Optimization of Signal Detection Using Deep CNN in Ultra-Massive MIMO


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We foresee greater complexity with the larger number of antennas. The application of deep learning to signal detection contributes to improved performance and reduced complexity, rather than using more complex channel estimation methods.
- We developed a modeling framework for detailed learning and simultaneous regression, incorporating real and imaginary components of complex matrices into the input layers of artificial neural networks to minimize potential errors. This approach allows us to reduce the system’s overall complexity and enhance its efficiency.
2. Materials and Methods
2.1. Fundamentals System Models
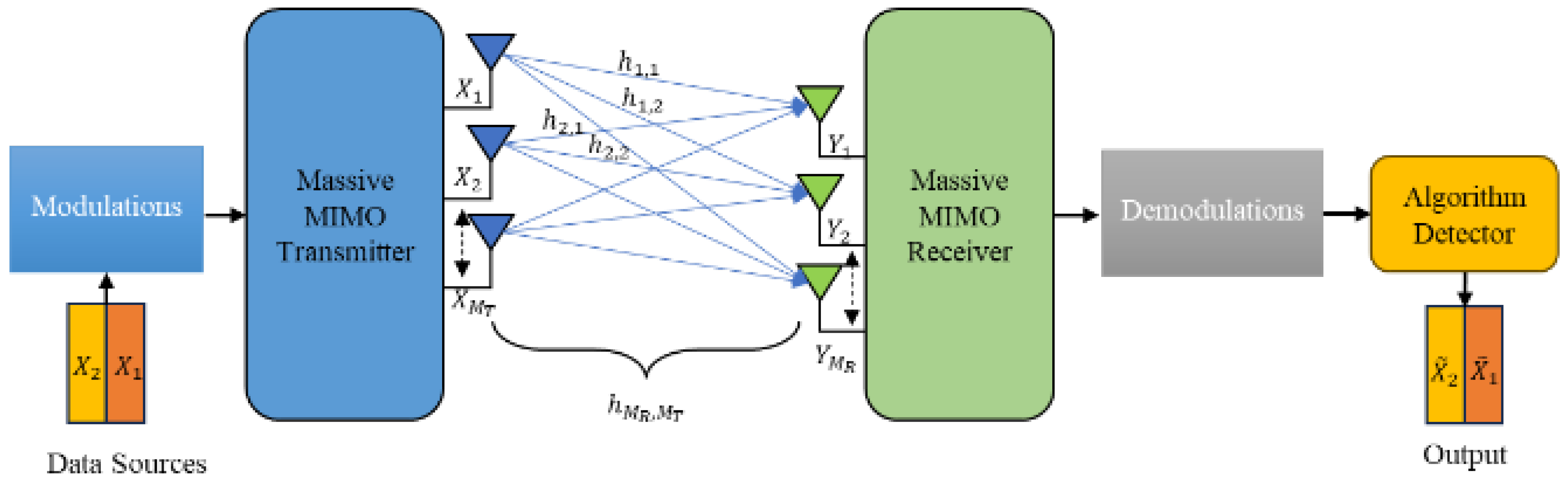
2.1.1. Massive MIMO
2.1.2. Ultra-Massive MIMO
2.2. Traditional Method
2.2.1. Zero Forcing Detector
2.2.2. MMSE Signal Detector
2.3. Machine Learning Method
2.3.1. Extreme Learning Machine (ELM)
2.3.2. Regularized Extreme Learning Machine (RELM)
2.3.3. Outlier-Robust Extreme Learning Machine (ORELM)
| Algorithm 1 ELM, RELM and ORELM algorithm. |
|
2.4. Proposed Method
Architecture of The Proposed Convolutional Neural Network for Signal Detection (CNN-SD)
