

Tracking Eye Movements as a Window on Language Processing: The Visual World Paradigm


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definition
:1. Introduction
2. Using the Visual World Paradigm to Study Language Processing
2.1. First Studies Tracking Eye Movements
- (1)
- While on a photographic safari in Africa, I managed to get a number of breath-taking shots of the wild terrain. (…) When I noticed a hungry lion slowly moving through the tall glass toward a herd of grazing zebra.
- (2)
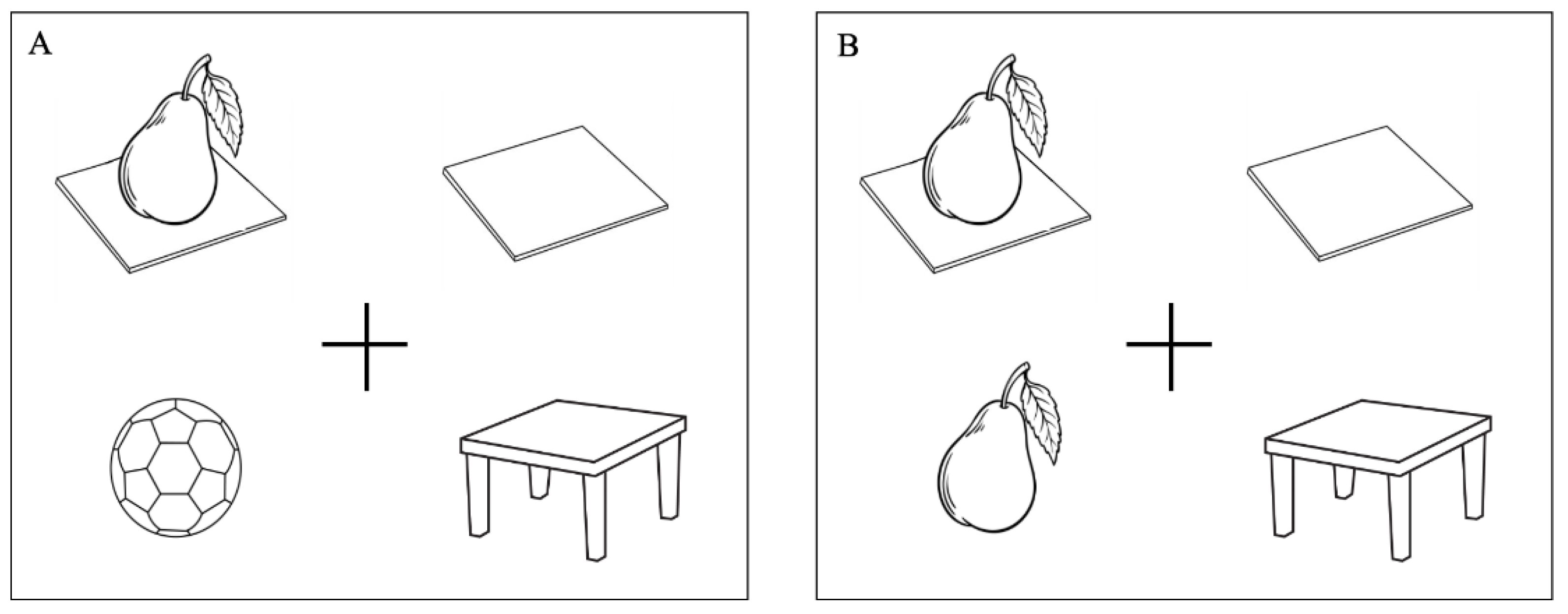
- Put the pear on the napkin on the table
- (3)
- Put the pear that is on the napkin on the table
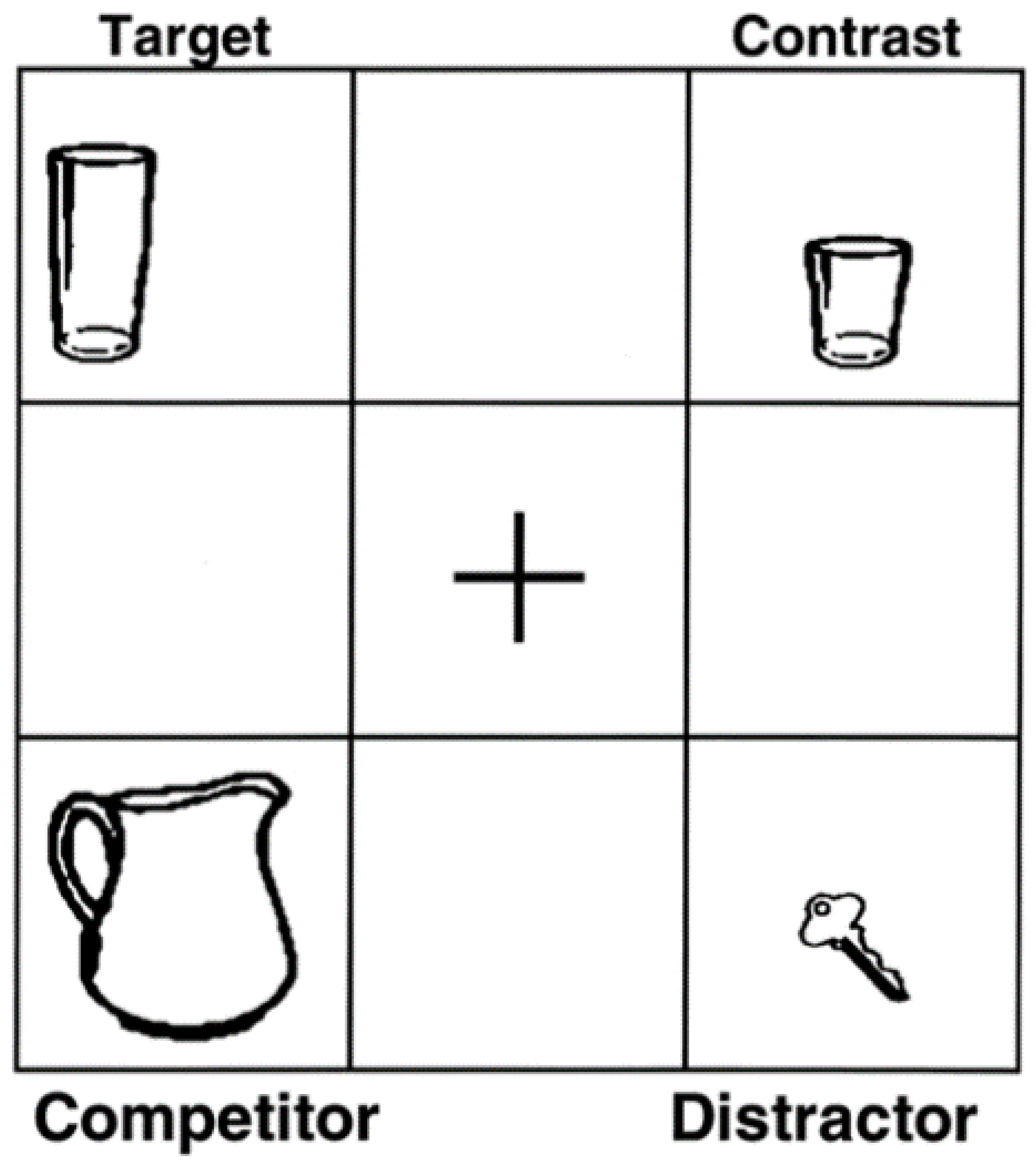
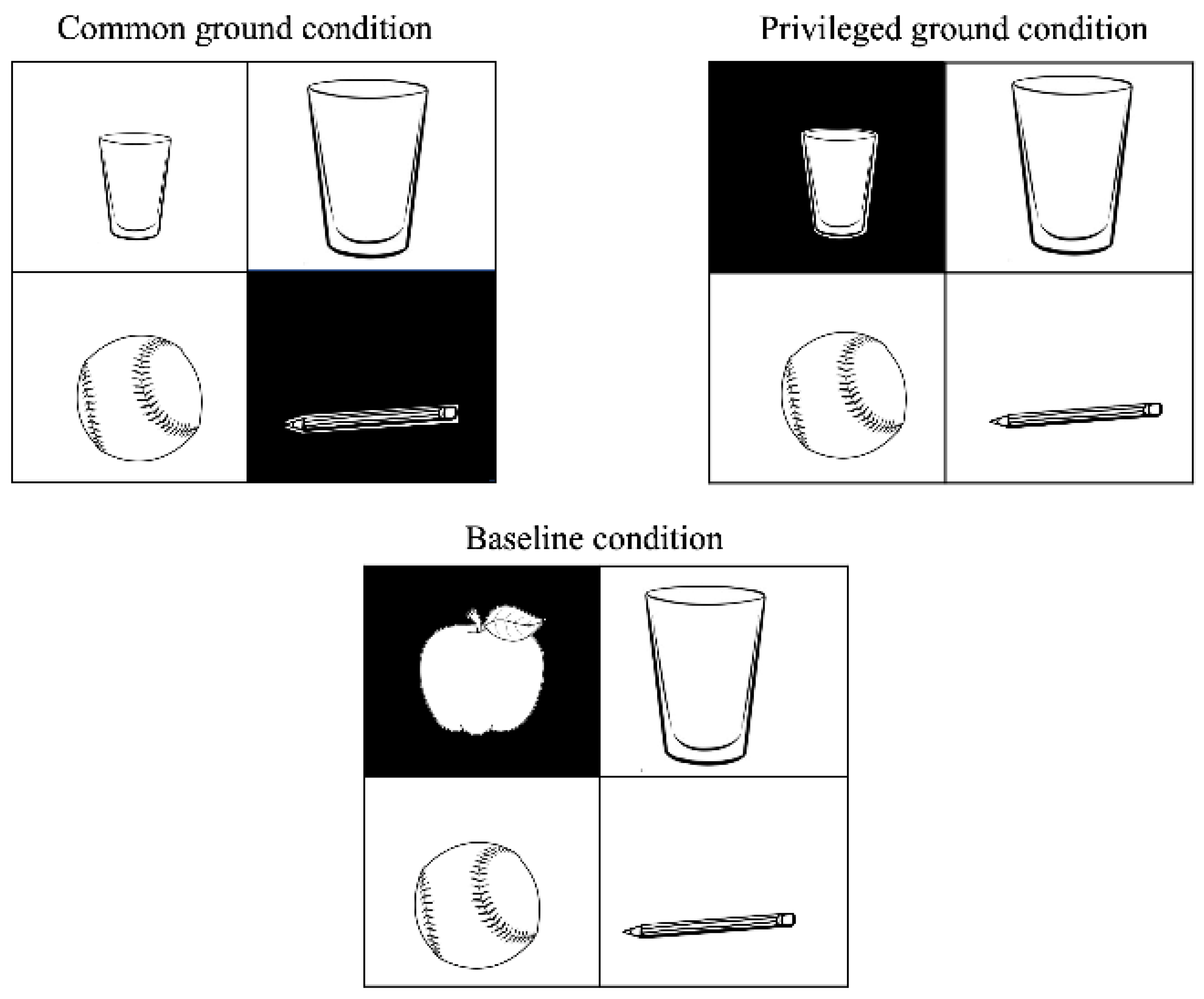
2.2. Procedures and Variants of the Visual World Paradigm
3. Tracking Children’s Eye Movements
3.1. The Preferential-Looking Paradigm
Advantages and Disadvantages
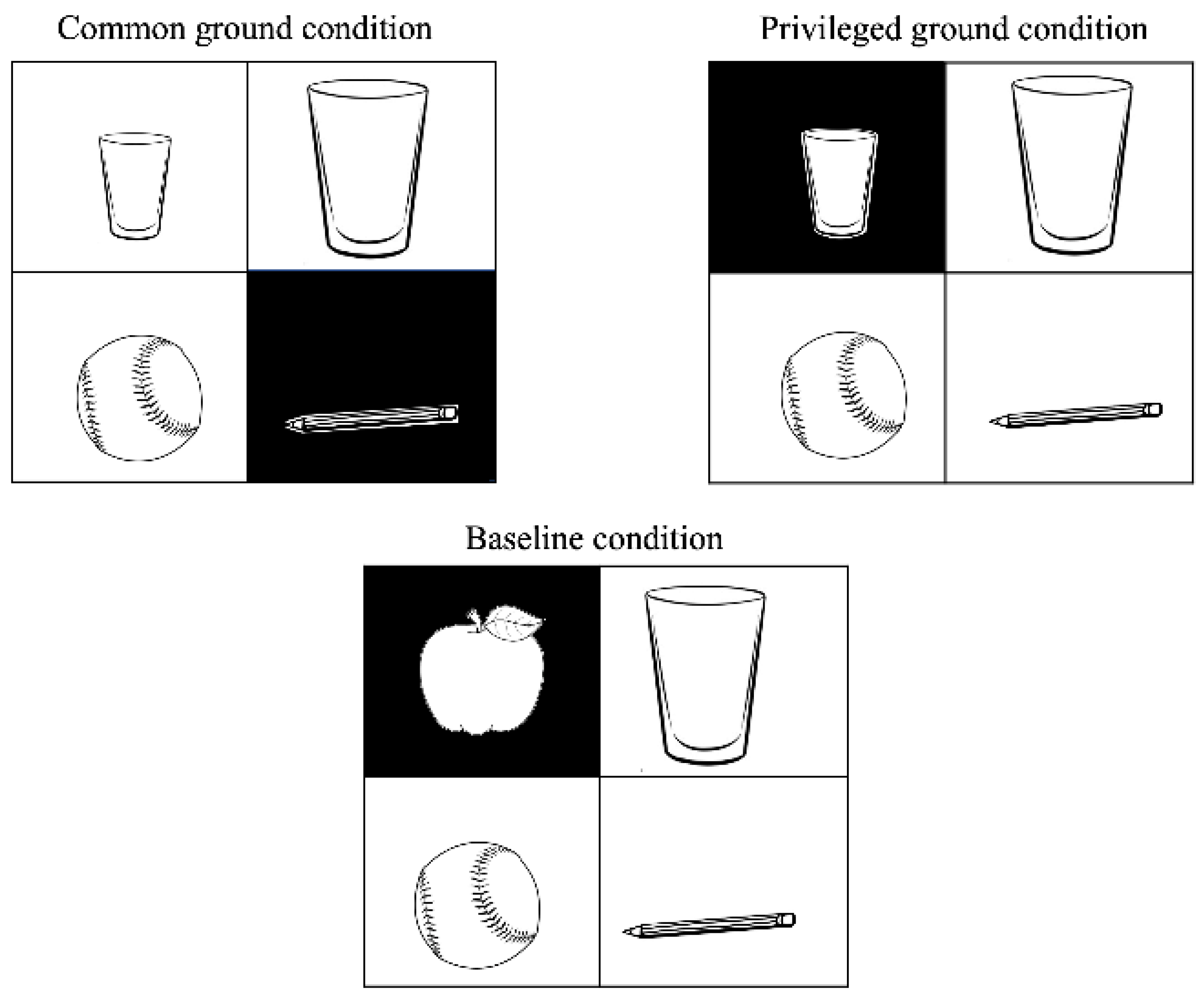
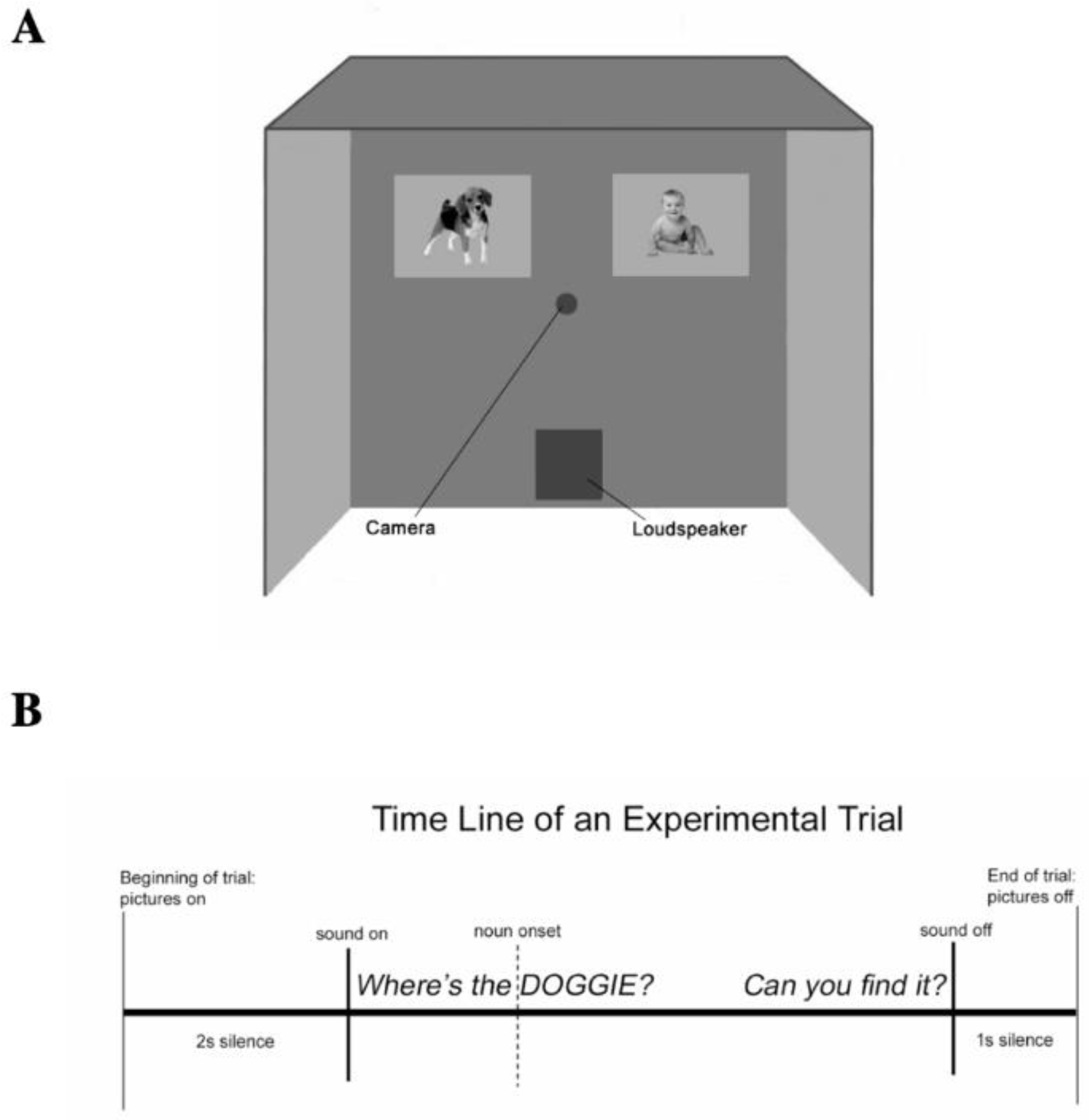
3.2. The Looking-While-Listening Task
Procedure and Limits
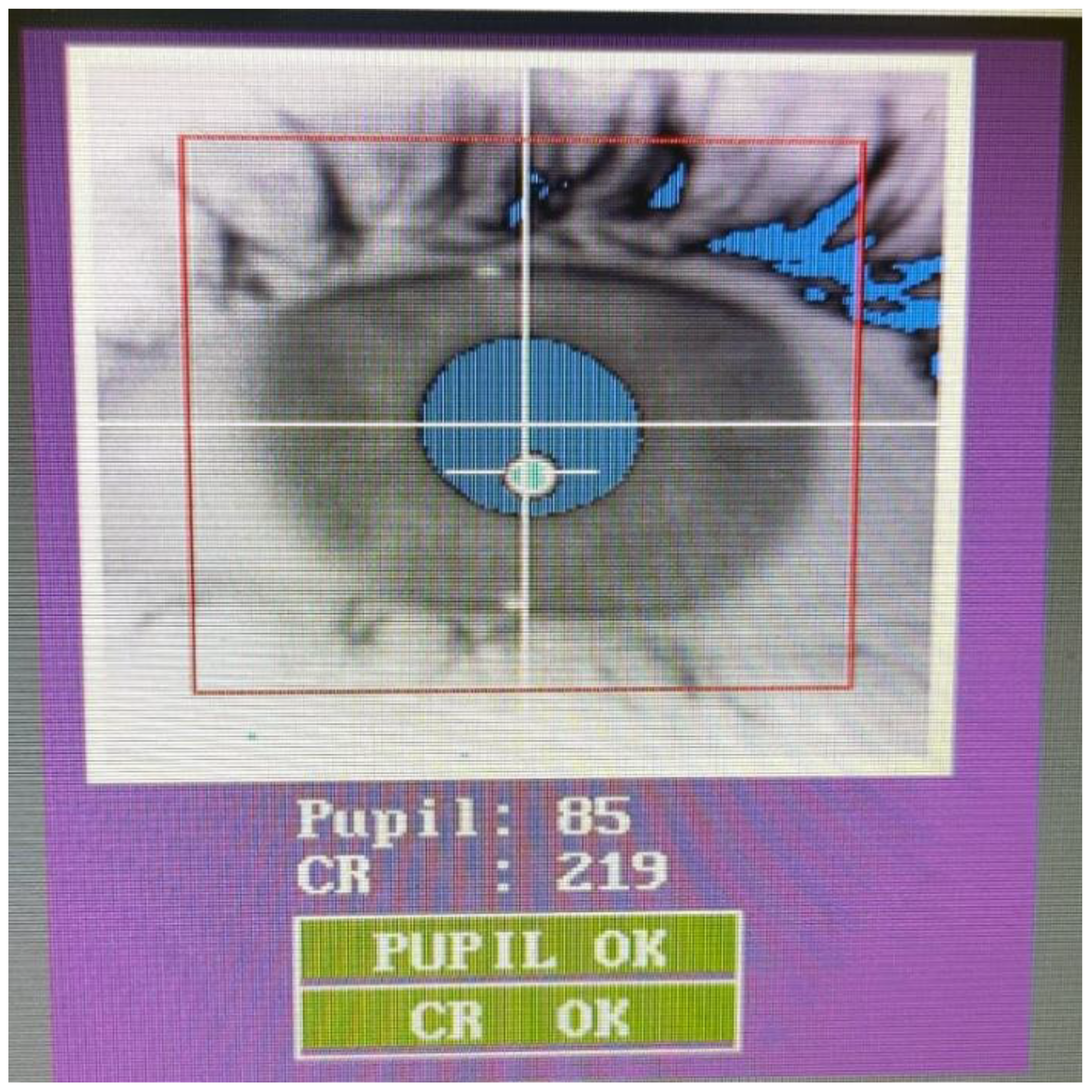
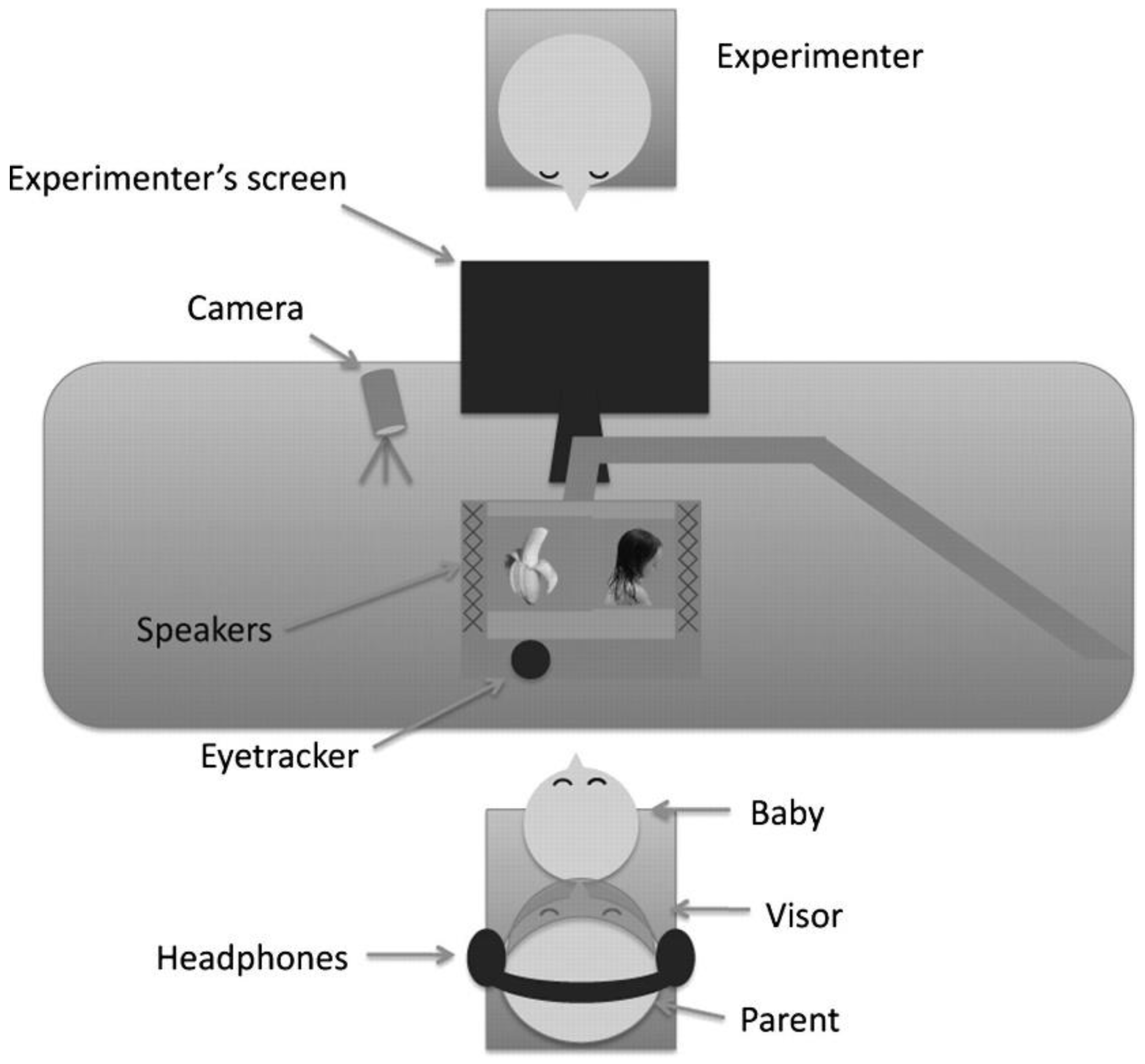
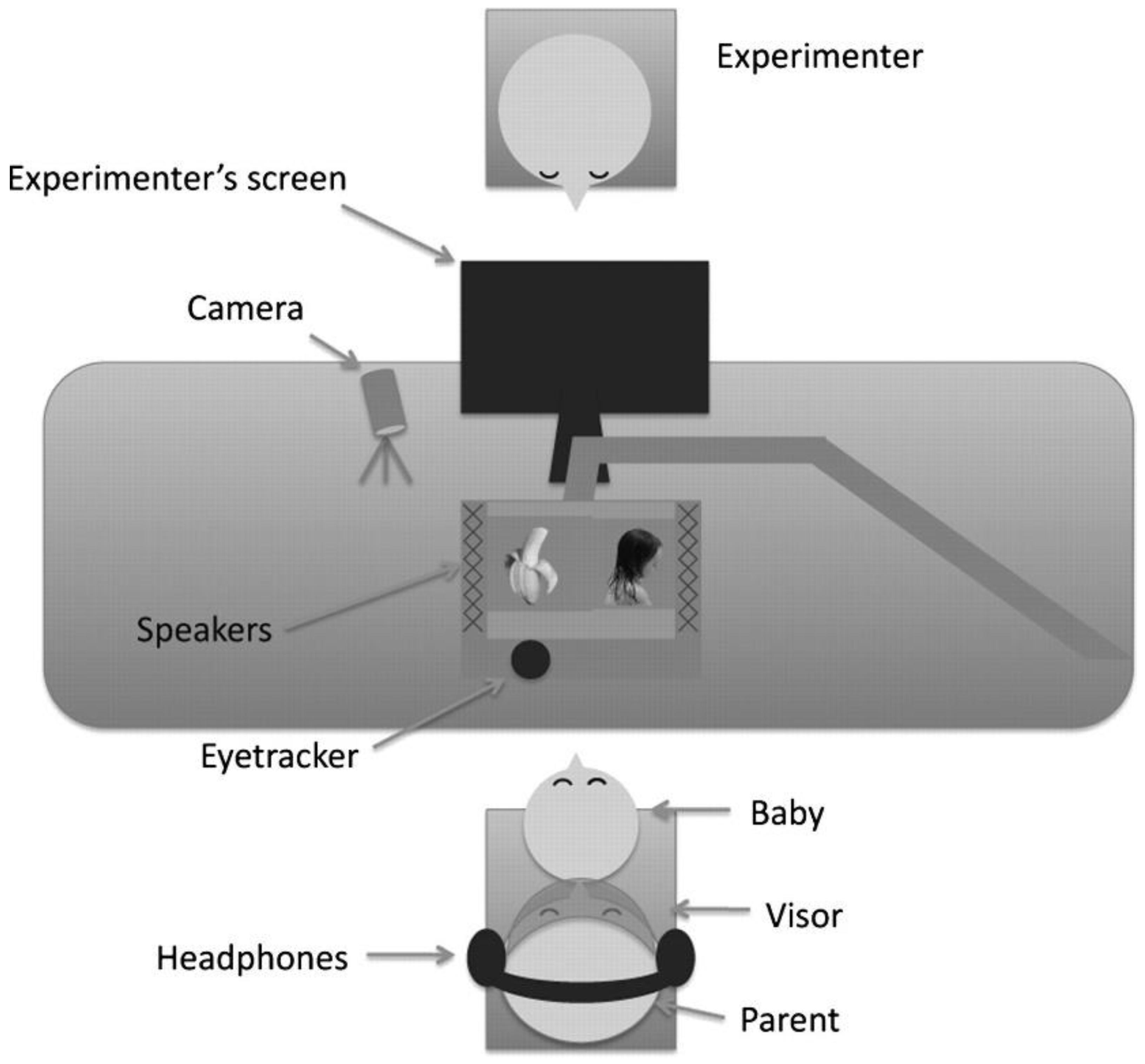
3.3. The Eye-Tracking Technology
3.3.1. The Analysis of Eye-Tracking Data
