A Mathematical Structure Underlying Sentences and Its Connection with Short–Term Memory


Abstract
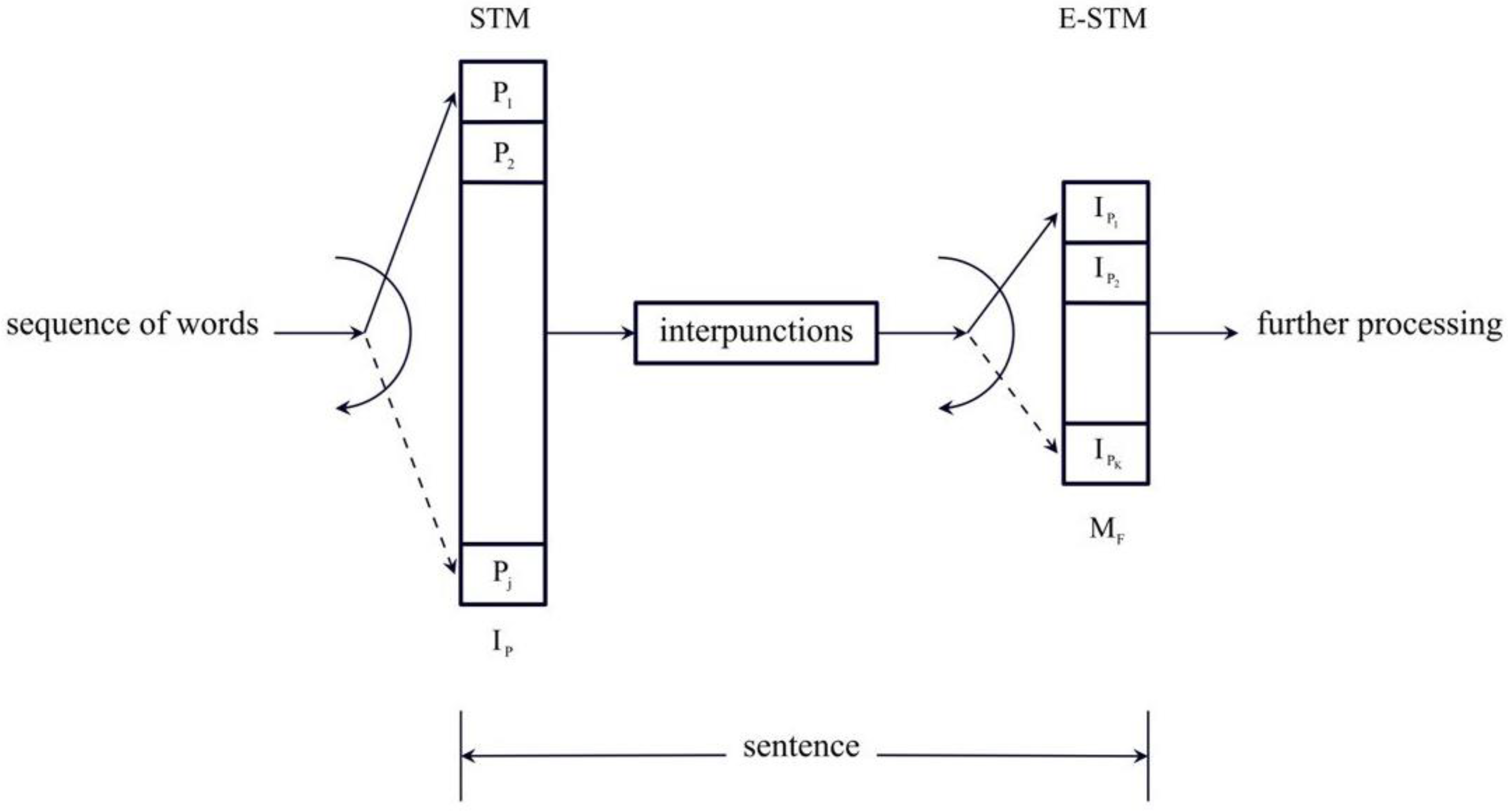
1. Does the Short–Term Memory Process Words with Two Independent Buffers in Series?
2. Probability Distribution of Sentence Length versus E–STM Buffer Size
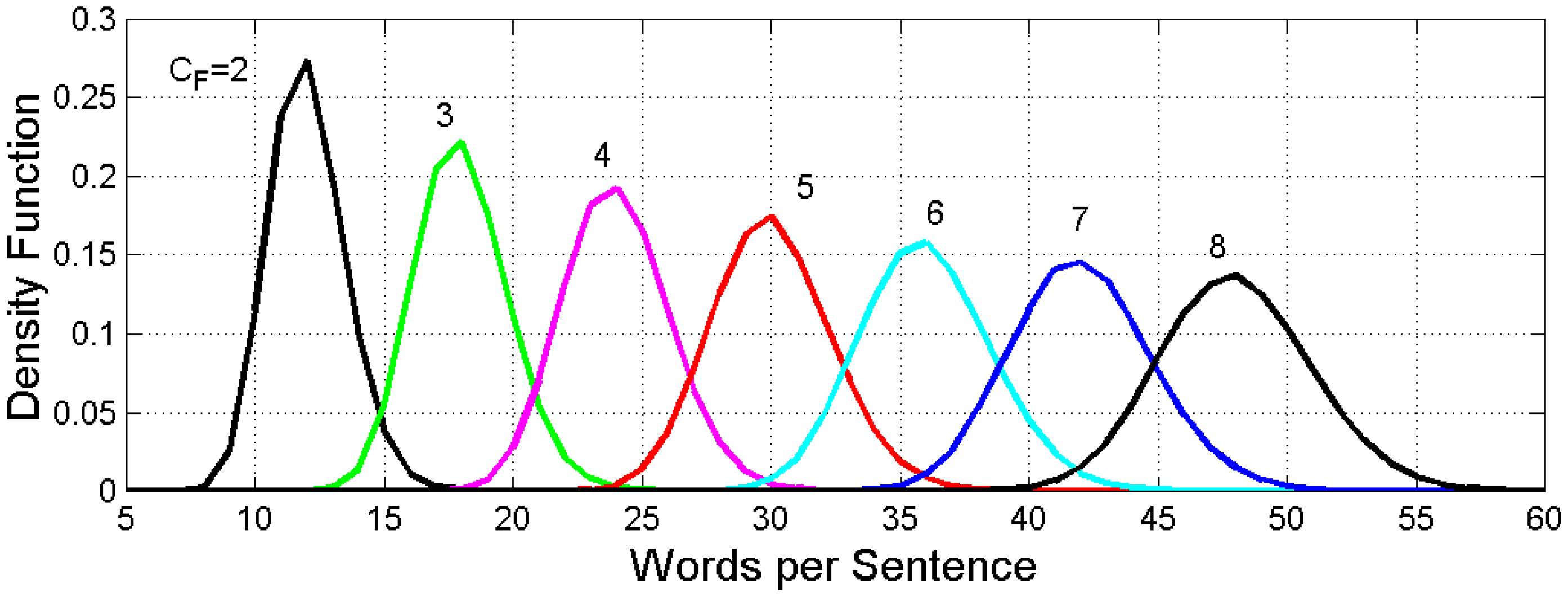
2.1. Probability Distribution of Sentence Length
- Consider a buffer made of cells. The sentence contains word intervals: for example, if , the sentence contains two interpunctions followed by a full stop, a question mark, or an exclamation mark.
- Generate independent values of according to the log–normal model given by Equation (1) and Table 1. The independence of from a cell to another cell is reasonable [1]. In detail, from a random number generator of standard Gaussian density variables (zero mean and unit standard deviation), we get the relationship ; therefore, the three-parameter log–normal variable is then given by .
- Add the number of words contained in the cells to obtain :
- Repeat steps one through three many times (we repeated these steps 100,000 times, i.e., we simulated 100,000 sentences of different length) to obtain a stable conditional PDF of .
- Repeat steps one through four for another and obtain another PDF.
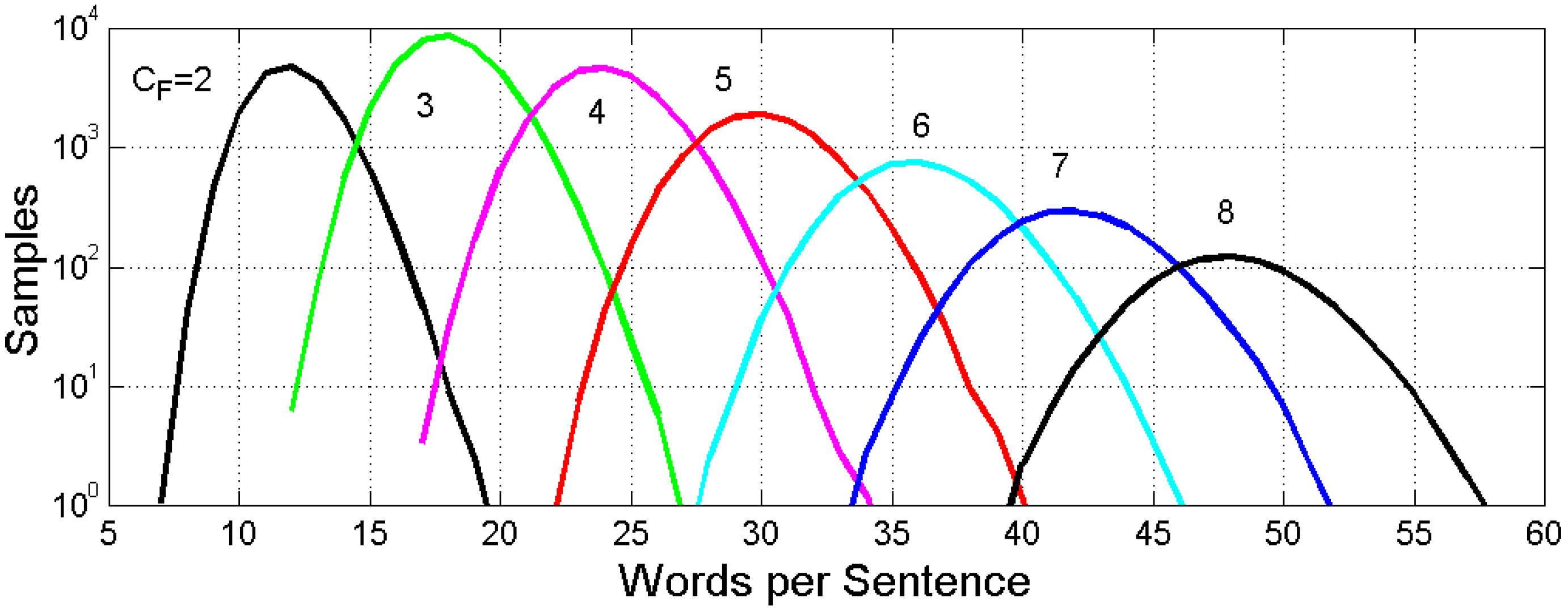
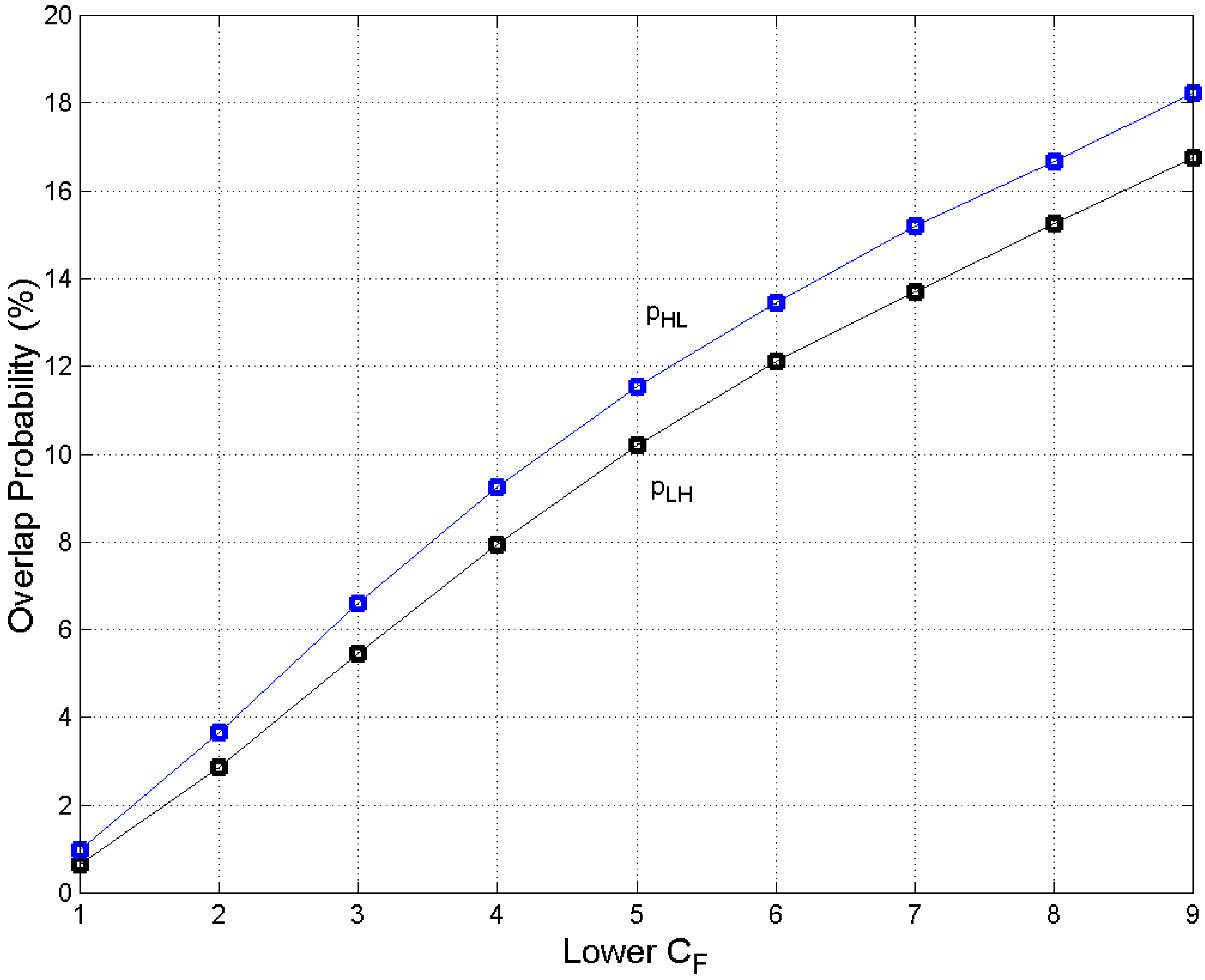
2.2. Overlap of the Conditional Probability Distributions
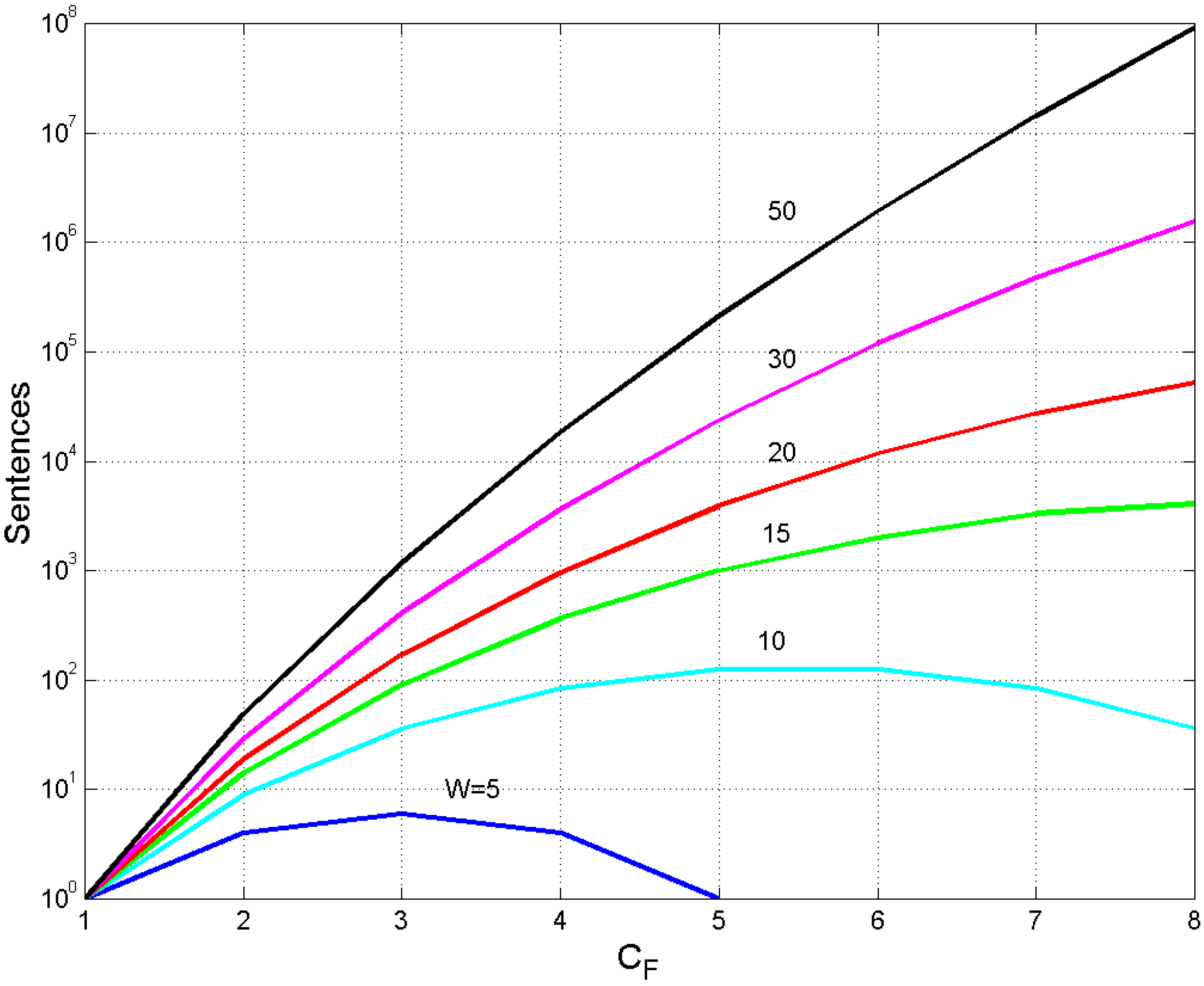
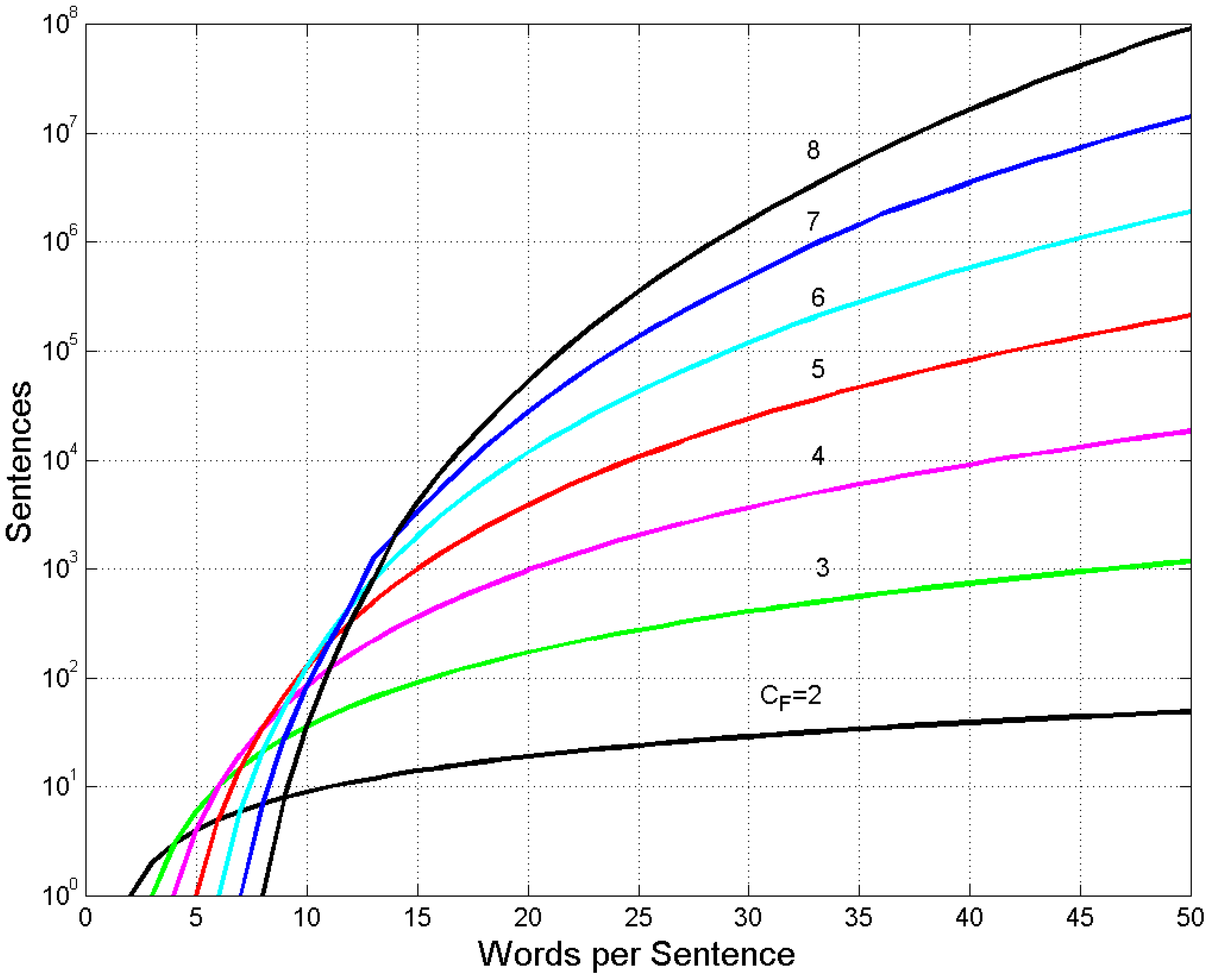
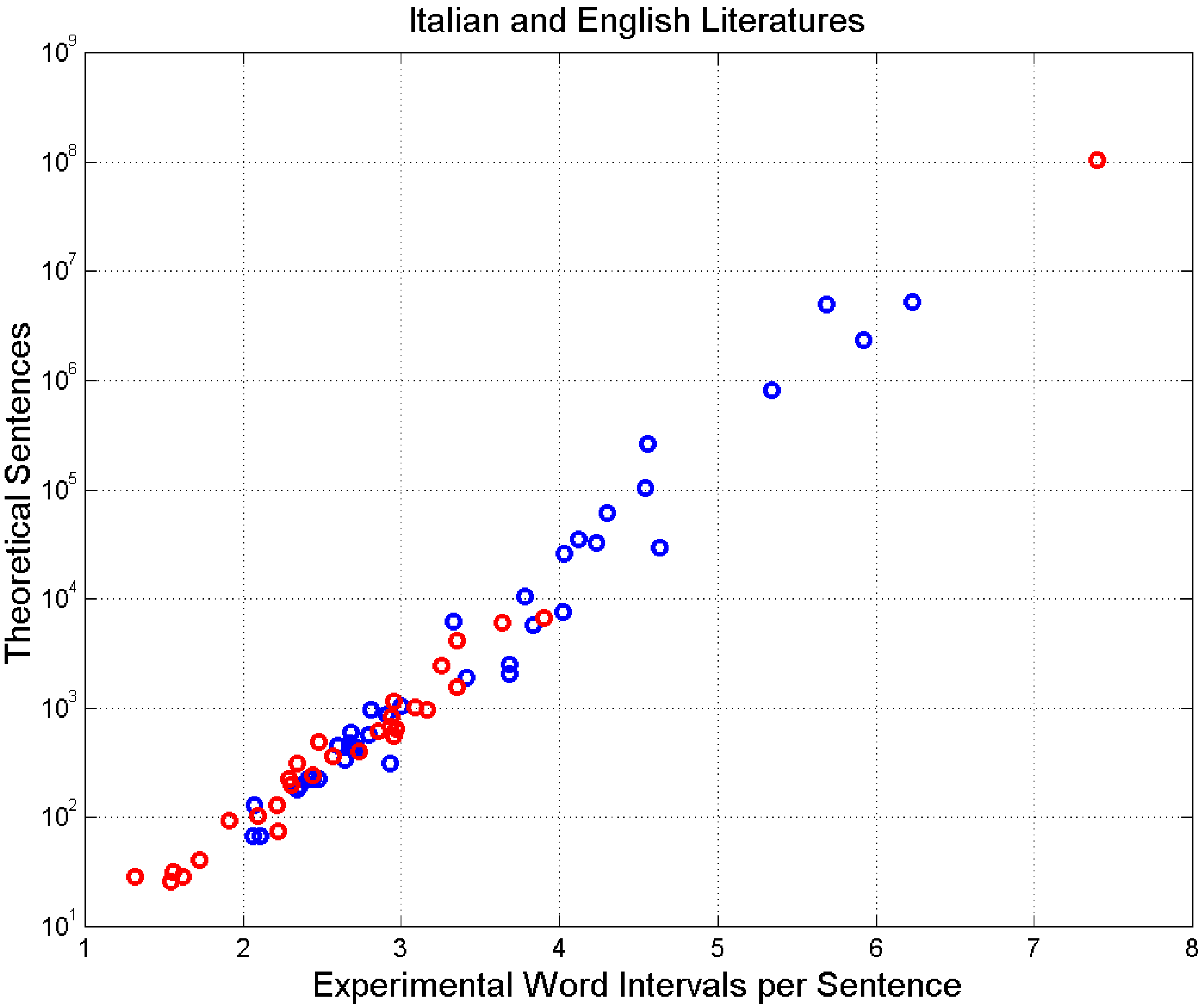
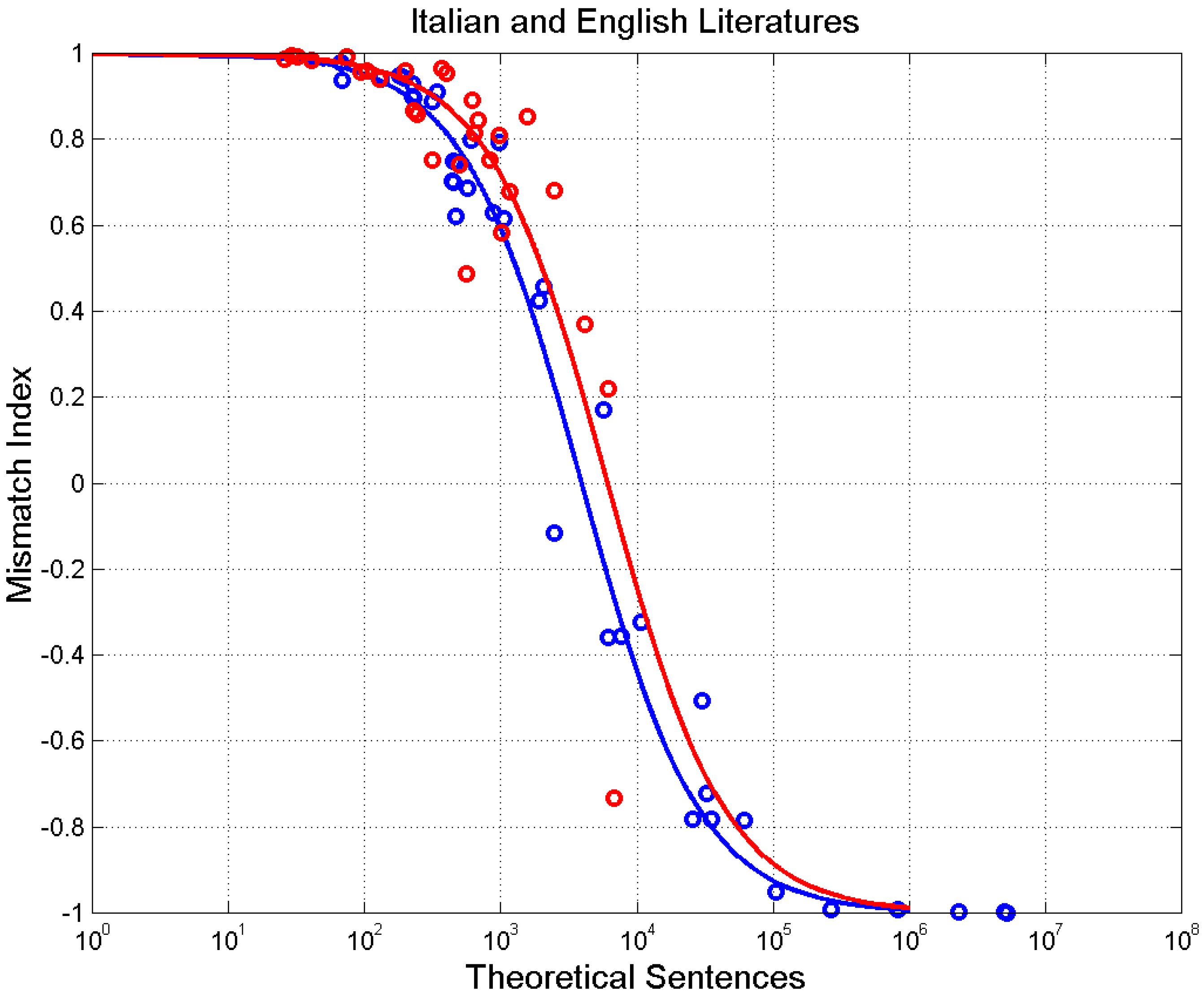
3. Theoretical Number of Sentences Recordable in Cells
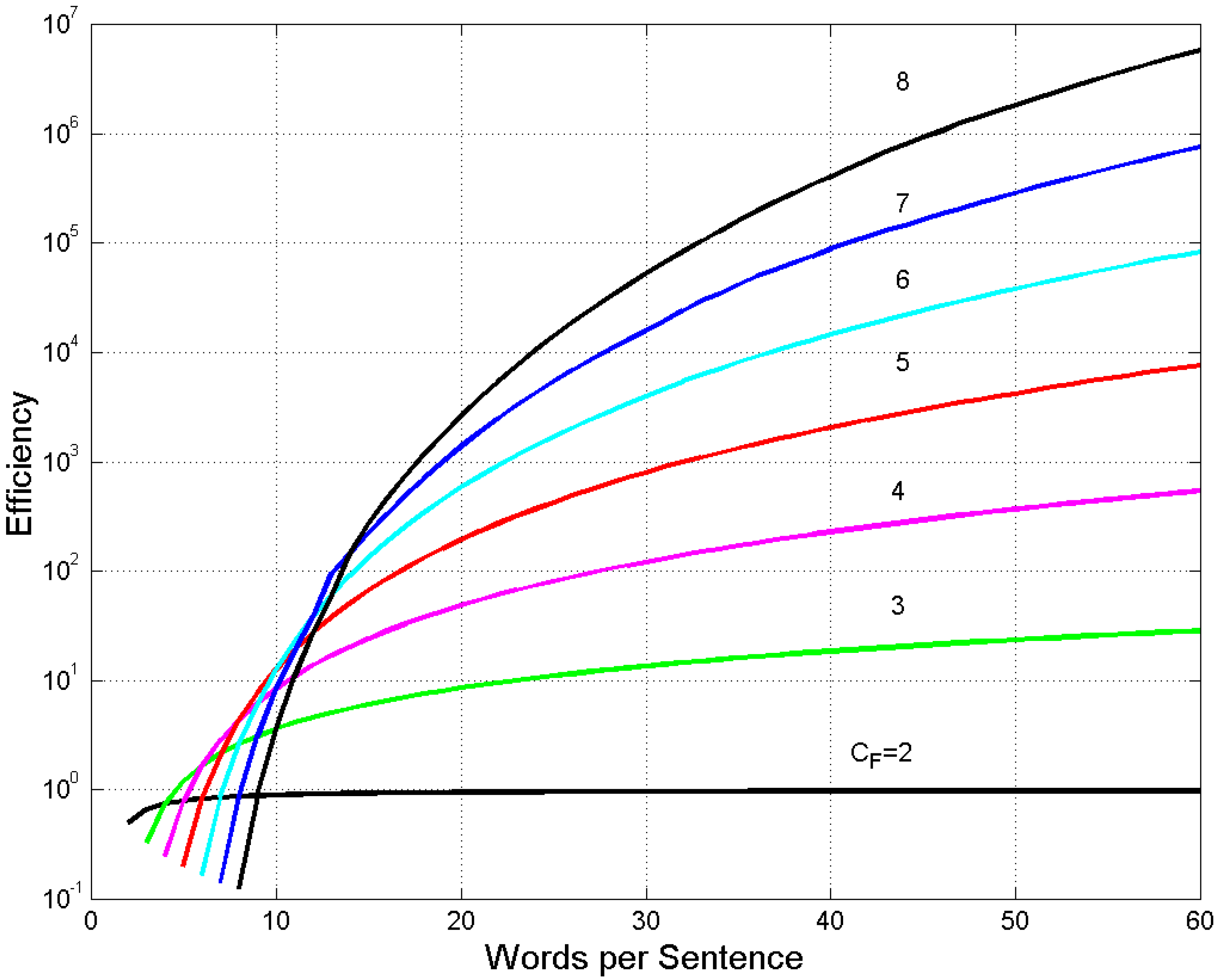
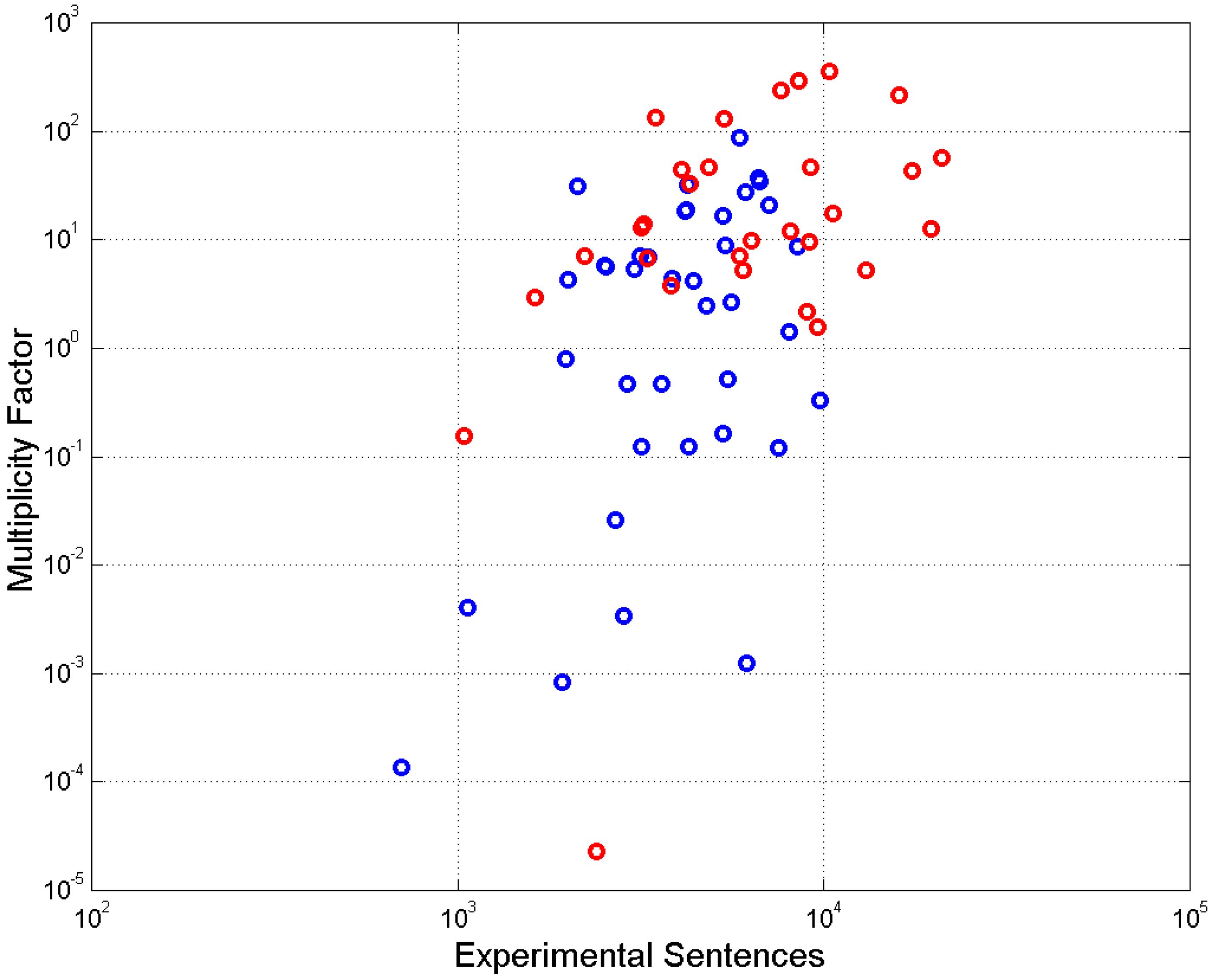
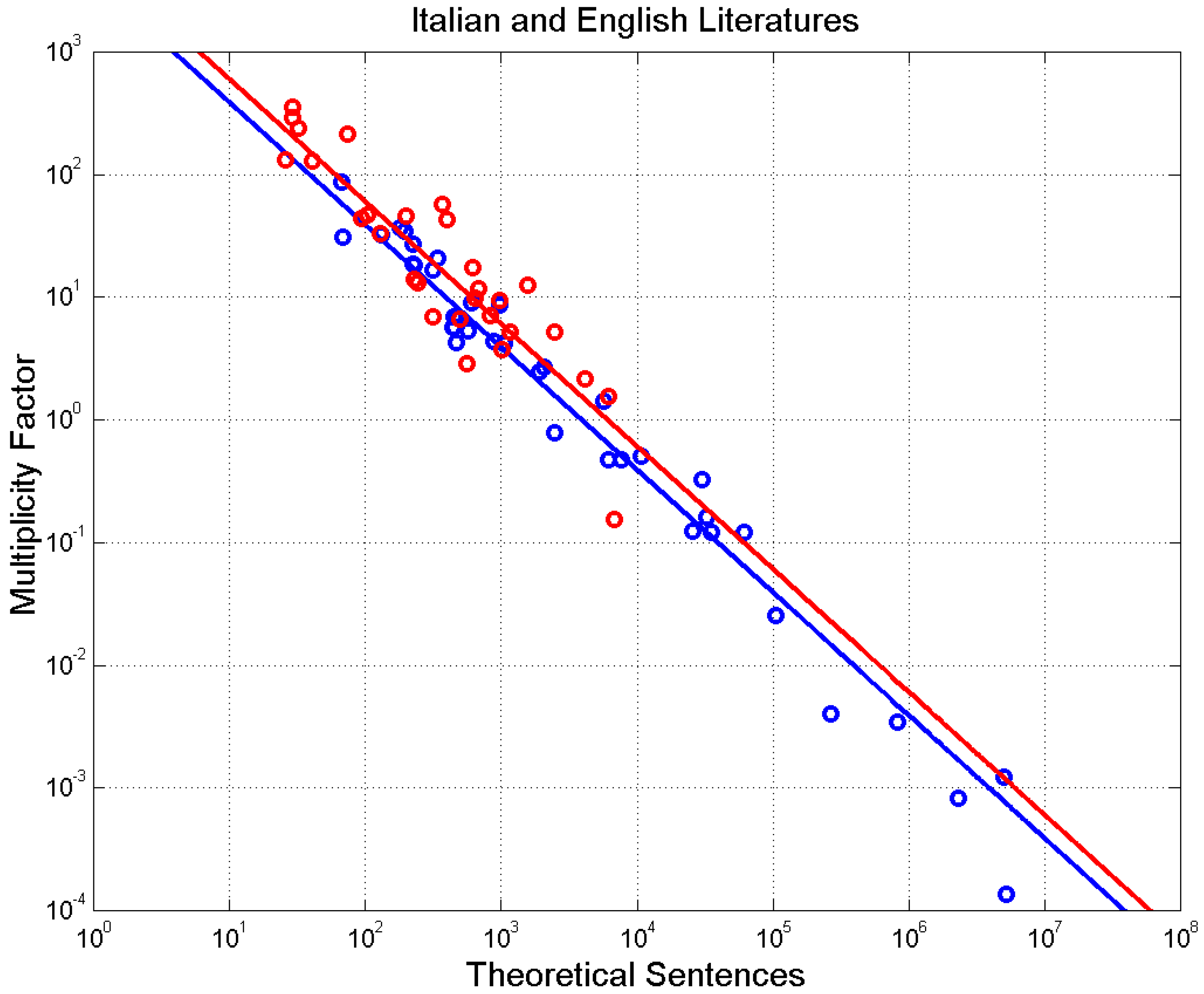
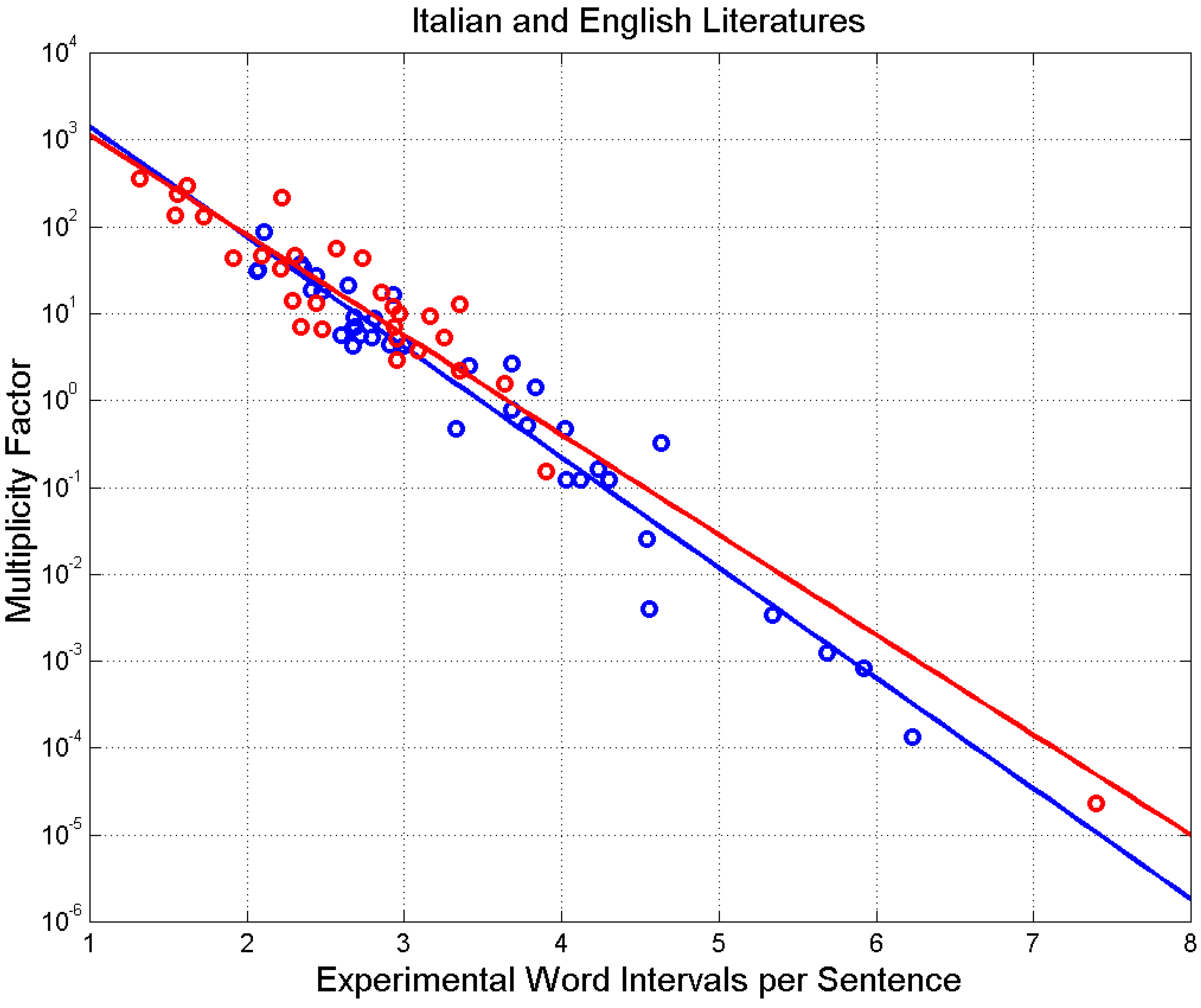
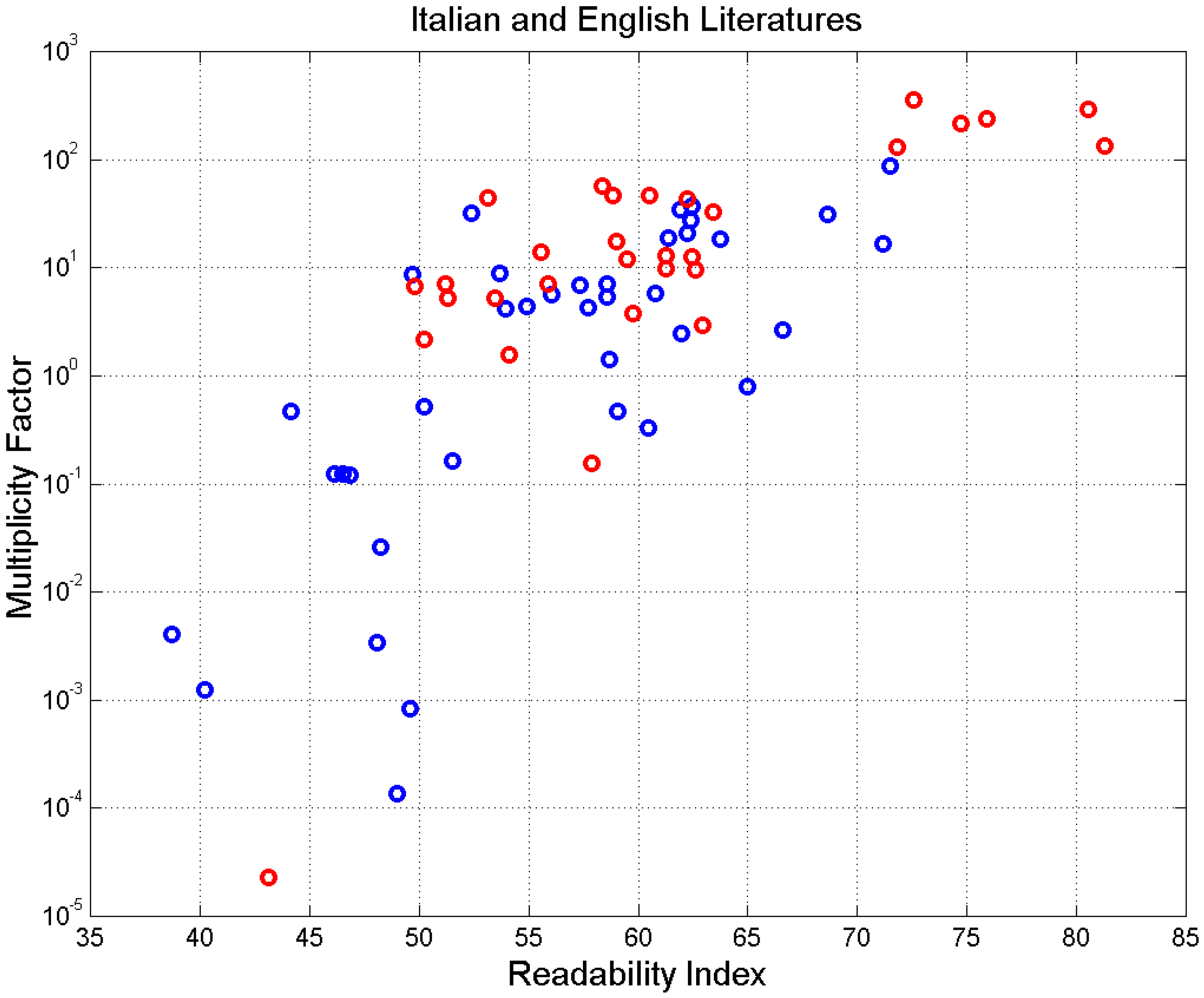
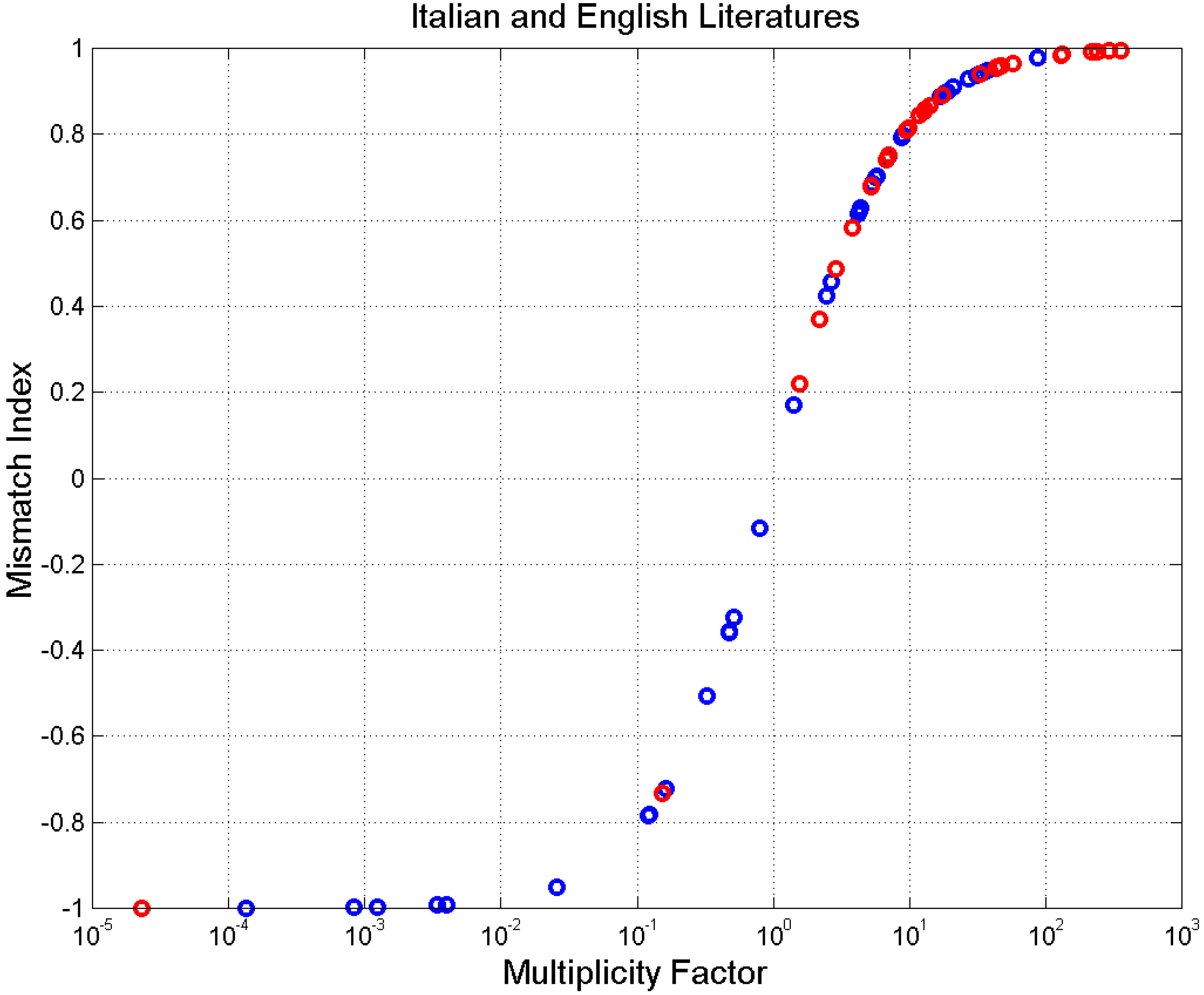
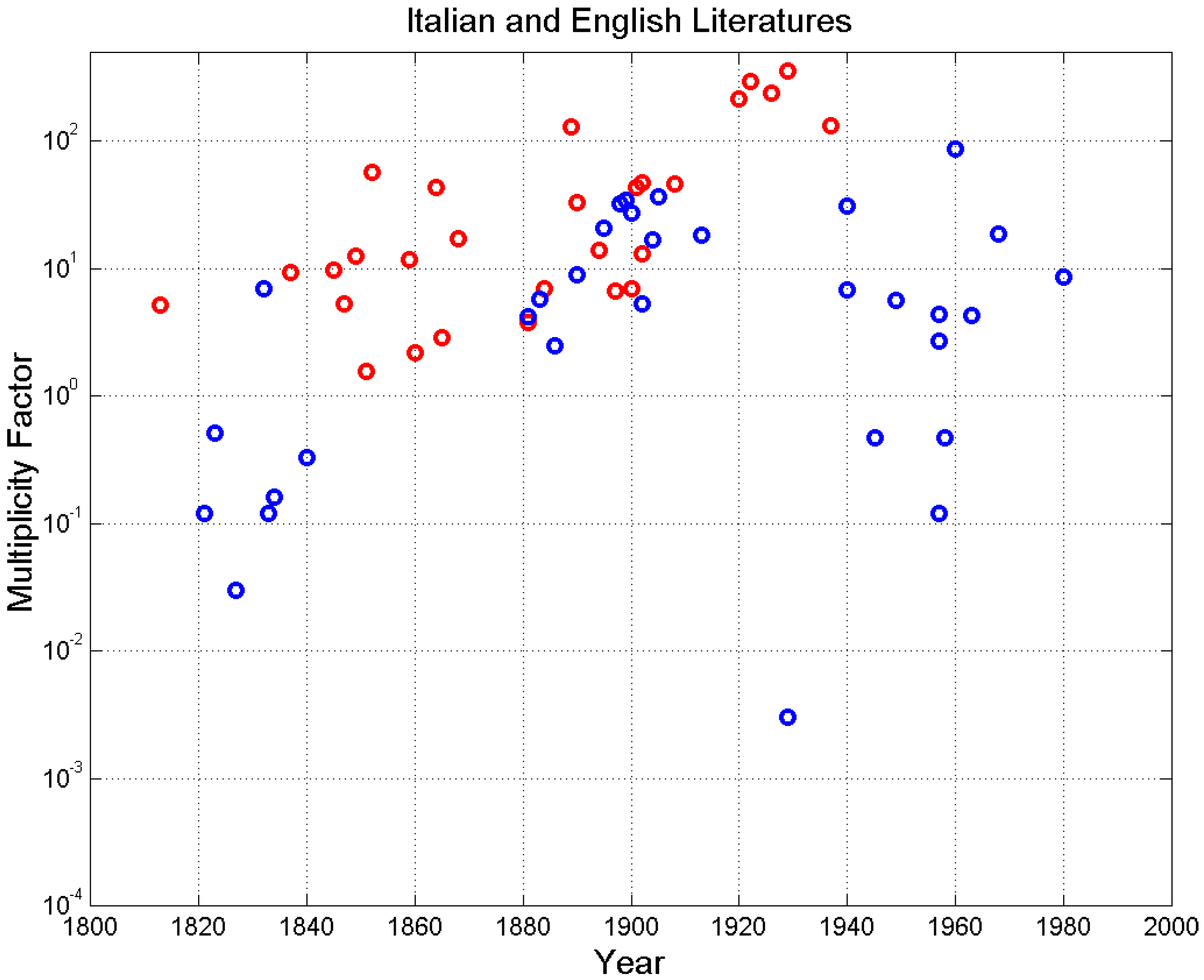
4. Experimental Multiplicity Factor of Sentences
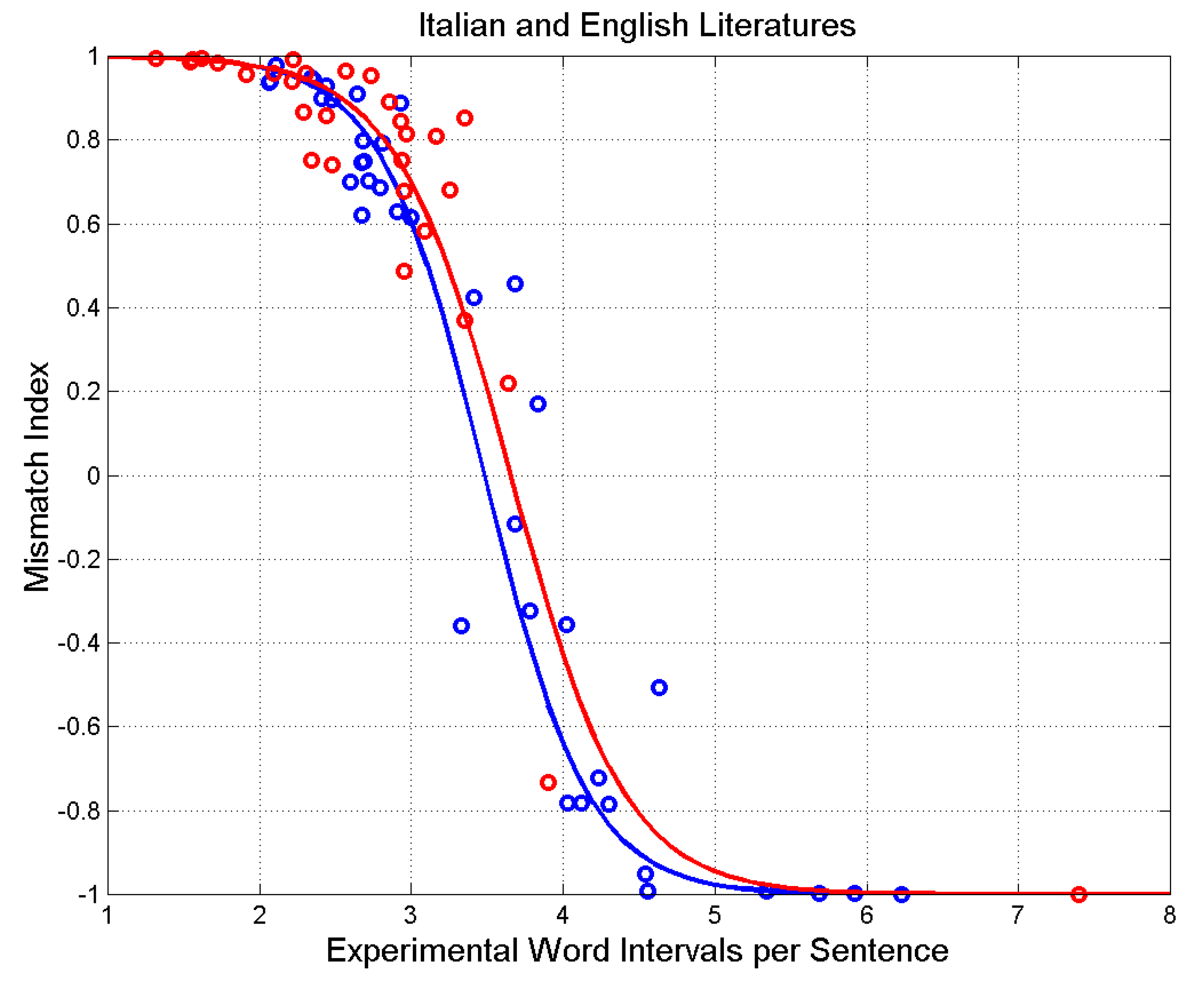
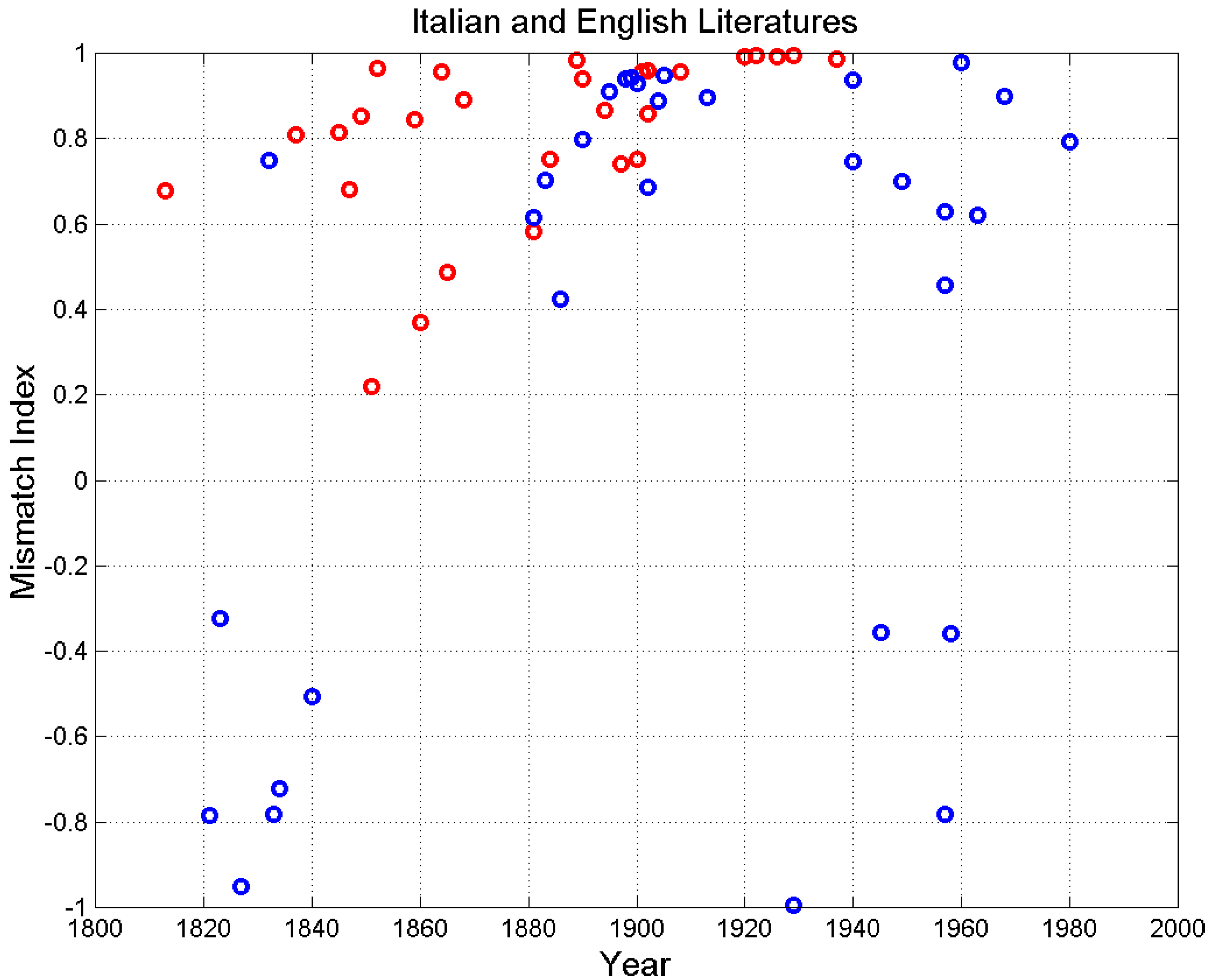
5. Mismatch Index
6. Time Dependence
7. Summary and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. List of Mathematical Symbols
| Symbol | Definition |
| Cells of E–STM buffer | |
| Universal readability index | |
| Mismatch index | |
| Word interval | |
| Word intervals in a sentence, chapter average | |
| Word intervals in a sentence, novel average | |
| Words in a sentence, chapter average | |
| Words in a sentence, novel average | |
| Experimental sentences | |
| Theoretical sentences written in cells | |
| Words in a sentence | |
| Three–parameter log–normal density function | |
| Gaussian PDF | |
| Mean value of Gaussian PDF | |
| standard deviation of Gaussian PDF | |
