


Towards Software-Defined Delay Tolerant Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Delay Tolerant Networking Background
2.1. DTN Overview
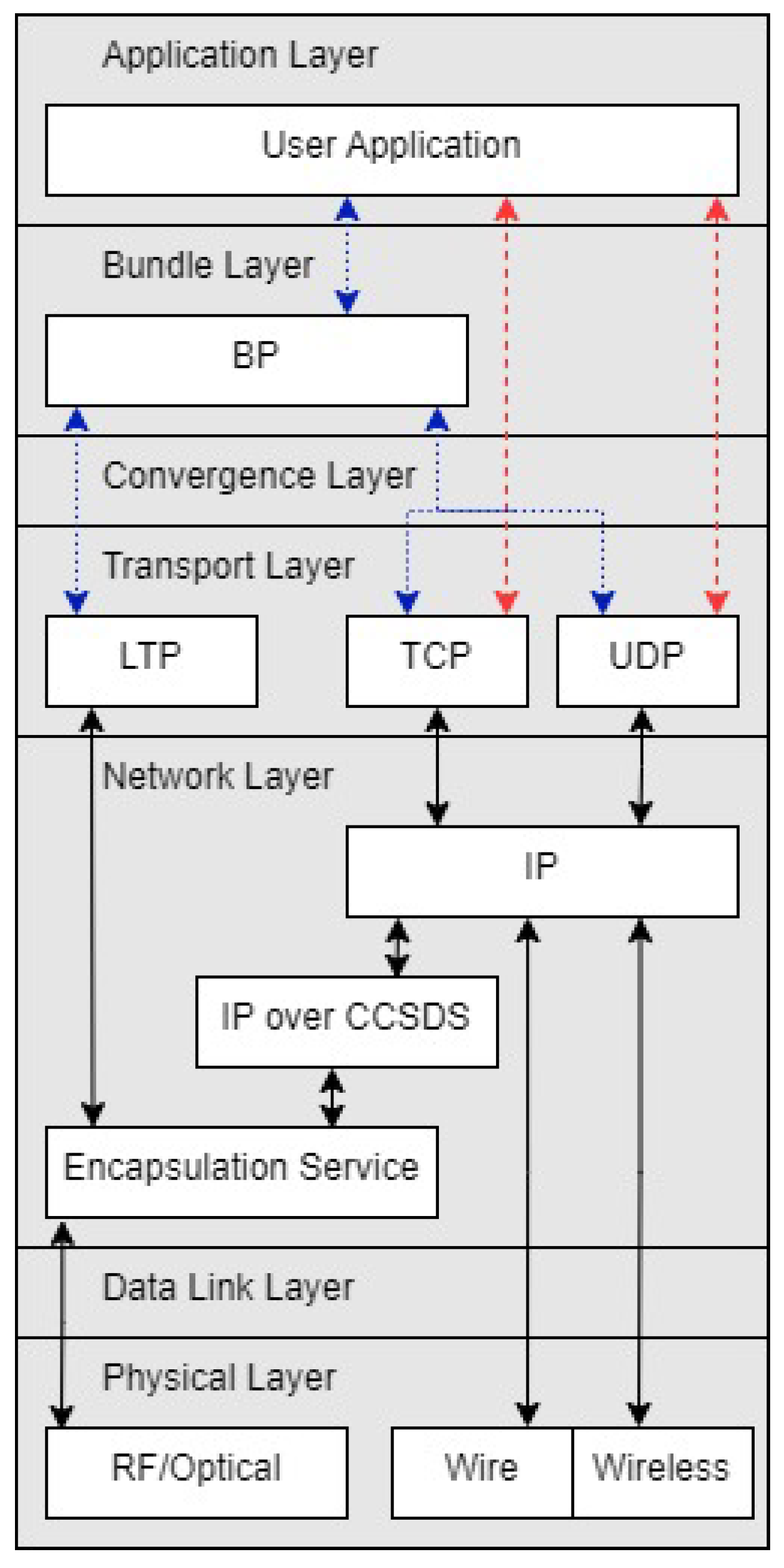
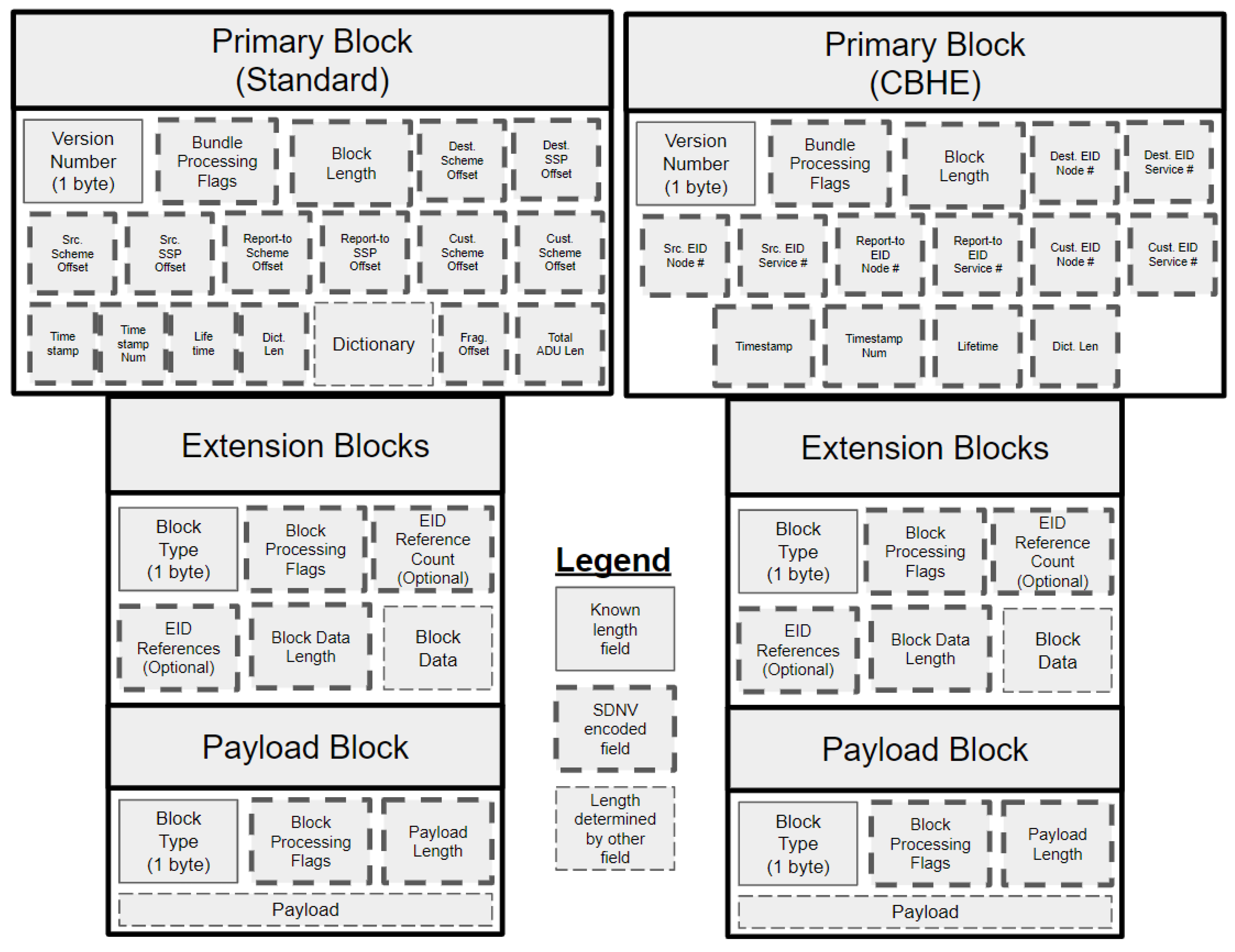
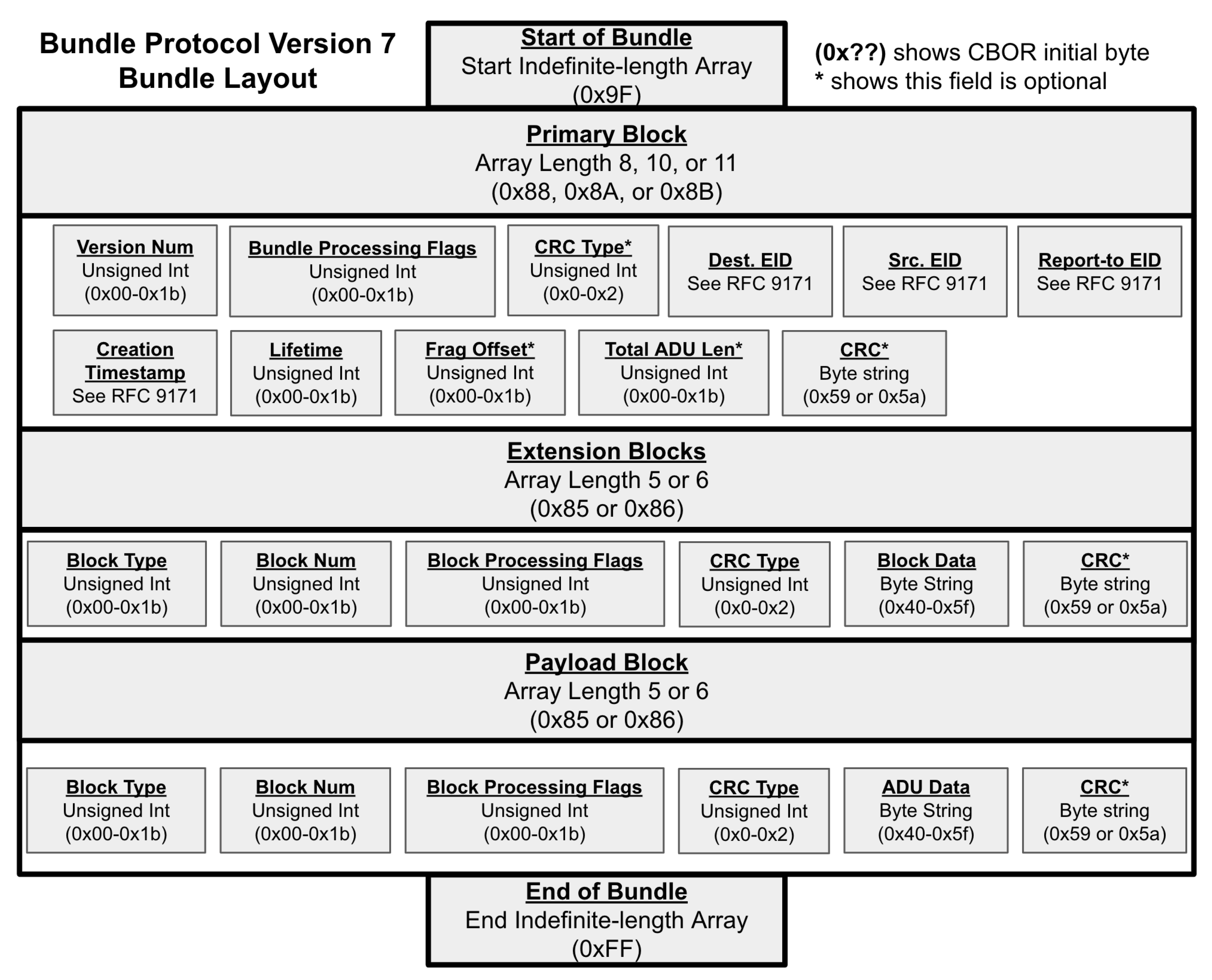