3.3.2. Limitations and Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Meyer, D.E.; Schvaneveldt, R.W. Facilitation in recognizing pairs of words: Evidence of a dependence between retrieval operations. J. Exp. Psychol. 1971, 90, 227–234. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wason, P.C. Response to Affirmative and Negative Binary Statements. Br. J. Psychol. 1961, 52, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Carpenter, P.A.; Just, M.A. Sentence comprehension: A psycholinguistic processing model of verification. Psychol. Rev. 1975, 82, 45–73. [Google Scholar] [CrossRef]
- Dickey, M.W.; Choy, J.J.; Thompson, C.K. Real-time comprehension of wh- movement in aphasia: Evidence from eyetracking while listening. Brain Lang. 2007, 100, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yee, E.; Blumstein, S.E.; Sedivy, J.C. Lexical-Semantic Activation in Broca’s and Wernicke’s Aphasia: Evidence from Eye Movements. J. Cogn. Neurosci. 2008, 20, 592–612. [Google Scholar] [CrossRef] [Green Version]
- Rayner, K. Eye movements in reading and information processing: 20 years of research. Psychol. Bull. 1998, 124, 372–422. [Google Scholar] [CrossRef] [PubMed]
- De Luca, M.; Di Pace, E.; Judica, A.; Spinelli, D.; Zoccolotti, P. Eye movement patterns in linguistic and non-linguistic tasks in developmental surface dyslexia. Neuropsychologia 1999, 37, 1407–1420. [Google Scholar] [CrossRef]