| Multiplicity factor | |
| Efficiency factor | |
| Mean value of log–normal PDF | |
| standard deviation of log–normal PDF |
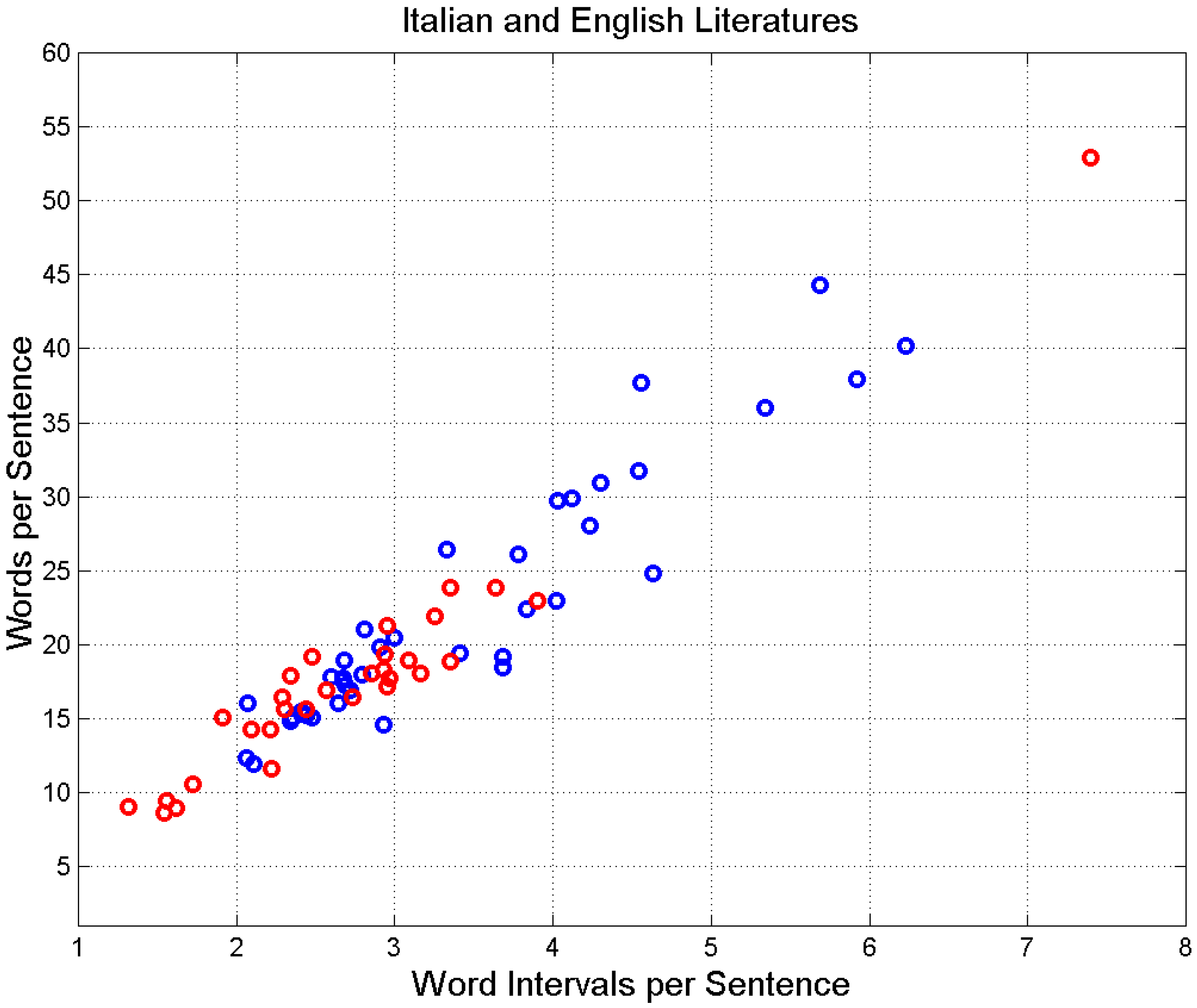
Appendix B. List of the Novels Considered from Italian and English Literature

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author (Literary Work, Year) | Sentences | ||||||
|---|---|---|---|---|---|---|---|
| Anonymous (I Fioretti di San Francesco, 1476) | 1064 | 4.65 | 37.70 | 8.24 | 4.56 | 0.004 | −0.99 |
| Bembo Pietro (Prose, 1525) | 1925 | 4.37 | 37.91 | 6.42 | 5.92 | 0.001 | −1.00 |
| Boccaccio Giovanni (Decameron, 1353) | 6147 | 4.48 | 44.27 | 7.79 | 5.69 | 0.001 | −1.00 |
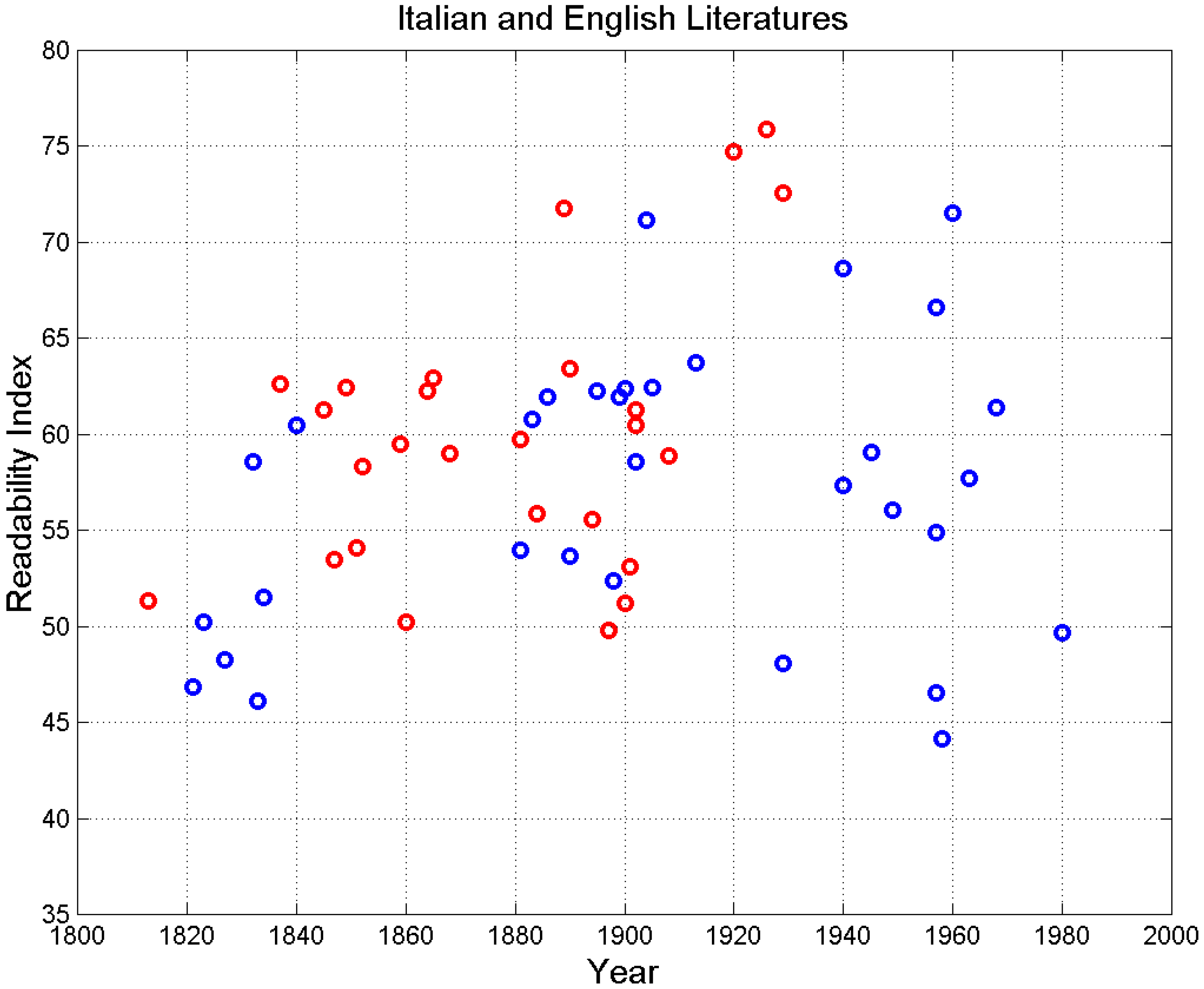
| Buzzati Dino (Il deserto dei tartari, 1940) | 3311 | 5.10 | 17.75 | 6.63 | 2.67 | 6.90 | 0.75 |
| Buzzati Dino (La boutique del mistero, 1968 *) | 4219 | 4.82 | 15.45 | 6.37 | 2.41 | 18.83 | 0.90 |
| Calvino (Il barone rampante, 1957 *) | 3864 | 4.63 | 19.87 | 6.73 | 2.91 | 4.37 | 0.63 |
| Calvino Italo (Marcovaldo, 1963 *) | 2000 | 4.74 | 17.60 | 6.59 | 2.67 | 4.28 | 0.62 |
| Cassola Carlo (La ragazza di Bube, 1960 *) | 5873 | 4.48 | 11.93 | 5.64 | 2.11 | 87.66 | 0.98 |
| Collodi Carlo (Pinocchio, 1883) | 2512 | 4.60 | 16.92 | 6.19 | 2.72 | 5.74 | 0.70 |
| Da Ponte Lorenzo (Vita, 1823) | 5459 | 4.71 | 26.15 | 6.91 | 3.78 | 0.51 | −0.32 |
| Deledda Grazia (Canne al vento, 1913, Nobel Prize 1926) | 4184 | 4.51 | 15.08 | 6.06 | 2.48 | 18.35 | 0.90 |
| D’Azeglio Massimo (Ettore Fieramosca, 1833) | 3182 | 4.64 | 29.77 | 7.36 | 4.03 | 0.12 | −0.78 |
| De Amicis Edmondo (Cuore, 1886) | 4775 | 4.55 | 19.43 | 5.61 | 3.41 | 2.48 | 0.42 |
| De Marchi Emilio (Demetrio Panelli, 1890) | 5363 | 4.70 | 18.95 | 7.06 | 2.68 | 8.95 | 0.80 |
| D’Annunzio Gabriele (Le novelle delle Pescara, 1902) | 3027 | 4.91 | 17.99 | 6.38 | 2.79 | 5.35 | 0.68 |
| Eco Umberto (Il nome della rosa, 1980 *) | 8490 | 4.81 | 21.08 | 7.46 | 2.81 | 8.70 | 0.79 |
| Fogazzaro (Il santo, 1905) | 6637 | 4.79 | 14.84 | 6.33 | 2.34 | 37.08 | 0.95 |
| Fogazzaro (Piccolo mondo antico, 1895) | 7069 | 4.79 | 16.08 | 6.10 | 2.64 | 20.98 | 0.91 |
| Gadda (Quer pasticciaccio brutto… 1957 *) | 5596 | 4.76 | 18.43 | 4.98 | 3.68 | 2.69 | 0.46 |
| Grossi Tommaso (Marco Visconti, 1834) | 5301 | 4.59 | 28.07 | 6.56 | 4.23 | 0.16 | −0.72 |
| Leopardi Giacomo (Operette morali, 1827) | 2694 | 4.70 | 31.78 | 6.90 | 4.54 | 0.03 | −0.95 |
| Levi Primo (Cristo si è fermato a Eboli, 1945 *) | 3611 | 4.73 | 22.94 | 5.70 | 4.02 | 0.47 | −0.36 |
| Machiavelli Niccolò (Il principe, 1532) | 702 | 4.71 | 40.17 | 6.45 | 6.23 | 0.0001 | −1.00 |
| Manzoni Alessandro (I promessi sposi, 1840) | 9766 | 4.60 | 24.83 | 5.30 | 4.63 | 0.33 | −0.51 |
