
Multi-Objective Optimisation for the Selection of Clusterings across Time †


Abstract
:1. Introduction
2. Related Work
3. Framework
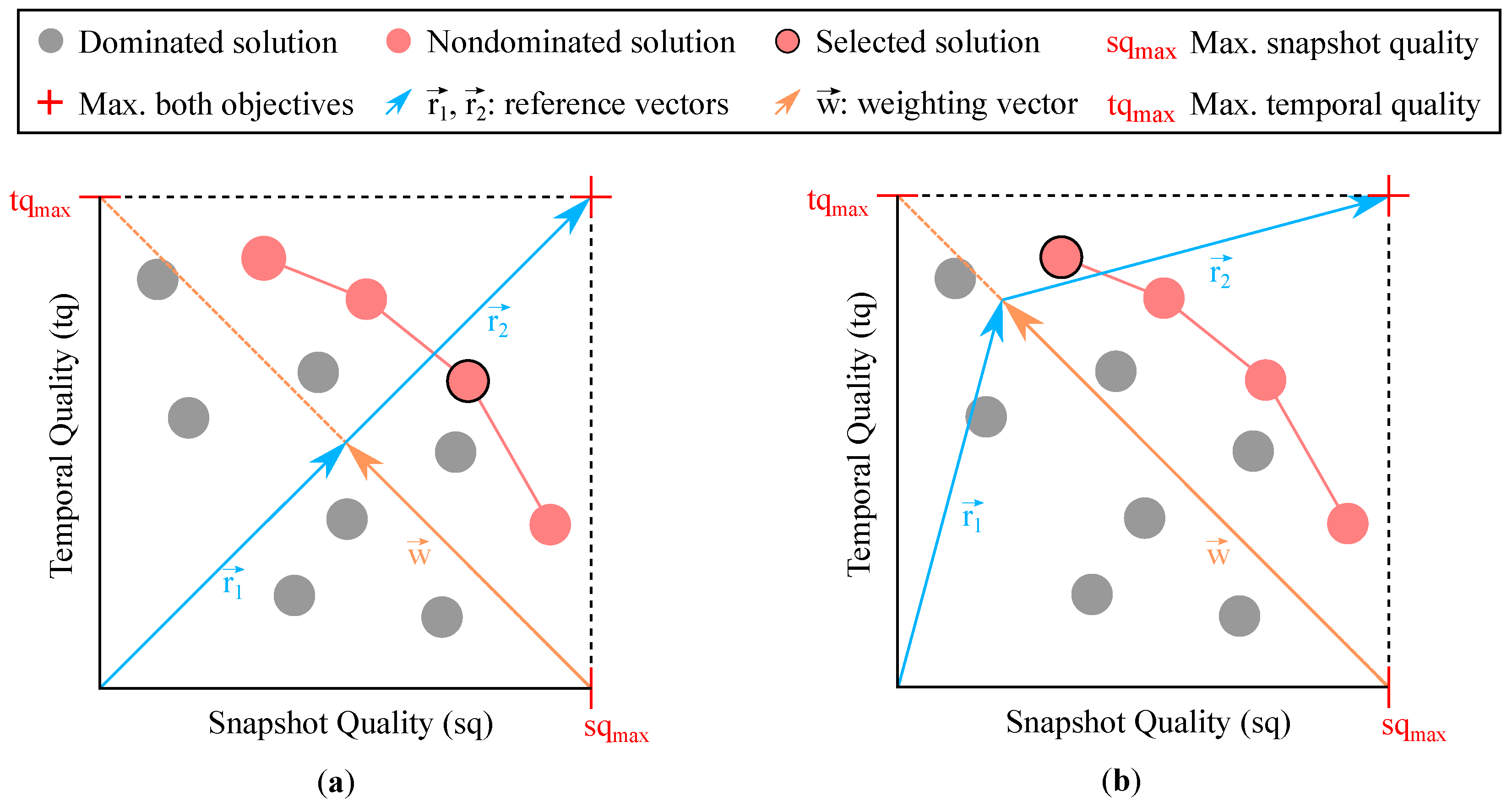
3.1. Weighting Procedure
- Weights with should match the endpoints of ;
- Every element from should be selectable by an appropriate weight (surjectivity);
- Two different weights should not map to the same element on (injectivity).
