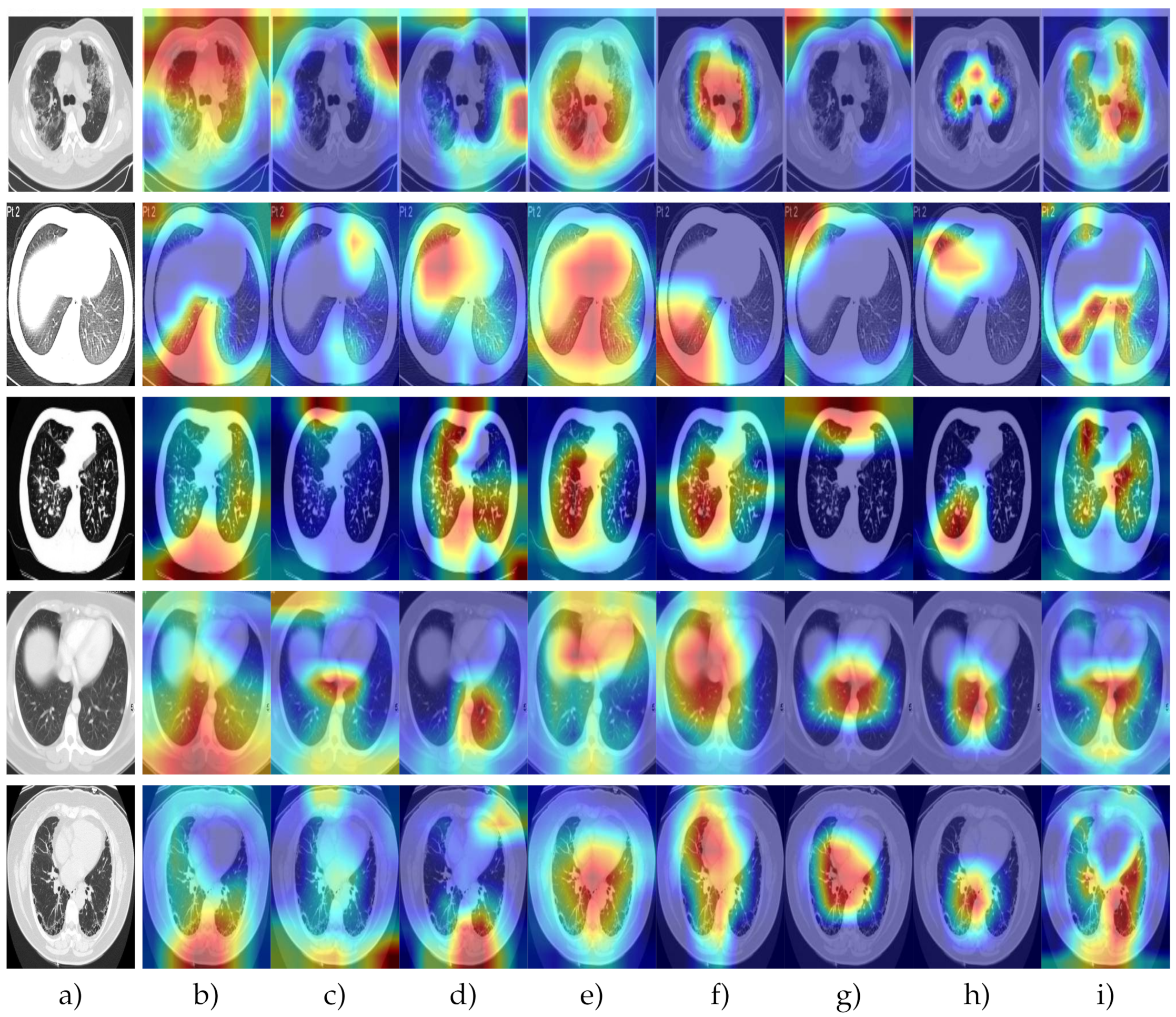
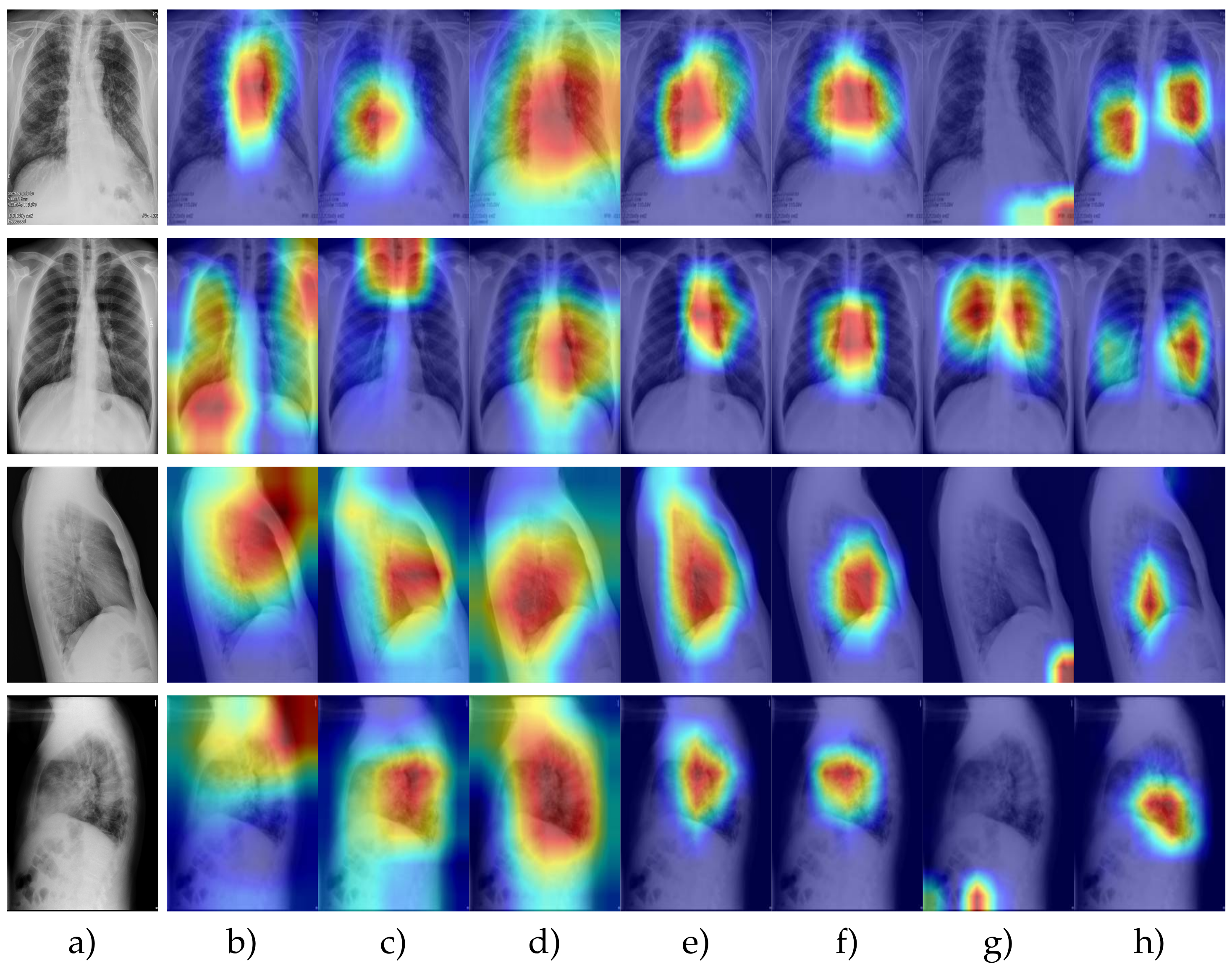
4.5. Attention
5. Open Problems and Challenges
- Lack of Significant Datasets: Data are vital for the progress of any field, and deep learning is no exception. Similarly, the identification of the specific anomalies requires significant annotated datasets. Although there are some available datasets for COVID-19, these are not significant enough for confident detection of an infection underway. Therefore, it is crucial to have large annotated datasets to accurately and appropriately detect the condition.
- Medical Experts Input: The system’s accuracy is dependent on the input of the experts in the research field. Although deep learning systems provide decent accuracy in identifying or classifying the infection, medical expert opinions are required on the outcome of the model to make sure that prediction is correct. The medical expert should also be consulted to determine the challenging cases and variants of the virus for the model’s robustness. Overall, the involvement of medical experts and their input should be at the heart of this research.
- Lack of Variants Identification: Since the pandemic’s start, everyone knew only one name: coronavirus. However, as time passed, more information about the infection came to light about the virus variants and strains. The infection capability and severity change depending on the strain; some are infectious, while others are dangerous. The identification and classification of these strains are vital so that the system can identify the strain type and warn about the challenges posed by infection.
- Models’ Efficiency: The efficiency of the models is another aspect neglected in COVID-19 research, as the focus thus far has been on the effectiveness rather than the efficiency. Real-time diagnosis is essential, along with accuracy, if the models need to be deployed for screening on devices. Therefore, it is desired to have research dedicated to training efficient models.
