
Examining Sentiment Analysis for Low-Resource Languages with Data Augmentation Techniques


Abstract
1. Introduction
2. Research Question
- (1)
- Can the data augmentation technique improve the performance metric?
- (2)
- What is the effect of using augmented data generated from different techniques? We explore three different data augmentation techniques and compare their performances with each other.
- (3)
- Can WordNet-based augmentation techniques work better with sentiment classification tasks?
- Does training with Lemma-based instances work for Croatian?
3. Literature Review
Data Augmentation
4. Data
4.1. Croatian Re-Annotation
4.2. Sentiment Analysis Datasets
- Bulgarian The Cinexio [34] dataset is composed of film reviews with 11-point star ratings: 0 (negative), 0.5, 1, …, 4.5, 5 (positive). Other meta-features included in the dataset were film length, director, actors, genre, country, and various scores.
- Croatian Pauza [33] contains restaurant reviews from Pauza.hr4, the largest food-ordering website in Croatia. Each review is assigned an opinion rating ranging from 0.5 (worst) to 6 (best). User-assigned ratings are the benchmark for the labels. The dataset also contains opinionated aspects.
- Slovak The Review3 [35] is composed of customer evaluations of a variety of services. The dataset is categorised using the 1–3 and 1–5 scales.
- Slovene The Opinion corpus of Slovene web commentaries KKS 1.001 [36] includes web commentaries on various topics (business, politics, sports, etc.) from four Slovene web portals (RtvSlo, 24ur, Finance, Reporter). Each instance within the dataset is tagged with one of three labels (negative, neutral, or positive).
4.3. Data Generation and Augmentation
4.4. Lemmatisation
- Original HR: super, odlicni cevapi.
- Lemmatised: super, odličan ćevap.
4.5. Expansion [Ours]
- (Original HR): “Pizze Capriciosa i tuna, dobre. Inače uvijek dostava na vrijeme i toplo jelo”.
- (Translated EN): “Pizza Capricios and tuna, good. Otherwise always delivery on time and hot food”.
4.5.1. Expansion-Combination [Ours]
4.5.2. Expansion-Permutation [Ours]
4.5.3. WordNet Augmentations
- (1)
- Lemma HR: Jako dobar pizza. (Translation: very good pizza.)
- (2)
- Augmented HR: jako divan pizza.
- (3)
- Augmented HR: jako krasan pizza.
- (1)
- HR: Jako dobra pizza i brza dostava. (Translation: Very good pizza and fast delivery.)
- (2)
- Augmented HR: Jako dobra pizza i brza dostavljanje.
- (3)
- Augmented HR: Jako dobra pizza i brza doprema.
4.6. Language Tools
4.7. MLM Augmentations
- (1)
- HR: Ne narucivat chilly. (Translation: Do not order chilly.)
- (2)
- Augmented HR: Ne narucivat meso. (Translation: Do not order meat.)
4.8. CLM Augmentations
- (1)
- HR: naručili salatu, dostava je bila na vrijeme, dostavljac simpatican.
- (2)
- translation: pizza arrived, no complaints just ordered a salad in advance, delivery was on time, the delivery man was nice.
