Abstract
Drowsiness driving poses a significant risk to road safety, necessitating effective drowsiness detection models. Most of the prior research has primarily relied on composite facial-based features, mainly focusing on the mouth and/or eye states, to identify drowsiness status. However, these models tend to overlook crucial information from input signals, resulting in suboptimal detection accuracy. Moreover, the absence of suitable algorithms and techniques for extracting other essential facial features, such as the eyebrow and nostril, further impacts the accuracy of drowsiness detection. To address these limitations, this study introduces an innovative algorithm and a technique for extracting drowsiness-related information from the eyebrow and nostril regions. Additionally, we propose a method, leveraging four composite facial-based drowsiness features; eyebrow, nostril, eye, and mouth states as inputs to a Convolutional Neural Network (CNN). A novel multilevel feature fusion method is employed to effectively combine the deep representations of these drowsiness-related features. The final step involves employing a Long-short-term memory (LSTM) recurrent neural network to classify the drowsiness status of drivers. Our proposed model is rigorously evaluated using the National Tsing Hua University drowsy driver detection (NTHU-DDD) video dataset. The experimental results demonstrate an impressive accuracy in different scenarios, and the accuracy result reached 0.973, showcasing the effectiveness of our approach in enhancing drowsiness detection accuracy and promoting road safety.
1. Introduction
Drowsiness driving refers to operating a motor vehicle while impaired cognitively due to insufficient sleep, tiredness, or exhaustion. It has the potential to impair the human brain to a similar extent as intoxication can. According to [], drowsiness impedes the driver’s responsiveness and information handling capacity, thus making the driver lose control of the vehicle and eventually stray from the path or cause a tail pursuit.
When a driver is in a drowsy state, his reduced ability to control the motor vehicle can lead to catastrophic accidents, potentially resulting in loss of life or severe injuries. He will also lose the perception of traffic flow, the ability to control the vehicle and the prediction of the dangerous situation all have a significant downward trend, which could lead to a sharp increase in the probability of traffic accidents [].
Recently, multiple safety driving assistant models have been proposed to scale back the risk of traffic accidents caused by drowsy drivers. Statistics have shown driving in a drowsiness state to be the leading cause of vehicle accidents [,].
A study by the National Highway Traffic Safety Administration (NHTSA) in 2016 revealed that the United States experienced 7.277 million traffic accidents, which resulted in 37,461 fatalities and 3.144 million injuries. Among these incidents, it is estimated that drowsy driving contributed to approximately 20% to 30% of these occurrences []. Furthermore, driving under the influence of drowsiness is the primary cause of over 100,000 road accidents annually, constituting approximately 2.2% death rate globally [].
Most existing models and algorithms to detect drowsiness driving are using machine learning techniques like classification, regression, clustering, and filtering techniques. The nature of the implemented models leads to the techniques being either in the neural network category (i.e., deep learning) or computer vision-based classifiers category []. The work of [] found that many studies on drowsiness driving detection focus on a single facial feature to determine a driver’s drowsiness status, neglecting the significance of considering the relationship between other facial-based drowsiness features and their timing. So, this limited approach reduces the accuracy of drowsiness detection. Even though [], used two composite facial features (eye and mouth states), these features alone were still insufficient for achieving optimal drowsiness detection accuracy, as such it is possible to improve accuracy by incorporating other important composite facial-based drowsiness features. However, a significant challenge is the lack of appropriate algorithms to accurately classify some of the drowsiness features from the driver’s facial landmark (i.e., eyebrows and nostrils), therefore, it is needed to design algorithms suitable for classifying the composite drowsiness features of the eyebrows and nostrils and to utilize their properties to further improve the detection accuracy. This paper tends to address the drawback of non-optimal drowsiness detection accuracy through the following contributions:
- First, Algorithms to extract the deep composite facial-based drowsiness features of eyebrows and nostrils are presented.
- A multilevel features fusion model suitable for combining the deep composite facial-based drowsiness features representation of the eyebrows, nostrils, mouth, and eyes states is proposed.
- Lastly, the fused deep representation of the eyebrows, nostrils, mouth, and eyes states is sent into the Long-short term memory (LSTM) recurrent neural network to classify the drowsiness status of the driver.
