1. Introduction
In wind energy industry, there is always some uncertainty about the final product due to the fact that wind speed is highly variable. The ability to predict wind speed for few hours in advance will help to ensure efficient utilization of the power generated, and therefore, enhance the position of wind energy compared to other forms of energy.
Forecasting of wind speed has been the subject of a lot of studies. Statistical and artificial neural networks are the approaches the most found in literature. Based on the hourly averaged wind speed (HAWS), several models have been developed using time series methodologies. In 1984, Geerts has proposed a short-term forecasting of wind speed using ARMA models [
1]. A comparison of the performances of ARMA models developed using one-year data with those of the persistent model has indicated that for more than 1 h, ARMA models provide better forecasting. This shows that models developed using several years data could provide better results than those developed using only one-year data. Daniel and Chen (1991) have used a three-year long time series to develop ARMA models [
2]. Since then, several similar studies have been realized for many sites around the world. Using 12-year data, Nfaoui et al. (1996) concluded that an AR(2) model is able to simulate the wind speed data of Tangiers (Morocco) [
3]. Such methodologies have been confirmed by Kamal and Jafri (1997) using data of Quetta (Pakistan) [
4]. Torres et al. (2004) used data of five locations in Navarre (Spain) to identify up to 10 different ARMA models [
5].
Models based on artificial neural networks have been compared with ARMA models by Sfetsos (1999) [
6]. Using only data of one month (March), the author has concluded that ANN models outperform the linear models. Using ANN and ARIMA models, More et al. (2003) have forecasted daily and monthly wind speed in India. Results indicate that performances of ANN models are better than ARIMA models [
7]. Using one-month long data (January), Erasmo et al. (2009) concluded that for the particular case of La Venta (México), a model with two layers and three neurons was the best for training and forecasting [
8].
In the following work, we propose HAWS forecasting systems based on adaptive combinations of two alternative (individual) models. The first model is based on ARMA approach, while the second is based on ANN approach. Adaptive combination is done by associating time-varying weights to the alternative models. The time-varying weights are adapted recursively using recursive least square algorithm (RLS). An important motive to combine forecasts from different models is the fundamental assumption that one model cannot identify the true process exactly, but different models may play a complementary role in the approximation of the data generating process, especially in case of doubt about the existence of the best estimator.
Data used in this work are measured over four years (November 2004 to October 2008) by the meteorological station situated at the airport of Adrar, Algeria (27.9° N, 0.3° W). Because of the gaps found in time series, our study is limited only for three months (January, November, and December). Data of the three first years are used to identify ARMA and train ANN models. The four-year data are used as an independent dataset to verify the forecasting ability of the obtained models.
2. ARMA Modeling
ARMA modeling for HAWS consists of three main steps: the first step is the power transformation which is done in order to carry the wind speed from Weibull distribution to Gaussian distribution [
2]. The second step is the standardization step. The purpose of this step is to eliminate non-stationarity due to daily cyclical behaviors. The last step is the identification step which consists of the order determination and parameters estimation.
2.1. Power Transformation
For lot of sites over the word, it has been found that Weibull distribution (Equation (1)) fits the wind distribution the best:
where
is the wind speed,
is the form factor, and
is the scale factor.
In order to fit ARMA models to the HAWS, power transformation of the observed data must be performed. The aim of the power transformation is to approximate the distribution of the wind data from a Weibull distribution to Gaussian one. The power transformation is performed by raising each value of the observed data by the same power index. For more accurate approximation, Daniel and Chen (1991) have proposed to use
as a reference to obtain more accurate index
using skewness statistics is given as [
2]:
where
is the number of considered years and
is the number of samples per month. After iterative calculations using several values of
, the selected
is the one that makes distribution of
symmetric i.e.,
. Values of Weibull parameters, of Dubey’s index
x and asymmetry index m are evaluated for the three proposed months and presented in
Table 1.
2.2. Standarisation
Diurnal non-stationarity can be eliminated by subtraction the hourly averaged wind speed
u(
t) from the transformed HAWS then dividing by the hourly standard deviation
[
5]. Transformed and standardized HAWS (TS-HAWS) are given as:
where
and
It is assumed that and are periodic functions, i.e., , , , and , where d is the number days for given month.