4.9. Experiments
4.10. Training Set Size
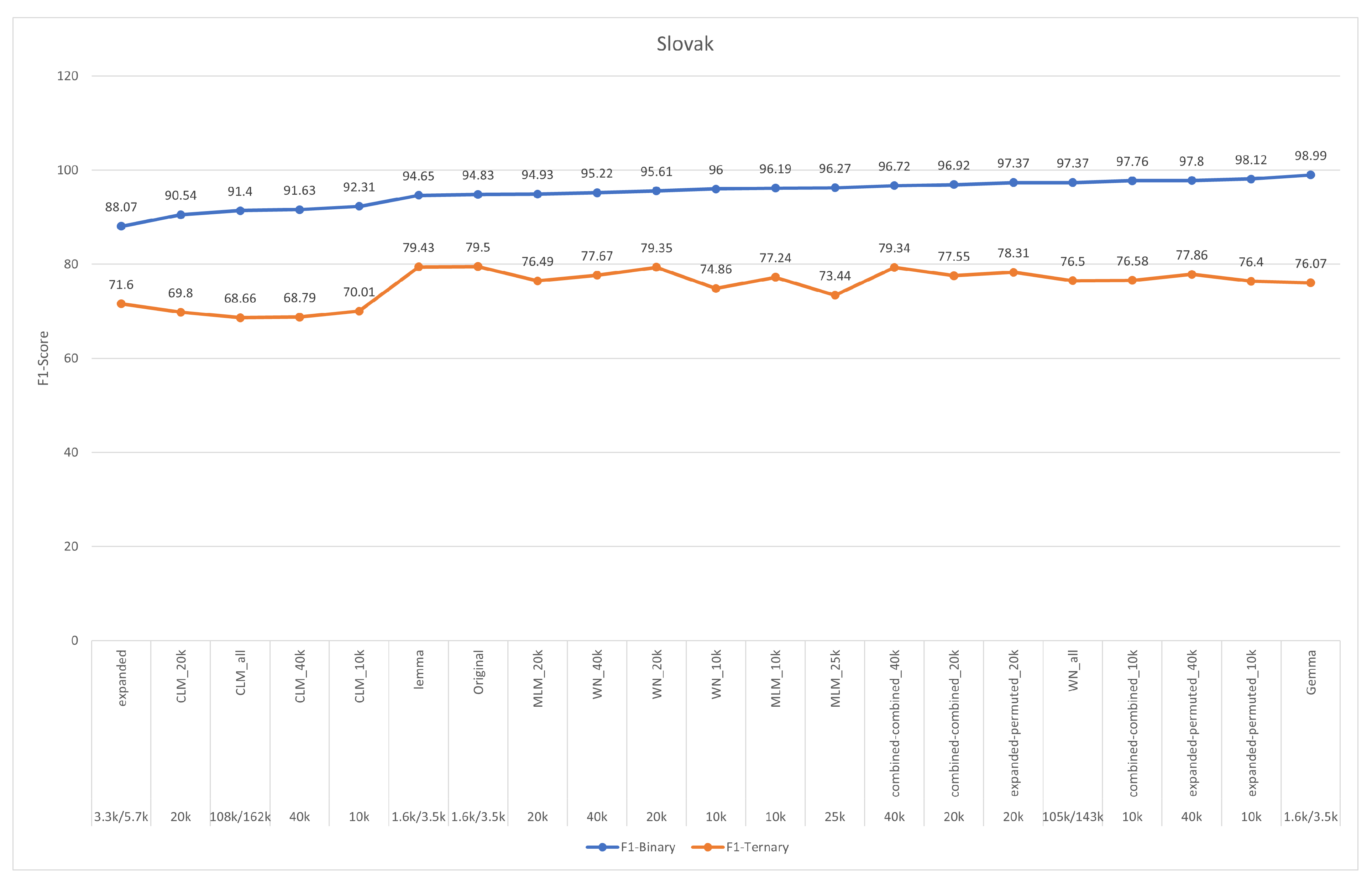
5. Results and Discussion
5.1. Error Analysis
5.1.1. Text Accompanied by Additional Context
- (Original BG) Пoлoвината салoн си тръгна на 30тата минута. Аз следя сериала oт кактo гo има и филма ми хареса.
- (Transliteration BG) Polovinata salon si trgna na 30tata minuta. Az sledya seriala ot kakto go ima i filma mikharesa.
- (Translation EN) Half the salon left at the 30 min mark. I’ve been following the series since it started and I liked the movie.
- Original label: positive; predicted: negative.
5.1.2. Reviews with Aspect Ratings
- (Original BG) 1 за декoрите … Начoсът заслужава 5.
