
Bayesian Nonparametric Inference in Elliptic PDEs: Convergence Rates and Implementation †


Abstract
1. Introduction
2. Materials and Methods
2.1. Likelihood, Prior and Posterior
2.2. Convergence Rates
2.3. Examples of Gaussian Priors
3. Results
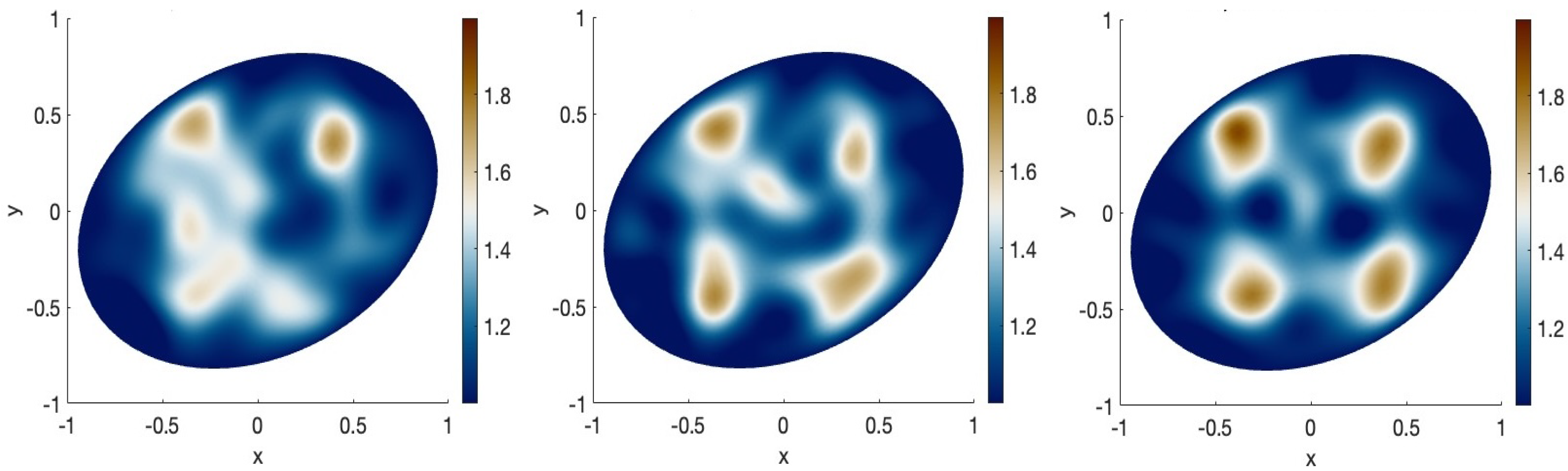
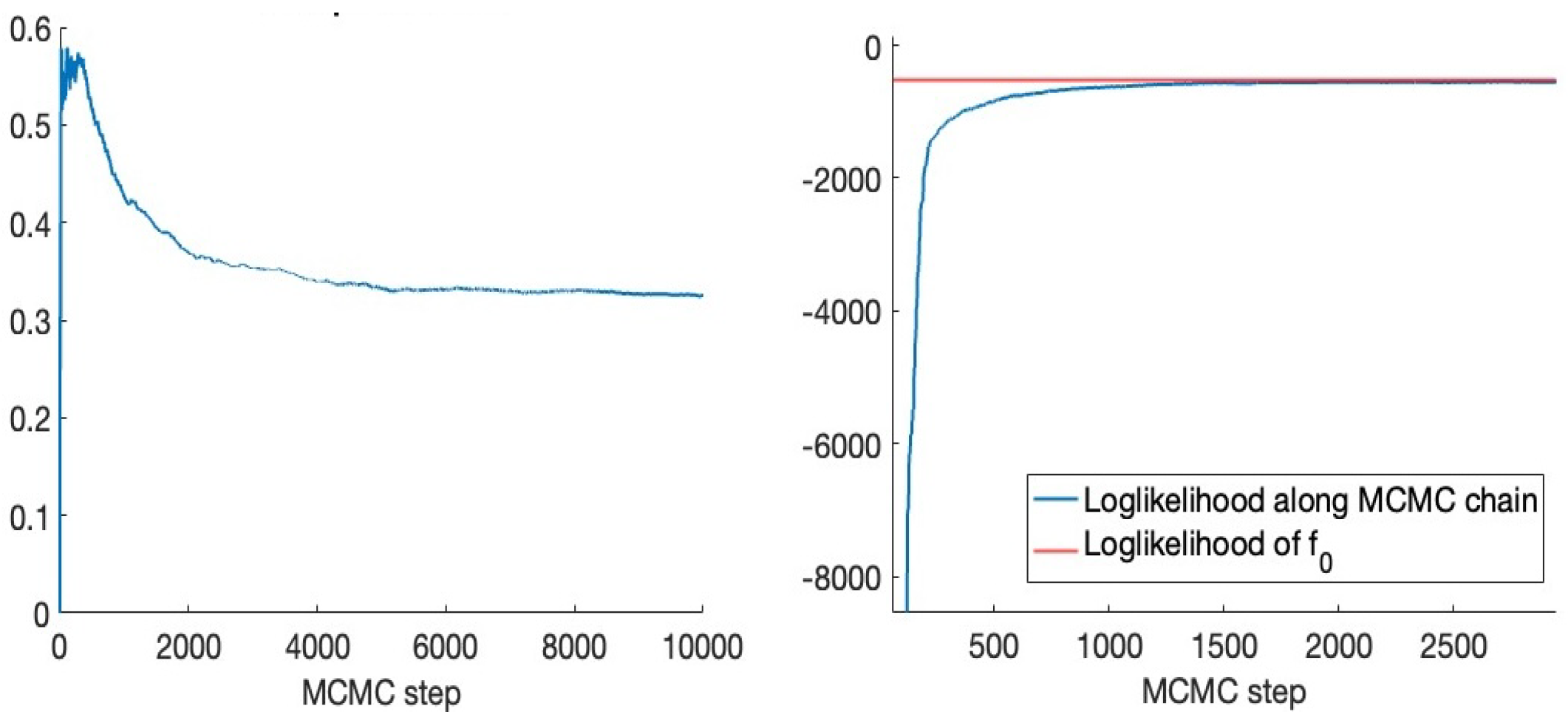
3.1. Results with Truncated Gaussian Series Priors
- Draw a prior sample , where is as in (18), and for define the proposal ;
3.2. Results with the Matérn Process Prior
4. Discussion
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Further Numerical Results


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ; series prior | 0.1197 | 0.0974 | 0.07234 |
| ; series prior | 7.22% | 5.90% | 4.71% |
| ; Matérn prior | 0.1241 | 0.0941 | 0.08148 |
| ; Matérn prior | 7.49% | 5.70% | 5.31% |
Appendix B. Proof of Theorem 1
- Step I: posterior contraction rates in prediction risk.
- Step II: remaining claims.
References
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems; Mathematics and Its Applications; Kluwer Academic Publishers Group: Dordrecht, The Netherlands, 1996; Volume 375, p. viii+321. [Google Scholar]
- Kaltenbacher, B.; Neubauer, A.; Scherzer, O. Iterative Regularization Methods for Nonlinear Ill-Posed Problems; Radon Series on Computational and Applied Mathematics; Walter de Gruyter GmbH & Co. KG: Berlin, Germany, 2008; Volume 6, p. viii+194. [Google Scholar] [CrossRef]
- Isakov, V. Inverse Problems for Partial Differential Equations, 3rd ed.; Applied Mathematical Sciences; Springer: Cham, Switzerland, 2017; Volume 127, p. xv+406. [Google Scholar] [CrossRef]
- Kaipio, J.; Somersalo, E. Statistical and Computational Inverse Problems; Number 160 in Applied Mathematical Sciences; Springer: New York, NY, USA, 2004. [Google Scholar]
- Bissantz, N.; Hohage, T.; Munk, A. Consistency and rates of convergence of nonlinear Tikhonov regularization with random noise. Inverse Probl. 2004, 20, 1773–1789. [Google Scholar] [CrossRef]
- Hohage, T.; Pricop, M. Nonlinear Tikhonov regularization in Hilbert scales for inverse boundary value problems with random noise. Inverse Probl. Imaging 2008, 2, 271–290. [Google Scholar] [CrossRef]
