
Machine Learning Model for Battle of Water Demand Forecasting †

 ,
, 
 and
and
Abstract
1. Introduction
2. Materials and Methods
- Division Point Selection: ExtraTrees selects a division point at random for each candidate feature and chooses the best of these random divisions.
- Tree Construction: Trees are grown to their maximum depth without pre-pruning, resulting in fewer leaf nodes. Random selection of split points and features avoids exhaustive search processes, making the algorithm efficient even with large amounts of data.
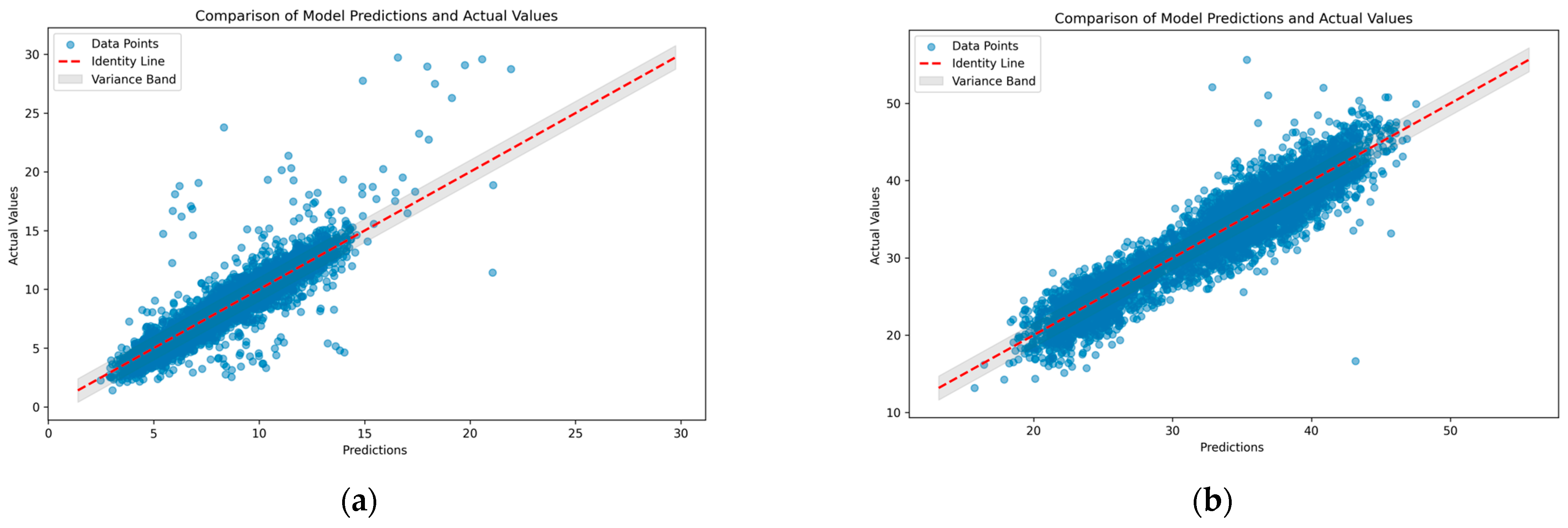
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pu, Z.; Yan, J.; Chen, L.; Li, Z.; Tian, W.; Tao, T. A hybrid Wavelet-CNN-LSTM deep learning model for short-term urban water demand forecasting. Front. Environ. Sci. Eng. 2023, 17, 22. [Google Scholar] [CrossRef]
- Donkor, E.A.; Mazzuchi, T.A.; Soyer, R.; Roberson, J.A. Urban Water Demand Forecasting: Review of Methods and Models. J. Water Resour. Plan. Manag. 2014, 140, 146–159. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]

{kind=link}
| DMA | Mean RMSE | RMSE Std Dev | Test RMSE | % Error |
|---|---|---|---|---|
| A | 1.247 | 0.170 | 1.102 | 9.18 |
| B | 0.474 | 0.030 | 0.477 | 3.11 |
| C | 0.439 | 0.017 | 0.449 | 6.11 |
| D | 2.449 | 0.098 | 2.423 | 5.78 |
| E | 2.080 | 0.119 | 2.201 | 1.71 |
| F | 0.949 | 0.027 | 0.942 | 8.91 |
| G | 1.373 | 0.175 | 1.330 | 3.68 |
| H | 1.026 | 0.252 | 0.891 | 3.18 |
| I | 1.310 | 0.047 | 1.326 | 4.84 |
| J | 1.347 | 0.071 | 1.333 | 3.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pagano, M.; Santonastaso, G.F.; Di Nardo, A.; Cuomo, S.; Schiano Di Cola, V. Machine Learning Model for Battle of Water Demand Forecasting. Eng. Proc. 2024, 69, 37. https://doi.org/10.3390/engproc2024069037
Pagano M, Santonastaso GF, Di Nardo A, Cuomo S, Schiano Di Cola V. Machine Learning Model for Battle of Water Demand Forecasting. Engineering Proceedings. 2024; 69(1):37. https://doi.org/10.3390/engproc2024069037
Chicago/Turabian StylePagano, Mario, Giovanni Francesco Santonastaso, Armando Di Nardo, Salvatore Cuomo, and Vincenzo Schiano Di Cola. 2024. "Machine Learning Model for Battle of Water Demand Forecasting" Engineering Proceedings 69, no. 1: 37. https://doi.org/10.3390/engproc2024069037
APA StylePagano, M., Santonastaso, G. F., Di Nardo, A., Cuomo, S., & Schiano Di Cola, V. (2024). Machine Learning Model for Battle of Water Demand Forecasting. Engineering Proceedings, 69(1), 37. https://doi.org/10.3390/engproc2024069037