
Supervised Sentiment Analysis of Indirect Qualitative Student Feedback for Unbiased Opinion Mining †



Abstract
:1. Introduction
2. Related Works
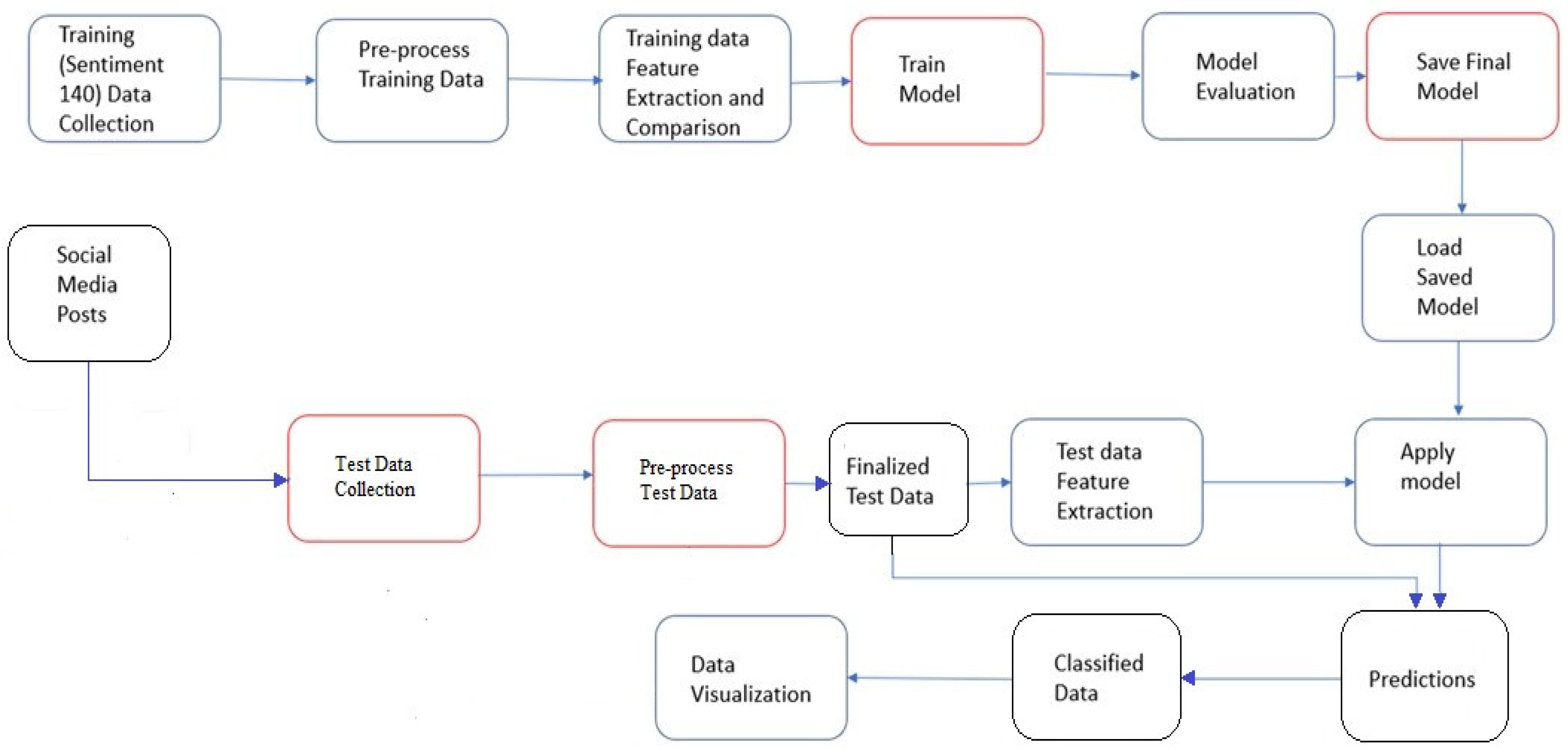
3. System Model
3.1. Training Data Collection (Sentiment 140 Data Collection)
3.2. Pre-Process Training Data
