
Towards Automated Cadastral Map Improvement: A Clustering Approach for Error Pattern Recognition


Abstract
1. Introduction
2. Data and Methods
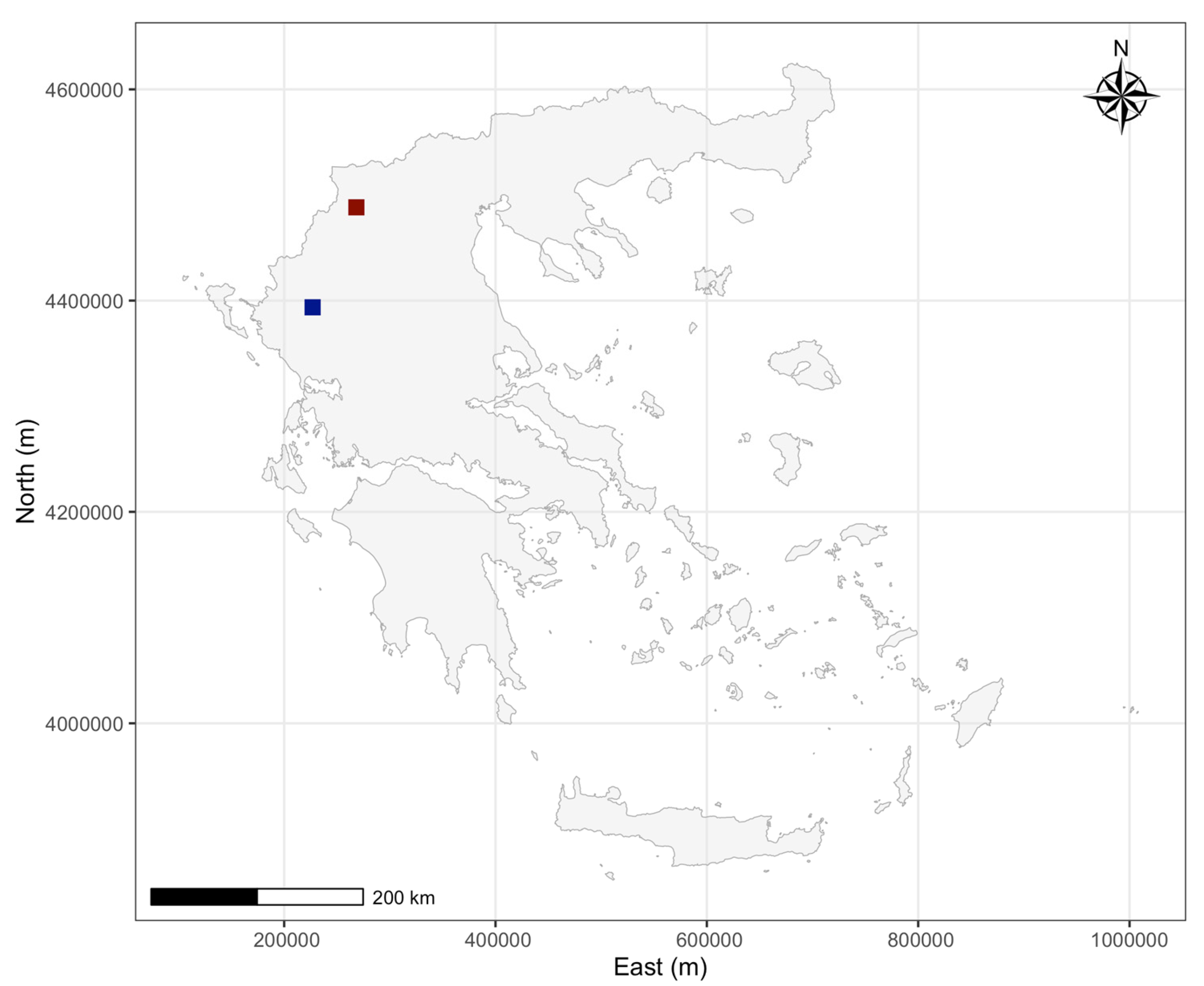
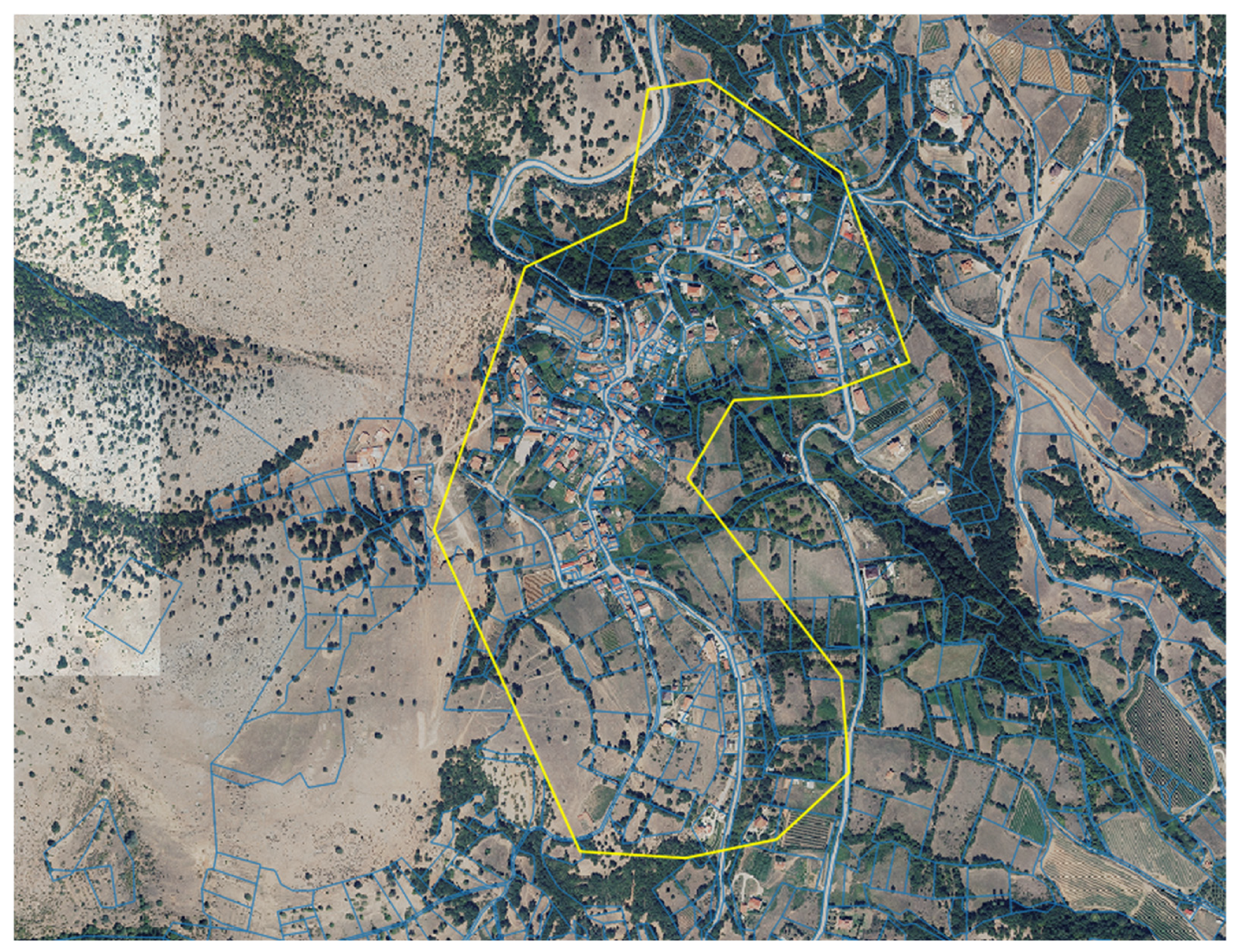
2.1. Study Area 1: Stavraki, Ioannina, Greece
2.2. Study Area 2: Kefalari, Kastoria, Greece
2.3. Data Sources
- GNC Data: The current (2025) digital vector data of the GNC maps were obtained from its open data portal [41] in shapefile format for both study areas. These data are referenced to the Hellenic Geodetic Reference System 1987 (HGRS87) [42], the official coordinate system for surveying applications in Greece;
- Land Survey Study Data: Higher-accuracy data were obtained from the digital land surveying study that was conducted by the Municipality of Ioannina in 2001 at a scale of 1:500. The survey was referenced to the Greek western zone of the Transverse Mercator (TM3 western zone) [43]. The purpose of this survey was to be the base map for the Implementing Act.
- The 1978 Land Distribution diagrams of Kefalari, that were conducted by the Greek Ministry of Agriculture in 1978, at a scale of 1:1000, were scanned and georeferenced using rubber-sheeting with QGIS software (version 3.42) [44]. These maps were referenced to the old Greek Datum (GR-Datum, [42,43]). Subsequently, the entire set of 101 parcels of the 1978 diagram was digitized into shapefile format.

2.4. Data Preprocessing
2.5. Clustering Algorithms
2.5.1. Fuzzy c-Means
2.5.2. Density-Based Spatial Clustering of Applications with Noise
2.5.3. Gaussian Mixture Models
- Expectation (E-step): Calculates the posterior probability of each component for each data point, given the current parameter estimates. This represents the probability that a data point belongs to a particular Gaussian component;
- Maximization (M-step): Updates the parameters to maximize the likelihood of the data, given the posterior probabilities calculated in the E-step.