- Benchmark Deficiency: Benchmarks play an important role in advancing the field and identifying the state-of-the-art methods from the crowd, as there is a significant effort in COVID-19 research. The lack of benchmarks made it hard to isolate the excellent investigation, analysis, and methods.
- Generalization: The proposed models’ generalization for COVID-19 case detection, classification, and identification is vital due to the variants and strains emerging. The trained model should have the ability to accurately detect and classify cases without retraining the whole system in case of a new variant. The best approach would be to apply attention to the details specific to the virus type. Moreover, it should be noted that the dataset quality may also influence the models’ generalization and robustness. Hence, a step toward generalization is to utilize pretrained models with attention mechanisms.
- Integrating Input Data Types: COVID-19 has been identified or detected from a single source such as an X-ray or CT. However, utilizing more information, including the body temperature, will help improve the performance and reliability of the methods. Furthermore, employing multiple data types helps predict the relationship between COVID-19 and the most robust combination for early detection.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Ethics Approval:
Code Availability:
References
- He, X.; Yang, X.; Zhang, S.; Zhao, J.; Zhang, Y.; Xing, E.; Xie, P. Sample-Efficient Deep Learning for COVID-19 Diagnosis Based on CT Scans. medRxiv 2020. [Google Scholar] [CrossRef]
- Wang, L.; Wong, A. COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-Ray Images. arXiv 2020, arXiv:2003.09871. [Google Scholar] [CrossRef] [PubMed]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Explainable COVID-19 detection using chest CT scans and deep learning. Sensors 2021, 21, 455. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Abdalla, M.; Barth, E.; Martinetz, T. COVID-Nets: Deep CNN architectures for detecting COVID-19 using chest CT scans. Peerj Comput. Sci. 2021, 7, e655. [Google Scholar] [CrossRef] [PubMed]
- Kini, A.S.; Gopal Reddy, A.N.; Kaur, M.; Satheesh, S.; Singh, J.; Martinetz, T.; Alshazly, H. Ensemble Deep Learning and Internet of Things-Based Automated COVID-19 Diagnosis Framework. Contrast Media Mol. Imaging 2022, 2022, 7377502. [Google Scholar] [CrossRef] [PubMed]
- Sakib, S.; Tazrin, T.; Fouda, M.M.; Fadlullah, Z.M.; Guizani, M. DL-CRC: Deep learning-based chest radiograph classification for COVID-19 detection: A novel approach. IEEE Access 2020, 8, 171575–171589. [Google Scholar] [CrossRef]
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Hu, S.; Wang, Y.; Hu, X.; Zheng, B.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography: A prospective study. medRxiv 2020. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 2020, 200905. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rajaraman, S.; Candemir, S.; Kim, I.; Thoma, G.; Antani, S. Visualization and interpretation of convolutional neural network predictions in detecting pneumonia in pediatric chest radiographs. Appl. Sci. 2018, 8, 1715. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Zhao, H.; Jie, Y.; Wang, R.; et al. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. medRxiv 2020. [Google Scholar] [CrossRef] [PubMed]
