
Uncertainty Quantification with Deep Ensemble Methods for Super-Resolution of Sentinel 2 Satellite Images †


Abstract
:1. Introduction
2. Methods
2.1. Bayesian Methods for Uncertainty Quantification in Deep Neural Networks
2.1.1. Bayesian Methods and Deep Ensembles
2.1.2. Utilizing the Loss-Weighted Deep Ensembles
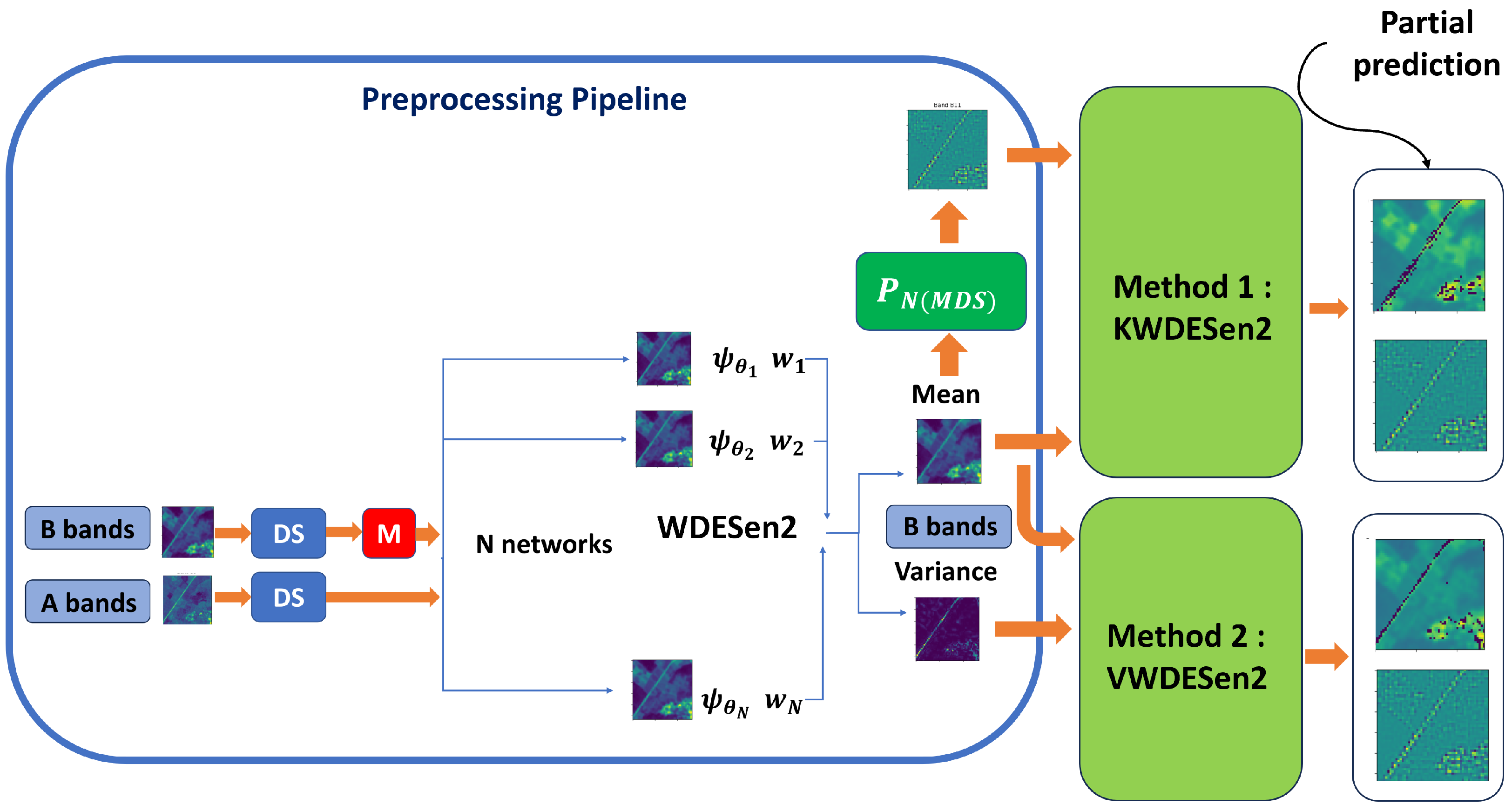
2.1.3. Derivation of Ensemble Weights: Contribution Ratio Control
2.2. Architecture of a Weighted Deep Ensemble for the Super-Resolution of Satellite Data: WDESen2
2.2.1. Kernel Component Exploration
2.3. Evaluation of the Predicted Variance and Kernel Projection of the Predictions of WDESen2
2.4. Dataset Splits

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Split | Patches | ||
|---|---|---|---|---|
| Tropical landscape/farmlands | 1 | Training Validation Test | ||
| Mountains landscape | 9 | Training Validation Test | 58,500, |
3. Results
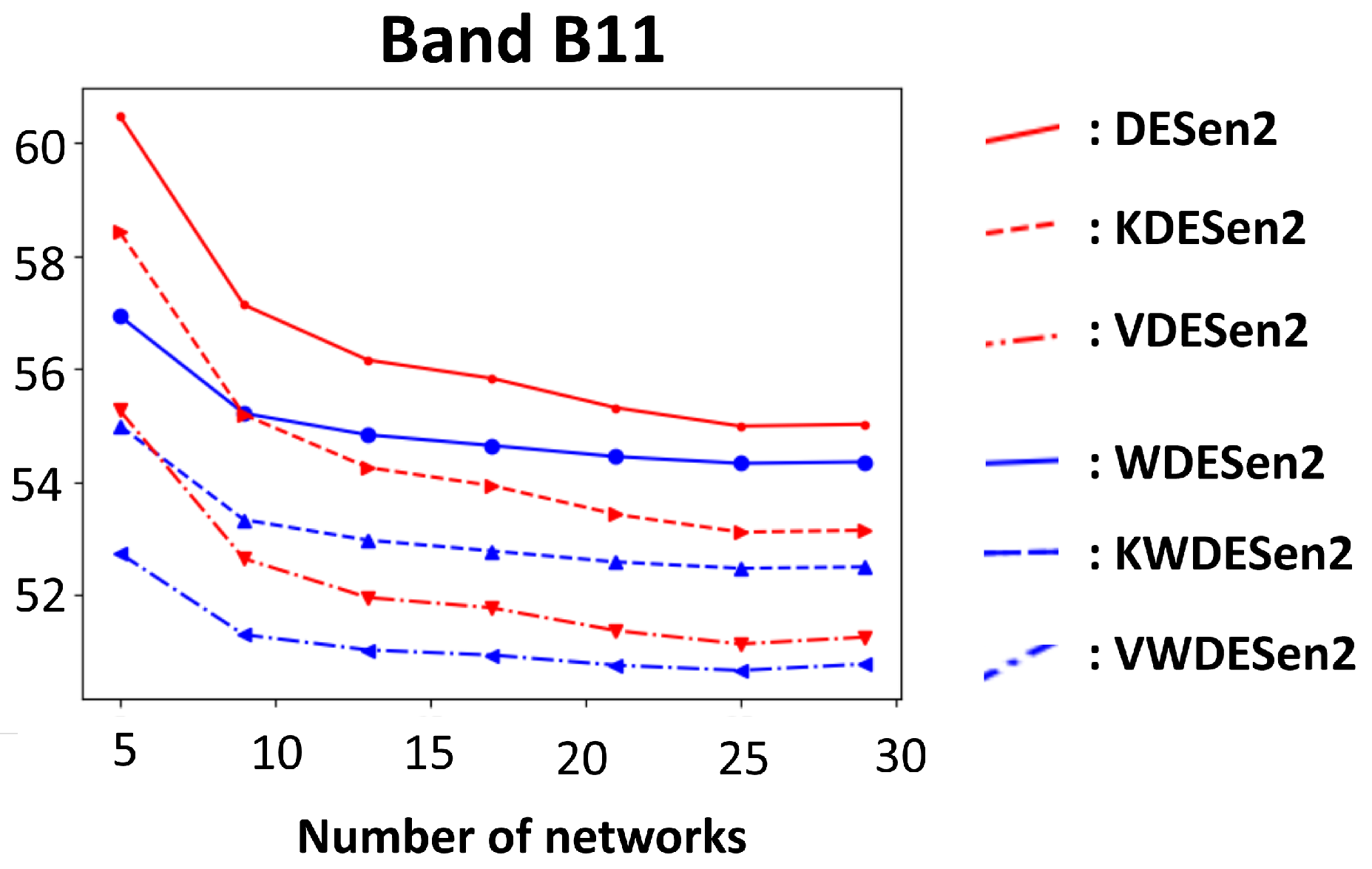
3.1. Linking Uncertainties and Physical Patterns on the Ground
3.2. Selective Prediction: Improving Accuracy with Uncertainty and Kernel Projections
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mura, M.; Bottalico, F.; Giannetti, F.; Bertani, R.; Giannini, R.; Mancini, M.; Orlandini, S.; Travaglini, D.; Chirici, G. Exploiting the capabilities of the Sentinel-2 multi spectral instrument for predicting growing stock volume in forest ecosystems. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 126–134. [Google Scholar] [CrossRef]
- Castillo, J.A.A.; Apan, A.A.; Maraseni, T.N.; Salmo, S.G. Estimation and mapping of above-ground biomass of mangrove forests and their replacement land uses in the Philippines using Sentinel imagery. ISPRS J. Photogramm. Remote Sens. 2017, 134, 70–85. [Google Scholar] [CrossRef]
