

A Sparse Multiclass Motor Imagery EEG Classification Using 1D-ConvResNet


Abstract
:1. Introduction
- Works well without preprocessing, such as using bandpass or spatial filters.
- Maintains the classification accuracy irrespective of the users’ proficiency in performing MI tasks.
- The classification accuracy is improved with the selected channels related to the sensory motor cortex region.
- The accuracy is optimal with reduced epoch lengths and is therefore suitable for a real-time MI-based BCI.
- The proposed method is computationally inexpensive and faster than other machine learning algorithms.
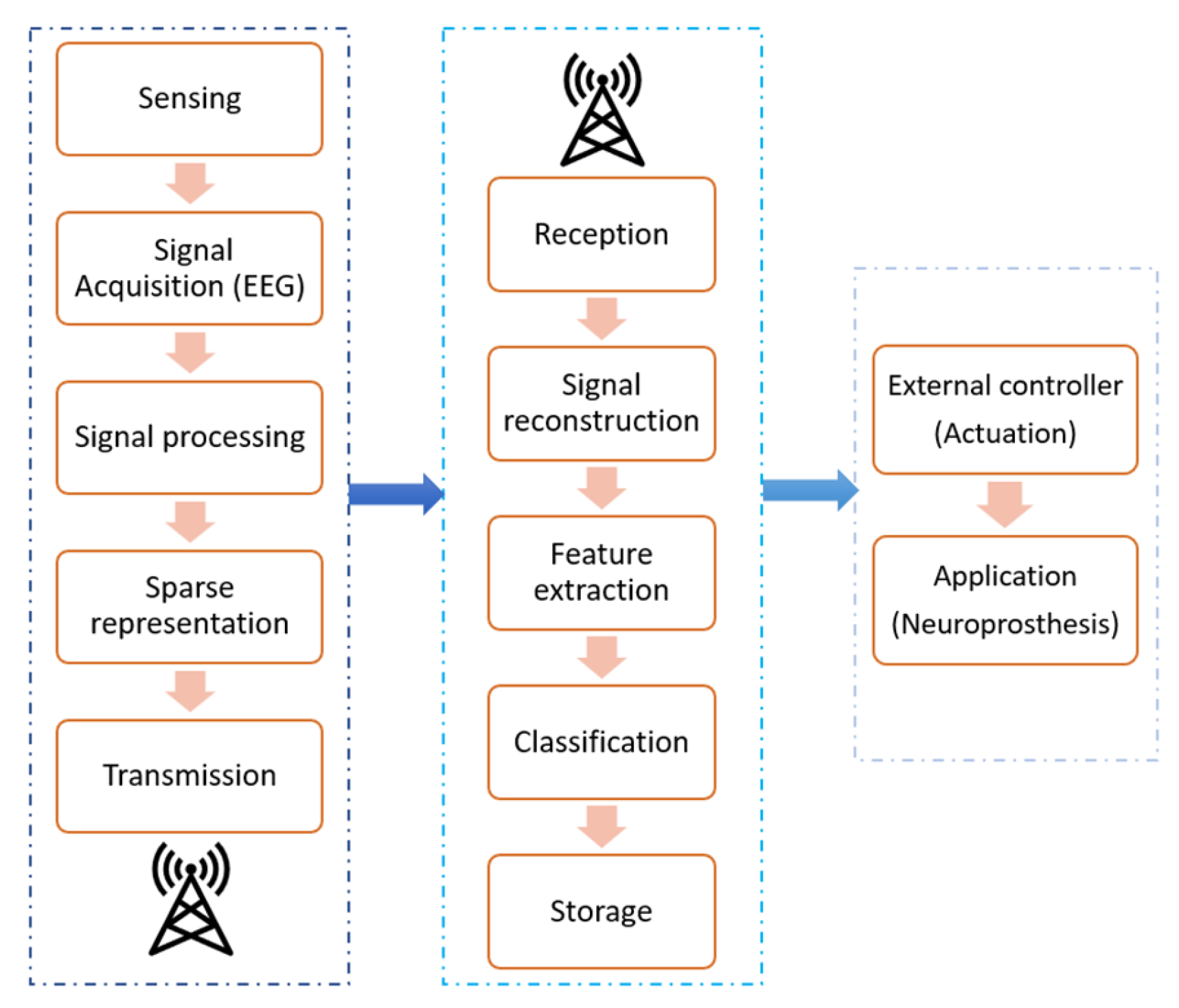
2. Materials and Methods
2.1. EEG Dataset
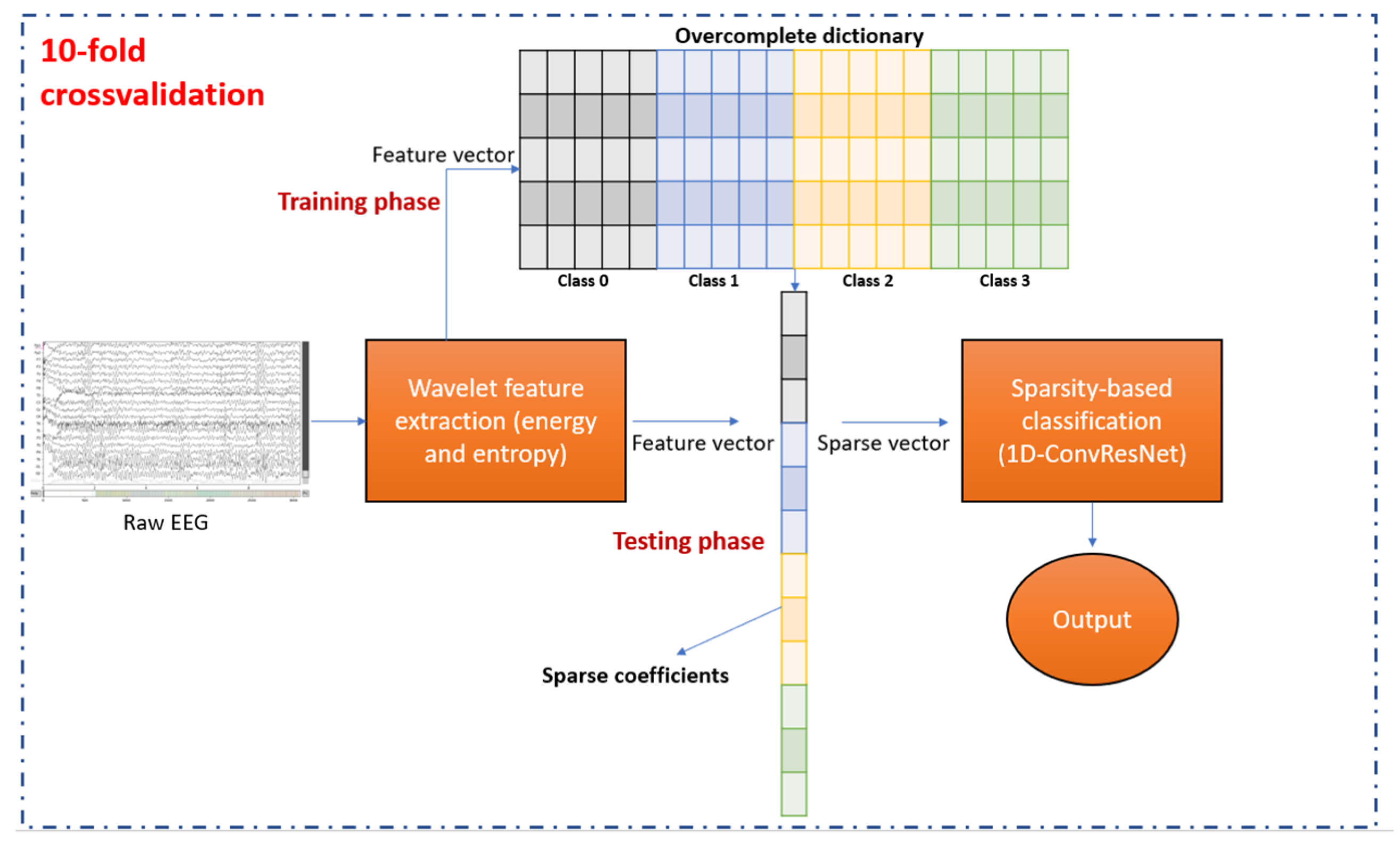
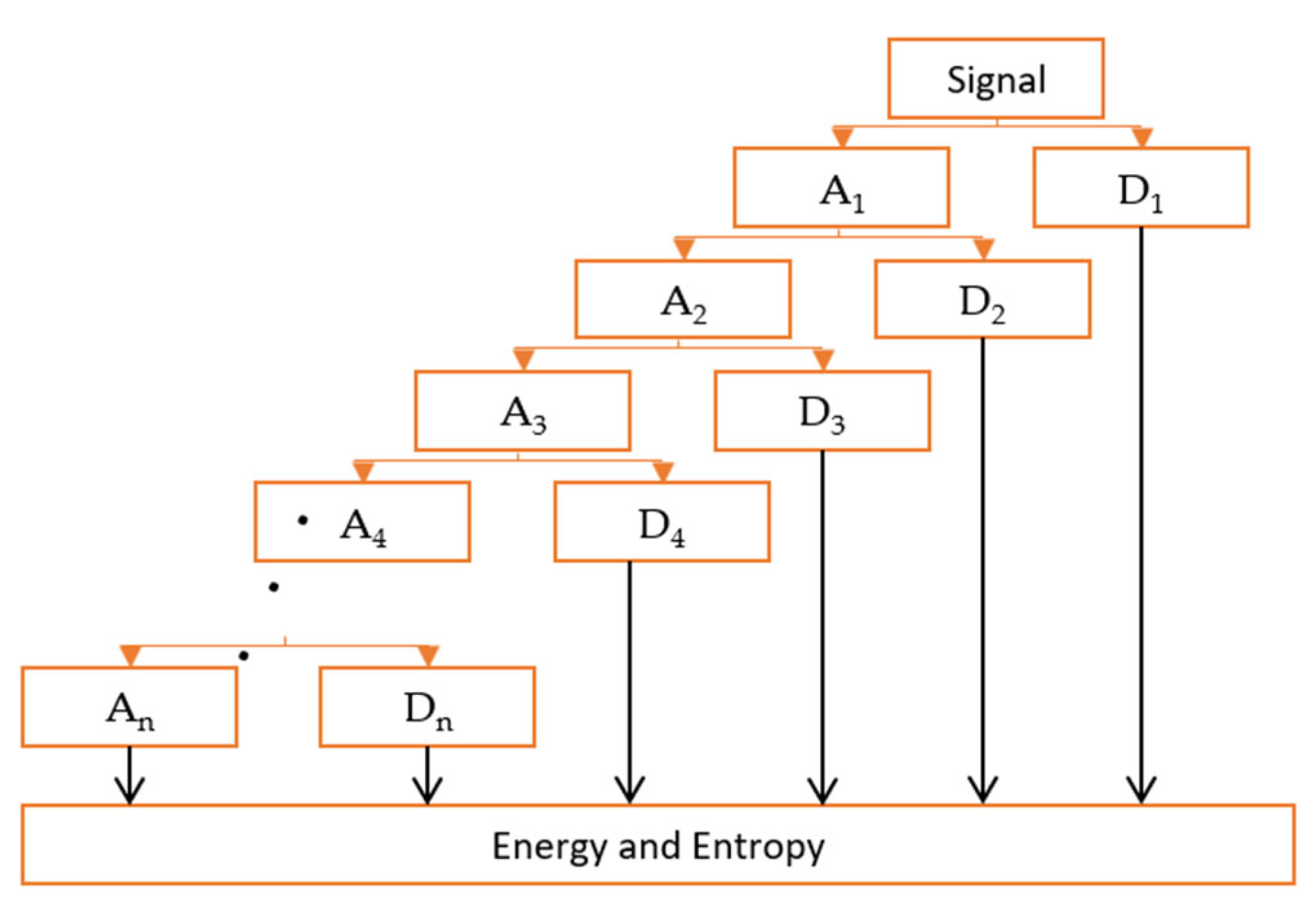
2.2. Feature Extraction and Dictionary Construction
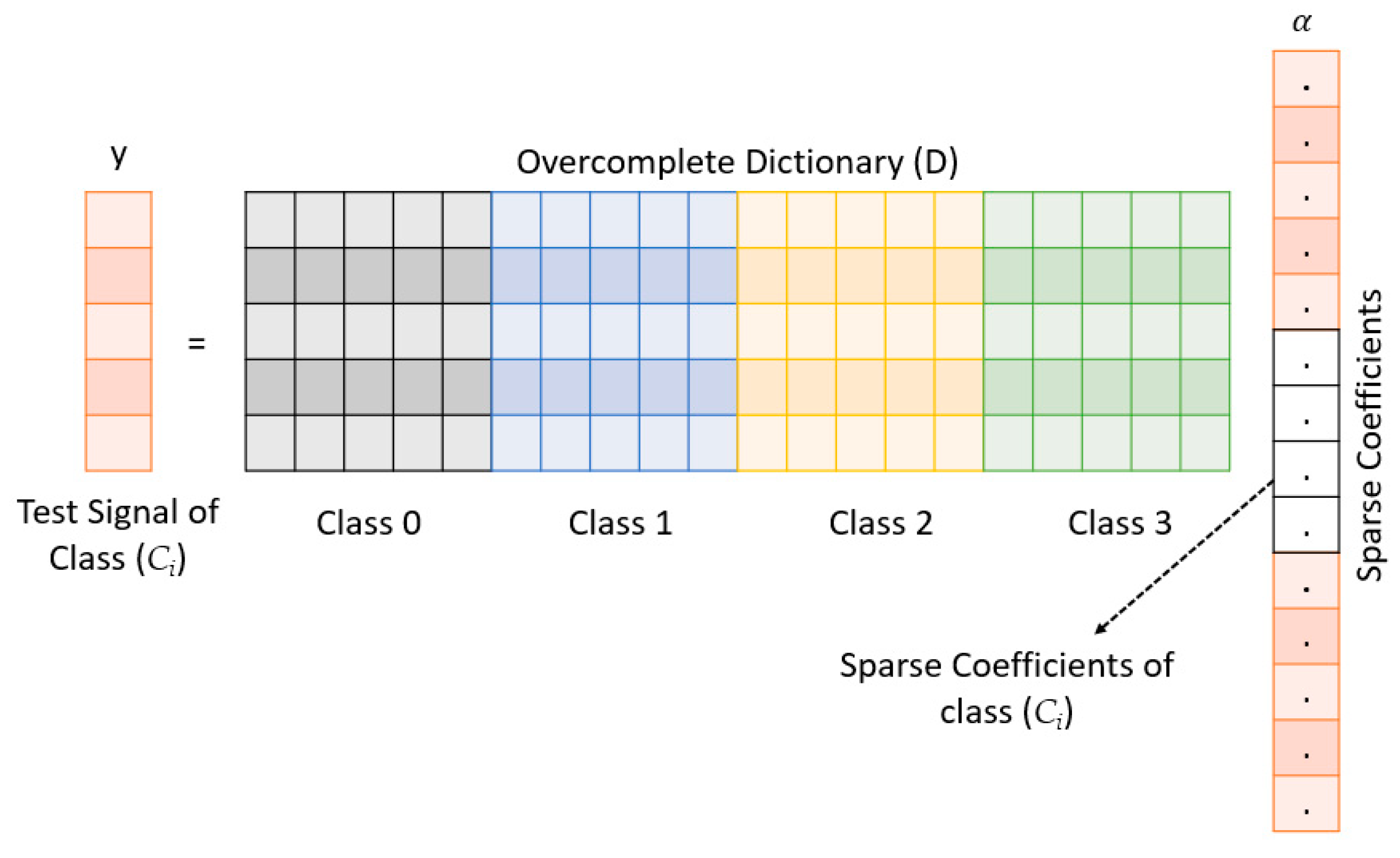
2.3. Sparse Representation
2.4. Sparsity-Based Classification
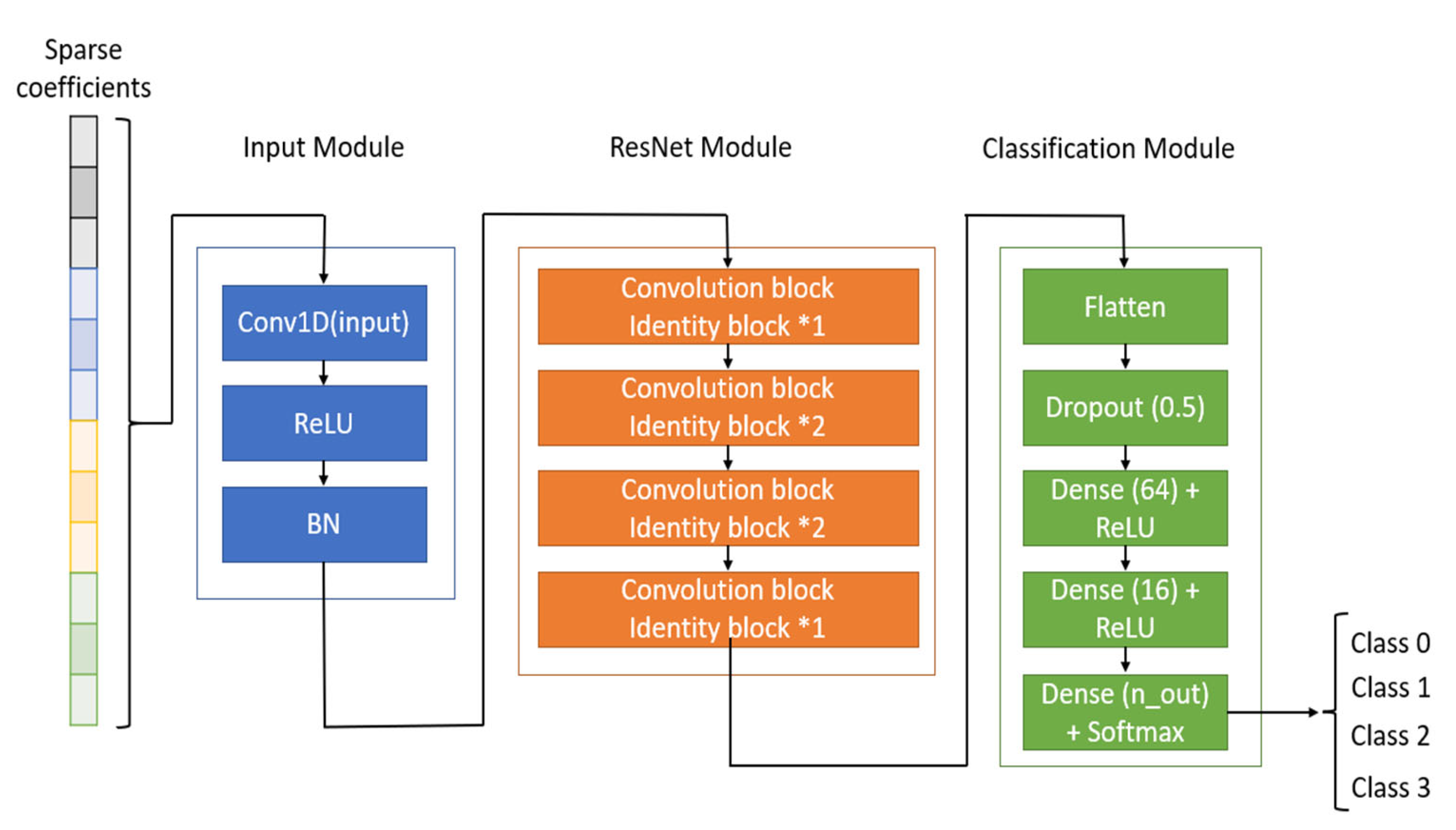
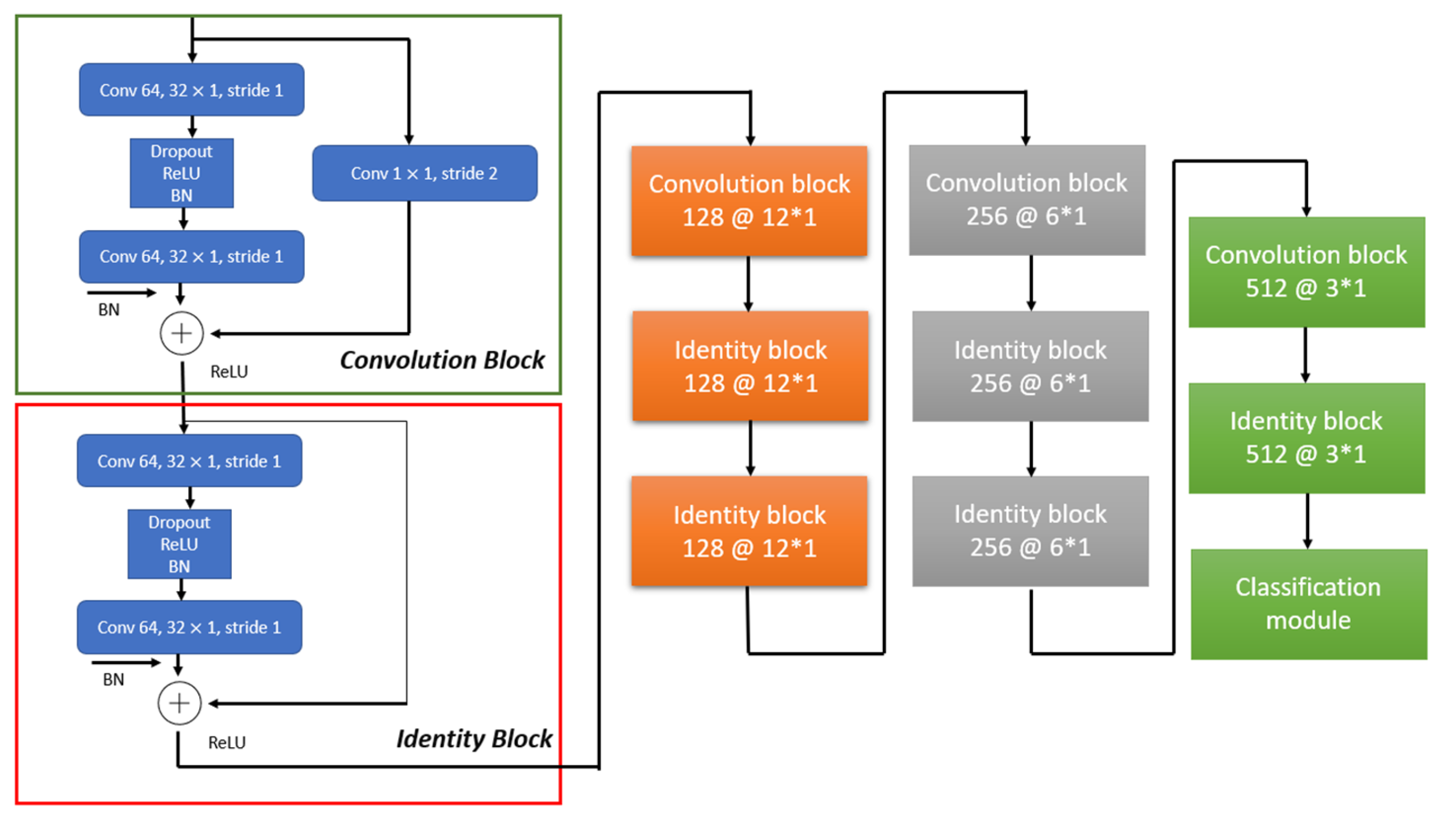
2.4.1. Residual Network Theory
2.4.2. Input Module
2.4.3. Residual Learning Module
2.4.4. Classification Module
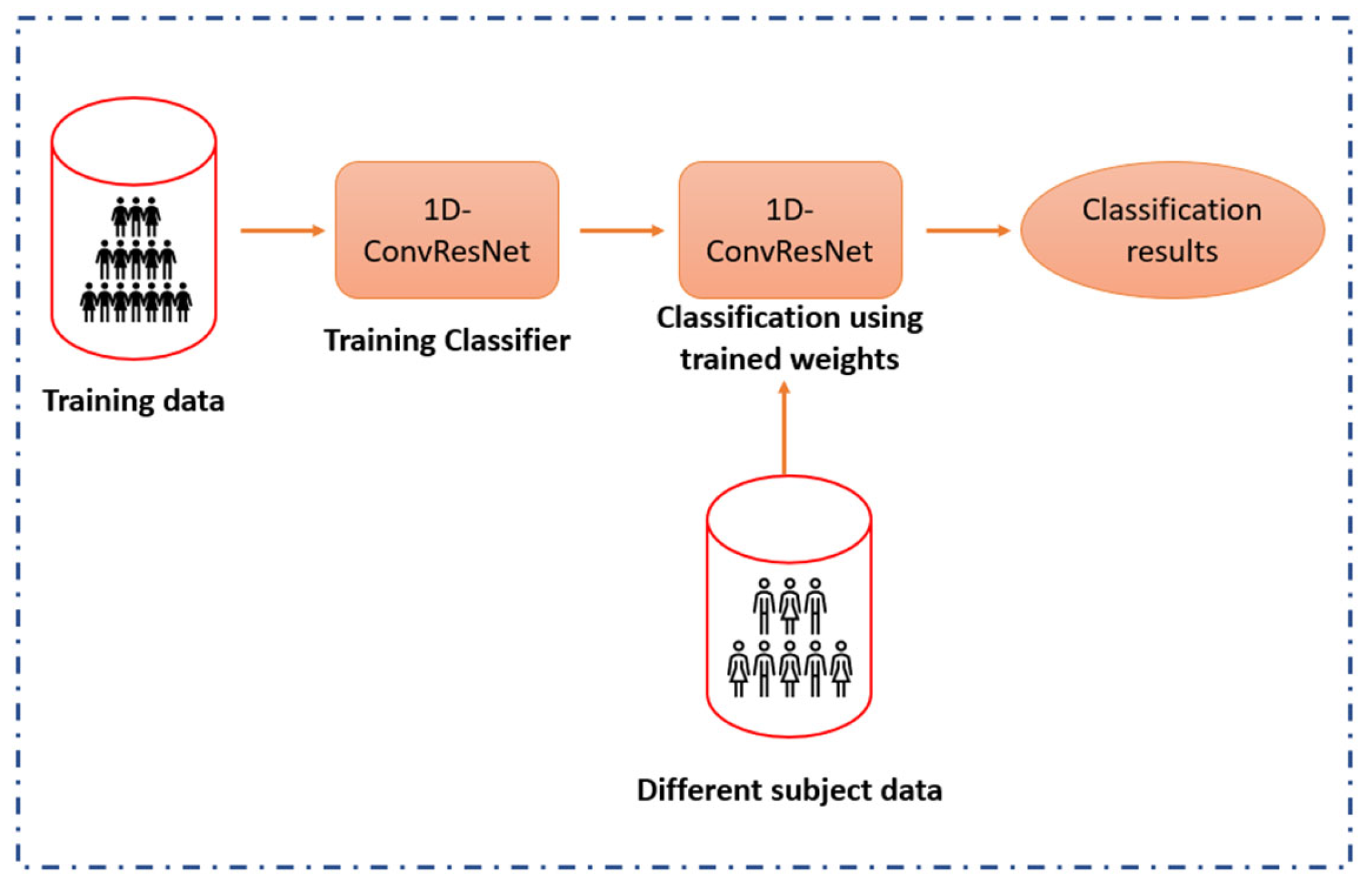
2.5. Subject-Independent Classification
3. Results
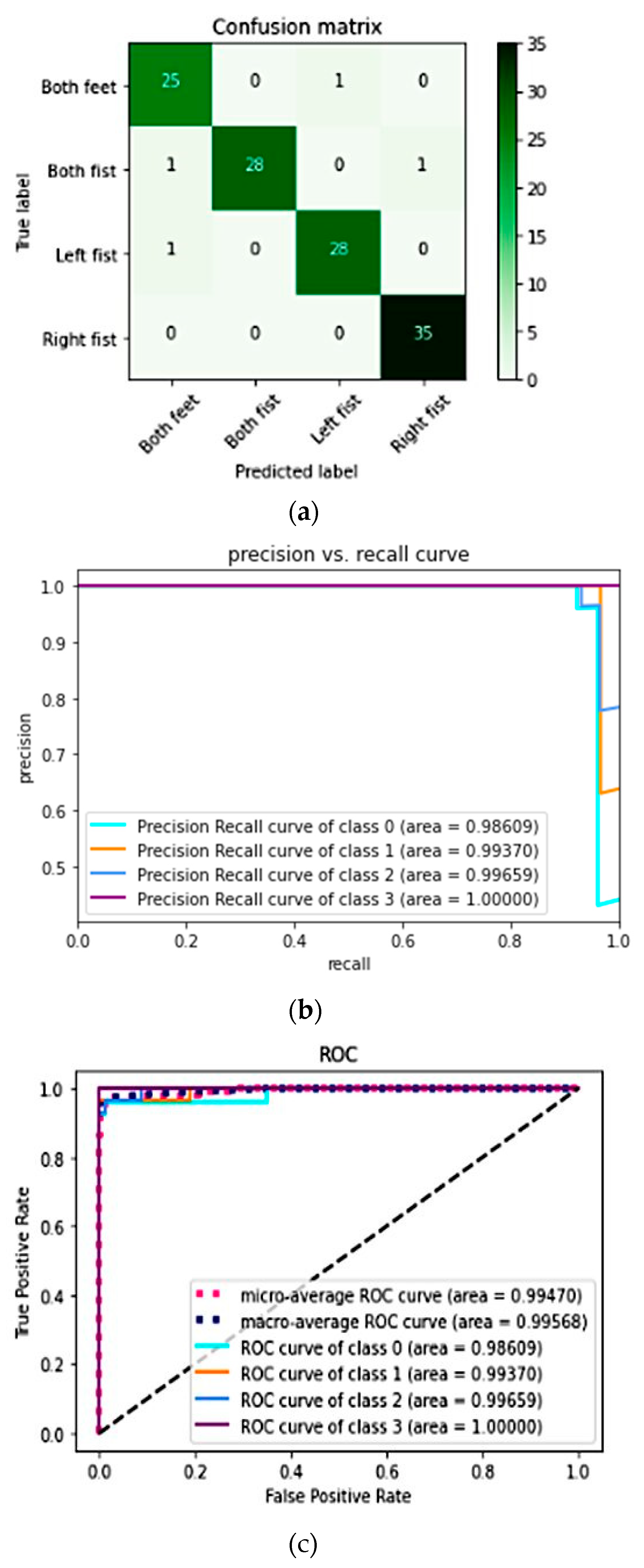
3.1. Subject-Independent Classification
3.2. Performance of the Proposed Method with Different Epoch Lengths
3.3. Performance of the Proposed Method with Different Epoch Lengths and Selected Channels
3.4. Performance of the Proposed Method with Different Features
3.5. Comparison of the Proposed Model with Different Classification Models
3.6. Comparison with State-of-the-Art Methods
4. Discussion
4.1. Accuracy
4.2. Computational Time
