
Feature Fusion for Emotion Recognition †


Abstract
:1. Introduction
2. Feature Extraction and Modeling Technique
2.1. Feature Extraction Technique
2.2. Modeling Technique
3. Proposed Work
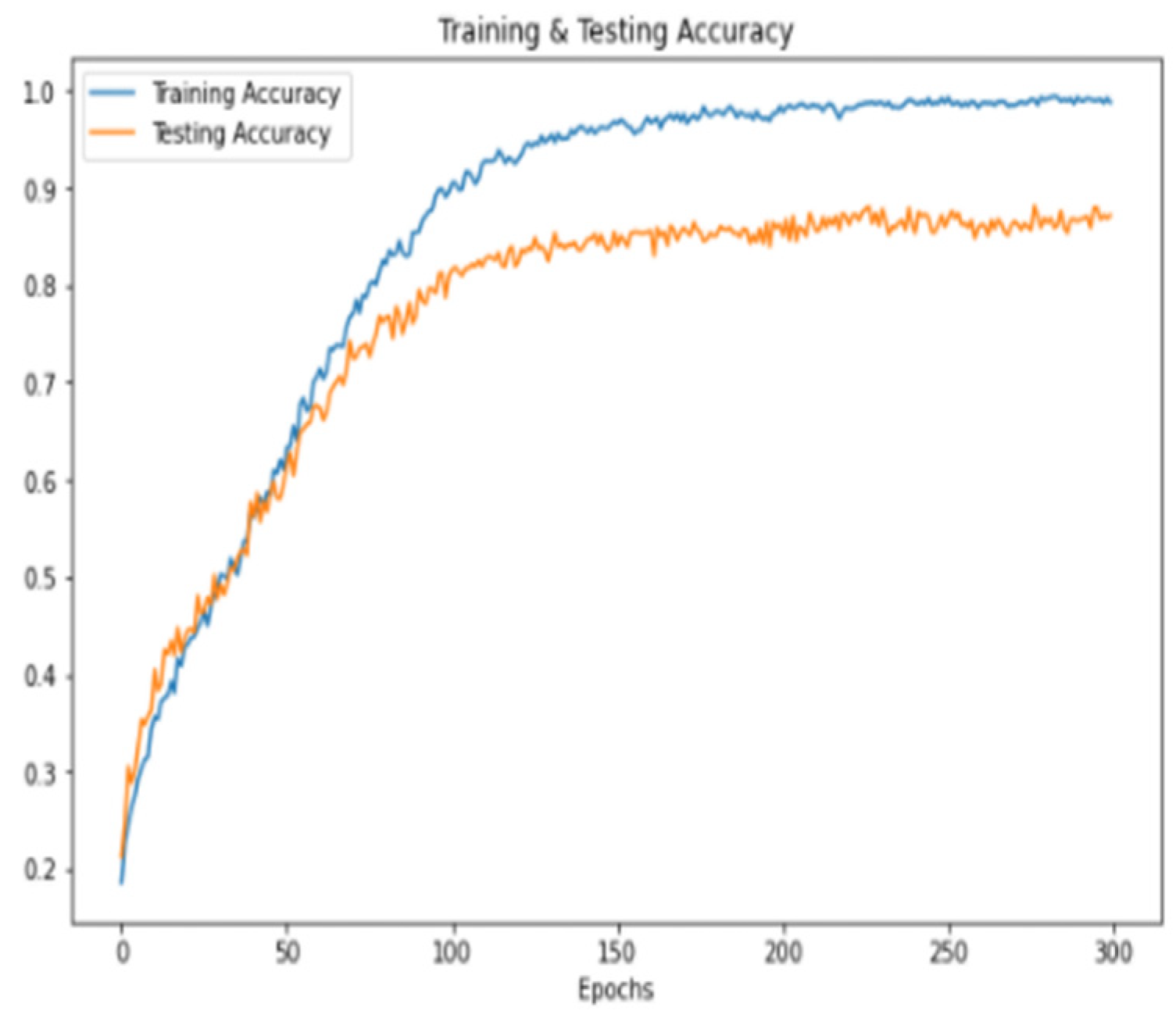
4. Experimental Work and Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, S.; Du, J.; Zhou, H.; Bai, X.; Lee, C.H.; Li, S. Speech Emotion Recognition Based on Acoustic Segment Model. In Proceedings of the 2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP), Hong Kong, China, 24–26 January 2021; pp. 1–5. [Google Scholar]
- Scotti, V.; Galati, F.; Sbattella, L.; Tedesco, R. Combining Deep and Unsupervised Features for Multilingual Speech Emotion Recognition. In Proceedings of the International Conference on Pattern Recognition, Talca, Chile, 7–19 April 2022; Springer: Cham, Switzerland, 2022; pp. 114–128. [Google Scholar]
- Kerkeni, L.; Serrestou, Y.; Mbarki, M.; Raoof, K.; Mahjoub, M.A. Speech Emotion Recognition: Methods and Cases Study. In Proceedings of the 10th International Conference on Agents and Artificial Intelligence, Funchal, Portugal, 16–18 January 2018. [Google Scholar] [CrossRef]
- Moine, C.L.; Obin, N.; Roebel, A. Speaker Attentive Speech Emotion Recognition. In Proceedings of the International Speech Communication Association (INTERSPEECH), Brno, Czechia, 30 August–3 September 2021. [Google Scholar]
- Nema, B.M.; Abdul-Kareem, A.A. Preprocessing signal for Speech Emotion Recognition. Al-Mustansiriyah J. Sci. 2017, 28, 157–165. [Google Scholar] [CrossRef]
- Tripathi, S.; Ramesh, A.; Kumar, A.; Singh, C.; Yenigalla, P. Learning Discriminative Features using Center Loss and Reconstruction as Regularizer for Speech Emotion Recognition. In Proceedings of the Workshop on Artificial Intelligence in Affective Computing, Macao, China, 10 August 2019; pp. 44–53. [Google Scholar]
- Huang, A.; Bao, M.P. Human Vocal Sentiment Analysis; NYU Shanghai CS Symposium: Shanghai, China, 2019. [Google Scholar]
- Mustaqeem; Kwon, S. A CNN-Assisted Enhanced Audio Signal Processing for Speech Emotion Recognition. Sensors 2019, 20, 183. [Google Scholar] [CrossRef] [PubMed]
- Guo, L.; Wang, L.; Dang, J.; Zhang, L.; Guan, H.; Li, X. Speech Emotion Recognition by Combining Amplitude and Phase Information Using Convolutional Neural Network. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar] [CrossRef]
- Johnson, A. Emotion Detection through Speech Analysis; National College of Ireland: Dublin, Ireland, 2019. [Google Scholar]
- Harár, P.; Burget, R.; Dutta, M.K. Speech emotion recognition with deep learning. In Proceedings of the 2017 4th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 2–3 February 2017. [Google Scholar] [CrossRef]
- Liu, G.K. Evaluating Gammatone Frequency Cepstral Coefficients with Neural Networks for Emotion Recognition from Speech. arXiv 2018, arXiv:1806.09010. [Google Scholar]