| Manzoni Alessandro (Fermo e Lucia, 1821) | 7496 | 4.75 | 30.98 | 7.17 | 4.30 | 0.12 | −0.78 |
| Moravia Alberto (Gli indifferenti, 1929 *) | 2830 | 4.81 | 36.00 | 6.74 | 5.34 | 0.003 | −0.99 |
| Moravia Alberto (La ciociara, 1957 *) | 4271 | 4.56 | 29.93 | 7.28 | 4.12 | 0.12 | −0.78 |
| Pavese Cesare (La bella estate, 1940) | 2121 | 4.54 | 12.37 | 5.97 | 2.06 | 31.19 | 0.94 |
| Pavese Cesare (La luna e i falò, 1949 *) | 2544 | 4.47 | 17.83 | 6.83 | 2.60 | 5.64 | 0.70 |
| Pellico Silvio (Le mie prigioni, 1832) | 3148 | 4.80 | 17.27 | 6.50 | 2.69 | 7.00 | 0.75 |
| Pirandello Luigi (Il fu Mattia Pascal, 1904, Nobel Prize 1934) | 5284 | 4.63 | 14.57 | 4.94 | 2.93 | 16.72 | 0.89 |
| Sacchetti Franco (Trecentonovelle, 1392) | 8060 | 4.37 | 22.43 | 5.82 | 3.83 | 1.41 | 0.17 |
| Salernitano Masuccio (Il Novellino, 1525) | 1965 | 4.40 | 19.20 | 5.14 | 3.68 | 0.79 | −0.12 |
| Salgari Emilio (Il corsaro nero, 1899) | 6686 | 4.99 | 15.09 | 6.36 | 2.36 | 34.46 | 0.94 |
| Salgari Emilio (I minatori dell’Alaska, 1900) | 6094 | 5.01 | 15.24 | 6.25 | 2.44 | 27.21 | 0.93 |
| Svevo Italo (Senilità, 1898) | 4236 | 4.86 | 16.04 | 7.75 | 2.07 | 32.34 | 0.94 |
| Tomasi di Lampedusa (Il gattopardo, 1958 *) | 2893 | 4.99 | 26.42 | 7.90 | 3.33 | 0.47 | −0.36 |
| Verga (I Malavoglia, 1881) | 4401 | 4.46 | 20.45 | 6.82 | 3.00 | 4.21 | 0.62 |
| Literary Work (Author, Year) | Sentences | ||||||
|---|---|---|---|---|---|---|---|
| The Adventures of Oliver Twist (C. Dickens, 1837–1839) | 9121 | 4.23 | 18.04 | 5.70 | 3.16 | 9.46 | 0.81 |
| David Copperfield (C. Dickens, 1849–1850) | 19,610 | 4.04 | 18.83 | 5.61 | 3.35 | 12.63 | 0.85 |
| Bleak House (C. Dickens, 1852–1853) | 20,967 | 4.23 | 16.95 | 6.59 | 2.57 | 56.98 | 0.97 |
| A Tale of Two Cities (C. Dickens, 1859) | 8098 | 4.26 | 18.27 | 6.19 | 2.93 | 11.89 | 0.84 |
| Our Mutual Friend (C. Dickens, 1864–1865) | 17,409 | 4.22 | 16.46 | 6.03 | 2.73 | 43.41 | 0.95 |
| Matthew King James (1611) | 1040 | 4.27 | 22.96 | 5.90 | 3.90 | 0.15 | −0.73 |
| Robinson Crusoe (D. Defoe, 1719) | 2393 | 3.94 | 52.90 | 7.12 | 7.40 | 0.00002 | −1.00 |
| Pride and Prejudice (J. Austen, 1813) | 6013 | 4.40 | 21.31 | 7.16 | 2.95 | 5.20 | 0.68 |
| Wuthering Heights (E. Brontë, 1845–1846) | 6352 | 4.27 | 17.78 | 5.97 | 2.97 | 9.83 | 0.82 |
| Vanity Fair (W. Thackeray, 1847–1848) | 13,007 | 4.63 | 21.95 | 6.73 | 3.25 | 5.26 | 0.68 |
| Moby Dick (H. Melville, 1851) | 9582 | 4.52 | 23.82 | 6.45 | 3.64 | 1.56 | 0.22 |
| The Mill On The Floss (G. Eliot, 1860) | 9018 | 4.29 | 23.84 | 7.09 | 3.35 | 2.17 | 0.37 |
| Alice’s Adventures in Wonderland (L. Carroll, 1865) | 1629 | 3.96 | 17.19 | 5.79 | 2.95 | 2.90 | 0.49 |
| Little Women (L.M. Alcott, 1868–1869) | 10,593 | 4.18 | 18.09 | 6.30 | 2.85 | 17.34 | 0.89 |