| Algorithm 2 CNN-SD algorithm. |
|
2.5. Channel Capacity
2.6. Outage Probability
2.7. Total Loss of Algorithm
2.7.1. Mean Square Error (MSE)
2.7.2. Training Loss
2.7.3. Validation Loss
3. Result and Discussion
3.1. Dataset Setup
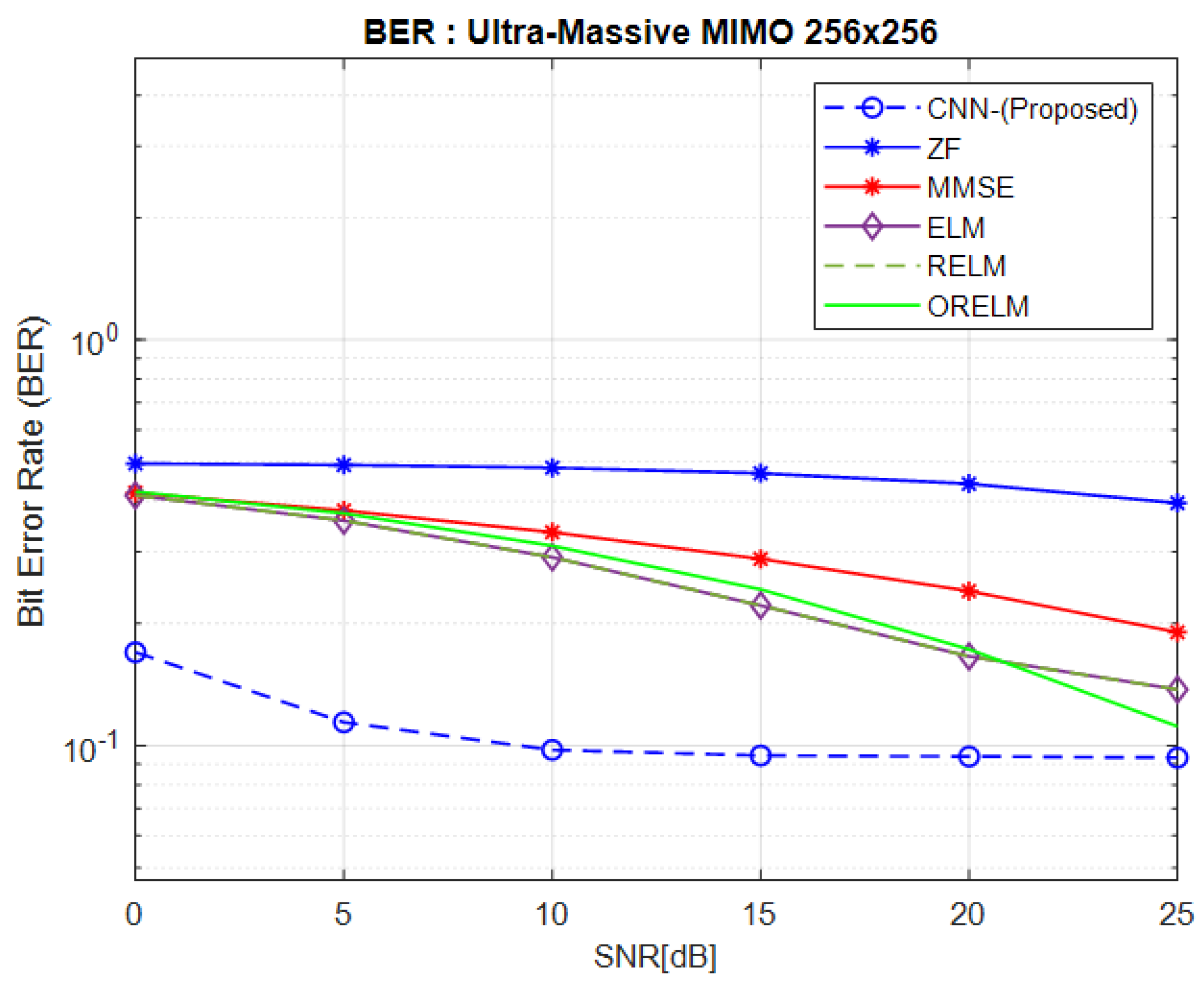
3.2. MSE and BER
3.3. Model Validation
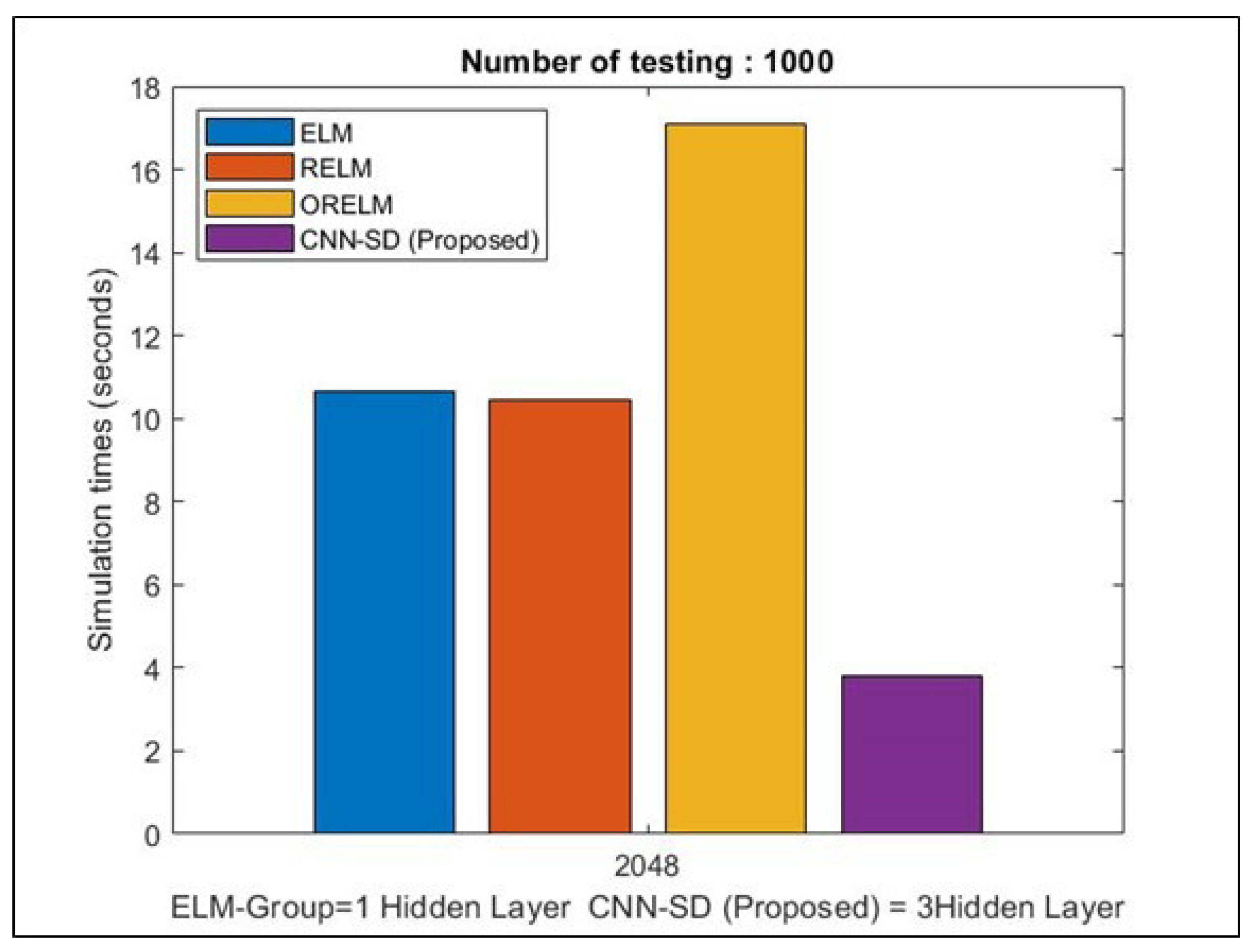
3.4. Computational Time
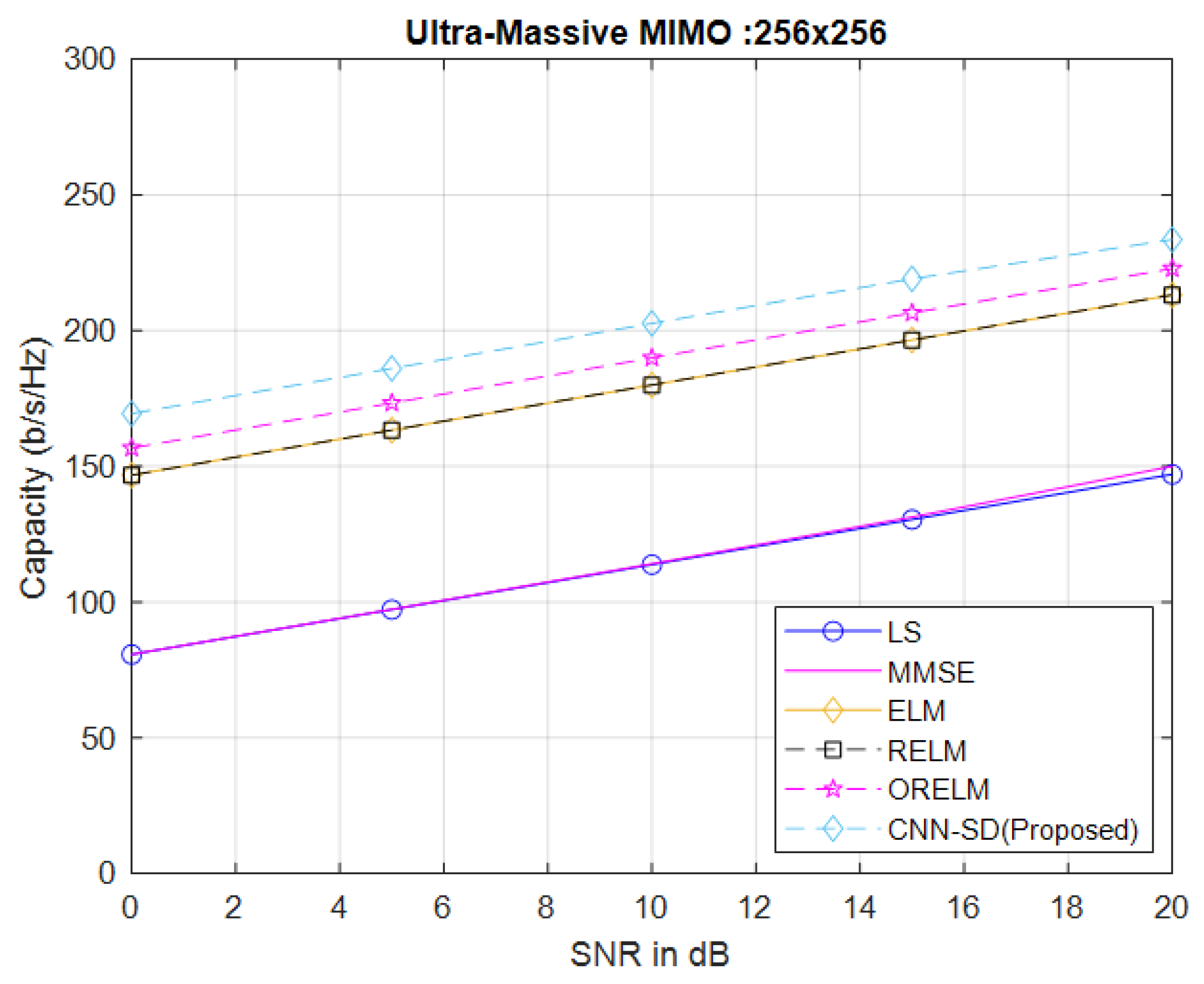
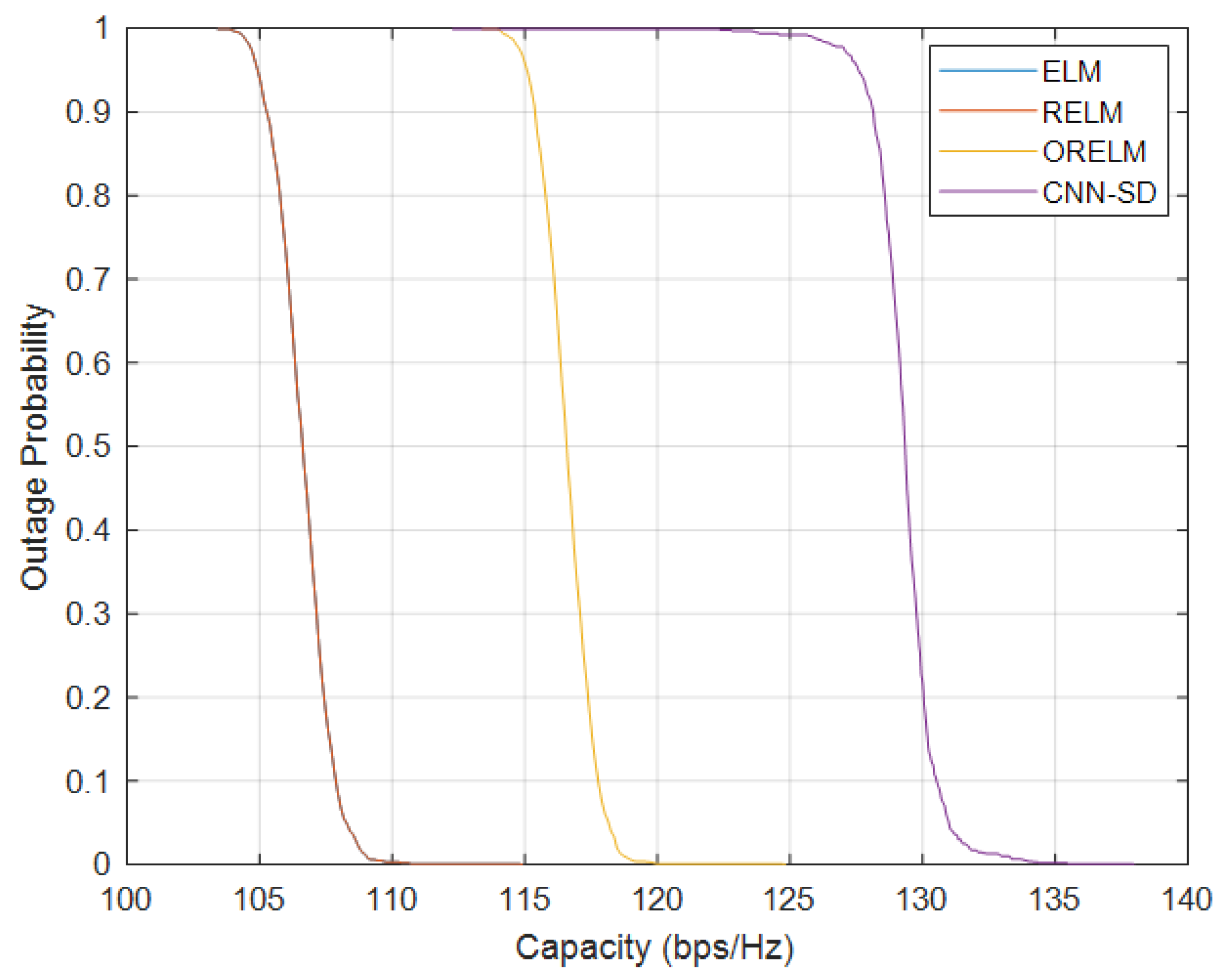
3.5. Channel Capacity and Outage Probability
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huo, Y.; Lin, X.; Di, B.; Zhang, H.; Hernando, F.J.L.; Tan, A.S.; Mumtaz, S.; Demir, Ö.T.; Chen-Hu, K. Technology Trends for Massive MIMO towards 6G. arXiv 2023, arXiv:2301.01703. [Google Scholar]
- Wang, X.; Kong, L.; Kong, F.; Qiu, F.; Xia, M.; Arnon, S.; Chen, G. Millimeter wave communication: A comprehensive survey. IEEE Commun. Surv. Tutor. 2018, 20, 1616–1653. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, C.X.; Yang, R.; Yu, L.; Lai, F.; Huang, J.; Feng, R.; Wang, C.; Li, C.; Zhong, Z. Ultra-massive MIMO channel measurements at 5.3 GHz and a general 6G channel model. IEEE Trans. Veh. Technol. 2022, 72, 20–34. [Google Scholar] [CrossRef]
