
Energy Efficiency Evaluation of Frameworks for Algorithms in Time Series Forecasting †



Abstract
1. Introduction
- 1.
- Assessing the energy consumption of various libraries used for time series forecasting, employing a range of techniques based on both statistical methods and ML.
- 2.
- Analyzing the greenhouse gas emissions resulting from the energy consumption of evaluated frameworks and algorithms.
- 3.
- Identifying the most energy-consuming algorithms and frameworks and understanding their environmental impact.
- 4.
- Contributing to the knowledge on the energy efficiency of Statistical and ML methods, supporting efforts to make data science more environmentally sustainable.
2. Materials and Methods
2.1. Data Description
2.2. Time Series Forecasting
2.2.1. Statistical Forecasting Models
- Autoregressive Integrated Moving Average (ARIMA) [8]
- Seasonal ARIMA (SARIMA) [9]
2.2.2. Machine Learning Forecasting Models
- Deep Learning
- Long Short-Term Memory (LSTM) [8]
- Decomposition-Based Models
- Prophet [8]
2.3. Time Series Libraries
- Statsmodels [12] designed for the estimation of statistical models, testing, and time series analysis, it offers tools for linear regression, logistic regression, generalized linear model (GLM), mixed effects models, ARIMA, SARIMA, and robust regression. Focused on statistical inference, it includes hypothesis testing, descriptive statistics, and diagnostics. It facilitates the decomposition of time series and model evaluation, with visualization capabilities to interpret results. It is suitable for academic research and practical applications.
- TensorFlow [13] is an open source library by Google, known for ML and DNN. It includes tools for time series analysis, such as LSTM to capture long-term dependencies. It allows efficient processing on Graphics Processing Unit (GPU) and Tensor Processing Unit (TPU), accelerating the training of complex models, and facilitates data preprocessing through normalization and segmentation.
- PyTorch [14] developed by Facebook AI Research lab, it is oriented towards deep learning and numerical computation. Ideal for time series analysis with RNNs, LSTMs, and Transformers. It uses dynamic computational graphs to modify models during execution, facilitating experimentation. It includes predefined components, GPU support, and visualization tools, integrating well with other data analysis and ML libraries.
- Darts [15] is a library for time series analysis and processing, offering a unified interface to implement and evaluate models such as ARIMA, exponential smoothing, RNNs, LSTMs, and transformer. It provides preprocessing tools, series visualization, and model evaluation through cross-validation and accuracy metrics. It integrates with other data analysis tools, being useful for academic and industrial applications
2.4. Performance Evaluation Metrics
2.4.1. Model Performance Evaluation
- Root mean squared error (RMSE): measures the average magnitude of the errors between predicted and observed values; larger errors are further penalized by squaring them before averaging and then taking the square root. The RMSE is defined as:where n is the number of observations, are the observed values, and are the predicted values.
- Mean absolute error (MAE) measures the average of the absolute values of the errors between predicted and observed values, providing a direct measure of the average magnitude of the error without heavily penalizing larger errors. The MAE is defined as:where n is the number of observations, are the observed values, and are the predicted values.
2.4.2. Measuring Energy Consumption
2.5. Energy Consumption Meters
- OpenZmeter [11]: is a low-cost, open source, intelligent hardware energy meter and power quality analyzer. It measures reactive, active, and apparent energy, frequency, root mean square (RMS) voltage, RMS current, power factor, phase angle, voltage events, harmonics up to the 50th order, and the total harmonic distortion (THD). It records energy consumption in kilowatt–hours (kWh). The device includes a web interface and an API for integration. It can be installed in electrical distribution panels and features Ethernet, Wi-Fi, and 4G connectivity. Additionally, it offers remote monitoring and real-time alerts.
- CodeCarbon [10] is an open source software tool designed to measure and reduce the carbon footprint of software programs. It tracks energy consumption in kilowatt–hours (kWh) during code execution, taking into account the hardware used and the geographical location of data centers to calculate emissions. In this context, the methodology for calculating carbon dioxide () emissions involves multiplying the carbon intensity of electricity (C, in grams of per kilowatt–hour) by the energy consumed (E, in kilowatt–hours) by the computational infrastructure. This product gives the total emissions in kilograms of -equivalents (eq):The tool also provides an application programming interface (API) API and Python libraries for integrating carbon footprint monitoring into software projects, along with detailed reports and visualizations considering the geographical location of data centers.