2.6. Selection of the Algorithms
2.7. Evaluation and Clustering Validity
3. Results
3.1. Exploratory Analysis
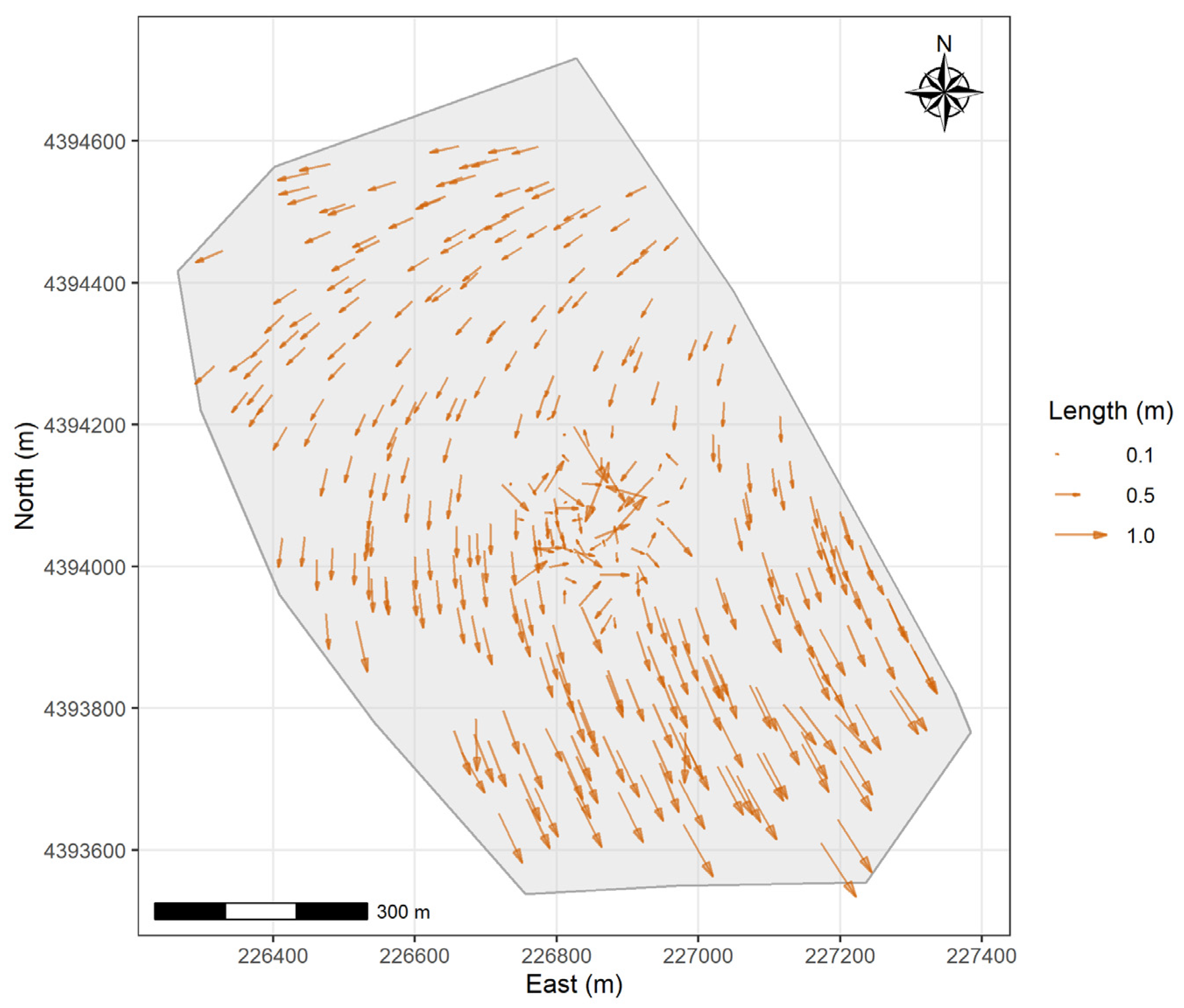
3.1.1. Stavraki
- Mean Error: The mean is close to zero (0.03 m), while the mean Δ is considerably larger and negative (−0.50 m). This indicates a systematic shift in the Northing direction between the 2025 and 2001 data;
- Symmetry: The near-zero skewness values for both and Δ suggest that the error distributions are approximately symmetric, although Δ has a slight positive skew;
- Tails: The negative kurtosis for ΔE indicates a platykurtic distribution that has lighter tails and a flatter peak compared to a normal distribution, whereas the positive value for ΔN is a leptokurtic distribution with heavier tails and a sharper peak;
- Variability: The CV for (10.67) is substantially larger than that for ΔNorth (0.66), indicating a greater relative variability in the Easting errors compared to the Northing errors;
- Skewness: Near-zero values suggest approximately symmetric distributions;
- Kurtosis: Low values indicate light tails, consistent with normal-like distributions.
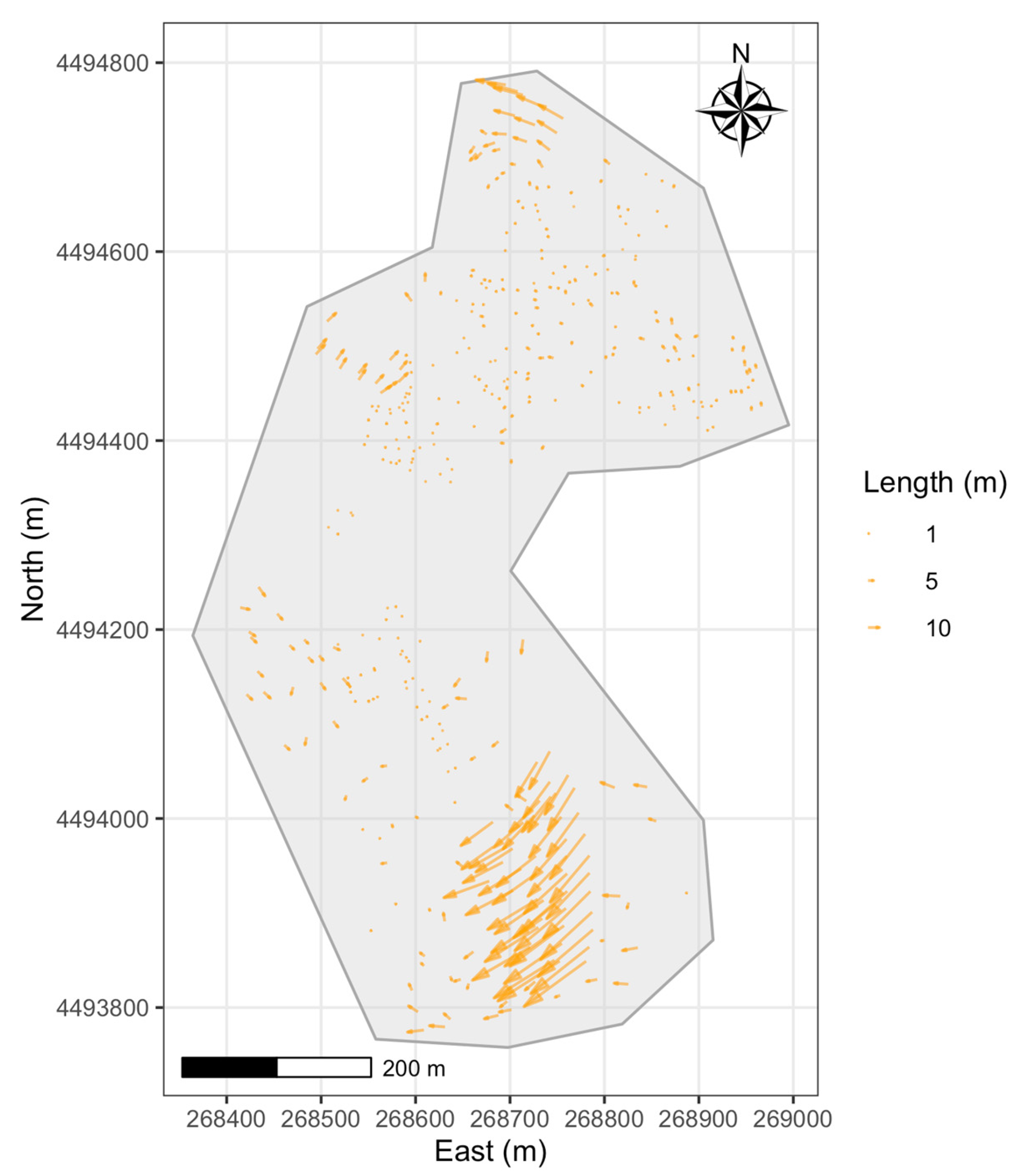
3.1.2. Kefalari
- Mean Error: Both mean ΔE and mean ΔN are considerably negative. This indicates a large, systematic shift primarily towards the west and south across the study area. The mean error magnitude is very high at 8.82 m.
- Variability: The standard deviations for both ΔE and ΔN are extremely large, signifying considerable variability and spread in the error magnitudes. The maximum error length reaches over 65 m.
- Distribution Shape (Skewness and Kurtosis): The large negative skewness values indicate that the error distributions are heavily skewed towards large negative errors. The high positive kurtosis values suggest leptokurtic distributions with heavy tails and sharp peaks, influenced by the presence of the very large error values.
3.2. Optimal Number of Clusters
3.2.1. Stavraki
- FCM: The elbow method was used, examining visually the WSS value as a function of the number of clusters (Figure 6). A distinct ‘elbow’ is observed between two and four clusters. By the principle of parsimony (preferring simpler models), k = 3 was selected as the optimal number of clusters, as it represents the point after which the improvement in explaining the variance becomes less considerable.
