
Real-Time Optimization of Social Distancing to Mitigate COVID-19 Pandemic Using Quantized Extremum Seeking



Abstract
:1. Introduction
2. COVID-19 Outbreak Modeling
2.1. SIR Modeling
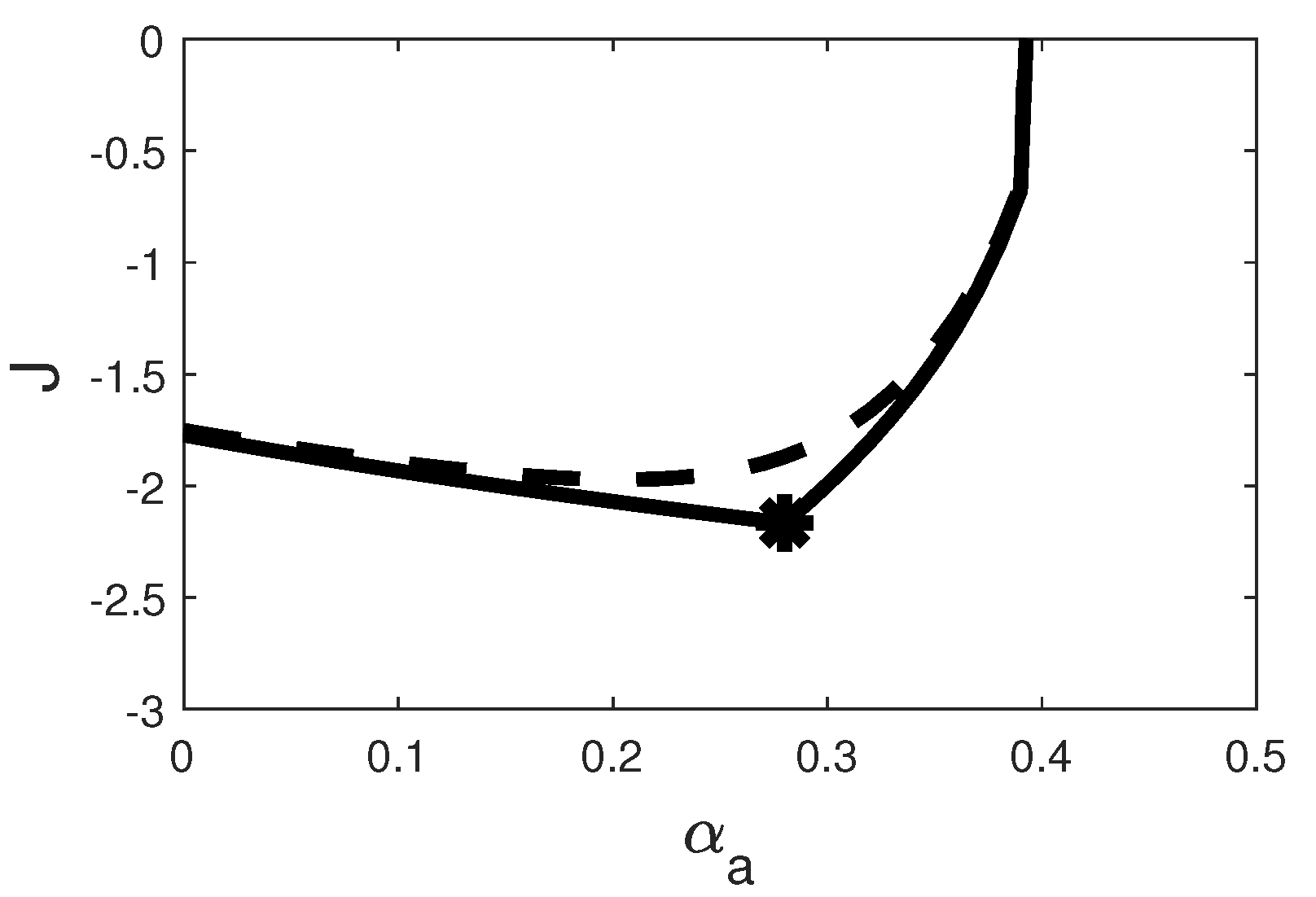
2.2. Bifurcation Analysis
2.3. Constrained Objective
3. Social Distancing Real-Time Optimization
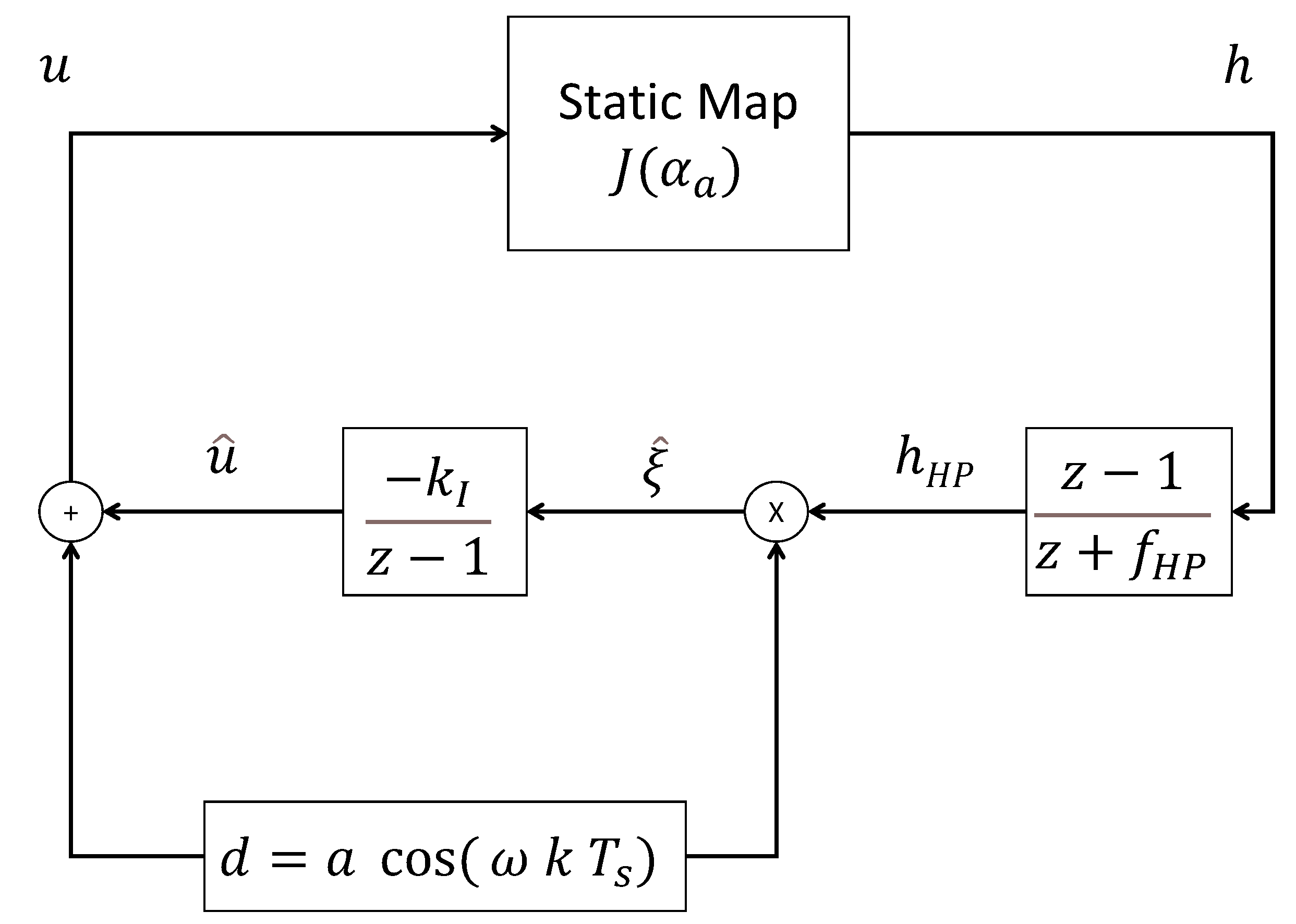
3.1. Classical Discrete-Time Extremum Seeking
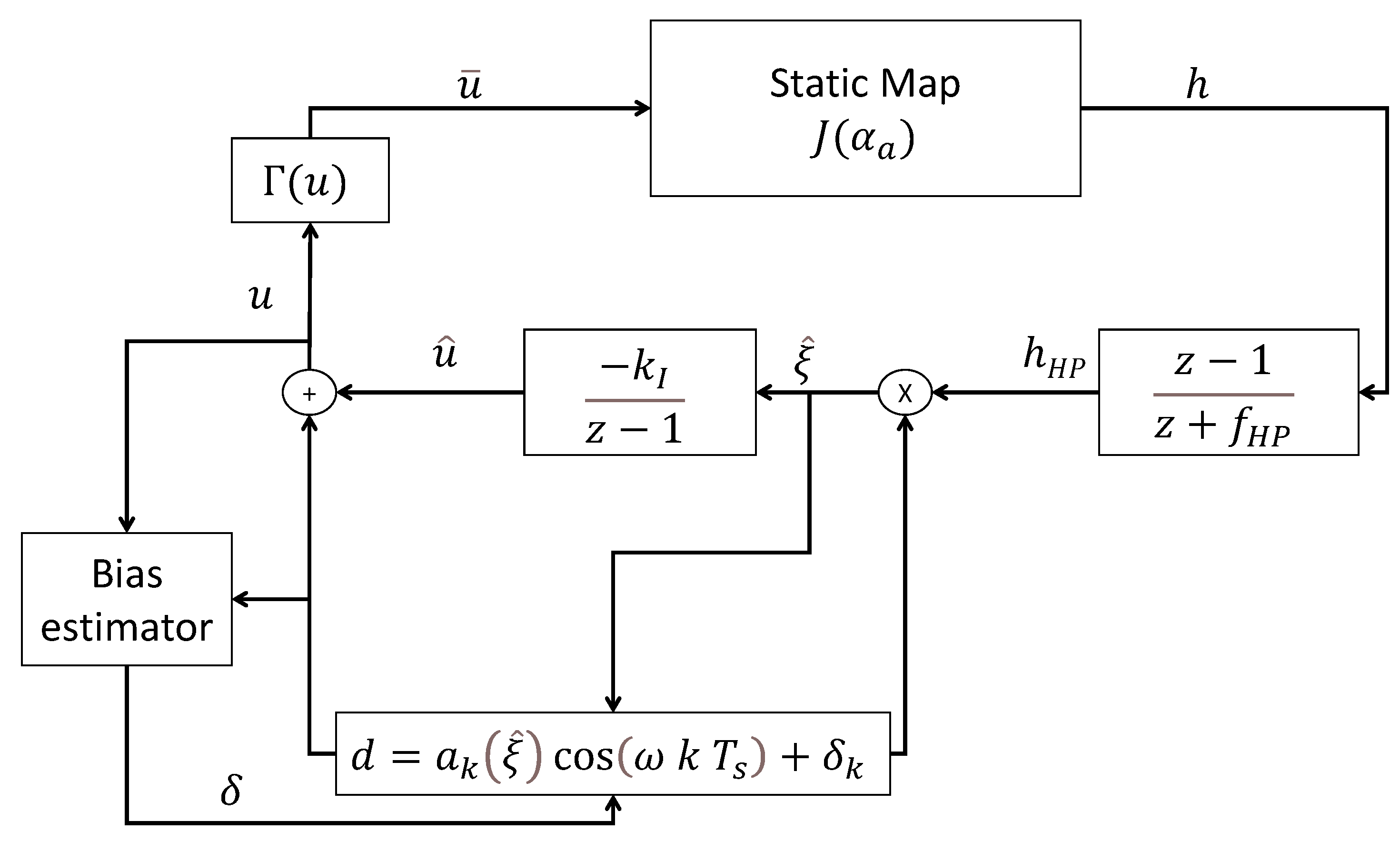
3.2. Discrete-Time Quantized Extremum Seeking
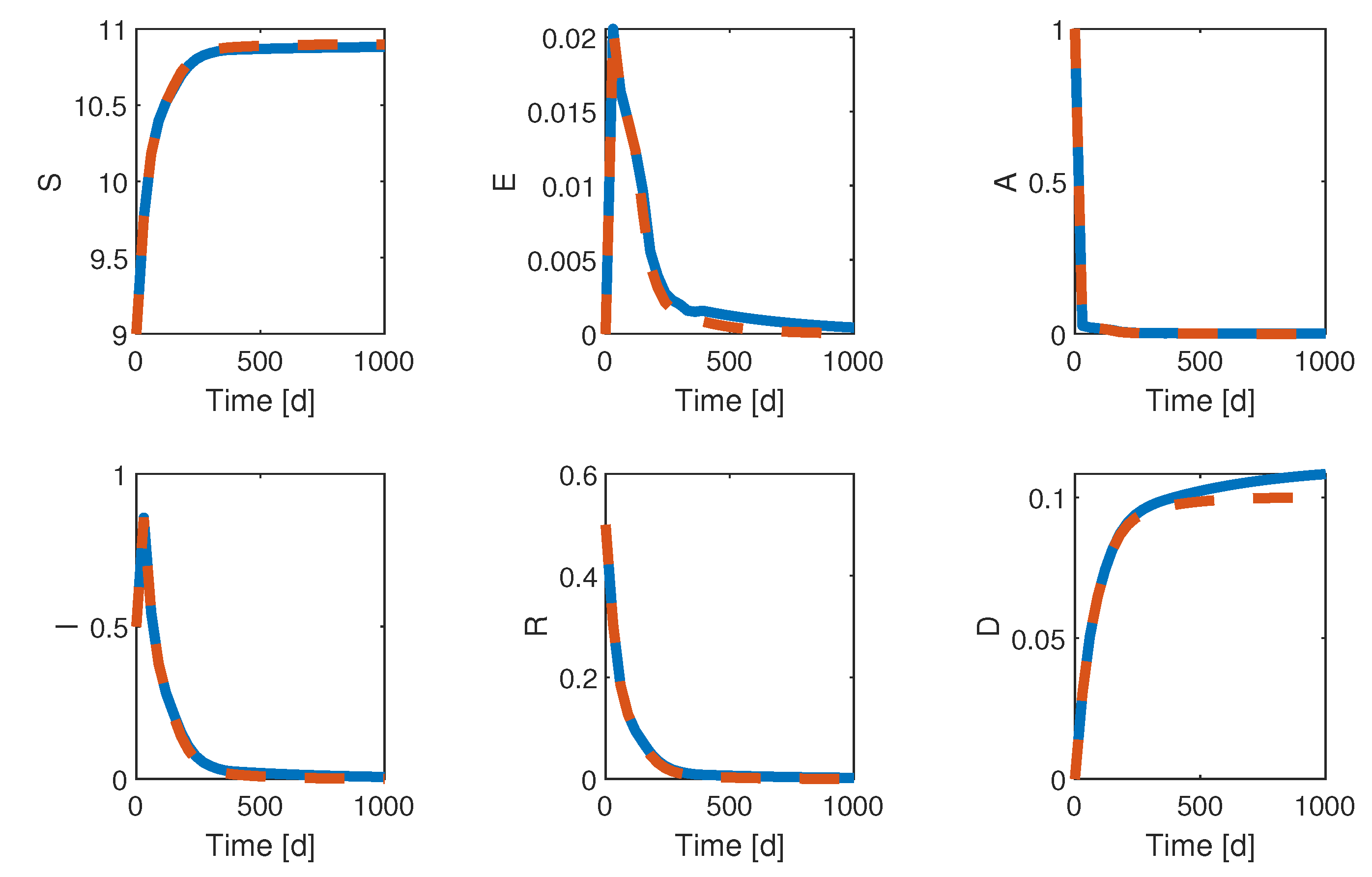
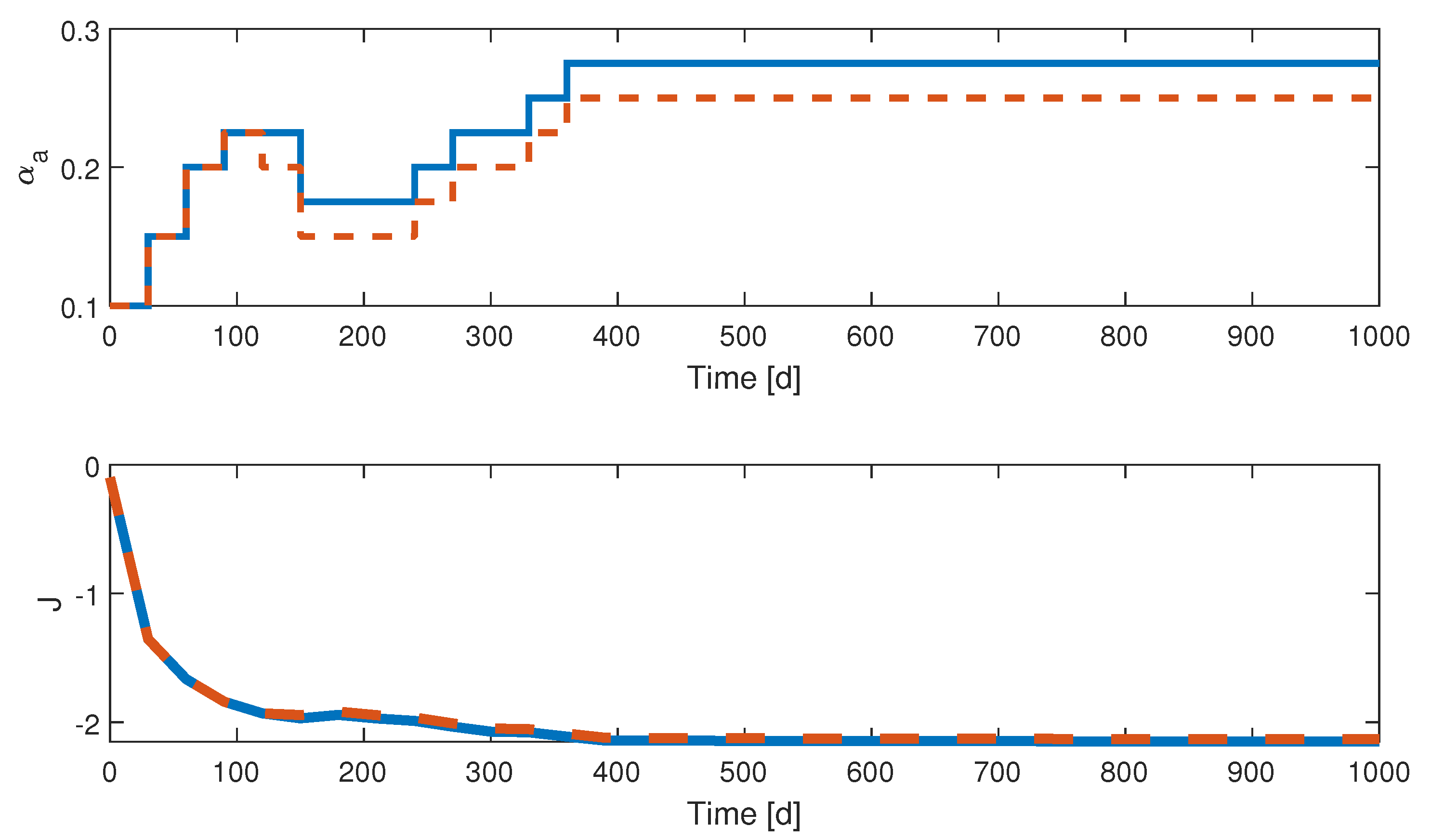
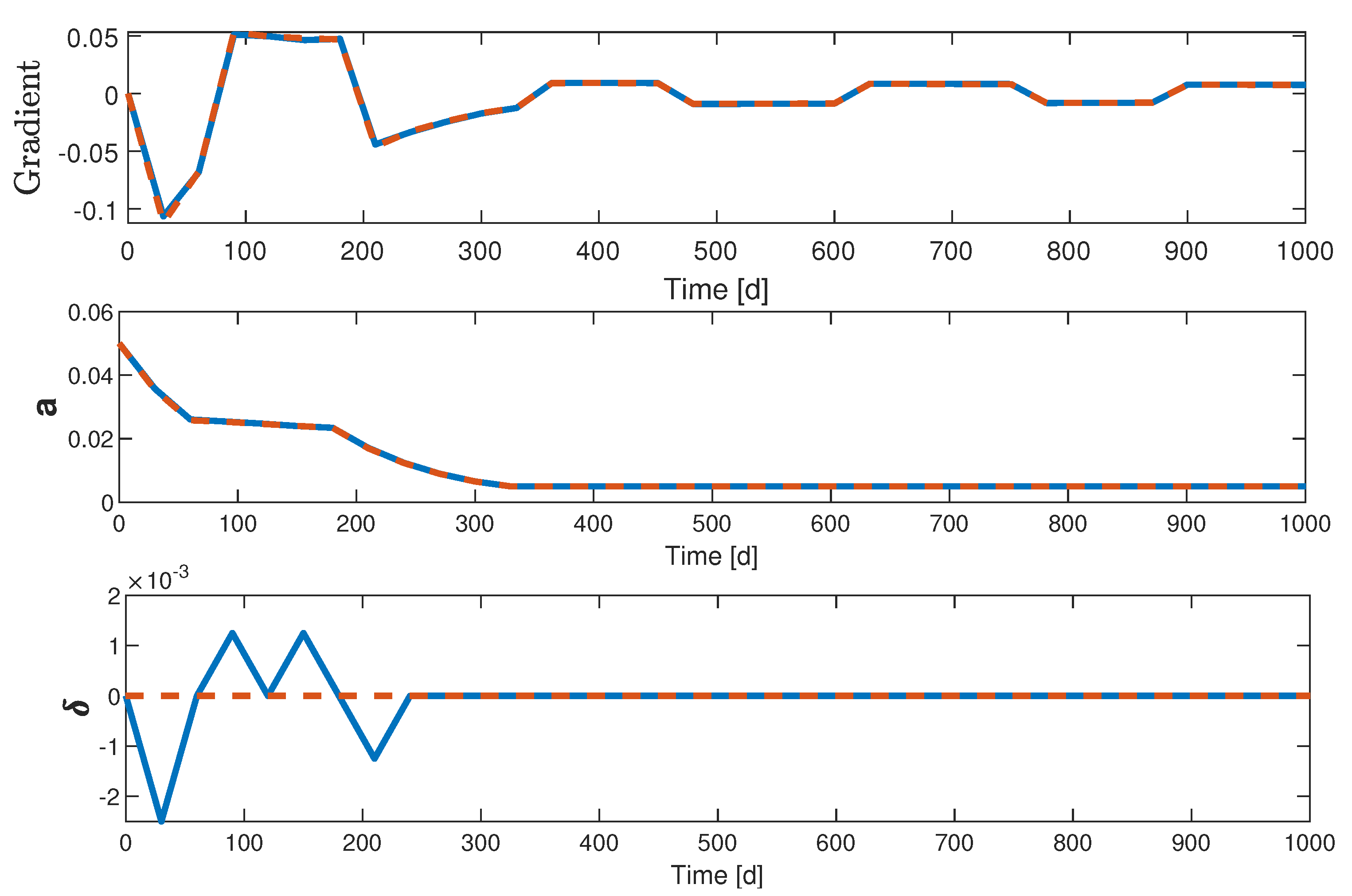
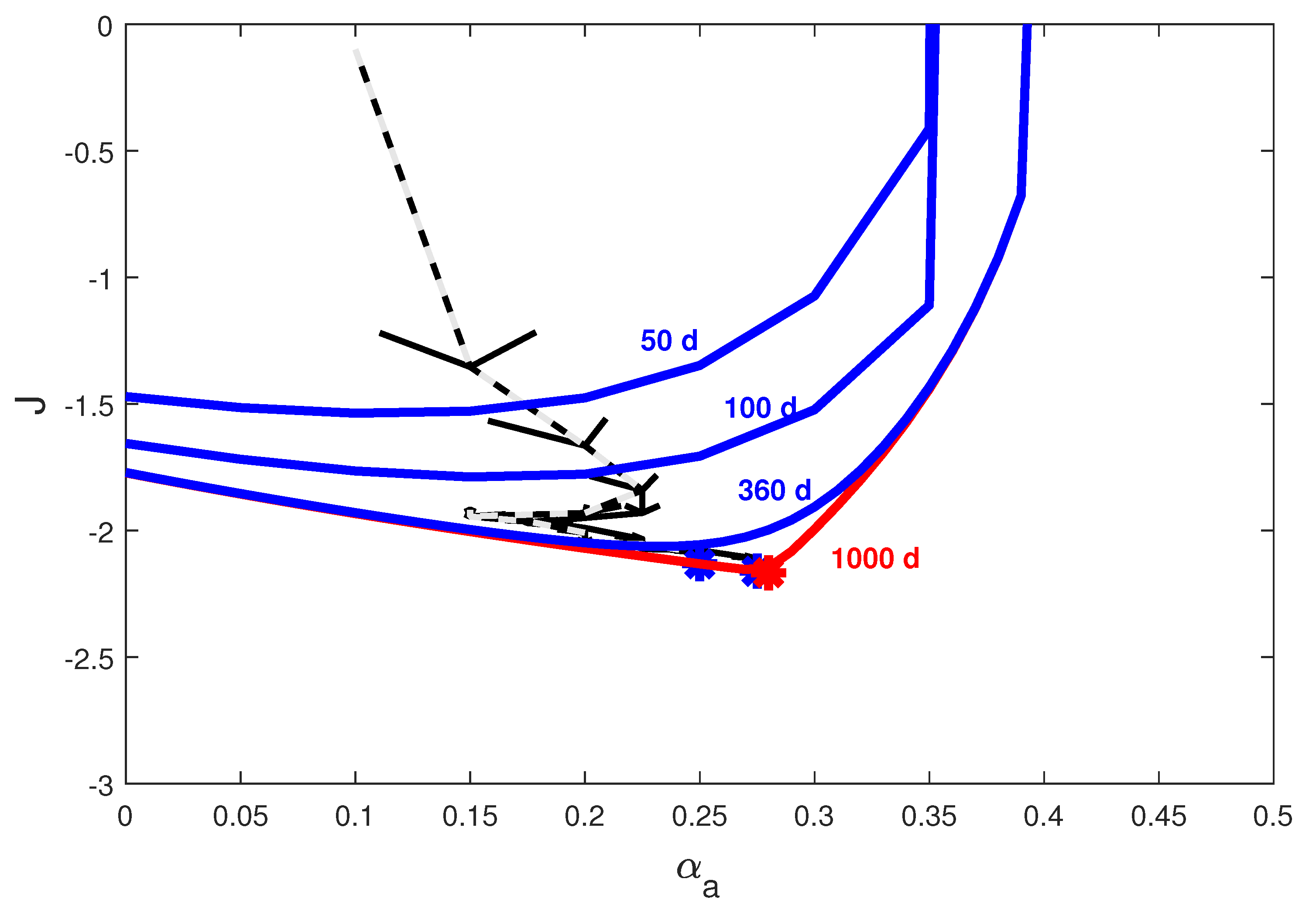
4. Quantized ESC Application to the SEAIR Model
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- McBryde, E.S.; Meehan, M.T.; Adegboye, O.A.; Adekunle, A.I.; Caldwell, J.M.; Pak, A.; Rojas, D.P.; Williams, B.; Trauer, J.M. Role of modelling in COVID-19 policy development. Paediatr. Respir. Rev. 2020, 35, 57–60. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G. A contribution to the mathematical theory of epidemics. Proc. R. Soc. Lond. A 1927, 115, 700–721. [Google Scholar]
- Tsay, C.; Lejarza, F.; Stadherr, M.; Baldea, M. Modeling, state estimation, and optimal control for the US COVID-19 outbreak. Sci. Rep. 2020, 10, 10711. [Google Scholar] [CrossRef] [PubMed]
- Köhler, J.; Schwenkel, L.; Koch, A.; Berberich, J.; Pauli, P.; Allgöwer, F. Robust and optimal predictive control of the COVID-19 outbreak. Annu. Rev. Control 2020, 51, 525–539. [Google Scholar] [CrossRef] [PubMed]
- Péni, T.; Csutak, B.; Szederkényl, G.; Röst, G. Nonlinear model predictive control with logic constraints for COVID-19 management. Nonlinear Dyn. 2020, 102, 1965–1986. [Google Scholar] [CrossRef] [PubMed]
- Shirin, A.; Lin, Y.; Sorrentino, F. Data-driven optimized control of the COVID-19 epidemics. Sci. Rep. 2021, 11, 6525. [Google Scholar] [CrossRef]
- Ghamizi, S.; Rwemalika, R.; Cordy, M.; Veiber, L.; Bissyandé, T.F.; Papadakis, M.; Klein, J.; Le Traon, Y. Data-driven Simulation and Optimization for COVID-19 Exit Strategies. In Proceedings of the KDD’20: Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery &Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 3434–3442. [Google Scholar]
- Eker, S. Validity and usefulness of COVID-19 models. Humanit. Soc. Sci. Commun. 2020, 7, 54. [Google Scholar] [CrossRef]
- Dewasme, L.; Vande Wouwer, A. Fast transient optimization of social distancing during COVID-19 pandemics using extremum seeking. IFAC-PapersOnLine 2021, 54, 145–150. [Google Scholar] [CrossRef]
- Markovič, R.; Šterk, M.; Marhl, M.; Perc, M.; Gosak, M. Socio-demographic and health factors drive the epidemic progression and should guide vaccination strategies for best COVID-19 containment. Results Phys. 2022, 26, 104433. [Google Scholar] [CrossRef] [PubMed]