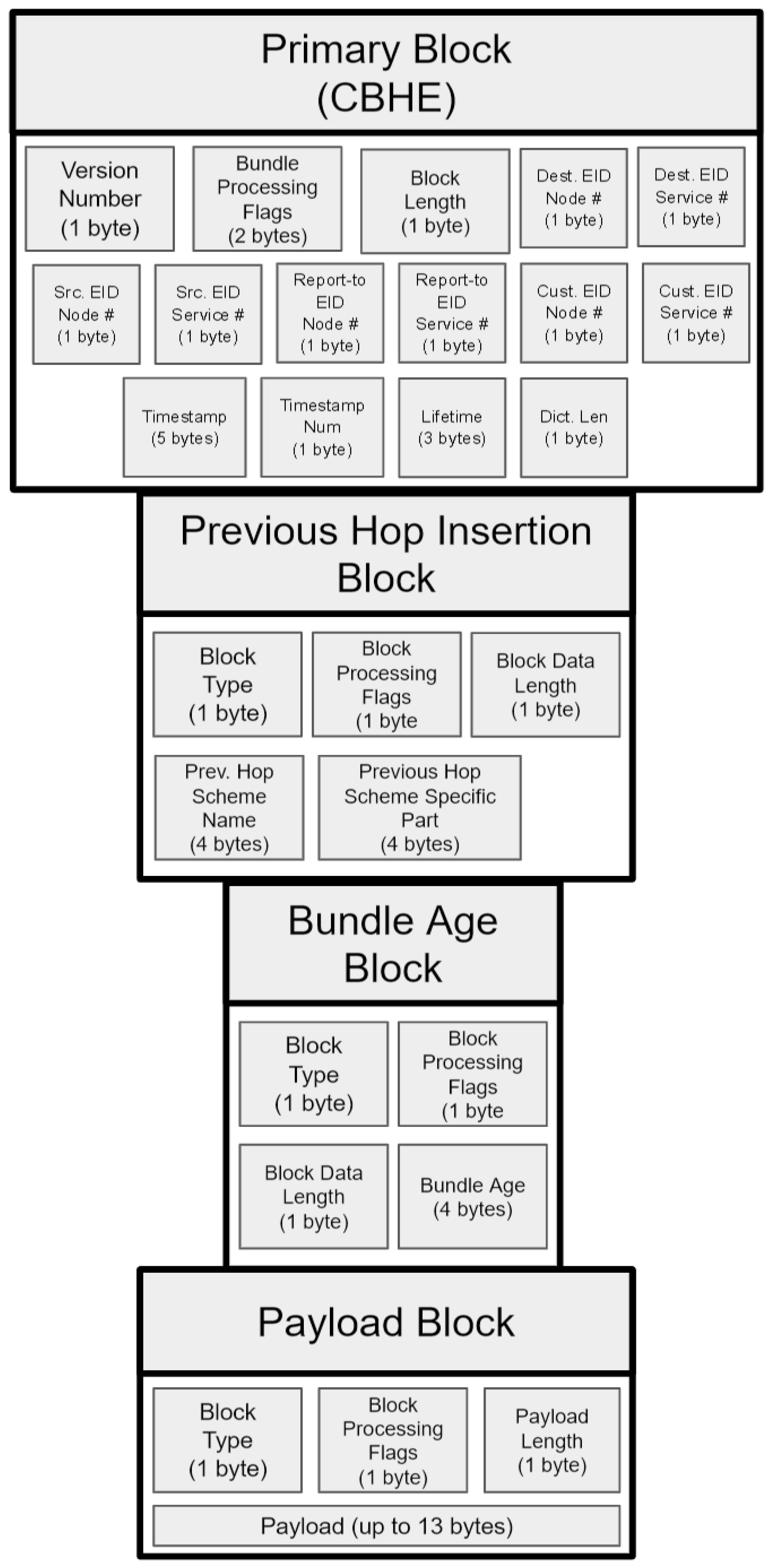
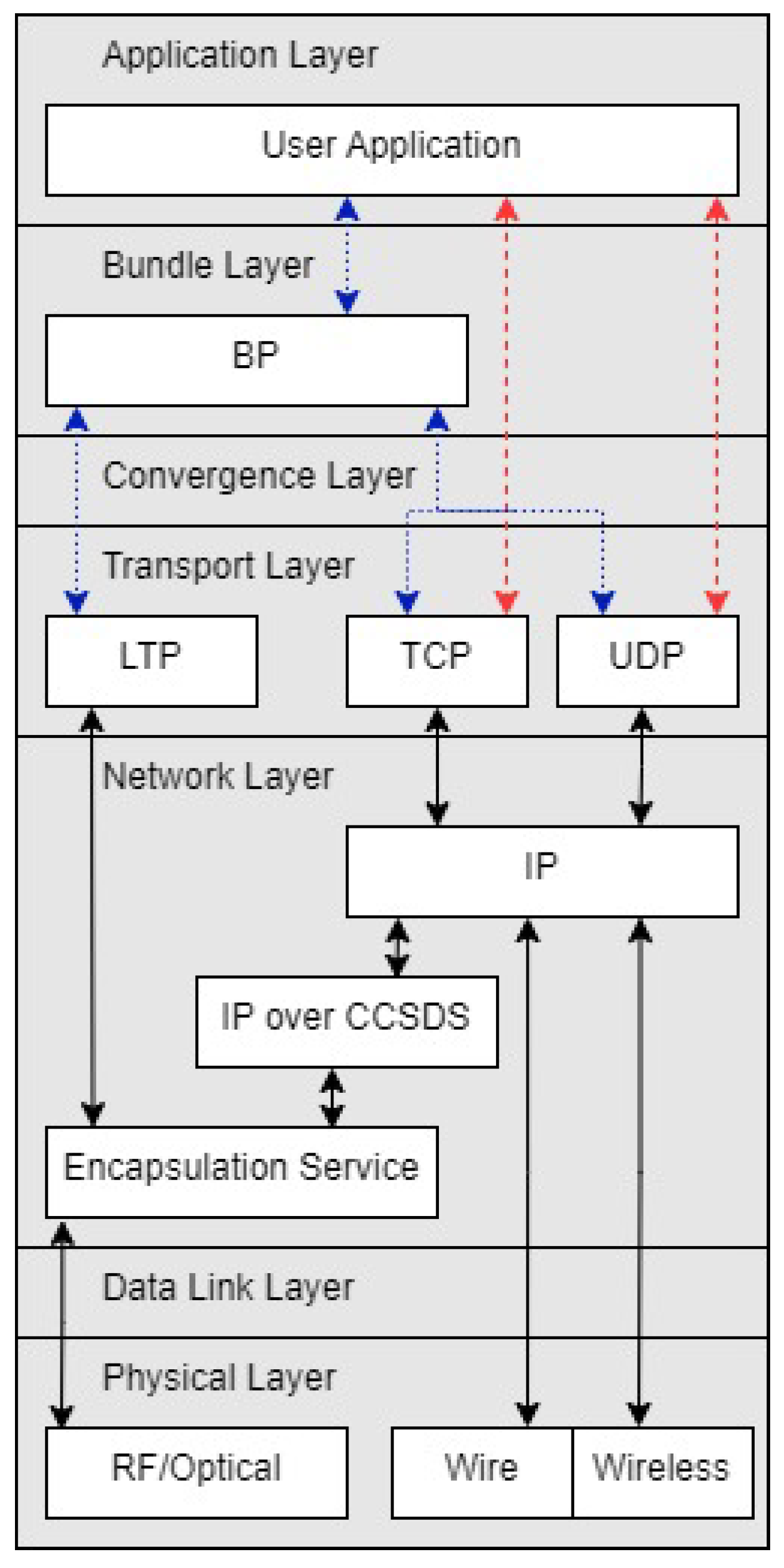
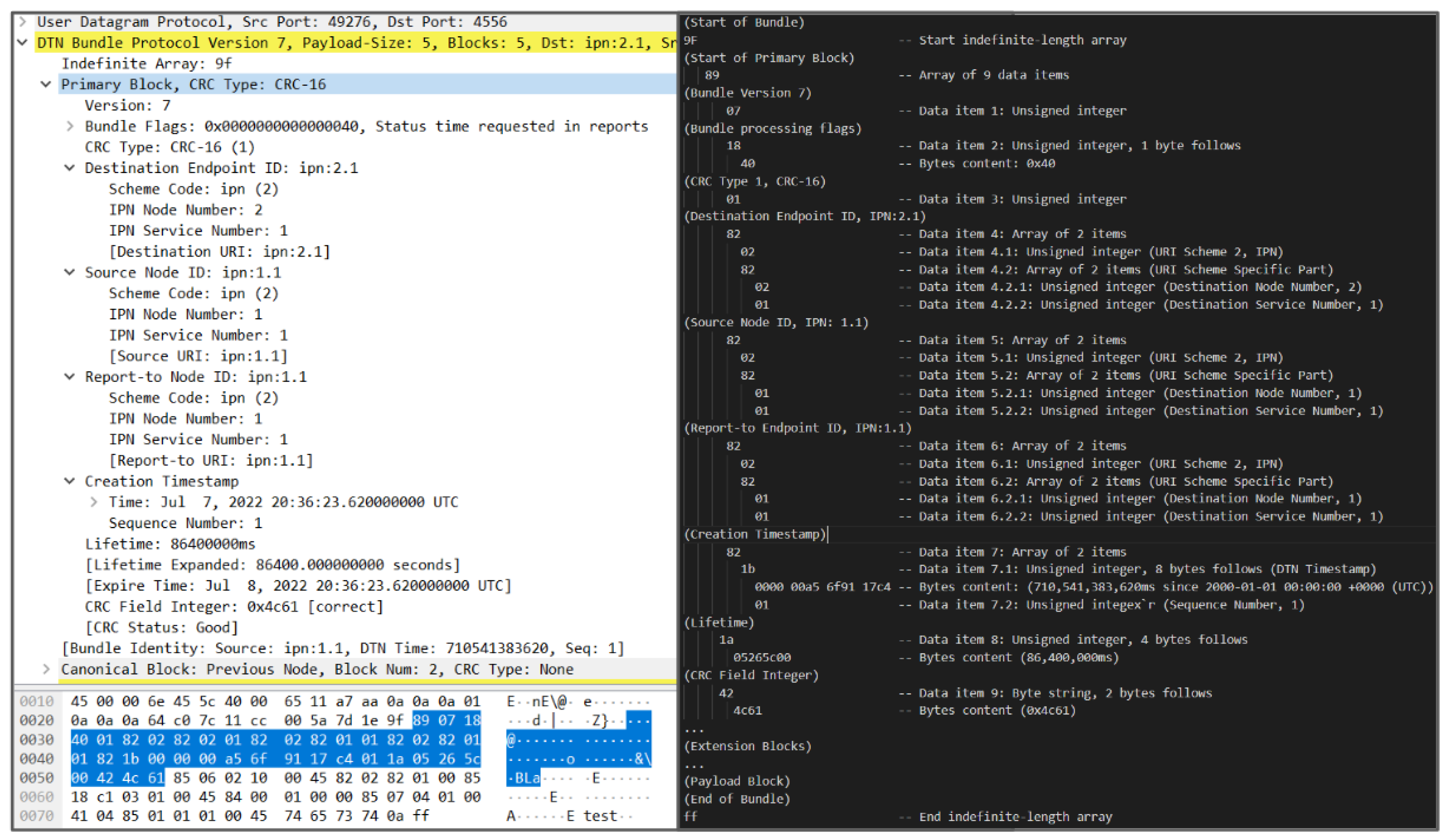
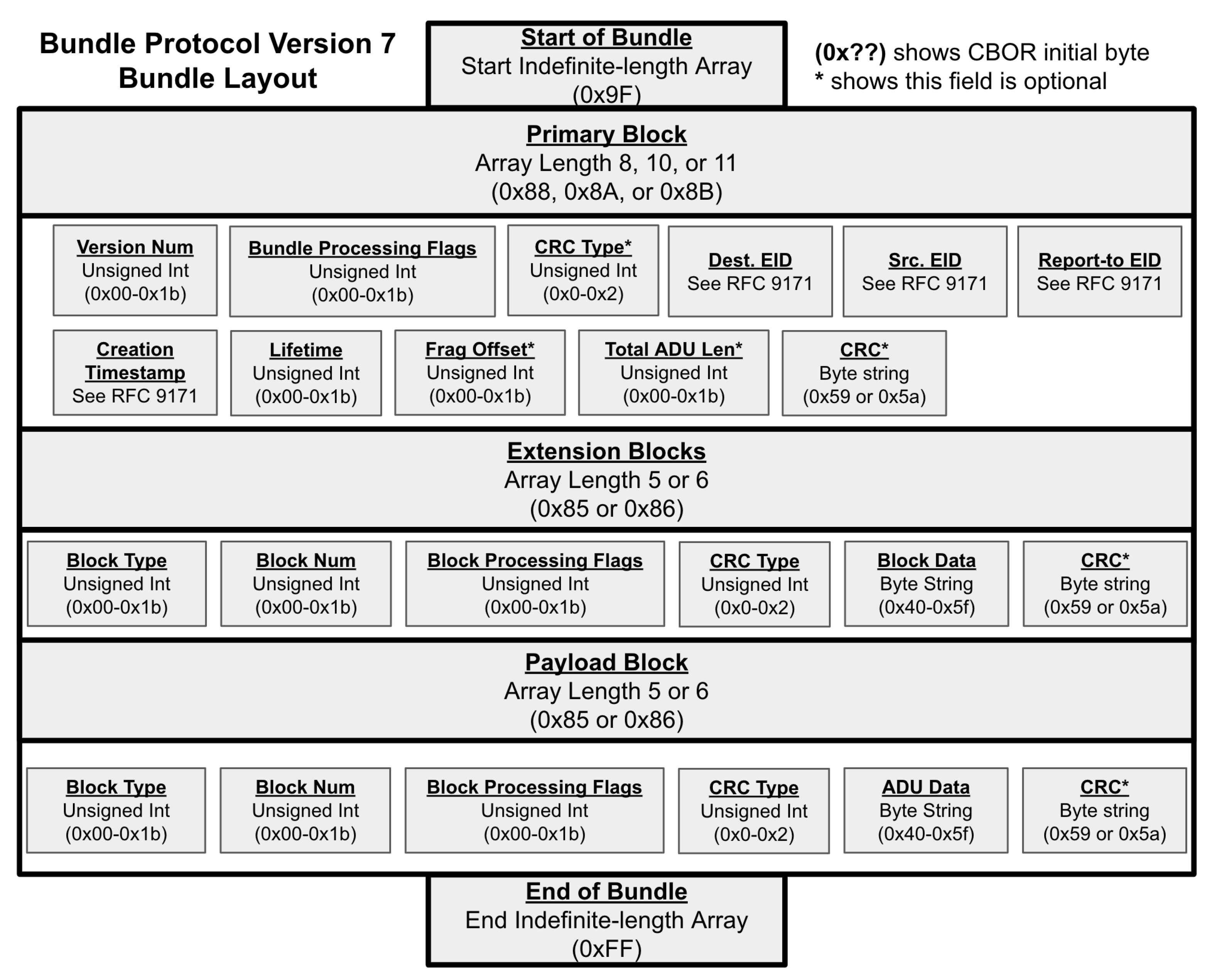
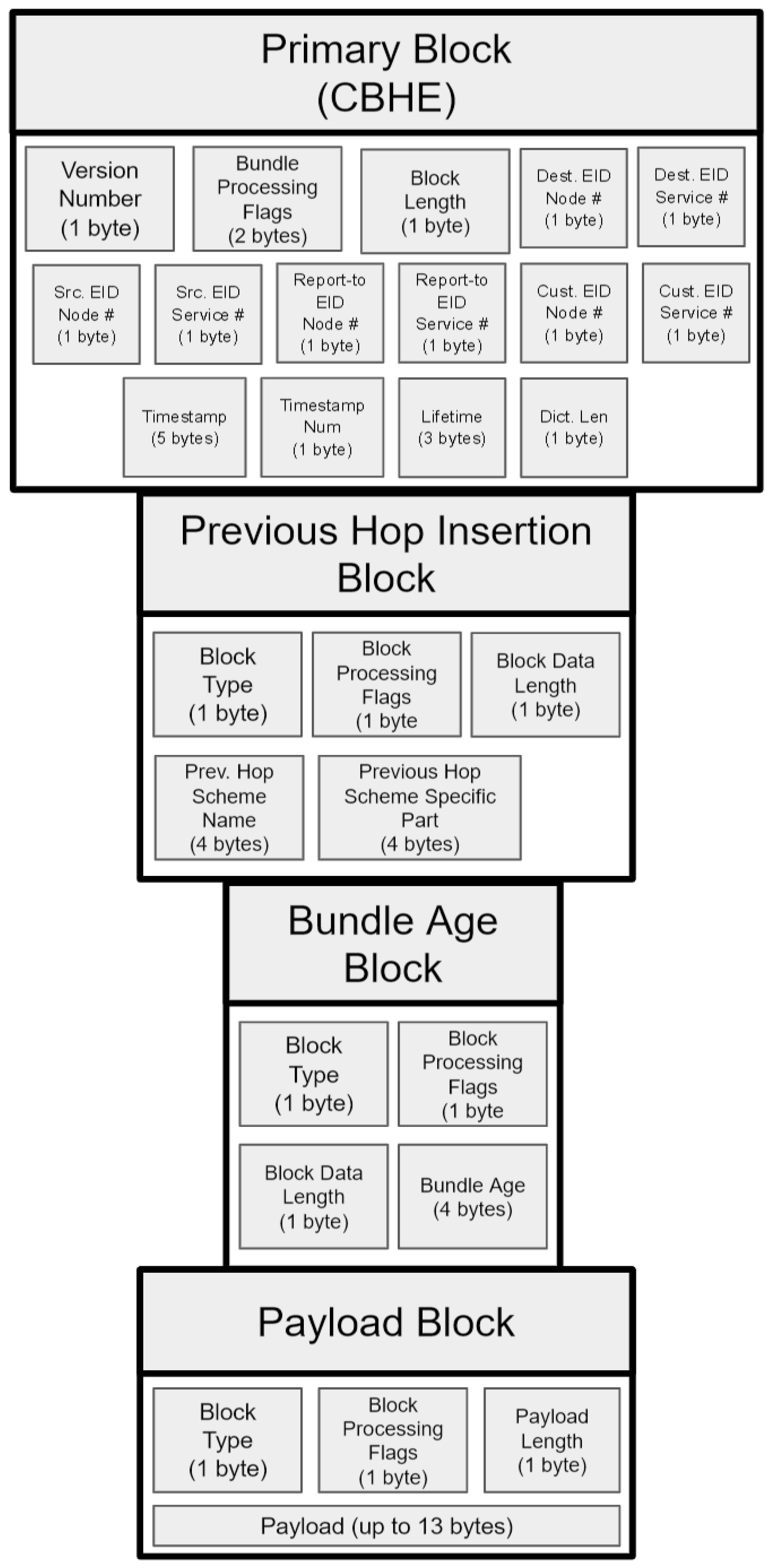
2.2. Bundle Protocol
2.3. Space DTN Routing and Scalability