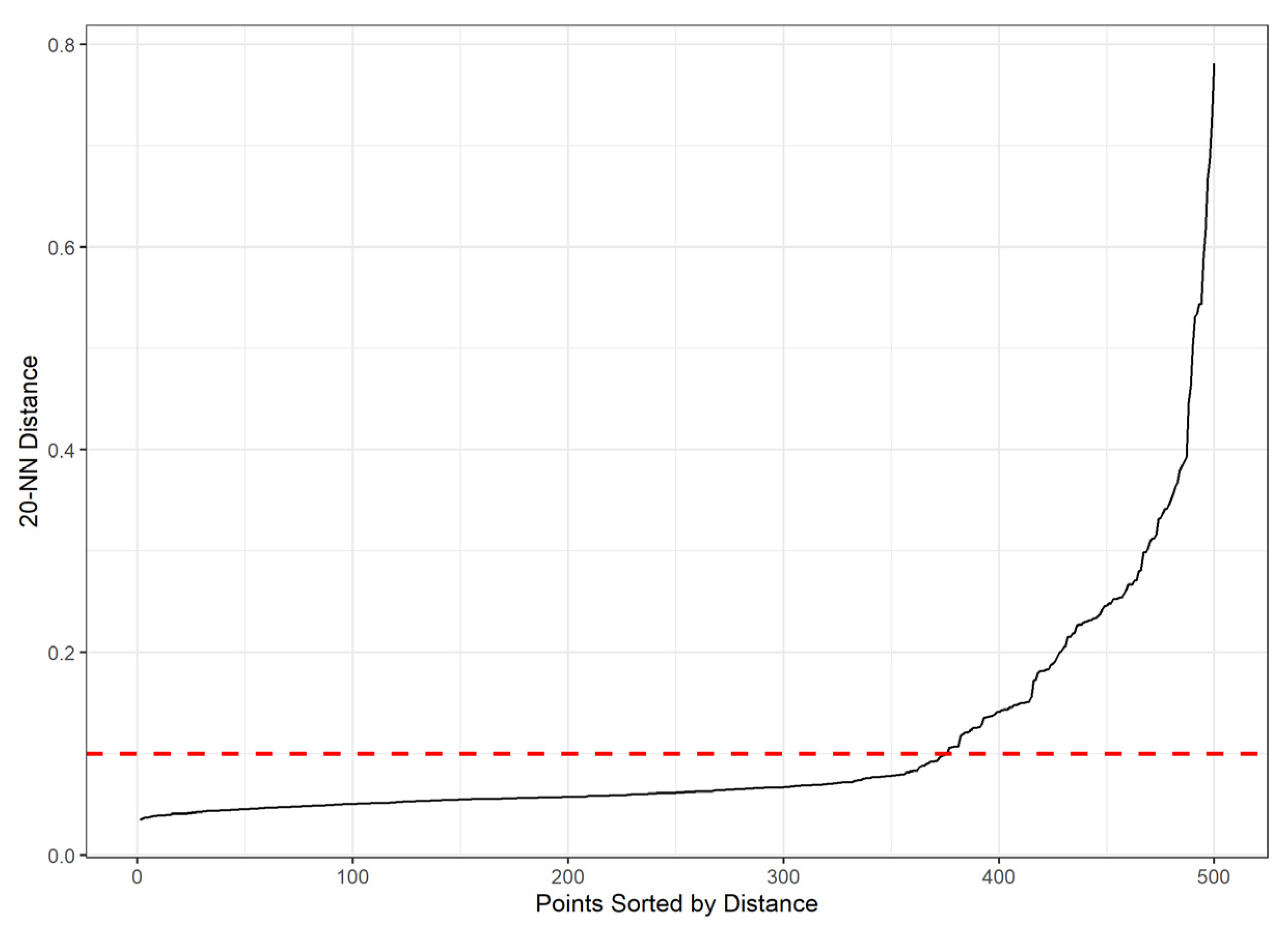
- DBSCAN: The 20-nearest neighbor distance plot (Figure 7) was examined. A visible ‘knee’ is observed around a distance of 0.10. Therefore, an ε value of 0.10 was selected. The value of was set to 20 points, to provide a stable local density estimate, which was validated through a visual inspection of the clustering results using different values of that parameter.
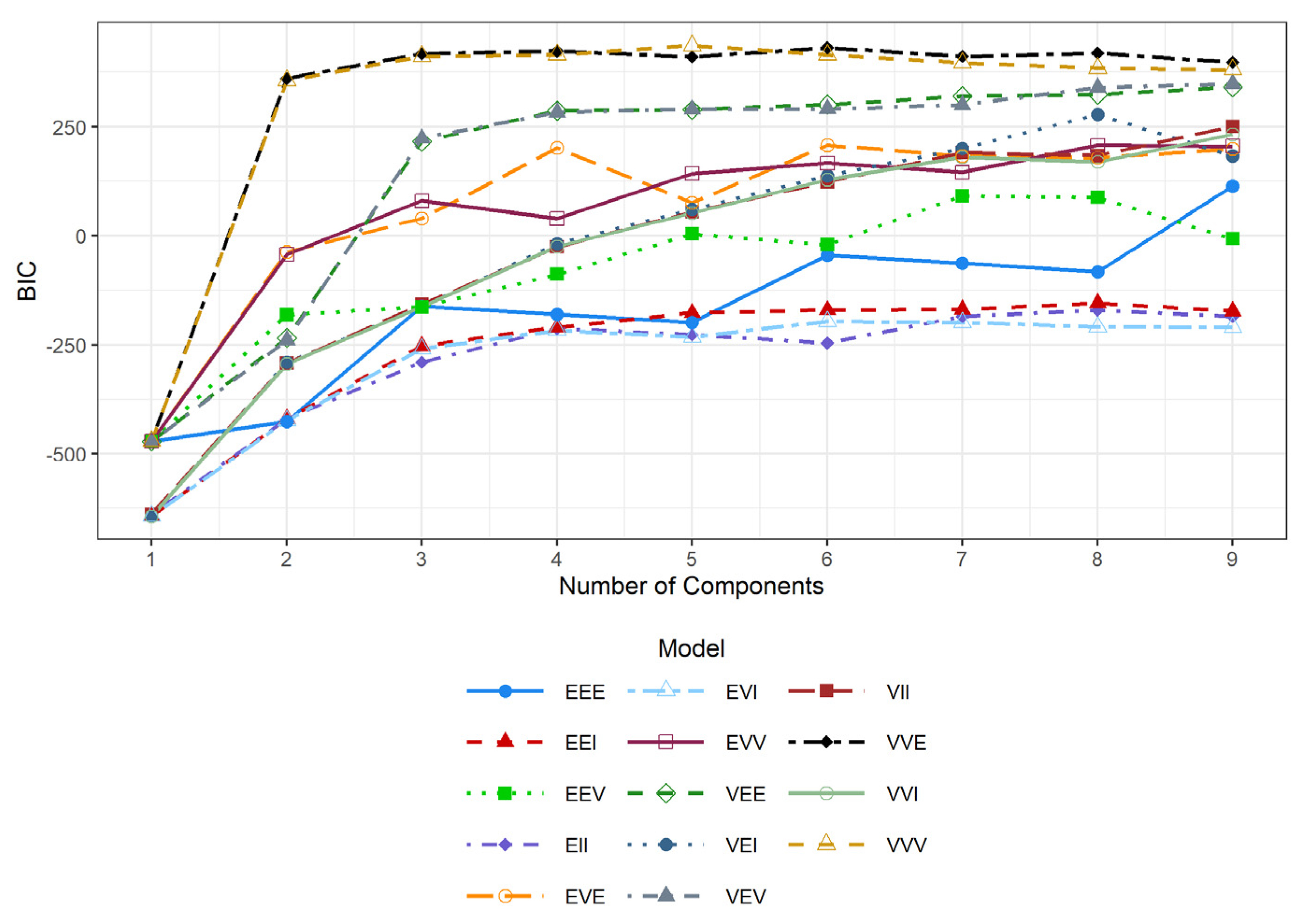
- GMM: The optimal number of components and covariance structures were selected using the Bayesian Information Criterion (BIC), which balances model fit against complexity [65] (Figure 8). Higher BIC values indicate a preferable model. Examining the BIC values across different models and component numbers, the optimal BIC was achieved for the ‘VVE’ (ellipsoidal, varying volume and shape, equal orientation) parameterization of the covariance matrix , with G = 2 components. Although models with G > 3 achieved higher BIC values, the visual inspection indicated that these led to spatially fragmented clusters lacking a clear interpretation consistent with the exploratory analysis. Therefore, the chosen model representing the peak BIC among simpler, interpretable clustering results was selected.
3.2.2. Kefalari
- FCM: A very distinct ‘elbow’, compared to Stavraki dataset, is observed at k = 2, after which the decrease in WSS becomes substantially less noticeable (Figure 9).
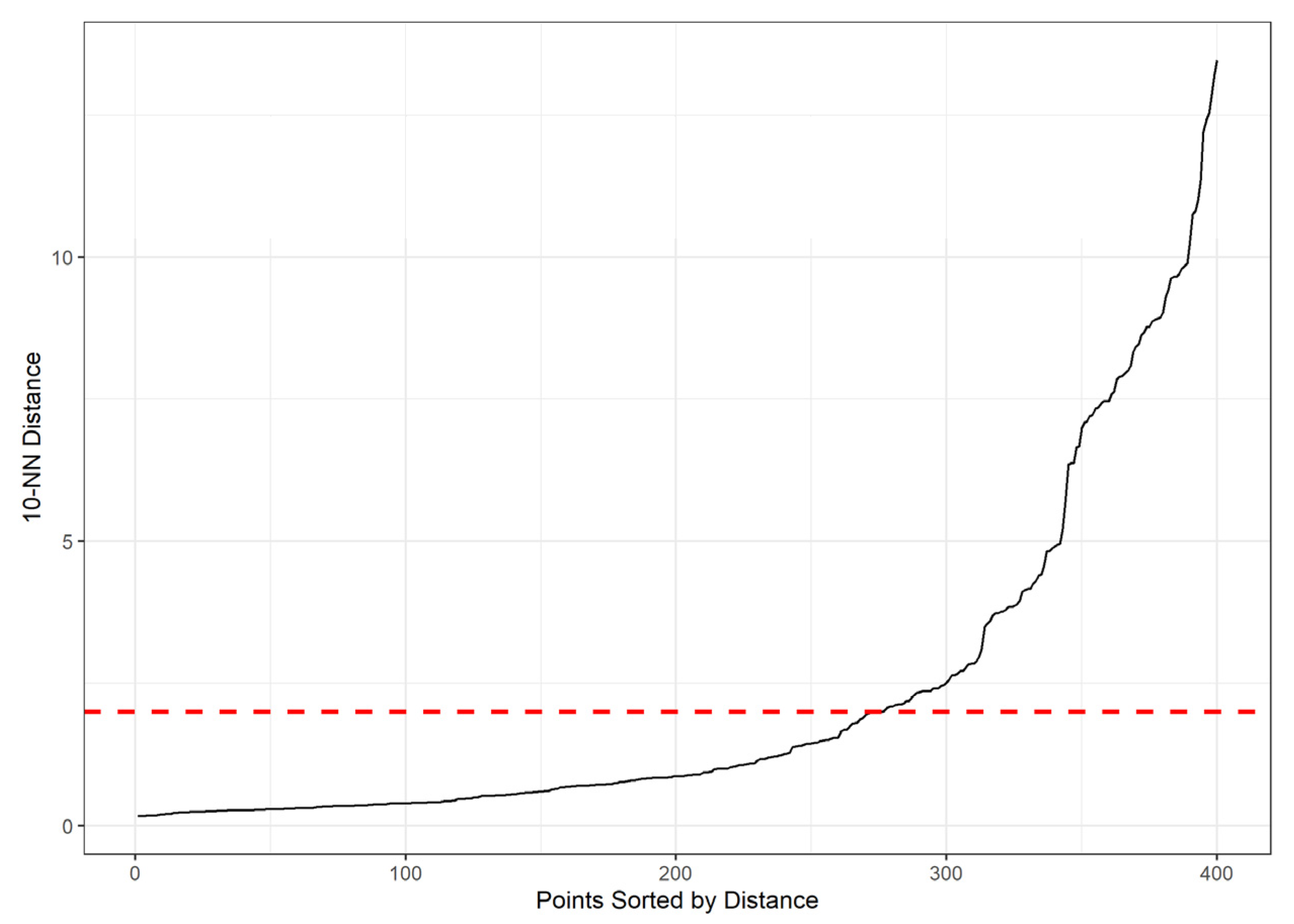
- DBSCAN: The 10-nearest neighbor distance plot (Figure 10) was examined. A visible ‘knee’, where the sorted distances begin to rise sharply, is observed around 2.0. Therefore, an ε value of 2.0 was selected.
