
Image Descriptions for Visually Impaired Individuals to Locate Restroom Facilities †

Abstract
:1. Introduction
2. Literature Review
2.1. Vision-Language Models
2.2. The BLIP Model
2.3. Joint Pre-Training of BLIP Model
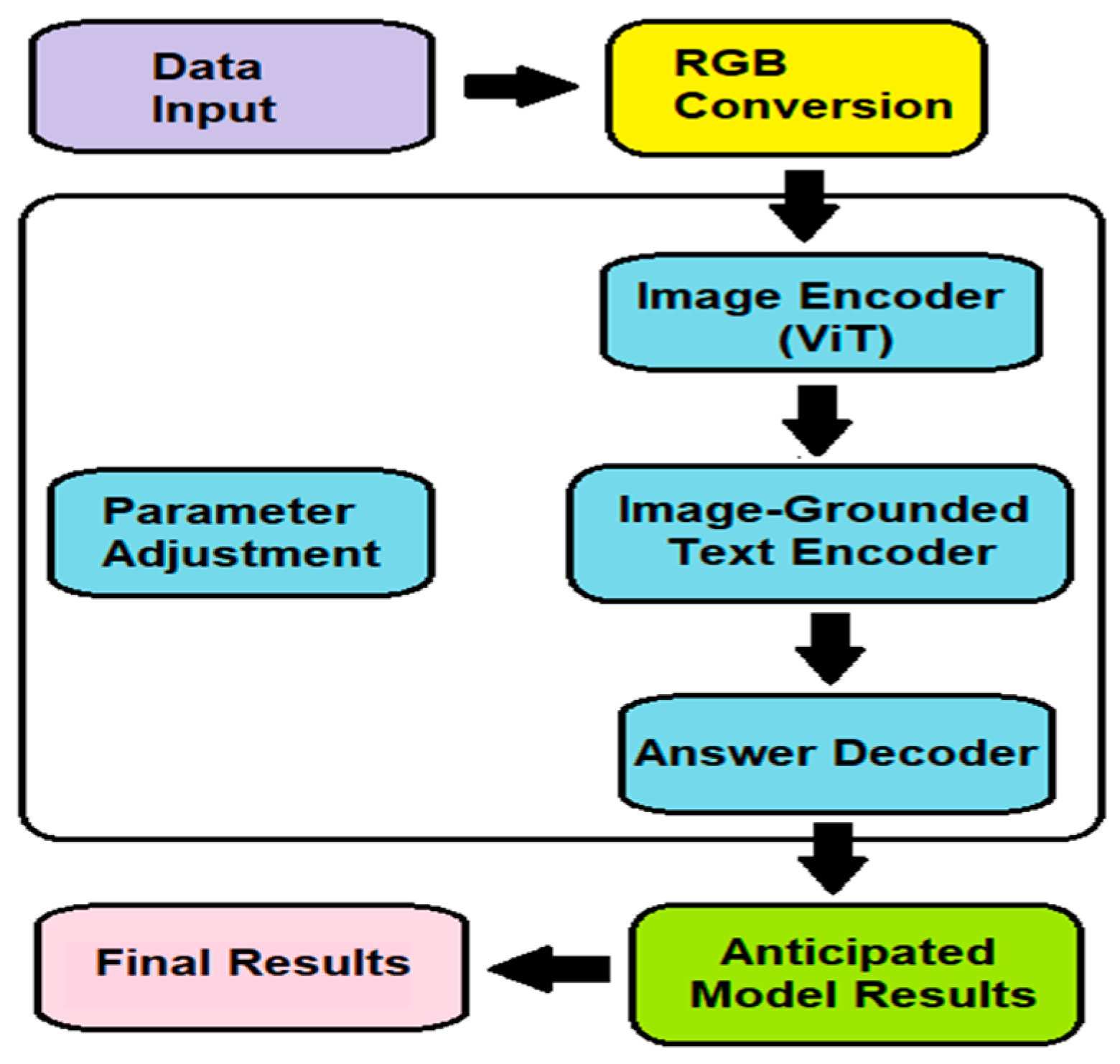
3. Methodology
3.1. Algorithm Architecture
3.2. Speech Synthesis Program
3.3. Training BLIP Model
3.4. Execution Environment
3.5. Device
3.6. Metrics for Evaluation of Model Performance
4. Results and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abhishek, S.; Sathish, H.; K, A.K.; T, A. Aiding the visually impaired using artificial intelligence and speech recognition technology. In Proceedings of the 4th International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 21–23 September 2022; pp. 1356–1362. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. BLIP: Bootstrapping Language-Image Pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Song, H.; Song, Y. Target research based on BLIP model. Acad. J. Sci. Technol. 2024, 9, 80–86. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft Coco: Common objects in context. In Proceedings of the Computer Vision-ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Patil, K.; Kharat, A.; Chaudhary, P.; Bidgar, S.; Gavhane, R. Guidance system for visually impaired people. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 988–993. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, C.S.; Wang, C.J.; Wang, J.W.; Liu, Y.C. UY-NET: A two-stage network to improve the result of detection in colonoscopy images. Appl. Sci. 2023, 13, 10800. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the Ninth International Conference on Learning Representations (ICLR 2021), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Thomas, A.; U, S.; Barman, S. Third eye: AI based vision system for visually impaired using deep learning. In Futuristic Trends in Artificial Intelligence; Interactive International Publishers: Bangalore, India, 2023; Volume 2, pp. 101–112. [Google Scholar]
- Tang, X.; Wang, Y.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Interacting-enhancing feature transformer for crossmodal remote-sensing image and text retrieval. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5611715. [Google Scholar] [CrossRef]
- Zeng, R.; Ma, W.; Wu, X.; Liu, W.; Liu, J. Image-text cross-modal retrieval with instance contrastive embedding. Electronics 2024, 13, 300. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, H.; Qi, G.; Cai, J. Causal attention for vision-language tasks. In Proceedings of the IEEE/CVF on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9842–9852. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. Int. J. Comput. Vis. 2016, 127, 398–414. [Google Scholar] [CrossRef]
