
Early Detection of Mesothelioma Using Machine Learning Algorithms †



Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Mesothelioma Dataset
3.2. Data Preprocessing
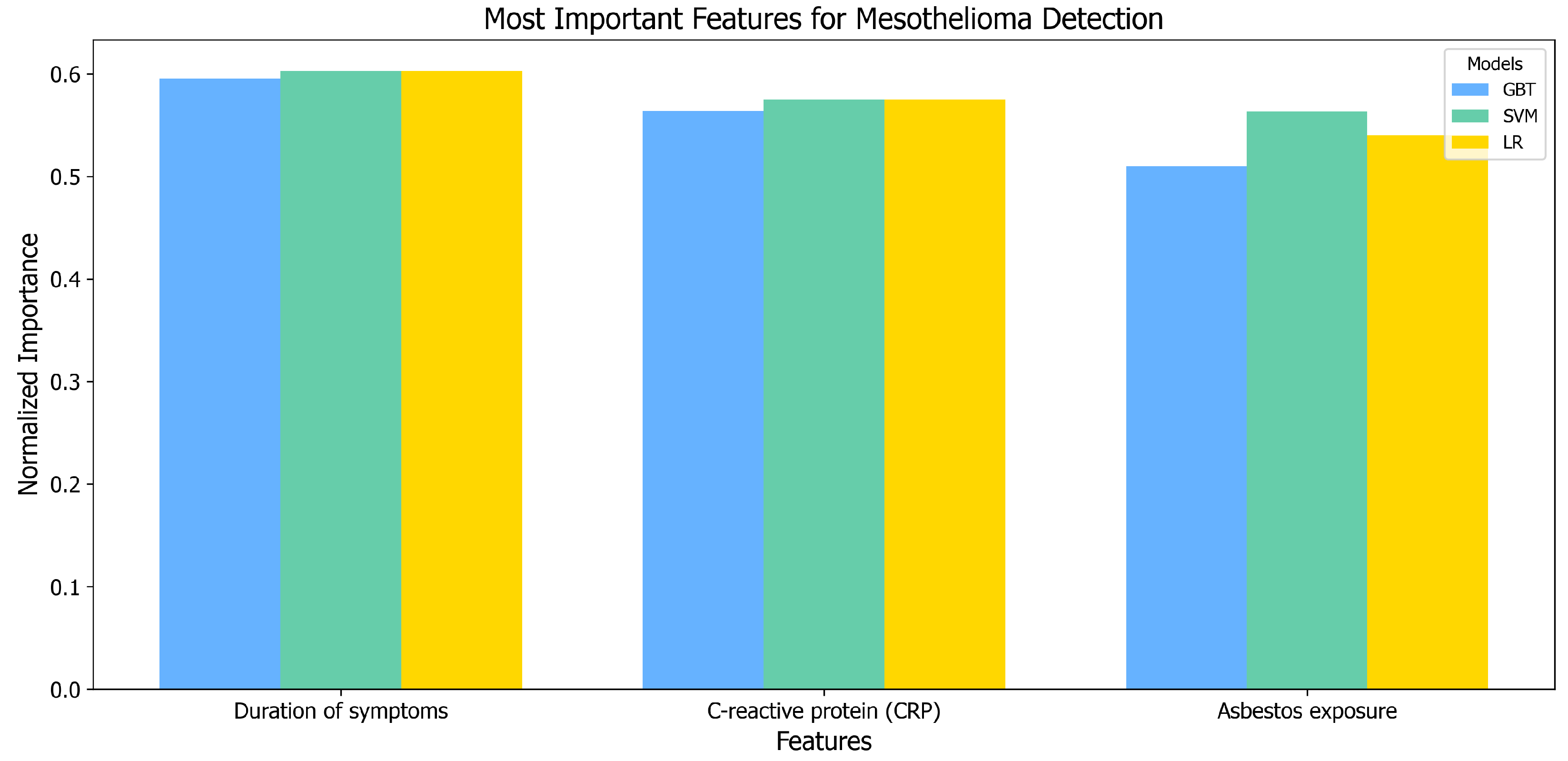
3.3. Feature Selection
3.4. Data Mining
3.4.1. Gradient Boosted Trees
3.4.2. Logistic Regression
3.4.3. Support Vector Machines
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Baumann, F.; Carbone, M. Environmental risk of mesothelioma in the United States: An emerging concern—Epidemiological issues. J. Toxicol. Environ. Health Part B 2016, 19, 231–249. [Google Scholar] [CrossRef] [PubMed]
- Teta, M.J.; Mink, P.J.; Lau, E.; Sceurman, B.K.; Foster, E.D. US mesothelioma patterns 1973–2002: Indicators of change and insights into background rates. Eur. J. Cancer Prev. 2008, 17, 525–534. [Google Scholar] [CrossRef] [PubMed]
- Bibby, A.C.; Tsim, S.; Kanellakis, N.; Ball, H.; Talbot, D.C.; Blyth, K.G.; Maskell, N.A.; Psallidas, I. Malignant pleural mesothelioma: An update on investigation, diagnosis and treatment. Eur. Respir. Rev. 2016, 25, 472–486. [Google Scholar] [CrossRef] [PubMed]
- Deo, R.C. Machine learning in medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [PubMed]
- Pass, H.I.; Levin, S.M.; Harbut, M.R.; Melamed, J.; Chiriboga, L.; Donington, J.; Huflejt, M.; Carbone, M.; Chia, D.; Goodglick, L.; et al. Fibulin-3 as a blood and effusion biomarker for pleural mesothelioma. N. Engl. J. Med. 2012, 367, 1417–1427. [Google Scholar] [CrossRef]
- Creaney, J.; Robinson, B.W. Serum and pleural fluid biomarkers for mesothelioma. Curr. Opin. Pulm. Med. 2009, 15, 366–370. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Emanuel, E.J. Predicting the future—Big data, machine learning, and clinical medicine. N. Engl. J. Med. 2016, 375, 1216. [Google Scholar] [CrossRef] [PubMed]
- Cruz, J.A.; Wishart, D.S. Applications of machine learning in cancer prediction and prognosis. Cancer Inform. 2006, 2, 117693510600200030. [Google Scholar] [CrossRef]
- Caruana, R.; Karampatziakis, N.; Yessenalina, A. An empirical evaluation of supervised learning in high dimensions. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 96–103. [Google Scholar]