The remaining parts of this paper are organized as follows. Section 2 summarizes the related literature. Section 3 explains the proposed drowsiness-driving detection model. In Section 4, experimentation and the resulting experimental outcomes are detailed to assess the model’s performance. Section 5 offers a conclusion and explores potential future research directions.
2. Review of Related Work
Researchers from various domains have achieved remarkable progress in identifying drowsiness levels, different ideas of how the level of drowsiness will be measured have been introduced, and several types of systems that can measure the extent of drowsiness in humans have been developed. Some systems are wearable, some use a camera to capture facial and eye movement while some use the state variable of the vehicle and many more [,].
A study by [], has proposed a model that estimates driver sleepiness by utilizing a combination of factored bilinear features and a long-term recurrent convolutional network. Additionally, they developed two distinct deep convolutional neural networks to extract the deep features of the driver’s eyes and mouth and to detect their states. Then a factorized bilinear feature fusion method is used to fuse the deep feature representation of the eyes and mouth. A recurrent network LSTM is used to model the variation of the driver’s drowsiness to provide detection of the driver’s drowsiness under various driving conditions.
Methods based on the driver’s facial behavior mainly examine the facial features to identify drowsiness driving, such as PERCLOS (eyelid closure rate surpassing the pupil over a certain time), mouth opening, head positioning, facial expressions, and more [,]. This method does not disrupt the driving experience, making it more acceptable to the drivers. A study by [], proposed a three-step system. It first identifies and tracks the eyes. It then performs image filtering to analyze the performance of the eyes under varying lighting conditions. The system relies on PERCLOS measurements to evaluate eye closure.
An automated yawn detection technique based on extracting the geometric and visual features of the eyes and mouth regions is proposed by []. This approach can effectively identify yawns that occur with or without hand covering. The work by [,], affirms that a solitary feature alone cannot efficiently predict drowsiness occurrence. Instead, combining various sources of non-invasive drowsiness features to create a standardized benchmark for detecting drowsiness occurrence would yield higher accuracy and reliability.
3. Proposed Work
This section introduces the dataset used in the conduct of this study and also describes how the proposed model works.
3.1. Dataset Description
The National Tsing Hua University drowsy driver detection (NTHU-DDD) dataset is a dataset collected by the NTHU computer laboratory to train and evaluate driver drowsiness detection models. The dataset recorded the driver’s facial states and changes through the use of visual sensors in a simulated driving environment. It consists of both male and female drivers, with various facial characteristics, different ethnicities, and 5 different scenarios (noglasses, glasses, night_noglasses, night_glasses, sunglasses), each scenario contains 4 videos with different situations and their corresponding annotation files.
Statistical Description of the Dataset
Table 1 describes the features in the National Tsing Hua driver drowsiness detection dataset, indicating the facial expressions and characteristics.

Table 1.
NTHU-DDD Statistical Description.
Table 1 above highlighted the dataset statistics, which helps in understanding the distribution and characteristics of different facial features in the dataset. For example, the “mean” gives an average value, and the “percentiles” provide insights into the range of values. It encompasses a diverse dataset statistic related to facial features, including variations in eye states, mouth actions, nostril conditions, eyebrow positions, drowsiness indications, and the presence of glasses, especially during night conditions. Additionally, it reflects variability in the presence of sunglasses across different instances.
3.2. Proposed Model
Figure 1 represents the proposed model, which works in five major stages; dataset acquisition, drowsiness features extraction, drowsiness features fusion, driver drowsiness detection, and drowsiness detection performance evaluation.
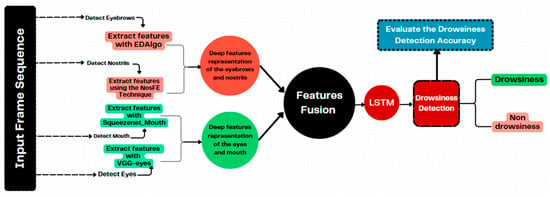
Figure 1.
The Proposed Model.