| Treasure Island (R. L. Stevenson, 1881–1882) | 3824 | 4.02 | 18.93 | 6.05 | 3.09 | 3.79 | 0.58 |
| Adventures of Huckleberry Finn (M. Twain, 1884) | 5887 | 3.85 | 19.39 | 6.63 | 2.94 | 7.05 | 0.75 |
| Three Men in a Boat (J.K. Jerome, 1889) | 5341 | 4.25 | 10.55 | 6.14 | 1.72 | 130.27 | 0.98 |
| The Picture of Dorian Gray (O. Wilde, 1890) | 4292 | 4.19 | 14.30 | 6.29 | 2.21 | 33.02 | 0.94 |
| The Jungle Book (R. Kipling, 1894) | 3214 | 4.11 | 16.46 | 7.14 | 2.29 | 14.10 | 0.87 |
| The War of the Worlds (H.G. Wells, 1897) | 3306 | 4.38 | 19.22 | 7.67 | 2.48 | 6.72 | 0.74 |
| The Wonderful Wizard of Oz (L.F. Baum, 1900) | 2219 | 4.017 | 17.90 | 7.63 | 2.34 | 7.02 | 0.75 |
| The Hound of The Baskervilles (A.C. Doyle, 1901–1902) | 4080 | 4.15 | 15.07 | 7.83 | 1.91 | 43.87 | 0.96 |
| Peter Pan (J.M. Barrie, 1902) | 3177 | 4.12 | 15.65 | 6.35 | 2.44 | 13.07 | 0.86 |
| A Little Princess (F.H. Burnett, 1902–1905) | 4838 | 4.18 | 14.26 | 6.79 | 2.09 | 46.97 | 0.96 |
| Martin Eden (J. London, 1908–1909) | 9173 | 4.32 | 15.61 | 6.76 | 2.30 | 46.33 | 0.96 |
| Women in love (D.H. Lawrence, 1920) | 16,048 | 4.26 | 11.62 | 5.22 | 2.22 | 216.86 | 0.99 |
| The Secret Adversary (A. Christie, 1922) | 8536 | 4.28 | 8.97 | 5.52 | 1.62 | 294.34 | 0.99 |
| The Sun Also Rises (E. Hemingway, 1926) | 7614 | 3.92 | 9.43 | 6.02 | 1.56 | 237.94 | 0.99 |
| A Farewell to Arms (H. Hemingway,1929) | 10,324 | 3.94 | 9.05 | 6.80 | 1.32 | 356.00 | 0.99 |
| Of Mice and Men (J. Steinbeck, 1937) | 3463 | 4.02 | 8.63 | 5.61 | 1.54 | 133.19 | 0.99 |
References
- Matricciani, E. Is Short-Term Memory Made of Two Processing Units? Clues from Italian and English Literatures down Several Centuries. Information 2024, 15, 6. [Google Scholar] [CrossRef]
- Deniz, F.; Nunez-Elizalde, A.O.; Huth, A.G.; Gallant Jack, L. The Representation of Semantic Information Across Human Cerebral Cortex During Listening Versus Reading Is Invariant to Stimulus Modality. J. Neurosci. 2019, 39, 7722–7736. [Google Scholar] [CrossRef]
- Miller, G.A. The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychol. Rev. 1956, 63, 81–97. [Google Scholar] [CrossRef]
- Crowder, R.G. Short-term memory: Where do we stand? Mem. Cogn. 1993, 21, 142–145. [Google Scholar] [CrossRef]
- Lisman, J.E.; Idiart, M.A.P. Storage of 7 ± 2 Short-Term Memories in Oscillatory Subcycles. Science 1995, 267, 1512–1515. [Google Scholar] [CrossRef]
- Cowan, N. The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behav. Brain Sci. 2001, 24, 87–114. [Google Scholar] [CrossRef]
- Bachelder, B.L. The Magical Number 7 ± 2: Span Theory on Capacity Limitations. Behav. Brain Sci. 2001, 24, 116–117. [Google Scholar] [CrossRef]
- Saaty, T.L.; Ozdemir, M.S. Why the Magic Number Seven Plus or Minus Two. Math. Comput. Model. 2003, 38, 233–244. [Google Scholar] [CrossRef]