- Desroches, A.S.; Joanisse, M.F.; Robertson, E.K. Specific phonological impairments in dyslexia revealed by eyetracking. Cognition 2006, 100, B32–B42. [Google Scholar] [CrossRef]
- Huettig, F.; Brouwer, S. Delayed Anticipatory Spoken Language Processing in Adults with Dyslexia—Evidence from Eye-tracking. Dyslexia 2015, 21, 97–122. [Google Scholar] [CrossRef] [Green Version]
- Benfatto, M.N.; Seimyr, G.Ö.; Ygge, J.; Pansell, T.; Rydberg, A.; Jacobson, C. Screening for Dyslexia Using Eye Tracking during Reading. PLoS ONE 2016, 11, e0165508. [Google Scholar] [CrossRef] [Green Version]
- Joseph HS, S.L.; Nation, K.; Liversedge, S.P. Using Eye Movements to Investigate Word Frequency Effects in Children’s Sentence Reading. Sch. Psychol. Rev. 2013, 42, 207–222. [Google Scholar] [CrossRef]
- Mani, N.; Huettig, F. Word reading skill predicts anticipation of upcoming spoken language input: A study of children developing proficiency in reading. J. Exp. Child Psychol. 2014, 126, 264–279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tribushinina, E.; Mak, W.M. Three-year-olds can predict a noun based on an attributive adjective: Evidence from eye-tracking. J. Child Lang. 2016, 43, 425–441. [Google Scholar] [CrossRef] [PubMed]
- Yarbus, A.L. Eye Movements and Vision; Plenum Press: New York, NY, USA, 1967. [Google Scholar]