- Krueger, T.; Gogolewski, K.; Bodych, M.; Gambin, A.; Giordano, G.; Cuschieri, S.; Czypionka, T.; Perc, M.; Petelos, E.; Rosińska, M.; et al. Risk assessment of COVID-19 epidemic resurgence in relation to SARS-CoV-2 variants and vaccination passes. Commun. Med. 2022, 2, 23. [Google Scholar] [CrossRef]
- Dias, S.; Queiroz, K.; Araujo, A. Controlling epidemic diseases based only on social distancing level: General case. ISA Trans. 2022, 124, 21–30. [Google Scholar] [CrossRef] [PubMed]
- Marques Lopes Santos, D.; Hugo Pereira Rodrigues, V.; Roux Oliveira, T. Epidemiological Control of COVID-19 Through the Theory of Variable Structure and Sliding Mode Systems. J. Control Autom. Electr. Syst. 2021, 33, 63–77. [Google Scholar] [CrossRef]
- Leblanc, M. Sur l’électrification des chemins de fer au moyen de courants alternatifs de fréquence élevée. Rev. Générale L’Électricité 1922, 12, 275–277. [Google Scholar]
- Guay, M.; Zhang, T. Adaptive extremum seeking control of nonlinear dynamic systems with parametric uncertainties. Automatica 2003, 39, 1283–1293. [Google Scholar] [CrossRef]
- Ariyur, K.B.; Krstic, M. Real-Time Optimization by Extremum-Seeking Control, wiley-interscience ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003. [Google Scholar]
- Tan, Y.; Moase, W.; Manzie, C.; Nesic, D.; Mareels, I. Extremum Seeking from 1922 to 2010. In Proceedings of the 29th Chinese Control Conference, Beijing, China, 29–31 July 2010; pp. 14–26. [Google Scholar]
- Dewasme, L.; Vande Wouwer, A. Model-Free Extremum Seeking Control of Bioprocesses: A Review with a Worked Example. Processes 2020, 8, 1209. [Google Scholar] [CrossRef]
- Aström, K.J.; Wittenmark, B. Adaptive Control, 2nd ed.; Addison-Wesley Publishing Company, Inc.: Boston, MA, USA, 1995. [Google Scholar]