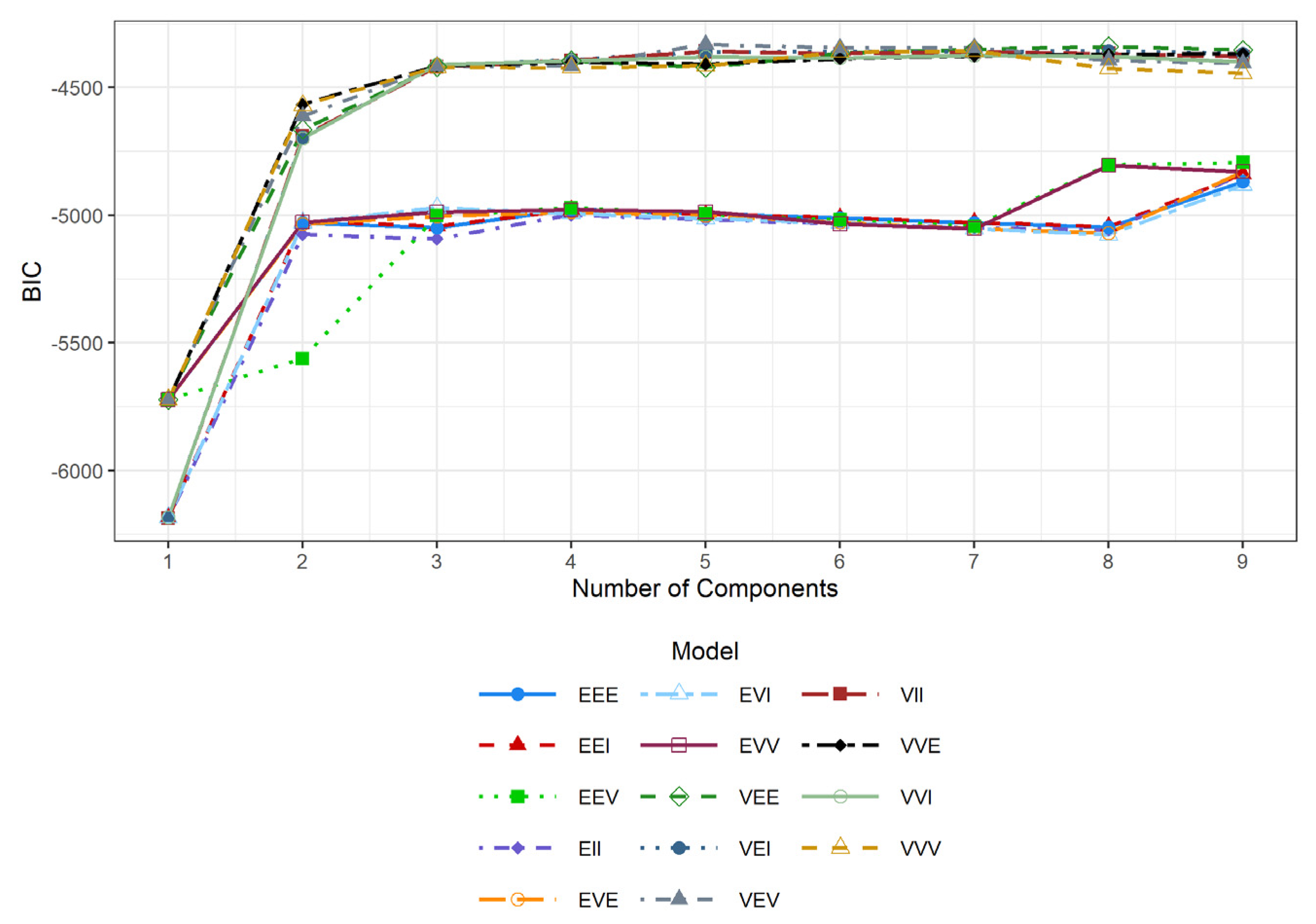
- GMM: Examining the BIC values across different models and component numbers, the optimal BIC was achieved for the ‘VVI’ (diagonal, varying volume, and shape) parameterization of the covariance matrix with G = 3 components (Figure 11). Although several models achieved higher BIC values for G > 5, these results were not consistent with the exploratory analysis.
3.3. Clustering Results—Visualizations
3.3.1. Stavraki
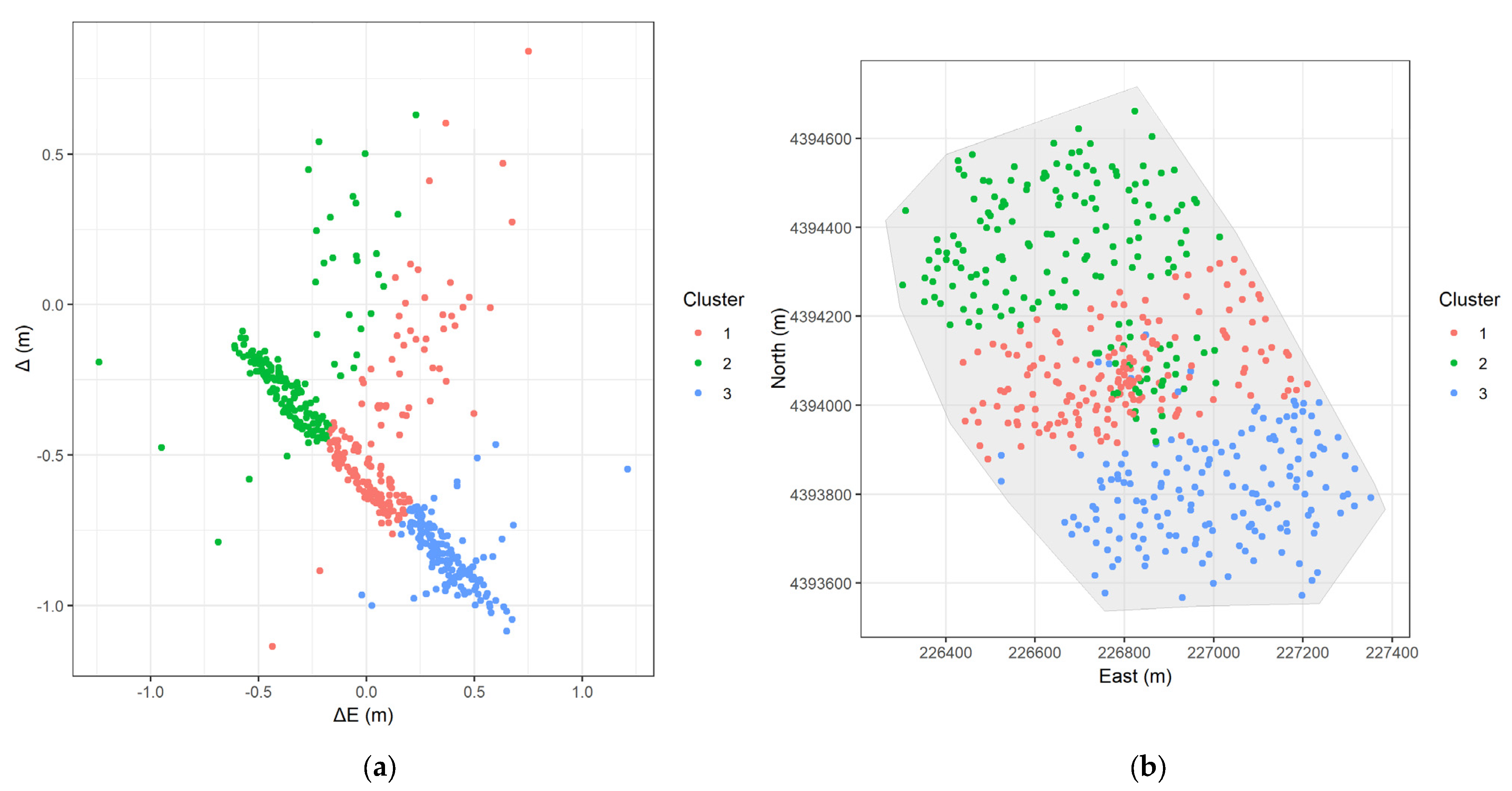
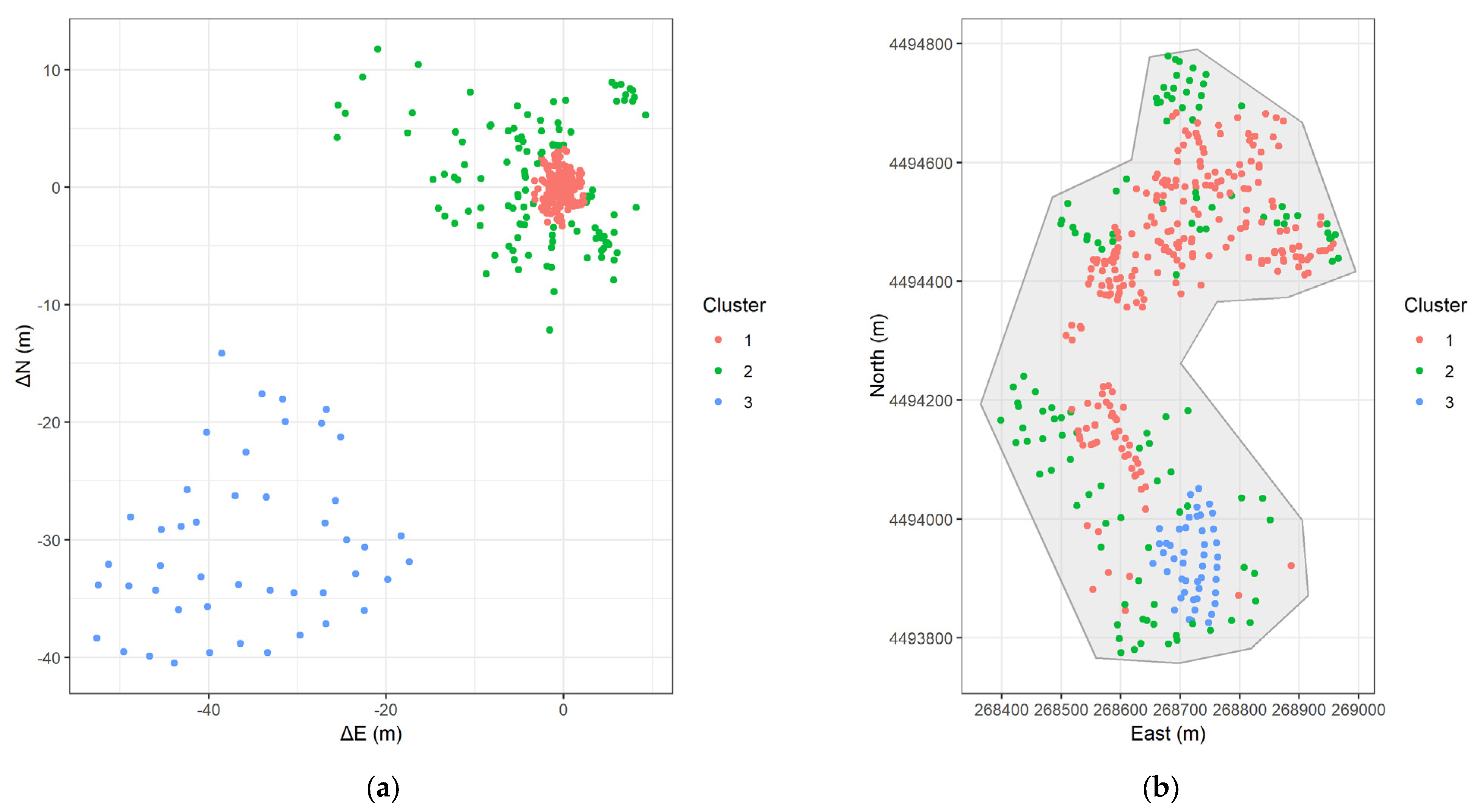