- Burgess, N.; Hitch, G.J. A revised model of short-term memory and long-term learning of verbal sequences. J. Mem. Lang. 2006, 55, 627–652. [Google Scholar] [CrossRef]
- Richardson, J.T.E. Measures of short-term memory: A historical review. Cortex 2007, 43, 635–650. [Google Scholar] [CrossRef]
- Mathy, F.; Feldman, J. What’s magic about magic numbers? Chunking and data compression in short-term memory. Cognition 2012, 122, 346–362. [Google Scholar] [CrossRef] [PubMed]
- Gignac, G.E. The Magical Numbers 7 and 4 Are Resistant to the Flynn Effect: No Evidence for Increases in Forward or Backward Recall across 85 Years of Data. Intelligence 2015, 48, 85–95. [Google Scholar] [CrossRef]
- Trauzettel-Klosinski, S.; Dietz, K. Standardized Assessment of Reading Performance: The New International Reading Speed Texts IreST. Investig. Ophthalmol. Vis. Sci. 2012, 53, 5452–5461. [Google Scholar] [CrossRef] [PubMed]
- Melton, A.W. Implications of Short-Term Memory for a General Theory of Memory. J. Verbal Learn. Verbal Behav. 1963, 2, 1–21. [Google Scholar] [CrossRef]
- Atkinson, R.C.; Shiffrin, R.M. The Control of Short-Term Memory. Sci. Am. 1971, 225, 82–91. [Google Scholar] [CrossRef]
- Murdock, B.B. Short-Term Memory. Psychol. Learn. Motiv. 1972, 5, 67–127. [Google Scholar]
- Baddeley, A.D.; Thomson, N.; Buchanan, M. Word Length and the Structure of Short-Term Memory. J. Verbal Learn. Verbal Behav. 1975, 14, 575–589. [Google Scholar] [CrossRef]
- Case, R.; Midian Kurland, D.; Goldberg, J. Operational efficiency and the growth of short-term memory span. J. Exp. Child Psychol. 1982, 33, 386–404. [Google Scholar] [CrossRef]
- Grondin, S. A temporal account of the limited processing capacity. Behav. Brain Sci. 2000, 24, 122–123. [Google Scholar] [CrossRef]
- Pothos, E.M.; Joula, P. Linguistic structure and short-term memory. Behav. Brain Sci. 2000, 138–139. [Google Scholar] [CrossRef]
- Conway, A.R.A.; Cowan, N.; Michael, F.; Bunting, M.F.; Therriaulta, D.J.; Minkoff, S.R.B. A latent variable analysis of working memory capacity, short-term memory capacity, processing speed, and general fluid intelligence. Intelligence 2002, 30, 163–183. [Google Scholar] [CrossRef]
- Jonides, J.; Lewis, R.L.; Nee, D.E.; Lustig, C.A.; Berman, M.G.; Moore, K.S. The Mind and Brain of Short-Term Memory. Annu. Rev. Psychol. 2008, 69, 193–224. [Google Scholar] [CrossRef] [PubMed]
- Barrouillest, P.; Camos, V. As Time Goes by: Temporal Constraints in Working Memory. Curr. Dir. Psychol. Sci. 2012, 21, 413–419. [Google Scholar] [CrossRef]
- Potter, M.C. Conceptual short term memory in perception and thought. Front. Psychol. 2012, 3, 113. [Google Scholar] [CrossRef]
