


An Uncertainty-Driven Proactive Self-Healing Model for Pervasive Applications




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We propose a self-healing model for maximizing the number of high-priority tasks served by an edge node. We pursue keeping free space in the local queue to host those tasks in support of real-time applications;
- We ensure the smooth operation of edge nodes under heavy traffic, avoiding overloading scenarios;
- We achieve the efficient management of the incoming load by taking the appropriate decisions for the offloading actions, taking into consideration the priority of tasks combined with their demand;
- We report on an extensive evaluation process of the proposed model, revealing its pros and cons.
2. Preliminaries and Scenario Description
2.1. Scenario Description
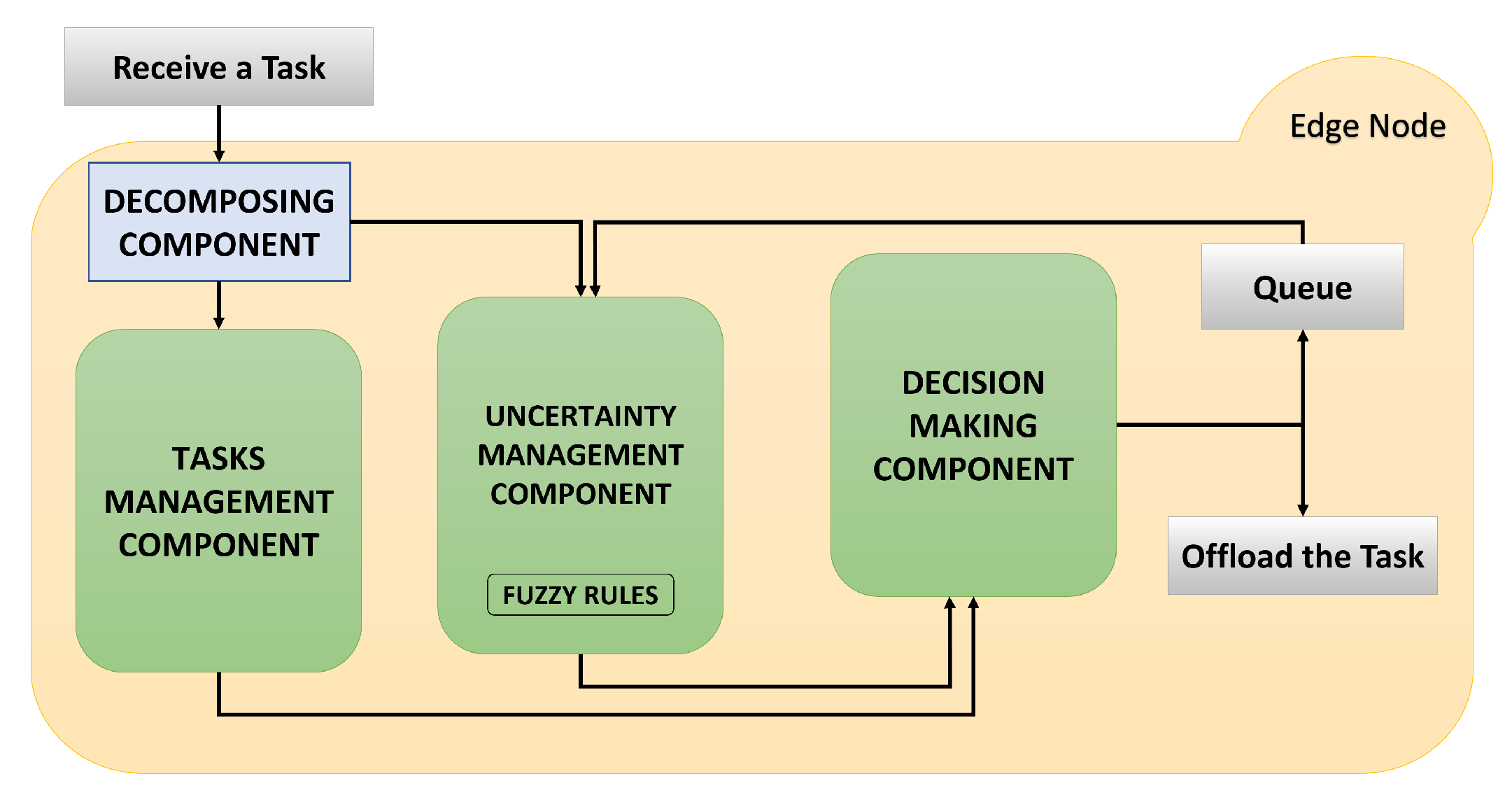
2.2. Task Management
2.3. Trend Estimation
2.4. Uncertainty-Based Estimation of Overloading
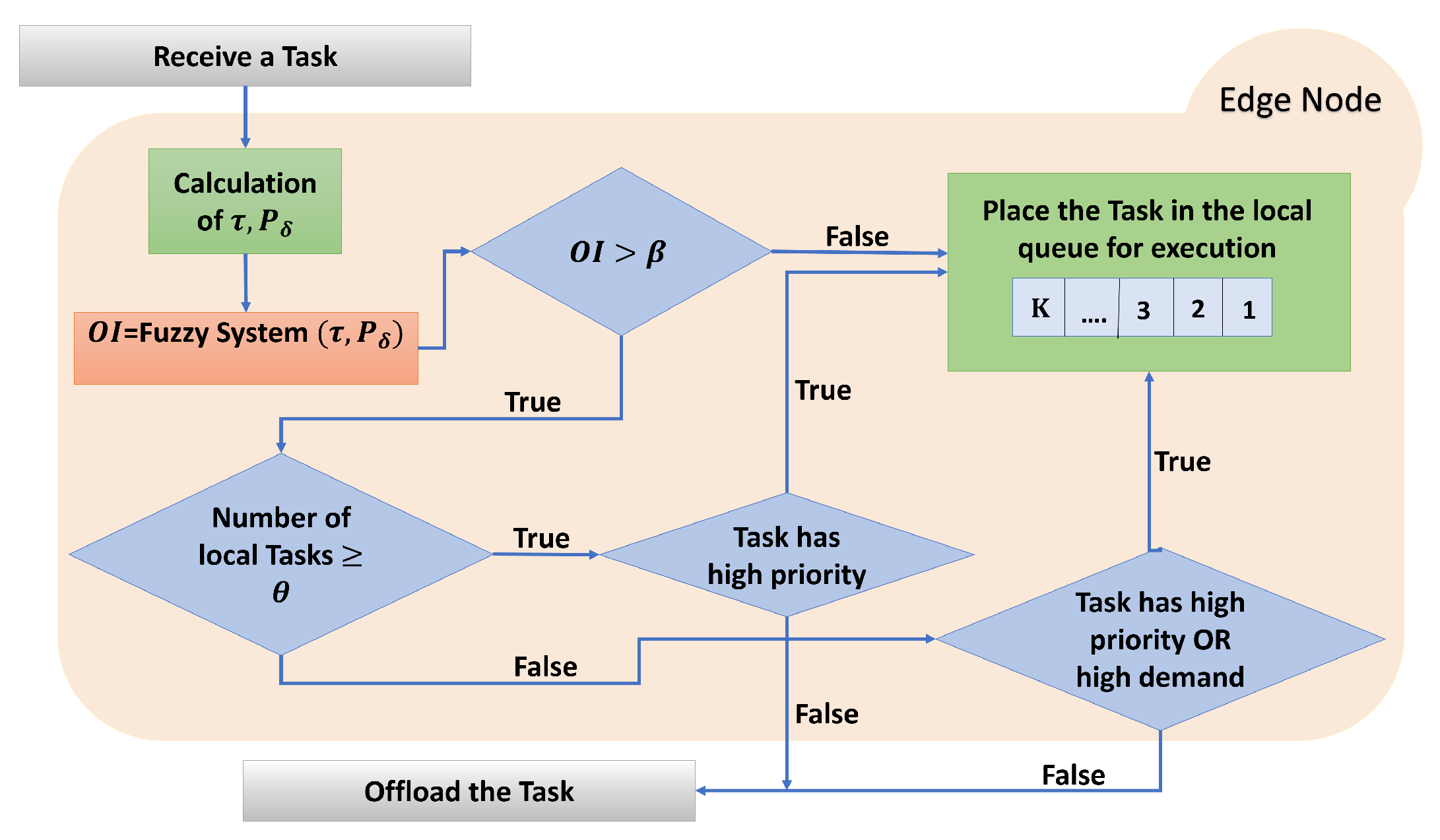
2.5. Offloading Strategy Based on the Overloading Indicator