- (Transliteration BG) 1 za dekorite … Nachost zasluzhava 5
- (Translation EN) 1 for the decorations … The nachos deserve a 5.
- original label: negative; predicted: positive.
5.1.3. Mixed Aspects
- (Original BG) Твърде мнoгo ненужнo пеене,нo всичкo oстаналo е супер!:)
- (Transliteration BG) Tvrde mnogo ne nuzhno peene, no vsichko ostanalo e super!:)
- (Translation EN) Too much unnecessary singing, but everything else is great!:)
- original rating: negative; predicted: positive.
5.1.4. Contradictory Expressions
- (Original BG) Красив филм с безкрайнo несъстoятелен сценарий.
- (Transliteration BG) Krasiv film s bezkraino nesstoyatelen stsenarii.
- (Translation EN) A beautiful film with an endlessly unworkable script.
- Original rating: negative; predicted: positive.
- (1)
- Some reviews contain sentences that are lengthy. The XLM-R accepts 512 (-2) tokens that have been processed by a tokeniser [16]. Due to the omission of these text tokens, the model performs poorly when the text is exceedingly long. This phenomenon is notable in the Slovene and Croatian datasets.
- (2)
- Cases in which the author gave the review a positive rating, but the text contains many unrelated negative statements. This occurs when the author rants about many other stores and writes one positive line about the target entity [50].
- (3)
- We also found that the greater the distance between the negation cue and the scope of the negation, the less likely the model is to capture the negation. For example, “Pizza dola mlaka, i ne ukusna”, vs. “Pizza dola mlaka, i ne ba ukusna”, and “Pizza dola mlaka, i ne ba previe ukusna”. The first sample was correctly classified, but the second and third samples were not [51].
- (4)
- People write negative reviews but rate the restaurant highly because they had a pleasant experience there [52].
- (5)
- Code-mixing and English text in Croatian and Slovene [53].
- (1)
- Brza dostava, ok hrana. Jedino kaj su zaboravili coca colu :(. (Translation EN) Fast delivery, ok food. Only what they forgot about Coca Cola :(.
- (2)
- Nisam vidjela prut na pizzi special, al nema veze, vratina je bila sasvim dovoljna! (Translation EN) I did not see the prosciutto on the pizza special, but it does not matter, the door was enough!
- (3)
- Malo gumasto tijesto, inace OK pizza. (Translation EN) A little rubber dough, otherwise ok pizza.
- (1)
- Bol som vemi spokojný. (Translation EN) I have been very satisfied.
- (2)
- super super super. (Translation EN) Super Super Super.
- (3)
- Bola vemi príjemná a milá. (Translation EN) She was very pleasant and nice.
- (4)
- Vemi ústretová a ochotná. (Translation EN) Very helpful and willing.
- (5)
- Bagety, ktoré som kúpila boli perfektné … akujem. (Translation EN) Baguettes I bought were perfect … Thank you.