4.3. Intersubject Variability
4.4. Limitations of Validation
4.5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Gurve, D.; Delisle-Rodriguez, D.; Bastos-Filho, T.; Krishnan, S. Trends in Compressive Sensing for EEG Signal Processing Applications. Sensors 2020, 20, 3703. [Google Scholar] [CrossRef] [PubMed]
- Jin, J.; Liu, C.; Daly, I.; Miao, Y.; Li, S.; Wang, X.; Cichocki, A. Bispectrum-Based Channel Selection for Motor Imagery Based Brain-Computer Interfacing. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2153–2163. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.-H.; Jeong, J.-H.; Shim, K.-H.; Lee, S.-W. Classification of High-Dimensional Motor Imagery Tasks Based on an End-to-End Role Assigned Convolutional Neural Network. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1359–1363. [Google Scholar] [CrossRef] [Green Version]
- Raza, H.; Rathee, D.; Zhou, S.-M.; Cecotti, H.; Prasad, G. Covariate shift estimation based adaptive ensemble learning for handling non-stationarity in motor imagery related EEG-based brain-computer interface. Neurocomputing 2019, 343, 154–166. [Google Scholar] [CrossRef] [PubMed]
- Leelaarporn, P.; Wachiraphan, P.; Kaewlee, T.; Udsa, T.; Chaisaen, R.; Choksatchawathi, T.; Laosirirat, R.; Lakhan, P.; Natnithikarat, P.; Thanontip, K.; et al. Sensor-Driven Achieving of Smart Living: A Review. IEEE Sens. J. 2021, 21, 10369–10391. [Google Scholar] [CrossRef]
- Pilastri, A.L.; Tavares, J.M.R. Reconstruction Algorithms in Compressive Sensing: An Overview. In Proceedings of the 11th Edition of the Doctoral Symposium in Informatics Engineering (DSIE-16), Porto, Portugal, 3 February 2016; pp. 127–137. [Google Scholar]
