Abstract
Statistical inference is used to estimate population parameters based on sample information and to quantify the sampling error based on the probability narrative. The population mean is inferred by its sample mean, but when using sample variance, the population variance is needed. In the quantitative analysis of the sampling error, the t-distribution is used. To determine the percentiles of the t-distribution, the cumulative probability density function is necessary. However, the analytic expression does not exist for the cumulative probability density function of the t-distribution. Its values are obtained using numerical integration. However, the percentiles of the t-distribution are not listed for degrees of freedom over 30, while only listed for every 10 data points in probability theory or mathematical statistics. This is inconvenient for research. Therefore, the cumulative probability density function of t-distribution was calculated using the Gaussian integration method in this study. The results show that the percentiles of the t-distribution are accurately estimated using the algorithm developed in this study.
1. Introduction
The census is conducted to measure or examine the statistics of a population. Sampling is performed to measure or examine members of a population. As the census is costly and time-consuming, sampling errors are critical, and artificial errors occur due to personnel fatigue. Therefore, the census is not more efficient than sampling.
The t-distribution is used in the quantitative analysis of sampling errors. To determine the percentiles of the t-distribution, its cumulative probability density function is used [1,2,3]. The function is derived by numerical integration. The Gaussian integration method is adopted in this study to integrate the probability density function of the t-distribution [4,5]. The integrand is fitted through the power series by the Gaussian integration method. If the step size is small enough and does not lead to the truncating error, accurate numerical integration is anticipated. The results of this study show that a high accuracy of percentiles of the t-distribution can be obtained using the algorithm developed in this article.
2. Gaussian Integration Method
Using the Gaussian integration method, +1 and −1 are taken as the upper and the lower limit, respectively. The integration result is obtained by summing specific integrand function values by multiplying the corresponding weights. These specific points are called Gaussian points [4,5].
For example, the two-point formula (m = 2 in (1)) is analyzed as follows.
When m equals 2 in (1), there are two weighting coefficients w1, w2, and two sampling points, λ1 and λ2, are obtained in advance. There are four unknowns and let
When are arbitrary, the following condition is satisfied:
This implies the following:
in (3) must be satisfied. Therefore,
Let in (3), then
When in (3), we have
When in (3),
Using (4) to (7),
Evaluation accuracy increases along with the increasing number of Gaussian points. The sampling points with sampling numbers 1 through 6 and their corresponding weighting coefficients, respectively, are listed in Table 1 [4,5].

Table 1.
Sampling points with sampling numbers 1 through 6 and their corresponding weighting coefficients, respectively.
If the upper and lower limits are not exactly equal to +1 and −1,
Equation (9) can be normalized as
Then,
By solving (11) and (12),
Substituting (15) and (16) into (9), the following is obtained:
3. Evaluation Percentiles of T-Distribution
The t-distribution is the abbreviation of Student′s t-distribution. The t-distribution was proposed by William Sealy Gosset. The t-distribution is used to infer the population mean with a small sample size and a normal distribution without its population variance. The quantitative analysis of sampling error always involves the t-distribution.
The probability density function of the t-distribution with degrees of freedom n is calculated as
where n is the degree of freedom and
is the Gamma function.
For the degree of freedom n in (18) to be a natural number,
and
To evaluate the percentile in Figure 1, must be evaluated. The probability of the random variable with a t-distribution greater than is . To find , (21) is used.
or
where is the function of in (22). The inverse function does not exist. That is found in Newton’s iteration method. Equation (22) is rewritten as
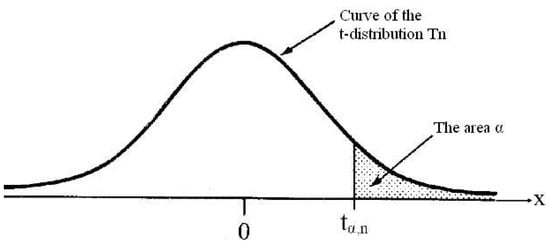
Figure 1.
The 100(1 − α) percentile tα,n corresponding to degrees of freedom n.
Then, to find ,
To give a guess value ,
and the iteration is conducted. in (26) is obtained by the following numerical differentiation.
Because the probability density function of the t-distribution is symmetric to x = 0, the five-point Gaussian integration method is adopted, and the interval (0,) is divided into equally spaced subintervals. With a guess value of 1.0, in (27) is set to , and the iteration is stopped when the magnitude of becomes smaller than . The 100(1 − ) percentile corresponds to the degrees of freedom n of 1 through 120, respectively, and equal to 0.200, 0.100, 0.050, 0.025, 0.010, 0.005, 0.001, and 0.0005, respectively (Table 2).