- Dewasme, L.; Feudjio Letchindjio, C.G.; Zuniga, I.T.; Vande Wouwer, A. Micro-algae productivity optimization using extremum-seeking control. In Proceedings of the 2017 25th Mediterranean Conference on Control and Automation (MED), Valletta, Malta, 3–6 July 2017; IEEE: Manhattan, NY, USA, 2017; pp. 672–677. [Google Scholar]
- Guay, M.; Burns, D. Extremum Seeking Control for Discrete-Time with Quantized and Saturated Actuators. Processes 2019, 7, 831. [Google Scholar] [CrossRef]
- Tan, Y.; Li, Y.; Mareels, I.M.Y. Extremum Seeking for Constrained Inputs. IEEE Trans. Autom. Control 2013, 58, 2405–2410. [Google Scholar] [CrossRef]
- Elie, R.; Hubert, E.; Turinici, G. Contact rate epidemic control of COVID-19: An equilibrium view. Math. Model. Nat. Phenom. 2020, 15, 35. [Google Scholar] [CrossRef]
- Srinivasan, B.; Biegler, L.; Bonvin, D. Tracking the necessary conditions of optimality with changing set of active constraints using a barrier-penalty function. Comput. Chem. Eng. 2008, 32, 572–579. [Google Scholar] [CrossRef]
