
Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison †


Abstract
:1. Introduction
2. Problem Statement
3. Literature Review
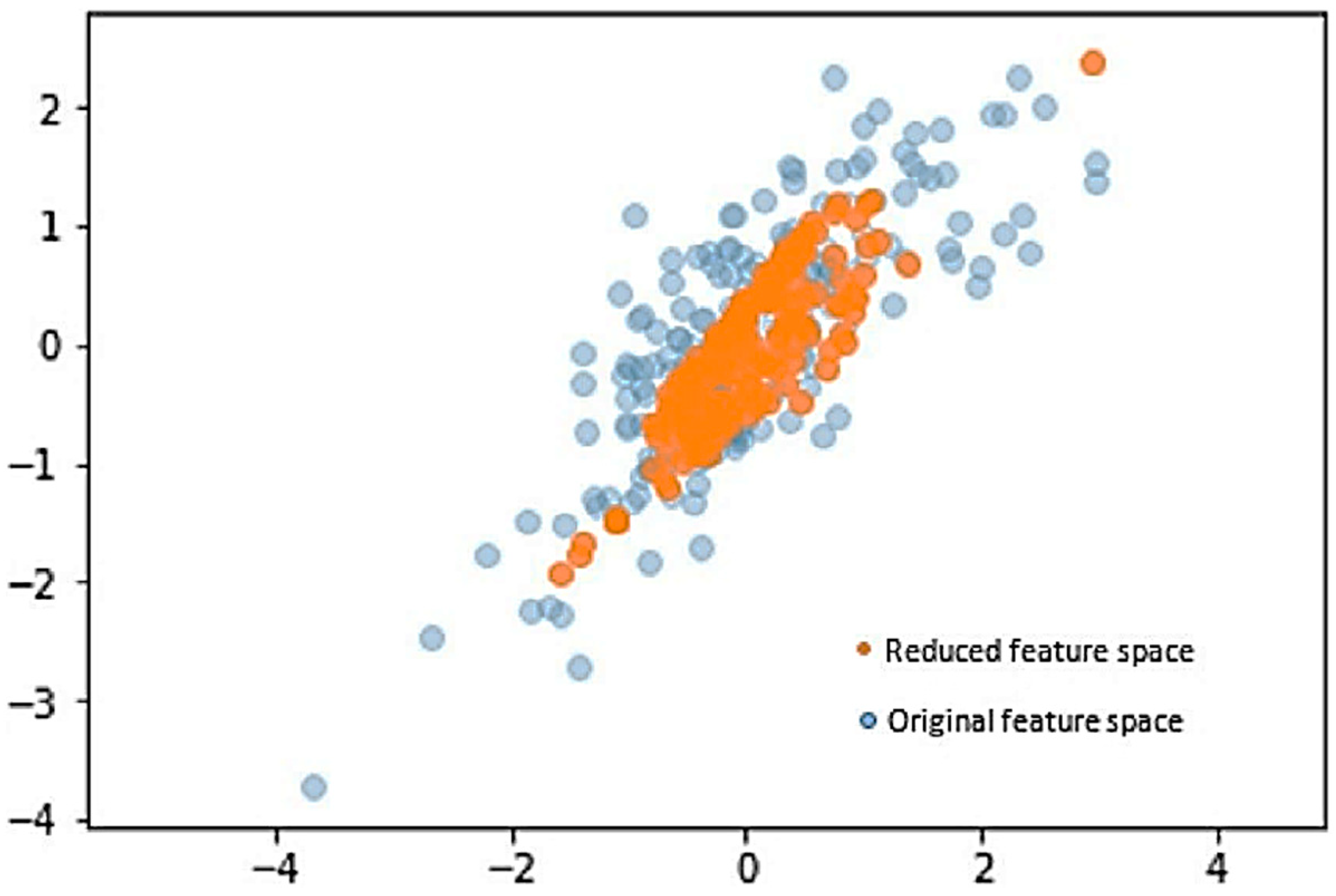
4. Principal Component Analysis
5. Proposed Model
- Data Pre-processing—In the prediction, inaccurate results might be generated because some attributes of the dataset have missing values. The model’s accuracy is reduced by such missing values. An efficient mean value is used for treating each attribute whether it has all values or is missing some values.
- Feature Selection—The performance of all the data mining algorithms can be improved through the use of effective feature selection. The performance of data classification is also enhanced by feature selection. Only some of the features of the dataset are important. Additional information is not provided by the redundant features that are present in the dataset. With regard to the context, not an ounce of helpful information is provided by the irrelevant features.
- Classification and analysis—Analysis of results and classification of the model are conducted after processing data using dimensionality reduction and feature selection methods. The output parameters are mapped over by the input parameters with the help of classification. On the basis of parameters, conclusions are drawn with the help of classification. The output prediction is also assisted by effective classification.