2.6. Computational Resources
2.7. Experimental Setup
3. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kashpruk, N.; Piskor-Ignatowicz, C.; Baranowski, J. Time Series Prediction in Industry 4.0: A Comprehensive Review and Prospects for Future Advancements. Appl. Sci. 2023, 13, 12374. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Chou, J.S.; Tran, D.S. Forecasting energy consumption time series using machine learning techniques based on usage patterns of residential householders. Energy 2018, 165, 709–726. [Google Scholar] [CrossRef]
- Merelo-Guervós, J.J.; García-Valdez, M.; Castillo, P.A. Energy Consumption of Evolutionary Algorithms in JavaScript. In Proceedings of the 17th Italian Workshop, WIVACE 2023, Venice, Italy, 6–8 September 2023; pp. 3–15. [Google Scholar]
- Escobar, J.J.; Rodríguez, F.; Prieto, B.; Kimovski, D.; Ortiz, A.; Damas, M. A distributed and energy-efficient KNN for EEG classification with dynamic money-saving policy in heterogeneous clusters. Computing 2023, 105, 2487–2510. [Google Scholar] [CrossRef]
- Díaz, A.F.; Prieto, B.; Escobar, J.J.; Lampert, T. Vampire: A smart energy meter for synchronous monitoring in a distributed computer system. J. Parallel Distrib. Comput. 2024, 184, 104794. [Google Scholar] [CrossRef]
- Prieto, B.; Escobar, J.J.; Gómez-López, J.C.; Díaz, A.F.; Lampert, T. Energy efficiency of personal computers: A comparative analysis. Sustainability 2022, 14, 12829. [Google Scholar] [CrossRef]
- Weytjens, H.; Lohmann, E.; Kleinsteuber, M. Cash flow prediction: MLP and LSTM compared to ARIMA and Prophet. Electron. Commer. Res. 2021, 21, 371–391. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G. Time Series Analysis, Forecasting and Control; Holden-Day, Inc.: Princeton, NJ, USA, 1990. [Google Scholar]