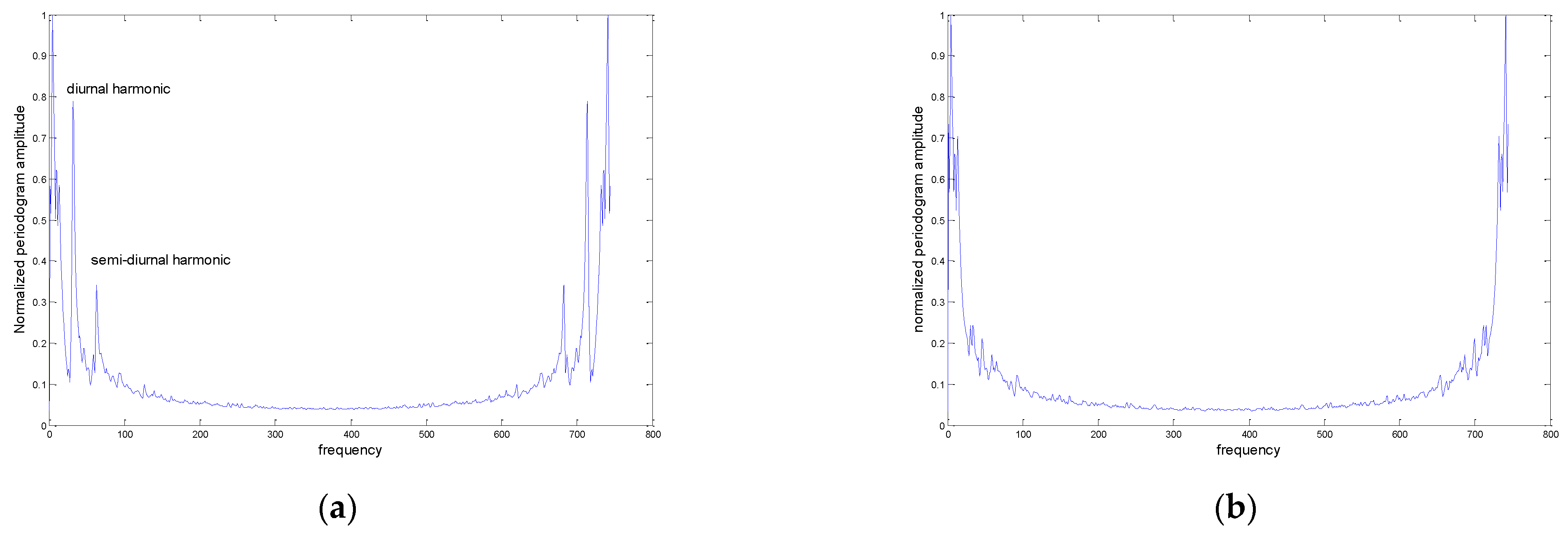
To illustrate the effect of standardization on HAWS, periodograms of original HAWS and TS-HASW are evaluated and presented in
Figure 1. It is clear that diurnal and semidiurnal harmonics present in the periodogram of HAWS in the form of peaks have been canceled from the periodogram of the TS-HAW.
2.3. ARMA Fitting
The following section consists of fitting ARMA models to TS-HAWS. A general model is given as:
where
p is the order of the autoregressive part,
q is the order of the moving part,
L is the lag operator, and
is a white Gaussian noise of zero mean and variance
.
