
AsymmeTree: A Flexible Python Package for the Simulation of Complex Gene Family Histories

Abstract
:1. Introduction
2. Related Work
3. Simulation of Species Trees and Gene Trees
3.1. Overview
3.2. Species Trees
- (a)
- the number N of (extant) species,
- (b)
- the age t of the tree, i.e., the time span between the root and the (non-loss) leaves, or
- (c)
- both N and t.
3.3. Gene Trees
3.4. Evolution Rate Heterogeneity
3.5. Pruning of Loss Branches
4. Simulation of Sequences
4.1. Overview
4.2. Substitution Model
4.3. Indel Model
4.4. Heterogeneity Model
4.5. True Alignment
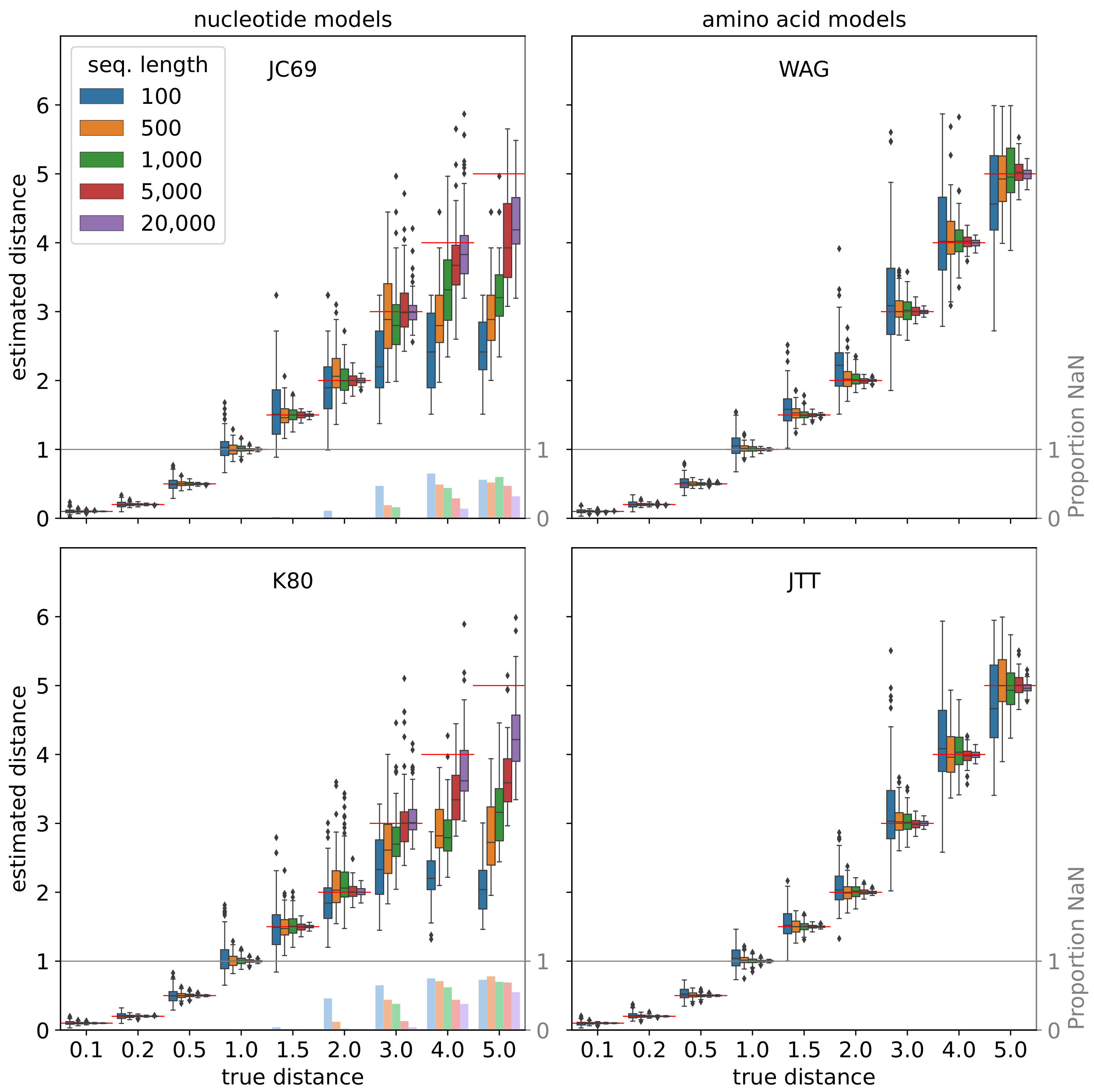
5. Benchmarking and Validation
6. Availability
7. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| (E)BDP | (episodic) birth-death process |
| GFH | gene family history |
| HGT | horizontal gene transfer |
| MSA | multiple sequence alignment |
References
- Ohno, S. Evolution by Gene Duplication; Springer: Berlin/Heidelberg, Germany, 1970. [Google Scholar] [CrossRef]
- Force, A.; Lynch, M.; Pickett, F.B.; Amores, A.; Yan, Y.L.; Postlethwait, J. Preservation of duplicate genes by complementary, degenerative mutations. Genetics 1999, 151, 1531–1545. [Google Scholar] [CrossRef] [PubMed]
- Lynch, M.; Conery, J.S. The evolutionary fate and consequences of duplicate genes. Science 2000, 290, 1151–1155. [Google Scholar] [CrossRef] [PubMed]
- Birchler, J.A.; Yang, H. The multiple fates of gene duplications: Deletion, hypofunctionalization, subfunctionalization, neofunctionalization, dosage balance constraints, and neutral variation. Plant Cell 2022, 34, 2466–2474. [Google Scholar] [CrossRef]
- Tatusov, R.L.; Koonin, E.V.; Lipman, D.J. A genomic perspective on protein families. Science 1997, 278, 631–637. [Google Scholar] [CrossRef]
- Zahn-Zabal, M.; Dessimoz, C.; Glover, N.M. Identifying orthologs with OMA: A primer. F1000Research 2020, 9, 27. [Google Scholar] [CrossRef] [PubMed]
- Fitch, W.M. Distinguishing homologous from analogous proteins. Syst. Zool. 1970, 19, 99–113. [Google Scholar] [CrossRef]
- Roth, A.C.J.; Gonnet, G.H.; Dessimoz, C. Algorithm of OMA for large-scale orthology inference. BMC Bioinform. 2008, 9, 518. [Google Scholar] [CrossRef]
- Hellmuth, M.; Hernandez-Rosales, M.; Huber, K.T.; Moulton, V.; Stadler, P.F.; Wieseke, N. Orthology Relations, Symbolic Ultrametrics, and Cographs. J. Math. Biol. 2013, 66, 399–420. [Google Scholar] [CrossRef]
- Gabaldón, T.; Koonin, E.V. Functional and evolutionary implications of gene orthology. Nat. Rev. Genet. 2013, 14, 360–366. [Google Scholar] [CrossRef]
- Altenhoff, A.M.; Boeckmann, B.; Capella-Gutierrez, S.; Dalquen, D.A.; DeLuca, T.; Forslund, K.; Huerta-Cepas, J.; Linard, B.; Pereira, C.; Pryszcz, L.P.; et al. Standardized benchmarking in the quest for orthologs. Nat. Methods 2016, 13, 425–430. [Google Scholar] [CrossRef]