- Benning, M.; Burger, M. Modern regularization methods for inverse problems. Acta Numer. 2018, 27, 1–111. [Google Scholar] [CrossRef]
- Arridge, S.; Maass, P.; Öktem, O.; Schönlieb, C.B. Solving inverse problems using data-driven models. Acta Numer. 2019, 28, 1–174. [Google Scholar] [CrossRef]
- Nickl, R. Bayesian Non-Linear Statistical Inverse Problems; Zurich Lectures in Advanced Mathematics; EMS Press: Berlin, Germany, 2023; p. xi+15. [Google Scholar] [CrossRef]
- Evans, L.C. Partial Differential Equations, 2nd ed.; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2010; Volume 19, p. xxii+749. [Google Scholar] [CrossRef]
- Yeh, W.W.G. Review of Parameter Identification Procedures in Groundwater Hydrology: The Inverse Problem. Water Resour. Res. 1986, 22, 95–108. [Google Scholar] [CrossRef]
- Richter, G.R. An inverse problem for the steady state diffusion equation. SIAM J. Appl. Math. 1981, 41, 210–221. [Google Scholar] [CrossRef]
- Knowles, I. Parameter identification for elliptic problems. J. Comput. Appl. Math. 2001, 131, 175–194. [Google Scholar] [CrossRef]
- Bonito, A.; Cohen, A.; DeVore, R.; Petrova, G.; Welper, G. Diffusion coefficients estimation for elliptic partial differential equations. SIAM J. Math. Anal. 2017, 49, 1570–1592. [Google Scholar] [CrossRef]
- Dashti, M.; Stuart, A.M. Uncertainty quantification and weak approximation of an elliptic inverse problem. SIAM J. Numer. Anal. 2011, 49, 2524–2542. [Google Scholar] [CrossRef]
- Cotter, S.; Roberts, G.; Stuart, A.; White, D. MCMC Methods for Functions: Modifying Old Algorithms to Make Them Faster. Stat. Sci. 2013, 28, 424–446. [Google Scholar] [CrossRef]
- Stuart, A.M. Inverse problems: A Bayesian perspective. Acta Numer. 2010, 19, 451–559. [Google Scholar] [CrossRef]
- Vollmer, S.J. Posterior consistency for Bayesian inverse problems through stability and regression results. Inverse Probl. 2013, 29, 125011. [Google Scholar] [CrossRef]
- Abraham, K.; Nickl, R. On statistical Calderón problems. Math. Stat. Learn. 2019, 2, 165–216. [Google Scholar] [CrossRef]
- Giordano, M.; Nickl, R. Consistency of Bayesian inference with Gaussian process priors in an elliptic inverse problem. Inverse Probl. 2020, 36, 85001–85036. [Google Scholar] [CrossRef]
