
Tackling the Data Sourcing Problem in Construction Procurement Using File-Scraping Algorithms †



{kind=link}
{kind=link}
Abstract
:1. Introduction
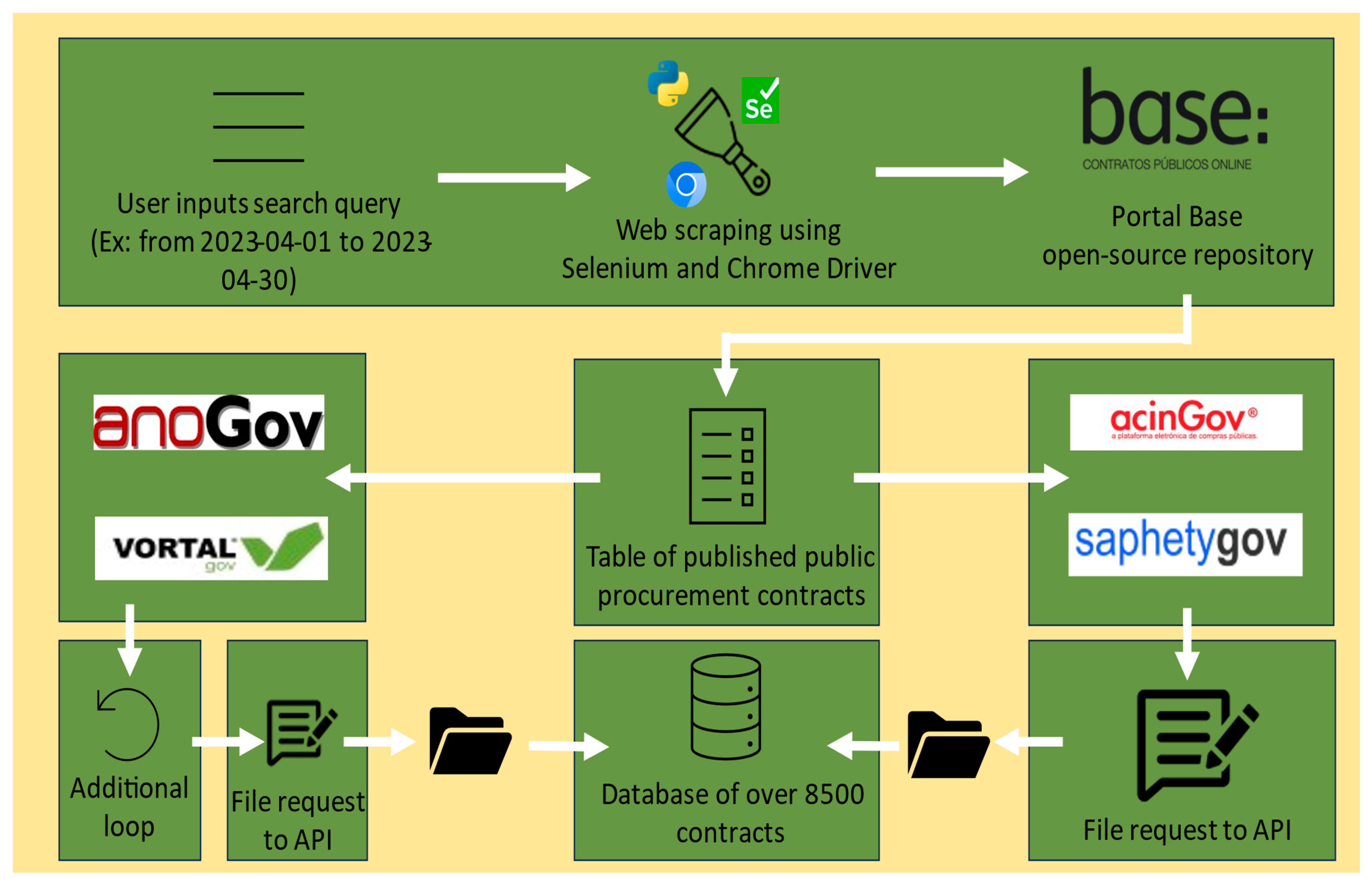
2. Methods
3. The Data
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chung, S.; Moon, S.; Kim, J.; Kim, J.; Lim, S.; Chi, S. Comparing natural language processing (NLP) applications in construction and computer science using preferred reporting items for systematic reviews (PRISMA). Autom. Constr. 2023, 154, 105020. [Google Scholar] [CrossRef]
- Jacques de Sousa, L.; Poças Martins, J.; Santos Baptista, J.; Sanhudo, L. Towards the Development of a Budget Categorisation Machine Learning Tool: A Review. In Proceedings of the Trends on Construction in the Digital Era, Guimarães, Portugal, 7–9 September 2022; pp. 101–110. [Google Scholar]
- Sepasgozar, S.M.E.; Davis, S. Construction Technology Adoption Cube: An Investigation on Process, Factors, Barriers, Drivers and Decision Makers Using NVivo and AHP Analysis. Buildings 2018, 8, 74. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Shahzad, D. Big Data in Construction: Current Applications and Future Opportunities. Big Data Cogn. Comput. 2022, 6, 18. [Google Scholar] [CrossRef]
- Elmousalami, H.H. Data on Field Canals Improvement Projects for Cost Prediction Using Artificial Intelligence. Data Brief 2020, 31, 105688. [Google Scholar] [CrossRef] [PubMed]
- Phaneendra, S.; Reddy, E.M. Big Data—Solutions for RDBMS Problems—A Survey. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 3686–3691. [Google Scholar]
- Jacques de Sousa, L.; Martins, J.; Baptista, J.; Sanhudo, L.; Mêda, P. Algoritmos de classificação de texto na automatização dos processos orçamentação. In Proceedings of the 4° Congresso Português de “Building Information Modelling”, Braga, Portugal, 4–6 May 2022; pp. 81–93. [Google Scholar]
- Xu, W.; Sun, J.; Ma, J.; Du, W. A personalised information recommendation system for R&D project opportunity finding in big data contexts. J. Netw. Comput. Appl. 2016, 59, 362–369. [Google Scholar] [CrossRef]
- Instituto dos Mercados Públicos, do Imobiliário e da Construção. Portal Base. Available online: https://www.base.gov.pt/ (accessed on 15 April 2023).
- DRE. Diário da Républica Electónico. Available online: https://dre.pt/dre/home (accessed on 6 January 2023).