- Toming, K.; Kutser, T.; Laas, A.; Sepp, M.; Paavel, B.; Noges, T. First Experiences in Mapping LakeWater Quality Parameters with Sentinel-2 MSI Imagery. Remote Sens. 2016, 8, 640. [Google Scholar] [CrossRef]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E. Super-Resolution of Sentinel-2 Images: Learning a Globally Applicable Deep Neural Network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2565–2586. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Brodu, N. Super-resolving multiresolution images with band-independent geometry of multispectral pixels. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4610–4617. [Google Scholar] [CrossRef]
- Dian, R.; Li, S.; Fang, L.; Bioucas-Dias, J. Hyperspectral image super-resolution via local low-rank and sparse representations. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4003–4006. [Google Scholar]
- Ulfarsson, M.O.; Palsson, F.; Dalla Mura, M.; Sveinsson, J.R. Sentinel-2 sharpening using a reduced-rank method. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6408–6420. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6405–6416. [Google Scholar]
- Omisore, O.M.; Akinyemi, T.O.; Du, W.; Duan, W.; Orji, R.; Do, T.N.; Wang, L. Weighting-Based Deep Ensemble Learning for Recognition of Interventionalists’ Hand Motions During Robot-Assisted Intravascular Catheterization. IEEE Trans. Hum. Mach. Syst. 2022, 53, 215–227. [Google Scholar] [CrossRef]
- Gupta, R.; Bhatnagar, A.S.; Singh, G. A Weighted Deep Ensemble for Indian Sign Language Recognition. IETE J. Res. 2023. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.M.; Triebel, R.; Jung, P.; Roscher, R.; et al. A Survey of Uncertainty in Deep Neural Networks. Artif. Intell. Rev. 2021, 56, 1513–1589. [Google Scholar] [CrossRef]
- Gruber, C.; Schenk, P.O.; Schierholz, M.; Kreuter, F.; Kauermann, G. Sources of Uncertainty in Machine Learning—A Statisticians’ View. arXiv 2023, arXiv:2305.16703. [Google Scholar]
- Bhadra, S.; Kelkar, V.A.; Brooks, F.J.; Anastasio, M.A. On hallucinations in tomographic image reconstruction. IEEE Trans. Med. Imaging 2021, 40, 3249–3260. [Google Scholar] [CrossRef] [PubMed]