- Cooper, R.M. The control of eye fixation by the meaning of spoken language: A new methodology for the real-time investigation of speech perception, memory, and language processing. Cogn. Psychol. 1974, 6, 84–107. [Google Scholar] [CrossRef]
- Mackworth, N.H. The wide-angle reflection eye camera for visual choice and pupil size. Percept. Psychophys. 1968, 3, 32–34. [Google Scholar] [CrossRef] [Green Version]
- Just, M.A.; Carpenter, P.A. A theory of reading: From eye fixations to comprehension. Psychol. Rev. 1980, 87, 329–354. [Google Scholar] [CrossRef] [PubMed]
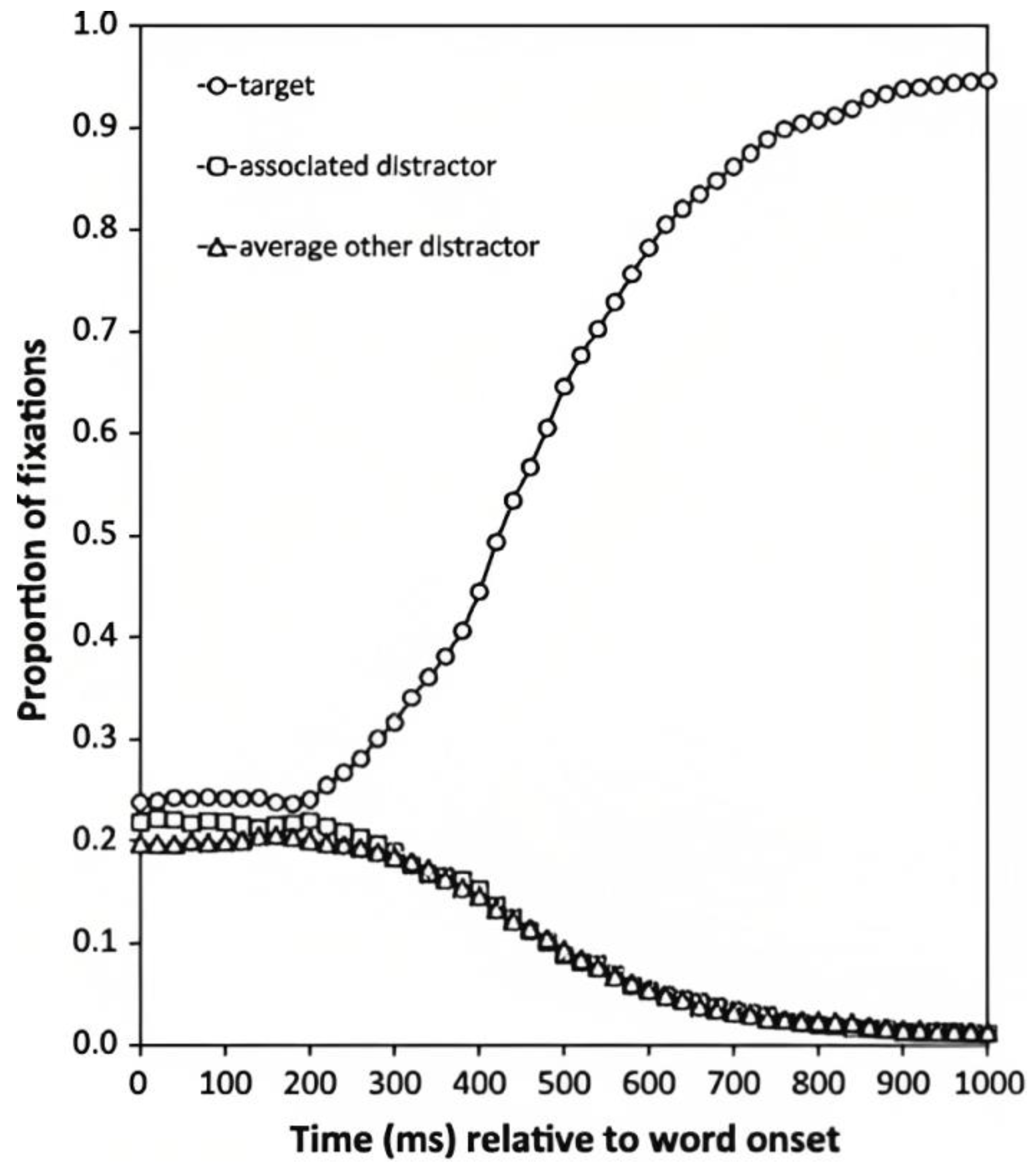
- Allopenna, P.D.; Magnuson, J.S.; Tanenhaus, M.K. Tracking the Time Course of Spoken Word Recognition Using Eye Movements: Evidence for Continuous Mapping Models. J. Mem. Lang. 1998, 38, 419–439. [Google Scholar] [CrossRef] [Green Version]
- Tanenhaus, M.K.; Spivey, M.; Eberhard, K.; Sedivy, J. Integration of visual and linguistic information in spoken language comprehension. Science 1995, 268, 1632–1634. [Google Scholar] [CrossRef] [Green Version]
- Frazier, L.; Fodor, J.D. The sausage machine: A new two-stage parsing model. Cognition 1978, 6, 291–325. [Google Scholar] [CrossRef]
- De Vincenzi, M. Syntactic Parsing Strategies in Italian; Kluwer: Dordrecht, The Netherlands, 1991. [Google Scholar]
- De Vincenzi, M.; Job, R. An investigation of Late Closure: The role of syntax, thematic structure and pragmatics in initial and final interpretation. J. Exp. Psychol. Learn. Mem. Cogn. 1995, 21, 1303–1321. [Google Scholar] [CrossRef]