5.2. Revisiting Research Questions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. Neural Netw. Tricks Trade Second. Ed. 2012, 7700, 437–478. [Google Scholar] [CrossRef]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Schreiner, C.; Torkkola, K.; Gardner, M.; Zhang, K. Using Machine Learning Techniques to Reduce Data Annotation Time. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Sydney, Australia, 20–22 November 2006; pp. 2438–2442. [Google Scholar] [CrossRef]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Kobayashi, S. Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 452–457. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Wu, T.; Guestrin, C.; Singh, S. Beyond Accuracy: Behavioral Testing of NLP models with CheckList. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4902–4912. [Google Scholar]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T. Generalizing to Unseen Domains: A Survey on Domain Generalization. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–27 August 2021; Zhou, Z.-H., Ed.; Survey Track. pp. 4627–4635. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-Level Convolutional Networks for Text Classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Zuo, X.; Chen, Y.; Liu, K.; Zhao, J. KnowDis: Knowledge Enhanced Data Augmentation for Event Causality Detection via Distant Supervision. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; pp. 1544–1550. [Google Scholar] [CrossRef]
- Yang, Y.; Malaviya, C.; Fernandez, J.; Swayamdipta, S.; Bras, R.L.; Wang, J.; Bhagavatula, C.; Choi, Y.; Downey, D. Generative Data Augmentation for Commonsense Reasoning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1008–1025. [Google Scholar] [CrossRef]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Su, P.; Li, G.; Wu, C.; Vijay-Shanker, K. Using Distant Supervision to Augment Manually Annotated Data for Relation Extraction. PLoS ONE 2019, 14, e0216913. [Google Scholar] [CrossRef] [PubMed]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction without Labeled Data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Garg, S.; Ramakrishnan, G. BAE: BERT-based Adversarial Examples for Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6174–6181. [Google Scholar]
- Li, L.; Ma, R.; Guo, Q.; Xue, X.; Qiu, X. BERT-ATTACK: Adversarial Attack Against BERT Using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6193–6202. [Google Scholar]
- Yoo, J.Y.; Qi, Y. Towards Improving Adversarial Training of NLP Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual, 16–20 November 2021; pp. 945–956. [Google Scholar]
- Ren, S.; Deng, Y.; He, K.; Che, W. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1085–1097. [Google Scholar] [CrossRef]
- Samanta, S.; Mehta, S. Towards Crafting Text Adversarial Samples. arXiv 2017, arXiv:1707.02812. [Google Scholar]
- Li, D.; Zhang, Y.; Peng, H.; Chen, L.; Brockett, C.; Sun, M.; Dolan, B. Contextualized Perturbation for Textual Adversarial Attack. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5053–5069. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 86–96. [Google Scholar] [CrossRef]
- Edunov, S.; Ott, M.; Auli, M.; Grangier, D. Understanding Back-Translation at Scale. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 489–500. [Google Scholar] [CrossRef]
- Longpre, S.; Wang, Y.; DuBois, C. How Effective is Task-Agnostic Data Augmentation for Pretrained Transformers? In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 4401–4411. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised Data Augmentation for Consistency Training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Martinc, M.; Montariol, S.; Pivovarova, L.; Zosa, E. Effectiveness of Data Augmentation and Pretraining for Improving Neural Headline Generation in Low-Resource Settings. In Proceedings of the LREC 2022, Marseille, France, 20–25 June 2022. [Google Scholar]
- Cheung, T.-H.; Yeung, D.-Y. {MODALS}: Modality-agnostic Automated Data Augmentation in the Latent Space. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Goldsmith, J.; Riggle, J.; Alan, C.L. The Handbook of Phonological Theory; Wiley Online Library: Hoboken, NJ, USA, 1995. [Google Scholar]
- Glavaš, G.; Korenčić, D.; Šnajder, J. Aspect-Oriented Opinion Mining from User Reviews in Croatian. In Proceedings of the 4th Biennial International Workshop on Balto-Slavic Natural Language Processing, Sofia, Bulgaria, 8–9 August 2013; pp. 18–23. [Google Scholar]
- Kapukaranov, B.; Nakov, P. Fine-Grained Sentiment Analysis for Movie Reviews in Bulgarian. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 7–9 September 2015; pp. 266–274. [Google Scholar]
- Pecar, S.; Simko, M.; Bielikova, M. Improving Sentiment Classification in Slovak Language. In Proceedings of the 7th Workshop on Balto-Slavic Natural Language Processing, Florence, Italy, 2 August 2019. [Google Scholar]
- Kadunc, K.; Robnik-Šikonja, M. Opinion Corpus of Slovene Web Commentaries KKS 1.001; Slovenian Language Resource Repository CLARIN.SI. 2017. Available online: http://hdl.handle.net/11356/1115 (accessed on 19 July 2022).