- El-Yaniv, R. On the Foundations of Noise-free Selective Classification. J. Mach. Learn. Res. 2010, 11, 1605–1641. [Google Scholar]
- Jiang, W.; Zhao, Y.; Wang, Z. Risk-controlled selective prediction for regression deep neural network models. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Wilson, A.G.; Izmailov, P. Bayesian Deep Learning and a Probabilistic Perspective of Generalization. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Online, 2–6 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Courrieu, P. Fast Computation of Moore-Penrose Inverse Matrices. Neural Inf. Process. Lett. Rev. 2008, 8, 25–29. [Google Scholar]







| B5 | B6 | B7 | B8a | B11 | B12 | Average | |
|---|---|---|---|---|---|---|---|
| RMSE | |||||||
| Bicubic | 93.2 | 105.1 | 124.6 | 133.6 | 105.4 | 94.8 | 109.4 |
| DSen2 | 44.5 | 54.3 | 58.9 | 60.2 | 62.5 | 53.0 | 55.5 |
| DESen2 | 35.7 | 43.6 | 50.8 | 52.8 | 55.1 | 45.8 | 47.3 |
| WDESen2 | 34.6 | 42.6 | 50.1 | 52.4 | 54.4 | 45.5 | 46.6 |
| KWDESen2 | 30.9 | 39.4 | 46.2 | 48.3 | 49.7 | 38.2 | 42.1 |
| VWDESen2 | 28.7 | 37.6 | 44.0 | 46.0 | 48.0 | 35.8 | 40.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iagaru, D.; Gottschling, N.M. Uncertainty Quantification with Deep Ensemble Methods for Super-Resolution of Sentinel 2 Satellite Images. Phys. Sci. Forum 2023, 9, 4. https://doi.org/10.3390/psf2023009004
Iagaru D, Gottschling NM. Uncertainty Quantification with Deep Ensemble Methods for Super-Resolution of Sentinel 2 Satellite Images. Physical Sciences Forum. 2023; 9(1):4. https://doi.org/10.3390/psf2023009004
Chicago/Turabian StyleIagaru, David, and Nina Maria Gottschling. 2023. "Uncertainty Quantification with Deep Ensemble Methods for Super-Resolution of Sentinel 2 Satellite Images" Physical Sciences Forum 9, no. 1: 4. https://doi.org/10.3390/psf2023009004
APA StyleIagaru, D., & Gottschling, N. M. (2023). Uncertainty Quantification with Deep Ensemble Methods for Super-Resolution of Sentinel 2 Satellite Images. Physical Sciences Forum, 9(1), 4. https://doi.org/10.3390/psf2023009004