- Ditthapron, A.; Banluesombatkul, N.; Ketrat, S.; Chuangsuwanich, E.; Wilaiprasitporn, T. Universal Joint Feature Extraction for P300 EEG Classification Using Multi-Task Autoencoder. IEEE Access 2019, 7, 68415–68428. [Google Scholar] [CrossRef]
- Shrivastwa, R.R.; Pudi, V.; Duo, C.; So, R. A brain–computer interface framework based on compressive sensing and deep learning. IEEE Consum. Electron. Mag. 2020, 9, 90–96. [Google Scholar] [CrossRef]
- Gao, G.; Shang, L.; Xiong, K.; Fang, J.; Zhang, C.; Gu, X. EEG Classification Based on Sparse Representation and Deep Learning. Neuroquantology 2018, 16. [Google Scholar] [CrossRef] [Green Version]
- Sreeja, S.R.; Samanta, D. Classification of multiclass motor imagery EEG signal using sparsity approach. Neurocomputing 2019, 368, 133–145. [Google Scholar] [CrossRef]
- Zeng, K.; Yan, J.; Wang, Y.; Sik, A.; Ouyang, G.; Li, X. Automatic detection of absence seizures with compressive sensing EEG. Neurocomputing 2016, 171, 497–502. [Google Scholar] [CrossRef] [Green Version]
- Chaisaen, R.; Autthasan, P.; Mingchinda, N.; Leelaarporn, P.; Kunaseth, N.; Tammajarung, S.; Manoonpong, P.; Mukhopadhyay, S.C.; Wilaiprasitporn, T. Decoding EEG Rhythms During Action Observation, Motor Imagery, and Execution for Standing and Sitting. IEEE Sens. J. 2020, 20, 13776–13786. [Google Scholar] [CrossRef]
- Wilaiprasitporn, T.; Ditthapron, A.; Matchaparn, K.; Tongbuasirilai, T.; Banluesombatkul, N.; Chuangsuwanich, E. Affective EEG-Based Person Identification Using the Deep Learning Approach. IEEE Trans. Cogn. Dev. Syst. 2019, 12, 486–496. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lema-Condo, E.L.; Bueno-Palomeque, F.L.; Castro-Villalobos, S.E.; Ordonez-Morales, E.F.; Serpa-Andrade, L.J. Comparison of Wavelet Transform Symlets (2-10) and Daubechies (2-10) for an Electroencephalographic Signal Analysis. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cusco, Peru, 15–18 August 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Gowri, M.S.G.; Raj, D.P.P. EEG Feature extraction using Daubechies Wavelet and Classification using Neural Network. Int. J. Comput. Sci. Eng. 2019, 7, 792–799. [Google Scholar] [CrossRef]
- Jacob, J.E.; Nair, G.K.; Iype, T.; Cherian, A. Diagnosis of Encephalopathy Based on Energies of EEG Subbands Using Discrete Wavelet Transform and Support Vector Machine. Neurol. Res. Int. 2018, 2018, 3209–3223. [Google Scholar] [CrossRef] [PubMed]
- Gajbhiye, P.; Mingchinda, N.; Chen, W.; Mukhopadhyay, S.C.; Wilaiprasitporn, T.; Tripathy, R.K. Wavelet Domain Optimized Savitzky–Golay Filter for the Removal of Motion Artifacts From EEG Recordings. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]
- Mao, Y.; Huiyang, Z.; Gui, X. Exploring Deep Neural Networks for Branch Prediction; ECE Department, NC University: Raleigh, NC, USA, 2018; pp. 1–7. [Google Scholar]
- Peng, D.; Liu, Z.; Wang, H.; Qin, Y.; Jia, L. A Novel Deeper One-Dimensional CNN With Residual Learning for Fault Diagnosis of Wheelset Bearings in High-Speed Trains. IEEE Access 2018, 7, 10278–10293. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation 2000, 101, E215–E220. [Google Scholar] [CrossRef] [Green Version]
- Schalk, G.; McFarland, D.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J. BCI2000: A General-Purpose Brain-Computer Interface (BCI) System. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef]
