
Spatiotemporal Prediction of Theft Risk with Deep Inception-Residual Networks



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
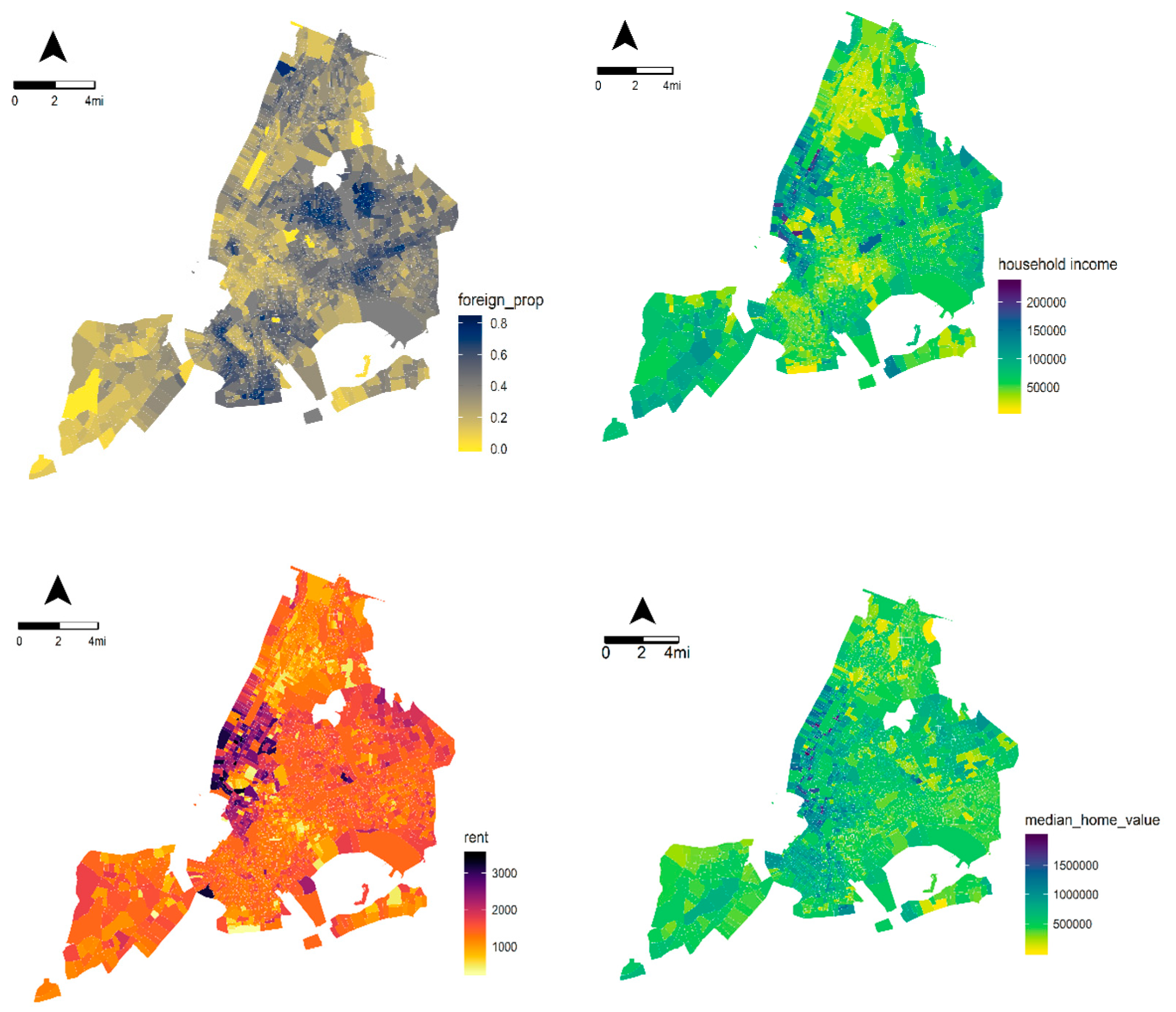
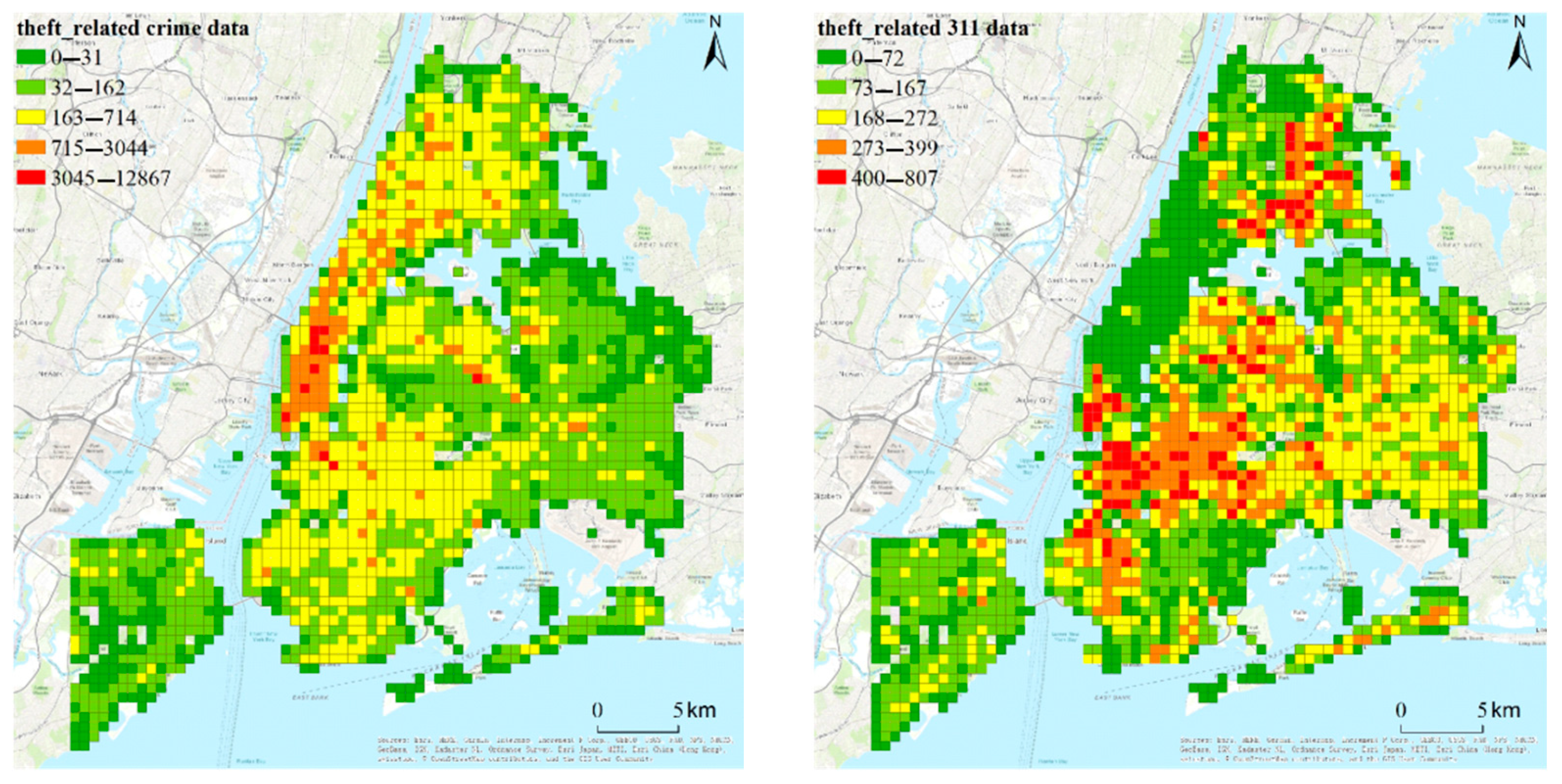
3. Research Context and the Datasets
4. Methods
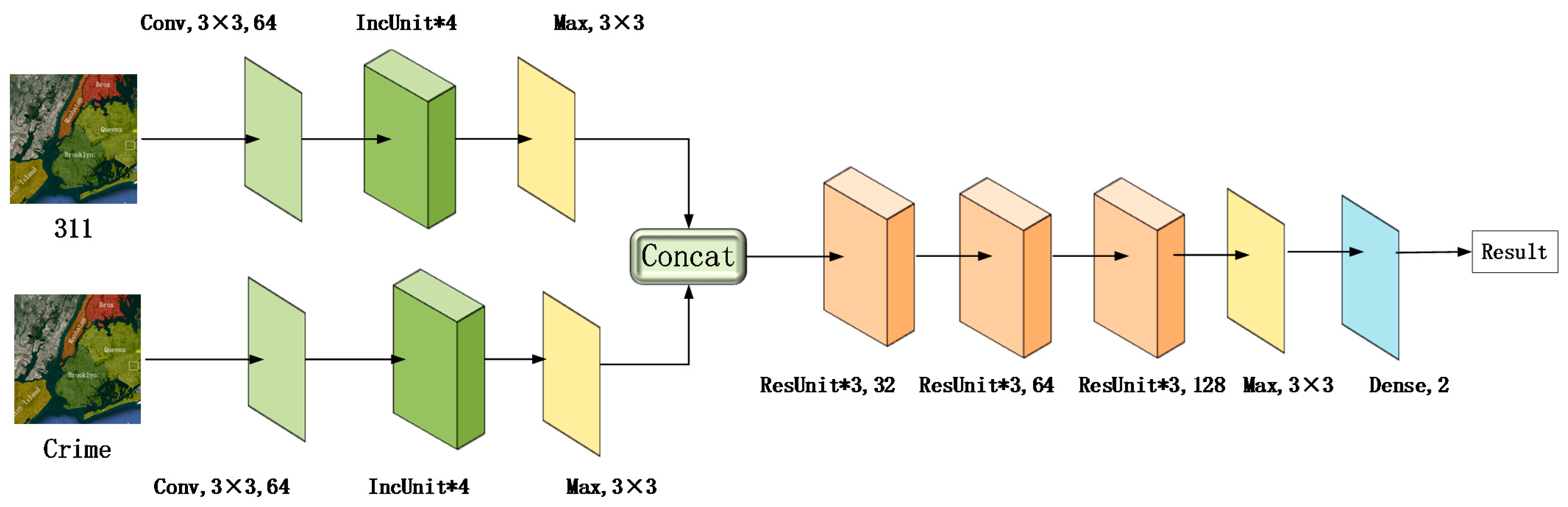
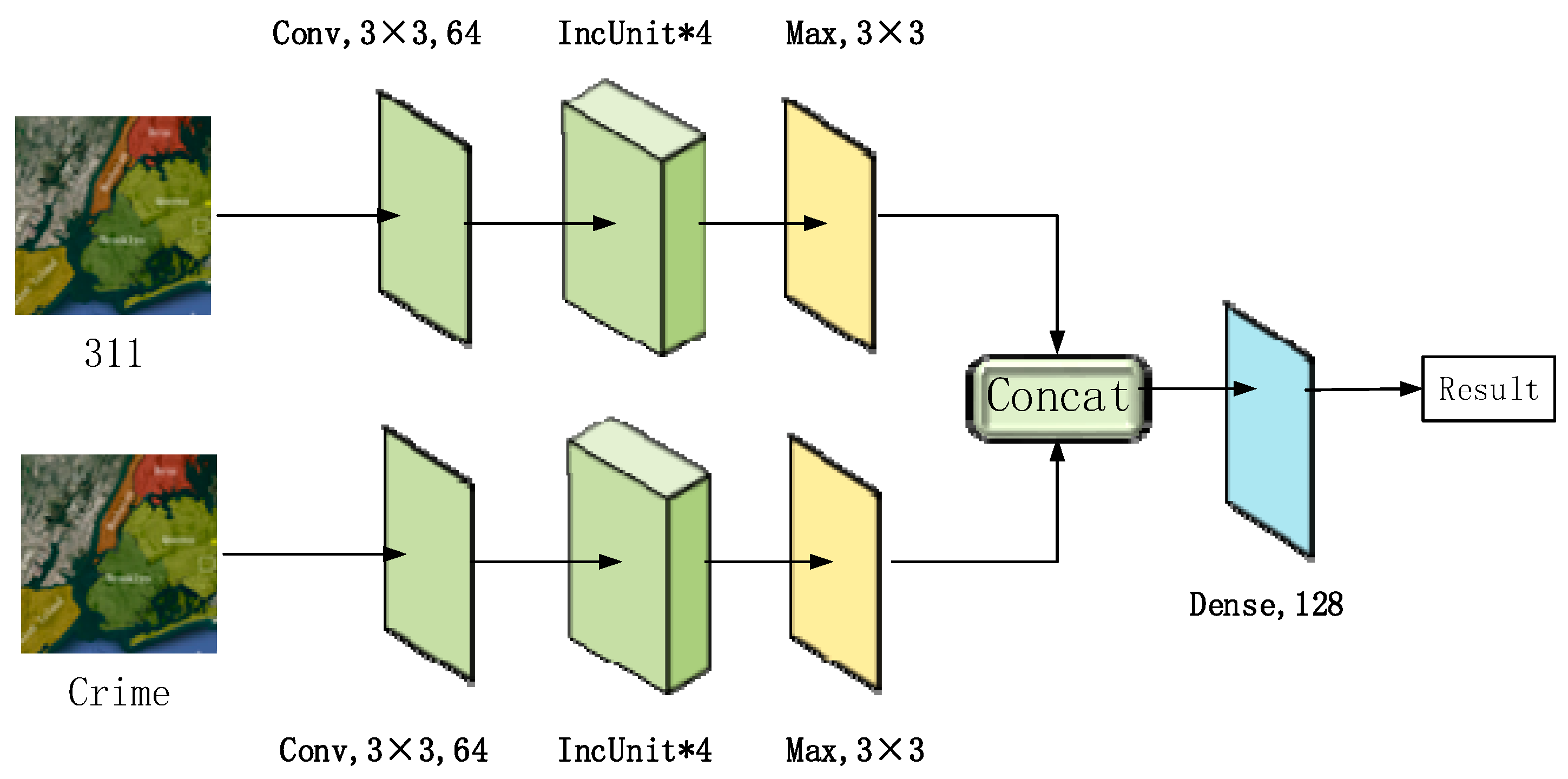
4.1. DIRNet
Architecture
4.2. Spatiotemporal Dependencies Represented in Convolutions
4.2.1. Convolution Layer
4.2.2. Pooling Layer
4.2.3. Concat Layer
4.2.4. Dense Layer
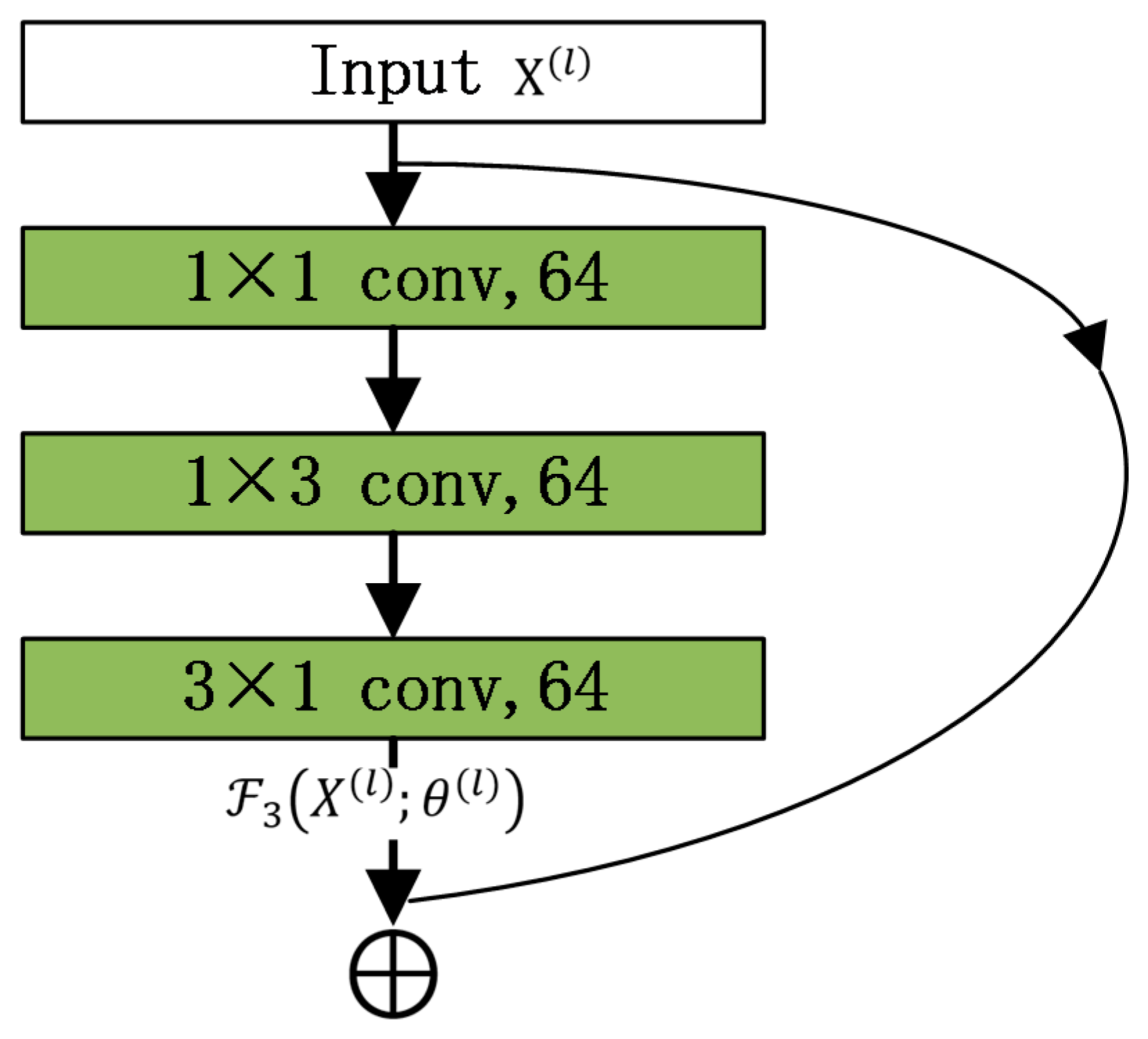
4.2.5. Inception Unit and Residual Unit
5. Experiments and Results
5.1. Experimental Setup
5.2. Evaluation Metrics for Machine Learning
5.3. Baseline Machine-Learning Models
- Support vector machines (SVMs) [20]: Following the literature, we ran SVMs using the Gaussian radial basis function(RBF) kernel to map the original features to a high-dimensional feature space.