2.3.1. Order Determination
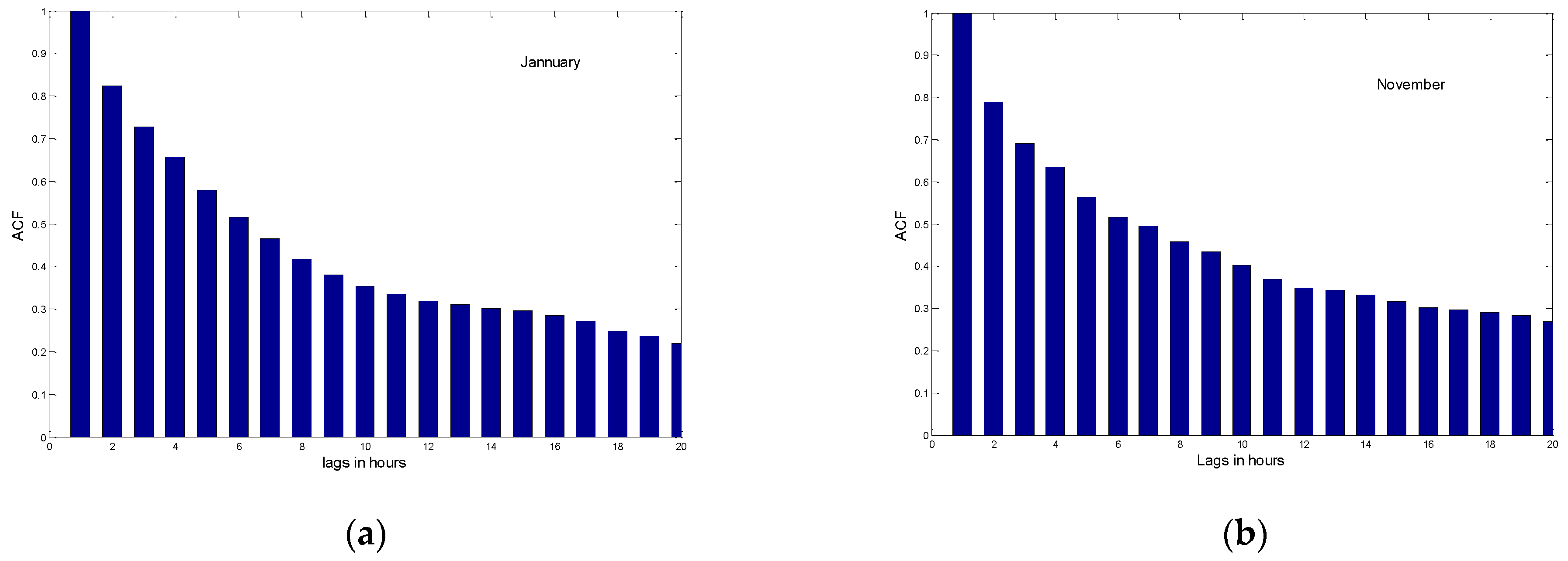
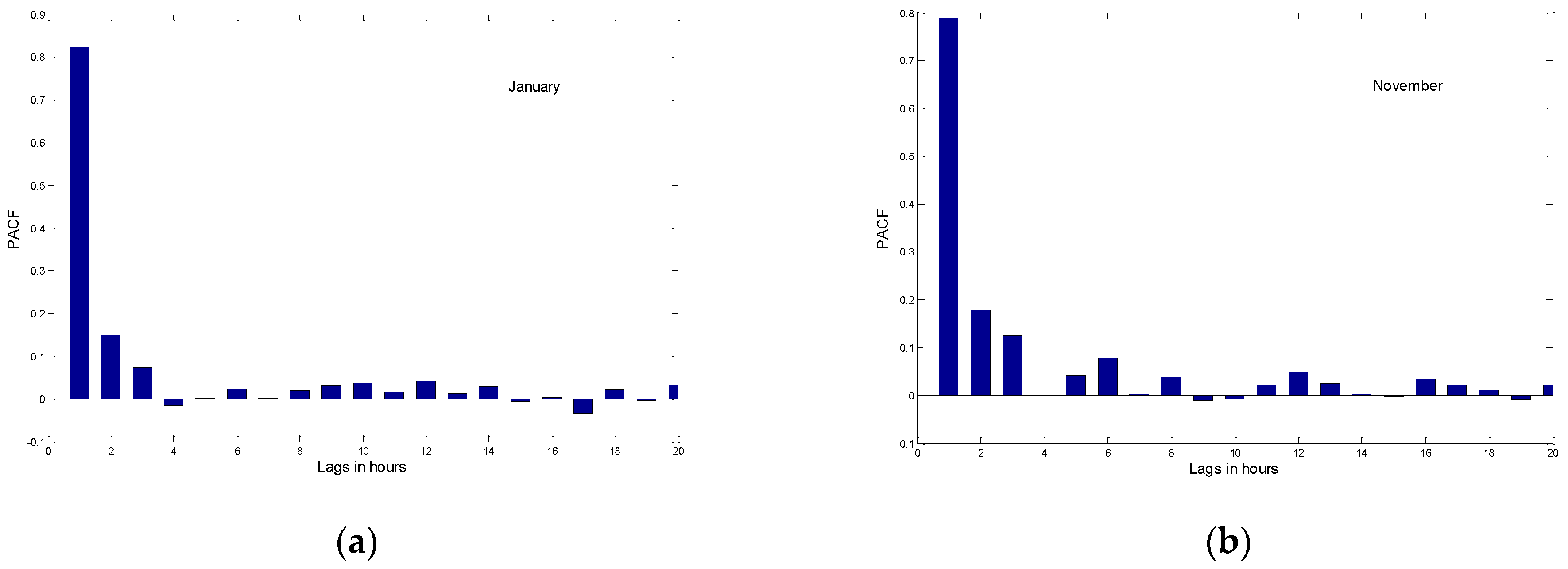
The following section consist of identifying the values of p and q. A pure MA process exhibits a cut of after q lags in the autocorrelation function (ACF); however, for pure AV or mixed ARMA process, the ACF deceases exponentially. Order of AV part can be determined using the partial autocorrelation function (PACF) that cut off after p lags for a pure AV process while it dies gradually in case of pure MA process.
Figure 2 and
Figure 3 present the ACF and PACF, respectively, evaluated for January, November, and December. While the ACFs of the three proposed months decrease exponentially, the PACFs cut almost zeros after the third order; this implies that HAWS can be modeled by a low order
.
ACF and PACF are used to determine an adequate group of ARMA models. Appropriate orders
are determined with the help of an additional criterion, such as Akaike information criterion [Storres].
where
T is the total number of parameters to be estimated.
2.3.2. Parameters Estimation Phase
Once
p and
q have been identified. The model coefficients
and
along the variance of the residuals