- Agtap, S. Speech based Emotion Recognition using various Features and SVM Classifier. Int. J. Res. Appl. Sci. Eng. Technol. 2019, 7, 111–114. [Google Scholar] [CrossRef]
- Yoon, S.; Byun, S.; Jung, K. Multimodal Speech Emotion Recognition Using Audio and Text. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar] [CrossRef]
- Tripathi, S.; Kumar, A.; Ramesh, A.; Singh, C.; Yenigalla, P. Deep Learning based Emotion Recognition System Using Speech Features and Transcriptions. arXiv 2019, arXiv:1906.05681. [Google Scholar]
- Zhang, Y.; Du, J.; Wang, Z.; Zhang, J.; Tu, Y. Attention Based Fully Convolutional Network for Speech Emotion Recognition. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018. [Google Scholar] [CrossRef]
- Damodar, N.; Vani, H.Y.; Anusuya, M.A. Voice Emotion Recognition using CNN and Decision Tree. Int. J. Innov. Technol. Explor. Eng. Regul. Issue 2019, 8, 4245–4249. [Google Scholar] [CrossRef]
- Venkataramanan, K.; Rajamohan, H.R. Emotion Recognition from Speech; Cornell University: Ithaca, NY, USA, 2019. [Google Scholar]
- Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech Emotion Recognition with Heterogeneous Feature Unification of Deep Neural Network. Sensors 2019, 19, 2730. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Yu, D.; Tashev, I. Speech Emotion Recognition Using Deep Neural Network and Extreme Learning Machine. In Proceedings of the INTERSPEECH, Singapore, 14–18 September 2014; pp. 223–227. [Google Scholar]

{kind=link}
| Emotions | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Actors | Genders | Sentences | Natural | Calm | Happy | Sad | Angry | Fear | Disgust | Surprised | |
| RAVDASS | 24 | 12 Male 12 Females | 2 | 96 | 192 | 192 | 192 | 192 | 192 | 192 | 192 |
| Emotion | Precision | Recall | F1-Score | Over-All Accuracy |
|---|---|---|---|---|
| Angry | 0.47 | 0.80 | 0.59 | 40.2% |
| Disgust | 0.34 | 0.43 | 0.38 | |
| Fear | 0.35 | 0.44 | 0.39 | |
| Happy | 0.27 | 0.43 | 0.33 | |
| Neutral | 0.72 | 0.23 | 0.35 | |
| Sad | 0.36 | 0.08 | 0.13 | |
| Surprise | 0.43 | 0.51 | 0.47 |
| Emotion | Experiment 1 | Experiment 2 | Experiment 3 | |||
| Features | Classifier | Features | Classifier | Features | Classifier | |
| MFCC, Chroma_Mel, contrast tonnetz | MLP | MFCC | CNN | MFCC, Chroma_Mel | MLP | |
| Accuracy | 39.81% | 42.9% | 41% | |||
| Experiment No. | Feature Extraction | Classification | Accuracy |
|---|---|---|---|
| 1 | MFCC, Chroma_STFT, Mel spectrogram | MLP | 71.07% |
| 2 | MFCC, Chroma_STFT, ZCR, RMS, PF, Mel Spectrogram | MLP | 84.44% |
| 3 | MFCC, Chroma_STFT, ZCR, RMS, PF, Mel Spectrogram | CNN | 87.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmood, A.
Feature Fusion for Emotion Recognition
Mahmood A.
Feature Fusion for Emotion Recognition
Mahmood, Awais.
2023. "Feature Fusion for Emotion Recognition
Mahmood, A.
(2023). Feature Fusion for Emotion Recognition