- Tagliani, M. On Vision and Language Interaction in Negation Processing: The Real-Time Interpretation of Sentential Negation in Typically Developed and Dyslexic Adults. Ph.D. Dissertation, University of Verona, Verona, Italy, University of Göttingen, Göttingen, Germany, 2021. [Google Scholar]
- Sedivy, J. Chapter 6. Using eyetracking in language acquisition research. In Experimental Methods in Language Acquisition Research; Blom, E., Unsworth, S., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2010; pp. 115–138. [Google Scholar] [CrossRef]
- Altmann GT, M.; Kamide, Y. Incremental interpretation at verbs: Restricting the domain of subsequent reference. Cognition 1999, 73, 247–264. [Google Scholar] [CrossRef] [Green Version]
- Nadig, A.S.; Sedivy, J.C. Evidence of Perspective-Taking Constraints in Children’s On-Line Reference Resolution. Psychol. Sci. 2002, 13, 329–336. [Google Scholar] [CrossRef]
- Sedivy, J.C.; KTanenhaus, M.; Chambers, C.G.; Carlson, G.N. Achieving incremental semantic interpretation through contextual representation. Cognition 1999, 71, 109–147. [Google Scholar] [CrossRef] [PubMed]
- Werker, J.F.; Tees, R.C. Cross-language speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behav. Dev. 1984, 7, 49–63. [Google Scholar] [CrossRef]