3.2.1. Drowsiness Features Extraction
To effectively extracts the deep feature representation of the driver’s eyebrows, nostrils, eyes, and mouth from a given consecutive frames in NTHU-DDD dataset. We detect different alterations and changes in facial expressions, specifically focusing on the region of interest (i.e., eyebrows, nostril, eyes, and mouth). These alterations are considered as modifications in shape or movement on driver’s face. In response to these changes, we proposed two techniques; EDAlgo and NoSFE techniques to extract the drowsiness features of the eyebrows and nostrils. Also, we adopted additional two methods Squeezenet_Mouth and VGG_eyes to extract drowsiness features of mouth and eyes respectively, enabling the identification of the driver’s state.
- (a)
- Eyebrows States Extraction
To derive the deep feature representation of the eyebrows, we have implemented Eyebrow feature extraction algorithm we named EDAlgo illustrated in Algorithm 1 which analyse facial landmarks from the processed frames using the Dlib library to obtain the state of eyebrows (raised or lowered). EDAlgo takes the processed frames as input and reads it in gray-scale and uses the face detector to identify the faces. For each detected face, the algorithm predicts its facial landmarks, specifically focusing on the right and left eyebrow regions. The eyebrow states is determined based on the position of certain landmarks. The algorithm returns 1 if both the eyebrows are raised (i.e., they leave their normal landmark states) and 0 otherwise. Figure 2 depicts the execution flow of the proposed algorithm.
| Algorithm 1 EDAlgo Pseudo-code |
| 1: Declare the state variables Raised, Lowered |
| 2: Set a letter to represent each of the eyebrows: L(left eyebrow), R(right eyebrow) |
| 3: Assign the derived values to represents L, R |
| 4: Declare and assign a numerical lalue for LI,RI from left to right |
| 5: Get all the processed frames that are represented in a Cartesian coordinates |
| 6: for frame in list(frames): |
| 7: shape ← predictor(gray_image, frame) |
| 8: shape ← face_utils.shape_to_np(shape) |
| 9: for feature in list(shape): |
| 10: (x,y) ← feature_describe(feature) |
| 11: detected_feature[feature] ← shape[x:y] |
| 12: Get the lowest point on the y-axis between the edge coordinates LI1 and LI5 |
| 13: Set Min ← min(L11.y, L15.y) |
| 14: Get the lowest point on the y-axis between the edge coordinates RI1 and RI5 |
| 15: Set Min ← min(R11.y,R15.y) |
| 16: if L13.y and R13.y >= Min: |
| 17: return 1 //Eyebrow is at raised state |
| 18: else: |
| 19: return 0 //Eyebrow is at lowered state |
| 20: Write all the acquired states into a file |
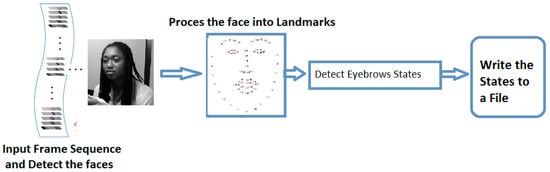
Figure 2.
The Execution flow of the Proposed EDAlgo.
EDAlgo depicted in Figure 3 aimed at extracting eyebrow states (raised or lowered) within processed facial landmarks, specifically focusing on the region of interest, corresponding to the eyebrows. The algorithm takes processed facial landmarks as input and generates an annotated list highlighting the changes in the eyebrow region, indicating whether they are raised or lowered.
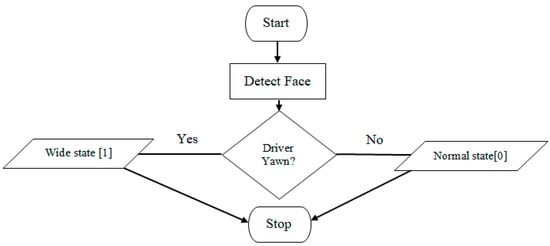
Figure 3.
Flowchart of the NosFE Feature Engineering.
- (b)
- Nostrils States Extraction
To effectively extract the nostril drowsiness states, a NosFE feature engineering technique was used, it is studied by [] that, behavioral characteristics of the human face when yawning are; (a) the mouth is wide open. (b) the eyes tend to be shut or dim (c) the nostrils are opened wider and pushed upwards.
