
Investigation on Performance of Single Precision Floating Point Multiplier (SPFPM) Using CSA Multiplier and Different Types of Adders †

Abstract
:1. Introduction
2. Representation and Calculation of Floating Point in IEEE-754 Standard
- i.
- The sign of the FP number is represented by the most significant bit (MSB): 0 for a positive number and 1 for a negative number. By taking the XOR of sign bit of multiplier and multiplicand, the sign-bit is consequently determined.
- ii.
- Bit (30-23) is used to express a biased exponent (E). E = e + 127, where e is the actual exponent, and 127 is the bias value for single precision. We add the exponents of two numbers using a different type of 8-bit full adder. After adding the exponents of two inputs, the bias is subtracted from this using a 9-bit subtractor (to cater the carry of addition) to obtain the final output.
- iii.
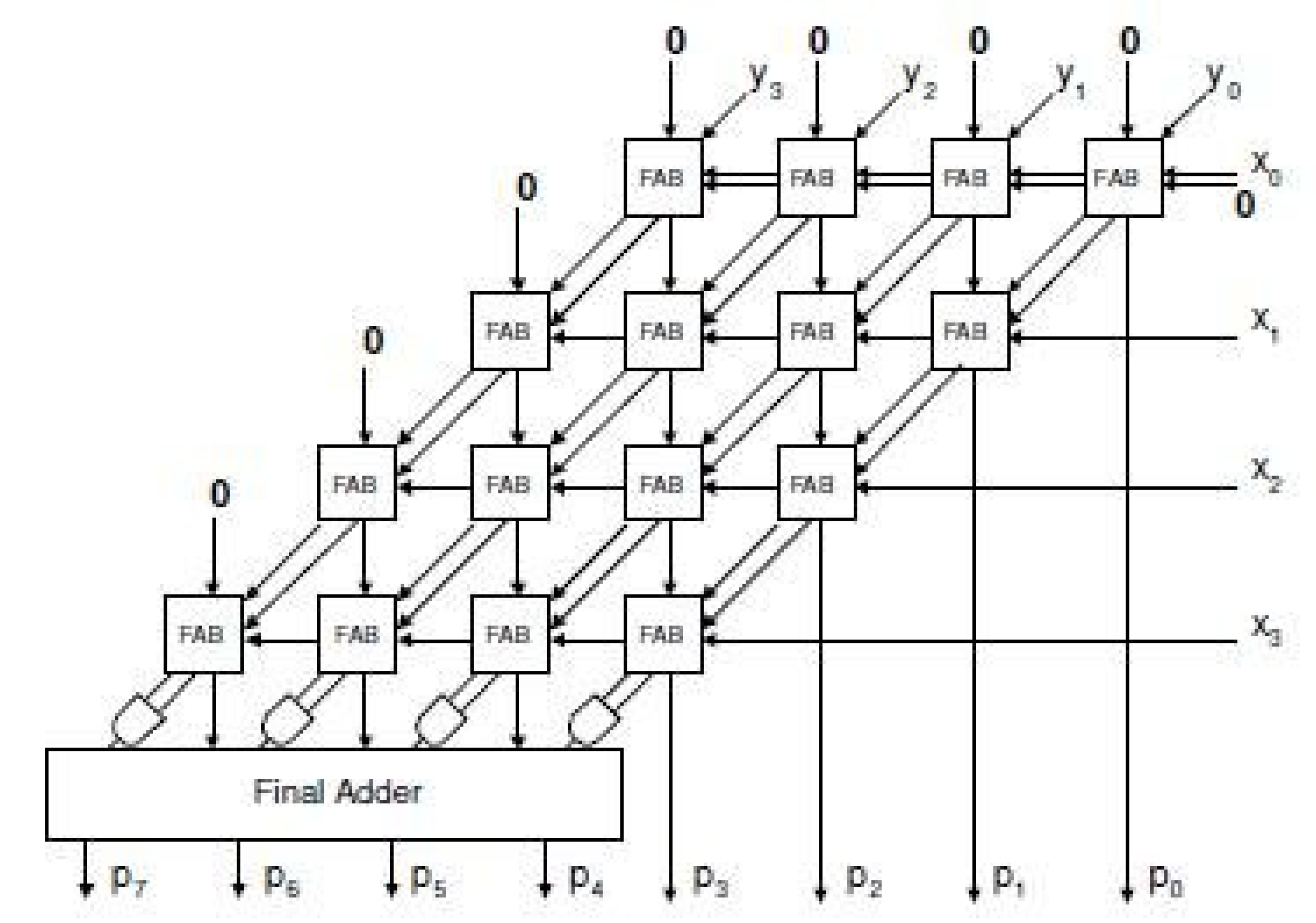
- The mantissa/significand for a binary number is represented by 0 to 22 bits as shown in Table 1. Here, we are using array multiplier for this purpose as shown in Figure 1. This involves the multiplication of 24-bit (23 fraction bits and one hidden bit) mantissas of two input numbers and results a 48-bit mantissa, which is then truncated to 24 bits.
- iv.
- As mentioned earlier, IEEE-754 standard floating point numbers always have one ‘1’ to the left of the binary point. We ignored the binary point while multiplying the mantissa. Therefore, the lower 46 bits are placed to the left of the binary point in the result. In this case, we have two possibilities, i.e., the binary point could be in 47th or 46th place.
- In the first case, no normalization is required if the leading ‘1’ bit is in 46th place (i.e., there is just one bit ‘1’ on the left), because the result is already normalized.
- In the second case, normalization is needed if the leading ‘1’ bit is at 47th place (i.e., it occurs one bit away from the binary point). So, mantissa needs to be shifted one unit left, and consequently, the exponent also requires normalization, which is done by adding one to it.