- Dilli, R.; Chandra, R.; Jordhana, D. Ultra-Massive MIMO Technologies for 6G Wireless Networks. Eng. Sci. 2021, 16, 308–318. [Google Scholar] [CrossRef]
- Wang, C.X.; Wang, J.; Hu, S.; Jiang, Z.H.; Tao, J.; Yan, F. Key Technologies in 6G Terahertz Wireless Communication Systems: A Survey. IEEE Veh. Technol. Mag. 2021, 16, 27–37. [Google Scholar] [CrossRef]
- Faisal, A.; Sarieddeen, H.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M.S. Ultramassive MIMO Systems at Terahertz Bands: Prospects and Challenges. IEEE Veh. Technol. Mag. 2020, 15, 33–42. [Google Scholar] [CrossRef]
- Murshed, R.U.; Ashraf, Z.B.; Hridhon, A.H.; Munasinghe, K.; Jamalipour, A.; Hossain, M.F. A CNN-LSTM-based Fusion Separation Deep Neural Network for 6G Ultra-Massive MIMO Hybrid Beamforming. IEEE Access 2023, 11, 38614–38630. [Google Scholar] [CrossRef]
- Sarieddeen, H.; Alouini, M.S.; Al-Naffouri, T.Y. Terahertz-Band Ultra-Massive Spatial Modulation MIMO. IEEE J. Sel. Areas Commun. 2019, 37, 2040–2052. [Google Scholar] [CrossRef]