- Orynbay, L.; Razakhova, B.; Peer, P.; Meden, B.; Emeršič, Ž. Recent advances in synthesis and interaction of speech, text, and vision. Electronics 2024, 13, 1726. [Google Scholar] [CrossRef]
- Post, M. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation, Brussels, Belgium, 31 October–1 November 2018; pp. 186–191. [Google Scholar]
- Streijl, R.C.; Winkler, S.; Hands, D.S. Mean opinion score (MOS) revisited: Methods and applications, limitations and alternatives. Multimed. Syst. 2016, 22, 213–227. [Google Scholar] [CrossRef]
- González-Chávez, O.; Ruiz, G.; Moctezuma, D.; Ramirez-delReal, T. Are metrics measuring what they should? An evaluation of image captioning task metrics. Signal Process. Image Commun. 2024, 120, 117071. [Google Scholar] [CrossRef]
- Computing and Reporting BLEU Scores. Available online: https://bricksdont.github.io/posts/2020/12/computing-and-reporting-bleu-scores/ (accessed on 22 August 2024).
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: Scaling text-to-speech with convolutional sequence learning. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–16. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operational System | Environment | Programming Language | Framework | Training Color Space | Image Resolution | CPU | Router |
|---|---|---|---|---|---|---|---|
| Windows | Anaconda | Python | Torch | RGB | QVGA (320 × 240) | Intel Core i7 2.60 GHz | TP-Link (LAN) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.-S.; Lo, N.-K.; Chien, Y.-H.; Lin, S.-S. Image Descriptions for Visually Impaired Individuals to Locate Restroom Facilities. Eng. Proc. 2025, 92, 13. https://doi.org/10.3390/engproc2025092013
He C-S, Lo N-K, Chien Y-H, Lin S-S. Image Descriptions for Visually Impaired Individuals to Locate Restroom Facilities. Engineering Proceedings. 2025; 92(1):13. https://doi.org/10.3390/engproc2025092013
Chicago/Turabian StyleHe, Cheng-Si, Nan-Kai Lo, Yu-Huan Chien, and Siao-Si Lin. 2025. "Image Descriptions for Visually Impaired Individuals to Locate Restroom Facilities" Engineering Proceedings 92, no. 1: 13. https://doi.org/10.3390/engproc2025092013
APA StyleHe, C.-S., Lo, N.-K., Chien, Y.-H., & Lin, S.-S. (2025). Image Descriptions for Visually Impaired Individuals to Locate Restroom Facilities. Engineering Proceedings, 92(1), 13. https://doi.org/10.3390/engproc2025092013