- Monard, F.; Nickl, R.; Paternain, G.P. Consistent inversion of noisy non-Abelian X-ray transforms. Comm. Pure Appl. Math. 2021, 74, 1045–1099. [Google Scholar] [CrossRef]
- Giordano, M. Asymptotic Theory for Bayesian Nonparametric Inference in Statistical Models Arising from Partial Differential Equations. Doctoral Thesis, University of Cambridge, Cambridge, UK, 2021. [Google Scholar] [CrossRef]
- Agapiou, S.; Wang, S. Laplace priors and spatial inhomogeneity in Bayesian inverse problems. Bernoulli 2024, 30, 878–910. [Google Scholar] [CrossRef]
- Ghosal, S.; van der Vaart, A.W. Fundamentals of Nonparametric Bayesian Inference; Cambridge University Press: New York, NY, USA, 2017. [Google Scholar]
- Giné, E.; Nickl, R. Mathematical Foundations of Infinite-Dimensional Statistical Models; Cambridge University Press: New York, NY, USA, 2016; p. xiv+690. [Google Scholar] [CrossRef]
- Nickl, R.; van de Geer, S.; Wang, S. Convergence rates for penalized least squares estimators in PDE constrained regression problems. SIAM/ASA J. Uncertain. Quantif. 2020, 8, 374–413. [Google Scholar] [CrossRef]
- Dashti, M.; Stuart, A.M. The Bayesian approach to inverse problems. In Handbook of Uncertainty Quantification; Springer: Cham, Switzerland, 2017; pp. 311–428. [Google Scholar]
- Haroske, D.D.; Triebel, H. Distributions, Sobolev Spaces, Elliptic Equations. EMS Press: Berlin, Germany, 2007. [Google Scholar]
- Taylor, M.E. Partial Differential Equations I; Springer: New York, NY, USA, 2011. [Google Scholar]
- Hairer, M.; Stuart, A.; Vollmer, S. Spectral Gaps for a Metropolis-Hastings Algorithm in Infinite Dimensions. Ann. Appl. Probab. 2014, 24, 2455–2490. [Google Scholar] [CrossRef]
- Hall, P.; Marron, J. On variance estimation in nonparametric regression. Biometrika 1990, 77, 415–419. [Google Scholar] [CrossRef]
- Wahba, G. Improper priors, spline smoothing and the problem of guarding against model errors in regression. J. R. Stat. Soc. Ser. B Stat. Methodol. 1978, 40, 364–372. [Google Scholar] [CrossRef]
- Rice, J. Bandwidth choice for nonparametric regression. Ann. Statist. 1984, 12, 1215–1230. [Google Scholar] [CrossRef]
- Kejzlar, V.; Son, M.; Bhattacharya, S.; Maiti, T. A fast and calibrated computer model emulator: An empirical Bayes approach. Stat. Comput. 2021, 31, 49. [Google Scholar] [CrossRef]
