

Dialogue Act Classification via Transfer Learning for Automated Labeling of Interviewee Responses in Virtual Reality Job Interview Training Platforms for Autistic Individuals

 , , and
, , and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Data Collection via Job Interview Training System
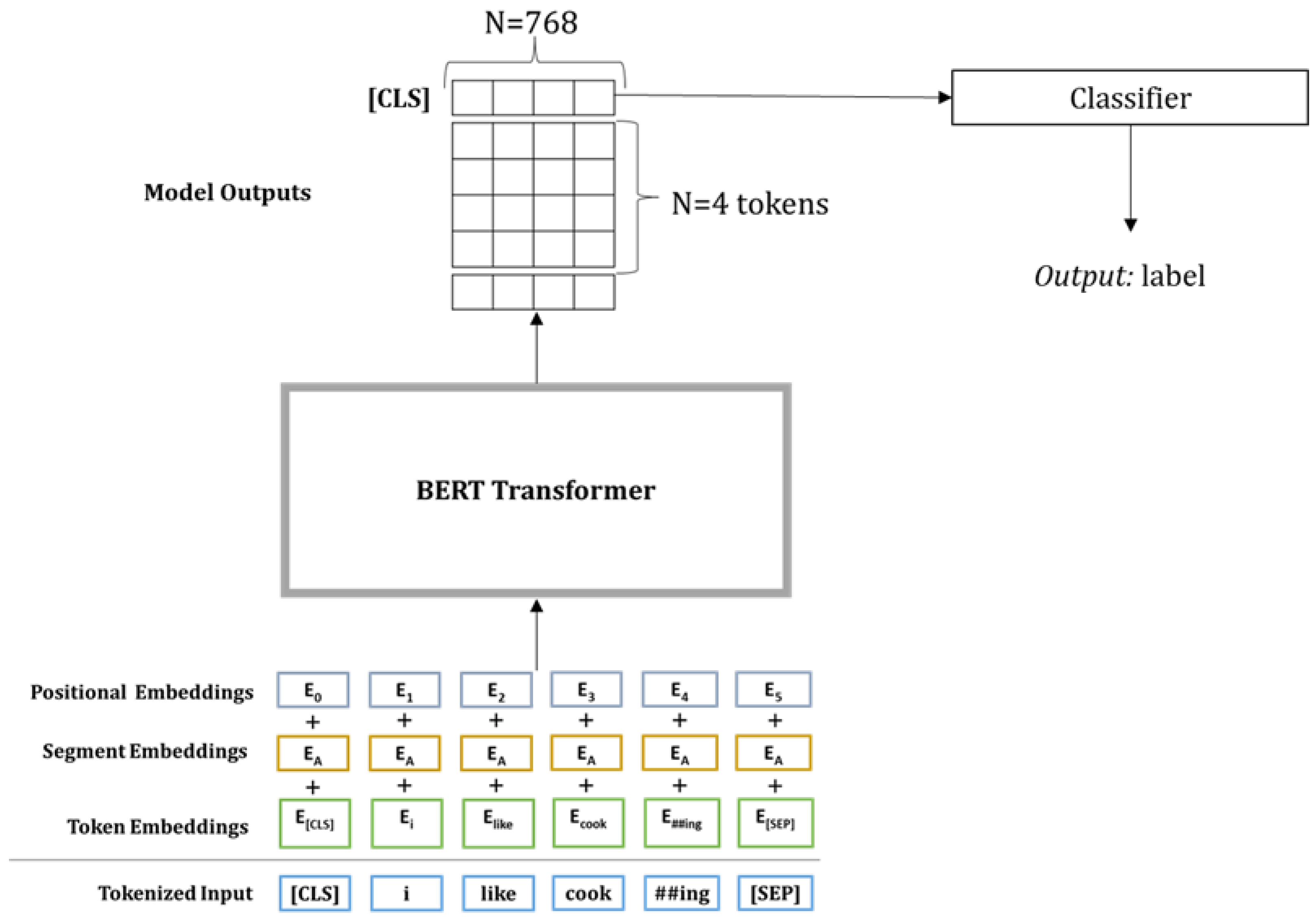
3.2. The BERT Architecture and Fine-Tuning BERT for Text Classification
3.3. Dialogue Act Labeling
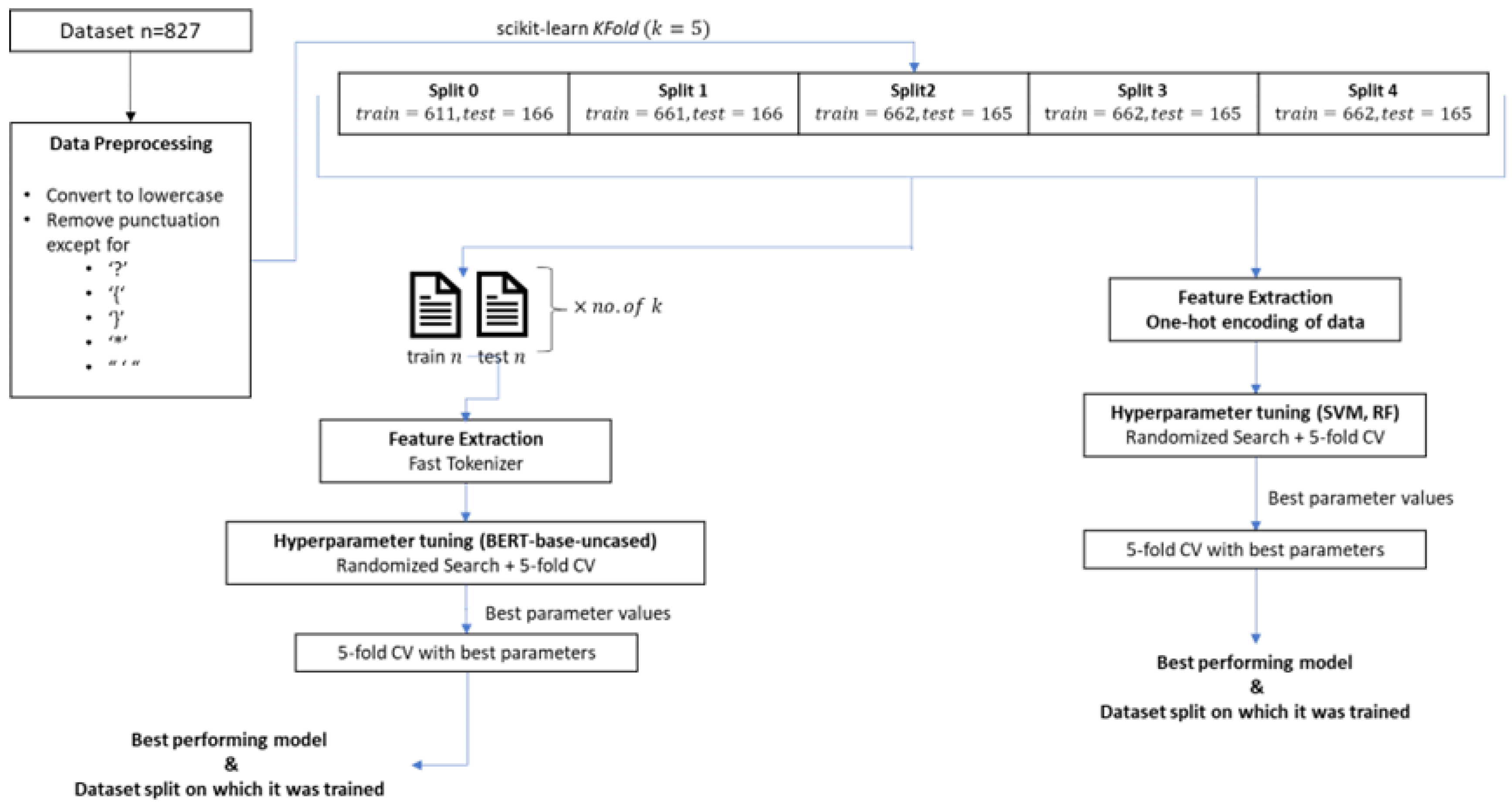
3.4. The Data
3.5. Model Training
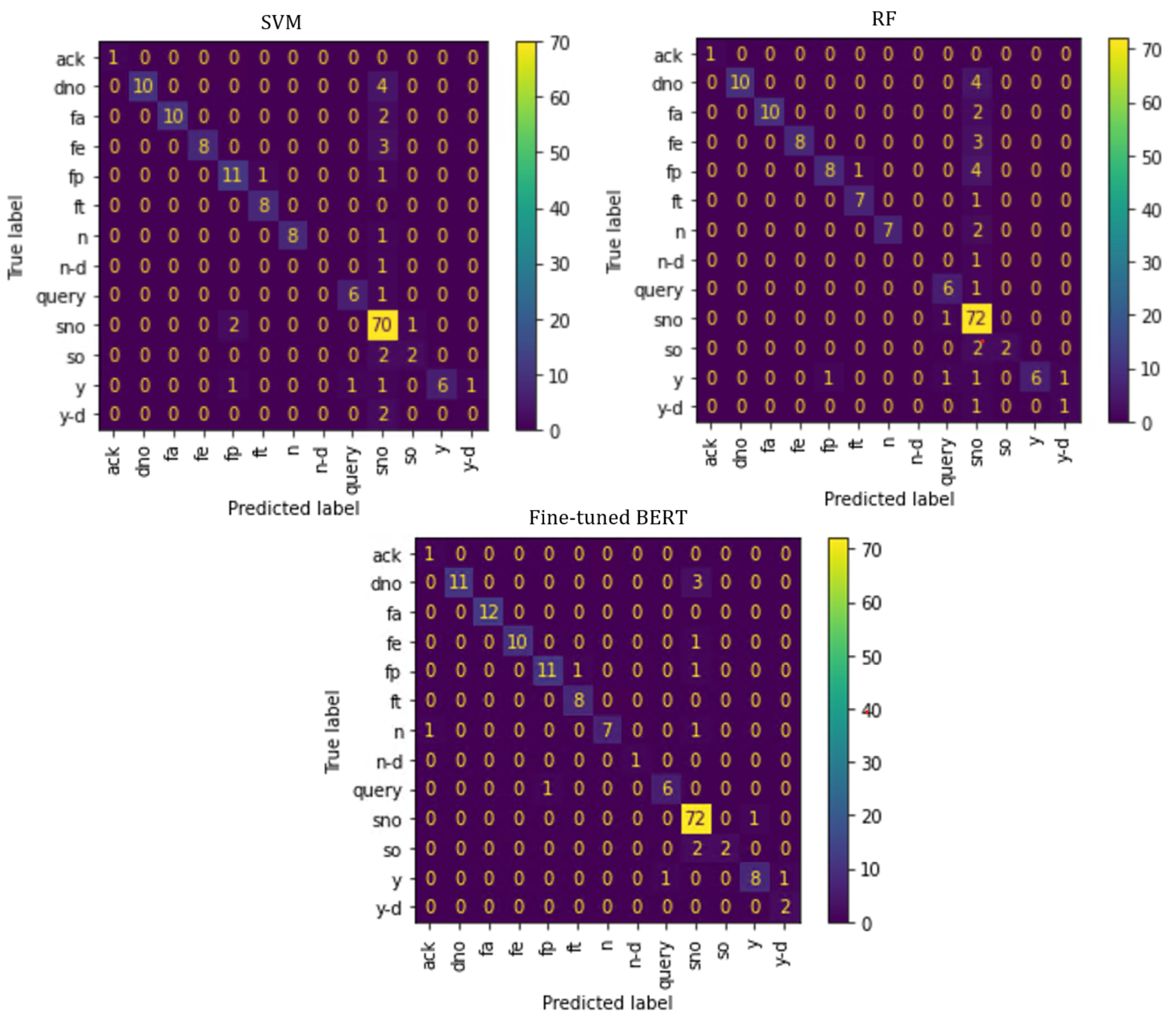
4. Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| VR | Virtual Reality |
| BERT | Bidirectional Encoder Representations from Transformers |
| DA | Dialogue Act |
| ASD | Autism Spectrum Disorder |
| SVM | Support Vector Machine |
| DAN | Deep Average Network |
| RNN | Recurrent Neural Network |
| SwDA | Switchboard Dialogue Act |
| POS | Parts of Speech |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| RoBERTa | Robustly Optimized BERT Approach |
| MLM | Masked Language Modeling |
| NSP | Next Sentence Prediction |
| TOD-BERT | Task-Oriented Dialogue BERT |
| CNN | Convolutional Neural Network |
| CV | Cross-Validation |
| LSTM | Long Short-Term Memory |
| CIRVR | Career Interview Readiness in Virtual Reality |
| IRB | Institutional Review Board |
| CSV | Comma-Separated Values |
| NLTK | Natural Language Toolkit |
| RBF | Radial Basis Function |
| JSON | JavaScript Object Notation |
Appendix A
Appendix A.1
Appendix A.2
Appendix A.3. Training a Fine-Tuned BERT
- config.json has the BERT-base-uncased architecture and configuration of the model, saved in JavaScript Object Notation (JSON).