- Schmidt, V.; Goyal, K.; Joshi, A.; Feld, B.; Conell, L.; Laskaris, N.; Blank, D.; Wilson, J.; Friedler, S.; Luccioni, S. CodeCarbon: Estimate and Track Carbon Emissions from Machine Learning Computing. Zenodo 2021. [Google Scholar] [CrossRef]
- Viciana, E.; Alcayde, A.; Montoya, F.G.; Baños, R.; Arrabal-Campos, F.M.; Zapata-Sierra, A.; Manzano-Agugliaro, F. OpenZmeter: An efficient low-cost energy smart meter and power quality analyzer. Sustainability 2018, 10, 4038. [Google Scholar] [CrossRef]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. SciPy 2010, 7, 1. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/static/extras/tensorflow-whitepaper2015.pdf (accessed on 4 July 2024).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Herzen, J.; Lässig, F.; Piazzetta, S.G.; Neuer, T.; Tafti, L.; Raille, G.; Van Pottelbergh, T.; Pasieka, M.; Skrodzki, A.; Huguenin, N.; et al. Darts: User-friendly modern machine learning for time series. J. Mach. Learn. Res. 2022, 23, 1–6. [Google Scholar]
- Xu, N. Time Series Analysis on Monthly Beer Production in Australia. Highlights Sci. Eng. Technol. 2024, 94, 392–401. [Google Scholar] [CrossRef]
- Han, Z.; Zhao, J.; Leung, H.; Ma, K.F.; Wang, W. A Review of Deep Learning Models for Time Series Prediction. IEEE Sensors J. 2021, 21, 7833–7848. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Bird, J. Electrical and Electronic Principles and Technology; Routledge: London, UK, 2017. [Google Scholar]
- Bouza, L.; Bugeau, A.; Lannelongue, L. How to estimate carbon footprint when training deep learning models? A guide and review. Environ. Res. Commun. 2023, 5, 115014. [Google Scholar] [CrossRef] [PubMed]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Feature | Statsmodels | TensorFlow | PyTorch | Darts | Prophet |