- Zheng, C.; Deng, X.; Fu, Q.; Zhou, Q.; Feng, J.; Ma, H.; Liu, W.; Wang, X. Deep learning-based detection for COVID-19 from chest CT using weak label. medRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Ng, M.Y.; Lee, E.Y.; Yang, J.; Yang, F.; Li, X.; Wang, H.; Lui, M.M.s.; Lo, C.S.Y.; Leung, B.; Khong, P.L.; et al. Imaging profile of the COVID-19 infection: Radiologic findings and literature review. Radiol. Cardiothorac. Imaging 2020, 2, e200034. [Google Scholar] [CrossRef] [Green Version]
- Farooq, M.; Hafeez, A. Covid-resnet: A deep learning framework for screening of covid19 from radiographs. arXiv 2020, arXiv:2003.14395. [Google Scholar]
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the CVPR09, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2010, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Hochreiter, S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness-Knowl. Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Wei, L.; Yangqing, J.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y.; et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 103–112. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, S.; Van der Maaten, L.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2820–2828. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Average Recall | Average Precision | Average F1 | Average Accuracy | Average AUC |
|---|---|---|---|---|---|
| AlexNet | 0.7810 | 0.7321 | 0.7558 | 0.7389 | 0.8007 |
| VGG11 | 0.8952 | 0.7344 | 0.8069 | 0.7783 | 0.8785 |
| VGG13 | 0.7524 | 0.8144 | 0.7822 | 0.7833 | 0.8610 |
| VGG16 | 0.8381 | 0.7333 | 0.7822 | 0.7586 | 0.8395 |
| VGG19 | 0.8476 | 0.7876 | 0.8165 | 0.8030 | 0.8796 |
| ResNet18 | 0.7524 | 0.7670 | 0.7596 | 0.7537 | 0.8397 |
| ResNet34 | 0.8667 | 0.7982 | 0.8311 | 0.8177 | 0.8851 |
| ResNet50 | 0.7905 | 0.8300 | 0.8098 | 0.8079 | 0.8769 |
| ResNet101 | 0.8571 | 0.7826 | 0.8182 | 0.8030 | 0.8880 |
| ResNet152 | 0.7333 | 0.8191 | 0.7739 | 0.7783 | 0.8670 |
| DenseNet121 | 0.7238 | 0.8444 | 0.7795 | 0.7882 | 0.8700 |
| DenseNet161 | 0.7905 | 0.8218 | 0.8058 | 0.8030 | 0.8729 |
| DenseNet169 | 0.7524 | 0.8495 | 0.7980 | 0.8030 | 0.8586 |
| DenseNet201 | 0.8476 | 0.7739 | 0.8091 | 0.7931 | 0.8698 |
| GoogleNet | 0.9429 | 0.6306 | 0.7557 | 0.6847 | 0.7815 |
| Efficient-b0 | 0.7333 | 0.7700 | 0.7512 | 0.7488 | 0.8518 |
| Efficient-b1 | 0.8095 | 0.7589 | 0.7834 | 0.7685 | 0.8588 |
| Efficient-b2 | 0.7143 | 0.7895 | 0.7500 | 0.7537 | 0.8325 |
| Efficient-b3 | 0.8190 | 0.8037 | 0.8113 | 0.8030 | 0.8862 |
| Efficient-b4 | 0.8190 | 0.8037 | 0.8113 | 0.8030 | 0.8862 |
| Efficient-b5 | 0.6952 | 0.7300 | 0.7122 | 0.7094 | 0.7903 |
| Efficient-b6 | 0.7524 | 0.7900 | 0.7707 | 0.7685 | 0.8552 |
| Efficient-b7 | 0.7905 | 0.7905 | 0.7905 | 0.7833 | 0.8566 |
| SqueezeNet1.0 | 0.9048 | 0.7090 | 0.7950 | 0.7586 | 0.8722 |
| SqueezeNet1.1 | 0.9333 | 0.7259 | 0.8167 | 0.7833 | 0.8725 |
| MNASNet0.5 | 0.5238 | 0.7857 | 0.6286 | 0.6798 | 0.7938 |
| MNASNet1.0 | 0.8952 | 0.7833 | 0.8356 | 0.8177 | 0.8845 |
| ResNeXt50-32x4d | 0.8000 | 0.8235 | 0.8116 | 0.8079 | 0.8726 |
| ResNeXt101-32x8d | 0.8000 | 0.7368 | 0.7671 | 0.7488 | 0.8624 |
| Wide-ResNet50.2 | 0.7905 | 0.7757 | 0.7830 | 0.7734 | 0.8571 |
| Wide-ResNet101-2 | 0.8667 | 0.7712 | 0.8161 | 0.7980 | 0.8863 |
| ShuffleNet-v2-x0.5 | 0.8190 | 0.7611 | 0.7890 | 0.7734 | 0.8654 |