6. Summary and Comparison
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ramirez-Figueroa, J.A.; Martin-Barreiro, C.; Nieto-Librero, A.B.; Leiva, V.; Galindo-Villardón, M.P. A new principal component analysis by particle swarm optimization with an environmental application for data science. Stoch. Environ. Res. Risk Assess. 2021, 35, 1969–1984. [Google Scholar] [CrossRef]
- Wan, L.; Gong, K.; Zhang, G.; Yuan, X.; Li, C.; Deng, X. An efficient rolling bearing fault diagnosis method based on spark and improved random forest algorithm. IEEE Access 2021, 9, 37866–37882. [Google Scholar] [CrossRef]
- Aljawarneh, S.; Yassein, M.B.; Aljundi, M. An enhanced J48 classification algorithm for the anomaly intrusion detection systems. Clust. Comput. 2019, 22, 10549–10565. [Google Scholar] [CrossRef]
- Sivaranjani, S.; Ananya, S.; Aravinth, J.; Karthika, R. Diabetes prediction using machine learning algorithms with feature selection and dimensionality reduction. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 141–146. [Google Scholar]
- Parhizkar, T.; Rafieipour, E.; Parhizkar, A. Evaluation and improvement of energy consumption prediction models using principal component analysis based feature reduction. J. Clean. Prod. 2021, 279, 123866. [Google Scholar] [CrossRef]
- Wang, X.; Zhai, M.; Ren, Z.; Ren, H.; Li, M.; Quan, D.; Chen, L.; Qiu, L. Exploratory study on classification of diabetes mellitus through a combined Random Forest Classifier. BMC Med. Inform. Decis. Mak. 2021, 21, 105. [Google Scholar] [CrossRef] [PubMed]
- Sadiq, M.T.; Yu, X.; Yuan, Z. Exploiting dimensionality reduction and neural network techniques for the development of expert brain–computer interfaces. Expert Syst. Appl. 2021, 164, 114031. [Google Scholar] [CrossRef]
- Guo, Y.; Zhou, Y.; Zhang, Z. Fault diagnosis of multi-channel data by the CNN with the multilinear principal component analysis. Measurement 2021, 171, 108513. [Google Scholar] [CrossRef]
- Hasan, B.M.S.; Abdulazeez, A.M. A Review of Principal Component Analysis Algorithm for Dimensionality Reduction. J. Soft Comput. Data Min. 2021, 2, 20–30. [Google Scholar]
- Hashim, M.; Amutha, R. Human activity recognition based on smartphone using fast feature dimensionality reduction technique. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 2365–2374. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, W.; Li, W.; Huang, Y. Large group activity security risk as- sessment and risk early warning based on random forest algorithm. Pattern Recognit. Lett. 2021, 144, 1–5. [Google Scholar] [CrossRef]
- Duan, Y.; Yang, C.; Chen, H.; Yan, W.; Li, H. Low-complexity point cloud de- noising for LiDAR by PCA-based dimension reduction. Opt. Commun. 2021, 482, 126567. [Google Scholar] [CrossRef]
- Razdan, S.; Gupta, H.; Seth, A. Performance Analysis of Network Intrusion De- tection Systems using J48 and Naive Bayes Algorithms. In Proceedings of the 2021 6th International Conference for Convergence in Technology (I2CT), Mumbai, India, 2–4 April 2021; pp. 1–7. [Google Scholar]
- Gewers, F.L.; Ferreira, G.R.; Arruda, H.F.D.; Silva, F.N.; Comin, C.H.; Amancio, D.R.; Costa, L.D.F. Principal component analysis: A natural approach to data exploration. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S. Incremental neural-network learning for big fraud data. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), IEEE, Toronto, ON, Canada, 11–14 October 2020; pp. 3551–3557. [Google Scholar]
- Anowar, F.; Sadaoui, S. Incremental learning framework for real-world fraud detection environment. Comput. Intell. 2021, 37, 635–656. [Google Scholar] [CrossRef]
- Spruyt, V. The curse of dimensionality in classification. Comput. Vis. Dummies 2014, 21, 35–40. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative review. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Jindal, P.; Kumar, D. A Review on Dimensionality Reduction Techniques. Int. J. Comput. Appl. 2017, 173, 42–46. [Google Scholar] [CrossRef]
- Verleysen, M.; François, D. The curse of dimensionality in data mining and time series prediction. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2005; pp. 758–770. [Google Scholar]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef]
- Abe, S. Feature selection and extraction, in: Support Vector Machines for Pattern Classification. In Advances in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2010; pp. 331–341. [Google Scholar]
- Yan, J.; Zhang, B.; Liu, N.; Yan, S.; Cheng, Q.; Fan, W.; Yang, Q.; Xi, W.; Chen, Z. Effective and efficient dimensionality reduction for large-scale and streaming data preprocessing. IEEE Trans. Knowl. Data Eng. 2006, 18, 320–333. [Google Scholar] [CrossRef]
- Chao, G.; Luo, Y.; Ding, W. Recent Advances in Supervised Dimension Reduction: A Survey. Mach. Learn. Knowl. Extr. 2019, 1, 341–358. [Google Scholar] [CrossRef]
- Gracia, A.; González, S.; Robles, V.; Menasalvas, E. A methodology to compare dimensionality reduction algorithms in terms of loss of quality. Inform. Sci. 2014, 270, 1–27. [Google Scholar] [CrossRef]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extrac- tion techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, IEEE, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Joshi, P. What Is Manifold Learning? 2014. Available online: https://prateekvjoshi.com/2014/06/21/what-is-manifold-learning/ (accessed on 10 February 2023).