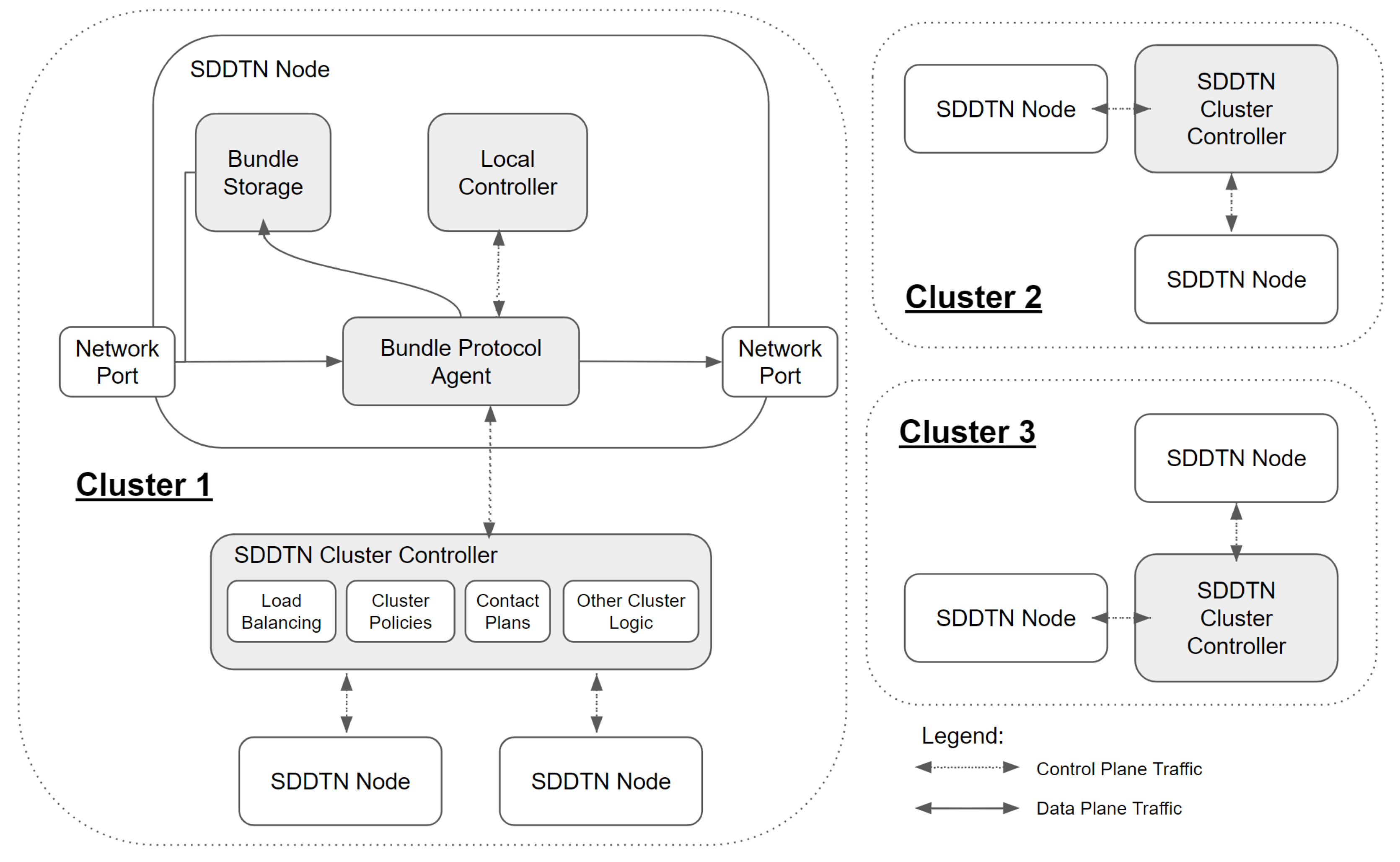
3. Software-Defined Delay Tolerant Networking Architecture
4. Proof-of-Concept Background and Setup
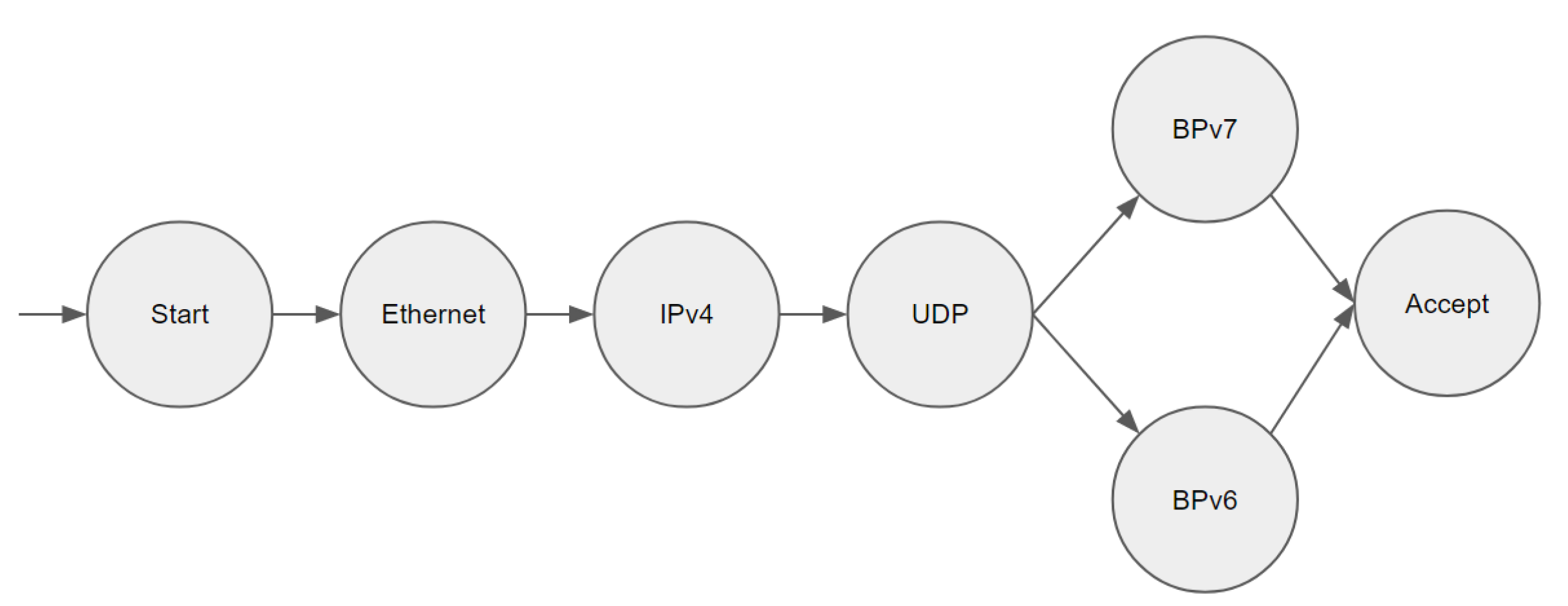
4.1. Programmable Data Planes and P4
4.2. Proof-of-Concept Motivation
4.3. Development Setup