|---|---|---|---|---|---|
| Main Approach | Statistical models | Deep learning | Deep learning | Time series | Bayesian structural time series |
| Supported Models | Regression, GLM, ARIMA, SARIMA | RNN, LSTM, Transformer | RNN, LSTM, transformer | ARIMA, exponential smoothing, RNN, LSTM, transformer | Additive, multiplicative seasonalities, changepoints |
| Preprocessing | Descriptive statistics, hypothesis testing | Normalization, segmentation | Normalization, segmentation | Scaling, value imputation | Handling missing values, outlier detection |
| Statistical Inference | Yes | No | No | Yes | Yes |
| Visualization | Yes | Yes | Yes | Yes | Yes |
| Hardware Acceleration | No | GPU, TPU | GPU | GPU | No |
| Category | Specifications |
|---|---|
| Hardware | |
| Architecture | x86_64 |
| Processors | 2× Intel Xeon E5-2640 v4 @ 2.40 GHz, 10 cores each, 90W TDP each |
| RAM | 126 GB |
| GPUs | 3× NVIDIA GeForce GTX 1080 Ti, 250W TDP, 11 GB each |
| 1× NVIDIA TITAN Xp, 250W TDP, 12 GB | |
| Power Meters | OpenZmeter |
| Software | |
| Operating system | Ubuntu 24.04 LTS |
| Python version | 3.10.14 |
| CodeCarbon version | 2.4.1 |
| Model | Libraries | Optimizer | Exec. Count |
|---|---|---|---|
| ARIMA | Darts | auto_arima | 15 |
| ARIMA | Statsmodels | auto_arima | 15 |
| LSTM | Keras | GridSearchCV | 15 |
| LSTM | PyTorch | Optuna | 15 |
| LSTM | TensorFlow | GridSearchCV | 15 |
| Prophet | Darts | GridSearchCV | 15 |
| Prophet | Prophet | GridSearchCV | 15 |
| SARIMA | Statsmodels | auto_arima | 15 |
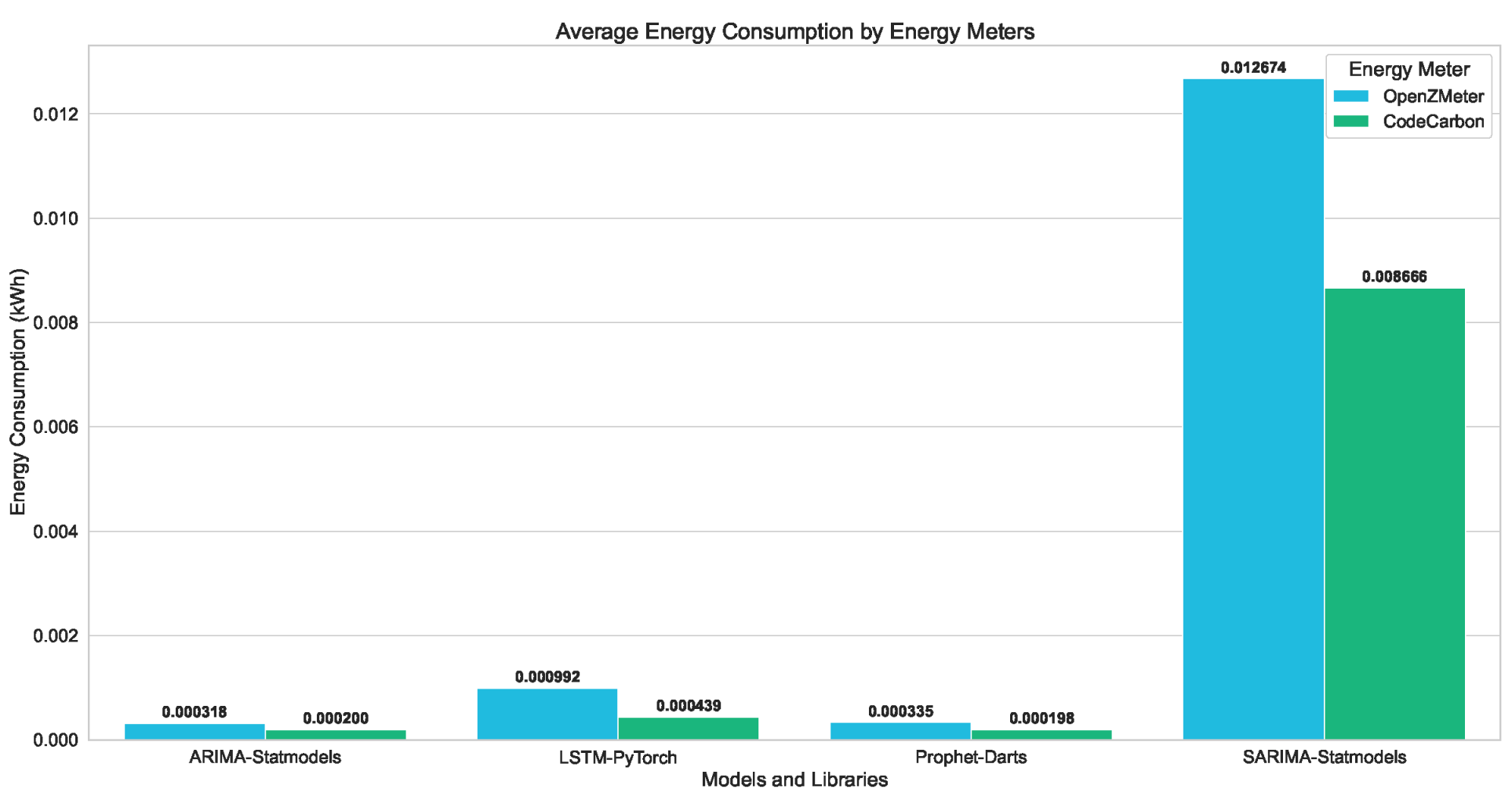
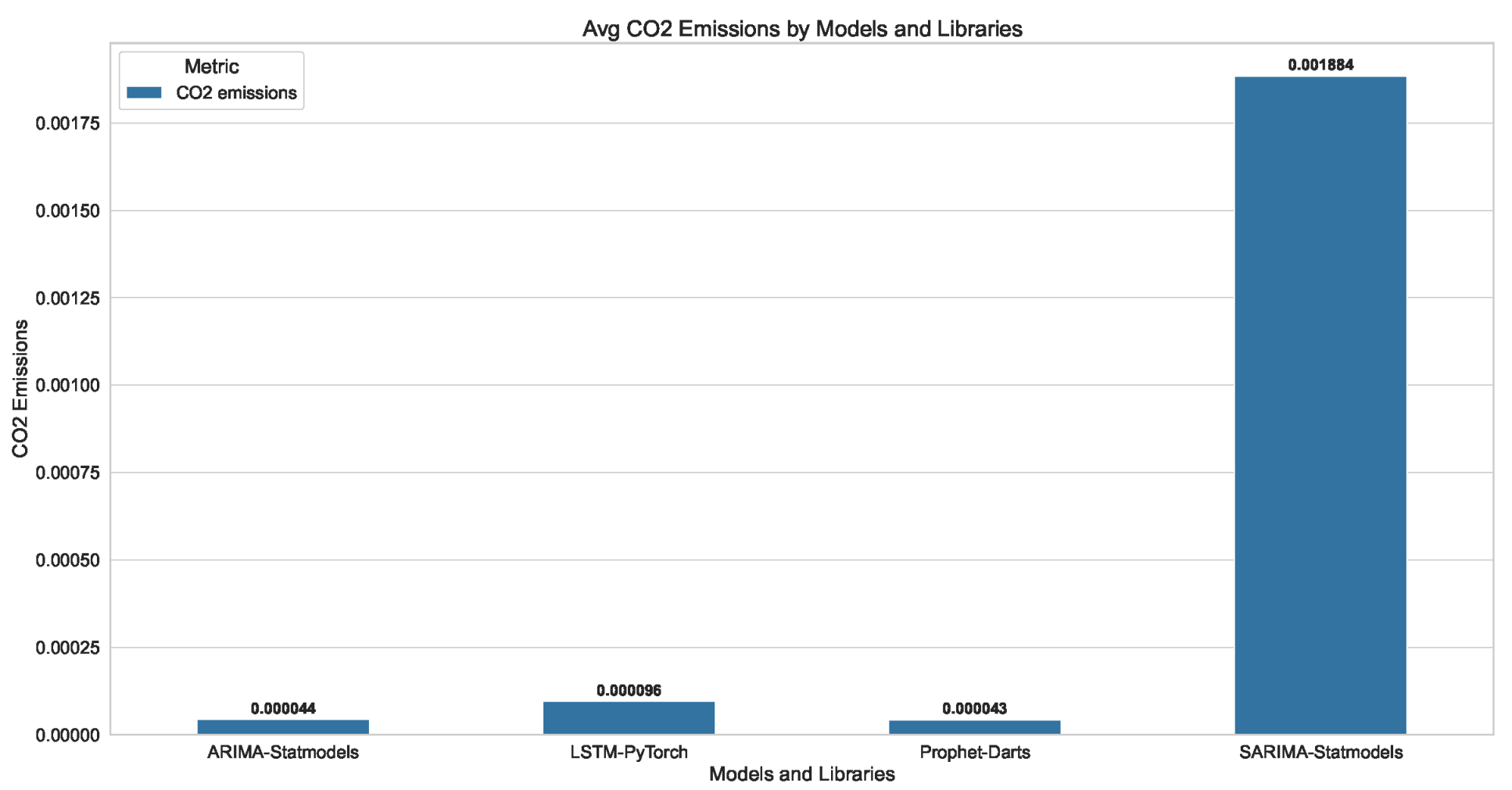
| Library | Avg Energy (kWh) | Emissions (kgs) | MAE | RMSE | |