- Sreeja, S.R.; Himanshu; Samanta, D. Distance-based weighted sparse representation to classify motor imagery EEG signals for BCI applications. Multimed. Tools Appl. 2020, 79, 13775–13793. [Google Scholar] [CrossRef]
- Wang, H.; Tang, C.; Xu, T.; Li, T.; Xu, L.; Yue, H.; Chen, P.; Li, J.; Bezerianos, A. An Approach of One-vs-Rest Filter Bank Common Spatial Pattern and Spiking Neural Networks for Multiple Motor Imagery Decoding. IEEE Access 2020, 8, 86850–86861. [Google Scholar] [CrossRef]
- Huang, J.-S.; Chen, B.-Q.; Zeng, N.-Y.; Cao, X.-C.; Li, Y. Accurate classification of ECG arrhythmia using MOWPT enhanced fast compression deep learning networks. J. Ambient. Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Hayou, S.; Doucet, A.; Rousseau, J. On the Impact of the Activation Function on Deep Neural Networks Training. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 4746–4754. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zhang, Y.; Nam, C.S.; Zhou, G.; Jin, J.; Wang, X.; Cichocki, A. Temporally Constrained Sparse Group Spatial Patterns for Motor Imagery BCI. IEEE Trans. Cybern. 2018, 49, 3322–3332. [Google Scholar] [CrossRef]
- Jin, J.; Miao, Y.; Daly, I.; Zuo, C.; Hu, D.; Cichocki, A. Correlation-based channel selection and regularized feature optimization for MI-based BCI. Neural Netw. 2019, 118, 262–270. [Google Scholar] [CrossRef]
- Bagh, N.; Machireddy, R. Detection of Motor Imagery Movements Based on the Features of Phase Space Reconstruction. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; pp. 916–919. [Google Scholar] [CrossRef]
- Blankertz, B.; Muller, K.-R.; Krusienski, D.; Schalk, G.; Wolpaw, J.; Schlogl, A.; Pfurtscheller, G.; Millan, J.; Schroder, M.; Birbaumer, N. The BCI competition III: Validating alternative approaches to actual BCI problems. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 153–159. [Google Scholar] [CrossRef]