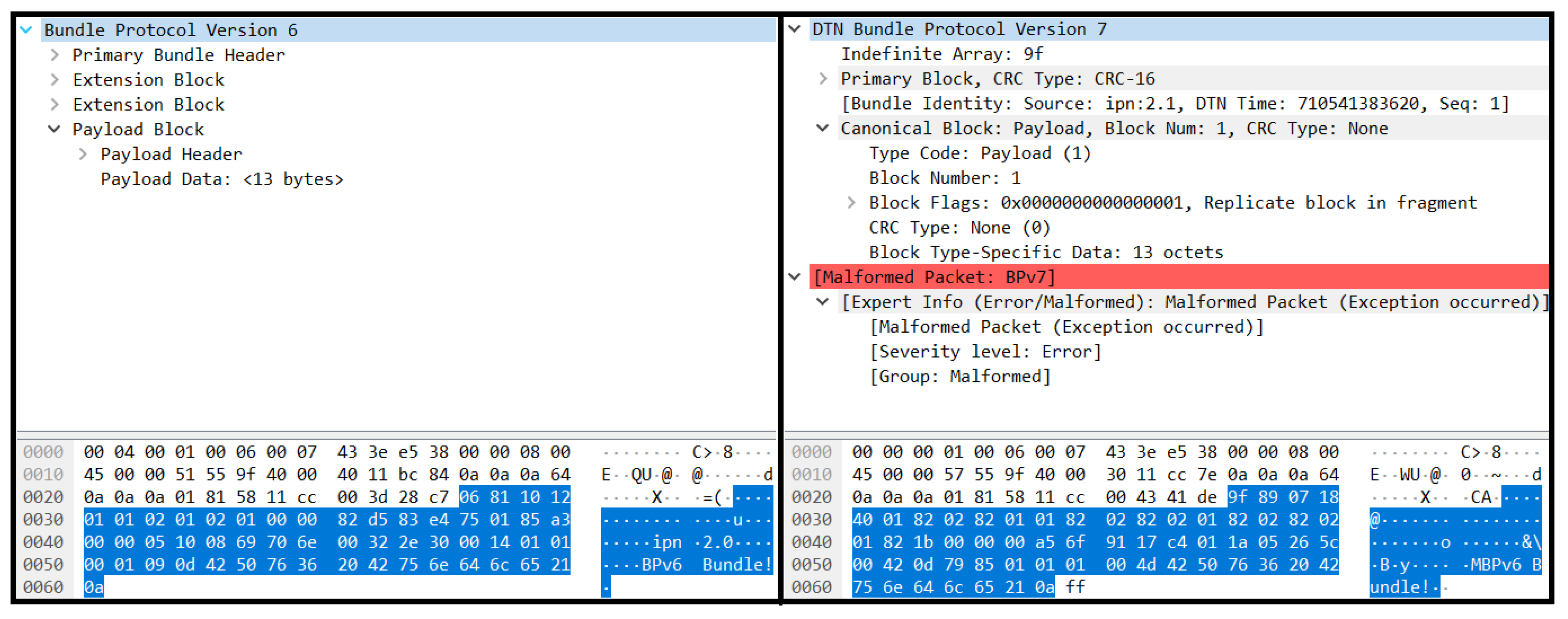
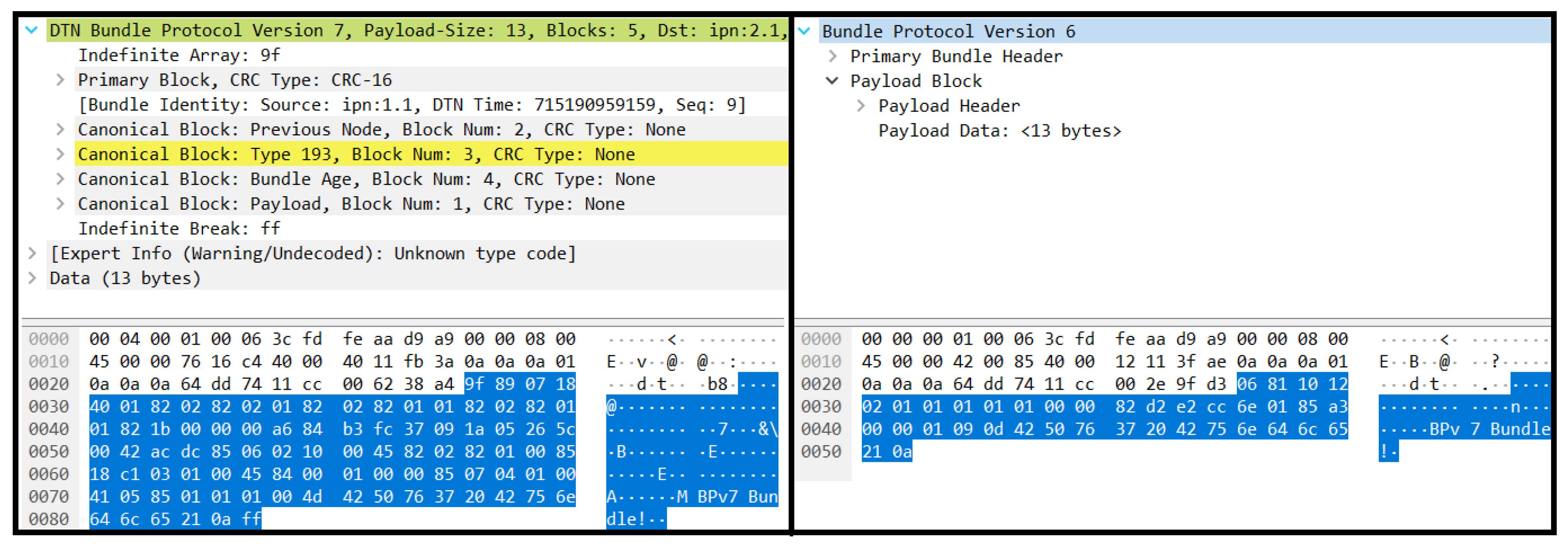
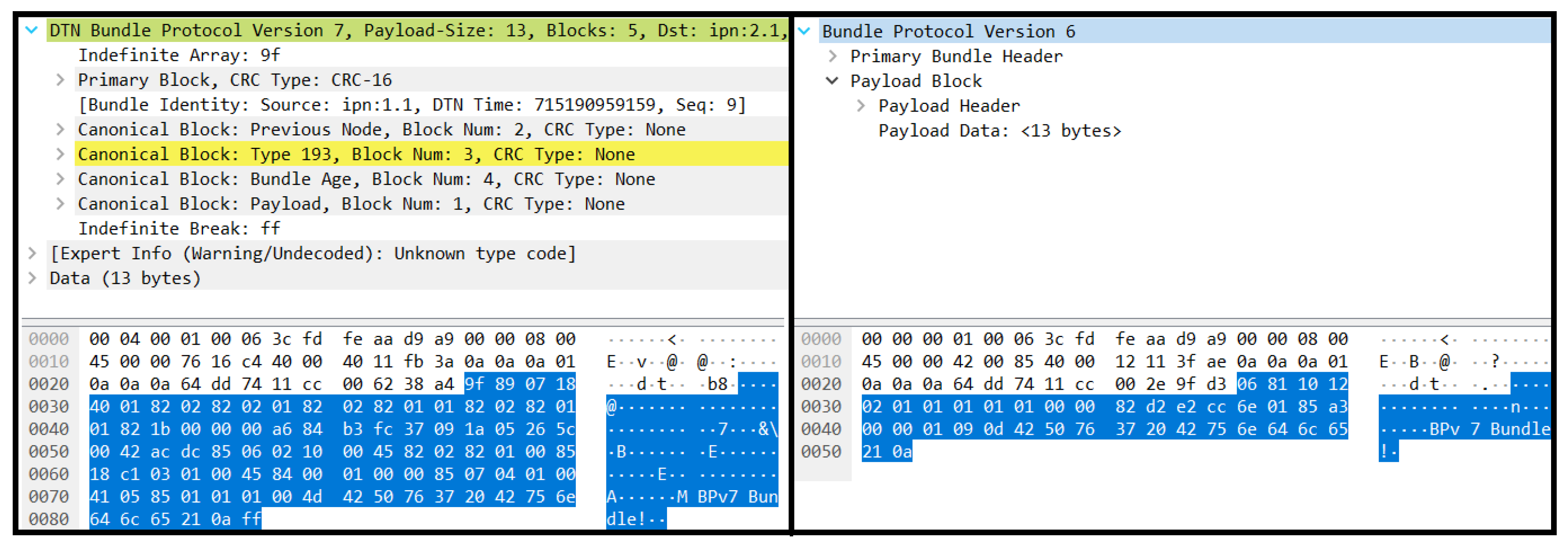
5. Proof-of-Concept Results
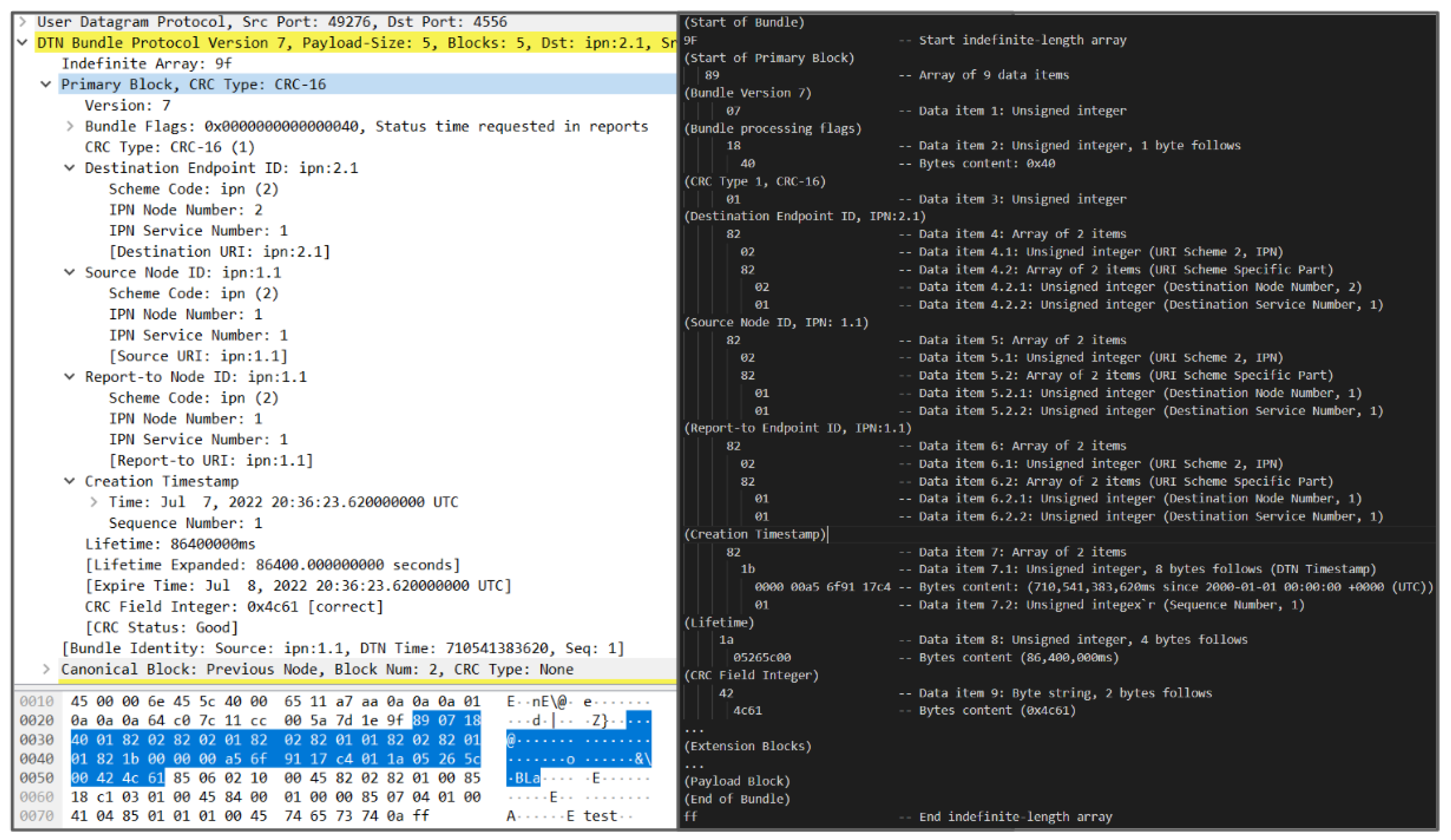
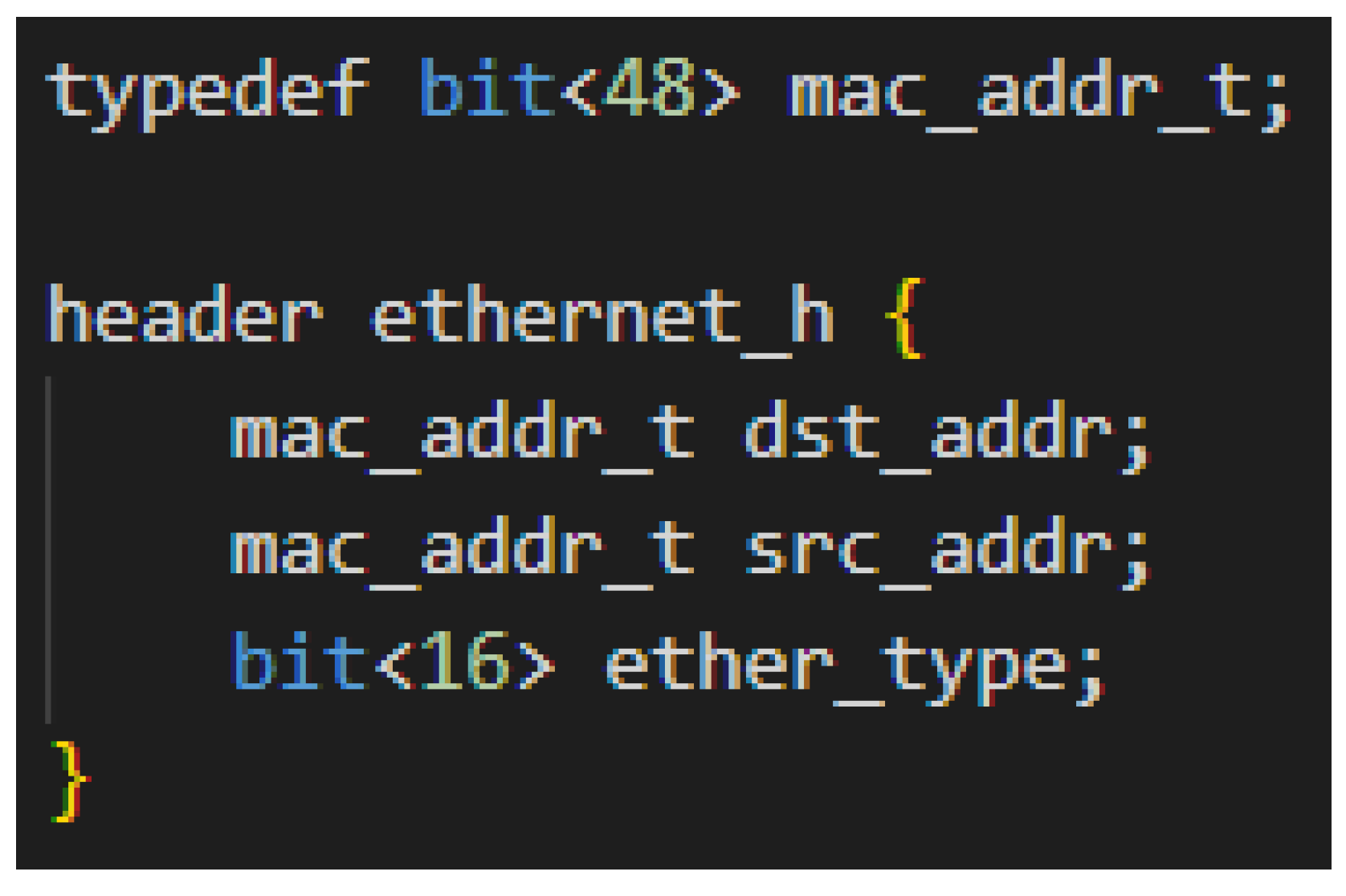
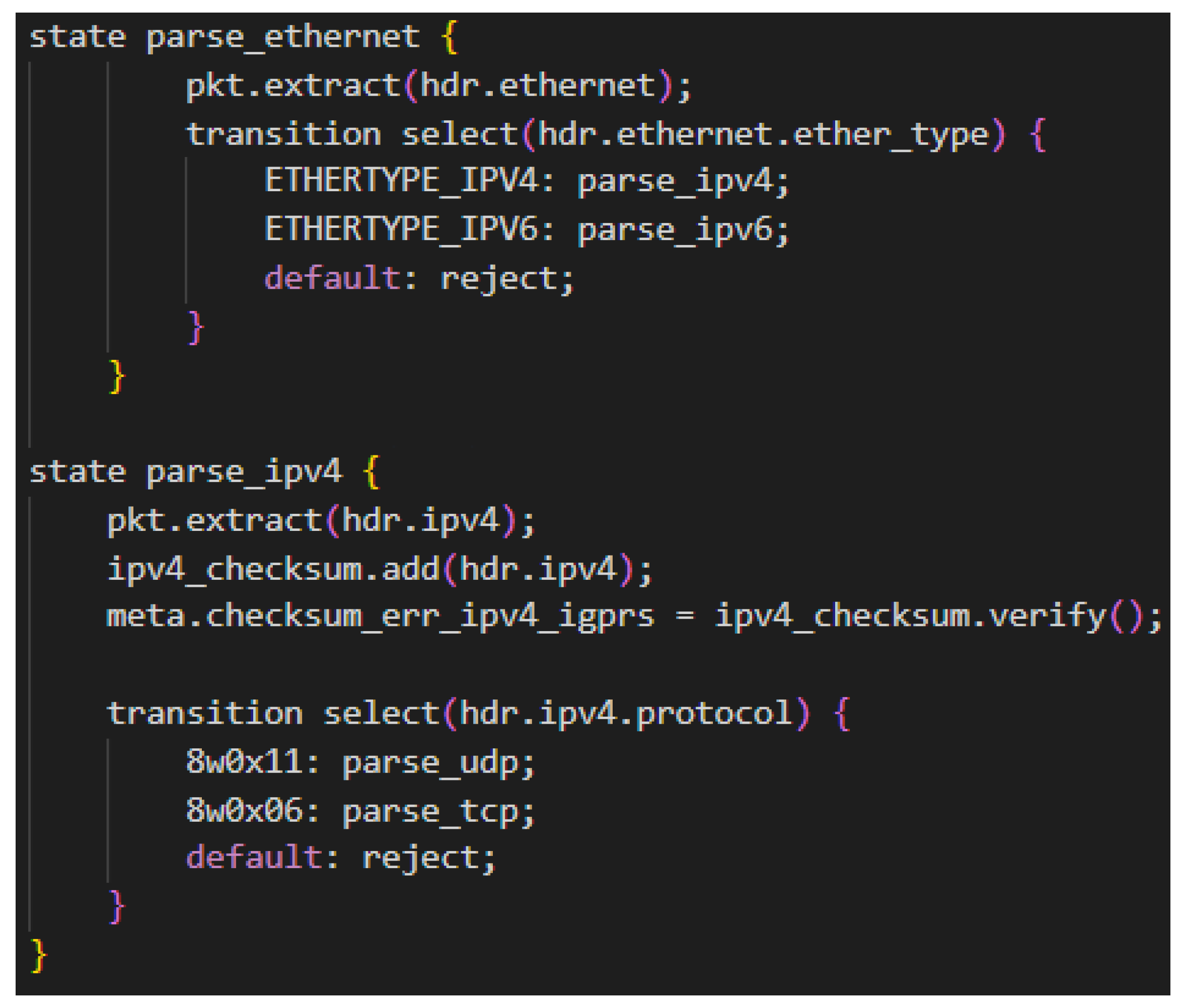