- Saffran, J.R. Constraints on Statistical Language Learning. J. Mem. Lang. 2002, 47, 172–196. [Google Scholar] [CrossRef] [Green Version]
- Hallé, P.A.; de Boysson-Bardies, B. Emergence of an early receptive lexicon: Infants’ recognition of words. Infant Behav. Dev. 1994, 17, 119–129. [Google Scholar] [CrossRef]
- Eimas, P.D.; Siqueland, E.R.; Jusczyk, P.; Vigorito, J. Speech perception in infants. Science 1971, 171, 303–306. [Google Scholar] [CrossRef] [PubMed]
- Tsushima, T.; Takizawa, O.; Sasaki, M.; Shiraki, S.; Nishi, K.; Kohno, M.; Menyuk, P.; Best, C. Discrimination of English /r-l/and /w-y/by Japanese infants at 6-12 Months: Language specific developmental changes in speech perception abilities. In Proceedings of the International Conference of Spoken Language Processing Acoustical Society of Japan, Yokohama, Japan, 18–22 September 1994; pp. 1695–1698. [Google Scholar]
- Bloom, L. One Word at a Time: The Use of Single Word Utterances before Syntax. In One Word at a Time; De Gruyter Mouton: Berlin, Germany, 2013. [Google Scholar] [CrossRef]
- Fenson, L.; Marchman, V.A.; Thal, D.J.; Dale, P.S.; Reznick, J.S.; Bates, E. MacArthur-Bates Communicative Development Inventories, 2nd ed.; APA PsycTests: Washington, DC, USA, 2006; Available online: https://psycnet.apa.org/doiLanding?doi=10.1037%2Ft11538-000 (accessed on 22 December 2022).