- FCM (Figure 12a): Three relatively well-separated clusters are formed. However, they do not capture the obvious linear pattern in the error space.
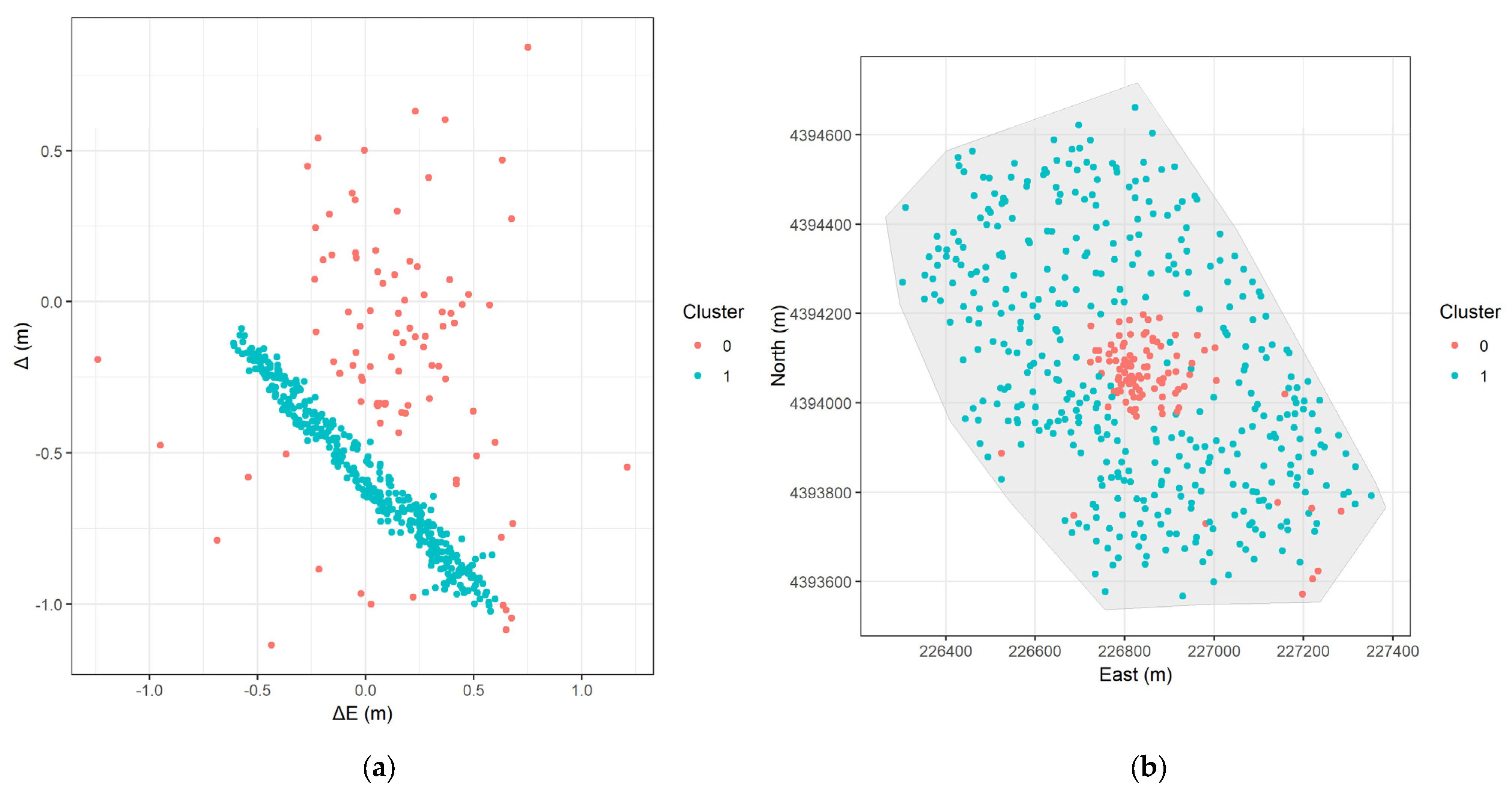
- DBSCAN (Figure 13a): The clear linear cluster (blue points) is identified as well as many noise points (red points). The linear cluster matches the suspected systematic error.
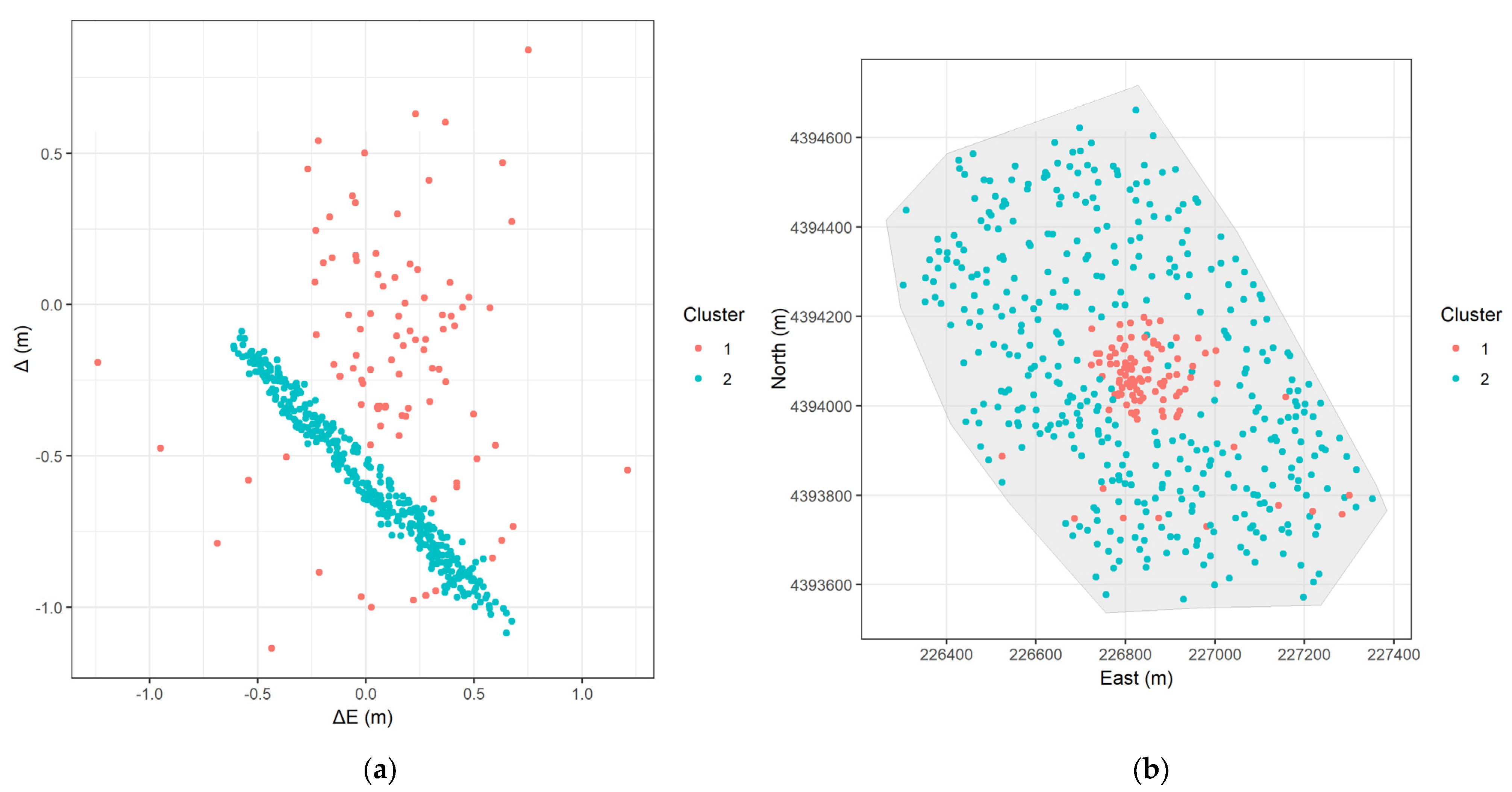
- GMM (Figure 14a): Like DBSCAN, identifies the linear cluster (blue points). However, it assigns all the other points to a separate cluster, so there are no assigned noise points.
