
Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data †

 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Data Modeling
2.2.1. Data Pre-Processing
- Structuring phase: The first step in the process of structuring the dataset was to organize the information in a single format since there were two datasets, one of the hydrological parameters and the other of meteorological parameters. The meteorological dataset had shifted columns and needed to be organized to execute the analysis correctly.
- Data cleaning phase: Considering the technical specifications of the different sensors, it was determined which data were outside the specified range for each measurement tool. We continued reviewing which treatment plants had sufficient turbidity data, which resulted in a dataset consisting of one treatment plant in the urban area and three treatment plants in the rural area.
- Data fusion phase: Once the data were organized and cleaned, a data fusion was performed with the dataset taken by IDEAM. Since both sets did not have the same time scale, a temporal adaptation was made to the IDEAM dataset to match each point in the database obtained from the previous phases.
2.2.2. Exploratory Analysis of Data
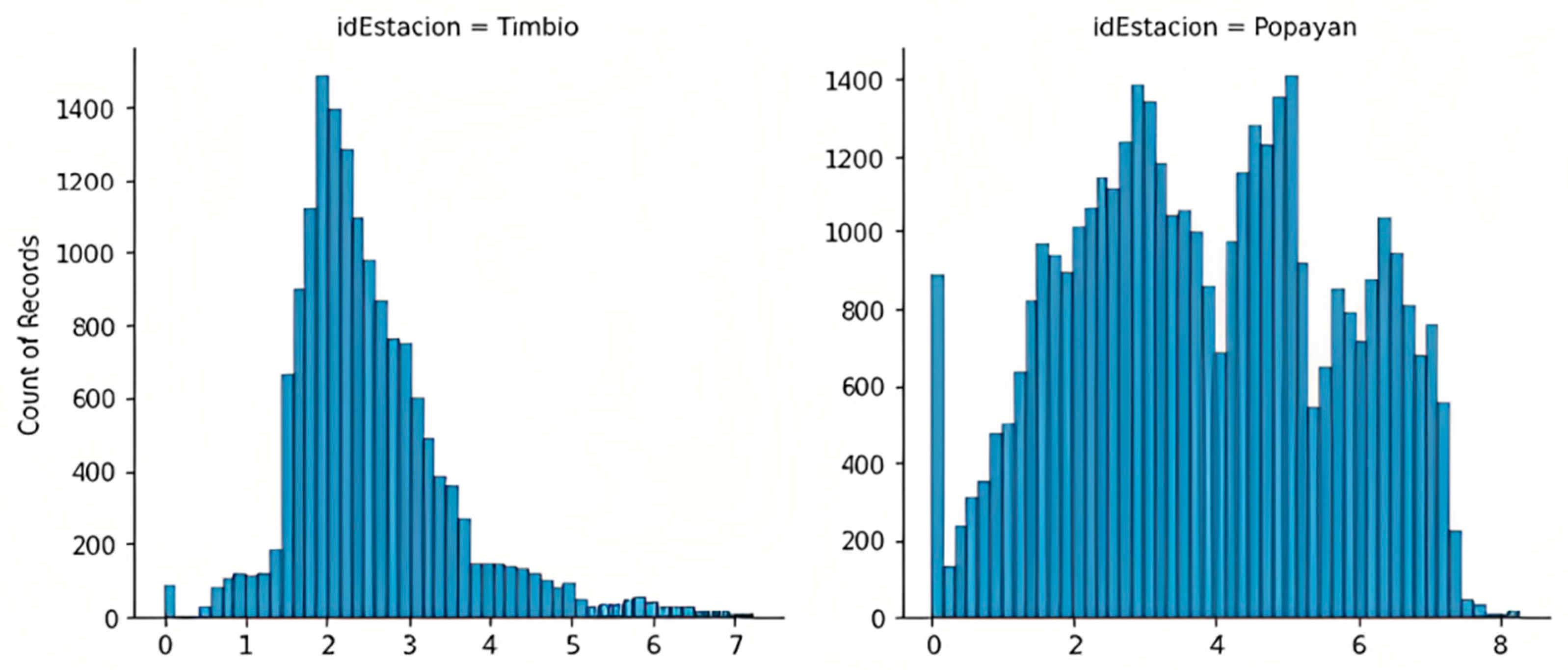
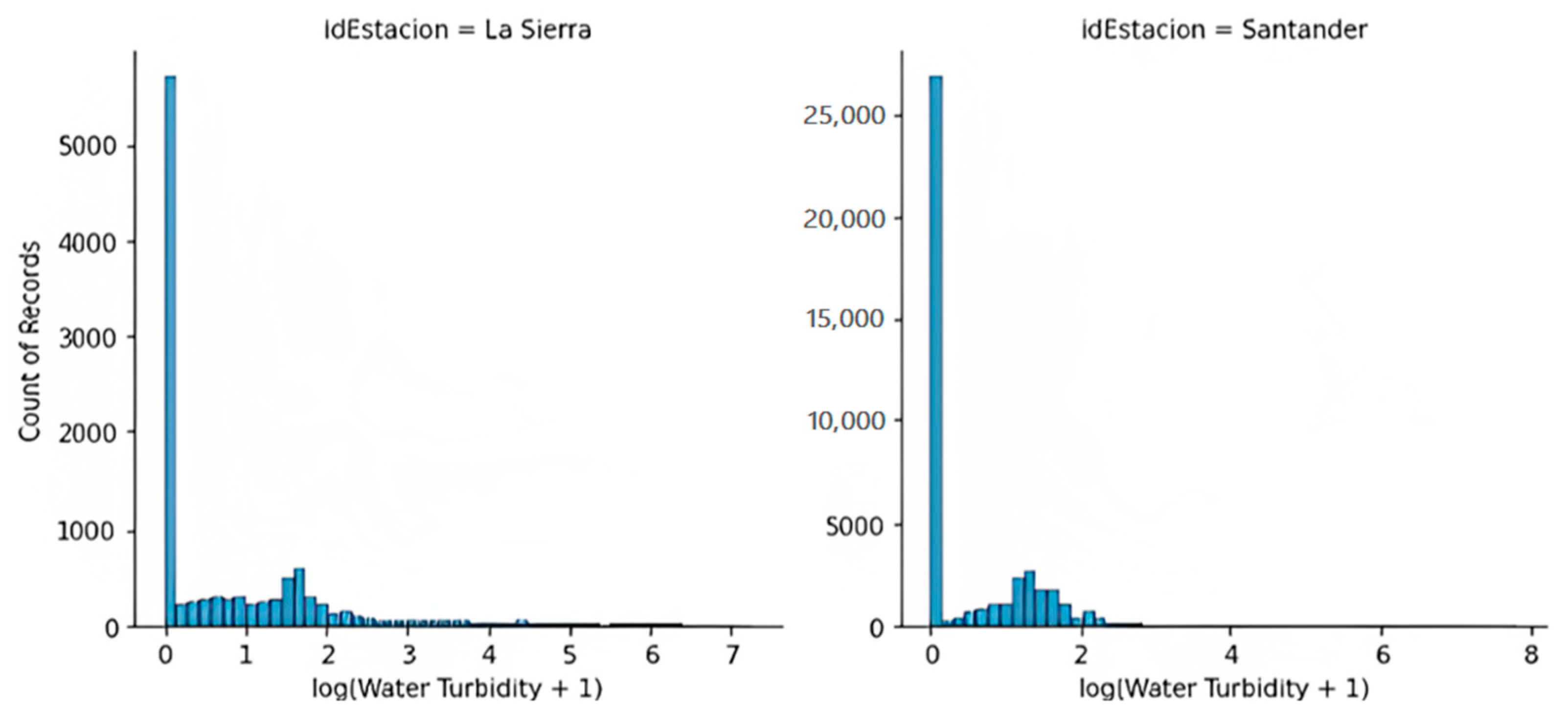
- Distribution of water turbidity: When evaluating the distribution of turbidity in the four treatment plants, distributions with long skews to the right are found. To correct the variable’s asymmetry and to obtain a better view of its distribution, a logarithmic transformation was applied to make the water turbidity as close as possible to the normal distribution. Given the large number of zero values in the turbidity measurements, an additional unit was added to avoid −∞ values. The following equation was applied for the logarithmic transformation of the water turbidity variable:
- Analysis of the relationship of variables with turbidity: A correlation analysis was conducted to investigate the possible relationship between turbidity and various water variables at all stations. In the initial phase of the study, no significant correlation was found between turbidity and variables, such as pH, DO, conductivity, and ORP. Thus, we performed an additional analysis to improve the correlation, consisting of the logarithmic transformation of the turbidity variable and the correlation with the water variables from the first analysis. Although an increase in correlation coefficients was observed, they were still considered low, indicating no linear relationship between turbidity and the examined water variables. This result suggests the need for a non-linear model to capture the complexity of the relationship between these variables. Otherwise, models could generate inaccurate data or significant error metrics, making interpretation and decision-making difficult.
2.2.3. Data Modeling
- Linear and non-linear models (linear regression, tree-based models).
- With or without outliers.
- With random or temporal division.
- With all stations, with Popayan information only, or with all stations except Popayan.
- With dummy variables that categorize the station.
- With all parameters or only with the most important ones.
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miljojkovic, D.; Trepsic, I.; Milovancevic, M. Assessment of physical and chemical indicators on water turbidity. Phys. A Stat. Mech. Its Appl. 2019, 527, 121171. [Google Scholar] [CrossRef]
- World Health Organization. Water quality and health-review of turbidity: Information for regulators and water suppliers. 2017. Available online: https://apps.who.int/iris/handle/10665/254631. (accessed on 10 January 2023).
- Ministerio de Ambiente, Vivienda y Desarrollo Territorial Y Ministerio de Protección Social. Decreto no 2115 de 2007. (June 2007). Available online: https://minvivienda.gov.co/sites/default/files/normativa/2115%20-%202007.pdf (accessed on 10 January 2023).