- Benedict, H. Early lexical development: Comprehension and production. J. Child Lang. 1979, 6, 183–200. [Google Scholar] [CrossRef]
- Markman, E.M. Categorization and Naming in Children: Problems of Induction; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Golinkoff, R.M.; Ma, W.; Song, L.; Hirsh-Pasek, K. Twenty-five years using the intermodal preferential looking paradigm to study language acquisition: What have we learned? Perspect. Psychol. Sci. 2013, 8, 316–339. [Google Scholar] [CrossRef] [Green Version]
- Fantz, R.L. Pattern Vision in Newborn Infants. Science 1963, 140, 296–297. [Google Scholar] [CrossRef] [PubMed]
- Fantz, R.L. Pattern Vision in Young Infants. Psychol. Rec. 1958, 8, 43. Available online: https://www.proquest.com/docview/1301204249/citation/9A76F464DBD14937PQ/1 (accessed on 22 December 2022). [CrossRef]
- Fantz, R.L. Visual Experience in Infants: Decreased Attention to Familiar Patterns Relative to Novel Ones. Science 1964, 146, 668–670. [Google Scholar] [CrossRef] [PubMed]
- Spelke, E. Infants’ intermodal perception of events. Cogn. Psychol. 1976, 8, 553–560. [Google Scholar] [CrossRef]
- Spelke, E.S. Perceiving bimodally specified events in infancy. Dev. Psychol. 1979, 15, 626–636. [Google Scholar] [CrossRef]
- Thomas, D.G.; Campos, J.J.; Shucard, D.W.; Ramsay, D.S.; Shucard, J. Semantic Comprehension in Infancy: A Signal Detection Analysis. Child Dev. 1981, 52, 798–803. [Google Scholar] [CrossRef]
- Ambridge, B.; Rowland, C.F. Experimental methods in studying child language acquisition. WIREs Cogn. Sci. 2013, 4, 149–168. [Google Scholar] [CrossRef]
- Naigles, L. Children use syntax to learn verb meanings. J. Child Lang. 1990, 17, 357–374. [Google Scholar] [CrossRef] [Green Version]
- Hoff, E. Research Methods in Child Language: A Practical Guide; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Golinkoff, R.M.; Hirsh-Pasek, K.; Mervis, C.B.; Frawley, W.B.; Parillo, M. Lexical principles can be extended to the acquisition of verbs. In Beyond Names for Things: Young Children’s Acquisition of Verbs; Psychology Press: London, UK, 1995; pp. 185–222. [Google Scholar]
- Reznick, J.S. Visual preference as a test of infant word comprehension. Appl. Psycholinguist. 1990, 11, 145–166. [Google Scholar] [CrossRef]
- Golinkoff, R.M.; Hirsh-Pasek, K.; Cauley, K.M.; Gordon, L. The eyes have it: Lexical and syntactic comprehension in a new paradigm. J. Child Lang. 1987, 14, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Hirsh-Pasek, K.; Golinkoff, R.M. The intermodal preferential looking paradigm: A window onto emerging language comprehension. In Methods for Assessing Children’s Syntax; The MIT Press: Cambridge, MA, USA, 1996; pp. 105–124. [Google Scholar]
- Naigles, L.G.; Kako, E.T. First Contact in Verb Acquisition: Defining a Role for Syntax. Child Dev. 1993, 64, 1665–1687. [Google Scholar] [CrossRef]
- Naigles, L.G.; Gelman, S.A. Overextensions in comprehension and production revisited: Preferential-looking in a study of dog, cat, and cow. J. Child Lang. 1995, 22, 19–46. [Google Scholar] [CrossRef]
- Golinkoff, R.M.; Hirsh-Pasek, K.; Bailey, L.M.; Wenger, N.R. Young children and adults use lexical principles to learn new nouns. Dev. Psychol. 1992, 28, 99–108. [Google Scholar] [CrossRef]
- Gleitman, L. The structural sources of verb meaning. Lang. Acquis. 1990, 1, 3–55. [Google Scholar] [CrossRef]
- Gleitman, L.R.; Cassidy, K.; Nappa, R.; Papafragou, A.; Trueswell, J.C. Hard words. Lang. Learn. Dev. 2005, 1, 23–64. [Google Scholar] [CrossRef]
- Landau, B.; Gleitman, L.R. Language and Experience; Harvard University Press: Cambridge, MA, USA, 1985. [Google Scholar]
- Lidz, J.; Waxman, S.; Freedman, J. What infants know about syntax but couldn’t have learned: Experimental evidence for syntactic structure at 18 months. Cognition 2003, 89, 295–303. [Google Scholar] [CrossRef] [PubMed]
- Halberda, J.; Sires, S.F.; Feigenson, L. Multiple Spatially Overlapping Sets Can Be Enumerated in Parallel. Psychol. Sci. 2006, 17, 572–576. [Google Scholar] [CrossRef]
- Markman, E.M.; Wachtel, G.F. Children’s use of mutual exclusivity to constrain the meanings of words. Cogn. Psychol. 1988, 20, 121–157. [Google Scholar] [CrossRef]
- Hollich, G.J.; Hirsh-Pasek, K.; Golinkoff, R.M.; Brand, R.J.; Brown, E.; Chung, H.L.; Hennon, E.; Rocroi, C.; Bloom, L. Breaking the Language Barrier: An Emergentist Coalition Model for the Origins of Word Learning. Monogr. Soc. Res. Child Dev. 2000, 65, 1–123. [Google Scholar] [PubMed]
- Bates, E. Comprehension and production in early language development: Comments on Savage-Rumbaugh et al. Monogr. Soc. Res. Child Dev. 1993, 58, 222–242. [Google Scholar] [CrossRef] [Green Version]
- Fernald, A.; Zangl, R.; Portillo, A.L.; Marchman, V.A. Looking while listening: Using eye movements to monitor spoken language. In Developmental Psycholinguistics: On-Line Methods in Children’s Language Processing; John Benjamins Publishing: Amsterdam, The Netherlands, 2008; pp. 97–134. [Google Scholar]
- Fernald, A.; McRoberts, G.; Herrera, C. The Role of prosodic features in early word recognition. In Proceedings of the 8th International Conference on Infant Studies, Miami, FL, USA, 7–10 May 1992. [Google Scholar]
- Fernald, A.; Pinto, J.P.; Swingley, D.; Weinberg, A.; McRoberts, G.W. Rapid Gains in Speed of Verbal Processing by Infants in the 2nd Year. Psychol. Sci. 1998, 9, 228–231. [Google Scholar] [CrossRef]
- Fernald, A.; Thorpe, K.; Marchman, V.A. Blue car, red car: Developing efficiency in online interpretation of adjective–noun phrases. Cogn. Psychol. 2010, 60, 190–217. [Google Scholar] [CrossRef] [Green Version]
- Arias-Trejo, N.; Plunkett, K. The effects of perceptual similarity and category membership on early word-referent identification. J. Exp. Child Psychol. 2010, 105, 63–80. [Google Scholar] [CrossRef] [PubMed]
- Mani, N.; Plunkett, K. Phonological specificity of vowels and consonants in early lexical representations. J. Mem. Lang. 2007, 57, 252–272. [Google Scholar] [CrossRef]
- Swingley, D.; Aslin, R.N. Spoken word recognition and lexical representation in very young children. Cognition 2000, 76, 147–166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swingley, D.; Aslin, R.N. Lexical Neighborhoods and the Word-Form Representations of 14-Month-Olds. Psychol. Sci. 2002, 13, 480–484. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Durrant, S.; Luche, C.D.; Cattani, A.; Floccia, C. Monodialectal and multidialectal infants’ representation of familiar words. J. Child Lang. 2015, 42, 447–465. [Google Scholar] [CrossRef] [PubMed]