can be estimated. The preliminary estimation is done applying the Yule–Walker relations for
, while
values are obtained using Newton–Raphson Algorithm. Final estimation of the parameters using the method of least squares error. Selected models for each month are presented in
Table 1.
Note that for the three studied months, it has been found that
is the best model (
Table 1).
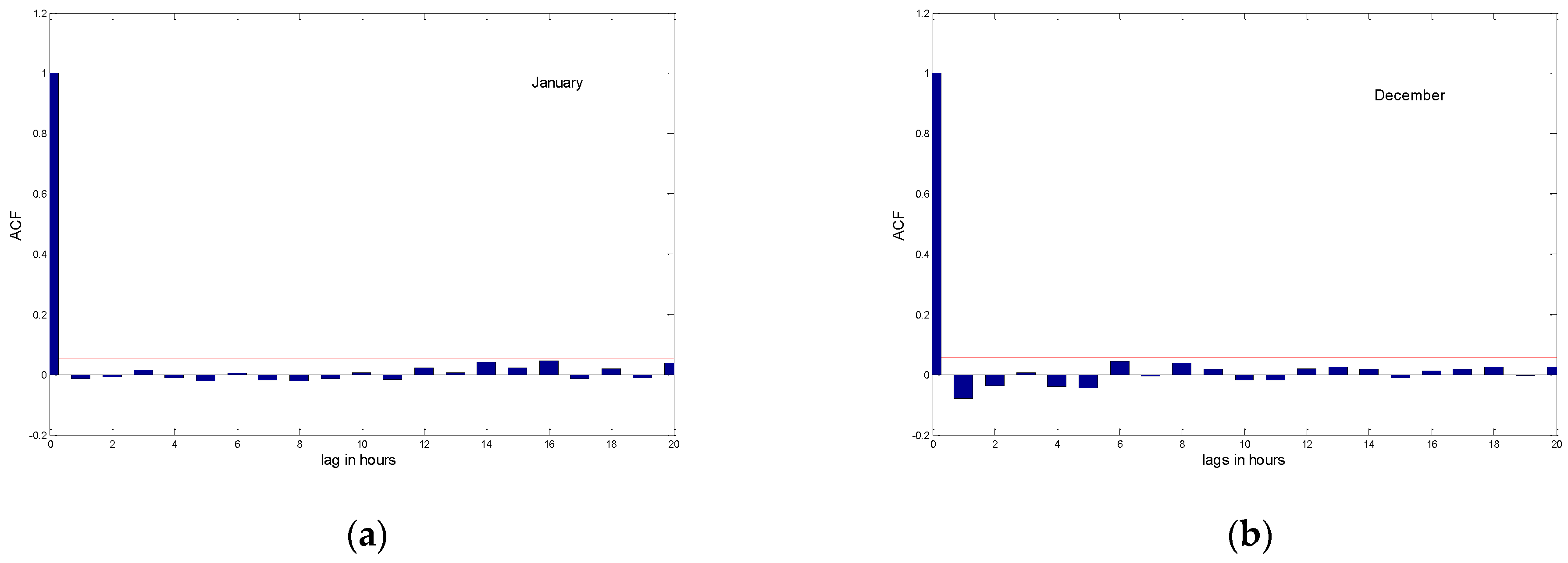
Finally, the models are validated by evaluating the ACF of the residuals. The fitted model can be accepted if the residuals are uncorrelated and normally distributed (
Figure 4).
In order to validate the estimated models, we evaluated the residual autocorrelation functions (
Figure 5). If the residuals are jointly independent, their autocorrelation functions cancel for a lag τ = 0. From
Figure 5, we can see that the residuals are uncorrelated. Thus the models are retained.
3. The Persistent Model
Persistent model as defined in [
5] is given as:
Equation (8) is equivalent to saying that the wind at instant h + t is simply the same as it was at time t. This model is developed by meteorologists as a comparison tool to supplement the other models. The accuracy of this model decreases rapidly with an increase of prediction lead time.