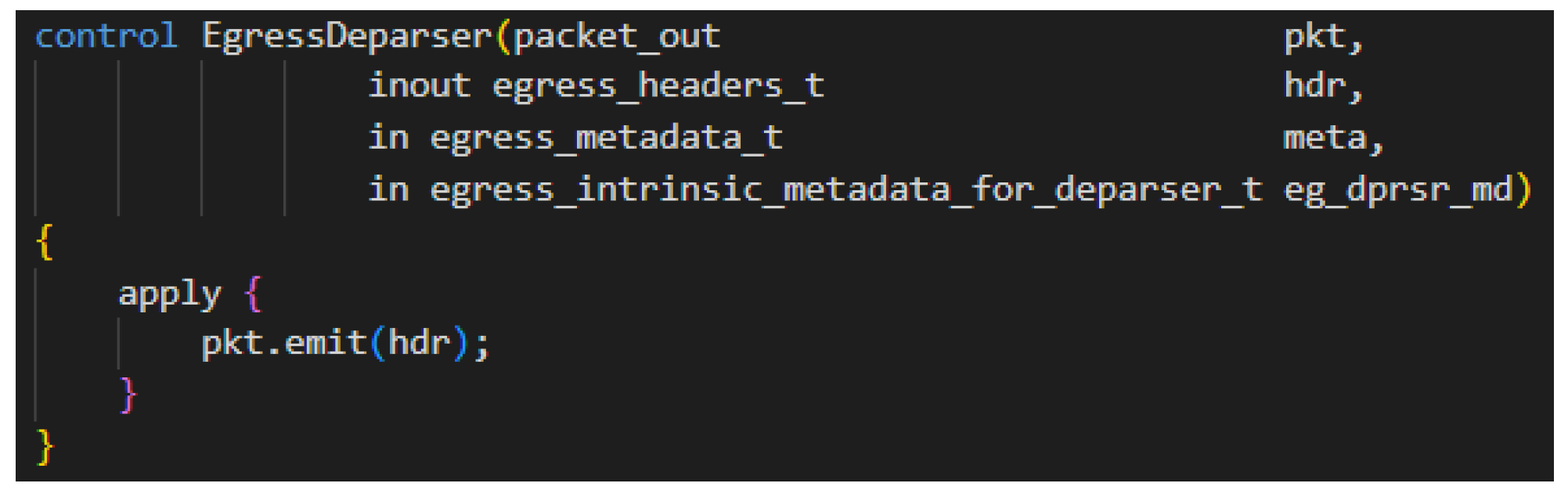
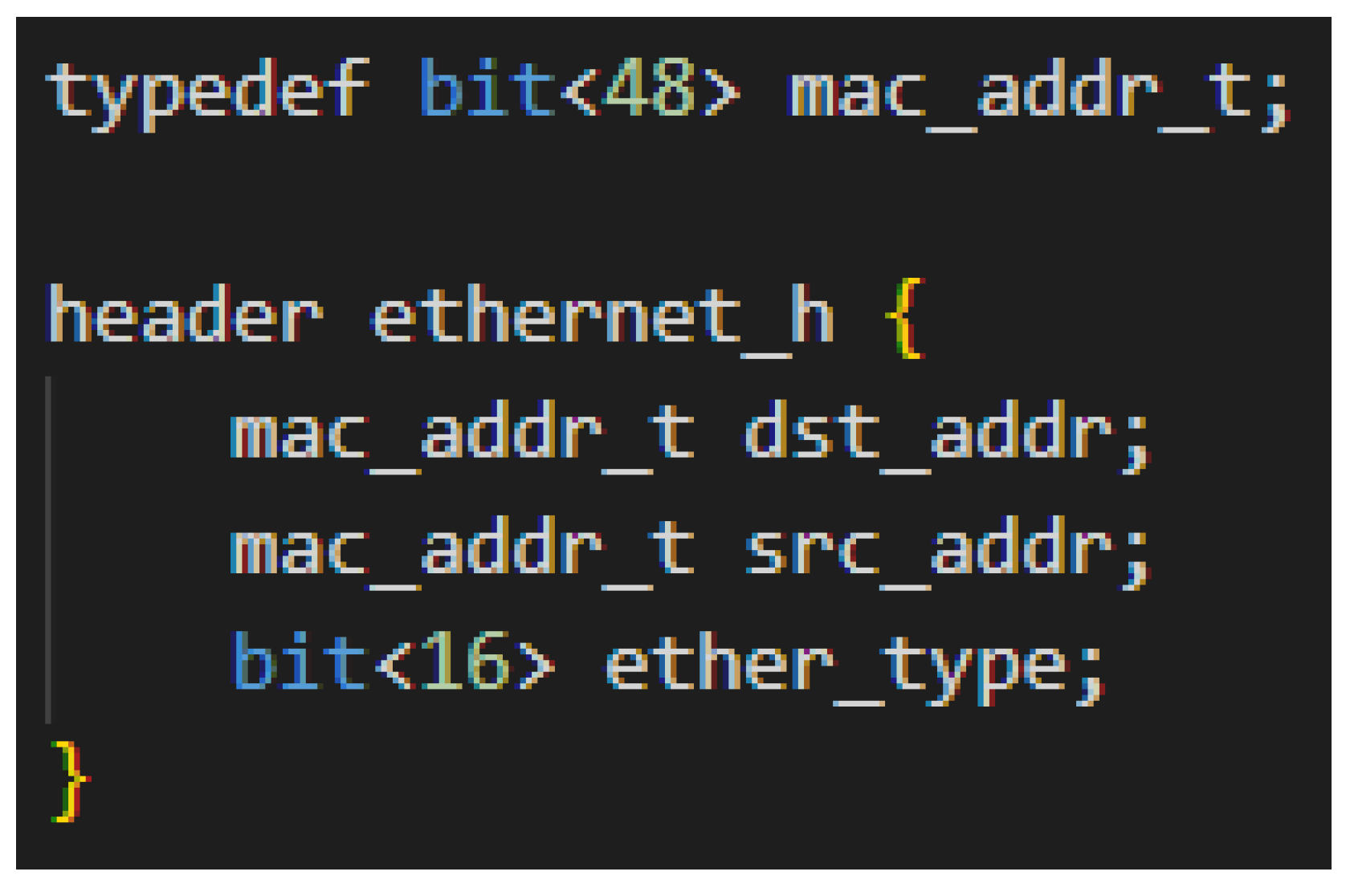
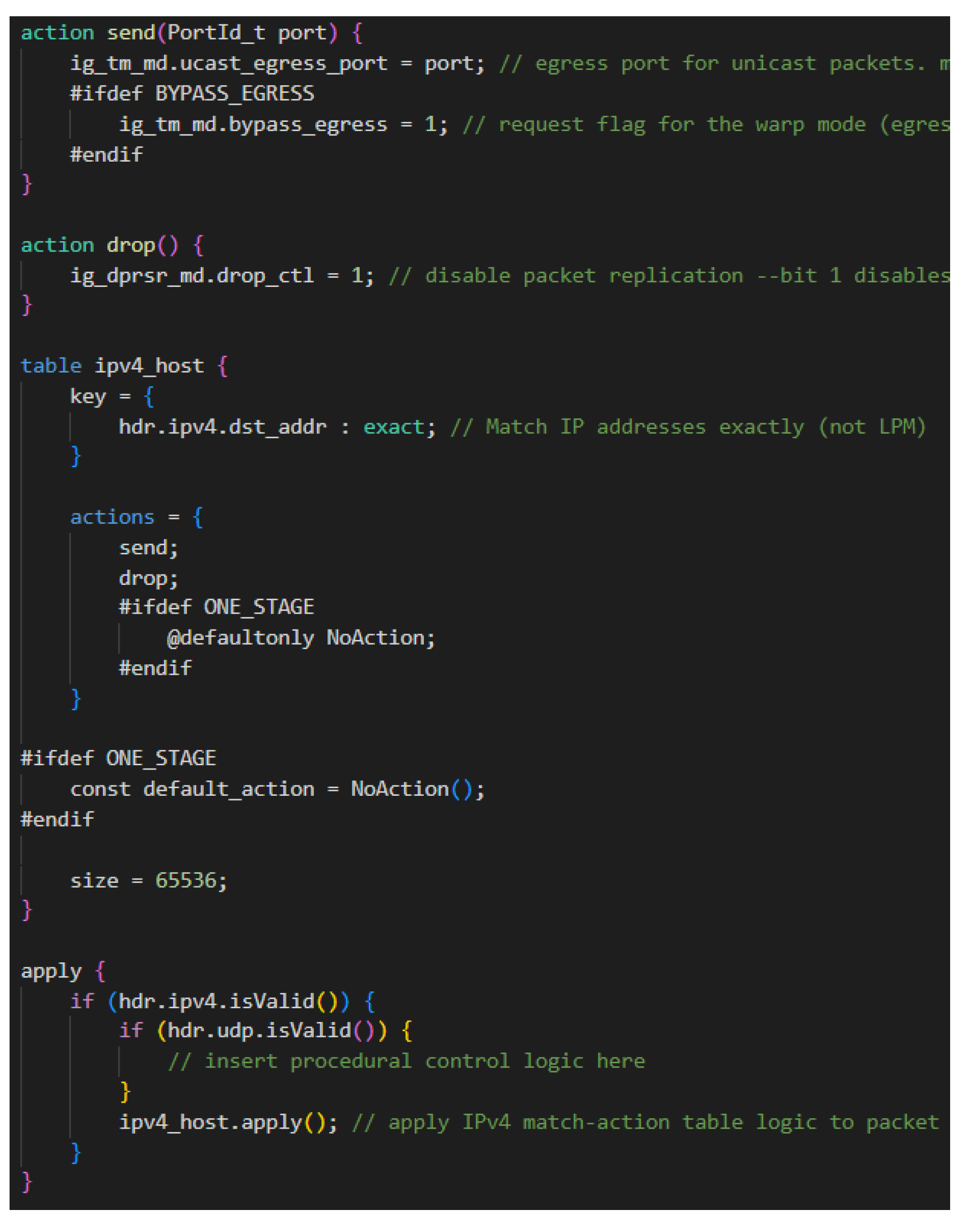
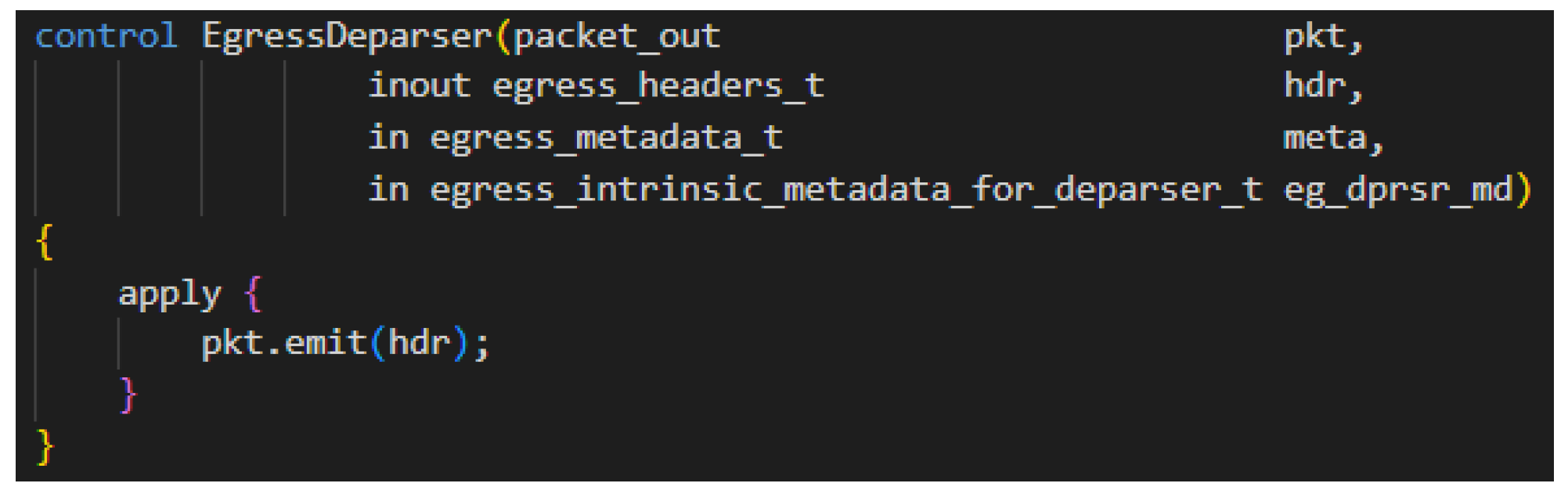
5.1. The P4 Algorithm
| Algorithm 1 P4 Bundle Translator Algorithm. |
Step 1: Parser
|
5.2. Design Constraints
5.3. Proof-of-Concept Evaluation
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Overview of P4

References
- LunaNet Interoperability Specification Document Version 4; Technical Report; National Aeronautics and Space Administration and European Space Agency: Washington, DC, USA, 2022.
- Otero, D.G. ESA Moonlight Initiative. Presented at IPNSIG Academy. 2022. Available online: https://ipnsig.org/wp-content/uploads/2022/11/IPNSIG-ESA-Moonlight-overview-Nov-2022-1.pdf (accessed on 26 September 2022).