|---|---|---|---|---|---|
| oZm | CC | ||||
| ARIMA | |||||
| Darts | 0.000336 | 0.000233 | 0.000051 | 0.164000 | 0.188000 |
| Statmodels | 0.000318 | 0.000200 | 0.000044 | 0.105000 | 0.122000 |
| LSTM | |||||
| Darts | 0.002428 | 0.000967 | 0.000210 | 0.136533 | 0.168400 |
| Keras | 0.001591 | 0.000705 | 0.000153 | 0.149600 | 0.173667 |
| PyTorch | 0.000992 | 0.000439 | 0.000096 | 0.133533 | 0.154067 |
| TensorFlow | 0.002061 | 0.000877 | 0.000191 | 0.144000 | 0.167000 |
| Prophet | |||||
| Darts | 0.000335 | 0.000198 | 0.000043 | 0.070000 | 0.083000 |
| Prophet | 0.001157 | 0.000705 | 0.000153 | 0.099000 | 0.117000 |
| SARIMA | |||||
| Statmodels | 0.012674 | 0.008666 | 0.001884 | 0.050000 | 0.063000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aquino-Brítez, S.; García-Sánchez, P.; Ortiz, A.; Aquino-Brítez, D. Energy Efficiency Evaluation of Frameworks for Algorithms in Time Series Forecasting. Eng. Proc. 2024, 68, 30. https://doi.org/10.3390/engproc2024068030
Aquino-Brítez S, García-Sánchez P, Ortiz A, Aquino-Brítez D. Energy Efficiency Evaluation of Frameworks for Algorithms in Time Series Forecasting. Engineering Proceedings. 2024; 68(1):30. https://doi.org/10.3390/engproc2024068030
Chicago/Turabian StyleAquino-Brítez, Sergio, Pablo García-Sánchez, Andrés Ortiz, and Diego Aquino-Brítez. 2024. "Energy Efficiency Evaluation of Frameworks for Algorithms in Time Series Forecasting" Engineering Proceedings 68, no. 1: 30. https://doi.org/10.3390/engproc2024068030
APA StyleAquino-Brítez, S., García-Sánchez, P., Ortiz, A., & Aquino-Brítez, D. (2024). Energy Efficiency Evaluation of Frameworks for Algorithms in Time Series Forecasting. Engineering Proceedings, 68(1), 30. https://doi.org/10.3390/engproc2024068030