Based on this assertion, nostril drowsiness features are derived using the NosFE feature creation technique of feature engineering as stated earlier. The nostril features were derived in two states; Normal state: This is the resting state of the face when the driver does not yawn (mouth is closed) and this is annotated by 0; and Wide state: This is the state of the nostril when the driver is yawn (mouth is wide open), annotated by 1. Figure 3 depicted the flowchart of the proposed NosFE technique.
- (c)
- Mouth and Eyes States Extraction using Adopted Methods
To extract the drowsiness features of mouth and eyes from driver’s facial face, we adopted the methods used by []. They used SqueezenetMouth to extract mouth drowsiness states and VGG-Eyes to extract eyes drowsiness states. Both of the methods leverage modifications to well-established network architectures, emphasizing sequential processing and effective feature extraction. The study underscores the significance of identifying critical driver states, such as drowsiness, to enhance safety in driving scenarios.
3.2.2. Drowsiness Features Fusion
The proposed multilevel feature fusion method combines information from different facial regions (eyebrows, eyes, nostrils, and mouth) to improve the detection of drowsiness in drivers. In the previous stage, two models were trained to capture detailed features from the eyes and mouth. Now, the fusion method extends this approach to include additional facial regions. Instead of focusing only on eyes and mouth, the new method considers features from eyebrows, eyes, nostrils, and mouth. It combines the information from these regions to create a comprehensive representation of the driver’s facial state. The fusion process involves blending the deep features extracted from each region, allowing it to understand correlations and nuances across the entire face. To prevent the model from becoming too complex and prone to over-fitting, we applied matrix decomposition technique, which breaks down the information into simpler components, making it more manageable and less likely to lead to computational challenges. Finally, an average pooling layer is used to gather relevant information and create a summary that aids in making predictions about the driver’s drowsiness.
3.2.3. Driver Drowsiness Detection Using LSTM
To classify driver drowsiness, we used a two layered LSTM architecture with 8 units to extract changes in the drowsiness state from the fused feature sequences at the frame level. Subsequently, the output from the LSTM unit was fed into a Hard-sigmoid layer to accurately predict the driver’s level of drowsiness.
3.2.4. Drowsiness Detection Performance Evaluation
The comparative assessment of the detection accuracy of our proposed model against existing state-of-the-art models, all trained using the same dataset, holds paramount significance in advancing the field of road safety. This analysis serves as a measure test for the effectiveness our approach. It also establishes benchmarks, guides future research, and promotes transparency, contributing to the ongoing evolution of road safety technologies.
3.3. Model Layering Architecture
The proposed model was trained with a two-layer Long-Short-Term Memory structure as depicted in Figure 4. The input layer uses a sigmoid activation function as described in Equation (1) with 8 units while the output layer uses a Hard-sigmoid activation function described in Equation (2) with one unit. The model was compiled with a Binary cross-entropy loss function in Equation (3) and a stochastic gradient descent (SGD) optimizer.
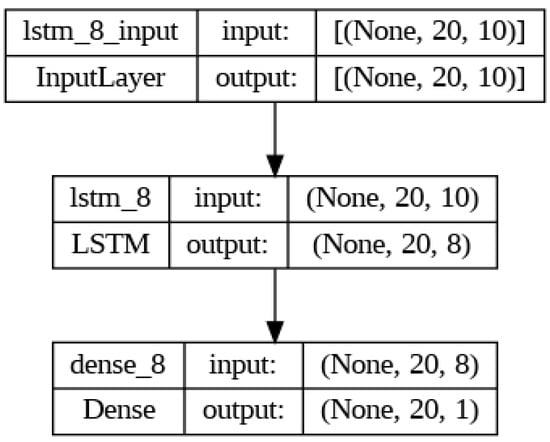
Figure 4.
The LSTM Architecture.
The sigmoid activation function used to receive the input units is described in Equation (1) below.
The Hard-sigmoid activation function used to present the output unit is described in Equation (2) below.
The Binary cross-entropy loss function used to compile the model is described in Equation (3) below.