3.3. Extraction and Comparison of Training Data Features
3.4. Train Model
3.5. Model Evaluation
3.6. Saving the Final Model
3.7. Test Data Collection
3.8. Load-Saved Model
3.9. Applying the Model
4. Results and Discussion
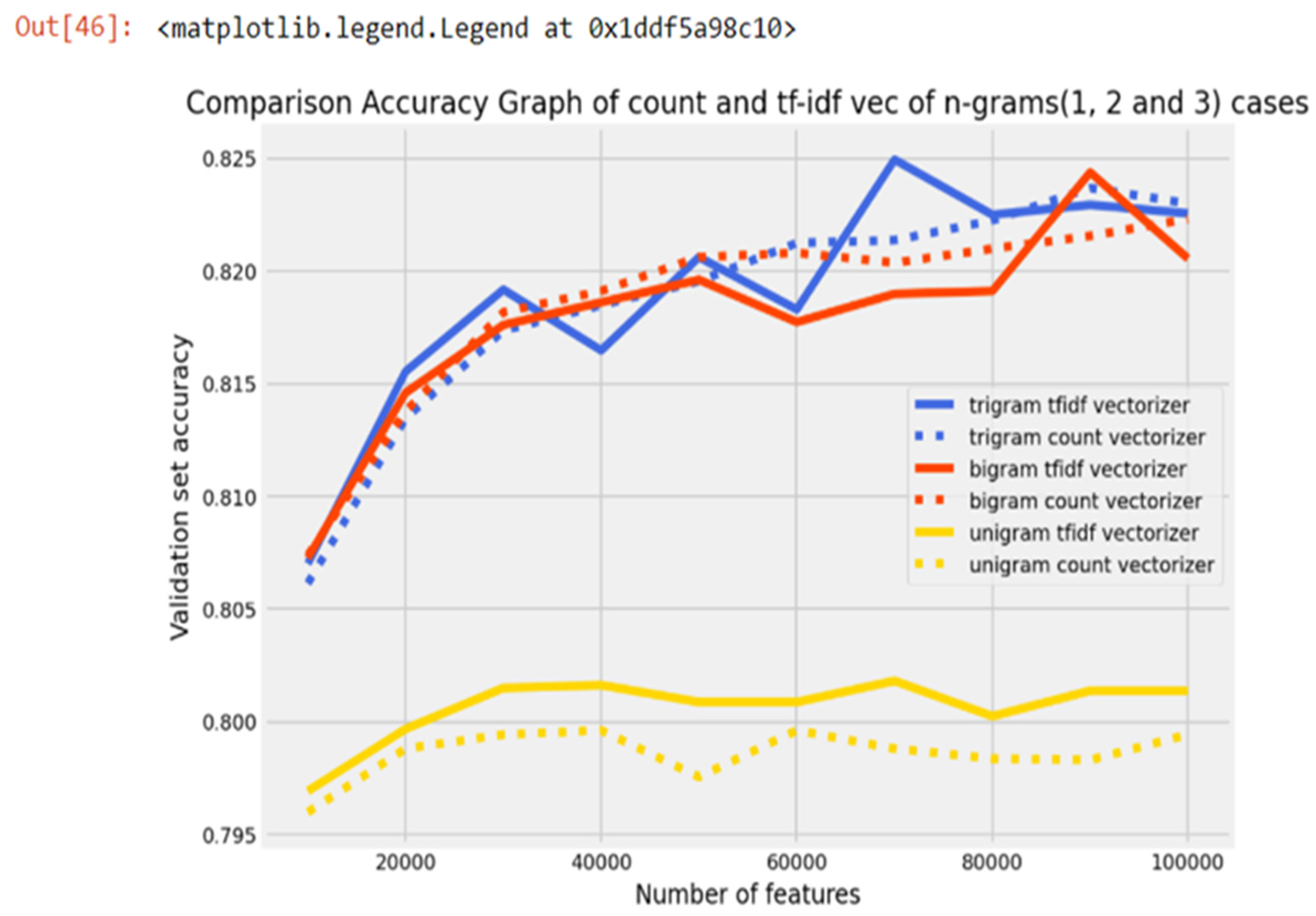
4.1. Feature Extraction
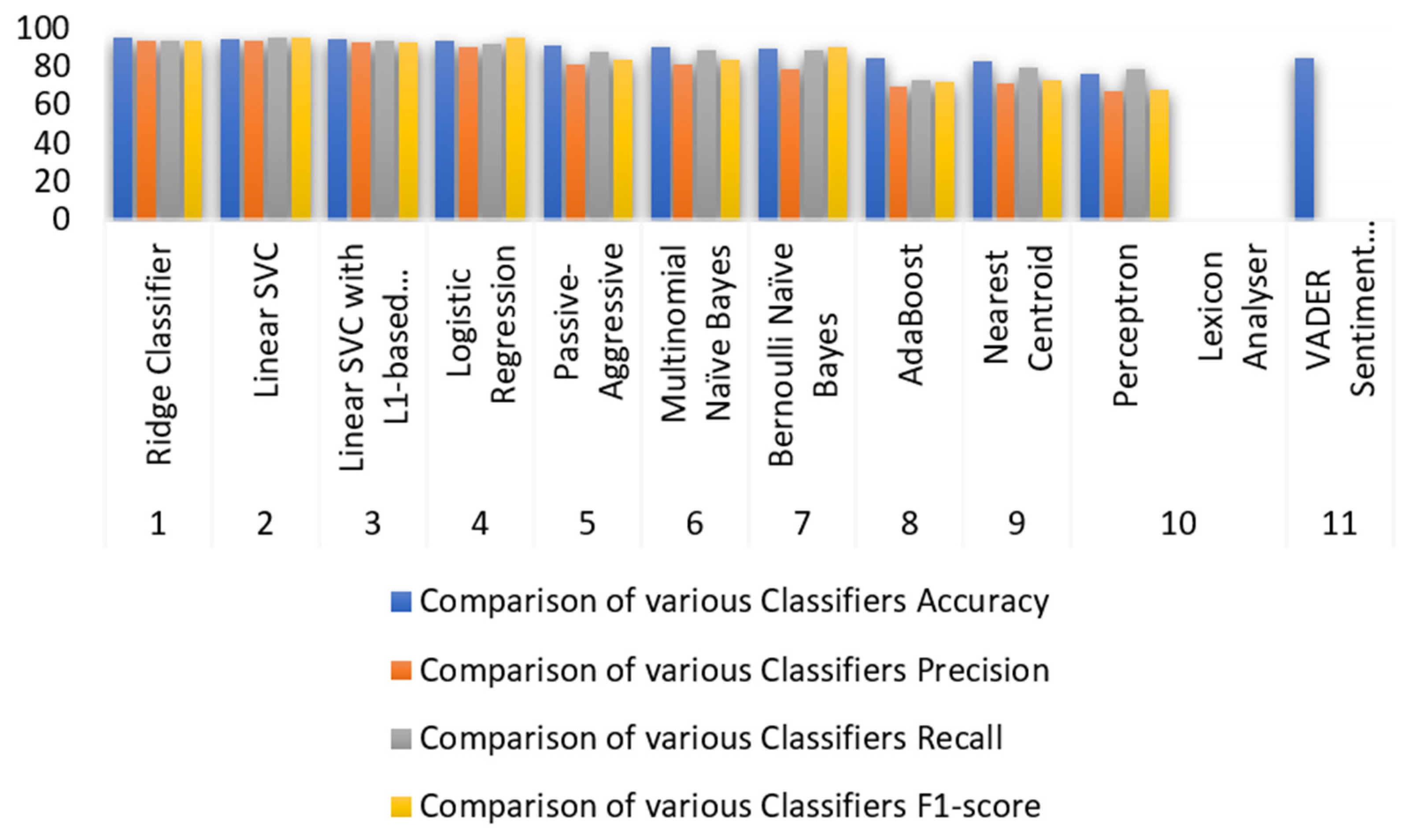
4.2. Modeling and Comparing Various Classification Model Results
4.3. Accuracy Comparison on Tweet Dataset
- Precision: The precision of a test is determined by dividing its true positives by the total of its true positives and false positives. Few incorrect positive predictions are indicated by a high precision score.