| Algorithm 1 Algorithm for Task Offloading based on |
|
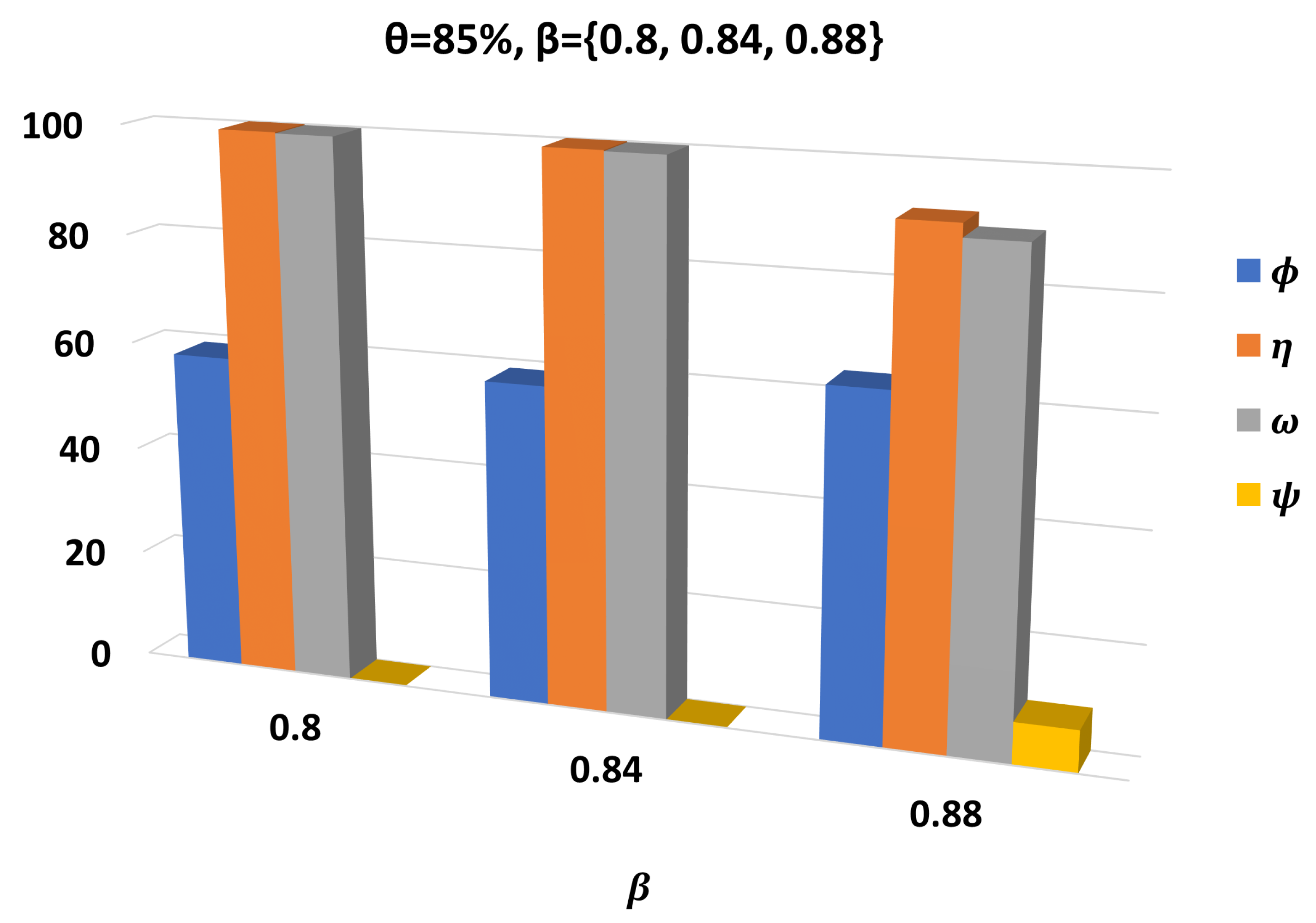
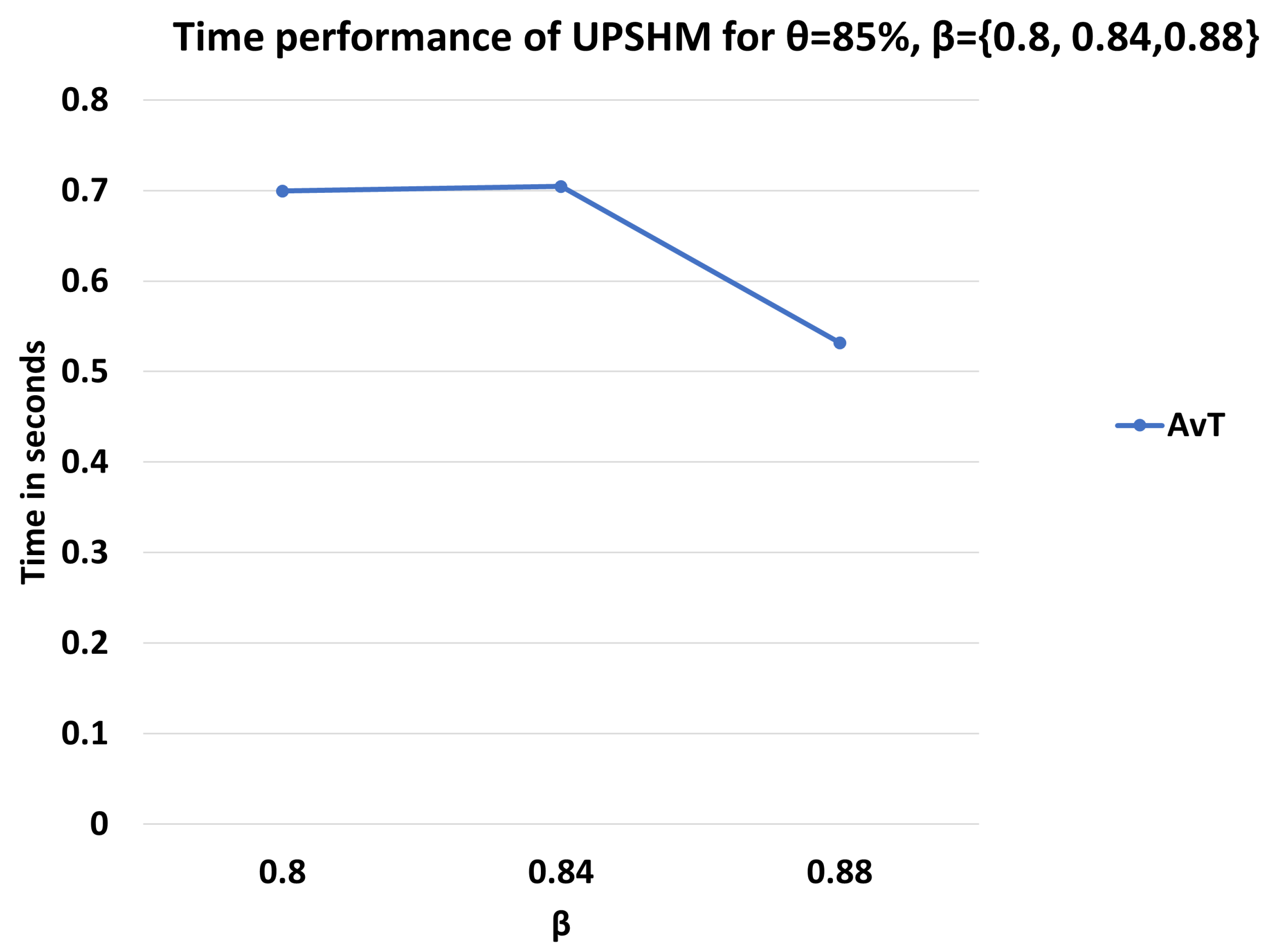
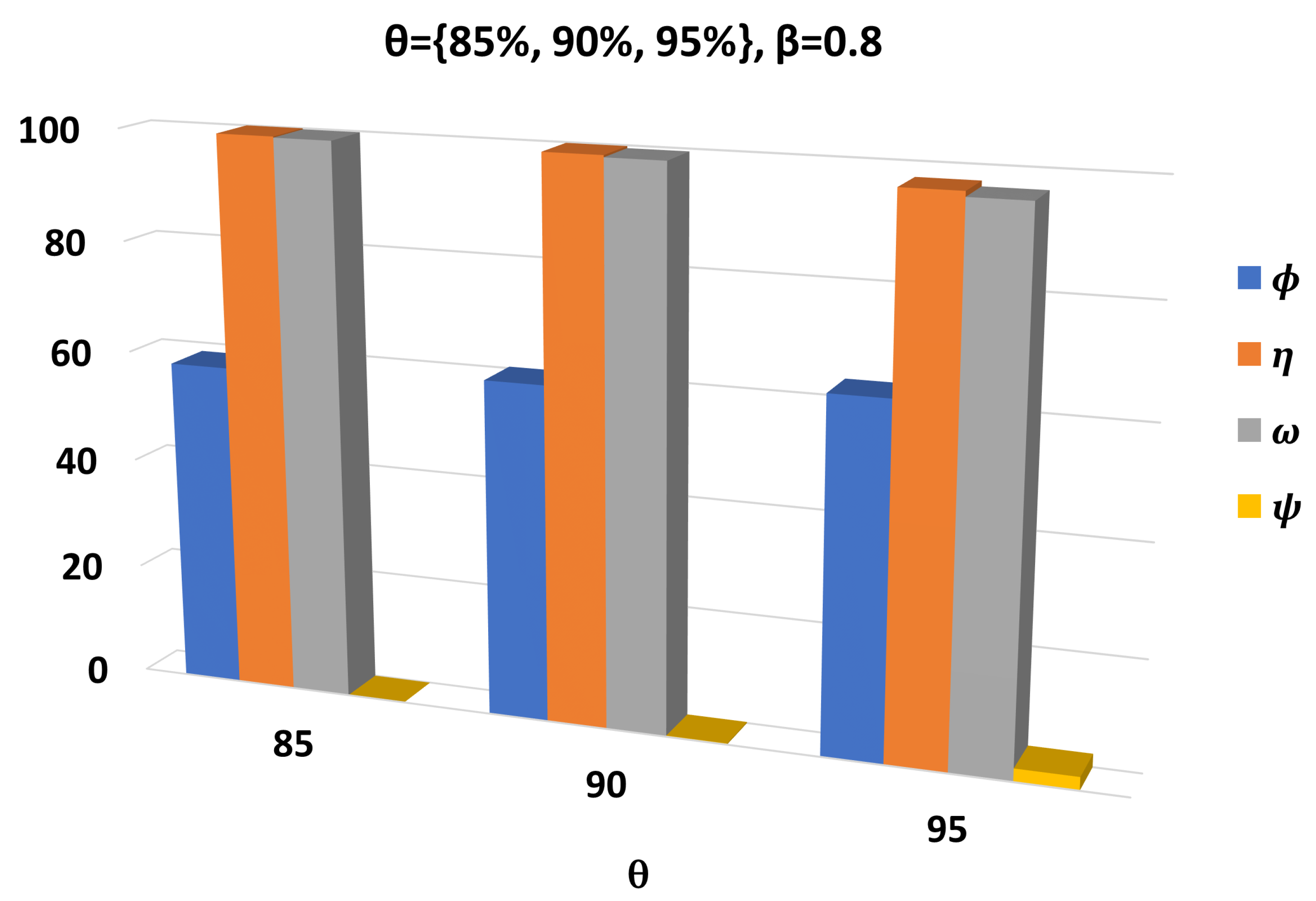
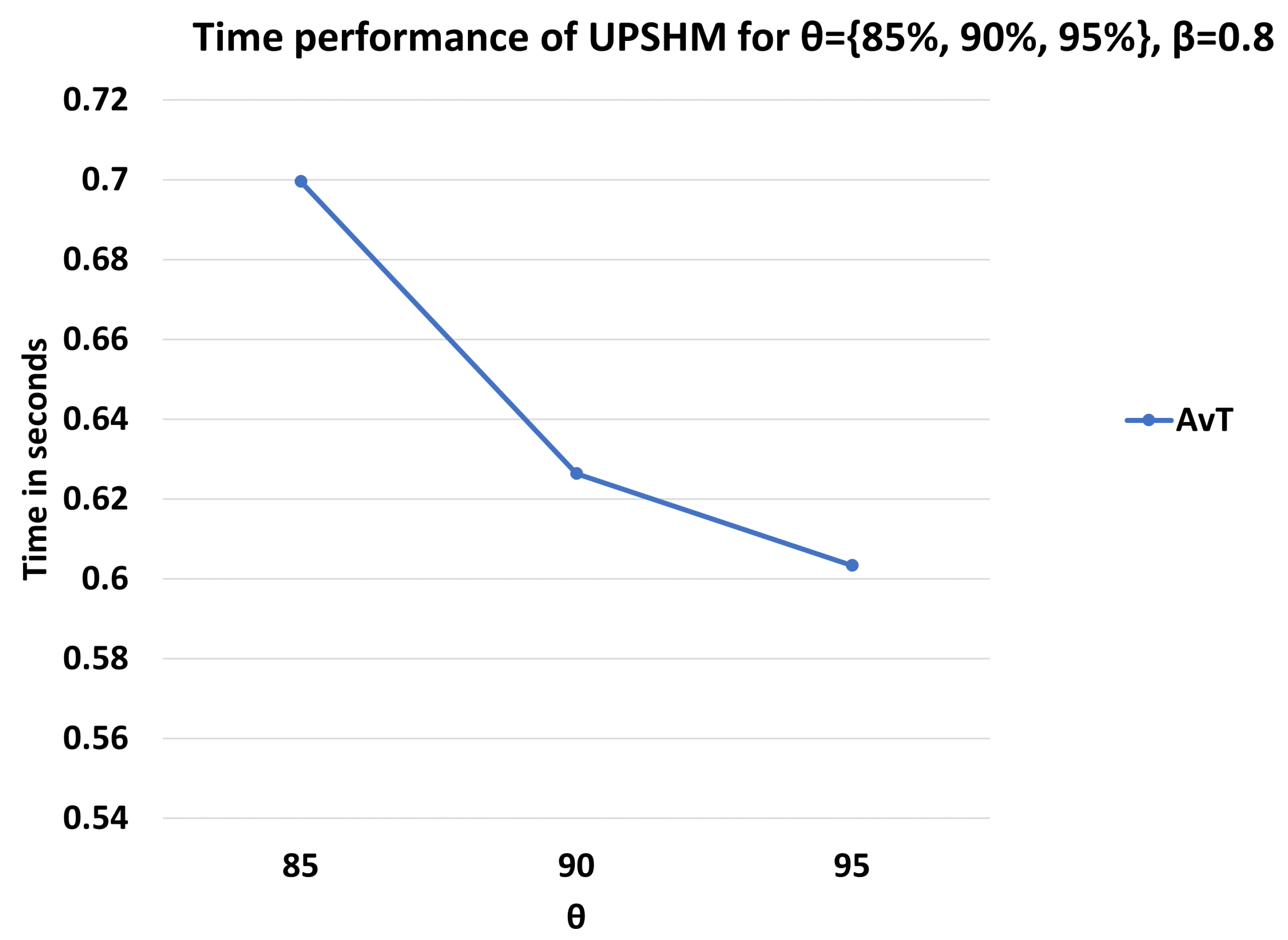
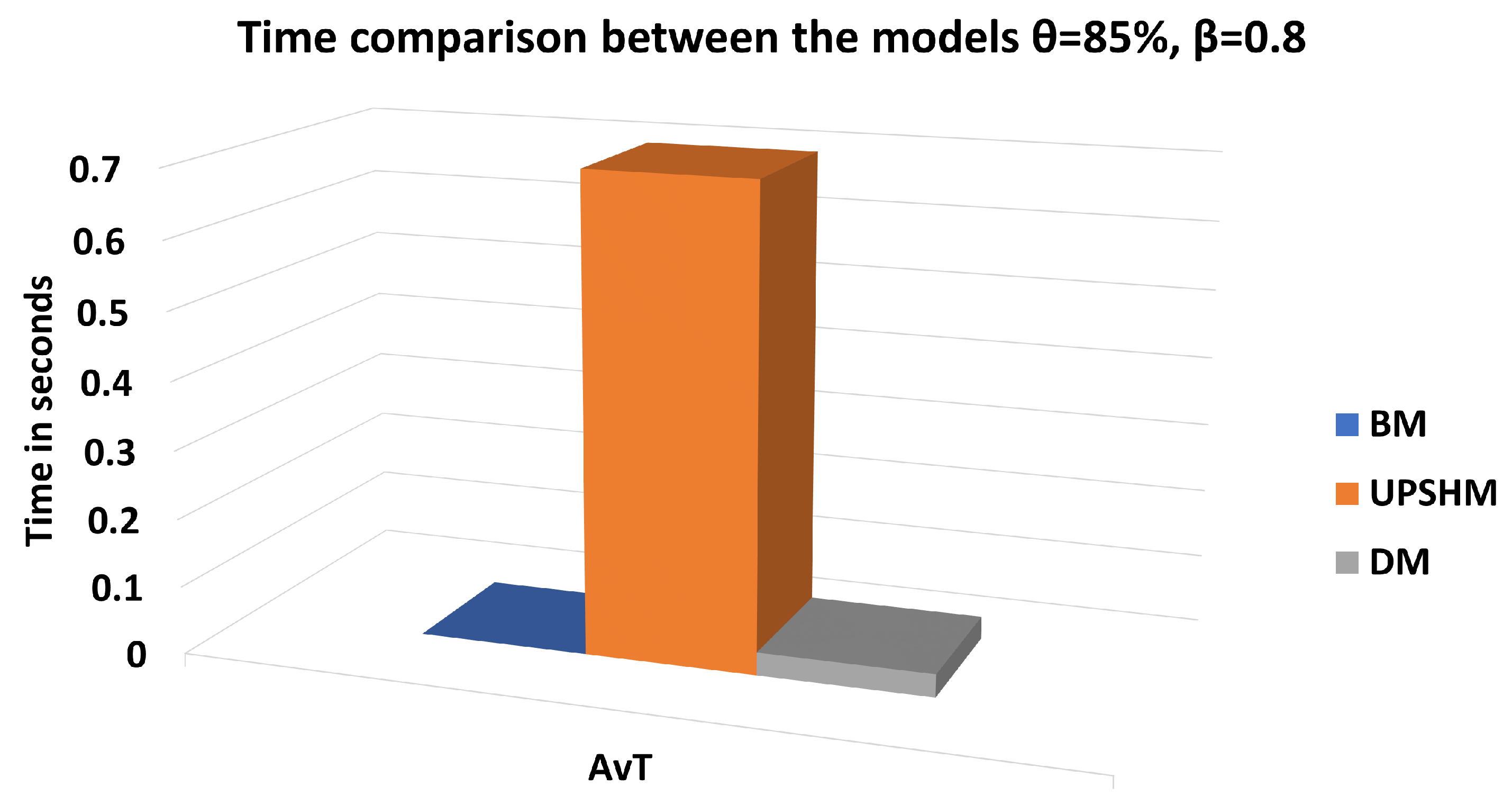
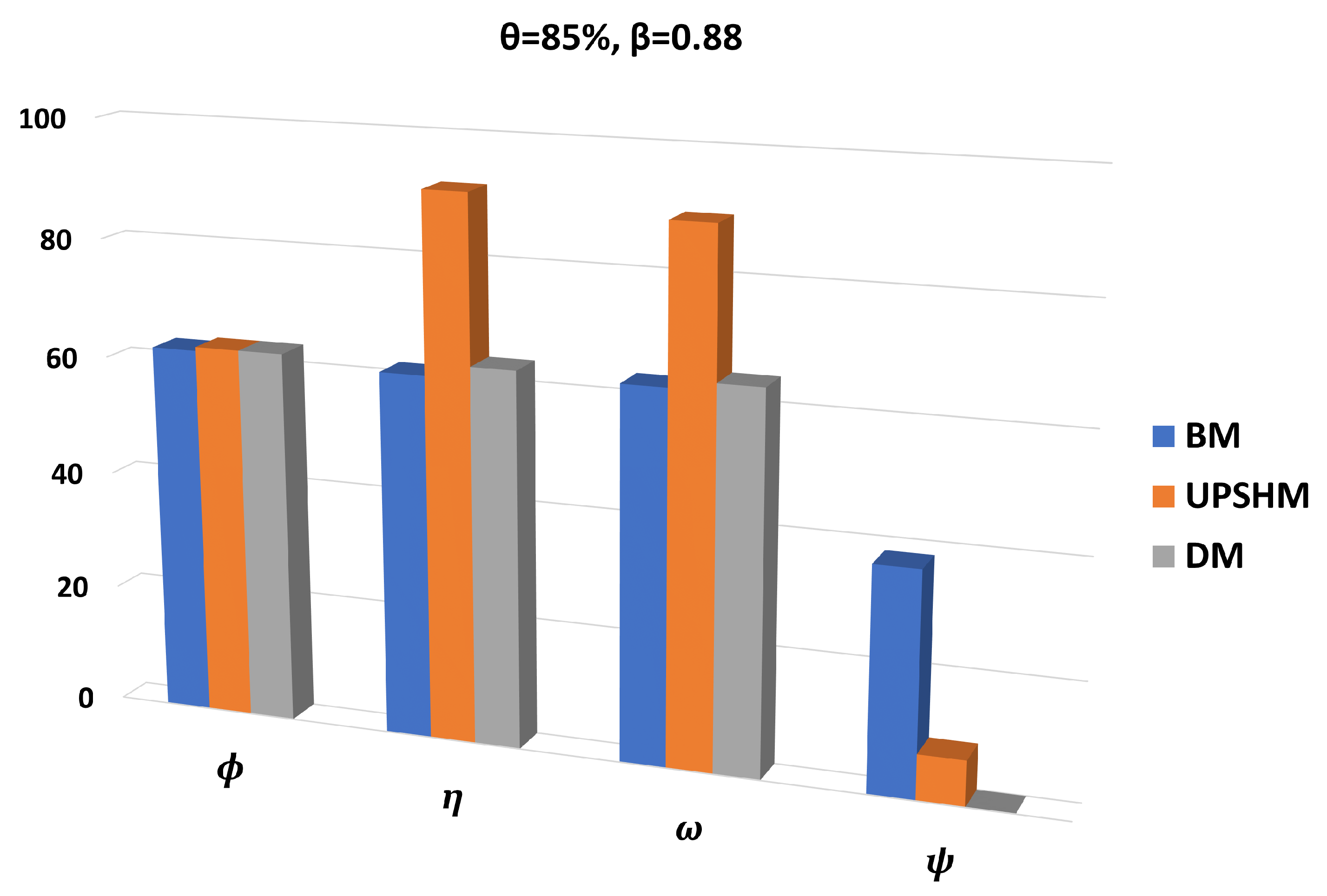
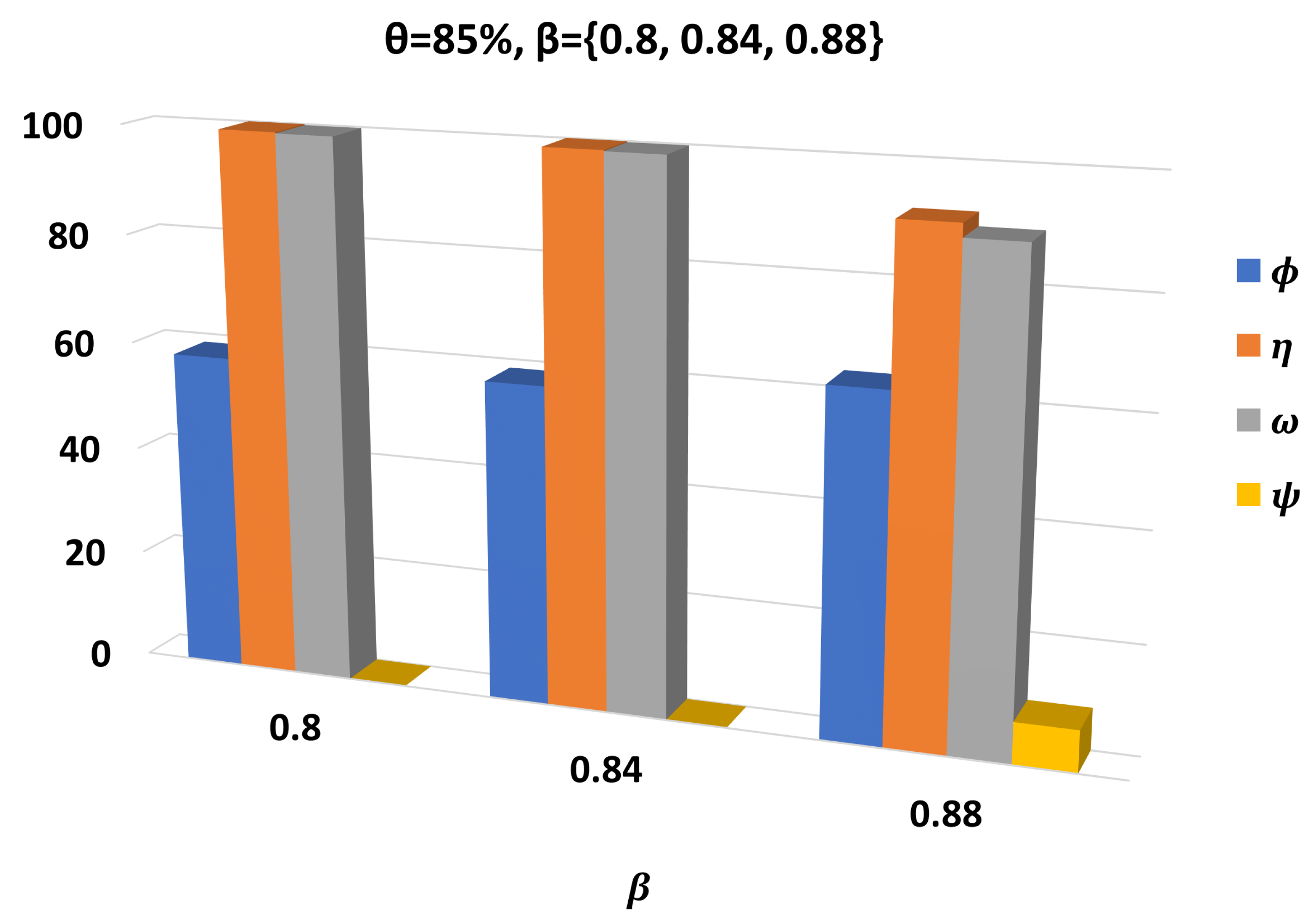
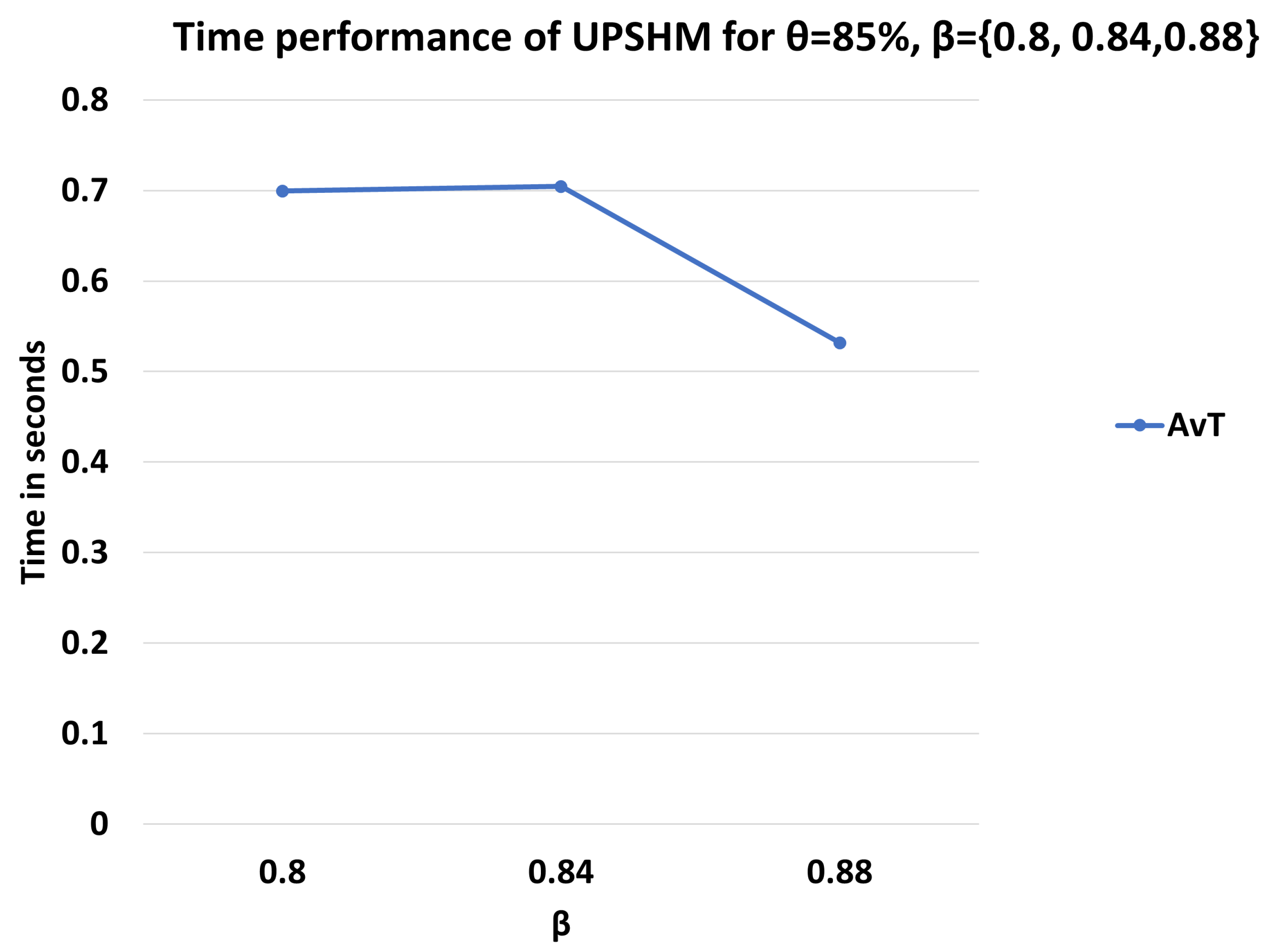
3. Results
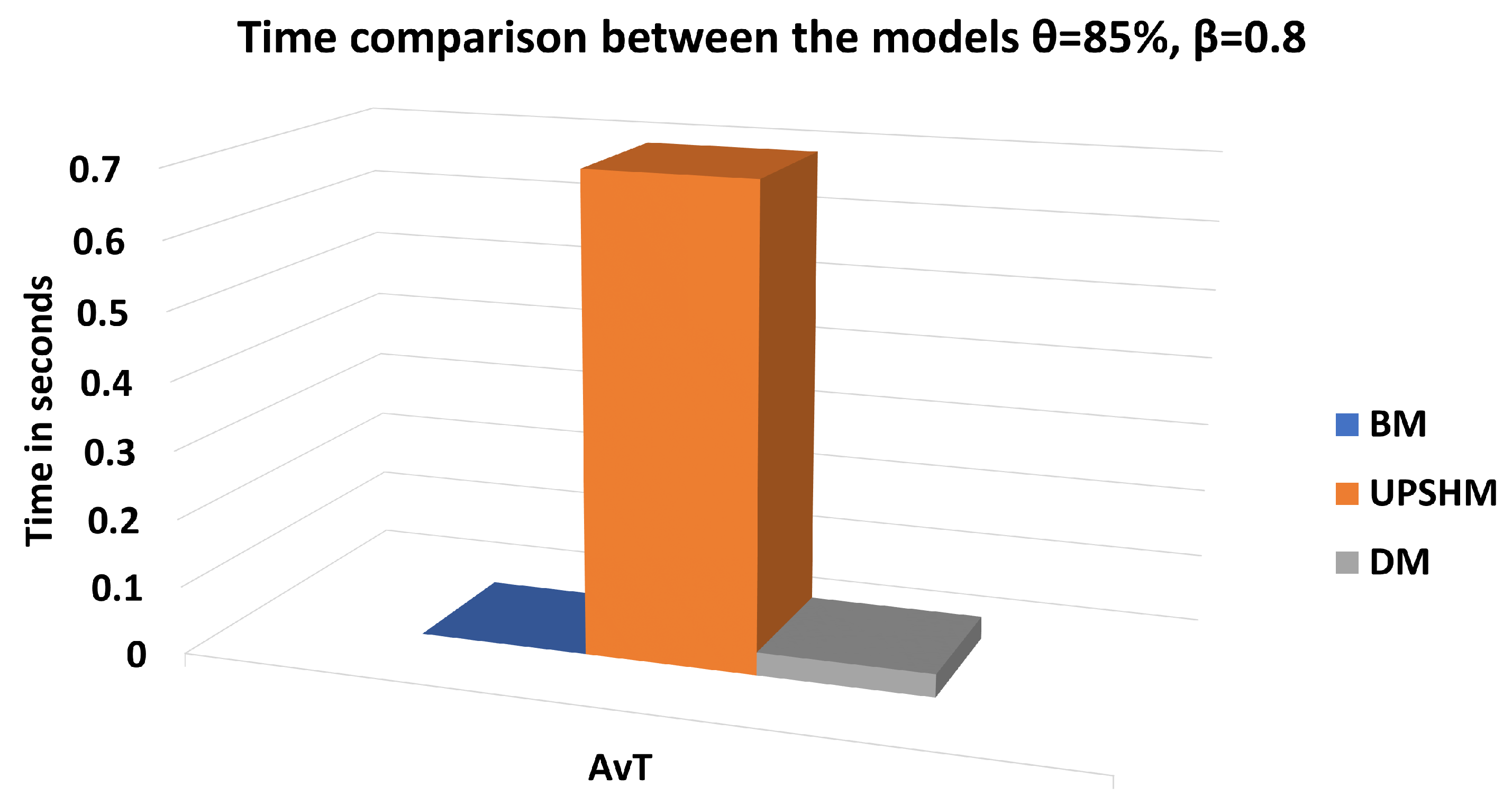
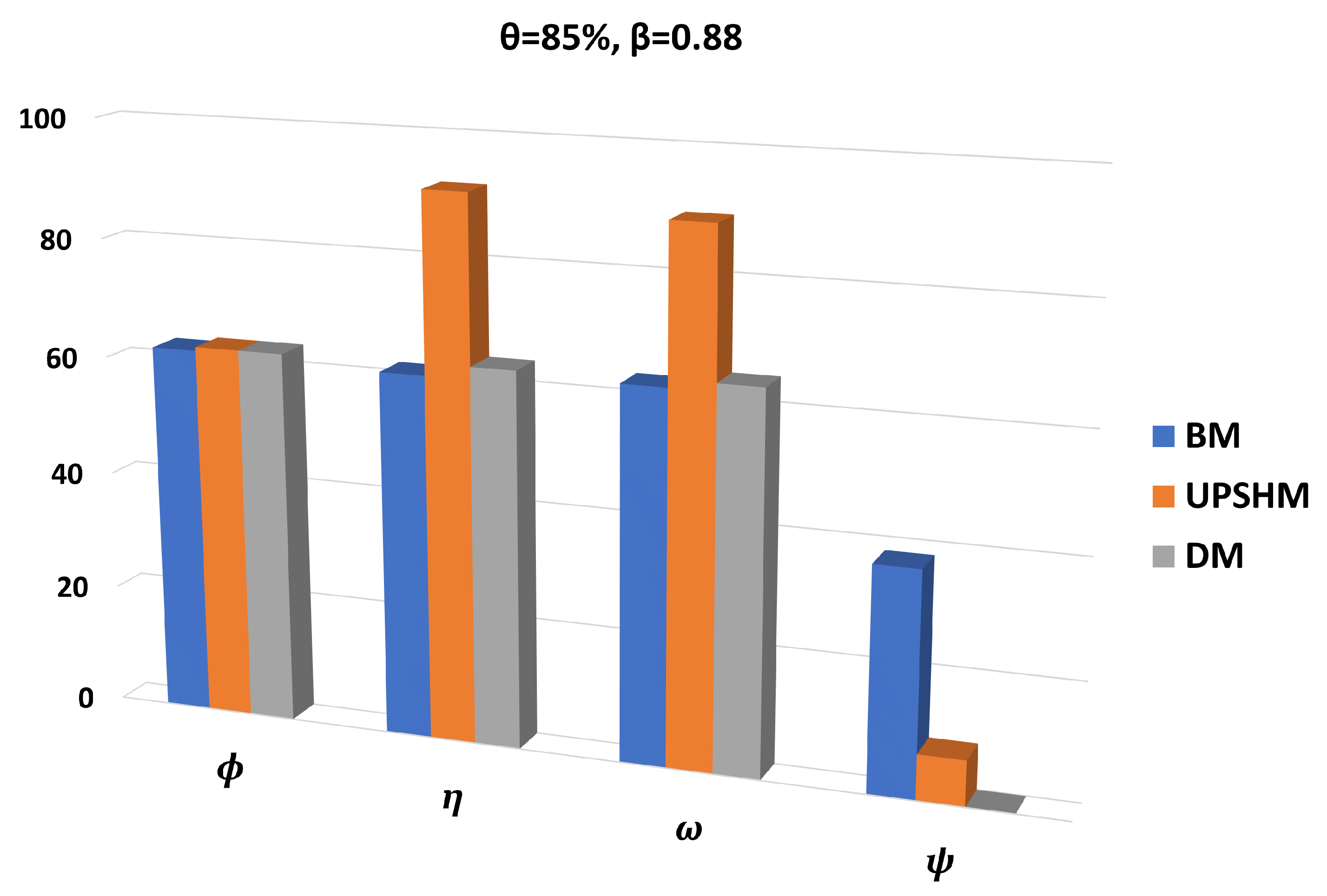
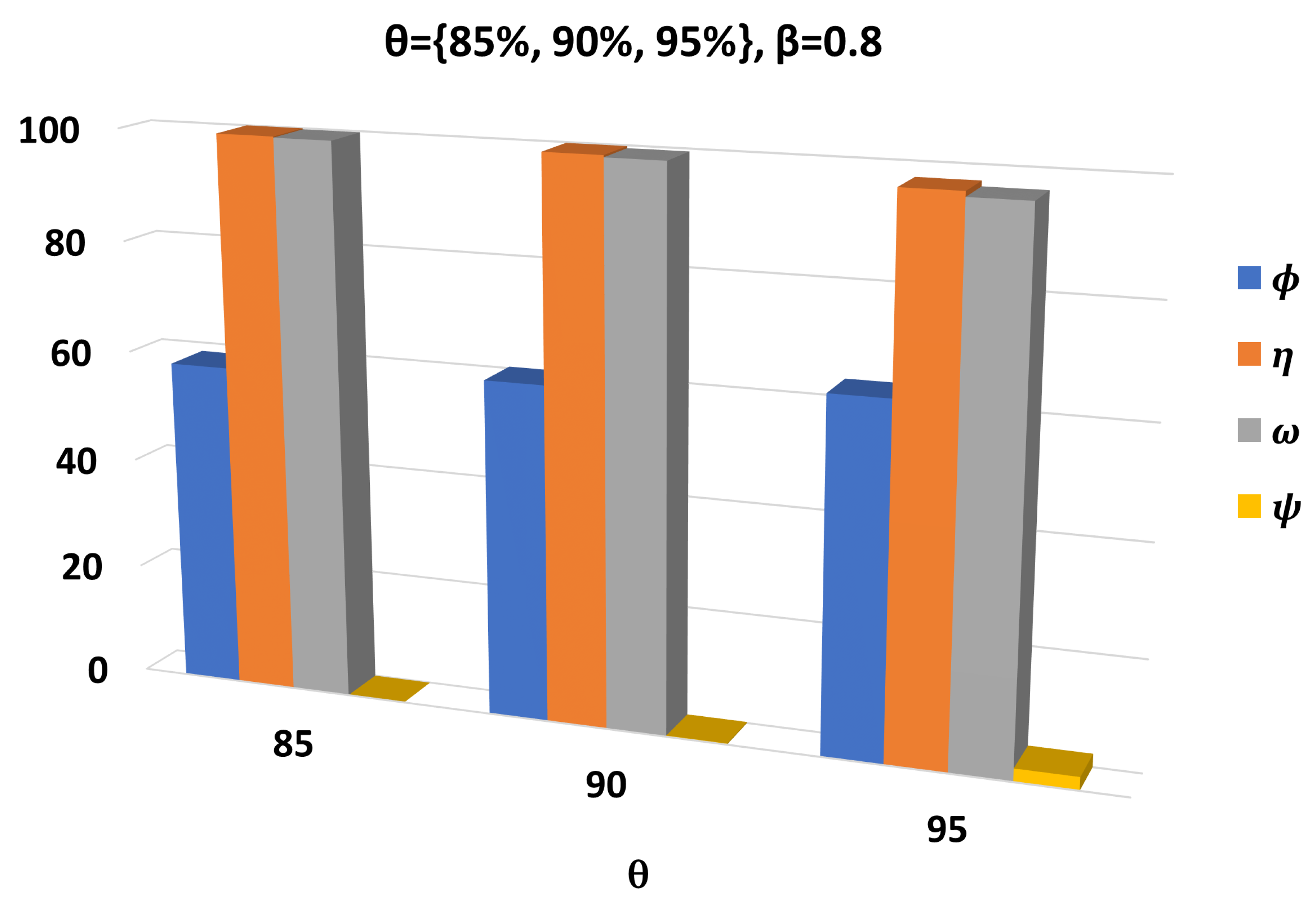
3.1. Setup and Performance Metrics
3.2. Performance Assessment
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AvT | Average Time for Offloading Decision |
| BM | Baseline Model |
| FCFS | First-Come-First-Served |
| FL | Fuzzy Logic |
| FRs | Fuzzy Rules |
| OI | Overlad Indicator |
| Probability Density Function | |
| PMF | Probability Mass Function |
| QoS | Quality of Service |
| UPSHM | Uncertainty-driven Proactive Self-Healing Model |
References