- pytorch_model.bin is the model in a binary file format.
- special_tokens_map.json has the [CLS], [SEP], and more special tokens stored as JSON.
- tokenizer.json consists of the tokenizer information, as well as the indices of the tokens in the vocabulary.
- tokenizer_config.json has the tokenizer configuration of the fine-tuned BERT model.
- training_args.bin is a binary file of the training arguments used while training the model.
- vocab.txt consists of all the words in the BERT-base vocabulary in a text file.
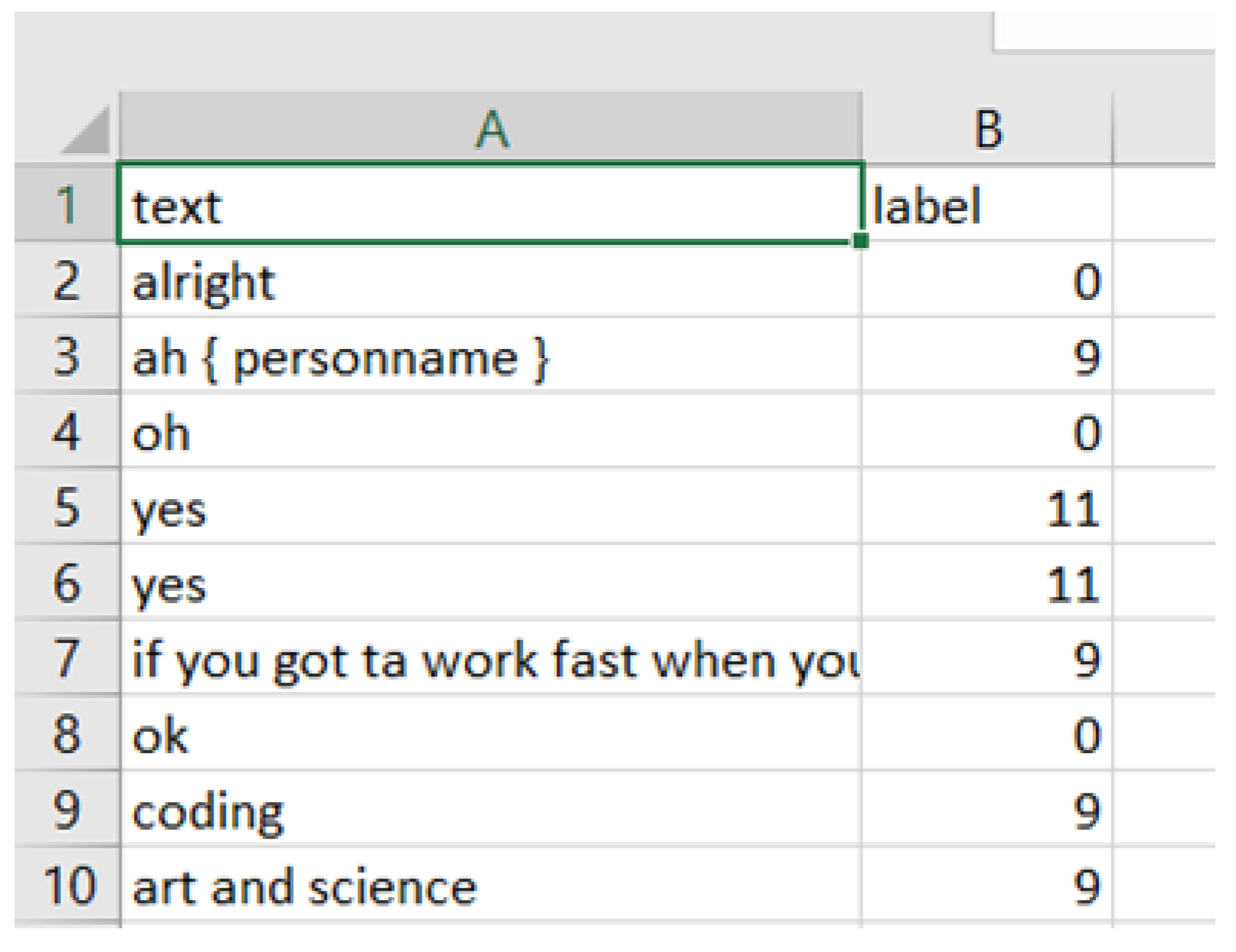
- Data PreprocessingThe first step is to prepare the data. Based on the task, a user may choose to preprocess their data, as we describe in Section 3.4. For further fine tuning of BERT, a user may have fewer or more classes than what the model was previously trained to predict. The utterances need to be in text (not tokens) and stored in the first column of a CSV file with the header “text”. The labels should be encoded to be represented as unique integers. For example, if your labels are ‘positive’, ‘negative’ or ‘neutral’, you can encode the labels as ‘positive’: 0, ‘negative’: 1, ‘neutral’: 2. The encoded label for each corresponding utterance should be in the second column of the CSV file with the header ‘label’. The training and testing data are to be separated into a training.csv file and a testing.csv file, and the columns in both files should have the same headers “text” and “label” (see Figure A1). Note that the training data can be further split into a training and validation set for evaluation of models during training, which is especially useful for early stopping.Figure A1. CSV file format for BERT training.
![Signals 04 00019 g0a1]() In the program, the CSV files are loaded using the load_dataset() function of the Python datasets library.train_data = load_dataset(‘csv’, ‘train’: ‘training.csv’)For tokenization and feature extraction, we use the BERTFastTokenizer from the transformers library, which has a from_pretrained() function that loads the saved tokenizer in fine-tuned BERT. The function takes the model name as an argument or the name of the folder where the fine-tuned BERT model files are stored, i.e., fine-tuned-BERT. The second parameter is do_lower_case = True, which internally converts the text to lowercase if it is not already. Below is the line of code to load the tokenizer.tokenizer = BERTFastTokenizer.from_pretrained(‘fine-tuned-BERT’, do_lower_case = True)Once loaded, the dataset is tokenized one sample at a time, where the tokenizer accepts a few arguments: padding = [True, False], truncation = [True, False], max_length = integer value. For example, to make all samples a fixed length, we can set padding to True; if the sentences are very long (greater than 512 tokens), we can set truncation to True; or if we want each sequence to be of a specific length, e.g., 32 tokens, then we can set max_length to that value. The preprocess function passed each sample in the train_data and returns the tokenized data.def preprocess(samples): return tokenizer(samples[‘text’], padding = True)tokenized_train_data = train_data.map(preprocess)Once the training and testing sets have been tokenized, we move on to the model.