- Brusselmans, L.; Arnouts, L.; Millevert, C.; Vandersnickt, J.; van Meerbeeck, J.P.; Lamote, K. Breath analysis as a diagnostic and screening tool for malignant pleural mesothelioma: A systematic review. Transl. Lung Cancer Res. 2018, 7, 520. [Google Scholar] [CrossRef] [PubMed]
- Bononi, I.; Comar, M.; Puozzo, A.; Stendardo, M.; Boschetto, P.; Orecchia, S.; Libener, R.; Guaschino, R.; Pietrobon, S.; Ferracin, M.; et al. Circulating microRNAs found dysregulated in ex-exposed asbestos workers and pleural mesothelioma patients as potential new biomarkers. Oncotarget 2016, 7, 82700. [Google Scholar] [CrossRef] [PubMed]
- Berthold, M.R.; Cebron, N.; Dill, F.; Gabriel, T.R.; Kötter, T.; Meinl, T.; Ohl, P.; Sieb, C.; Thiel, K.; Wiswedel, B. KNIME: The Konstanz Information Miner. In Proceedings of the 31st Annual Conference of the Gesellschaft für Klassifikation e. V., Freiburg, Germany, 7–9 March 2007. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Ramamohan, Y.; Vasantharao, K.; Chakravarti, C.K.; Ratnam, A. A study of data mining tools in knowledge discovery process. Int. J. Soft Comput. Eng. (IJSCE) ISSN 2012, 2, 2231–2307. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]


{kind=link}
{kind=link}
| Model | Accuracy | F1 Score | AUC ROC | MCC 1 |
|---|---|---|---|---|
| GBT | 1.00 | 1.00 | 0.595 | 1.00 |
| LR | 1.00 | 1.00 | 0.603 | 1.00 |
| SVM | 1.00 | 1.00 | 0.603 | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gill, T.S.; Shirazi, M.A.; Zaidi, S.S.H. Early Detection of Mesothelioma Using Machine Learning Algorithms. Eng. Proc. 2023, 46, 6. https://doi.org/10.3390/engproc2023046006
Gill TS, Shirazi MA, Zaidi SSH. Early Detection of Mesothelioma Using Machine Learning Algorithms. Engineering Proceedings. 2023; 46(1):6. https://doi.org/10.3390/engproc2023046006
Chicago/Turabian StyleGill, Taimur Shahzad, Muhammad Ayaz Shirazi, and Syed Sajjad Haider Zaidi. 2023. "Early Detection of Mesothelioma Using Machine Learning Algorithms" Engineering Proceedings 46, no. 1: 6. https://doi.org/10.3390/engproc2023046006
APA StyleGill, T. S., Shirazi, M. A., & Zaidi, S. S. H. (2023). Early Detection of Mesothelioma Using Machine Learning Algorithms. Engineering Proceedings, 46(1), 6. https://doi.org/10.3390/engproc2023046006