2.1. GUM Method
Measurements are always influenced by unpredictable factors, so a result can only ever approximate the quantity of interest. Influence factors can, however, be identified and described in probabilistic terms. In this manner, a measurement process can be represented by a mathematical model. This is the approach taken in the GUM.
The first step is to identify a function called the measurement model that
contains every quantity, including all corrections and correction factors that can contribute a significant component of uncertainty to the measurement result [
3] [Section 4.1.2]. In the GUM, this is expressed as an explicit function:
where
Y is the quantity intended to be measured (the
measurand) and the input arguments
are quantities that influence the measurement outcome. All arguments of
are treated in the same way when evaluating uncertainty. Some of the input terms may represent other measured quantities. For example, electrical resistance could be measured by first measuring potential difference
V and current
I and then evaluating ratio
. Other input terms may represent nuisance factors that perturb the measurement, such as Johnson noise in a resistor. The measurement model can be thought of as a recipe for evaluating the measurand: if
were all known exactly, then
Y could be determined. However, with only approximate values available for input quantities, an approximate value for
Y will be obtained.
GUM uses a specific term,
standard uncertainty, in relation to the unpredictability of measurement outcomes (i.e., the fact that
y and
Y differ by an unpredictable amount). A standard uncertainty is an estimate of the standard deviation of a probability distribution for the difference (error) between
y and
Y. There is a formula in the GUM to propagate standard uncertainties through a measurement model and obtain the standard uncertainty in a result. For a model in the form of Equation (
1), the standard uncertainty of
y, as an estimate of
Y, is calculated as follows:
where
and
are
components of uncertainty that relate small changes in input values to corresponding changes in
y.
The terms and are the standard uncertainties in the input values and , respectively. The correlation coefficient attributed to a pair of input estimates is , where when .
Standard uncertainties are associated with a number called the
degrees of freedom, usually denoted
. The interpretation given to
x,
, and
in the GUM is analogous to familiar sample statistics: the sample mean, the standard error in the sample mean, and the degrees of freedom [
8] [Chapter 9]. However, degrees of freedom are interpreted more broadly in the GUM, because uncertainty evaluation is not always based on a sample of data. When a standard uncertainty is considered to be known very accurately, the degrees of freedom is large (up to infinity), but a small number of degrees of freedom (as low as unity) signifies a very rough estimate of the underlying standard deviation. Again, the GUM provides an equation for propagating degrees of freedom, called the Welch–Satterthwaite formula. The number of degrees of freedom associated with a standard uncertainty
is as follows.
However, there is an important restriction on the use of this equation. It is not valid when input estimates that have finite degrees of freedom are correlated with each other. This is not a rare occurrence. For example, estimates obtained from linear least-squares regressions are often correlated and have finite degrees of freedom. Fortunately, an extended form of (
5) can be used in some important special cases (see
Appendix A.1) [
9].
Equations (
1)–(
5) describe a methodology for evaluating measurement uncertainty that any GUM-compliant data processing should adhere to. However, in many situations, it is inconvenient, if not impossible, to formulate a single, complete, measurement model such as Equation (
1). Usually, a traceable measurement is perceived as a staged process, and it is difficult to describe when approached at more than one stage at a time. However, there is a mathematically equivalent formulation of these calculations that allows staged models to be handled. This formulation leads to a new abstract data type called an