- FCM (Figure 12b): The spatial distribution reveals that the clusters are not strictly distinct. The red, blue, and green points are mixed in the center of the study area and form three bands parallel to the x-axis.
- DBSCAN (Figure 13b): The blue points (the linear cluster) form a distinct, spatially contiguous region covering most of the study area, matching the area where we observed the ring-like, counter-clockwise rotational error pattern in Figure 3. The red noise points are concentrated in the central area.
- GMM (Figure 14b): The spatial distribution is very similar to DBSCAN, with the blue points forming a contiguous region corresponding to the rotational error. Most of the ‘noise’ points from DBSCAN now form the red cluster, making the distinction of signal to noise less clear.
3.3.2. Kefalari
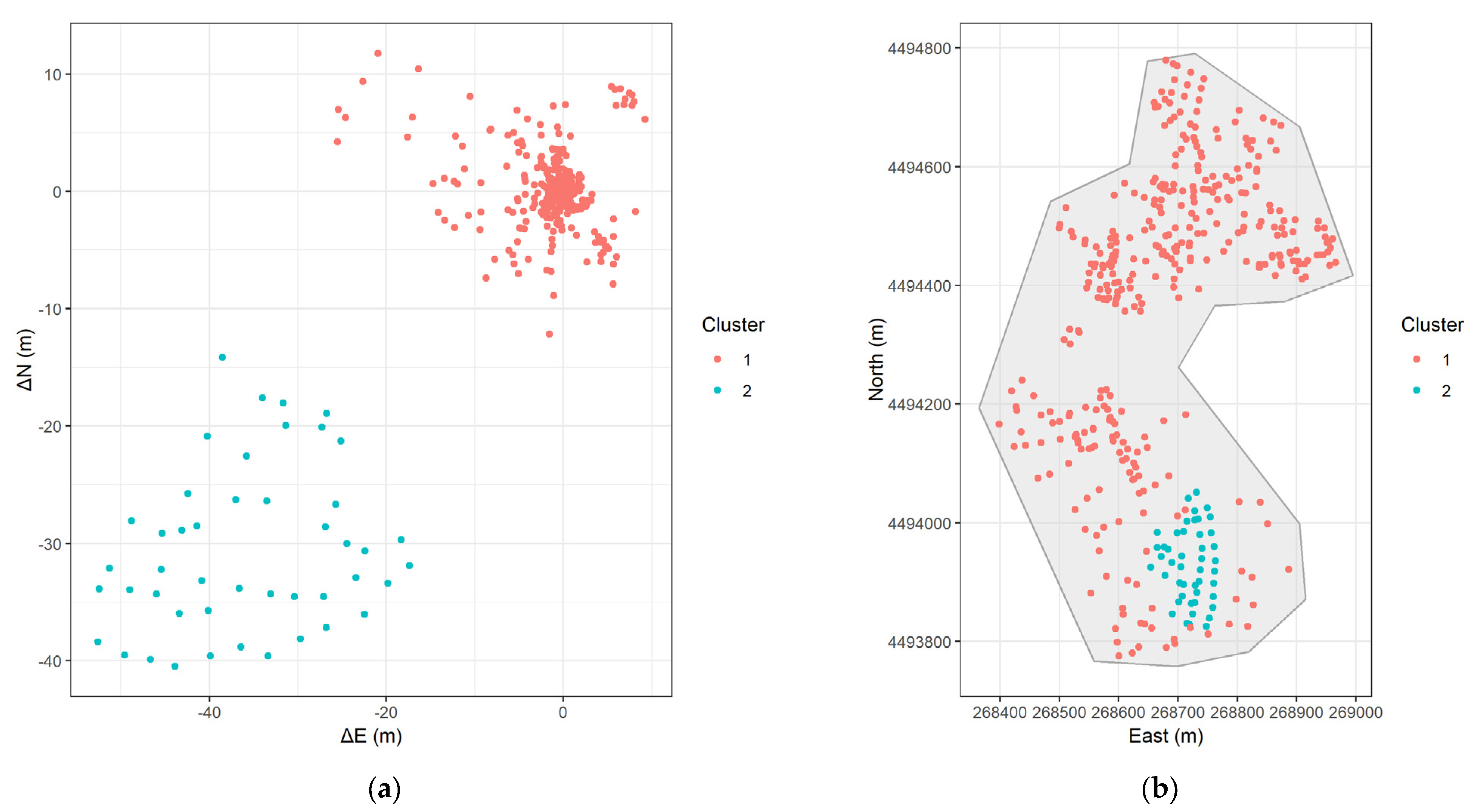
- FCM (Figure 15): Two relatively well-separated clusters are formed both in the error and the actual space. Cluster 2 (blue) exhibits large negative values, and these points are the ones already identified in the southern region of the study area.
- DBSCAN (Figure 16): The data form three clusters and a set of noise points. The noise points are characterized by very large error magnitudes in the error space. The main dense cluster (cluster 1, green) is located near the origin in the error space and corresponds to points widespread across the central study area. Two smaller distinct clusters were also identified: cluster 2 (blue) and 3 (purple), located in the mid-western area spatially.
- GMM (Figure 17): Cluster 3 (blue) is exactly the same as cluster 2 from FCM. The GMM further divided the points with smaller errors into two groups: cluster 1 (red), representing a tight core with the smallest error magnitudes near the origin in the error space and located centrally in the study area spatially (like cluster 1 of DBSCAN); and cluster 2 (green), which approximately surrounds cluster 1 both in the error and the actual space.
3.4. Silhouette Scores
3.4.1. Stavraki
3.4.2. Kefalari
3.5. Cluster Characteristics
3.5.1. Stavraki
3.5.2. Kefalari
4. Discussion
- In the first study area, the analysis uncovered a dominant, systematic counter-clockwise rotational error pattern affecting a large, ring-shaped portion of the area, surrounding a central zone with smaller, more random errors. This pattern strongly suggests that a transformation error was introduced during the integration of the precise 2001 Implementing Act data into the GNC geodatabase in 2005, as suspected by local surveyors. Both DBSCAN and the GMM effectively captured this structure. DBSCAN excelled by explicitly isolating the central, less systematic errors as ‘noise,’ providing a clear distinction between the main systematic issue and other variations. In the contrary, FCM failed to capture these error patterns.