- Anaby-Tavor, A.; Carmeli, B.; Goldbraich, E.; Kantor, A.; Kour, G.; Shlomov, S.; Tepper, N.; Zwerdling, N. Do Not Have Enough Data? Deep Learning to the Rescue! In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, the Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 7383–7390. [Google Scholar] [CrossRef]
- Bollegala, D.; Weir, D.; Carroll, J.A. Using Multiple Sources to Construct a Sentiment Sensitive Thesaurus for Cross-Domain Sentiment Classification. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 132–141. [Google Scholar]
- Gamon, M. Sentiment Classification on Customer Feedback Data: Noisy data, large feature vectors, and the role of linguistic analysis. In Proceedings of the COLING 2004: 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 841–847. [Google Scholar]
- Itertools Combinations. 2022. Available online: https://docs.python.org/3/library/itertools.html#itertools.combinations (accessed on 26 July 2022).
- Itertools Permutations. 2022. Available online: https://docs.python.org/3/library/itertools.html#itertools.permutations (accessed on 26 July 2022).
- Erjavec, T.; Fišer, D. Building Slovene Wordnet. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Koeva, S.; Genov, A.; Totkov, G. Towards Bulgarian Wordnet. Rom. J. Inf. Sci. Technol. 2004, 7, 45–60. [Google Scholar]
- Raffaelli, I.; Tadic, M.; Bekavac, B.; Agic, Ž. Building croatian wordnet. In Proceedings of the GWC, Szeged, Hungary, 22–25 January 2008; pp. 349–360. [Google Scholar]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999; Volume 463. [Google Scholar]
- Gemini Team Google. Gemini: A Family of Highly Capable Multimodal Models. arXiv 2023, arXiv:2312.11805. [Google Scholar] [CrossRef]
- Yeh, A. More Accurate Tests for the Statistical Significance of Result Differences. In Proceedings of the COLING 2000 Volume 2: The 18th International Conference on Computational Linguistics, Saarbrücken, Germany, 31 July–4 August 2000. [Google Scholar]
- Kolesnichenko, L.; Velldal, E.; Øvrelid, L. Word Substitution with Masked Language Models as Data Augmentation for Sentiment Analysis. In Proceedings of the Second Workshop on Resources and Representations for Under-Resourced Languages and Domains (RESOURCEFUL-2023), Torshavn, Danmark, 22 May 2023; pp. 42–47. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. In Foundations and Trends in Information Retrieval; Now Publishers Inc.: Norwell, MA, USA, 2008; pp. 1–135. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Khandelwal, A.; Sawant, S. NegBERT: A Transfer Learning Approach for Negation Detection and Scope Resolution. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 5739–5748. [Google Scholar]
- Askalidis, G.; Kim, S.J.; Malthouse, E.C. Understanding and Overcoming Biases in Online Review Systems. Decis. Support Syst. 2017, 97, 23–30. [Google Scholar] [CrossRef]
- Utsab, B.; Das, A.; Joachim, W.; Foster, J. Code Mixing: A Challenge for Language Identification in the Language of Social Media. In Proceedings of the First Workshop on Computational Approaches to Code Switching, Doha, Qatar, 25 October 2014; pp. 13–23. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Purpose | Method | Sample Size | Key Findings |