uncertain number, which can represent inexactly known quantities [
4]. The uncertain-number format satisfies the requirements for information exchange identified in the GUM [
3] [Section 0.4].
2.2. The Uncertain-Number Methodology
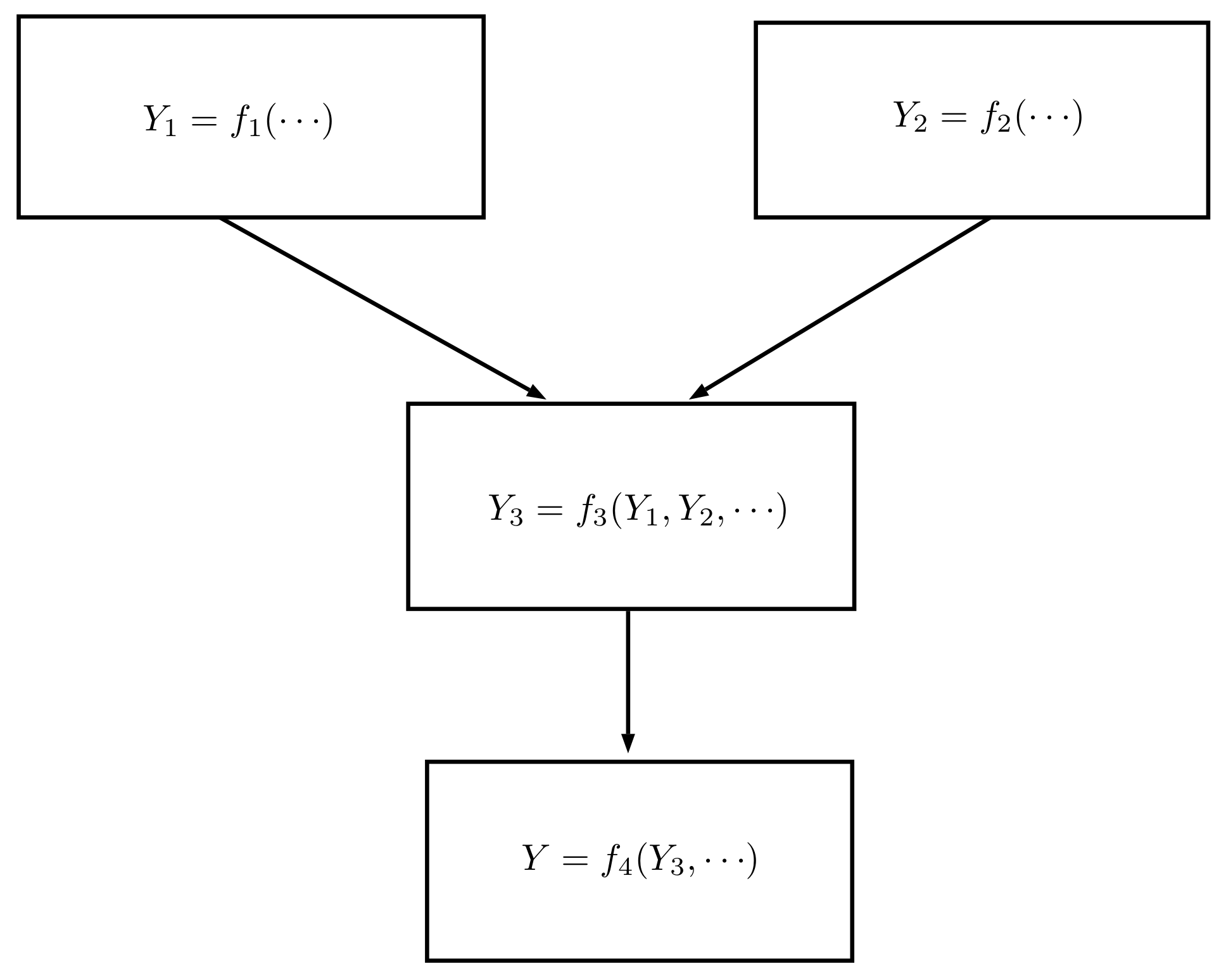
A mathematical expression may often be decomposed into stages and evaluated algorithmically as a sequence of basic operations. For instance, the following is the case:
and can be broken into four stages (also shown in
Figure 1):
This approach can be applied to measurement models. The evaluation of some arbitrary function
can be decomposed into
stages, each producing an intermediate result:
with the final stage yielding the result
. The set of inputs to the
hth stage function, denoted here as
, may include previous stage results
and model inputs
. Using the chain rule for partial differentiation, the components of uncertainty defined in Equation (
4) can be evaluated at each stage. The component of uncertainty in
due to uncertainty in the
jth model input is as follows.
Thus, the set of components of uncertainty , corresponding to , can be evaluated stage-by-stage to finally obtain the set of components of uncertainty in the result, (when , the notation may be simplified to , which is the standard uncertainty of model input ).
In GTC, an uncertain number is used to encapsulate results at each stage (, and the associated components of uncertainty, ). Uncertain numbers provide a convenient and succinct representation for quantities. Their algebraic properties essentially match those of ordinary number types. Thus, data processing algorithms can be expressed with familiar mathematical operations applied to uncertain-number terms representing quantities in a model. There is no need to derive the expressions for components of uncertainty; this is handled algorithmically.
The results of uncertain-number calculations are also transferable: the result of one calculation may be used as an argument in further calculations (as is performed routinely in numerical calculation). This is an open-ended process that can, in principle, continue indefinitely. The transferability of results is needed to support metrological traceability in staged measurement models. This will be discussed further in the next section and in
Section 3.6. The open-ended nature of uncertain-number computations is also illustrated in the example shown in
Section 2.4.
2.3. Traceability Chains and Uncertainty
Traceability provides accurate and reliable information about physical quantities that can be used to inform decisions. Because a quantity of interest can never be determined exactly, a decision based on the information available may not be correct; there will be some uncertainty—in a colloquial sense—about the correctness of a decision informed by data subject to measurement error. However, the risks associated with poor decision outcomes can be managed if the unpredictability of measurement results can be described in probabilistic terms (i.e., if the accuracy can be quantified). In this sense, the metrologist’s use of the term measurement uncertainty is associated with a likely magnitude of measurement error. To address the need for results that can be relied upon, metrological traceability requires the careful evaluation of measurement uncertainty.
Traceable measurement can be thought of as a collaborative process that is carried out in stages. Ultimately, a traceable measurement is of benefit to a nominal ‘end user’ at the last stage of a traceability chain, who needs information about a quantity to inform a decision (e.g., measuring the weights of shipping containers to inform the loading distribution of a container ship). The accuracy of a final result depends on all the stages; thus, the sources of uncertainty must be traced as far back as the units of measurement realised at the beginning of the process. This ensures that the result is meaningful and comparable with other traceable measurements of the same quantity.