- Cerf, V.; Burleigh, S.; Hooke, A.; Torgerson, L.; Durst, R.; Scott, K.; Fall, K.; Weiss, H. Delay-Tolerant Networking Architecture; RFC 4838; IETF: Fremont, CA, USA, 2007. [Google Scholar] [CrossRef] [Green Version]
- Demmer, M. A Delay Tolerant Networking and System Architecture for Developing Regions. Ph.D. Thesis, University of California, Berkeley, CA, USA, 2008. [Google Scholar]
- Basciano, T.; Pohlchuck, B.; Shamburger, N.M. Application of Delay Tolerant Networking on the International Space Station. In Proceedings of the ISS Research and Development Conference, Atlanta, GA, USA, 29 July–1 August 2019. [Google Scholar]
- Fraire, J.A.; De Jonckère, O.; Burleigh, S. Routing in the Space Internet: A contact graph routing tutorial. J. Netw. Comput. Appl. 2021, 174, 102884. [Google Scholar] [CrossRef]
- Cerf, V.; Kaneko, Y.; Burleigh, S.; Suzuki, K.; Luque, M. IPNSIG Strategy Working Group Report: A Strategy Toward a Solar System Internet for Humanity; IPNSIG: Arlington, VA, USA, 2021. [Google Scholar]
- Fall, K. A Delay-Tolerant Network Architecture for Challenged Internets. In Proceedings of the 2003 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’03, Karlsruhe, Germany, 25–29 August 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 27–34. [Google Scholar] [CrossRef] [Green Version]
- Sipos, B.; Demmer, M.; Ott, J.; Perreault, S. Delay-Tolerant Networking TCP Convergence-Layer Protocol Version 4; RFC 9174; IETF: Fremont, CA, USA, 2022. [Google Scholar] [CrossRef]
- Scott, K.; Burleigh, S. Bundle Protocol Specification; RFC 5050; IETF: Fremont, CA, USA, 2007. [Google Scholar] [CrossRef]
- Burleigh, S.; Fall, K.; Birrane, E.J. Bundle Protocol Version 7; RFC 9171; IETF: Fremont, CA, USA, 2022. [Google Scholar] [CrossRef]
- NASA Jet Propulsion Laboratory. Interplanetary Overlay Network (ION). Available online: https://sourceforge.net/projects/ion-dtn/ (accessed on 1 September 2022).
- The Consultative Committee for Space Data Systems. Licklider Transmission Protocol (LTP) for CCSDS; CCSDS Blue Book; CCSDS: Washington, DC, USA, 2015. [Google Scholar]
- Burleigh, S. Contact Graph Routing. 2009. Available online: https://tools.ietf.org/html/draft-burleigh-dtnrg-cgr-00 (accessed on 1 September 2022).
- NASA Glenn Research Center. High Rate Delay Tolerant Networking (HDTN). Available online: https://www1.grc.nasa.gov/space/scan/acs/tech-studies/dtn/ (accessed on 1 September 2022).
- Hylton, A.; Raible, D. High Data Rate Architecture (HiDRA). In Proceedings of the Ka and Broadband Communications Conference 2016, Cleveland, OH, USA, 17–20 October 2016. [Google Scholar]
- Hylton, A.; Raible, D.; Clark, G.; Dudukovich, R.; Tomko, B.; Burke, L. Rising above the cloud: Toward high-rate delay-tolerant networking in low earth orbit. In Proceedings of the 37th International Communications Satellite Systems Conference (ICSSC-2019), Okinawa, Japan, 29 October–1 November 2019; pp. 1–17. [Google Scholar] [CrossRef]
- Hylton, A.; Cleveland, J.; Dudukovich, R.; Iannicca, D.; Kortas, N.; LaFuente, B.; Nowakowski, J.; Raible, D.; Short, B.; Tomko, B.; et al. New Horizons for a Practical and Performance-Optimized Solar System Internet. In Proceedings of the IEEE Aerospace Conference 2022, Big Sky, MT, USA, 5–12 March 2022. [Google Scholar]
- Raible, D.; Dudukovich, R.; Tomko, B.; Kortas, N.; LaFuente, B.; Iannicca, D.; Basciano, T.; Pohlchuck, W.; Deaton, J.; Hylton, A.; et al. Developing High Performance Space Networking Capabilities for the International Space Station and Beyond; Technical Memorandum; NASA: Washington, DC, USA, 2022.
- Eddy, W.; Davies, E.B. Using Self-Delimiting Numeric Values in Protocols; RFC 6256; IETF: Fremont, CA, USA, 2011. [Google Scholar] [CrossRef] [Green Version]
- Burleigh, S. Compressed Bundle Header Encoding (CBHE); RFC 6260; IETF: Fremont, CA, USA, 2011. [Google Scholar] [CrossRef]
- Bormann, C.; Hoffman, P.E. Concise Binary Object Representation (CBOR); RFC 8949; IETF: Fremont, CA, USA, 2020. [Google Scholar] [CrossRef]
- Jain, S.; Fall, K.; Patra, R. Routing in a Delay Tolerant Network. In Proceedings of the 2004 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Portland, OR, USA, 30 August–3 September 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 145–158. [Google Scholar] [CrossRef] [Green Version]
- Jones, E.P.C.; Li, L.; Ward, P.A.S. Practical Routing in Delay-Tolerant Networks. In Proceedings of the 2005 ACM SIGCOMM Workshop on Delay-Tolerant Networking, Philadelphia, PA, USA, 26 August 2005; Association for Computing Machinery: New York, NY, USA, 2005; pp. 237–243. [Google Scholar] [CrossRef] [Green Version]
- Burleigh, S.; Caini, C.; Messina, J.J.; Rodolfi, M. Toward a unified routing framework for delay-tolerant networking. In Proceedings of the 2016 IEEE International Conference on Wireless for Space and Extreme Environments (WiSEE), Aachen, Germany, 26–29 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 82–86. [Google Scholar]
- Alessi, N. Hierarchical Inter-Regional Routing Algorithm for Interplanetary Networks. Master’s Thesis, University of Bologna, Bologna, Italy, 2019. [Google Scholar]
- Booth, S.; Hylton, A.; Dudukovich, R.; Kortas, N.; LaFuente, B.; Tomko, B. Alleviating Bundle Throughput Constriction for Delay Tolerant Networking (DTN) Bundles with Software Defined Networking (SDN). In Proceedings of the SPACOMM 2022, the Fourteenth International Conference on Advances in Satellite and Space Communications, Barcelona, Spain, 24–28 April 2022. [Google Scholar]
- Zacarias, I.; Gaspary, L.; Kohl, A.; Fernandes, R.; Stocchero, J.; Pignaton de Freitas, E. Combining Software-Defined and Delay-Tolerant Approaches in Last-Mile Tactical Edge Networking. IEEE Commun. Mag. 2017, 55, 22–29. [Google Scholar] [CrossRef]
- Tao, P.; Ying, C.; Sun, Z.; Tan, S.; Wang, P.; Sun, Z. The Controller Placement of Software-Defined Networks Based on Minimum Delay and Load Balancing. In Proceedings of the 2018 IEEE 16th Intl Conf on Dependable, Autonomic and Secure Computing, 16th Intl Conf on Pervasive Intelligence and Computing, 4th Intl Conf on Big Data Intelligence and Computing and Cyber Science and Technology Congress(DASC/PiCom/DataCom/CyberSciTech), Athens, Greece, 12–15 August 2018; pp. 310–313. [Google Scholar] [CrossRef]
- Killi, B.P.R.; Reddy, E.A.; Rao, S.V. Cooperative game theory based network partitioning for controller placement in SDN. In Proceedings of the 2018 10th International Conference on Communication Systems & Networks (COMSNETS), Bengaluru, India, 3–7 January 2018; pp. 105–112. [Google Scholar] [CrossRef]
- Isong, B.; Molose, R.R.S.; Abu-Mahfouz, A.M.; Dladlu, N. Comprehensive Review of SDN Controller Placement Strategies. IEEE Access 2020, 8, 170070–170092. [Google Scholar] [CrossRef]
- Hauser, F.; Häberle, M.; Merling, D.; Lindner, S.; Gurevich, V.; Zeiger, F.; Frank, R.; Menth, M. A Survey on Data Plane Programming with P4: Fundamentals, Advances, and Applied Research. arXiv 2021, arXiv:2101.10632. [Google Scholar] [CrossRef]
- The P4 Language Consortium. P4_16 Language Specification Version 1.2.3. Available online: https://p4.org/p4-spec/docs/P4-16-v-1.2.3.html (accessed on 1 September 2022).
- Fingerhut, A. P4lang/P4-Spec: Issue #264 Define New Operations on Varbits. Available online: https://github.com/p4lang/p4-spec/issues/264 (accessed on 1 September 2022).
- Fingerhut, A. Guide to Handling Variable Length Headers in P4. Available online: https://github.com/jafingerhut/p4-guide/tree/master/variable-length-header (accessed on 1 September 2022).
- Kim, J.; Kim, H.; Rexford, J. Analyzing Traffic by Domain Name in the Data Plane. In Proceedings of the ACM SIGCOMM Symposium on SDN Research (SOSR), Virtual, 11–12 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–12. [Google Scholar] [CrossRef]
- Kim, J.; Kim, H.; Rexford, J. Meta4: Netassay_tunnel_j8.p4. Available online: https://github.com/hyojoonkim/Meta4/blob/main/P4/netassay_tunnel_j8.p4 (accessed on 1 September 2022).
- Rijsinghani, A. Computation of the Internet Checksum via Incremental Update; RFC 1624; IETF: Fremont, CA, USA, 1994. [Google Scholar] [CrossRef]
- Musumeci, F.; Fidanci, A.C.; Paolucci, F.; Cugini, F.; Tornatore, M. Machine-Learning-Enabled DDoS Attacks Detection in P4 Programmable Networks. J. Netw. Syst. Manag. 2022, 30, 21. [Google Scholar] [CrossRef]
- NASA Space Communications and Navigation. Cognitive Communications Project. Available online: https://www1.grc.nasa.gov/space/scan/acs/cognitive-communications/ (accessed on 1 September 2022).






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ta, D.; Booth, S.; Dudukovich, R. Towards Software-Defined Delay Tolerant Networks. Network 2023, 3, 15-38. https://doi.org/10.3390/network3010002
Ta D, Booth S, Dudukovich R. Towards Software-Defined Delay Tolerant Networks. Network. 2023; 3(1):15-38. https://doi.org/10.3390/network3010002
Chicago/Turabian StyleTa, Dominick, Stephanie Booth, and Rachel Dudukovich. 2023. "Towards Software-Defined Delay Tolerant Networks" Network 3, no. 1: 15-38. https://doi.org/10.3390/network3010002
APA StyleTa, D., Booth, S., & Dudukovich, R. (2023). Towards Software-Defined Delay Tolerant Networks. Network, 3(1), 15-38. https://doi.org/10.3390/network3010002