
Interpretable Sewer Defect Detection with Large Multimodal Models †


Abstract
:1. Introduction
2. Methods and Materials
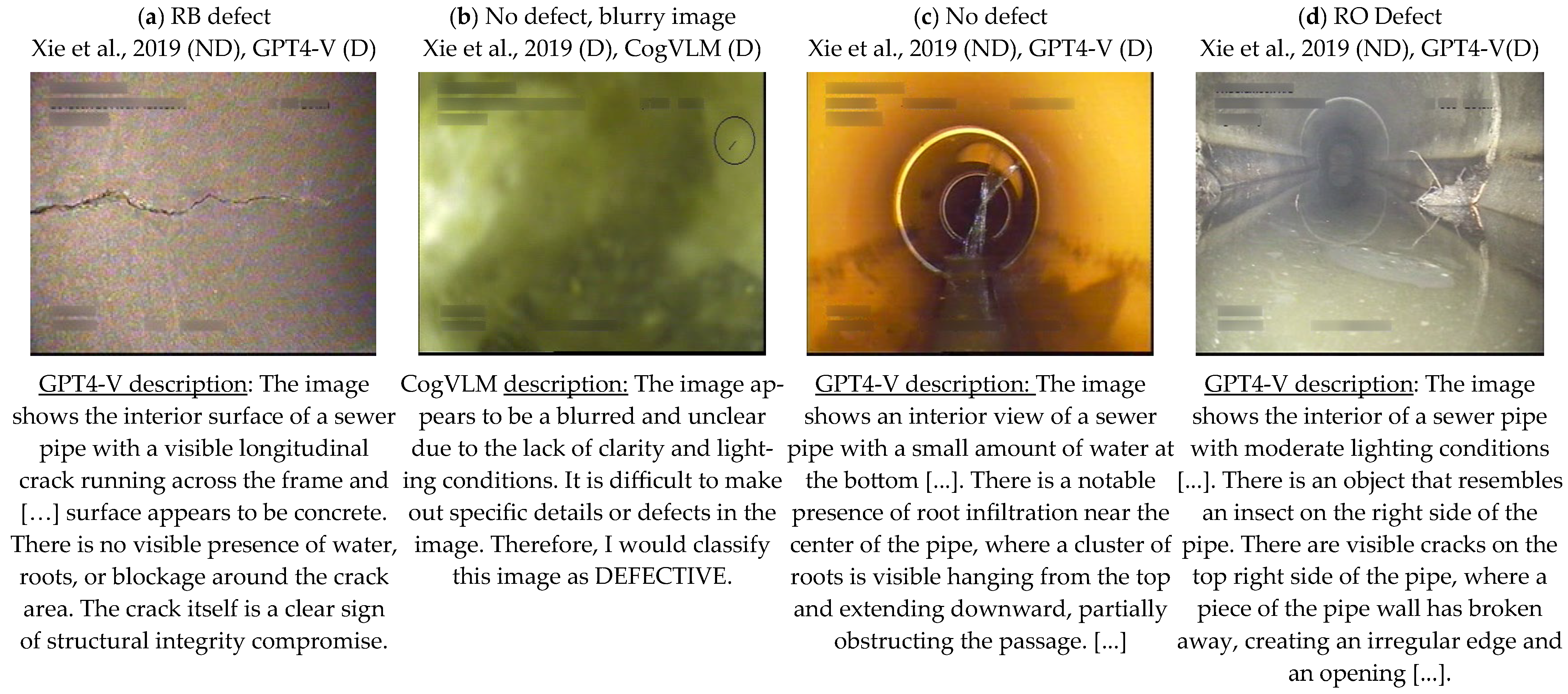
3. Results and Discussion
4. Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dirksen, J.; Clemens, F.H.L.R.; Korving, H.; Cherqui, F.; Le Gauffre, P.; Ertl, T.; Plihal, H.; Müller, K.; Snaterse, C.T.M. The consistency of visual sewer inspection data. Struct. Infrastruct. Eng. 2013, 9, 214–228. [Google Scholar] [CrossRef]
- Haurum, J.B.; Moeslund, T.B. A survey on image-based automation of CCTV and SSET sewer inspections. Autom. Constr. 2020, 111, 103061. [Google Scholar] [CrossRef]
- Tscheikner-Gratl, F.; Caradot, N.; Cherqui, F.; Leitão, J.P.; Ahmadi, M.; Langeveld, J.G.; Le Gat, Y.; Scholten, L.; Roghani, B.; Rodríguez, J.P.; et al. Sewer asset management–state of the art and research needs. Urban Water J. 2019, 16, 662–675. [Google Scholar] [CrossRef]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Wang, W.; Lv, Q.; Yu, W.; Hong, W.; Qi, J.; Wang, Y.; Ji, J.; Yang, Z.; Zhao, L.; Song, X.; et al. Cogvlm: Visual expert for pretrained language models. arXiv 2023, arXiv:2311.03079. [Google Scholar]
- Xie, Q.; Li, D.; Xu, J.; Yu, Z.; Wang, J. Automatic detection and classification of sewer defects via hierarchical deep learning. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1836–1847. [Google Scholar] [CrossRef]
- Haurum, J.B.; Moeslund, T.B. Sewer-ML: A multi-label sewer defect classification dataset and benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13456–13467. [Google Scholar]

{kind=link}
| Model | Accuracy | Recall | Precision | F1 Score | Not Predicted |
|---|---|---|---|---|---|
| Xie et al. [6] | 0.81 | 0.75 | 0.85 | 0.80 | 0 |
| GPT4-V | 0.65 | 0.54 | 0.70 | 0.61 | 3 |
| GPT4-V (basic prompt) | 0.61 | 0.49 | 0.65 | 0.56 | 2 |
| CogVLM | 0.60 | 0.40 | 0.69 | 0.50 | 16 |
| LLaVA | 0.52 | 0.26 | 0.53 | 0.35 | 0 |
| Defect Type | Xie et al. [6] | GPT4-V | GPT4-V (Basic Prompt) | CogVLM | LLaVA |
|---|---|---|---|---|---|
| DE | 0.75 | 0.42 | 0.33 | 0.29 | 0.33 |
| OB | 0.92 | 0.40 | 0.57 | 0.20 | 0.18 |
| PF | 0.75 | 0.62 | 0.57 | 0.57 | 0.18 |
| RB | 0.95 | 0.95 | 0.86 | 0.86 | 0.67 |
| RO | 0.89 | 0.91 | 0.82 | 0.69 | 0.57 |
| NoDefect | 0.93 | 0.87 | 0.85 | 0.90 | 0.87 |
| Overall | 0.80 | 0.61 | 0.56 | 0.50 | 0.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taormina, R.; van der Werf, J.A. Interpretable Sewer Defect Detection with Large Multimodal Models. Eng. Proc. 2024, 69, 158. https://doi.org/10.3390/engproc2024069158
Taormina R, van der Werf JA. Interpretable Sewer Defect Detection with Large Multimodal Models. Engineering Proceedings. 2024; 69(1):158. https://doi.org/10.3390/engproc2024069158
Chicago/Turabian StyleTaormina, Riccardo, and Job Augustijn van der Werf. 2024. "Interpretable Sewer Defect Detection with Large Multimodal Models" Engineering Proceedings 69, no. 1: 158. https://doi.org/10.3390/engproc2024069158
APA StyleTaormina, R., & van der Werf, J. A. (2024). Interpretable Sewer Defect Detection with Large Multimodal Models. Engineering Proceedings, 69(1), 158. https://doi.org/10.3390/engproc2024069158