4. Neural Networks
Thus far, we have examined linear prediction with ARMA models, which constitute a mostly linear approach to data analysis. Now, we turn to the more complex neural networks. Neural networks have similar uses to linear prediction filters, and can be applied to the same general set of problems.
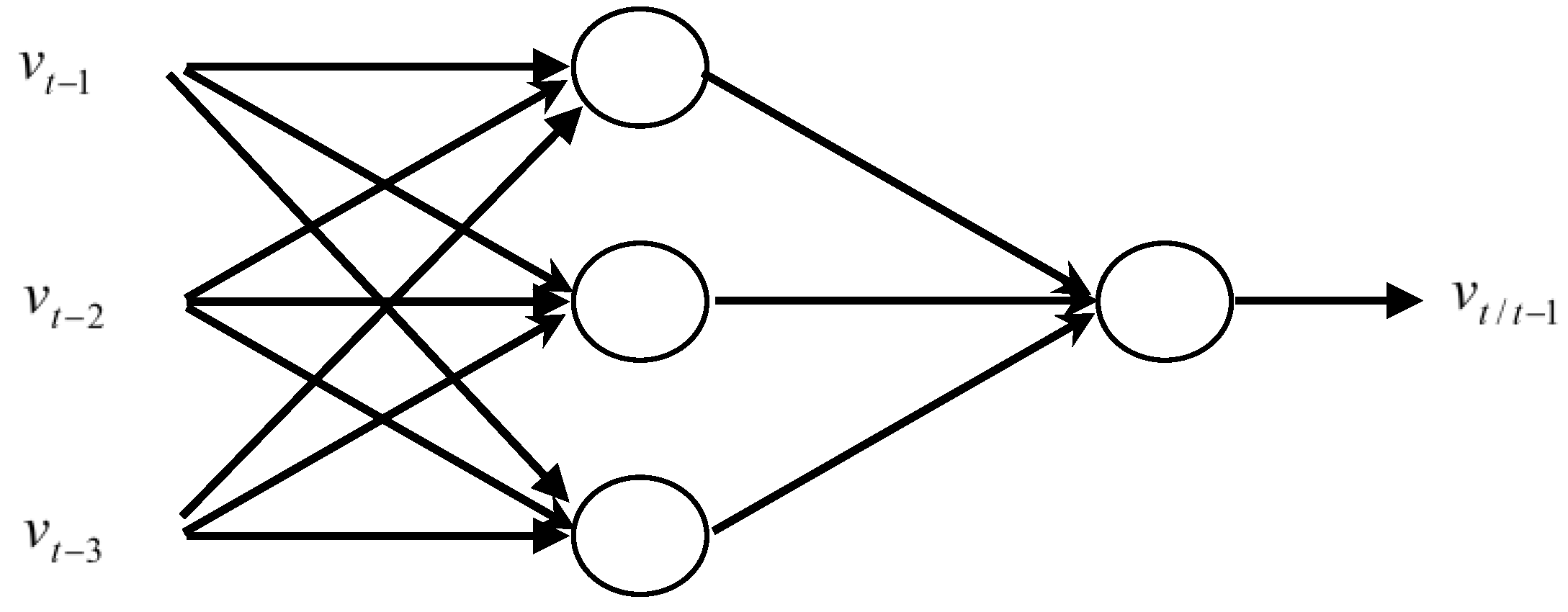
In general, rules to determine the number of inputs, outputs, and layers do not exist. In the following work, and based on results obtained by Sfetsos (1999) and Erasmo (2009) [
9,
10], it was decided to use feed-forward ANN (
Figure 6). In fact, Sfetsos has found that with the Levenberg–Marquard algorithm as a training method, the feed-forward ANN is very adequate to model the wind speed.
The response of the ANN output neuron is:
where
and
are nonlinear sigmoid activation functions.
The proposed ANN networks are trained to predict the wind speed one step ahead. Prediction of h hours in advance is obtained iteratively, i.e., is predicted using , is predicted using , and so on.
5. Forecast Combination
When several candidate models are available to forecast single variable, we can either select the best model or combine them. Combination of forecast is very advised in case of doubt about the existence of the best model. Our purpose in the following section is to build a linear combination
of the competing forecasts as:
where
and
are time varying coefficients that are updated recursively using recursive least square method (RLS). RLS estimation consists of minimizing the cost function given as:
where
,
and
is the forgetting profile. Usually,
, where
is the forgetting factor [
11] The forgetting profile
is the weight associated to the
jth residual and it allows to reduce the importance of old data recursively.
According to [
11], the RLS estimator of
is given as:
where
, which is the one step-ahead prediction error, and
is called the gain matrix or the weighted covariance matrix that can be estimated as [
12]:
The choice of
is very important in the recursive estimation of weights. It is indicated in [
13] that most applications use a constant forgetting factor typically inside
.
6. Results and Discussion
To allow a comparison of models, the evolution of the RMSE is evaluated for the persistent, ARMA, feed-forward, and combined models when forecasts are done 1–7 h in advance.