- In the second study area, the errors were characterized by significant magnitudes and strong spatial localization. The analysis confirmed the presence of the distinct sub-area in the south with a very large displacement, contrasting with other areas with relatively smaller errors. This points to gross errors that occurred during the georeferencing and digitization of the historical 1978 Land Distribution diagram into the GCN, affecting specific parts of the study area differently. In this area, the GMM excelled, providing the finest result, partitioning the data into three meaningful clusters: the large systematic error zone, a central area with minimal errors, and an intermediate surrounding zone. DBSCAN identified the largest errors as noise; however, possibly due to significant differences in data densities, it did not perform as well as the GMM. FCM provided a coarser, though somewhat useful, separation in the actual and error space between the very large displacement area and the rest.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| BIC | Bayesian Information Criterion |
| CV | Coefficient of Variation |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| EM | Expectation Maximization |
| FCM | Fuzzy c-means |
| FFPLA | Fit-For-Purpose Land Administration |
| FIG | International Federation of Surveyors |
| GCN | Greek National Cadastre |
| GMM | Gaussian Mixture Model |
| HGRS87 | Hellenic Geodetic Reference System 1987 |
| kNN | k-Nearest Neighbor |
| LAS | Land Administration Systems |
| Probability Density Function | |
| RMSE | Root Mean Squared Error |
| SD | Standard Deviation |
| TKMP | Turkish Land Registry and Cadastre Modernization Project |
| TM | Transverse Mercator |
| WSS | Within-cluster Sum of Squares |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Model | Distribution | Volume | Shape | Orientation |
|---|---|---|---|---|---|
| EII | Spherical | Equal | Equal | - | |
| VII | Spherical | Variable | Equal | - | |
| EEI | Diagonal | Equal | Equal | Coordinate axes | |
| VEI | Diagonal | Variable | Equal | Coordinate axes | |
| EVI | Diagonal | Equal | Variable | Coordinate axes | |
| VVI | Diagonal | Variable | Variable | Coordinate axes | |
| EEE | Ellipsoidal | Equal | Equal | Equal | |
| VEE | Ellipsoidal | Variable | Equal | Equal | |
| EVE | Ellipsoidal | Equal | Variable | Equal | |
| VVE | Ellipsoidal | Variable | Variable | Equal | |
| EEV | Ellipsoidal | Equal | Equal | Variable | |
| VEV | Ellipsoidal | Variable | Equal | Variable | |
| EVV | Ellipsoidal | Equal | Variable | Variable | |
| VVV | Ellipsoidal | Variable | Variable | Variable |
References
- Movahhed Moghaddam, S.; Azadi, H.; Sklenička, P.; Janečková, K. Impacts of Land Tenure Security on the Conversion of Agricultural Land to Urban Use. Land Degrad. Dev. 2025. [Google Scholar] [CrossRef]
- Bydłosz, J. The Application of the Land Administration Domain Model in Building a Country Profile for the Polish Cadastre. Land Use Policy 2015, 49, 598–605. [Google Scholar] [CrossRef]
- Uşak, B.; Çağdaş, V.; Kara, A. Current Cadastral Trends—A Literature Review of the Last Decade. Land 2024, 13, 2100. [Google Scholar] [CrossRef]
- Aguzarova, L.A.; Aguzarova, F.S. On the Issue of Cadastral Value and Its Impact on Property Taxation in the Russian Federation. In Business 4.0 as a Subject of the Digital Economy; Popkova, E.G., Ed.; Advances in Science, Technology & Innovation; Springer International Publishing: Cham, Switzerland, 2022; pp. 595–599. ISBN 978-3-030-90323-7. [Google Scholar]
- El Ayachi, M.; Semlali, E.H. Digital Cadastral Map, a Multipurpose Tool for Sustainable Development. In Proceedings of the International Conference on Spatial Information for Sustainable Development, Nairobi, Kenya, 2–5 October 2001; pp. 2–5. [Google Scholar]
- Jahani Chehrehbargh, F.; Rajabifard, A.; Atazadeh, B.; Steudler, D. Current Challenges and Strategic Directions for Land Administration System Modernisation in Indonesia. J. Spat. Sci. 2024, 69, 1097–1129. [Google Scholar] [CrossRef]
- Hashim, N.M.; Omar, A.H.; Ramli, S.N.M.; Omar, K.M.; Din, N. Cadastral Database Positional Accuracy Improvement. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 91–96. [Google Scholar] [CrossRef]
- Ercan, O. Evolution of the Cadastre Renewal Understanding in Türkiye: A Fit-for-Purpose Renewal Model Proposal. Land Use Policy 2023, 131, 106755. [Google Scholar] [CrossRef]
- Kysel’, P.; Hudecová, L. Testing of a New Way of Cadastral Maps Renewal in Slovakia. Géod. Vestn. 2022, 66, 521–535. [Google Scholar]
- Lauhkonen, H. Cadastral Renewal in Finland-The Challenges of Implementing LIS. GIM Int. 2007, 21, 42. [Google Scholar]
- Cetl, V.; Roic, M.; Ivic, S.M. Towards a Real Property Cadastre in Croatia. Surv. Rev. 2012, 44, 17–22. [Google Scholar] [CrossRef]
- Roić, M.; Križanović, J.; Pivac, D. An Approach to Resolve Inconsistencies of Data in the Cadastre. Land 2021, 10, 70. [Google Scholar] [CrossRef]
- Thompson, R.J. A Model for the Creation and Progressive Improvement of a Digital Cadastral Data Base. Land Use Policy 2015, 49, 565–576. [Google Scholar] [CrossRef]
- Bennett, R.M.; Unger, E.-M.; Lemmen, C.; Dijkstra, P. Land Administration Maintenance: A Review of the Persistent Problem and Emerging Fit-for-Purpose Solutions. Land 2021, 10, 509. [Google Scholar] [CrossRef]
- Morgenstern, D.; Prell, K.M.; Riemer, H.G. Digitisation and Geometrical Improvement of Inhomogeneous Cadastral Maps. Surv. Rev. 1989, 30, 149–159. [Google Scholar] [CrossRef]
- Tamim, N.S. A Methodology to Create a Digital Cadastral Overlay Through Upgrading Digitized Cadastral Data; The Ohio State University: Columbus, OH, USA, 1992. [Google Scholar]
- Tuno, N.; Mulahusić, A.; Kogoj, D. Improving the Positional Accuracy of Digital Cadastral Maps through Optimal Geometric Transformation. J. Surv. Eng. 2017, 143, 05017002. [Google Scholar] [CrossRef]
- Čeh, M.; Gielsdorf, F.; Trobec, B.; Krivic, M.; Lisec, A. Improving the Positional Accuracy of Traditional Cadastral Index Maps with Membrane Adjustment in Slovenia. ISPRS Int. J. Geo-Inf. 2019, 8, 338. [Google Scholar] [CrossRef]
- Franken, J.; Florijn, W.; Hoekstra, M.; Hagemans, E. Rebuilding the Cadastral Map of The Netherlands, the Artificial Intelligence Solution. In Proceedings of the FIG Working Week, Amsterdam, The Netherlands, 10–14 May 2020. [Google Scholar]
- Petitpierre, R.; Guhennec, P. Effective Annotation for the Automatic Vectorization of Cadastral Maps. Digit. Scholarsh. Humanit. 2023, 38, 1227–1237. [Google Scholar] [CrossRef]
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2001; ISBN 978-1-4899-0519-2. [Google Scholar]
- Tyagi, A.K.; Chahal, P. Artificial Intelligence and Machine Learning Algorithms. In Challenges and Applications for Implementing Machine Learning in Computer Vision; IGI Global Scientific Publishing: Hershey, PA, USA, 2020; pp. 188–219. [Google Scholar]
- Hartigan, J.A. Clustering Algorithms; John Wiley & Sons Inc.: New York, NY, USA, 1975; ISBN 978-0-471-35645-5. [Google Scholar]
- Jain, A.K.; Duin, R.P.W.; Mao, J. Statistical Pattern Recognition: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 4–37. [Google Scholar] [CrossRef]
- Oyewole, G.J.; Thopil, G.A. Data Clustering: Application and Trends. Artif. Intell. Rev. 2023, 56, 6439–6475. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Tong, H. Data Mining: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2022. [Google Scholar]
- Grubesic, T.H.; Wei, R.; Murray, A.T. Spatial Clustering Overview and Comparison: Accuracy, Sensitivity, and Computational Expense. Ann. Assoc. Am. Geogr. 2014, 104, 1134–1156. [Google Scholar] [CrossRef]
- Wang, H.; Song, C.; Wang, J.; Gao, P. A Raster-Based Spatial Clustering Method with Robustness to Spatial Outliers. Sci. Rep. 2024, 14, 4103. [Google Scholar] [CrossRef]
- Xie, Y.; Shekhar, S.; Li, Y. Statistically-Robust Clustering Techniques for Mapping Spatial Hotspots: A Survey. ACM Comput. Surv. 2023, 55, 3487893. [Google Scholar] [CrossRef]
- Vantas, K.; Sidiropoulos, E.; Loukas, A. Robustness Spatiotemporal Clustering and Trend Detection of Rainfall Erosivity Density in Greece. Water 2019, 11, 1050. [Google Scholar] [CrossRef]
- Milligan, G.W.; Cooper, M.C. An Examination of Procedures for Determining the Number of Clusters in a Data Set. Psychometrika 1985, 50, 159–179. [Google Scholar] [CrossRef]
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef]
- Vantas, K.; Sidiropoulos, E. Intra-Storm Pattern Recognition through Fuzzy Clustering. Hydrology 2021, 8, 57. [Google Scholar] [CrossRef]
- Potsiou, C.; Volakakis, M.; Doublidis, P. Hellenic Cadastre: State of the Art Experience, Proposals and Future Strategies. Comput. Environ. Urban Syst. 2001, 25, 445–476. [Google Scholar] [CrossRef]
- Hellenic Republic. Law 2308: Cadastral Survey for the Creation of a National Cadastre. Procedure Up to the First Entries in the Cadastral Books and Other Provisions; Hellenic Republic: Athens, Greece, 1995; p. 8. [Google Scholar]
- Hellenic Republic. Law 2664: National Cadastre and Other Provisions; Hellenic Republic: Athens, Greece, 1998; p. 20. [Google Scholar]
- Arvanitis, A. Cadastre 2020; Editions Ziti: Thessaloniki, Greece, 2014; ISBN 978-960-456-423-1. [Google Scholar]
- Vantas, K. Improving the Positional Accuracy of Cadastral Maps via Machine Learning Methods; Aristotle University of Thessaloniki: Thessaloniki, Greece, 2022. [Google Scholar]
- Cadastre: The First Public Agency to Integrate Artificial Intelligence. Available online: https://www.ktimatologio.gr/grafeio-tipou/deltia-tipou/1493 (accessed on 10 March 2025). (In Greek).
- Hellenic Republic. Law 1337: Expansion of Urban Plans, Residential Development and Related Regulations; Hellenic Republic: Athens, Greece, 1983; p. 16. [Google Scholar]
- Greek National Cadastre—Open Data Portal. Available online: https://data.ktimatologio.gr/ (accessed on 11 March 2025).
- Veis, G. Reference Systems and the Realization of the Hellenic Geodetic Reference System 1987. In Technika Chronika; Technical Chamber of Greece: Athens, Greece, 1995; pp. 16–22. [Google Scholar]
- Fotiou, A.; Livieratos, E. Geometric Geodesy and Networks; Editions Ziti: Thessaloniki, Greece, 2000; ISBN 960-431-612-5. [Google Scholar]
- QGIS Geographic Information System, Version 3.42; QGIS Development Team, 2025.
- Hellenic Mapping and Cadastral Organization. Tables of Coefficients for Coordinates Transformation of the Hellenic Area; HEMCO: Athens, Greece, 1995. [Google Scholar]
- R: A Language and Environment for Statistical Computing; Version 4.4.2; Foundation for Statistical Computing: Vienna, Austria, 2025.
- Maechler, M.; Rousseeuw, P.; Struyf, A.S.; Hubert, M.; Hornik, K.; Studer, M.; Roudier, P.; Gonzalez, J.; Kozlowski, K.; Schubert, E.; et al. Cluster: “Finding Groups in Data”, Version 2.1.8. 2024.