- Marimon, W.; Jimenez, N.; Jiménez, C.; Chavarro, J.; Domínguez, E. Comparative Analysis of Water Quality Indices and Their Relationship with Anthropogenic Activities, Case Study: Bogotá River. Res. Square 2021. [Google Scholar] [CrossRef]
- García-Rentería, F.-F.; Nieto, G.A.C.; Cortez, G.H. Evaluation of wastewater discharge reduction scenarios in the Buenaventura Bay. Water 2023, 15, 1027. [Google Scholar] [CrossRef]
- Anexo 1. Available online: http://cinara.univalle.edu.co/images/convocatorias/Convocatoria2/Anexos/ANEXO%201 (accessed on 13 January 2023).
- Khairi, M.T.M.; Ibrahim, S.; Yunus, M.A.M.; Faramarzi, M.; Yusuf, Z. Artificial neural network approach for predicting the water turbidity level using optical tomography. Arab. J. Sci. Eng. 2015, 41, 3369–3379. [Google Scholar] [CrossRef]
- El Din, E.S.; Zhang, Y.; Suliman, A. Mapping concentrations of surface water quality parameters using a novel remote sensing and artificial intelligence framework. Int. J. Remote Sens. 2017, 38, 1023–1042. [Google Scholar] [CrossRef]
- Kim, S.E.; Seo, I.W. Artificial neural network ensemble modeling with conjunctive data clustering for water quality prediction in rivers. J. Hydro-Environ. Res. 2015, 9, 325–339. [Google Scholar] [CrossRef]
- Delpla, I.; Florea, M.; Rodriguez, M. Drinking water source monitoring using early warning systems based on data mining techniques. Water Resour. Manag. 2019, 33, 129–140. [Google Scholar] [CrossRef]
- Sharaf El Din, E. Enhancing the accuracy of retrieving quantities of turbidity and total suspended solids using Landsat-8-based-principal component analysis technique. J. Spat. Sci. 2019, 66, 493–512. [Google Scholar] [CrossRef]
- Miguel-Chinchilla, L.; Heasley, E.; Loiselle, S.; Thornhill, I. Local and landscape influences on turbidity in urban streams: A global approach using citizen scientists. Freshw. Sci. 2019, 38, 303–320. [Google Scholar] [CrossRef]
- DHIME. Available online: http://dhime.ideam.gov.co/webgis/home (accessed on 25 October 2022).



{kind=link}
{kind=link}
| Database | Data Division | Outlier Limit (NTU) | RMSE—In the Sample | RMSE: Sample Output |
|---|---|---|---|---|
| Stations (dummies), predictors: all parameters, turbidity prediction | Random | - | 202.30 | 206.93 |
| Stations (dummies), predictors: all parameters, box cox transformation and, log-turbidity prediction | Random | - | 225.83 | 223.54 |
| Stations (cat codes), predictors: pH, conductivity, potOxyReduction, PA, T and P, turbidity prediction, and data normalization. | Random | - | 202.16 | 203.39 |
| Stations (cat codes), predictors: pH, conductivity, potOxyReduction, PA, T and P, turbidity prediction, and data normalization. | Random | 62.6 | 8.85 | 8.85 |
| Model | Outlier Limit (NTU) | RMSE—In the Sample | RMSE: Sample Output |
|---|---|---|---|
| Stacking-Estimator K-Neighbors-Regressor | 300 | 0.0 | 8.0 |
| Stacking-Estimator Extra-Trees-Regressor | - | 7.38 | 9.26 |
| Make-union Extra-Trees-Regressor | 300 | 17.94 | 83.56 |
| Make-union Extra-Trees-Regressor | - | 79.68 | 118.61 |
| Stacking-Estimator Random-Forest-Regressor | 300 | 1.83 | 2.37 |
| Stacking-Estimator Random-Forest-Regressor | - | 20.92 | 3.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernandez Alvarez, V.; Granada Salazar, D.; Figueroa, C.; Corrales, J.C.; Casanova, J.F. Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data. Environ. Sci. Proc. 2023, 25, 89. https://doi.org/10.3390/ECWS-7-14326
Fernandez Alvarez V, Granada Salazar D, Figueroa C, Corrales JC, Casanova JF. Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data. Environmental Sciences Proceedings. 2023; 25(1):89. https://doi.org/10.3390/ECWS-7-14326
Chicago/Turabian StyleFernandez Alvarez, Vanessa, Daniela Granada Salazar, Cristhian Figueroa, Juan Carlos Corrales, and Juan Fernando Casanova. 2023. "Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data" Environmental Sciences Proceedings 25, no. 1: 89. https://doi.org/10.3390/ECWS-7-14326
APA StyleFernandez Alvarez, V., Granada Salazar, D., Figueroa, C., Corrales, J. C., & Casanova, J. F. (2023). Estimation of Water Turbidity in Drinking Water Treatment Plants Using Machine Learning Based on Water and Meteorological Data. Environmental Sciences Proceedings, 25(1), 89. https://doi.org/10.3390/ECWS-7-14326