| ShuffleNet-v2-x1.0 | 0.7714 | 0.7431 | 0.7570 | 0.7438 | 0.8289 |
| MobileNet-v2 | 0.7810 | 0.7736 | 0.7773 | 0.7685 | 0.8549 |
| Methods | Average Recall | Average Precision | Average F1 | Average Accuracy | Average AUC |
|---|---|---|---|---|---|
| AlexNet | 0.0952 | 0.5000 | 0.1600 | 0.8306 | 0.6445 |
| VGG11 | 0.1429 | 0.5000 | 0.2222 | 0.8306 | 0.6815 |
| VGG13 | 0.1905 | 0.5000 | 0.2759 | 0.8306 | 0.6875 |
| VGG16 | 0.1905 | 1.0000 | 0.3200 | 0.8629 | 0.7240 |
| VGG19 | 0.1905 | 0.8000 | 0.3077 | 0.8548 | 0.6366 |
| ResNet18 | 0.2857 | 0.8571 | 0.4286 | 0.8710 | 0.7406 |
| ResNet34 | 0.1905 | 0.6667 | 0.2963 | 0.8468 | 0.7235 |
| ResNet50 | 0.1429 | 0.7500 | 0.2400 | 0.8468 | 0.6588 |
| ResNet101 | 0.0952 | 0.4000 | 0.1538 | 0.8226 | 0.5825 |
| ResNet152 | 0.1429 | 0.4286 | 0.2143 | 0.8226 | 0.6084 |
| DenseNet121 | 0.3810 | 0.5333 | : 0.4444 | 0.8387 | 0.6764 |
| DenseNet161 | 0.3810 | 0.6667 | : 0.4848 | 0.8629 | 0.6320 |
| DenseNet169 | 0.1429 | 0.3750 | : 0.2069 | 0.8145 | 0.5927 |
| DenseNet201 | 0.0952 | 0.2857 | : 0.1429 | 0.8065 | 0.5890 |
| GoogleNet | 0.2381 | 0.8333 | 0.3704 | 0.8629 | 0.6990 |
| EfficientNet-b0 | 0.1429 | 1.0000 | 0.2500 | 0.8548 | 0.6893 |
| EfficientNet-b1 | 0.2381 | 0.4545 | 0.3125 | 0.8226 | 0.6644 |
| EfficientNet-b2 | 0.3333 | 0.7000 | 0.4516 | 0.8629 | 0.7180 |
| EfficientNet-b3 | 0.2381 | 0.8333 | 0.3704 | 0.8629 | 0.7263 |
| EfficientNet-b4 | 0.1429 | 0.7500 | 0.2400 | 0.8468 | 0.7499 |
| EfficientNet-b5 | 0.0952 | 0.5000 | 0.1600 | 0.8306 | 0.6251 |
| EfficientNet-b6 | 0.1429 | 0.3750 | 0.2069 | 0.8145 | 0.6671 |
| EfficientNet-b7 | 0.1429 | 0.7500 | 0.2400 | 0.8468 | 0.7069 |
| SqueezeNet1.0 | 0.285 | 0.4000 | 0.3333 | 0.8065 | 0.6602 |
| SqueezeNet1.1 | 0.2381 | 0.7143 | 0.3571 | 0.8548 | 0.6338 |
| MNASNet0.5 | 0.6667 | 0.4000 | 0.5000 | 0.7742 | 0.7383 |
| MNASNet1.0 | 0.5238 | 0.4400 | 0.4783 | 0.8065 | 0.7560 |
| ResNeXt50-32x4d | 0.2381 | 0.5556 | 0.3333 | 0.8387 | 0.7110 |
| ResNeXt101-32x8d | 0.1429 | 0.7500 | 0.2400 | 0.8468 | 0.6990 |
| Wide-ResNet50.2 | 0.1905 | 1.0000 | 0.3200 | 0.8629 | 0.6630 |
| Wide-ResNet101-2 | 0.2381 | 0.3125 | 0.2703 | 0.7823 | 0.6144 |
| ShuffleNet-v2-x0.5 | 0.2381 | 0.5556 | 0.3333 | 0.8387 | 0.6620 |
| ShuffleNet-v2-x1.0 | 0.1905 | 0.4000 | 0.2581 | 0.8145 | 0.6482 |
| MobileNet-v2 | 0.3333 | 0.7000 | 0.4516 | 0.8629 | 0.7180 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saqib, M.; Anwar, A.; Anwar, S.; Petersson, L.; Sharma, N.; Blumenstein, M. COVID-19 Detection from Radiographs: Is Deep Learning Able to Handle the Crisis? Signals 2022, 3, 296-312. https://doi.org/10.3390/signals3020019
Saqib M, Anwar A, Anwar S, Petersson L, Sharma N, Blumenstein M. COVID-19 Detection from Radiographs: Is Deep Learning Able to Handle the Crisis? Signals. 2022; 3(2):296-312. https://doi.org/10.3390/signals3020019
Chicago/Turabian StyleSaqib, Muhammad, Abbas Anwar, Saeed Anwar, Lars Petersson, Nabin Sharma, and Michael Blumenstein. 2022. "COVID-19 Detection from Radiographs: Is Deep Learning Able to Handle the Crisis?" Signals 3, no. 2: 296-312. https://doi.org/10.3390/signals3020019
APA StyleSaqib, M., Anwar, A., Anwar, S., Petersson, L., Sharma, N., & Blumenstein, M. (2022). COVID-19 Detection from Radiographs: Is Deep Learning Able to Handle the Crisis? Signals, 3(2), 296-312. https://doi.org/10.3390/signals3020019