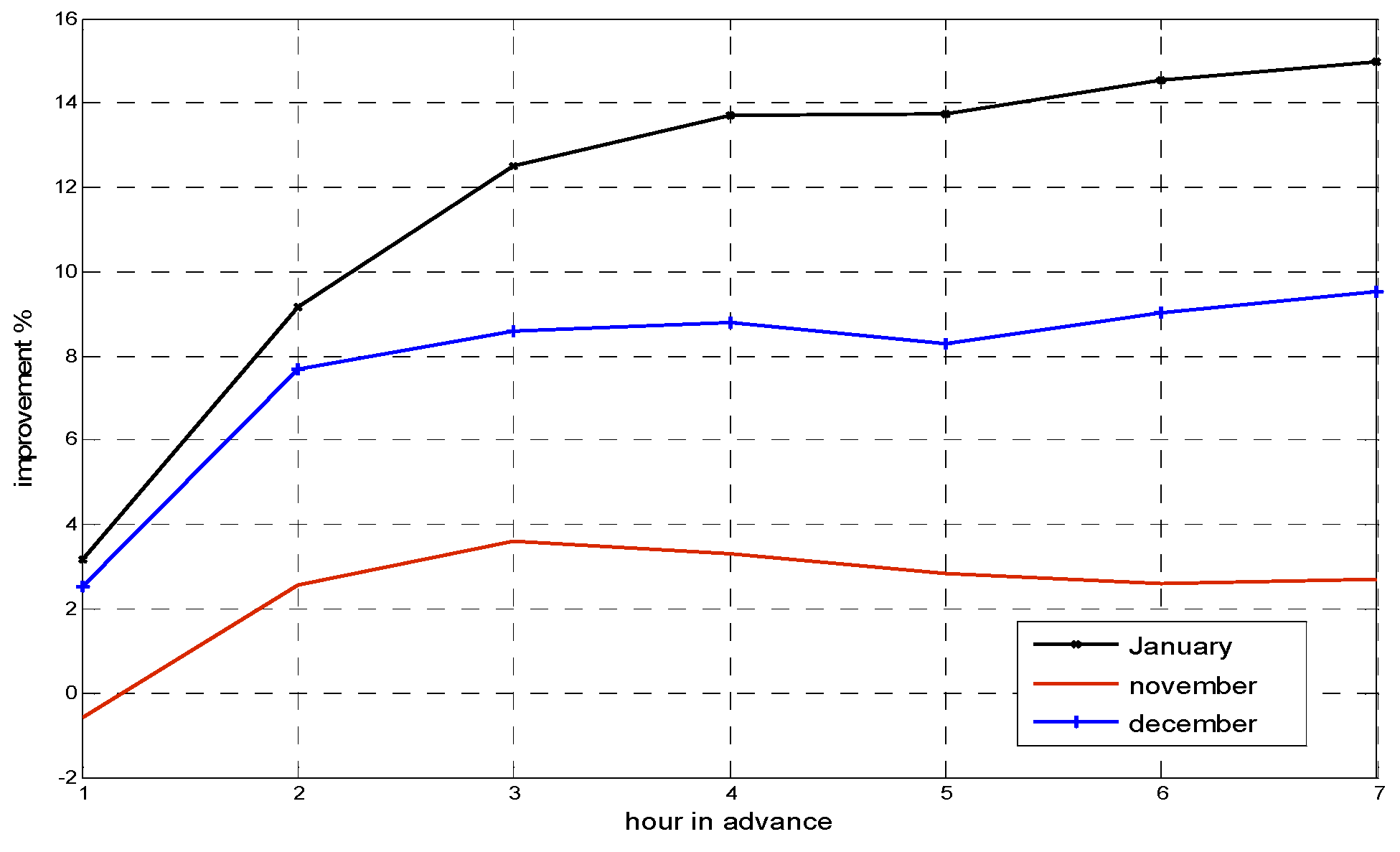
For ANN models, it has been found that forecasting wind speed using TS-HAWS instead of HAWS data yields better performances. As indicated in
Table 2, only in one case, forecasting with HAWS has provided lower RMSE (1 h ahead in November). Improvement of forecasting with TS-HAWS over HAWS is presented in
Figure 6. Maximum improvement of 15% has been obtained in January when forecasting 7 h ahead.
For all the studied cases, we have found that the RMSE of the persistence models are greater than the RMSE of the other models (
Table 3). These results are similar to those obtained by Torres [
5] and Sfetsos [
6], which indicated that ARMA- and ANN-based models provide better forecasts than the persistence models.
In 66.67% of the studied cases, it has been found that ARMA models provide relatively lower RMSE than ANN models (
Table 3 and
Table 4). Evaluation of the forecasting improvement of ARMA models over ANN models varies between −0.61% and 03.49%. These results differ from that obtained by Strores (1999), who has found that ANN models can achieve lower RMSE than ARMA models.