- Knapik, B.; Szabò, B.; van der Vaart, A.W.; van Zanten, H. Bayes procedures for adaptive inference in inverse problems for the white noise model. Probab. Theory Relat. Fields 2015, 164, 771–813. [Google Scholar] [CrossRef]
- Rousseau, J.; Szabo, B. Asymptotic behaviour of the empirical Bayes posteriors associated to maximum marginal likelihood estimator. Ann. Stat. 2017, 45, 833–865. [Google Scholar] [CrossRef] [PubMed]
- Teckentrup, A.L. Convergence of Gaussian process regression with estimated hyper-parameters and applications in Bayesian inverse problems. SIAM/ASA J. Uncertain. Quantif. 2020, 8, 1310–1337. [Google Scholar] [CrossRef]
- Agapiou, S.; Bardsley, J.M.; Papaspiliopoulos, O.; Stuart, A.M. Analysis of the Gibbs sampler for hierarchical inverse problems. SIAM/ASA J. Uncertain. Quantif. 2014, 2, 511–544. [Google Scholar] [CrossRef]
- Giordano, M.; Ray, K. Nonparametric Bayesian inference for reversible multidimensional diffusions. Ann. Stat. 2022, 50, 2872–2898. [Google Scholar] [CrossRef]
- Li, W.V.; Linde, W. Approximation, metric entropy and small ball estimates for Gaussian measures. Ann. Probab. 1999, 27, 1556–1578. [Google Scholar] [CrossRef]



| n | 100 | 250 | 500 | 1000 |
|---|---|---|---|---|
| ; series prior | 0.2981 | 0.2232 | 0.2144 | 0.1581 |
| ; series prior | 17.67% | 12.23% | 12.71% | 9.36% |
| ; Matérn prior | 0.3289 | 0.2677 | 0.2033 | 0.1647 |
| ; Matérn prior | 18.98% | 15.86% | 12.05% | 9.76% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giordano, M. Bayesian Nonparametric Inference in Elliptic PDEs: Convergence Rates and Implementation. Foundations 2025, 5, 14. https://doi.org/10.3390/foundations5020014
Giordano M. Bayesian Nonparametric Inference in Elliptic PDEs: Convergence Rates and Implementation. Foundations. 2025; 5(2):14. https://doi.org/10.3390/foundations5020014
Chicago/Turabian StyleGiordano, Matteo. 2025. "Bayesian Nonparametric Inference in Elliptic PDEs: Convergence Rates and Implementation" Foundations 5, no. 2: 14. https://doi.org/10.3390/foundations5020014
APA StyleGiordano, M. (2025). Bayesian Nonparametric Inference in Elliptic PDEs: Convergence Rates and Implementation. Foundations, 5(2), 14. https://doi.org/10.3390/foundations5020014