In the program, the CSV files are loaded using the load_dataset() function of the Python datasets library.train_data = load_dataset(‘csv’, ‘train’: ‘training.csv’)For tokenization and feature extraction, we use the BERTFastTokenizer from the transformers library, which has a from_pretrained() function that loads the saved tokenizer in fine-tuned BERT. The function takes the model name as an argument or the name of the folder where the fine-tuned BERT model files are stored, i.e., fine-tuned-BERT. The second parameter is do_lower_case = True, which internally converts the text to lowercase if it is not already. Below is the line of code to load the tokenizer.tokenizer = BERTFastTokenizer.from_pretrained(‘fine-tuned-BERT’, do_lower_case = True)Once loaded, the dataset is tokenized one sample at a time, where the tokenizer accepts a few arguments: padding = [True, False], truncation = [True, False], max_length = integer value. For example, to make all samples a fixed length, we can set padding to True; if the sentences are very long (greater than 512 tokens), we can set truncation to True; or if we want each sequence to be of a specific length, e.g., 32 tokens, then we can set max_length to that value. The preprocess function passed each sample in the train_data and returns the tokenized data.def preprocess(samples): return tokenizer(samples[‘text’], padding = True)tokenized_train_data = train_data.map(preprocess)Once the training and testing sets have been tokenized, we move on to the model. - Loading the ModelHere, we use the transformers library’s BertForSequenceClassification to load the model using the function from_pretrained(), as shown below.model = BERTForSequenceClassification.from_pretrained (“fine-tuned-BERT”, num_labels = 3)We can also specify where we want to store the model: on the GPU or on the CPU. To store the model on the GPU, we use model.to(“cuda”), and to store it on CPU, we use model.to(“cpu”).
- Defining Training ArgumentsThere are several hyperparameters that can be initialized before training. Here, we use the TrainingArguments function of the transformers library to set the hyperparameters. Specifically, we focus on the number of training epochs or training cycles, the learning rate, and the batch size, which can be affected by the amount of free memory we have available on our system. Here, we had a GPU memory of 16GB, which stores the model and the training data at any given time. Hence, we were only able to initiate the maximum batch size to 32. Other parameters in the TrainingArgs can be found at [87]. Just as we conducted hyperparameter tuning using an in-house randomized search on 5 folds of data, the user can follow the same method, or experiment with different values and use early stopping to find the best model. More hyperparameter-tuning options can be found in [88]. The training arguments, for example, are initialized as follows:training_args = TrainingArguments(num_train_epochs = 40,learning_rate = 5e-5,per_device_batch_size = 8,weight_decay = 0.01,output_dir= “Models/fine-tuned-BERT2”)
- Model TrainingWe use the transformers Trainer function to train the model. This function takes a few arguments. The first is the model loaded in Step 2; then, the args, which are the training_args from Step 3. The tokenized_train_data from Step 1 is passed to the train_dataset parameter. The tokenizer parameter is set to the tokenizer that we loaded from the pretrained model. Another optional parameter is the Data Collator. Data collators [89] are objects that form batches of data from a list of data input. Here, we used DataCollatorWithPadding and passed the tokenizer as an argument:data_collator = DataCollatorWithPadding(tokenizer=tokenizer)trainer = Trainer (model =model,args = training_args,train_dataset = tokenized_train_data,tokenizer = tokenizer,data_collator = data_collator)Next, we call the Trainer’s train() function.trainer.train()After training, the model can be saved along with the learned weights and data using the Trainer’s save(model name) function.trainer.save(model name)
- InferenceFor predictions, we create an inference pipeline. For this task, we can switch to the CPU if not enough GPU space is available. The text input, for example, “Hi there!”, is first preprocessed by converting to lower case and by removing any punctuation, as described in Section 3.4. The input is converted into tokens by the tokenizer with the same arguments as those used to tokenize the training set (e.g., padding = True). This input is passed to the model, from which we obtain the outputs on which we apply SoftMax, which gives us three probabilities for each class that add up to 1. The argmax of the probabilities is the predicted class label.

References
- Maenner, M.J.; Shaw, K.A.; Bakian, A.V.; Bilder, D.A.; Durkin, M.S.; Esler, A.; Furnier, S.M.; Hallas, L.; Hall-Lande, J.; Hudson, A.; et al. Prevalence and characteristics of autism spectrum disorder among children aged 8 years—Autism and developmental disabilities monitoring network, 11 sites, United States, 2018. MMWR Surveill. Summ. 2021, 70, 1–16. [Google Scholar] [CrossRef] [PubMed]
- American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders: DSM-5, 5th ed.; American Psychiatric Association: San Francisco, CA, USA, 2013; pp. 50–59. [Google Scholar] [CrossRef]