3.2. Transition-Based Temporal Quality Metric
4. Experiments
4.1. Datasets and Frameworks for Comparison
4.2. Instantiations of Clustering Algorithms
- Cluster all time series at time t with all combinations of and .
- Let each framework select a clustering from the set of resulting clusterings.
- Move to the next time point, .
4.3. Framework Parameter Settings and Clustering Evaluation Metric
4.4. Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MOSCAT | Multi-objective optimisation for selection of clusterings across time (method) |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise (method) |
| TOPSIS | Technique for Order Preference by Similarity to Ideal Solution (method) |
| COVID-19 | Coronavirus disease 2019 (infectious disease) |
References
- James, N.; Menzies, M. Cluster-based dual evolution for multivariate time series: Analyzing COVID-19. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 61108. [Google Scholar] [CrossRef]
- Simmhan, Y.; Noor, M.U. Scalable prediction of energy consumption using incremental time series clustering. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 29–36. [Google Scholar]
- Gružauskas, V.; Čalnerytė, D.; Fyleris, T.; Kriščiūnas, A. Application of multivariate time series cluster analysis to regional socioeconomic indicators of municipalities. Real Estate Manag. Valuat. 2021, 29, 39–51. [Google Scholar] [CrossRef]
- Korlakov, S.; Klassen, G.; Bravidor, M.; Conrad, S. Alone We Can Do So Little; Together We Cannot Be Detected. Eng. Proc. 2022, 18, 3. [Google Scholar] [CrossRef]
- Abdallah, I.; Duthé, G.; Barber, S.; Chatzi, E. Identifying evolving leading edge erosion by tracking clusters of lift coefficients. Proc. J. Phys. Conf. Ser. 2022, 2265, 32089. [Google Scholar] [CrossRef]
- Klassen, G.; Tatusch, M.; Huo, W.; Conrad, S. Evaluating machine learning algorithms in predicting financial restatements. In Proceedings of the 2020 The 4th International Conference on Business and Information Management, Rome, Italy, 3–5 August 2020; ACM: New York, NY, USA, 2020; pp. 95–100. [Google Scholar]
- Chakrabarti, D.; Kumar, R.; Tomkins, A. Evolutionary clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006. [Google Scholar]
- Chi, Y.; Song, X.; Zhou, D.; Hino, K.; Tseng, B.L. On evolutionary spectral clustering. ACM Trans. Knowl. Discov. Data (TKDD) 2009, 3, 1–30. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Deng, B. Evolutionary clustering with DBSCAN. In Proceedings of the 2013 Ninth International Conference on Natural Computation (ICNC), Shenyang, China, 23–25 July 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Li, T.; Chen, L.; Jensen, C.S.; Pedersen, T.B.; Gao, Y.; Hu, J. Evolutionary clustering of moving objects. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Shankar, R.; Kiran, G.; Pudi, V. Evolutionary clustering using frequent itemsets. In Proceedings of the First International Workshop on Novel Data Stream Pattern Mining Techniques, Washington, DC, USA, 25 July 2010; ACM: New York, NY, USA, 2010. [Google Scholar]
- Ma, X.; Zhang, B.; Ma, C.; Ma, Z. Co-regularized nonnegative matrix factorization for evolving community detection in dynamic networks. Inf. Sci. 2020, 528, 265–279. [Google Scholar] [CrossRef]