- Trollberg, O.; Jacobsen, E. Greedy Extremum Seeking Control with Applications to Biochemical Processes. IFAC-PaperOnLine 2016, 49, 109–114. [Google Scholar] [CrossRef]
- Choi, J.; Krstić, M.; Ariyur, K.; Lee, J. Extremum Seeking Control for Discrete-Time Systems. IEEE Trans. Autom. Control 2002, 47, 318–323. [Google Scholar] [CrossRef]
- DeHaan, D.; Guay, M. Extremum-seeking control of state-constrained nonlinear systems. Automatica 2005, 41, 1567–1574. [Google Scholar] [CrossRef]
- Atta, K.; Hostettler, R.; Birk, W.; Johansson, A. Phasor Extremum Seeking Control with Adaptive Perturbation Amplitude. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 7069–7074. [Google Scholar]
- Dewasme, L.; Vande Wouwer, A.; Feudjio Letchindjio, C.; Ahmad, A.; Engell, S. Maximum-likelihood extremum seeking control of microalgae cultures. IFAC-PapersOnLine 2021, 54, 336–341. [Google Scholar] [CrossRef]
- Ghaffari, A.; Krstić, M.; Nesić, D. Multivariable Newton-based extremum seeking. J. Process Control 2012, 48, 1759–1767. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | l | |||||
|---|---|---|---|---|---|---|
| 2 | 1 | 1 | 200 |
| h | |||||||
|---|---|---|---|---|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewasme, L.; Vande Wouwer, A. Real-Time Optimization of Social Distancing to Mitigate COVID-19 Pandemic Using Quantized Extremum Seeking. COVID 2022, 2, 1077-1088. https://doi.org/10.3390/covid2080079
Dewasme L, Vande Wouwer A. Real-Time Optimization of Social Distancing to Mitigate COVID-19 Pandemic Using Quantized Extremum Seeking. COVID. 2022; 2(8):1077-1088. https://doi.org/10.3390/covid2080079
Chicago/Turabian StyleDewasme, Laurent, and Alain Vande Wouwer. 2022. "Real-Time Optimization of Social Distancing to Mitigate COVID-19 Pandemic Using Quantized Extremum Seeking" COVID 2, no. 8: 1077-1088. https://doi.org/10.3390/covid2080079