- Jones, G.; Macken, B. Questioning short-term memory and its measurements: Why digit span measures long-term associative learning. Cognition 2015, 144, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Chekaf, M.; Cowan, N.; Mathy, F. Chunk formation in immediate memory and how it relates to data compression. Cognition 2016, 155, 96–107. [Google Scholar] [CrossRef]
- Norris, D. Short-Term Memory and Long-Term Memory Are Still Different. Psychol. Bull. 2017, 143, 992–1009. [Google Scholar] [CrossRef]
- Houdt, G.V.; Mosquera, C.; Napoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Islam, M.; Sarkar, A.; Hossain, M.; Ahmed, M.; Ferdous, A. Prediction of Attention and Short-Term Memory Loss by EEG Workload Estimation. J. Biosci. Med. 2023, 11, 304–318. [Google Scholar] [CrossRef]
- Rosenzweig, M.R.; Bennett, E.L.; Colombo, P.J.; Lee, P.D.W. Short-term, intermediate-term and Long-term memories. Behav. Brain Res. 1993, 57, 193–198. [Google Scholar] [CrossRef]
- Kaminski, J. Intermediate-Term Memory as a Bridge between Working and Long-Term Memory. J. Neurosci. 2017, 37, 5045–5047. [Google Scholar] [CrossRef][Green Version]
- Matricciani, E. Deep Language Statistics of Italian throughout Seven Centuries of Literature and Empirical Connections with Miller’s 7 ∓ 2 Law and Short-Term Memory. Open J. Stat. 2019, 9, 373–406. [Google Scholar] [CrossRef]
- Strinati, E.C.; Barbarossa, S. 6G Networks: Beyond Shannon towards Semantic and Goal-Oriented Communications. Comput. Netw. 2021, 190, 107930. [Google Scholar] [CrossRef]
- Shi, G.; Xiao, Y.; Li, Y.; Xie, X. From semantic communication to semantic-aware networking: Model, architecture, and open problems. IEEE Commun. Mag. 2021, 59, 44–50. [Google Scholar] [CrossRef]
- Xie, H.; Qin, Z.; Li, G.Y.; Juang, B.H. Deep learning enabled semantic communication systems. IEEE Trans. Signal Process. 2021, 69, 2663–2675. [Google Scholar] [CrossRef]
- Luo, X.; Chen, H.H.; Guo, Q. Semantic communications: Overview, open issues, and future research directions. IEEE Wirel. Commun. 2022, 29, 210–219. [Google Scholar] [CrossRef]
- Yang, W.; Du, H.; Liew, Z.Q.; Lim, W.Y.B.; Xiong, Z.; Niyato, D.; Chi, X.; Shen, X.; Miao, C. Semantic Communications for Future Internet: Fundamentals, Applications, and Challenges. IEEE Commun. Surv. Tutor. 2023, 25, 213–250. [Google Scholar] [CrossRef]
- Xie, H.; Qin, A. A lite distributed semantic communication system for internet of things. IEEE J. Sel. Areas Commun. 2021, 39, 142–153. [Google Scholar]
- Bellegarda, J.R. Exploiting Latent Semantic Information in Statistical Language Modeling. Proc. IEEE 2000, 88, 1279–1296. [Google Scholar] [CrossRef]
- D’Alfonso, S. On Quantifying Semantic Information. Information 2011, 2, 61–101. [Google Scholar] [CrossRef]