- Chi, Y.; Song, X.; Zhou, D.; Hino, K.; Tseng, B.L. Evolutionary spectral clustering by incorporating temporal smoothness. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; ACM: New York, NY, USA, 2007. [Google Scholar]
- Putri, G.H.; Read, M.N.; Koprinska, I.; Singh, D.; Röhm, U.; Ashhurst, T.M.; King, N.J. ChronoClust: Density-based clustering and cluster tracking in high-dimensional time-series data. Knowl.-Based Syst. 2019, 174, 9–26. [Google Scholar] [CrossRef]
- Zhang, J.; Song, Y.; Chen, G.; Zhang, C. On-line evolutionary exponential family mixture. In Proceedings of the Twenty-First International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; IJCAI: San Francisco, CA, USA, 2009. [Google Scholar]
- Xu, K.S.; Kliger, M.; Hero III, A.O. Adaptive evolutionary clustering. Data Min. Knowl. Discov. 2014, 28, 304–336. [Google Scholar] [CrossRef]
- Klassen, G.; Tatusch, M.; Conrad, S. Cluster-based stability evaluation in time series data sets. Appl. Intell. 2023, 53, 16606–16629. [Google Scholar] [CrossRef] [PubMed]
- Srinivasan, V.; Shocker, A.D. Linear programming techniques for multidimensional analysis of preferences. Psychometrika 1973, 38, 337–369. [Google Scholar] [CrossRef]
- Hwang, C.; Yoon, K. Multiple Attribute Decision Making, Methods and Applications; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Martinez-Morales, J.D.; Pineda-Rico, U.; Stevens-Navarro, E. Performance comparison between MADM algorithms for vertical handoff in 4G networks. In Proceedings of the 2010 7th International Conference on Electrical Engineering Computing Science and Automatic Control, Tuxtla Gutierrez, Mexico, 8–10 September 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Márquez, D.G.; Otero, A.; Félix, P.; García, C.A. A novel and simple strategy for evolving prototype based clustering. Pattern Recognit. 2018, 82, 16–30. [Google Scholar] [CrossRef]
- Lin, Y.R.; Chi, Y.; Zhu, S.; Sundaram, H.; Tseng, B.L. Analyzing communities and their evolutions in dynamic social networks. ACM Trans. Knowl. Discov. Data (TKDD) 2009, 3, 1–31. [Google Scholar] [CrossRef]
- Mucha, P.J.; Richardson, T.; Macon, K.; Porter, M.A.; Onnela, J.P. Community structure in time-dependent, multiscale, and multiplex networks. Science 2010, 328, 876–878. [Google Scholar] [CrossRef] [PubMed]
- Du, N.; Jia, X.; Gao, J.; Gopalakrishnan, V.; Zhang, A. Tracking temporal community strength in dynamic networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 3125–3137. [Google Scholar] [CrossRef]
- Folino, F.; Pizzuti, C. An evolutionary multiobjective approach for community discovery in dynamic networks. IEEE Trans. Knowl. Data Eng. 2013, 26, 1838–1852. [Google Scholar] [CrossRef]
- Yin, Y.; Zhao, Y.; Li, H.; Dong, X. Multi-objective evolutionary clustering for large-scale dynamic community detection. Inf. Sci. 2021, 549, 269–287. [Google Scholar] [CrossRef]
- Li, W.; Zhou, X.; Yang, C.; Fan, Y.; Wang, Z.; Liu, Y. Multi-objective optimization algorithm based on characteristics fusion of dynamic social networks for community discovery. Inf. Fusion 2022, 79, 110–123. [Google Scholar] [CrossRef]