- Redolfi, M. How children acquire adjectives: Evidence from three eye-tracking studies on Italian. Doctoral Dissertation, University of Verona, Verona, Italy, University of Konstanz, Konstanz, Germany, 2022. [Google Scholar]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Wass, S.V. The use of eye-tracking with infants and children. In Practical Research with Children; Routledge: London, UK, 2016; pp. 50–71. [Google Scholar] [CrossRef]
- Tanenhaus, M.K.; Brown-Schmidt, S. Language processing in the natural world. Philos. Trans. R. Soc. B Biol. Sci. 2008, 363, 1105–1122. [Google Scholar] [CrossRef] [Green Version]
- Bergelson, E.; Swingley, D. At 6–9 months, human infants know the meanings of many common nouns. Proc. Natl. Acad. Sci. USA 2012, 109, 3253–3258. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salverda, A.P.; Tanenhaus, M.K. The Visual World Paradigm. In Research Methods in Psycholinguistics and the Neurobiology of Language: A Practical Guide; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Salverda, A.P.; Kleinschmidt, D.; Tanenhaus, M.K. Immediate effects of anticipatory coarticulation in spoken-word recognition. J. Mem. Lang. 2014, 71, 145–163. [Google Scholar] [CrossRef] [Green Version]
- Baayen, H.; Vasishth, S.; Kliegl, R.; Bates, D. The cave of shadows: Addressing the human factor with generalized additive mixed models. J. Mem. Lang. 2017, 94, 206–234. [Google Scholar] [CrossRef] [Green Version]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Magnuson, J.S. Fixations in the visual world paradigm: Where, when, why? J. Cult. Cogn. Sci. 2019, 3, 113–139. [Google Scholar] [CrossRef]
- Venhuizen, N.J.; Crocker, M.W.; Brouwer, H. Expectation-based comprehension: Modeling the interaction of world knowledge and linguistic experience. Discourse Process. 2019, 56, 229–255. [Google Scholar] [CrossRef] [Green Version]
- Dahan, D.; Tanenhaus, M.K. Looking at the rope when looking for the snake: Conceptually mediated eye movements during spoken-word recognition. Psychon. Bull. Rev. 2005, 12, 453–459. [Google Scholar] [CrossRef] [Green Version]
- Huettig, F.; Rommers, J.; Meyer, A.S. Using the visual world paradigm to study language processing: A review and critical evaluation. Acta Psychol. 2011, 137, 151–171. [Google Scholar] [CrossRef] [Green Version]
- Huizeling, E.; Alday, P.M.; Peeters, D.; Hagoort, P. Combining EEG and eye-tracking to investigate the prediction of upcoming speech in naturalistic virtual environments: A 3D visual world paradigm. In Proceedings of the 18th NVP Winter Conference on Brain and Cognition, Egmond aan Zee, The Netherlands, 28–30 April 2022. [Google Scholar]
- Huettig, F.; Guerra, E. Effects of speech rate, preview time of visual context, and participant instructions reveal strong limits on prediction in language processing. Brain Res. 2019, 1706, 196–208. [Google Scholar] [CrossRef] [Green Version]
- Orenes, I.; Beltrán, D.; Santamaría, C. How negation is understood: Evidence from the visual world paradigm. J. Mem. Lang. 2014, 74, 36–45. [Google Scholar] [CrossRef]
- Orenes, I.; Moxey, L.; Scheepers, C.; Santamaría, C. Negation in context: Evidence from the visual world paradigm. Q. J. Exp. Psychol. 2016, 69, 1082–1092. [Google Scholar] [CrossRef] [Green Version]
- Orenes, I.; García-Madruga, J.A.; Espino, O.; Byrne, R.M. The Comprehension of Counterfactual Conditionals: Evidence from Eye-Tracking in the Visual World Paradigm. Front. Psychol. 2019, 10, 1172. [Google Scholar] [CrossRef] [Green Version]
- Özge, D.; Küntay, A.; Snedeker, J. Why wait for the verb? Turkish speaking children use case markers for incremental language comprehension. Cognition 2019, 183, 152–180. [Google Scholar] [CrossRef]
- Bergelson, E.; Aslin, R. Semantic specificity in one-year-olds’ word comprehension. Lang. Learn. Dev. 2017, 13, 481–501. [Google Scholar] [CrossRef] [Green Version]
- Bergelson, E.; Swingley, D. Young infants’ word comprehension given an unfamiliar talker or altered pronunciations. Child Dev. 2018, 89, 1567–1576. [Google Scholar] [CrossRef] [Green Version]
- Mani, N.; Huettig, F. Prediction during language processing is a piece of cake—But only for skilled producers. J. Exp. Psychol. Hum. Percept. Perform. 2012, 38, 843. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borovsky, A.; Elman, J.L.; Fernald, A. Knowing a lot for one’s age: Vocabulary skill and not age is associated with anticipatory incremental sentence interpretation in children and adults. J. Exp. Child Psychol. 2012, 112, 417–436. [Google Scholar] [CrossRef] [Green Version]
- Mak, W.M.; Tribushinina, E.; Lomako, J.; Gagarina, N.; Abrosova, E.; Sanders, T. Connective processing by bilingual children and monolinguals with specific language impairment: Distinct profiles. J. Child Lang. 2017, 44, 329–345. [Google Scholar] [CrossRef] [Green Version]
- Thompson, C.K.; Choy, J.J. Pronominal resolution and gap filling in agrammatic aphasia: Evidence from eye movements. J. Psycholinguist. Res. 2009, 38, 255–283. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Kim, H.; Harris, H.; Haberstroh, A.; Wright, H.H.; Rothermich, K. Eye tracking measures for studying language comprehension deficits in aphasia: A systematic search and scoping review. J. Speech Lang. Hear. Res. 2021, 64, 1008–1022. [Google Scholar] [CrossRef]
- Franzen, L.; Stark, Z.; Johnson, A.P. Individuals with dyslexia use a different visual sampling strategy to read text. Sci. Rep. 2021, 11, 6449. [Google Scholar] [CrossRef]
- Robertson, E.K.; Gallant, J.E. Eye tracking reveals subtle spoken sentence comprehension problems in children with dyslexia. Lingua 2019, 228, 102708. [Google Scholar] [CrossRef]
- Huettig, F.; McQueen, J.M. The tug of war between phonological, semantic and shape information in language-mediated visual search. J. Mem. Lang. 2007, 57, 460–482. [Google Scholar] [CrossRef] [Green Version]
- de Groot, F.; Huettig, F.; Olivers, C.N.L. When meaning matters: The temporal dynamics of semantic influences on visual attention. J. Exp. Psychol. Hum. Percept. Perform. 2016, 42, 180–196. [Google Scholar] [CrossRef] [PubMed] [Green Version]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tagliani, M.; Redolfi, M. Tracking Eye Movements as a Window on Language Processing: The Visual World Paradigm. Encyclopedia 2023, 3, 245-266. https://doi.org/10.3390/encyclopedia3010016
Tagliani M, Redolfi M. Tracking Eye Movements as a Window on Language Processing: The Visual World Paradigm. Encyclopedia. 2023; 3(1):245-266. https://doi.org/10.3390/encyclopedia3010016
Chicago/Turabian StyleTagliani, Marta, and Michela Redolfi. 2023. "Tracking Eye Movements as a Window on Language Processing: The Visual World Paradigm" Encyclopedia 3, no. 1: 245-266. https://doi.org/10.3390/encyclopedia3010016
APA StyleTagliani, M., & Redolfi, M. (2023). Tracking Eye Movements as a Window on Language Processing: The Visual World Paradigm. Encyclopedia, 3(1), 245-266. https://doi.org/10.3390/encyclopedia3010016