- STCN: Spatiotemporal crime network (STCN) applies inception networks and fractal networks simultaneously to forecast crime risks. The parameters of STCN implemented in this case are the same as the best model described in Duan et al. [23].
5.4. Performance Comparison
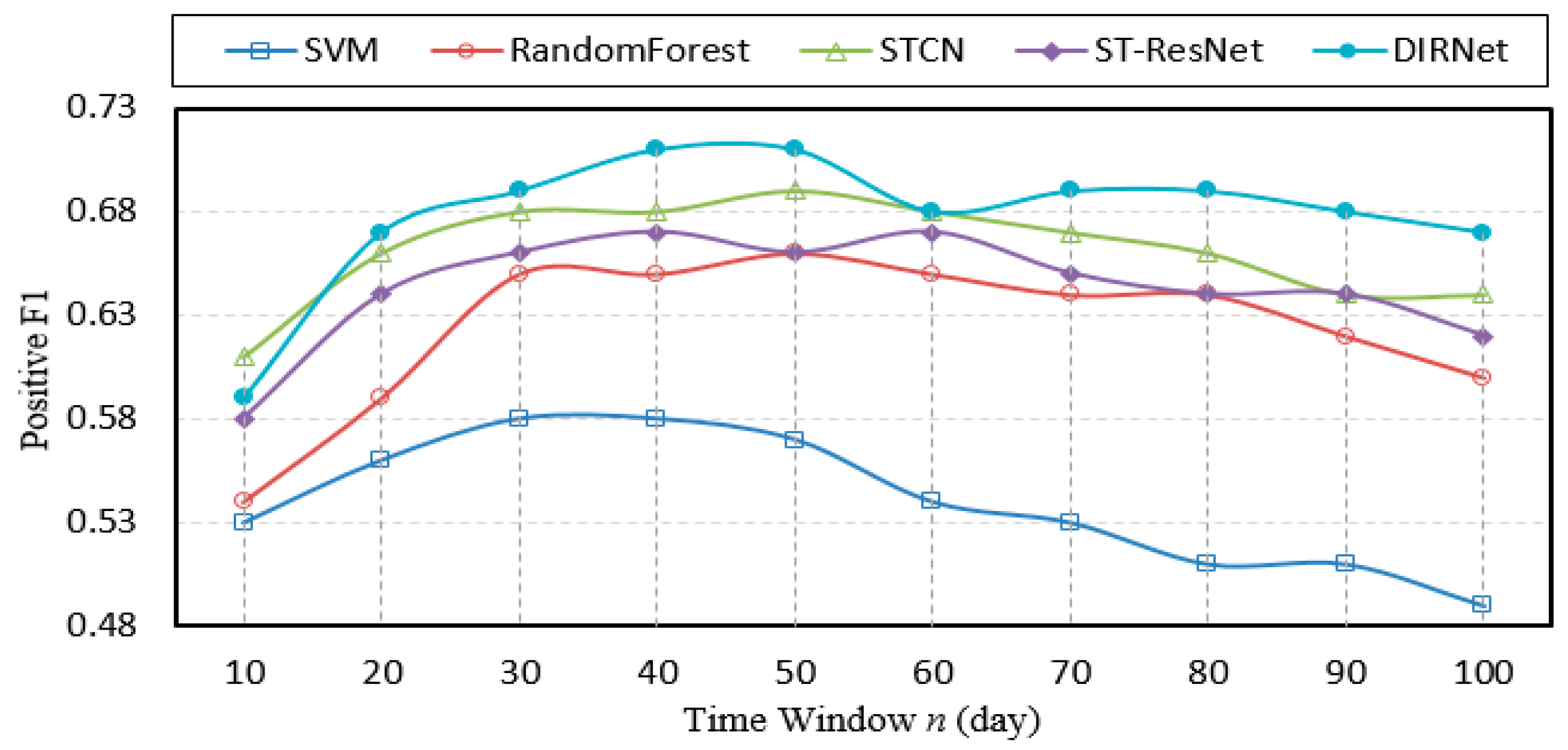
5.4.1. Comparative Performance Studies on Time Window N
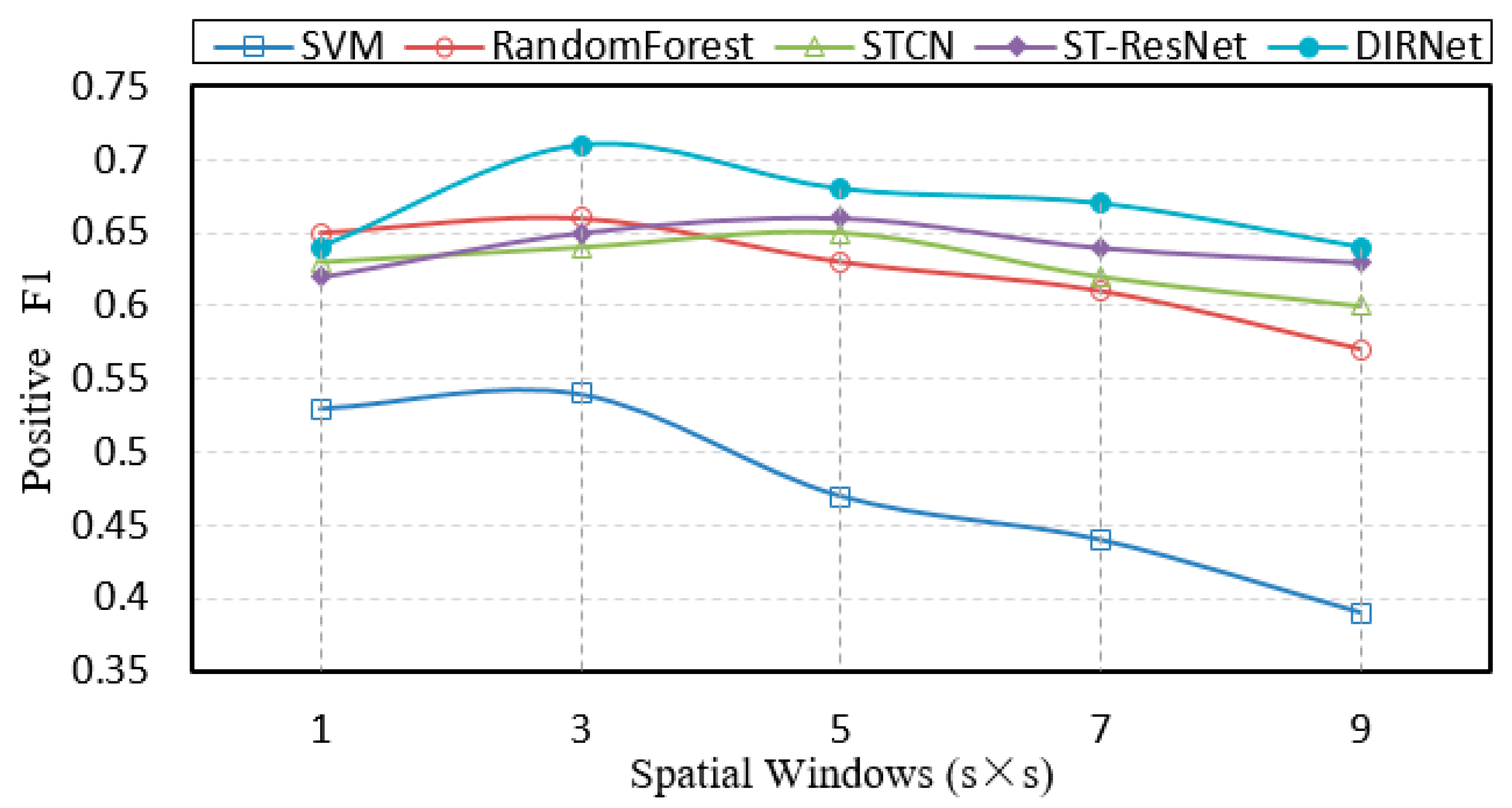
5.4.2. Comparative Performance Studies on Spatial Ranges
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Neirotti, P.; De Marco, A.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current trends in Smart City initiatives: Some stylised facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Butt, U.M.; Letchmunan, S.; Hassan, F.H.; Ali, M.; Baqir, A.; Sherazi, H.H.R. Spatio-Temporal Crime HotSpot Detection and Prediction: A Systematic Literature Review. IEEE Access 2020, 8, 166553–166574. [Google Scholar] [CrossRef]
- Hossain, S.; Abtahee, A.; Kashem, I.; Hoque, M.M.; Sarker, I.H. Crime Prediction Using Spatio-Temporal Data. arXiv 2020, arXiv:2003.09322. preprint. [Google Scholar]