Combined models provide relatively better performances than the ARMA and the ANN models a few hours in advance (1–4 h); however, for long-term forecasting, individual models can provide lower RMSE than the combined models (
Table 3).
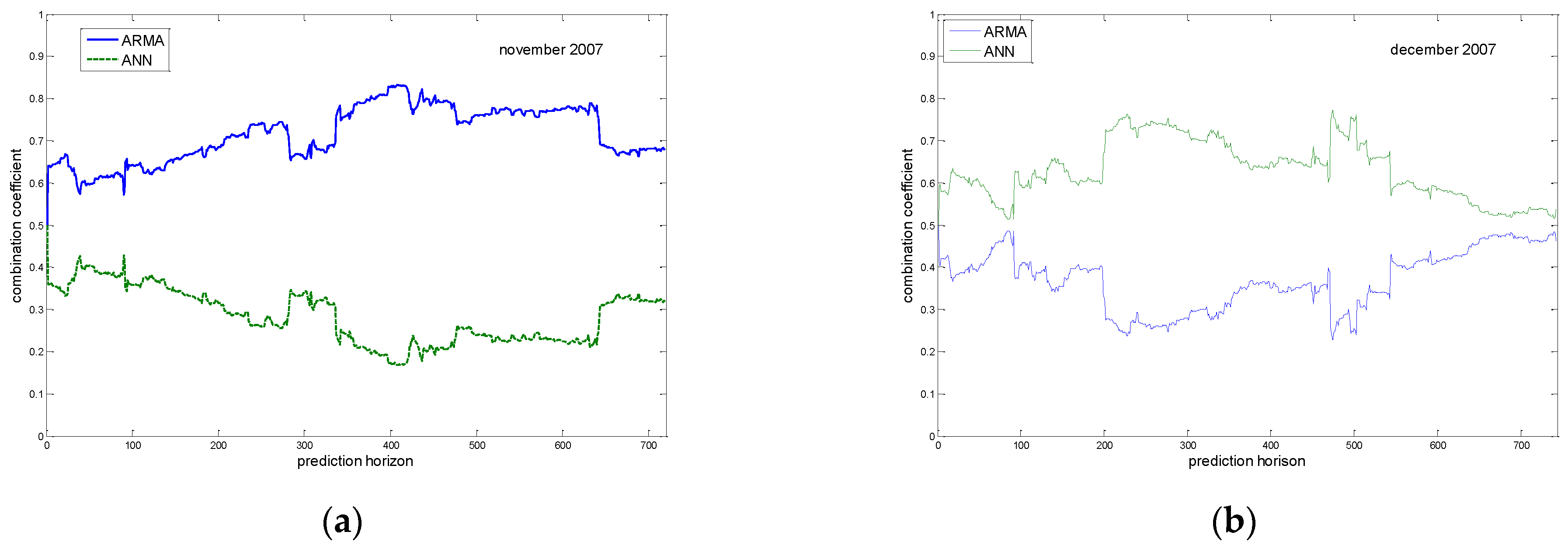
To better understand the role of individual models in the final combination, we have presented in
Figure 7 the variation of the combination coefficients when real wind is measured for November and December 2007. The first 100 wind speed values have been used to initialize coefficients and the covariance matrix.
Figure 7a shows that the coefficient of the ARMA model is greater than the one of the ANN model, which means that the ARMA model is providing lower error for November 2007. In December 2007, and as indicated in
Figure 7b, the ANN model forecasts the wind speed better than ARMA models.
7. Conclusions
In this study, models based on ARMA methodology as well as ANN theory have been proposed to forecast the hourly wind speed. The obtained results have indicated that both ARMA and ANN models are capable to predict wind speed for few hours in advance. Performances comparison between ARMA and ANN models has indicated that their performances are very close.
An adaptive combination of the two proposed approaches has proposed to improve the forecasting performances. The obtained results have indicated that for a few hours in advance, the combined model outperform the individual models.
For ANN modeling, it has been found in this work that the use of the transformed and standardized TS-HAWS provides better results than HAWS.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}