- Wang, X.; Hersche, M.; Tömekce, B.; Kaya, B.; Magno, M.; Benini, L. An Accurate EEGNet-Based Motor-Imagery Brain–Computer Interface for Low-Power Edge Computing. In Proceedings of the 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 1 June–1 July 2020. [Google Scholar]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [Green Version]
- She, Q.; Chen, K.; Ma, Y.; Nguyen, T.; Zhang, Y. Sparse Representation-Based Extreme Learning Machine for Motor Imagery EEG Classification. Comput. Intell. Neurosci. 2018, 2018, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Zhang, B.; Yu, N.; Liu, K.; Sun, K. Advanced TSGL-EEGNet for Motor Imagery EEG-Based Brain-Computer Interfaces. IEEE Access 2021, 9, 25118–25130. [Google Scholar] [CrossRef]
- Singh, A.; Lal, S.; Guesgen, H.W. Small Sample Motor Imagery Classification Using Regularized Riemannian Features. IEEE Access 2019, 7, 46858–46869. [Google Scholar] [CrossRef]
- Kwon, O.-Y.; Lee, M.-H.; Guan, C.; Lee, S.-W. Subject-Independent Brain–Computer Interfaces Based on Deep Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3839–3852. [Google Scholar] [CrossRef]
- Banluesombatkul, N.; Ouppaphan, P.; Leelaarporn, P.; Lakhan, P.; Chaitusaney, B.; Jaimchariyatam, N.; Chuangsuwanich, E.; Chen, W.; Phan, H.; Dilokthanakul, N.; et al. MetaSleepLearner: A Pilot Study on Fast Adaptation of Bio-Signals-Based Sleep Stage Classifier to New Individual Subject Using Meta-Learning. IEEE J. Biomed. Health Inform. 2021, 25, 1949–1963. [Google Scholar] [CrossRef]