|---|---|---|---|---|
| [18] | relation extraction in NLP | Distant supervision (DS) using Freebase as a lookup table | 800 K | Multi-instance learning framework. |
| [29] | Classifying sentiment in tweets | Remote supervision using emoticons as labels | 1600 K | Emoticons were used as labels for the SA of tweets. |
| [25] | Enhancing NMT with synthetic data | Back-translation | 100 K | Used machine translation as paraphraser. |
| [7] | Improving adversarial attack performance | Altered language model trained on WikiText-103 corpus | 7 K–540 K | Contextual DA method outperforms traditional DA methods |
| [26] | Improving NMT sample quality | Sampling and noisy beam outputs for back-translation | 29 M | Noisy beam outputs, create better synthetic data than beam or greedy search. |
| [17] | Curating datasets for BioNLP tasks | Distant supervision with heuristics to reduce noise | 25 K–77 K | Proposed heuristics to reduce noise. |
| [22] | Generating adversarial samples for NLP | Synonym replacement using WordNet | 25 K –1.4 M | Saliency-based methods for detecting important words. |
| [6] | Simplifying data augmentation | EDA: synonym replacement, random replacement, swap, deletion | 500–5 K | Found small augmentation values () produced better performance gains than large values. |
| [19] | Improving adversarial sample generation | Contextual perturbations using BERT masked language model | 10 K–598 K datasets | Used BERT for replacing and inserting tokens at masked locations. |
| [27] | Examining the impact of pre-trained language models on data augmentation | Augmentation with BERT, XL-NET, and RoBERTa | 500–10 K | DA did not provide consistent improvements for pre-trained transformers. |
| [28] | Enforcing consistency in model predictions with augmented data | Consistency training with back-translation and TF-IDF | 25 K | Used consistency loss to improve model predictions. |
| [24] | Extending adversarial attack methods | Contextualized perturbations with RoBERTa | 105 K–560 K | Introduced replace, insert, and merge operations for adversarial attacks. |
| [31] | Proposing data augmentation using latent space for difficult-to-classify samples | Latent space augmentation using interpolation and noise addition | 50 K–120 K | Difficult-to-classify samples contain more information, making them ideal for DA in low-data settings. |
| [30] | Comparing augmentation strategies for headline generation in various languages | WordNet and Bert-based augmentation | 10 K–260 K | Domain-specific data benefit more from data augmentation and pretraining schemes |
| Ours | Comparing multiple DA strategies for SA in various low-resourced languages | Expansion and permutation-based techniques | 10 K–40 K | Transformer-based models do not benefit from DA based on synonymy. |
| Language | Dataset | Train | Val | Test |
|---|---|---|---|---|