Table 2.
The 100(1 − ) percentile corresponding to the degrees of freedom n equal to 1 through 120, respectively, and equal to 0.200, 0.100, 0.050, 0.025, 0.010, 0.005, 0.001, and 0.0005, respectively.
4. Conclusions
The derivation process of the Gaussian numerical integration using (1)–(17) shows that when m = 2, two weight coefficients, w1 and w2, need to be determined at two sampling points, λ1 and λ2, resulting in four unknowns. The integrand is fitted as a cubic polynomial. Therefore, the form of the integrand in (1) is
where m is the number of sampling points in the Gaussian integral. Using (1) for integration, the theoretical error approaches zero even if the integration interval is not subdivided. However, since the probability density function of the t-distribution in (19) does not have the finite polynomial form as in (28), it is necessary to appropriately partition the integration interval before applying Gaussian integration with m sampling points and summing the results.
The probability density function of the t-distribution with degrees of freedom n (19) indicates that the percentile for n = 1 is particularly difficult to calculate accurately, especially the percentile
The value is calculated to verify the correctness of the 100(1 − α) percentiles of the t-distribution listed in Table 2. The Newton–Raphson method is used to calculate the percentiles of the t-distribution (26) and (27), with an initial guess of 1.0 and an increment equal to in (27). Iteration stops when the adjustment in (26) is smaller than a specified threshold .
For n = 1, . The Gaussian integration method is used with m = 5 sampling points, dividing the interval from 0 to the specified limit into equal subintervals, and the result is after 15 iterations. The interval is partitioned from 0 to into varying numbers of equal subintervals for NSECT = 100, 175, 250, 500, 750, 1000, 2500, 5000, , , , and , and the results are listed in Table 3. Partitioning the interval into 1000 to 2500 subintervals yields the t-distribution’s 100(1 – 0.0005) percentile approaching 636.619249. Moreover, as the value of NSECT increases, the calculated result remains 636.619249, indicating that there is no issue with rounding errors in the computation process.
Table 3.
The 100(1 – 0.0005) percentiles by partitioning the interval from 0 to into varying numbers of equal subintervals for NSECT = 100, 175, 250, 500, 750, 1000, 2500, 5000, , , and .
To verify the accuracy of = 636.619249, = 636.619249 in (23) for validation. The interval is partitioned from 0 to 636.619249 into various numbers of equal subintervals. NSECT = 100, 175, 250, 500, 750, 1000, 2500, 5000, , , and , and the probability is that the random variable of the t-distribution exceeds 636.619249 (Table 4). If the number of subintervals NSECT exceeds 750, the probability is accurately calculated as 0.000500.
Table 4.
The probability that a random variable of the t-distribution exceeds the value 636.619249 by partitioning the interval from 0 to 636.619249 into various numbers of equal subintervals, NSECT = 100, 175, 250, 500, 750, 1000, 2500, 5000, , , , and .
The negative result for NSECT = 100 arises because 100 is too small, increasing error and yielding a probability greater than 0.5. Thus, it is reasonable to conclude that using increments as in (27), stopping iteration when the adjustment in (26) is less than a specified threshold , and selecting an appropriate number of subintervals is valid. Each of the 100(1 − α) percentiles of the t-distribution in Table 2 is calculated in five seconds. Furthermore, rounding the values in Table 2 to three decimal places yields results that match exactly with those from highly authoritative publications [6].
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The author declares no conflict of interest.
References
- Montgomery, D.C. Design and Analysis of Experiments; John Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Lee, J.B.; Max, E. Introduction to Probability and Mathematical Statistics; Duxbury Press: Belmont, CA, USA, 1992. [Google Scholar]
- Jay, L.D. Probability and Statistics for Engineering and the Sciences; Brooks/Cole: Pacific Grove, CA, USA, 2012. [Google Scholar]
- Zienkiewicz, O.C. The Finite Element Method; McGraw-Hill Book Co.: Maidenhead, UK, 1977. [Google Scholar]
- Bathe, K.J. Finite Element Procedures in Engineering Analysis; Prentice-Hall: Upper Saddle River, NJ, USA, 1982. [Google Scholar]
- Pearson, E.S.; Hartley, H.O. Biometrika Tables for Statisticians; Cambridge University Press: Cambridge, UK, 1966. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).