- Zhong, Y. A Theory of Semantic Information. China Commun. 2017, 14, 1–17. [Google Scholar] [CrossRef]
- Papoulis Papoulis, A. Probability & Statistics; Prentice Hall: Hoboken, NJ, USA, 1990. [Google Scholar]
- Matricciani, E. Readability Indices Do Not Say It All on a Text Readability. Analytics 2023, 2, 296–314. [Google Scholar] [CrossRef]
- Matricciani, E. The Theory of Linguistic Channels in Alphabetical Texts; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2024. [Google Scholar]
- Matricciani, E. Capacity of Linguistic Communication Channels in Literary Texts: Application to Charles Dickens’ Novels. Information 2023, 14, 68. [Google Scholar] [CrossRef]



















| IP | 1.689 | 0.180 |
| PF | 3.038 | 0.441 |
| MF | 0.849 | 0.483 |
| Words (Items Storeable) | E–STM Buffer Made of Cells | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 2 | 1 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 3 | 3 | 1 | 0 | 0 | 0 | 0 |
| 5 | 1 | 4 | 6 | 4 | 1 | 0 | 0 | 0 |
| 6 | 1 | 5 | 10 | 10 | 5 | 1 | 0 | 0 |
| 7 | 1 | 6 | 15 | 20 | 15 | 6 | 1 | 0 |
| 8 | 1 | 7 | 21 | 35 | 35 | 21 | 7 | 1 |
| 9 | 1 | 8 | 28 | 56 | 70 | 56 | 28 | 8 |
| 10 | 1 | 9 | 36 | 84 | 126 | 126 | 84 | 36 |
| 11 | 1 | 10 | 45 | 120 | 210 | 252 | 210 | 120 |
| 12 | 1 | 11 | 55 | 165 | 330 | 462 | 462 | 330 |
| 13 | 1 | 12 | 66 | 220 | 495 | 792 | 1254 | 792 |
| 14 | 1 | 13 | 78 | 286 | 715 | 1287 | 2046 | 2046 |
| 15 | 1 | 14 | 91 | 364 | 1001 | 2002 | 3333 | 4092 |
| 16 | 1 | 15 | 105 | 455 | 1365 | 3003 | 5335 | 7425 |
| 17 | 1 | 16 | 120 | 560 | 1820 | 4368 | 8338 | 12,760 |
| 18 | 1 | 17 | 136 | 680 | 2380 | 6188 | 12,706 | 21,098 |
| 19 | 1 | 18 | 153 | 816 | 3060 | 8568 | 18,894 | 33,804 |
| 20 | 1 | 19 | 171 | 969 | 3876 | 11,628 | 27,462 | 52,698 |
| 21 | 1 | 20 | 190 | 1140 | 4845 | 15,504 | 39,090 | 80,160 |
| 22 | 1 | 21 | 210 | 1330 | 5985 | 20,349 | 54,594 | 119,250 |
| 23 | 1 | 22 | 231 | 1540 | 7315 | 26,334 | 74,943 | 173,844 |
| 24 | 1 | 23 | 253 | 1771 | 8855 | 33,649 | 101,277 | 248,787 |
| 25 | 1 | 24 | 276 | 2024 | 10,626 | 42,504 | 134,926 | 350,064 |
| 26 | 1 | 25 | 300 | 2300 | 12,650 | 53,130 | 177,430 | 484,990 |
| 27 | 1 | 26 | 325 | 2600 | 14,950 | 65,780 | 230,560 | 662,420 |
| 28 | 1 | 27 | 351 | 2925 | 17,550 | 80,730 | 296,340 | 892,980 |
| 29 | 1 | 28 | 378 | 3276 | 20,475 | 98,280 | 377,070 | 1,189,320 |
| 30 | 1 | 29 | 406 | 3654 | 23,751 | 118,755 | 475,350 | 1,566,390 |
| 31 | 1 | 30 | 435 | 4060 | 27,405 | 142,506 | 594,105 | 2,041,740 |
| 32 | 1 | 31 | 465 | 4495 | 31,465 | 173,971 | 768,076 | 2,635,845 |
| 33 | 1 | 32 | 496 | 4960 | 35,960 | 205,436 | 973,512 | 3,403,921 |
| 34 | 1 | 33 | 528 | 5456 | 40,920 | 241,396 | 1,178,948 | 4,377,433 |
| 35 | 1 | 34 | 561 | 5984 | 46,376 | 282,316 | 1,461,264 | 5,556,381 |