- Fadel, W.; Kollod, C.; Wahdow, M.; Ibrahim, Y.; Ulbert, I. Multi-Class Classification of Motor Imagery EEG Signals Using Image-Based Deep Recurrent Convolutional Neural Network. In Proceedings of the 2020 8th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 26–28 February 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Cai, S.; Shu, Y.; Chen, G.; Ooi, B.C.; Wang, W.; Zhang, M. Effective and efficient dropout for deep convolutional neural networks. arXiv 2019, arXiv:1904.03392. [Google Scholar]
- Roots, K.; Muhammad, Y.; Muhammad, N. Fusion Convolutional Neural Network for Cross-Subject EEG Motor Imagery Classification. Computers 2020, 9, 72. [Google Scholar] [CrossRef]
- Dose, H.; Moller, J.S.; Puthusserypady, S.; Iversen, H.K. A Deep Learning MI-EEG Classification Model for BCIs. In Proceedings of the 26th European Signal Processing Conference, Rome, Italy, 3–7 September 2018; pp. 1676–1679. [Google Scholar] [CrossRef] [Green Version]
- Lun, X.; Yu, Z.; Chen, T.; Wang, F.; Hou, Y. A Simplified CNN Classification Method for MI-EEG via the Electrode Pairs Signals. Front. Hum. Neurosci. 2020, 14, 338. [Google Scholar] [CrossRef] [PubMed]
- Mishra, A.; Thakkar, F.N.; Modi, C.; Kher, R. Selecting the Most Favorable Wavelet for Compressing ECG Signals Using Compressive Sensing Approach. In Proceedings of the 2012 International Conference on Communication Systems and Network Technologies, Rajkot, India, 11–13 May 2012; pp. 128–132. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epoch (Length of Trial in Seconds) | Accuracy (%) | Training Time (s) | Testing Time (s) |
|---|---|---|---|
| 0.1 | 76.08 ± 0.45 | 300 | 0.25 |
| 0.2 | 62.59 ± 0.25 | 259.06 | 0.33 |
| 0.3 | 72.8 ± 0.24 | 140.8 | 0.39 |
| 0.4 | 90 ± 0.16 | 110.63 | 0.45 |