- Taboas, A.; Doepke, K.; Zimmerman, C. Preferences for identity-first versus person-first language in a US sample of autism stakeholders. Autism 2023, 27, 565–570. [Google Scholar] [CrossRef] [PubMed]
- Roux, A.M.; Rast, J.E.; Anderson, K.A.; Shattuck, P.T. National Autism Indicators Report: Developmental Disability Services and Outcomes in Adulthood; Life Course Outcomes Program, AJ Drexel Autism Institute, Drexel University: Philadelphia, PA, USA, 2017. [Google Scholar]
- Wehman, P.; Taylor, J.; Brooke, V.; Avellone, L.; Whittenburg, H.; Ham, W.; Brooke, A.M.; Carr, S. Toward Competitive Employment for Persons with Intellectual and Developmental Disabilities: What Progress Have We Made and Where Do We Need to Go. Res. Pract. Pers. Sev. Disabil. 2018, 43, 131–144. [Google Scholar] [CrossRef]
- Hayward, S.M.; McVilly, K.R.; Stokes, M.A. Autism and employment: What works. Res. Autism Spectr. Disord. 2019, 60, 48–58. [Google Scholar] [CrossRef]
- Booth, J. Autism Equality in the Workplace. Removing Barriers and Challenging Discrimination; Jessica Kingsley Publishers: London, UK, 2016. [Google Scholar]
- Harmuth, E.; Silletta, E.; Bailey, A.; Adams, T.; Beck, C.; Barbic, S.P. Barriers and facilitators to employment for adults with autism: A scoping review. Ann. Int. Occup. Ther. 2018, 1, 31–40. [Google Scholar] [CrossRef]
- Ohl, A.; Grice Sheff, M.; Small, S.; Nguyen, J.; Paskor, K.; Zanjirian, A. Predictors of employment status among adults with Autism Spectrum Disorder. Work 2017, 56, 345–355. [Google Scholar] [CrossRef]
- Flower, R.L.; Dickens, L.M.; Hedley, D. Barriers to Employment: Raters’ Perceptions of Male Autistic and Non-Autistic Candidates During a Simulated Job Interview and the Impact of Diagnostic Disclosure. Autism Adulthood 2021, 3, 300–309. [Google Scholar] [CrossRef]
- Maras, K.L.; Norris, J.E.; Nicholson, J.; Heasman, B.; Remington, A.; Crane, L. Ameliorating the disadvantage for autistic job seekers: An initial evaluation of adapted employment interview questions. Autism 2020, 25, 1060–1075. [Google Scholar] [CrossRef]
- Smith, M.J.; Ginger, E.J.; Wright, K.; Wright, M.A.; Taylor, J.L.; Humm, L.B.; Olsen, D.E.; Bell, M.D.; Fleming, M.F. Virtual reality job interview training in adults with autism spectrum disorder. J. Autism Dev. Disord. 2014, 44, 2450–2463. [Google Scholar] [CrossRef]
- Haruki, K.; Muraki, Y.; Yamamoto, K.; Lala, D.; Inoue, K.; Kawahara, T. Simultaneous Job Interview System Using Multiple Semi-Autonomous Agents. In Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue, Edinburgh, UK, 7–9 September 2022; Association for Computational Linguistics: Edinburgh, UK, 2022; pp. 107–110. [Google Scholar]
- Smith, M.J.; Pinto, R.M.; Dawalt, L.; Smith, J.; Sherwood, K.; Miles, R.; Taylor, J.; Hume, K.; Dawkins, T.; Baker-Ericzén, M.; et al. Using community-engaged methods to adapt virtual reality job-interview training for transition-age youth on the autism spectrum. Res. Autism Spectr. Disord. 2020, 71, 101498. [Google Scholar] [CrossRef]
- Baur, T.; Damian, I.; Gebhard, P.; Porayska-Pomsta, K.; André, E. A Job Interview Simulation: Social Cue-Based Interaction with a Virtual Character. In Proceedings of the 2013 International Conference on Social Computing, Alexandria, VA, USA, 8–14 September 2013; pp. 220–227. [Google Scholar] [CrossRef]
- Strickland, D.C.; Coles, C.D.; Southern, L.B. JobTIPS: A transition to employment program for individuals with autism spectrum disorders. J. Autism Dev. Disord. 2013, 43, 2472–2483. [Google Scholar] [CrossRef]
- VirtualSpeech: Soft Skills Training with VR. 2021. Available online: https://virtualspeech.com/ (accessed on 12 January 2023).
- Smith, M.J.; Smith, J.D.; Jordan, N.; Sherwood, K.; McRobert, E.; Ross, B.; Oulvey, E.A.; Atkins, M.S. Virtual Reality Job Interview Training in Transition Services: Results of a Single-Arm, Noncontrolled Effectiveness-Implementation Hybrid Trial. J. Spec. Educ. Technol. 2021, 36, 3–17. [Google Scholar] [CrossRef]
- Smith, M.; Sherwood, K.; Ross, B.; Smith, J.; DaWalt, L.; Bishop, L.; Humm, L.; Elkins, J.; Steacy, C. Virtual interview training for autistic transition age youth: A randomized controlled feasibility and effectiveness trial. Autism 2021, 25, 1536–1552. [Google Scholar] [CrossRef]
- Damian, I.; Baur, T.; Lugrin, B.; Gebhard, P.; Mehlmann, G.; André, E. Games are Better than Books: In-Situ Comparison of an Interactive Job Interview Game with Conventional Training. In Artificial Intelligence in Education; Conati, C., Heffernan, N., Mitrovic, A., Verdejo, M.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 84–94. [Google Scholar]
- Schmid Mast, M.; Kleinlogel, E.P.; Tur, B.; Bachmann, M. The future of interpersonal skills development: Immersive virtual reality training with virtual humans. Hum. Resour. Dev. Q. 2018, 29, 125–141. [Google Scholar] [CrossRef]
- Kwon, J.H.; Powell, J.; Chalmers, A. How level of realism influences anxiety in virtual reality environments for a job interview. Int. J. Hum. Comput. Stud. 2013, 71, 978–987. [Google Scholar] [CrossRef]
- Zhao, W. How Different Virtual Reality Environments Influence Job Interview Anxiety. Bachelor’s Thesis, The University of Twente, Enschede, The Netherlands, July 2022. Available online: http://essay.utwente.nl/91801/ (accessed on 4 April 2023).