From Figure 4, The LSTM architecture utilized in the model consists of a single LSTM layer with 8 units, employing a sigmoid activation function. The input shape specified for the LSTM layer is (20, 10), indicating that it expects input sequences of length 20 with each time step comprising 10 features. Additionally, it returns sequences which means it is followed by another layer that can accept sequences as input.
4. Discussion of Results
This section is devoted to the presentation and discussion of the experimental results.
4.1. Implementation Environment
The work was implemented on the Google Colab environment and was stitched with Python, pandas, and Tensorflow libraries.
4.2. Proposed Model Training
The training outcomes of the proposed model reveal a compelling progression in performance across 20 epochs. We concatenated the training and validation data to have a training and validation dataset of 380,880 rows of which 77% was used for training and the remaining 23% for validation. The dataset reshaped, shuffled and further batched in twentieth (20) for the training.
4.3. Proposed Model Performance
The National Tsing Hua University drowsy driver detection (NTHU-DDD) was used to score the correctness of our model. The dataset was split by dividing the dataset between each state. Then 10% of each state was taken for evaluation and 90% for training and validation. The splitting occurs as follows:
- Glasses: 106,918 total rows, 10,691 for evaluation, 96,226 for training and validation
- Noglasses: 106,240 total rows, 10,624 for evaluation, 95,616 for training and validation.
- Sunglasses: 108,023 total rows, 10,802 for evaluation, 97,220 for training and validation.
- Nightglasses: 49,682 total rows, 4968 for evaluation, 44,713 for training and validation.
- Night_noglasses: 52,408 total rows, 5240 for evaluation, 47,167 for training and validation.
All training and validation data were concatenated to give a training and validation dataset of 380,880 rows of which 77% (293,277 rows) was used for training and 23% (87,602 rows) for validation. It was then reshaped into three dimensions and then converted to a tensor using the Tensor function after which it was shuffled and further batched in preparation for the training.
To evaluate the proposed model performance, Table 2 provides a comprehensive comparison of the proposed model with state-of-the-art models, all trained on the NTHDDD dataset. Their key distinction lies in the fact that the proposed model utilizes multiple facial features (eyebrows, eyes, nostrils, and mouth states), setting it apart from existing models that rely on either one or two facial features (eyes and/or mouth states).
Table 2.
Accuracy Results Comparison.
In Table 2, the proposed model achieves a significantly higher accuracy of 0.96 compared to the state-of-the-art models (ranging from 0.638 to 0.802), showcasing its superior capability to detect drowsiness when drivers are not wearing glasses. The proposed model outperforms all state-of-the-art models with an exceptional accuracy of 0.997, surpassing the range of 0.623 to 0.774 observed in the other models. This highlights its robustness in accurately detecting drowsiness even when drivers wear normal glasses. Again, it achieves a remarkable accuracy of 0.989, outperforming existing models that range from 0.570 to 0.709. This underscores its effectiveness in handling drowsiness detection under various eyewear conditions. It also demonstrates a high accuracy of 0.972, surpassing the range of 0.630 to 0.785 observed in state-of-the-art models. Its effectiveness in low light conditions without glasses is notably superior here. Finally, it achieves a strong accuracy of 0.951, outperforming the range of 0.602 to 0.741 seen in other models. This emphasizes its robust performance in night time scenarios even when drivers wear glasses (Figure 5).
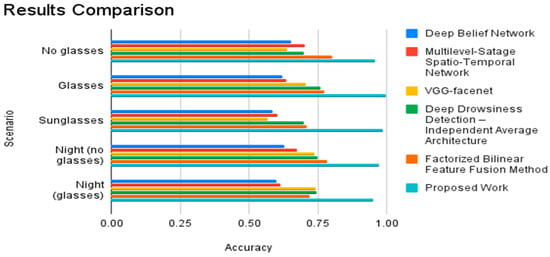
Figure 5.
Average accuracy results of different drowsiness detection models and the proposed work.
5. Conclusions and Future Work
In conclusion, the proposed model, distinguished by its utilization of multiple composite facial features and a multilevel features fusion method, emerges as a pioneering solution in the field of Artificial intelligence road transportation. Through extensive evaluation on diverse scenarios, the model consistently outperforms state-of-the-art models, showcasing superior accuracy scores, adaptability to challenging conditions, and advanced learning capabilities. Its collective performance on a combined dataset further affirms its robustness and effectiveness in comprehensive drowsiness detection. This model holds great promise for enhancing driver safety.