| Bulgarian | Cinexio | 5520 | 614 | 682 |
| Croatian | Pauza | 2050 | 227 | 1033 |
| Slovak | Reviews3 | 3834 | 661 | 1235 |
| Slovene | KKS | 3977 | 200 | 600 |
| Language | Method | Model Name |
|---|---|---|
| Croatian | CLM | macedonizer/hr-gpt2 |
| MLM | EMBEDDIA/crosloengual-bert | |
| Bulgarian | CLM | rmihaylov/gpt2-medium-bg |
| MLM | rmihaylov/bert-base-bg | |
| Slovak | CLM | Milos/slovak-gpt-j-405M |
| MLM | gerulata/slovakbert | |
| Slovene | CLM | macedonizer/sl-gpt2 |
| MLM | EMBEDDIA/sloberta |
| Language | Version | Train | Dev | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| neg | pos | neu | neg | pos | neu | neg | pos | neu | ||
| Croatian | Original | 467 | 1586 | 145 | 47 | 159 | 14 | 236 | 719 | 78 |
| lemma | 467 | 1586 | 145 | 47 | 159 | 14 | 236 | 719 | 78 | |
| expanded | 1523 | 3979 | 436 | 44 | 398 | 152 | 742 | 1787 | 254 | |
| Bulgarian | Original | 864 | 3898 | 710 | 96 | 436 | 80 | 107 | 486 | 88 |
| lemma | 864 | 3898 | 710 | 96 | 436 | 80 | 107 | 486 | 88 | |
| expanded | 1435 | 6321 | 1060 | 154 | 686 | 116 | 185 | 803 | 133 | |
| neg | pos | neu | neg | pos | neu | neg | pos | neu | ||
| Slovak | Original | 297 | 1337 | 1926 | 46 | 211 | 265 | 80 | 416 | 545 |
| lemma | 297 | 1337 | 1926 | 46 | 211 | 265 | 80 | 416 | 545 | |
| expanded | 879 | 2493 | 2397 | 136 | 352 | 326 | 279 | 841 | 627 | |
| Slovene | Original | 2722 | 749 | 506 | 138 | 37 | 25 | 431 | 112 | 57 |
| lemma | 2722 | 749 | 506 | 138 | 37 | 25 | 431 | 112 | 57 | |
| expanded | 13,676 | 2165 | 2073 | 559 | 170 | 141 | 2183 | 400 | 229 | |
| Language | Version | Binary | Ternary | ||
|---|---|---|---|---|---|
| F1 | ACC | F1 | ACC | ||
| Croatian | Original | 94.11 | 95.86 | 75.04 | 88.18 |
| lemma | 93.61 | 95.53 | 60.95 | 77.77 | |
| expanded | 73.99 | 78.76 | 73.31 | 86.93 | |
| gemma | 98.05 | 98.03 | 90.84 | 90.99 | |
| Bulgarian | Original | 90.00 | 94.43 | 72.90 | 83.55 |
| lemma | 88.82 | 93.76 | 68.31 | 81.20 | |
| expanded | 84.44 | 91.09 | 65.89 | 80.55 | |
| gemma | 96.41 | 96.45 | 80.39 | 84.43 | |
| Slovak | Original | 94.83 | 97.17 | 79.50 | 81.07 |
| lemma | 94.65 | 96.97 | 79.43 | 81.84 | |
| expanded | 88.07 | 90.98 | 71.60 | 72.46 | |
| gemma | 98.99 | 98.99 | 76.07 | 76.65 | |
| Slovene | Original | 80.92 | 87.84 | 68.70 | 79.33 |
| lemma | 79.25 | 87.29 | 66.38 | 77.16 | |
| expanded | 68.05 | 85.63 | 49.96 | 67.03 | |
| gemma | 93.57 | 93.73 | 85.8 | 85.83 | |
| Lang | Ver | Binary_10k | Ternary_10k | Binary_20k | Ternary_20k | Binary_40k | Ternary_40k | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | ||
| Hr | expanded-combined | 95.37 | 96.84 | 73.17 | 87.41 | 95.84 | 97.16 | 72.96 | 85.96 | 94.26 | 96.07 | 71.84 | 87.6 |
| expanded-permuted | 95.53 | 96.84 | 73.87 | 87.99 | 94.79 | 96.4 | 68.72 | 84.99 | 93.06 | 95.31 | 71.63 | 86.93 | |
| Bg | expanded-combined | 90.16 | 94.26 | 66.18 | 76.35 | 89.88 | 93.92 | 72.23 | 81.93 | 89.41 | 93.76 | 72.27 | 82.96 |
| expanded-permuted | 89.85 | 94.26 | 71.7 | 80.91 | 89.17 | 93.76 | 71.69 | 81.64 | 89.08 | 93.76 | 70.5 | 79.29 | |