- Yastrebova, A.; Kirichek, R.; Koucheryavy, Y.; Borodin, A.; Koucheryavy, A. Future networks 2030: Architecture & requirements. In Proceedings of the 2018 10th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Moscow, Russia, 5–9 November 2018; pp. 1–8. [Google Scholar]
- Di Crescenzo, A.; Giorno, V.; Kumar, B.K.; Nobile, A.G. M/M/1 queue in two alternating environments and its heavy traffic approximation. J. Math. Anal. Appl. 2018, 465, 973–1001. [Google Scholar] [CrossRef]
- Saia, J.; Trehan, A. Picking up the pieces: Self-healing in reconfigurable networks. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; pp. 1–12. [Google Scholar]
- Tang, M.; Wong, V.W. Deep reinforcement learning for task offloading in mobile edge computing systems. IEEE Trans. Mob. Comput. 2020, 21, 1985–1997. [Google Scholar] [CrossRef]
- Almutairi, J.; Aldossary, M. A novel approach for IoT tasks offloading in edge-cloud environments. J. Cloud Comput. 2021, 10, 1–19. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.; Nouri, N.A.; Dhelim, S.; Ning, H. A novel framework for mobile-edge computing by optimizing task offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J.; Lv, J. Toward intelligent task offloading at the edge. IEEE Netw. 2019, 34, 128–134. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Vu, T.T.; Van Huynh, N.; Hoang, D.T.; Nguyen, D.N.; Dutkiewicz, E. Offloading energy efficiency with delay constraint for cooperative mobile edge computing networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Ni, W.; Tian, H.; Lyu, X.; Fan, S. Service-dependent task offloading for multiuser mobile edge computing system. Electron. Lett. 2019, 55, 839–841. [Google Scholar] [CrossRef]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task offloading and resource allocation for mobile edge computing by deep reinforcement learning based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Alghamdi, I.; Anagnostopoulos, C.; Pezaros, D.P. On the optimality of task offloading in mobile edge computing environments. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Alghamdi, I.; Anagnostopoulos, C.; Pezaros, D.P. Time-optimized task offloading decision making in mobile edge computing. In Proceedings of the 2019 Wireless Days (WD), Manchester, UK, 24–26 April 2019; pp. 1–8. [Google Scholar]
- Alghamdi, I.; Anagnostopoulos, C.; Pezaros, D.P. Optimized Contextual Data Offloading in Mobile Edge Computing. In Proceedings of the 2021 IFIP/IEEE International Symposium on Integrated Network Management (IM), Bordeaux, France, 17–21 May 2021; pp. 473–479. [Google Scholar]
- Alghamdi, I.; Anagnostopoulos, C.; Pezaros, D.P. Data quality-aware task offloading in mobile edge computing: An optimal stopping theory approach. Future Gener. Comput. Syst. 2021, 117, 462–479. [Google Scholar] [CrossRef]
- Kan, T.Y.; Chiang, Y.; Wei, H.Y. Task offloading and resource allocation in mobile-edge computing system. In Proceedings of the 2018 27th wireless and optical communication conference (WOCC), Hualien, Taiwan, 30 April–1 May 2018; pp. 1–4. [Google Scholar]
- Shi, J.; Du, J.; Wang, J.; Wang, J.; Yuan, J. Priority-aware task offloading in Vehicular Fog Computing based on deep reinforcement learning. IEEE Trans. Veh. Technol. 2020, 69, 16067–16081. [Google Scholar] [CrossRef]