- Villani, D.; Repetto, C.; Cipresso, P.; Riva, G. May I Experience More Presence in Doing the Same Thing in Virtual Reality than in Reality? An Answer from a Simulated Job Interview. Interact. Comput. 2012, 24, 265–272. [Google Scholar] [CrossRef]
- Adiani, D.; Breen, M.; Migovich, M.; Wade, J.; Hunt, S.; Tauseef, M.; Khan, N.; Colopietro, K.; Lanthier, M.; Swanson, A.; et al. Multimodal job interview simulator for training of autistic individuals. Assist. Technol. 2023, 1–18. [Google Scholar] [CrossRef]
- McTear, M.F.; Callejas, Z.; Griol, D. The Conversational Interface; Springer: Cham, Switzerland, 2016; Volume 6. [Google Scholar]
- Searle, J.R. What is a speech act. Perspect. Philos. Lang. Concise Anthol. 1965, 2000, 253–268. [Google Scholar]
- Chatterjee, A.; Sengupta, S. Intent Mining from past conversations for Conversational Agent. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 4140–4152. [Google Scholar] [CrossRef]
- Enayet, A.; Sukthankar, G. Poster: A Transfer Learning Approach for Dialogue Act Classification of GitHub Issue Comments. In Proceedings of the International Conference on Social Informatics, Pisa, Italy, 6–9 October 2020. [Google Scholar] [CrossRef]
- Montenegro, C.; López Zorrilla, A.; Mikel Olaso, J.; Santana, R.; Justo, R.; Lozano, J.A.; Torres, M.I. A Dialogue-Act Taxonomy for a Virtual Coach Designed to Improve the Life of Elderly. Multimodal Technol. Interact. 2019, 3, 52. [Google Scholar] [CrossRef]
- Ahmadvand, A.; Choi, J.I.; Agichtein, E. Contextual Dialogue Act Classification for Open-Domain Conversational Agents. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’19), Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1273–1276. [Google Scholar] [CrossRef]
- Stolcke, A.; Ries, K.; Coccaro, N.; Shriberg, E.; Bates, R.A.; Jurafsky, D.; Taylor, P.; Martin, R.; Ess-Dykema, C.V.; Meteer, M. Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech. Comput. Linguist. 2000, 26, 339–373. [Google Scholar] [CrossRef]
- Wood, A.; Eberhart, Z.; McMillan, C. Dialogue Act Classification for Virtual Agents for Software Engineers during Debugging. In Proceedings of the IEEE/ACM 42nd International Conference on Software Engineering Workshops, New York, NY, USA, 27 June–19 July 2020; pp. 462–469. [Google Scholar] [CrossRef]
- Liu, L.; Tang, L.; Dong, W.; Yao, S.; Zhou, W. An overview of topic modeling and its current applications in bioinformatics. SpringerPlus 2016, 5, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Khatri, C.; Goel, R.; Hedayatnia, B.; Metanillou, A.; Venkatesh, A.; Gabriel, R.; Mandal, A. Contextual Topic Modeling for Dialog Systems. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 892–899. [Google Scholar] [CrossRef]
- Boyer, K.E.; Grafsgaard, J.F.; Ha, E.Y.; Phillips, R.; Lester, J.C. An Affect-Enriched Dialogue Act Classification Model for Task-Oriented Dialogue. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 1190–1199. [Google Scholar]
- Saha, T.; Gupta, D.; Saha, S.; Bhattacharyya, P. Emotion aided dialogue act classification for task-independent conversations in a multi-modal framework. Cogn. Comput. 2021, 13, 277–289. [Google Scholar] [CrossRef]
- Rangarajan, V.; Bangalore, S.; Narayanan, S. Exploiting prosodic features for dialog act tagging in a discriminative modeling framework. In Proceedings of the Interspeech, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Adiani, D.; Itzkovitz, A.; Bian, D.; Katz, H.; Breen, M.; Hunt, S.; Swanson, A.; Vogus, T.J.; Wade, J.; Sarkar, N. Career Interview Readiness in Virtual Reality (CIRVR): A Platform for Simulated Interview Training for Autistic Individuals and Their Employers. ACM Trans. Access. Comput. 2022, 15, 1–28. [Google Scholar] [CrossRef]
- Jurafsky, D.; Shriberg, E.; Biasca, D. Switchboard SWBD-DAMSL Shallow-Discourse-Function Annotation Coders Manual, Draft 13. University of Colorado at Boulder &+ SRI International. 1997. Available online: https://www1.icsi.berkeley.edu/pubs/speech/tr-97-02.pdf (accessed on 4 April 2023).
- Chakravarty, S.; Chava, R.V.S.P.; Fox, E.A. Dialog Acts Classification for Question-Answer Corpora. In Proceedings of the Third Workshop on Automated Semantic Analysis of Information in Legal Text (ASAIL@ICAIL), Montreal, QC, Canada, 17–21 June 2019; Available online: https://ceur-ws.org/Vol-2385/paper6.pdf (accessed on 4 April 2023).
- Sadohara, K.; Kojima, H.; Narita, T.; Nihei, M.; Kamata, M.; Onaka, S.; Fujita, Y.; Inoue, T. Sub-Lexical Dialogue Act Classification in a Spoken Dialogue System Support for the Elderly with Cognitive Disabilities. In Proceedings of the Fourth Workshop on Speech and Language Processing for Assistive Technologies, Grenoble, France, 21–22 August 2013; pp. 93–98. [Google Scholar]
- Fernandez, R.; Picard, R.W. Dialog act classification from prosodic features using support vector machines. In Proceedings of the Speech Prosody 2002, Aix-en-Provence, France, 11–13 April 2002; pp. 291–294. [Google Scholar]
- Surendran, D.; Levow, G.A. Dialog act tagging with support vector machines and hidden Markov models. In Proceedings of the 2006 Interspeech, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Grau, S.; Sanchis, E.; Castro, M.J.; Vilar, D. Dialogue act classification using a Bayesian approach. In Proceedings of the 9th Conference Speech and Computer, St. Petersburg, Russia, 20–22 September 2004. [Google Scholar]
- Keizer, S.; Akker, R.O.D. Dialogue act recognition under uncertainty using Bayesian networks. Nat. Lang. Eng. 2007, 13, 287–316. [Google Scholar] [CrossRef]
- Moldovan, C.; Rus, V.; Graesser, A.C. Automated Speech Act Classification For Online Chat. In Proceedings of the Midwest Artificial Intelligence and Cognitive Science Conference, Cincinnati, OH, USA, 16–17 April 2011. [Google Scholar]
- Fiel, M. Machine learning techniques in dialogue act recognition. Eest. Raken. Uhingu Aastaraam. 2007, 3, 117–134. [Google Scholar] [CrossRef]
- Raheja, V.; Tetreault, J. Dialogue Act Classification with Context-Aware Self-Attention. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 3727–3733. [Google Scholar] [CrossRef]
- The Switchboard Dialog Act Corpus. Available online: https://compprag.christopherpotts.net/swda.html (accessed on 4 April 2023).
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Bozinovski, S. Reminder of the First Paper on Transfer Learning in Neural Networks, 1976. Informatica 2020, 44, 291–302. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for 586 Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Duran, N.; Battle, S.; Smith, J. Sentence encoding for Dialogue Act classification. Nat. Lang. Eng. 2023, 29, 794–823. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Noble, B.; Maraev, V. Large-scale text pre-training helps with dialogue act recognition, but not without fine-tuning. In Proceedings of the 14th International Conference on Computational Semantics (IWCS), Groningen, The Netherlands, 14–18 June 2021; pp. 166–172. [Google Scholar]
- Wu, C.; Hoi, S.C.H.; Socher, R.; Xiong, C. ToD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogues. arXiv 2020, arXiv:2004.06871. [Google Scholar]
- Microsoft Azure|Speech-to-Text Documentation. Available online: https://learn.microsoft.com/en-us/azure/cognitive-services/speech-service/index-speech-to-text (accessed on 13 January 2023).