| Sk | expanded-combined | 97.76 | 98.79 | 76.58 | 77.52 | 96.92 | 98.38 | 77.55 | 78.09 | 96.72 | 98.18 | 79.34 | 80 |
| expanded-permuted | 98.12 | 98.99 | 76.4 | 76.94 | 97.37 | 98.58 | 78.31 | 79.05 | 97.8 | 98.79 | 77.86 | 79.05 | |
| Sv | expanded-combined | 75.89 | 81.76 | 59.73 | 70.16 | 77.9 | 84.16 | 62.89 | 74.88 | 77.67 | 83.6 | 58.8 | 67 |
| expanded-permuted | 75.57 | 81.21 | 53.66 | 60.16 | 74.07 | 79.92 | 54.62 | 59.33 | 77.84 | 83.24 | 61.5 | 73.5 | |
| 10k | 20k | 25k | 40k | All | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lang | Version | Binary | Ternary | Binary | Ternary | Binary | Ternary | Binary | Ternary | Binary | Ternary | ||||||||||
| F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | F1 | ACC | ||
| Hr | WN | 94.18 | 95.96 | 71.90 | 87.12 | 93.09 | 95.31 | 68.73 | 84.80 | 94.20 | 95.96 | 61.78 | 84.31 | 93.94 | 95.86 | 69.43 | 86.73 | ||||
| MLM | 92.30 | 94.55 | 67.74 | 81.31 | 90.26 | 93.35 | 70.63 | 83.93 | 90.76 | 93.68 | 69.36 | 83.15 | |||||||||
| CLM | 92.06 | 94.44 | 64.96 | 81.89 | 90.74 | 93.89 | 6235 | 81.80 | 89.73 | 93.02 | 67.11 | 83.83 | |||||||||
| Bg | WN | 91.56 | 94.94 | 70.64 | 84.43 | ||||||||||||||||
| MLM | 88.73 | 93.76 | 70.07 | 81.49 | |||||||||||||||||
| CLM | 87.07 | 92.58 | 61.87 | 79.73 | 84.15 | 90.55 | 59.05 | 77.09 | 82.76 | 88.87 | 58.43 | 80.02 | 84.10 | 91.23 | 58.35 | 76.65 | |||||
| Sk | WN | 96.00 | 97.78 | 74.86 | 79.82 | 95.61 | 97.58 | 79.35 | 82.32 | 95.22 | 97.37 | 77.67 | 80.97 | 97.37 | 98.58 | 76.50 | 78.96 | ||||
| MLM | 96.19 | 97.98 | 77.24 | 78.67 | 94.93 | 97.17 | 76.49 | 76.75 | 96.27 | 97.98 | 73.44 | 74.25 | |||||||||
| CLM | 92.31 | 95.96 | 70.01 | 72.14 | 90.54 | 94.55 | 69.8 | 71.85 | 91.63 | 95.56 | 68.79 | 71.66 | 91.40 | 95.16 | 68.66 | 70.50 | |||||
| Sv | WN | 73.47 | 79.18 | 59.39 | 68.83 | 78.25 | 84.71 | 53.33 | 65.00 | 78.25 | 84.71 | 58.53 | 69.5 | 77.83 | 86.37 | 59.87 | 73.5 | ||||
| MLM | 63.02 | 66.11 | 62.00 | 72.16 | 73.99 | 79.37 | 60.827 | 72.33 | 76.152 | 82.13 | 56.11 | 64.16 | |||||||||
| CLM | 74.29 | 81.03 | 55.16 | 65.33 | 67.19 | 72.19 | 54.46 | 69.83 | 90.26 | 73.66 | 56.38 | 65.83 | 65.89 | 69.98 | 47.68 | 57.83 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakkar, G.; Preradović, N.M.; Tadić, M. Examining Sentiment Analysis for Low-Resource Languages with Data Augmentation Techniques. Eng 2024, 5, 2920-2942. https://doi.org/10.3390/eng5040152
Thakkar G, Preradović NM, Tadić M. Examining Sentiment Analysis for Low-Resource Languages with Data Augmentation Techniques. Eng. 2024; 5(4):2920-2942. https://doi.org/10.3390/eng5040152
Chicago/Turabian StyleThakkar, Gaurish, Nives Mikelić Preradović, and Marko Tadić. 2024. "Examining Sentiment Analysis for Low-Resource Languages with Data Augmentation Techniques" Eng 5, no. 4: 2920-2942. https://doi.org/10.3390/eng5040152
APA StyleThakkar, G., Preradović, N. M., & Tadić, M. (2024). Examining Sentiment Analysis for Low-Resource Languages with Data Augmentation Techniques. Eng, 5(4), 2920-2942. https://doi.org/10.3390/eng5040152