In the future, we will look into combining the drowsiness features we see on a driver’s face with their body signals like heart rate, skin temperature, etc. We can also add in details about how the driver is driving the vehicle (i.e., vehicle driving parameters). We can also consider collecting a local dataset to localize the model. Doing these could make the drowsiness detection even more accurate and might help us understand drowsiness in drivers from different angles and improve our ability to detect it.
Author Contributions
Conceptualization, L.Y. and M.H. (Mohammed Hassan); methodology, L.Y.; software, L.Y.; validation, L.Y., H.K. and M.H. (Mohammed Hassan); resources, L.Y. and H.K., supervision, M.H. (Mohammed Hassan), H.K.; project administration, M.H. (Mohammed Hamada). All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from Computer Vision Lab, National Tsuing Hua University and are available at http://cv.cs.nthu.edu.tw/php/callforpaper/datasets/DDD/ with the permission of Computer Vision Lab, National Tsuing Hua University.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, C.S.; Lu, J.; Ma, K.K. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics): Preface. Lect. Notes Comput. Sci. 2017, 10116, V–VI. [Google Scholar] [CrossRef]
- Chen, S.; Wang, Z.; Chen, W. Driver drowsiness estimation based on factorized bilinear feature fusion and a long-short-term recurrent convolutional network. Information 2021, 12, 3. [Google Scholar] [CrossRef]
- Dehais, F.; Duprès, A.; Di Flumeri, G.; Verdière, K.J.; Borghini, G.; Babiloni, F.; Roy, R.N. Monitoring pilot’s cognitive fatigue with engagement features in simulated and actual flight conditions using a hybrid fNIRS-EEG passive BCI. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018. [Google Scholar]
- Garcia, I.; Bronte, S.; Bergasa, L.M.; Almazan, J.; Yebes, J. Vision-based drowsiness detector for Real Driving Conditions. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposiu, Alcala de Henares, Spain, 3–7 June 2012; pp. 618–623. [Google Scholar]
- Hu, X.; Lodewijks, G. Detecting fatigue in car drivers and aircraft pilots by using non-invasive measures: The value of differentiation of sleepiness and mental fatigue Detecting fatigue in car drivers and aircraft pilots by using non-invasive measures: The value of differentiation of sleepiness and mental fatigue. J. Saf. Res. 2020, 72, 173–187. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Hua, C. Driver fatigue recognition based on facial expression analysis using local binary patterns. Optik 2015, 126, 4501–4505. [Google Scholar] [CrossRef]
- Mohana, B.; Rani, C.S. Drowsiness Detection Based on Eye Closure and Yawning Detection. Int. J. Recent Technol. Eng. 2019, 8, 8941–8944. [Google Scholar] [CrossRef]
- Sun, Y.; Yan, P.; Li, Z.; Zou, J.; Hong, D. Driver fatigue detection system based on colored and infrared eye features fusion. Comput. Mater. Contin. 2020, 63, 1563–1574. [Google Scholar] [CrossRef]
- Wang, H.; Dragomir, A.; Itrat, N.; Li, J.; Thakor, N.V.; Bezerianos, A. A novel real-time driving fatigue detection system based on wireless dry EEG. Cogn. Neurodyn. 2018, 12, 365–376. [Google Scholar] [CrossRef] [PubMed]
- Omerustaoglu, F.; Sakar, C.O.; Kar, G. Distracted driver detection by combining in-vehicle and image data using deep learning. Appl. Soft Comput. 2020, 7, 96–117. [Google Scholar] [CrossRef]
- Weng, C.H.; Lai, Y.H.; Lai, S.H. Driver Drowsiness Detection via a Hierarchical Temporal Deep Belief Network. In Proceedings of the 13th Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016; pp. 117–133. [Google Scholar]
- Yuen, K.; Martin, S.; Trivedi, M.M. Looking at Faces in a Vehicle: A Deep CNN Based Approach and Evaluation. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 649–654. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).