- Wilhelm, M.; Krakowczyk, D.; Trollmann, F.; Albayrak, S. eRing: Multiple finger gesture recognition with one ring using an electric field. In Proceedings of the 2nd international Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 25–26 June 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, OR, USA, 2–4 August 1996; ACM: New York, NY, USA, 1996. [Google Scholar]
- Gonzalez, T.F. Clustering to minimize the maximum intercluster distance. Theor. Comput. Sci. 1985, 38, 293–306. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Manning, C.D. An Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]


{kind=link}
{kind=link}
| Term | Description |
|---|---|
| Maximum snapshot quality | |
| Maximum temporal quality | |
| Snapshot quality of given solution at time t | |
| Temporal quality of given solution at time t | |
| w | weight with |
| Dataset | No. Features | No. Time Series | No. Classes | Time Series Length |
|---|---|---|---|---|
| ERing | 4 | 300 | 6 | 65 |
| Motions | 6 | 80 | 4 | 100 |
| Dataset | Baseline | Evol. Clustering | MOSCAT |
|---|---|---|---|
| ERing | 0.191 ± 0.058 | 0.178 ± 0.005 | 0.180 ± 0.004 |
| Motions | 0.288 ± 0.057 | 0.284 ± 0.049 | 0.477 ± 0.057 |
| Purity | Weight | ||||
|---|---|---|---|---|---|
| Dataset | k | Baseline | Evol. Clustering | MOSCAT | MOSCAT |
| Motions | 2 | 0.371 ± 0.016 | 0.280 ± 0.016 | 0.280 ± 0.016 | 0.8 |
| 3 | 0.388 ± 0.048 | 0.421 ± 0.044 | 0.397 ± 0.037 | 0.9 | |
| 4 | 0.450 ± 0.046 | 0.485 ± 0.039 | 0.469 ± 0.042 | 0.8 | |
| 5 | 0.451 ± 0.045 | 0.479 ± 0.038 | 0.465 ± 0.051 | 0.8 | |
| 6 | 0.476 ± 0.035 | 0.497 ± 0.030 | 0.504 ± 0.047 | 0.8 | |
| 7 | 0.459 ± 0.048 | 0.499 ± 0.026 | 0.547 ± 0.047 | 0.8 | |
| 8 | 0.485 ± 0.042 | 0.503 ± 0.026 | 0.507 ± 0.043 | 0.7 | |
| 9 | 0.484 ± 0.040 | 0.500 ± 0.024 | 0.510 ± 0.048 | 0.7 | |
| 10 | 0.461 ± 0.047 | 0.501 ± 0.026 | 0.510 ± 0.059 | 0.7 | |
| ERing | 2 | 0.325 ± 0.013 | 0.324 ± 0.013 | 0.325 ± 0.013 | 0.0 |
| 3 | 0.448 ± 0.039 | 0.445 ± 0.045 | 0.448 ± 0.039 | 0.0 | |
| 4 | 0.535 ± 0.063 | 0.530 ± 0.069 | 0.536 ± 0.061 | 0.8 | |
| 5 | 0.524 ± 0.069 | 0.537 ± 0.069 | 0.526 ± 0.066 | 0.8 | |
| 6 | 0.569 ± 0.071 | 0.573 ± 0.077 | 0.567 ± 0.074 | 0.8 | |
| 7 | 0.586 ± 0.086 | 0.587 ± 0.088 | 0.589 ± 0.085 | 0.8 | |
| 8 | 0.598 ± 0.076 | 0.582 ± 0.077 | 0.600 ± 0.079 | 0.7 | |
| 9 | 0.602 ± 0.078 | 0.592 ± 0.079 | 0.604 ± 0.082 | 0.7 | |
| 10 | 0.611 ± 0.074 | 0.602 ± 0.076 | 0.612 ± 0.078 | 0.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Korlakov, S.; Klassen, G.; Bauer, L.T.; Conrad, S. Multi-Objective Optimisation for the Selection of Clusterings across Time. Eng. Proc. 2024, 68, 48. https://doi.org/10.3390/engproc2024068048
Korlakov S, Klassen G, Bauer LT, Conrad S. Multi-Objective Optimisation for the Selection of Clusterings across Time. Engineering Proceedings. 2024; 68(1):48. https://doi.org/10.3390/engproc2024068048
Chicago/Turabian StyleKorlakov, Sergej, Gerhard Klassen, Luca T. Bauer, and Stefan Conrad. 2024. "Multi-Objective Optimisation for the Selection of Clusterings across Time" Engineering Proceedings 68, no. 1: 48. https://doi.org/10.3390/engproc2024068048