- Lee, Y.; Sou, S.I. On improving gauss-seidel iteration for signal detection in uplink multiuser massive MIMO systems. In Proceedings of the 2018 3rd International Conference on Computer and Communication Systems (ICCCS), Nagoya, Japan, 27–30 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 268–272. [Google Scholar]
- Jiang, Y.; Varanasi, M.K.; Li, J. Performance analysis of ZF and MMSE equalizers for MIMO systems: An in-depth study of the high SNR regime. IEEE Trans. Inf. Theory 2011, 57, 2008–2026. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Chen, S.; Liang, Y.C.; Sun, S.; Kang, S.; Cheng, W.; Peng, M. Vision, requirements, and technology trend of 6G: How to tackle the challenges of system coverage, capacity, user data-rate and movement speed. IEEE Wirel. Commun. 2020, 27, 218–228. [Google Scholar] [CrossRef]
- Mai, Z.; Chen, Y.; Du, L. A Novel Blind mmWave Channel Estimation Algorithm Based on ML-ELM. IEEE Commun. Lett. 2021, 25, 1549–1553. [Google Scholar] [CrossRef]
- Keramidi, I.P.; Moscholios, I.D.; Sarigiannidis, P.G. Call Blocking Probabilities under a Probabilistic Bandwidth Reservation Policy in Mobile Hotspots. Telecom 2021, 2, 554–573. [Google Scholar] [CrossRef]
- Heath, R.W.; Gonzalez-Prelcic, N.; Rangan, S.; Roh, W.; Sayeed, A.M. An overview of signal processing techniques for millimeter wave MIMO systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 436–453. [Google Scholar] [CrossRef]