| 36 | 1 | 35 | 595 | 6545 | 52,360 | 328,692 | 1,789,956 | 7,017,645 |
| 37 | 1 | 36 | 630 | 7140 | 58,905 | 381,052 | 2,118,648 | 8,807,601 |
| 38 | 1 | 37 | 666 | 7770 | 66,045 | 439,957 | 2,499,700 | 10,926,249 |
| 39 | 1 | 38 | 703 | 8436 | 73,815 | 506,002 | 2,939,657 | 13,425,949 |
| 40 | 1 | 39 | 741 | 9139 | 82,251 | 579,817 | 3,519,474 | 16,365,606 |
| 41 | 1 | 40 | 780 | 9880 | 91,390 | 662,068 | 4,099,291 | 19,885,080 |
| 42 | 1 | 41 | 820 | 10,660 | 101,270 | 753,458 | 4,761,359 | 23,984,371 |
| 43 | 1 | 42 | 861 | 11,480 | 111,930 | 854,728 | 5,514,817 | 29,499,188 |
| 44 | 1 | 43 | 903 | 12,341 | 123,410 | 966,658 | 6,369,545 | 35,014,005 |
| 45 | 1 | 44 | 946 | 13,244 | 135,751 | 1,090,068 | 7,336,203 | 41,383,550 |
| 46 | 1 | 45 | 990 | 14,190 | 148,995 | 1,225,819 | 8,426,271 | 48,719,753 |
| 47 | 1 | 46 | 1035 | 15,180 | 163,185 | 1,374,814 | 9,652,090 | 58,371,843 |
| 48 | 1 | 47 | 1081 | 16,215 | 178,365 | 1,537,999 | 11,026,904 | 68,023,933 |
| 49 | 1 | 48 | 1128 | 17,296 | 194,580 | 1,716,364 | 12,564,903 | 79,050,837 |
| 50 | 1 | 49 | 1176 | 18,424 | 211,876 | 1,910,944 | 14,281,267 | 91,615,740 |
| 51 | 1 | 50 | 1225 | 19,600 | 230,300 | 2,122,820 | 16,192,211 | 105,897,007 |
| 52 | 1 | 51 | 1275 | 20,825 | 251,125 | 2,353,120 | 18,315,031 | 122,089,218 |
| 53 | 1 | 52 | 1326 | 22,100 | 273,225 | 2,604,245 | 20,668,151 | 140,404,249 |
| 54 | 1 | 53 | 1378 | 23,426 | 296,651 | 2,877,470 | 23,272,396 | 161,072,400 |
| 55 | 1 | 54 | 1431 | 24,804 | 320,077 | 3,174,121 | 26,149,866 | 184,344,796 |
| 56 | 1 | 55 | 1485 | 26,235 | 344,881 | 3,494,198 | 29,323,987 | 210,494,662 |
| 57 | 1 | 56 | 1540 | 27,720 | 371,116 | 3,839,079 | 32,818,185 | 239,818,649 |
| 58 | 1 | 57 | 1596 | 29,260 | 398,836 | 4,210,195 | 36,657,264 | 272,636,834 |
| 59 | 1 | 58 | 1653 | 30,856 | 428,096 | 4,609,031 | 40,867,459 | 309,294,098 |
| 60 | 1 | 59 | 1711 | 32,509 | 458,952 | 5,037,127 | 45,476,490 | 350,161,557 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matricciani, E. A Mathematical Structure Underlying Sentences and Its Connection with Short–Term Memory. AppliedMath 2024, 4, 120-142. https://doi.org/10.3390/appliedmath4010007
Matricciani E. A Mathematical Structure Underlying Sentences and Its Connection with Short–Term Memory. AppliedMath. 2024; 4(1):120-142. https://doi.org/10.3390/appliedmath4010007
Chicago/Turabian StyleMatricciani, Emilio. 2024. "A Mathematical Structure Underlying Sentences and Its Connection with Short–Term Memory" AppliedMath 4, no. 1: 120-142. https://doi.org/10.3390/appliedmath4010007
APA StyleMatricciani, E. (2024). A Mathematical Structure Underlying Sentences and Its Connection with Short–Term Memory. AppliedMath, 4(1), 120-142. https://doi.org/10.3390/appliedmath4010007