- Jacques de Sousa, L.; Poças Martins, J.; Sanhudo, L. Base de dados: Contratação pública em Portugal entre 2015 e 2022. In Proceedings of the Construção 2022, Guimarães, Portugal, 5–7 December 2022. [Google Scholar]
- Jacques de Sousa, L.; Poças Martins, J.; Sanhudo, L. Portuguese public procurement data for construction (2015–2022). Data Brief 2023, 48, 109063. [Google Scholar] [CrossRef] [PubMed]
- Selenium. Available online: https://www.selenium.dev/ (accessed on 10 July 2023).
- Chrome Driver. Available online: https://chromedriver.chromium.org/downloads (accessed on 10 July 2023).
- Acingov. Available online: https://www.acingov.pt/acingovprod/2/index.php/ (accessed on 10 July 2023).
- Saphetygov. Available online: https://gov.saphety.com/bizgov/econcursos/loginAction!index.action (accessed on 10 July 2023).
- Vortalgov. Available online: https://www.vortal.biz/vortalgov/ (accessed on 10 July 2023).
- Anogov. Available online: https://anogov.com/r5/en/ (accessed on 10 July 2023).
- Jacques de Sousa, L.; Martins, J.; Sanhudo, L. Framework for the Automation of Construction Task Matching from Bills of Quantities using Natural Language Processing. In Proceedings of the 5th Doctoral Congress in Engineering (DCE 23′), Porto, Portugal, 15–16 June 2023. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jacques de Sousa, L.; Poças Martins, J.; Sanhudo, L. Tackling the Data Sourcing Problem in Construction Procurement Using File-Scraping Algorithms. Eng. Proc. 2023, 53, 34. https://doi.org/10.3390/IOCBD2023-15190
Jacques de Sousa L, Poças Martins J, Sanhudo L. Tackling the Data Sourcing Problem in Construction Procurement Using File-Scraping Algorithms. Engineering Proceedings. 2023; 53(1):34. https://doi.org/10.3390/IOCBD2023-15190
Chicago/Turabian StyleJacques de Sousa, Luís, João Poças Martins, and Luís Sanhudo. 2023. "Tackling the Data Sourcing Problem in Construction Procurement Using File-Scraping Algorithms" Engineering Proceedings 53, no. 1: 34. https://doi.org/10.3390/IOCBD2023-15190
APA StyleJacques de Sousa, L., Poças Martins, J., & Sanhudo, L. (2023). Tackling the Data Sourcing Problem in Construction Procurement Using File-Scraping Algorithms. Engineering Proceedings, 53(1), 34. https://doi.org/10.3390/IOCBD2023-15190