- Hahsler, M.; Piekenbrock, M.; Arya, S.; Mount, D.; Malzer, C. Dbscan: Density-Based Spatial Clustering of Applications with Noise (DBSCAN) and Related Algorithms, Version 1.2.2. 2025.
- Mclust: Gaussian Mixture Modelling for Model-Based Clustering, Classification, and Density Estimation, Version 6.1.1. 2024.
- Fraley, C.; Raftery, A.E.; Scrucca, L.; Murphy, T.B.; Fop, M. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses; Version 1.0.7; Kassambara, A., Mundt, F., Eds.; 2020. [Google Scholar]
- Wickham, H.; Chang, W.; Henry, L.; Pedersen, T.L.; Takahashi, K.; Wilke, C.; Woo, K.; Yutani, H.; Dunnington, D.; van den Brand, T.; et al. Ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics; Version 3.5.1; 2024. [Google Scholar]
- Pebesma, E.; Bivand, R.; Racine, E.; Sumner, M.; Cook, I.; Keitt, T.; Lovelace, R.; Wickham, H.; Ooms, J.; Müller, K.; et al. Sf: Simple Features for R, Version 1.0-20. 2024.
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Sarle, W.S. Finding Groups in Data: An Introduction to Cluster Analysis. J. Am. Stat. Assoc. 1991, 86, 830. [Google Scholar] [CrossRef]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Nayak, J.; Naik, B.; Behera, H.S. Fuzzy C-Means (FCM) Clustering Algorithm: A Decade Review from 2000 to 2014. In Proceedings of the Computational Intelligence in Data Mining—Volume 2, Proceedings of the International Conference on CIDM, 20–21 December 2014; Jain, L.C., Behera, H.S., Mandal, J.K., Mohapatra, D.P., Eds.; Springer: New Delhi, India, 2015; pp. 133–149. [Google Scholar]
- Huang, M.; Xia, Z.; Wang, H.; Zeng, Q.; Wang, Q. The Range of the Value for the Fuzzifier of the Fuzzy C-Means Algorithm. Pattern Recognit. Lett. 2012, 33, 2280–2284. [Google Scholar] [CrossRef]
- Bezdek, J.C. Objective Function Clustering. In Pattern Recognition with Fuzzy Objective Function Algorithms; Springer: Boston, MA, USA, 1981; pp. 43–93. ISBN 978-1-4757-0452-5. [Google Scholar]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method for Identification of the Best Customer Profile Cluster. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Novi Sad, Serbia, 6–8 June 2018; IOP Publishing: Bristol, UK, 2018; Volume 336, p. 012017. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. Density-Based Spatial Clustering of Applications with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; Volume 240. [Google Scholar]
- Kriegel, H.; Kröger, P.; Sander, J.; Zimek, A. Density-based Clustering. WIREs Data Min. Knowl. 2011, 1, 231–240. [Google Scholar] [CrossRef]
- Hahsler, M.; Piekenbrock, M.; Doran, D. Dbscan: Fast Density-Based Clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian Mixture Models. Encycl. Biom. 2009, 741, 3. [Google Scholar]
- Scrucca, L.; Fraley, C.; Murphy, T.B.; Raftery, A.E. Model-Based Clustering, Classification, and Density Estimation Using Mclust in R; Chapman and Hall/CRC: Boca Raton, FL, USA, 2023; ISBN 978-1-032-23495-3. [Google Scholar]
- Scrucca, L.; Fop, M.; Murphy, T.B.; Raftery, A.E. Mclust 5: Clustering, Classification and Density Estimation Using Gaussian Finite Mixture Models. R J. 2016, 8, 289. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E. Model-Based Clustering, Discriminant Analysis, and Density Estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- Yang, M.-S.; Lai, C.-Y.; Lin, C.-Y. A Robust EM Clustering Algorithm for Gaussian Mixture Models. Pattern Recognit. 2012, 45, 3950–3961. [Google Scholar] [CrossRef]
- Gupta, M.R.; Chen, Y. Theory and Use of the EM Algorithm. Found. Trends® Signal Process. 2011, 4, 223–296. [Google Scholar] [CrossRef]
- Shahapure, K.R.; Nicholas, C. Cluster Quality Analysis Using Silhouette Score. In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, NSW, Australia, 6–9 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 747–748. [Google Scholar]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An Extensive Comparative Study of Cluster Validity Indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Hellenic Republic. Approval of Technical Specifications and the Regulation of Estimated Fees for Cadastral Survey Studies for the Creation of the National Cadastre in the Remaining Areas of the Country; Ministry of Environment and Energy: Athens, Greece, 2016; p. 228.
- Sisman, Y. Coordinate Transformation of Cadastral Maps Using Different Adjustment Methods. J. Chin. Inst. Eng. 2014, 37, 869–882. [Google Scholar] [CrossRef]
- Tong, X.; Liang, D.; Xu, G.; Zhang, S. Positional Accuracy Improvement: A Comparative Study in Shanghai, China. Int. J. Geogr. Inf. Sci. 2011, 25, 1147–1171. [Google Scholar] [CrossRef]
- Manzano-Agugliaro, F.; Montoya, F.G.; San-Antonio-Gómez, C.; López-Márquez, S.; Aguilera, M.J.; Gil, C. The Assessment of Evolutionary Algorithms for Analyzing the Positional Accuracy and Uncertainty of Maps. Expert Syst. Appl. 2014, 41, 6346–6360. [Google Scholar] [CrossRef]
- Watson, G.A. Computing Helmert Transformations. J. Comput. Appl. Math. 2006, 197, 387–394. [Google Scholar] [CrossRef]



| Metric | Min | Mean | Median | Max | SD | Skew | Kurtosis | CV |
|---|---|---|---|---|---|---|---|---|
| −0.95 | 0.03 | 0.05 | 1.21 | 0.33 | −0.06 | −0.65 | 10.67 | |
| −1.13 | −0.50 | −0.53 | 0.84 | 0.33 | 0.75 | 0.76 | 0.66 | |
| L | 0.04 | 0.63 | 0.59 | 1.33 | 0.25 | 0.28 | −0.47 | 0.39 |
| Metric | Min | Mean | Median | Max | SD | Skew | Kurtosis | CV |
|---|---|---|---|---|---|---|---|---|
| −52.61 | −5.26 | −0.88 | 10.07 | 12.27 | −2.22 | 4.20 | 2.33 | |
| −40.49 | −3.27 | −0.15 | 11.77 | 10.55 | −2.23 | 4.08 | 3.23 | |
| L | 0.18 | 8.82 | 2.44 | 65.14 | 14.91 | 2.30 | 4.12 | 1.69 |
| Algorithm | Mean Silhouette Score |
|---|---|
| FCM | 0.43 |
| DBSCAN | 0.32 |
| GMM | 0.25 |
| Algorithm | Mean Silhouette Score |
|---|---|
| FCM | 0.85 |
| DBSCAN | 0.58 |
| GMM | 0.44 |
| Algorithm | Cluster | Number of Points | Mean ΔE (m) | Mean ΔN (m) | SD ΔE (m) | SD ΔN (m) | Mean Length (m) |
|---|---|---|---|---|---|---|---|
| FCM | 1 | 178 | −0.336 | −0.224 | 0.184 | 0.215 | 0.471 |
| 2 | 158 | 0.385 | −0.831 | 0.139 | 0.11 | 0.923 | |
| 3 | 164 | 0.068 | −0.462 | 0.169 | 0.262 | 0.537 | |
| DBSCAN | 0 (noise) | 102 | 0.088 | −0.172 | 0.366 | 0.387 | 0.47 |
| 1 | 398 | 0.008 | −0.576 | 0.332 | 0.246 | 0.678 | |
| GMM | 1 | 103 | 0.077 | −0.166 | 0.352 | 0.37 | 0.458 |
| 2 | 397 | 0.01 | −0.579 | 0.336 | 0.249 | 0.682 |
| Algorithm | Cluster | Number of Points | Mean ΔE (m) | Mean ΔN (m) | SD ΔE (m) | SD ΔN (m) | Mean Length (m) |
|---|---|---|---|---|---|---|---|
| FCM | 1 | 354 | −1.35 | 0.215 | 4.66 | 3.12 | 3.74 |
| 2 | 46 | −35.6 | −30.6 | 9.83 | 6.93 | 47.5 | |
| DBSCAN | 0 (noise) | 76 | −26.4 | −17.8 | 14.6 | 17.2 | 34.5 |
| 1 | 296 | −0.91 | 0.06 | 1.83 | 2.09 | 2.23 | |
| 2 | 17 | 4.67 | −4.88 | 0.918 | 1.28 | 6.83 | |
| 3 | 11 | 7.08 | 7.88 | 1.11 | 0.827 | 10.7 | |
| GMM | 1 | 237 | −0.43 | 0.037 | 1.08 | 1.18 | 1.44 |
| 2 | 117 | −3.21 | 0.575 | 7.64 | 5.16 | 8.4 | |
| 3 | 46 | −35.6 | −30.6 | 9.83 | 6.93 | 47.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vantas, K.; Mirkopoulou, V. Towards Automated Cadastral Map Improvement: A Clustering Approach for Error Pattern Recognition. Geomatics 2025, 5, 16. https://doi.org/10.3390/geomatics5020016
Vantas K, Mirkopoulou V. Towards Automated Cadastral Map Improvement: A Clustering Approach for Error Pattern Recognition. Geomatics. 2025; 5(2):16. https://doi.org/10.3390/geomatics5020016
Chicago/Turabian StyleVantas, Konstantinos, and Vasiliki Mirkopoulou. 2025. "Towards Automated Cadastral Map Improvement: A Clustering Approach for Error Pattern Recognition" Geomatics 5, no. 2: 16. https://doi.org/10.3390/geomatics5020016
APA StyleVantas, K., & Mirkopoulou, V. (2025). Towards Automated Cadastral Map Improvement: A Clustering Approach for Error Pattern Recognition. Geomatics, 5(2), 16. https://doi.org/10.3390/geomatics5020016