- Xu, B.; Tao, C.; Feng, Z.; Raqui, Y.; Ranwez, S. A Benchmarking on Cloud based Speech-To-Text Services for French Speech and Background Noise Effect. In Proceedings of the 6th National Conference on Practical Applications of Artificial Intelligence, Bordeaux, France; 2021. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune bert for text classification? In Proceedings of the Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; pp. 194–206. [Google Scholar]
- Kim, S.N.; Cavedon, L.; Baldwin, T. Classifying dialogue acts in one-on-one live chats. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 862–871. [Google Scholar]
- Webb, G. Overfitting. In Encyclopedia of Machine Learning and Data Mining; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2017; pp. 947–948. [Google Scholar] [CrossRef]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A Survey of Predictive Modeling on Imbalanced Domains. ACM Comput. Surv. 2016, 49, 1–50. [Google Scholar] [CrossRef]
- Li, D.; Hasanaj, E.; Li, S. 3-Baselines. 2010. Available online: https://blog.ml.cmu.edu/2020/08/31/3-baselines/ (accessed on 13 January 2023).
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Cham, Switzerland, 2016; pp. 207–235. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Schabus, D.; Krenn, B.; Neubarth, F. Data-Driven Identification of Dialogue Acts in Chat Messages. In Proceedings of the Conference on Natural Language Processing, Bochum, Germany, 19–21 September 2016. [Google Scholar]
- Malik, U.; Barange, M.; Saunier, J.; Pauchet, A. Performance comparison of machine learning models trained on manual vs ASR transcriptions for dialogue act annotation. In Proceedings of the 2018 IEEE 30th International Conference on Tools with Artificial Intelligence (ICTAI), Volos, Greece, 5–7 November 2018; pp. 1013–1017. [Google Scholar]
- Dantas, J. The Importance of k-Fold Cross-Validation for Model Prediction in Machine Learning. Towards Data Science. 2020. Available online: https://towardsdatascience.com/the-importance-of-k-fold-cross-validation-for-model-prediction-in-machine-learning-4709d3fed2ef (accessed on 4 April 2023).
- KFold. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html (accessed on 4 April 2023).
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Label Encoder. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html (accessed on 4 April 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Randomized Search Cross Validation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RandomizedSearchCV.html (accessed on 4 April 2023).
- Sreenivasa, S. Radial Basis Function (RBF) Kernel: The Go-To Kernel. 2020. Available online: https://towardsdatascience.com/radial-basis-function-rbf-kernel-the-go-to-kernel-acf0d22c798a (accessed on 4 April 2023).
- Hugging Face Transformers. Available online: https://huggingface.co/docs/transformers/index (accessed on 4 April 2023).
- Fast Tokenizer. Available online: https://huggingface.co/learn/nlp-course/chapter6/3 (accessed on 4 April 2023).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Jurafsky, D.; Shriberg, E.; Fox, B.; Curl, T. Lexical, prosodic, and syntactic cues for dialog acts. In Discourse Relations and Discourse Markers; Association for Computational Lingustics (ACL): Montreal, QC, Canada, 1998. [Google Scholar]
- Shushma, G.; Jacob, I.J. A Semantic Approach for Computing Speech Emotion Text Classification Using Machine Learning Algorithms. In Proceedings of the 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT), Trichy, India, 16–18 February 2022; pp. 1–5. [Google Scholar]
- Hendr, A.; Ozgunalp, U.; Erbilek Kaya, M. Diagnosis of Autism Spectrum Disorder Using Convolutional Neural Networks. Electronics 2023, 12, 612. [Google Scholar] [CrossRef]
- Wu, T.W.; Su, R.; Juang, B.H. A Context-Aware Hierarchical BERT Fusion Network for Multi-turn Dialog Act Detection. In Proceedings of the 2021 Interspeech, Brno, Czechia, 30 August–3 September 2021. [Google Scholar]
- Wu, T.W.; Juang, B.H. Knowledge Augmented Bert Mutual Network in Multi-Turn Spoken Dialogues. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7487–7491. [Google Scholar]
- Peng, W.; Hu, Y.; Xing, L.; Xie, Y.; Zhang, X.; Sun, Y. Modeling intention, emotion and external world in dialogue systems. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7042–7046. [Google Scholar]
- Hugging Face Training Arguments. Available online: https://huggingface.co/docs/transformers/v4.28.1/en/main_classes/trainer#transformers.TrainingArguments (accessed on 4 April 2023).
- BERT HyperParameter Tuning. Available online: https://huggingface.co/docs/transformers/hpo_train (accessed on 4 April 2023).
- Data Collator. Available online: https://huggingface.co/docs/transformers/main_classes/data_collator3 (accessed on 4 April 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dialogue Act | Description | Example |
|---|---|---|
| wh | Wh-questions, which generally start with “who”, “what”, “where”, “when”, “why”, “how”, etc. | What is your name? |
| wh-d | Wh-declarative questions, when there is more than one statement in a wh-*question. | You said math is your favorite subject. What kind of grades did you get in Math? |
| bin | Binary question, which can be answered with a “yes” or “no”. | Does that sound good? |
| bin-d | Binary-declarative question, which can also be answered with a “yes” or “no”, but has an explanation or a statement before it. | Before getting into some technical questions about the position, tell me, do you have any prior work experience? |
| qo | Open question or general questions, not specific to any context, to know the options of the person who is answering. | How do you feel this interview is going? |