- Kang, W.H.; Kang, H.-B. Prediction of crime occurrence from multi-modal data using deep learning. PLoS ONE 2017, 12, e0176244. [Google Scholar] [CrossRef]
- Chainey, S. The Crime Prediction Framework—A Spatial Temporal Framework for Targeting Patrols, Crime Prevention and Strategic Policy. In Proceedings of the National Security Summit, San Diego, CA, USA, 18 July 2015. [Google Scholar]
- Bannister, J.; O’Sullivan, A.; Bates, E. Place and time in the Criminology of Place. Theor. Criminol. 2017, 23, 315–332. [Google Scholar] [CrossRef]
- Kalantari, M.; Yaghmaei, B.; Ghezelbash, S. Spatio-temporal analysis of crime by developing a method to detect critical distances for the Knox test. Int. J. Geogr. Inf. Sci. 2016, 30, 2302–2320. [Google Scholar] [CrossRef]
- Duan, L.; Ye, X.; Hu, T.; Zhu, X. Prediction of Suspect Location Based on Spatiotemporal Semantics. ISPRS Int. J. Geo-Inf. 2017, 6, 185. [Google Scholar] [CrossRef] [Green Version]
- Rosser, G.; Davies, T.; Bowers, K.J.; Johnson, S.D.; Cheng, T. Predictive Crime Mapping: Arbitrary Grids or Street Networks? J. Quant. Criminol. 2017, 33, 569–594. [Google Scholar] [CrossRef] [Green Version]
- Adepeju, M.; Rosser, G.; Cheng, T. Novel evaluation metrics for sparse spatio-temporal point process hotspot predictions - a crime case study. Int. J. Geogr. Inf. Sci. 2016, 30, 2133–2154. [Google Scholar] [CrossRef]
- Wells, W.; Wu, L.; Ye, X. Patterns of Near-Repeat Gun Assaults in Houston. J. Res. Crime Delinq. 2011, 49, 186–212. [Google Scholar] [CrossRef]
- Caplan, J.M.; Kennedy, L.W.; Miller, J. Risk Terrain Modeling: Brokering Criminological Theory and GIS Methods for Crime Forecasting. Justice Q. 2011, 28, 360–381. [Google Scholar] [CrossRef]
- Law, J.; Quick, M.; Chan, P. Bayesian Spatio-Temporal Modeling for Analysing Local Patterns of Crime Over Time at the Small-Area Level. J. Quant. Criminol. 2013, 30, 57–78. [Google Scholar] [CrossRef]