- Garrett, D.; Peterson, D.; Anderson, C.; Thaut, M. Comparison of linear, nonlinear, and feature selection methods for EEG signal classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2003, 11, 141–144. [Google Scholar] [CrossRef] [PubMed]
- Rastogi, A.K.; Taterh, S.; Kumar, B.S. Dimensionality Reduction Approach for High Dimensional Data using HGA based Bio Inspired Algorithm. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 227–239. [Google Scholar]
- Rastogi, A.K.; Taterh, S.; Kumar, B.S. Bio-Inspired Algorithms for Prey Model Optimization (February 2022). In Proceedings of the 2022 2nd International Conference on Innovative Practices in Technology and Management (ICIPTM), Gautam Buddha Nagar, Pradesh, India, 23–25 February 2022; pp. 264–269. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Proposed Solution | Advantages | Limitations |
|---|---|---|
| Disjoint principal component analysis method | It helps in resolving the issue related with multivariate analysis and dimensionality reduction. | The solution quality degrades with the in- crease in the size of the dataset provided to the method. |
| Rolling Bearing Fault Diagnosis Method | It provides a better fault diagnosis accuracy and has high training and modelling speed for the datasets. | These methods can provide low fault diagnosis when imbalanced datasets are taken with very few samples. |
| Enhanced J48 classification algorithm | It provides efficient performance and accuracy in feature selection process. | The proposed method is not yet implemented in the real network environments. |
| Principle component analysis method | It helps in increasing the test set accuracy of the random forest and SVM through dimensionality reduction. | The accuracy reduces with the feature elimination of SVM algorithm. |
| PCA-based prediction method | It helps in predicting building’s energy consumption through random forest, SVR and linear regression method accurately in less execution time. | However, it can be less useful for the times of different energy consumption patterns and in lower ambient temperature. |
| SVM-SMOTE and LASSO combined with random forest | Random forest classifier combining with SVM-SMOTE and LASSO feature reduction method can accurately predict. | The performance of model required better understanding of parameter optimization methods. |
| Method for pattern mining | Effective method of two-step filtering the data. | Slow process of model training and testing time. |
| Fault diagnosis method | Lower computational cost and superior performance. | The multi-channel data should be homogenous. |
| Principal component analysis algorithm for dimensionality reduction | Speed up the processing and storage process by reducing high dimensions in large datasets. | It is less efficient in low-dimensional data. |
| Fast feature dimensionality reduction technique | Reduced computational cost and high accuracy rate. | Less response time. |
| Random forest algorithm | In risk assessment, it shows high predictive ability. | Restricted to only large-scale group activities. |
| Principal component analysis based adaptive clustering method | High recall and precision. | Cannot remove all the noise from dataset. |
| Naïve Bayes and J48 algorithms for network intrusion detection systems | In detection of anomalies, better performance is displayed by J48. | There are more chances of false alarms in case of Naïve Bayes algorithm then J48 algorithm. |
| Principal component analysis | Uses decorrelation to reduce dimensionality. | Not efficient when comes to simplifying datasets. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rastogi, A.K.; Taterh, S.; Kumar, B.S. Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison. Eng. Proc. 2023, 59, 82. https://doi.org/10.3390/engproc2023059082
Rastogi AK, Taterh S, Kumar BS. Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison. Engineering Proceedings. 2023; 59(1):82. https://doi.org/10.3390/engproc2023059082
Chicago/Turabian StyleRastogi, Ashish Kumar, Swapnesh Taterh, and Billakurthi Suresh Kumar. 2023. "Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison" Engineering Proceedings 59, no. 1: 82. https://doi.org/10.3390/engproc2023059082
APA StyleRastogi, A. K., Taterh, S., & Kumar, B. S. (2023). Dimensionality Reduction Algorithms in Machine Learning: A Theoretical and Experimental Comparison. Engineering Proceedings, 59(1), 82. https://doi.org/10.3390/engproc2023059082