- Sztrik, J. Basic Queueing Theory; University of Debrecen, Faculty of Informatics: Debrecen, Hungary, 2012; Volume 193, pp. 60–67. [Google Scholar]
- Bhat, U.N. An Introduction to Queueing Theory: Modeling and Analysis in Applications; Springer: Berlin/Heidelberg, Germany, 2008; Volume 36. [Google Scholar]
- Kolomvatsos, K.; Anagnostopoulos, C. A Proactive Statistical Model Supporting Services and Tasks Management in Pervasive Applications. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3020–3031. [Google Scholar] [CrossRef]
- Soula, M.; Karanika, A.; Kolomvatsos, K.; Anagnostopoulos, C.; Stamoulis, G. Intelligent tasks allocation at the edge based on machine learning and bio-inspired algorithms. Evol. Syst. 2022, 13, 221–242. [Google Scholar] [CrossRef]
- Kolomvatsos, K. Data-Driven Type-2 Fuzzy Sets for Tasks Management at the Edge. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 377–386. [Google Scholar] [CrossRef]
- Kolomvatsos, K. Proactive tasks management for pervasive computing applications. J. Netw. Comput. Appl. 2021, 176, 102948. [Google Scholar] [CrossRef]
- Kolomvatsos, K.; Anagnostopoulos, C. Multi-criteria optimal task allocation at the edge. Future Gener. Comput. Syst. 2019, 93, 358–372. [Google Scholar] [CrossRef] [Green Version]
- Fountas, P.; Kolomvatsos, K.; Anagnostopoulos, C. A Deep Learning Model for Data Synopses Management in Pervasive Computing Applications. In Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 619–636. [Google Scholar]
- Muñoz-Pichardo, J.M.; Lozano-Aguilera, E.D.; Pascual-Acosta, A.; Muñoz-Reyes, A.M. Multiple Ordinal Correlation Based on Kendall’s Tau Measure: A Proposal. Mathematics 2021, 9, 1616. [Google Scholar] [CrossRef]
- Brossart, D.F.; Laird, V.C.; Armstrong, T.W. Interpreting Kendall’s Tau and Tau-U for single-case experimental designs. Cogent Psychol. 2018, 5, 1518687. [Google Scholar] [CrossRef]
- Karanika, A.; Oikonomou, P.; Kolomvatsos, K.; Loukopoulos, T. A demand-driven, proactive tasks management model at the edge. In Proceedings of the 2020 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Wijayasekara, V.A.; Vekneswaran, P. Decision Making Engine for Task Offloading in On-device Inference Based Mobile Applications. In Proceedings of the 2021 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Toronto, ON, Canada, 21–24 April 2021; pp. 1–6. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papathanasaki, M.; Fountas, P.; Kolomvatsos, K. An Uncertainty-Driven Proactive Self-Healing Model for Pervasive Applications. Network 2022, 2, 568-582. https://doi.org/10.3390/network2040033
Papathanasaki M, Fountas P, Kolomvatsos K. An Uncertainty-Driven Proactive Self-Healing Model for Pervasive Applications. Network. 2022; 2(4):568-582. https://doi.org/10.3390/network2040033
Chicago/Turabian StylePapathanasaki, Maria, Panagiotis Fountas, and Kostas Kolomvatsos. 2022. "An Uncertainty-Driven Proactive Self-Healing Model for Pervasive Applications" Network 2, no. 4: 568-582. https://doi.org/10.3390/network2040033
APA StylePapathanasaki, M., Fountas, P., & Kolomvatsos, K. (2022). An Uncertainty-Driven Proactive Self-Healing Model for Pervasive Applications. Network, 2(4), 568-582. https://doi.org/10.3390/network2040033