- Kadar, C.; Iria, J.; Cvijikj, I.P. Exploring Foursquare-derived Features for Crime Prediction in New York City. In Proceedings of the 5th International Workshop on Urban Computing (UrbComp 2016), San Francisco, CA, USA, 14 August 2016. [Google Scholar]
- Gerber, M.S. Predicting crime using Twitter and kernel density estimation. Decis. Support Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Chohlas-Wood, A.; Merali, A.; Reed, W.; Damoulas, T. Mining 911 Calls in New York City: Temporal Patterns, Detection, and Forecasting. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Wang, H.; Kifer, D.; Graif, C.; Li, Z. Crime Rate Inference with Big Data. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 635–644. [Google Scholar]
- Iqbal, R. An Experimental Study of Classification Algorithms for Crime Prediction. Indian J. Sci. Technol. 2013, 6, 1–7. [Google Scholar] [CrossRef]
- Wang, X.; Brown, D.E. The spatio-temporal modeling for criminal incidents. Secur. Inf. 2012, 1, 2. [Google Scholar] [CrossRef] [Green Version]
- Chandrasekar, A.; Raj, A.S.; Kumar, P. Crime Prediction and Classification in San Francisco City. Available online: http://cs229.stanford.edu/proj2015/228{\_}report.pdf (accessed on 24 December 2020).
- Chun, S.A.; Paturu, V.A.; Yuan, S.; Pathak, R.; Atluri, V.; Adam, N.R. Crime Prediction Model using Deep Neural Networks. In Proceedings of the 20th Annual International Conference on Digital Government Research, Dubai, UAE, 18–20 June 2019; pp. 512–514. [Google Scholar]
- Wang, B.; Zhang, D.; Zhang, D.; Brantingham, J.P.; Bertozzi, L.A. Deep learning for real time crime forecasting. arXiv 2017, arXiv:1707.03340. preprint. [Google Scholar]
- Duan, L.; Hu, T.; Cheng, E.; Zhu, J.; Gao, C. Deep Convolutional Neural Networks for Spatiotemporal Crime Prediction. In Proceedings of the International Conference on Information and Knowledge Engineering (IKE); CSREA Press: Las Vegas, NV, USA, 2017; The Steering Committee of the World Congress in Computer Science, Computer. [Google Scholar]