| or | Choice question, made of two parts connected by conjunction “or”. | Do you have any experience with spreadsheet software such as Microsoft Excel or Google Spreadsheets? |
| Dialogue Act | Description | Example |
|---|---|---|
| y | Variations of “yes” answers. | “yes”, “yeah”, “of course”, “definitely is”, “that’s right”, “I am sure”, etc. |
| y-d | Yes-answer with an explanation. | Yes. I have experience with Excel. |
| n | Variations of “no” answers. | “No, I don’t think so”, “certainly not”, “I am afraid not”, “not really”, “I don’t have experience…”, “we don’t”, etc. |
| n-d | No-answer with an explanation. | “User didn’t respond”, “I…”. |
| xx | Uninterpretable responses or any responses which look incomplete, such as one word and the user stopped talking. | How do you feel this interview is going? |
| sno | Non-opinionated statements. | I started working on a project the other day. |
| so | Opinionated statements. | Anything which starts with “I think”, “I believe”, “I feel”, etc. |
| ack | Acknowledgements. | “okay”, “uh-huh”, “I see”, etc. |
| dno | It is a response given when the person is unsure, doesn’t know, or doesn’t recall. | “I don’t know”, “maybe”, “I guess”, “I suppose”, etc. |
| query | Interviewee-initiated question. | What is the work environment like? |
| ft | Thank yous | “thanks”, “thank you” |
| fa | Apologies. | “I’m sorry” |
| fe | Exclamations. | “shoot”, “oh goodness”, “jeez”, etc. |
| fp | Greetings or conventional openings. | “hello”, “nice to meet you” |
| Dialogue Act | No. of Samples | Percentage Distribution (%) |
|---|---|---|
| y | 50 | |
| y-d | 17 | |
| n | 49 | |
| n-d | 10 | |
| sno | 381 | |
| so | 30 | |
| ack | 13 | |
| dno | 44 | |
| query | 34 | |
| ft | 3 | |
| fa | 1 | |
| fe | 2 | |
| fp | 6 |
| Labels | Split 0 | Split 1 | Split 2 | Split 3 | Split 4 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train0 | Test0 | Train1 | Test1 | Train2 | Test2 | Train3 | Test3 | Train4 | Test4 | |
| y | 42 | 8 | 42 | 8 | 40 | 10 | 36 | 14 | 40 | 10 |
| y-d | 12 | 5 | 12 | 5 | 15 | 2 | 13 | 4 | 16 | 1 |
| n | 36 | 13 | 39 | 10 | 40 | 9 | 42 | 7 | 39 | 10 |
| n-d | 8 | 2 | 8 | 2 | 9 | 1 | 7 | 3 | 8 | 2 |
| sno | 298 | 83 | 300 | 81 | 308 | 73 | 306 | 75 | 312 | 69 |
| so | 25 | 5 | 24 | 6 | 26 | 4 | 23 | 7 | 22 | 8 |
| ack | 10 | 3 | 12 | 1 | 12 | 1 | 8 | 5 | 10 | 3 |
| dno | 39 | 5 | 38 | 6 | 30 | 14 | 35 | 9 | 34 | 10 |
| query | 30 | 4 | 29 | 5 | 27 | 7 | 24 | 10 | 26 | 8 |
| ft | 31 | 10 | 35 | 6 | 33 | 8 | 33 | 8 | 32 | 9 |
| fa | 36 | 6 | 32 | 10 | 30 | 12 | 37 | 5 | 33 | 9 |
| fe | 40 | 13 | 42 | 11 | 42 | 11 | 45 | 8 | 43 | 10 |
| fp | 54 | 9 | 48 | 15 | 50 | 13 | 53 | 10 | 47 | 16 |
| SVM a | RF a | BERT b | |||
|---|---|---|---|---|---|
| Hyperparameter | Range of Values | Hyperparameter | Range of Values | Hyperparameter | Range of Values |
| C | 10–100 | max_depth | 10–110, None | batch_size | 8, 16, 32 |
| kernel | radial basis function (rbf) [77], linear | max_features | ‘auto’, ‘sqrt’ | learning_rate | , , |
| min_samples_leaf | 1, 2, 4 | epochs | 20, 30, 40 | ||
| min_samples_split | 1–10 | ||||
| n_estimators | 10–190 | ||||
| bootstrap | True, False | ||||
| Dataset | SVM Baseline | RF Baseline | Fine-Tuned BERT | |||
|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| Split 0 | 0.86 | 0.71 | 0.81 | 0.61 | 0.87 | 0.77 |
| Split 1 | 0.84 | 0.63 | 0.79 | 0.58 | 0.84 | 0.70 |
| Split 2 | 0.85 | 0.72 | 0.84 | 0.74 | 0.92 | 0.87 |
| Split 3 | 0.76 | 0.61 | 0.73 | 0.53 | 0.87 | 0.81 |
| Split 4 | 0.79 | 0.61 | 0.76 | 0.56 | 0.85 | 0.77 |
| Mean | 0.82 | 0.65 | 0.78 | 0.60 | 0.87 | 0.78 |
| Standard Deviation (SD) | 0.04 | 0.05 | 0.04 | 0.07 | 0.03 | 0.06 |
| Dialogue Act | SVM Baseline | RF Baseline | Fine-Tuned BERT |
|---|---|---|---|
| Accuracy = 0.85 | Accuracy = 0.84 | Accuracy = 0.92 | |
| F1-Score = 0.72 | F1-Score = 0.74 | F1-Score = 0.87 | |
| y | 0.75 | 0.75 | 0.84 |
| y-d | 0.00 | 0.50 | 0.80 |
| n | 0.94 | 0.88 | 0.88 |
| n-d | 0.00 | 0.00 | 1.00 |
| sno | 0.87 | 0.86 | 0.94 |
| so | 0.57 | 0.67 | 0.67 |
| ack | 1.00 | 1.00 | 0.67 |
| dno | 0.83 | 0.83 | 0.88 |
| query | 0.86 | 0.80 | 0.86 |
| ft | 0.94 | 0.88 | 0.94 |
| fa | 0.91 | 0.91 | 1.00 |
| fe | 0.84 | 0.84 | 0.95 |
| fp | 0.81 | 0.73 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adiani, D.; Colopietro, K.; Wade, J.; Migovich, M.; Vogus, T.J.; Sarkar, N. Dialogue Act Classification via Transfer Learning for Automated Labeling of Interviewee Responses in Virtual Reality Job Interview Training Platforms for Autistic Individuals. Signals 2023, 4, 359-380. https://doi.org/10.3390/signals4020019
Adiani D, Colopietro K, Wade J, Migovich M, Vogus TJ, Sarkar N. Dialogue Act Classification via Transfer Learning for Automated Labeling of Interviewee Responses in Virtual Reality Job Interview Training Platforms for Autistic Individuals. Signals. 2023; 4(2):359-380. https://doi.org/10.3390/signals4020019
Chicago/Turabian StyleAdiani, Deeksha, Kelley Colopietro, Joshua Wade, Miroslava Migovich, Timothy J. Vogus, and Nilanjan Sarkar. 2023. "Dialogue Act Classification via Transfer Learning for Automated Labeling of Interviewee Responses in Virtual Reality Job Interview Training Platforms for Autistic Individuals" Signals 4, no. 2: 359-380. https://doi.org/10.3390/signals4020019
APA StyleAdiani, D., Colopietro, K., Wade, J., Migovich, M., Vogus, T. J., & Sarkar, N. (2023). Dialogue Act Classification via Transfer Learning for Automated Labeling of Interviewee Responses in Virtual Reality Job Interview Training Platforms for Autistic Individuals. Signals, 4(2), 359-380. https://doi.org/10.3390/signals4020019