- Recall: The ratio of true positives to the total of true positives and false negatives is called recall, which is sometimes referred to as sensitivity or the true positive rate. Recall scores that are high suggest fewer incorrect negative predictions.
- F1-score: The harmonic mean of recall and precision is known as the F1-score. It takes into account both precision and recall, providing an equitable assessment of the model’s performance. When there is an uneven distribution of classes, the F1-score is helpful.
- Support: The number of occurrences in every sentiment class is represented by a support. It shows how many occurrences of each sentiment the model has predicted.
4.4. Data Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Vorvoreanu, M.; Madhavan, K. Mining Social Media Data for Understanding Students’ Learning Experiences. IEEE Trans. Learn. Technol. 2014, 7, 246–259. [Google Scholar] [CrossRef]
- Aung, K.Z.; Myo, N.N. Sentiment analysis of students’ comment using lexicon-based approach. In Proceedings of the IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 149–154. [Google Scholar]
- Dalipi, F.; Zdravkova, K.; Ahlgren, F. Sentiment Analysis of Students’ Feedback in MOOCs: A Systematic Literature Review. Front. Artif. Intell. 2021, 4, 728708. [Google Scholar] [CrossRef] [PubMed]
- Wook, M.; Razali NA, M.; Ramli, S.; Wahab, N.A.; Hasbullah, N.A.; Zainudin, N.M.; Talib, M.L. Opinion mining Technique for developing student feedback analysis system using lexicon-based approach (OMFeedback). Educ. Inf. Technol. 2020, 25, 2549–2560. [Google Scholar] [CrossRef]
- Dsouza, D.D.; Deepika, D.P.N.; Machado, E.J.; Adesh, N.D. Sentimental analysis of student feedback using machine learning techniques. Int. J. Recent Technol. Eng. 2019, 8, 986–991. [Google Scholar]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2010, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Rosalind, J.M.; Suguna, S. Predicting Students’ Satisfaction towards Online Courses Using Aspect-Based Sentiment Analysis. In Computer, Communication, and Signal Processing; Neuhold, E.J., Fernando, X., Lu, J., Piramuthu, S., Chandrabose, A., Eds.; IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2022; p. 651. [Google Scholar]
- Ortony, A.; Turner, T.J. What’s basic about basic emotions? Psychol. Rev. 1990, 97, 315. [Google Scholar] [CrossRef] [PubMed]
- Mohammad, S.M.; Kiritchenko, S.; Zhu, X. Nrc-canada: Building the state-of-the art in sentiment analysis of tweets. In Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; pp. 321–327. [Google Scholar]
- Ömer Osmanoğlu, U.; Atak, O.N.; Çağlar, K.; Kayhan, H.; Can, T. Sentiment analysis for distance education course materials: A machine learning approach. J. Educ. Technol. Online Learn. 2010, 3, 31–48. [Google Scholar] [CrossRef]
- Lwin, H.H.; Oo, S.; Ye, K.Z.; Lin, K.K.; Aung, W.P.; Ko, P.P. Feedback analysis in outcome base education using machine learning. In Proceedings of the 2020 17th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 24–27 June 2020. [Google Scholar]
- Sivakumar, M.; Reddy, U.S. Aspect based sentiment analysis of student’s opinion using machine learning techniques. In Proceedings of the 2017 International Conference on Inventive Computing and Informatics, Coimbatore, India, 23–24 November 2017. [Google Scholar]
- Ahmad, M.; Aftab, S.; Bashir, M.S.; Hameed, N. Sentiment analysis using SVM: A systematic literature review. Int. J. Adv. Comput. Sci. Appl. 2018, 9. [Google Scholar] [CrossRef]