- Nguyen, V.L.; Lin, P.C.; Cheng, B.C.; Hwang, R.H.; Lin, Y.D. Security and privacy for 6G: A survey on prospective technologies and challenges. IEEE Commun. Surv. Tutor. 2021, 23, 2384–2428. [Google Scholar] [CrossRef]
- Gao, X.; Dai, L.; Yuen, C.; Zhang, Y. Low-complexity MMSE signal detection based on Richardson method for large-scale MIMO systems. In Proceedings of the 2014 IEEE 80th Vehicular Technology Conference (VTC2014-Fall), Vancouver, BC, Canada, 14–17 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–5. [Google Scholar]
- Nakai-Kasai, A.; Wadayama, T. MMSE signal detection for MIMO systems based on ordinary differential equation. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6176–6181. [Google Scholar]
- Jin, F.; Liu, Q.; Liu, H.; Wu, P. A Low Complexity Signal Detection Scheme Based on Improved Newton Iteration for Massive MIMO Systems. IEEE Commun. Lett. 2019, 23, 748–751. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Zheng, Q.; Chen, L. Regularized Extreme Learning Machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TE, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar] [CrossRef]
- Zhang, K.; Luo, M. Outlier-robust extreme learning machine for regression problems. Neurocomputing 2015, 151, 1519–1527. [Google Scholar] [CrossRef]
- Sarieddeen, H.; Abdallah, A.; Mansour, M.M.; Alouini, M.S.; Al-Naffouri, T.Y. Terahertz-band MIMO-NOMA: Adaptive superposition coding and subspace detection. IEEE Open J. Commun. Soc. 2021, 2, 2628–2644. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keawin, C.; Innok, A.; Uthansakul, P. Optimization of Signal Detection Using Deep CNN in Ultra-Massive MIMO. Telecom 2024, 5, 280-295. https://doi.org/10.3390/telecom5020014
Keawin C, Innok A, Uthansakul P. Optimization of Signal Detection Using Deep CNN in Ultra-Massive MIMO. Telecom. 2024; 5(2):280-295. https://doi.org/10.3390/telecom5020014
Chicago/Turabian StyleKeawin, Chittapon, Apinya Innok, and Peerapong Uthansakul. 2024. "Optimization of Signal Detection Using Deep CNN in Ultra-Massive MIMO" Telecom 5, no. 2: 280-295. https://doi.org/10.3390/telecom5020014
APA StyleKeawin, C., Innok, A., & Uthansakul, P. (2024). Optimization of Signal Detection Using Deep CNN in Ultra-Massive MIMO. Telecom, 5(2), 280-295. https://doi.org/10.3390/telecom5020014