3. Adders for Comparison
3.1. Carry Look Ahead Adder (CLA)
3.2. Carry Skip Adder (CSA/CBA)
3.3. Carry Increment Adder (CIA)
4. Results
4.1. Comparison with the Literature
4.2. Device Utilization Summary
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Floating Point Number. 754-2008 IEEE Standard for Floating-Point Arithmetic. 2008, pp. 1–70. Available online: https://steve.hollasch.net/cgindex/coding/ieeefloat.html (accessed on 20 April 2021).
- Manolopoulos, K.; Reisis, D.; Chouliaras, V.A. An efficient multiple floating point multiplier. In Proceedings of the 2011 18th IEEE International Conference on Electronics, Circuits, and Systems, Beirut, Lebanon, 11–14 December 2011; pp. 153–156. [Google Scholar]
- Weste, N.H.E.; Harris, D. CMOS VLSI Design: A Circuits and Systems Perspective, 3rd ed.; Pearson Education: London, UK, 2005; pp. 345–356. [Google Scholar]
- Digital Multipliers. Available online: https://www.ijemr.net/DOC/DigitalMultipliers-AReview(220-223)8aa5905d-5da5-4b50-8b2e-f0bd850becb7.pdf (accessed on 17 May 2021).
- Mangalath, N.S.; Priya, R.; Malathi, P. An efficient universal multi-mode floating point multiplier using Vedic mathematics. In Proceedings of the IEEE 2014 International Conference on Advances in Communication and Computing Technologies (ICACACT), Mumbai, India, 10–11 August 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Raahemifar, K.; Ahmadi, M. Fast carry-look-ahead adder. In Proceedings of the Engineering Solutions for the Next Millennium. 1999 IEEE Canadian Conference on Electrical and Computer Engineering (Cat. No.99TH8411), Edmonton, AB, Canada, 9–12 May 1999. [Google Scholar]
- Jom, S.; Asha, J. Hybrid Variable Latency Carry Skip Adder. In Proceedings of the International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–6. [Google Scholar]
- Devi, A.B.; Kumar, M.; Laishram, R. Design and Implementation of an Improved Carry Increment Adder. Int. J. VLSI Des. Commun. Syst. 2016, 7, 21–27. [Google Scholar] [CrossRef]
- Ramya, V.; Seshasayanan, R. Low power single precision BCD floating–point Vedic multiplier. Microprocess. Microsyst. 2020, 72, 102930. [Google Scholar] [CrossRef]
- Krishnan, T.; Saravanan, S. Design of Low-Area and High Speed Pipelined Single Precision Floating Point Multiplier. In Proceedings of the IEEE 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, India 6–7 March 2020; pp. 1259–1264. [Google Scholar] [CrossRef]
- McNamaraField, D. Programmable Gate Arrays Accelerate Applications from the Cloud to the Edge; Intel Corporation: Santa Clara, CA, USA, 2021. [Google Scholar]

{kind=link}
| Sign Bit | Exponent | Mantissa | ||
|---|---|---|---|---|
| b31 | b31 | b23 | b22 | b0 |
| Description | Proposed | [9] | [10] |
|---|---|---|---|
| Year | 2021 | 2020 | 2020 |
| FPGA | Spartan 6 | Cadence EDA Tool | Altera Cyclone II |
| Multiplication Algorithm | Carry Save Array Multiplier | Vedic multiplier | Array Multiplier |
| Adder Algorithm | CIA, CSA, CLA, RCA | Kogge stone | Modified CLA |
| Description | Ripple Carry Adder- (Used/Available) | Carry Skip Adder (Used/Available) | Carry Select Adder (Used/Available) | Carry Look Ahead Adder (Used/Available) | Carry Increment (Used/Available) |
|---|---|---|---|---|---|
| Number of Slice LUTs | 821/27,288 | 821/27,288 | 822/27,288 | 823/27,288 | 823/27,288 |
| Occupied Slices | 341/6822 | 352/6822 | 353/6822 | 347/6822 | 325/6822 |
| Bonded IOBs | 144/218 | 144/218 | 144/218 | 144/218 | 144/218 |
| Average Fan-out | 4.58 | 4.58 | 4.58 | 4.57 | 4.57 |
| Total Delay | 82.292 ns | 81.783 ns | 81.716 ns | 82.138 ns | 81.716 ns |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amjad, H.; Ahmad, Z.; Abrar, M.; Rasheed, H. Investigation on Performance of Single Precision Floating Point Multiplier (SPFPM) Using CSA Multiplier and Different Types of Adders. Eng. Proc. 2021, 12, 107. https://doi.org/10.3390/engproc2021012107
Amjad H, Ahmad Z, Abrar M, Rasheed H. Investigation on Performance of Single Precision Floating Point Multiplier (SPFPM) Using CSA Multiplier and Different Types of Adders. Engineering Proceedings. 2021; 12(1):107. https://doi.org/10.3390/engproc2021012107
Chicago/Turabian StyleAmjad, Hasaan, Zeeshan Ahmad, Muneeb Abrar, and Hina Rasheed. 2021. "Investigation on Performance of Single Precision Floating Point Multiplier (SPFPM) Using CSA Multiplier and Different Types of Adders" Engineering Proceedings 12, no. 1: 107. https://doi.org/10.3390/engproc2021012107
APA StyleAmjad, H., Ahmad, Z., Abrar, M., & Rasheed, H. (2021). Investigation on Performance of Single Precision Floating Point Multiplier (SPFPM) Using CSA Multiplier and Different Types of Adders. Engineering Proceedings, 12(1), 107. https://doi.org/10.3390/engproc2021012107