- Dehbozorgi, N.; Mohandoss, D.P. Aspect-based emotion analysis on speech for predicting performance in collaborative learning. In Proceedings of the 2021 IEEE Frontiers in Education Conference, FIE, Lincoln, NE, USA, 13–16 October 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Lalata, J.P.; Gerardo, B.; Medina, R. A sentiment analysis model for faculty comment evaluation using ensemble machine learning algorithms. In Proceedings of the 2019 International Conference on Big Data Engineering, Hong Kong, China, 11–13 June 2019; pp. 68–73. [Google Scholar]
- Edalati, M.; Imran, A.S.; Kastrati, Z.; Daudpota, S.M. The Potential of Machine Learning Algorithms for Sentiment Classification of Students’ Feedback on MOOC. In Lecture Notes in Networks and Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 11–22. [Google Scholar]
- Wehbe, D.; Alhammadi, A.; Almaskari, H.; Alsereidi, K.; Ismail, H. UAE e-learning sentiment analysis framework. In Proceedings of the ArabWIC 2021: The 7th Annual Intl. Conference on Arab Women in Computing in Conjunction with the 2nd Forum of Women in Research, Sharjah, United Arab Emirates, 25–26 August 2021; ACM: New York, NY, USA, 2021. [Google Scholar]
- Kastrati, Z.; Imran, A.S.; Kurti, A. Weakly supervised framework for aspect-based sentiment analysis on students’ reviews of MOOCs. IEEE Access 2020, 8, 106799–106810. [Google Scholar] [CrossRef]
- Chaithanya, D.S.; Narayana, K.L.; Maheh, T.R. A Comprehensive Analysis: Classification Techniques for Educational Data mining. In Proceedings of the 2021 International Conference on Disruptive Technologies for Multi-Disciplinary Research and Applications (CENTCON), Bengaluru, India, 19–21 November 2021; pp. 173–176. [Google Scholar] [CrossRef]
- Ramakrishna, M.T.; Venkatesan, V.K.; Bhardwaj, R.; Bhatia, S.; Rahmani, M.K.I.; Lashari, S.A.; Alabdali, A.M. HCoF: Hybrid Collaborative Filtering Using Social and Semantic Suggestions for Friend Recommendation. Electronics 2023, 12, 1365. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers Comparison | |||||
| Sl. No. | Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
| 1 | Ridge Classifier | 95.16 | 94 | 94 | 94 |
| 2 | Linear SVC | 94.73 | 94 | 95 | 95 |
| 3 | Linear SVC with L1-based feature selection | 94.62 | 93 | 94 | 93 |
| 4 | Logistic Regression | 93.75 | 90 | 92 | 95 |
| 5 | Passive-Aggressive | 91.03 | 81 | 88 | 84 |
| 6 | Multinomial Naïve Bayes | 90.62 | 81 | 89 | 84 |
| 7 | Bernoulli Naïve Bayes | 89.43 | 79 | 89 | 90 |
| 8 | AdaBoost | 84.56 | 70 | 73 | 72 |
| 9 | Nearest Centroid | 83.02 | 71 | 80 | 73 |
| 10 | Perceptron | 76.15 | 67 | 79 | 68 |
| Lexicon Analyzer | |||||
| 11 | Vader sentiment analyzer | 84.83 | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasad, S.B.A.; Nakka, R.P.K. Supervised Sentiment Analysis of Indirect Qualitative Student Feedback for Unbiased Opinion Mining. Eng. Proc. 2023, 59, 15. https://doi.org/10.3390/engproc2023059015
Prasad SBA, Nakka RPK. Supervised Sentiment Analysis of Indirect Qualitative Student Feedback for Unbiased Opinion Mining. Engineering Proceedings. 2023; 59(1):15. https://doi.org/10.3390/engproc2023059015
Chicago/Turabian StylePrasad, Smitha Bidadi Anjan, and Raja Praveen Kumar Nakka. 2023. "Supervised Sentiment Analysis of Indirect Qualitative Student Feedback for Unbiased Opinion Mining" Engineering Proceedings 59, no. 1: 15. https://doi.org/10.3390/engproc2023059015
APA StylePrasad, S. B. A., & Nakka, R. P. K. (2023). Supervised Sentiment Analysis of Indirect Qualitative Student Feedback for Unbiased Opinion Mining. Engineering Proceedings, 59(1), 15. https://doi.org/10.3390/engproc2023059015