- Hipp, J.R. Income inequality, race and place: Does the distribution of race and class within neighborhoods affect crime rates? Criminology 2007, 45, 665–697. [Google Scholar] [CrossRef] [Green Version]
- Wilson, Q.J.; Kelling, G.L. Broken windows. Atl. Mon. 1982, 249, 29–38. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Pinheiro, P.; Collobert, R. Recurrent Convolutional Neural Networks for Scene Labeling. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Zheng, Y. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. arXiv 2016, arXiv:1610.00081. preprint. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Ganganwar, V. An overview of classification algorithms for imbalanced datasets. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 42–47. [Google Scholar]
- Pagani, A.; Mehrotra, A.; Musolesi, M. Graph input representations for machine learning applications in urban network analysis. Environ. Plan. B: Urban Anal. City Sci. 2019. [Google Scholar] [CrossRef] [Green Version]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, X.; Duan, L.; Peng, Q. Spatiotemporal Prediction of Theft Risk with Deep Inception-Residual Networks. Smart Cities 2021, 4, 204-216. https://doi.org/10.3390/smartcities4010013
Ye X, Duan L, Peng Q. Spatiotemporal Prediction of Theft Risk with Deep Inception-Residual Networks. Smart Cities. 2021; 4(1):204-216. https://doi.org/10.3390/smartcities4010013
Chicago/Turabian StyleYe, Xinyue, Lian Duan, and Qiong Peng. 2021. "Spatiotemporal Prediction of Theft Risk with Deep Inception-Residual Networks" Smart Cities 4, no. 1: 204-216. https://doi.org/10.3390/smartcities4010013
APA StyleYe, X., Duan, L., & Peng, Q. (2021). Spatiotemporal Prediction of Theft Risk with Deep Inception-Residual Networks. Smart Cities, 4(1), 204-216. https://doi.org/10.3390/smartcities4010013