While the GUM’s expression of a measurement model takes the form of a single all-encompassing Equation (
1), the staged formulation in
Section 2.2 handles the fact that people involved at one stage generally do not have detailed knowledge about processes carried out at other stages. For example,
Figure 2 shows a traceable measurement in four parts (e.g., stages 1 and 2 correspond to the realisation of reference standards, stage 3 to the calibration of a measuring instrument using those standards, and stage 4 to an end-user measurement using the calibrated instrument). The staged model is described as follows;
where unspecified arguments ‘⋯’ represent some subset of the influence quantities
. The end user can probably only formulate a model for stage 4,
; thus, information about earlier stages must be summarised and reported down the chain in a suitable format. If the model was expressed as a single function, the composition of the stages would provide the following.
Now, the outcome of data processing should not be affected by the expression of the model as a single function or a series of functions. This has a bearing on how information should be communicated along a traceability chain [
10]. By reporting uncertain numbers between stages, final results can be obtained that are the same as would be found for a single model. Uncertain numbers realise the GUM’s ideal method for evaluating and expressing the uncertainty of a result [
3] [Section 0.4].
2.4. A Simple Example
This section presents an example of uncertain-number data processing applied to a simple electrical network.
Figure 3 shows an electrical network with three resistors in series. A voltmeter can be connected between the lower terminal and any of the three terminals above, allowing the potential difference between terminals 0 and 1, 0 and 2, or 0 and 3 to be measured (
,
, or
, respectively).
We adopt a simple model for an imperfect voltmeter. The model has three sources of error (influence quantities) that affect the response of a meter (reading) to an input voltage
V. A random error (noise), represented as
, affects every reading; a systematic error,
, contributes a fixed offset to every reading; a systematic relative error,
, contributes an error proportional to the reading itself (representing imperfect scaling or non-linearity of the instrument). The relationship between the input voltage,
V, and a voltmeter reading,
v, is expressed by the model (already shown in
Section 2.2).
The influence quantities , , and are unknown, and so their effects cannot be corrected. However, the displayed value v is used as an approximation for V, because we assume that the instrument is properly adjusted. This is the same as assuming that the residual errors are small enough to be considered approximately zero. The uncertainty in the value of v, due to the estimates , can be found if the uncertainties , , and are known.
For uncertain number objects representing inputs to a measurement model, we find it helpful to adopt the term elementary uncertain number. Elementary uncertain numbers represent influence quantities. Numeric data must be provided when defining elementary uncertain numbers during the problem initialisation phase; this includes the following: a value (the estimate), a standard uncertainty, and a number of degrees of freedom.
We can use GTC to evaluate properties of the circuit, given measured values and some information about the voltmeter’s characteristics. Objects of the class Voltmeter, shown below, are used for data processing. During initialisation of a new Voltmeter (execution of __init__()), elementary uncertain numbers representing the two systematic errors are created and stored as instance variables (ureal() creates the uncertain numbers).
The
applied_voltage() method implements the model Equation (
8). It returns an uncertain number for the applied voltage corresponding to a displayed value,
v (the second argument,
index, is used to create a label for the elementary uncertain number,
E_rnd, which is associated with random noise). In the code below, the uncertain numbers
V_10,
V_20 and
V_30 are obtained from measurements of
,
, and
.
We can infer circuit properties from these uncertain-number results. For example, the code below shows how accurately the voltage was measured and the most important contributions to the uncertainty in that measured value.
The function display() prints the measured value and a standard uncertainty in parentheses, followed by a list of components of uncertainty in order of magnitude. The label for each component is shown on the left and the magnitude of the component of uncertainty on the right. The two most significant figures of standard uncertainty are shown. Here, has a measured value of 0.1258 volts and a standard uncertainty of 0.0050 volts.
Note that the dominant component of uncertainty is associated with the approximation made for systematic offset error . Very similar results are obtained for and .
Other circuit properties can be calculated too. For example, the potential difference across resistor 2 can be found by taking the difference between V_20 and V_10. Subtracting those uncertain numbers in the argument, display(V_20-V_10,"V_20-V_10") yields the following.
![Metrology 02 00009 i005]()
This is an interesting result, which illustrates the detailed underlying calculation of uncertainty that is performed automatically. The standard uncertainty in the difference here is only V—significantly less than the standard uncertainty in the individual measurements (both V). The uncertainty in this voltage difference is lower because it is insensitive to the offset (the offset is exactly the same in both readings). The display of components of uncertainty shows that the sensitivity to has been reduced to zero and that the influence of is now dominant. We might also expect a smaller contribution to uncertainty to come from relative systematic error . However, that component varies in proportion to the applied voltage (it is a systematic relative error), and since is about three times larger than , the contribution to uncertainty from is still about two times larger than it was in the direct measurement of .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}