| 0.5 | 96.6 ± 0.18 | 98 | 0.5 |
| Epoch (Length of Trial in Seconds) | Accuracy (%) | Training Time (s) | Testing Time (s) |
|---|---|---|---|
| 0.1 | 77.9 ± 0.18 | 250 | 0.18 |
| 0.2 | 63 ± 0.22 | 213.45 | 0.18 |
| 0.3 | 76.85 ± 0.18 | 125 | 0.2 |
| 0.4 | 94.8 ± 0.25 | 96.25 | 0.32 |
| 0.5 | 98.75 ± 0.46 | 75 | 0.33 |
| Features | Accuracy (%) | Training Time (s) | Testing Time (s) |
|---|---|---|---|
| Wavelet entropy | 93 ± 0.28 | 110 | 0.34 |
| Wavelet energy | 93.9 ± 0.25 | 111 | 0.34 |
| Kurtosis | 86.11 ± 1.26 | 122.76 | 0.34 |
| Wavelet entropy + Wavelet energy (Proposed) | 96 ± 0.19 | 125.6 | 0.38 |
| Power spectral density | 91.2 ± 0.84 | 156 | 0.54 |
| Common spatial pattern | 94.5 ± 0.456 | 142 | 0.45 |
| Classifier | Accuracy (%) | Testing Time (s) |
|---|---|---|
| SVM | 92.46 ± 0.28 | 0.45 |
| LDA | 68 ± 2.98 | 0.78 |
| k-NN | 56.2 ± 2.74 | 0.76 |
| CNN | 66.9 ± 0.25 | 0.62 |
| Proposed model | 96.6 ± 0.18 | 0.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gangapuram, H.; Manian, V. A Sparse Multiclass Motor Imagery EEG Classification Using 1D-ConvResNet. Signals 2023, 4, 235-250. https://doi.org/10.3390/signals4010013
Gangapuram H, Manian V. A Sparse Multiclass Motor Imagery EEG Classification Using 1D-ConvResNet. Signals. 2023; 4(1):235-250. https://doi.org/10.3390/signals4010013
Chicago/Turabian StyleGangapuram, Harshini, and Vidya Manian. 2023. "A Sparse Multiclass Motor Imagery EEG Classification Using 1D-ConvResNet" Signals 4, no. 1: 235-250. https://doi.org/10.3390/signals4010013
APA StyleGangapuram, H., & Manian, V. (2023). A Sparse Multiclass Motor Imagery EEG Classification Using 1D-ConvResNet. Signals, 4(1), 235-250. https://doi.org/10.3390/signals4010013