- Nichio, B.T.L.; Marchaukoski, J.N.; Raittz, R.T. New Tools in Orthology Analysis: A Brief Review of Promising Perspectives. Front. Genet. 2017, 8, 165. [Google Scholar] [CrossRef] [PubMed]
- Setubal, J.C.; Stadler, P.F. Gene Phyologenies and Orthologous Groups. In Comparative Genomics; Setubal, J.C., Stadler, P.F., Stoye, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1704, pp. 1–28. [Google Scholar] [CrossRef]
- Pascual-Anaya, J.; D’Aniello, S.; Kuratani, S.; Garcia-Fernàndez, J. Evolution of Hox gene clusters in deuterostomes. BMC Dev. Biol. 2013, 13, 26. [Google Scholar] [CrossRef] [PubMed]
- Stadler, P.F.; Geiß, M.; Schaller, D.; López Sánchez, A.; Gonzalez Laffitte, M.; Valdivia, D.; Hellmuth, M.; Hernandez Rosales, M. From pairs of most similar sequences to phylogenetic best matches. Alg. Mol. Biol. 2020, 15, 5. [Google Scholar] [CrossRef]
- Schaller, D.; Geiß, M.; Stadler, P.F.; Hellmuth, M. Complete Characterization of Incorrect Orthology Assignments in Best Match Graphs. J. Math. Biol. 2021, 82, 20. [Google Scholar] [CrossRef] [PubMed]
- Talevich, E.; Invergo, B.M.; Cock, P.J.; Chapman, B.A. Bio.Phylo: A unified toolkit for processing, analyzing and visualizing phylogenetic trees in Biopython. BMC Bioinform. 2012, 13, 209. [Google Scholar] [CrossRef] [PubMed]
- Huerta-Cepas, J.; Serra, F.; Bork, P. ETE 3: Reconstruction, Analysis, and Visualization of Phylogenomic Data. Mol. Biol. Evol. 2016, 33, 1635–1638. [Google Scholar] [CrossRef]
- Schaller, D.; Hellmuth, M.; Stadler, P.F. A simpler linear-time algorithm for the common refinement of rooted phylogenetic trees on a common leaf set. Alg. Mol. Biol. 2021, 16, 23. [Google Scholar] [CrossRef]
- Aho, A.V.; Sagiv, Y.; Szymanski, T.G.; Ullman, J.D. Inferring a tree from lowest common ancestors with an application to the optimization of relational expressions. SIAM J. Comput. 1981, 10, 405–421. [Google Scholar] [CrossRef]
- Deng, Y.; Fernández-Baca, D. Fast Compatibility Testing for Rooted Phylogenetic Trees. Algorithmica 2018, 80, 2453–2477. [Google Scholar] [CrossRef]
- Keller-Schmidt, S.; Klemm, K. A model of macroevolution as a branching process based on innovations. Adv. Complex Syst. 2012, 15, 1250043. [Google Scholar] [CrossRef]
- Stadler, T. Simulating trees with a fixed number of extant species. Syst. Biol. 2011, 60, 676–684. [Google Scholar] [CrossRef] [PubMed]
- Byrne, K.P.; Wolfe, K.H. Consistent Patterns of Rate Asymmetry and Gene Loss Indicate Widespread Neofunctionalization of Yeast Genes After Whole-Genome Duplication. Genetics 2007, 175, 1341–1350. [Google Scholar] [CrossRef] [PubMed]
- Mallo, D.; De Oliveira Martins, L.; Posada, D. SimPhy: Phylogenomic Simulation of Gene, Locus, and Species Trees. Syst. Biol. 2016, 65, 334–344. [Google Scholar] [CrossRef] [PubMed]
- Kundu, S.; Bansal, M.S. SaGePhy: An improved phylogenetic simulation framework for gene and subgene evolution. Bioinformatics 2019, 35, 3496–3498. [Google Scholar] [CrossRef] [PubMed]
- Kendall, D.G. On the Generalized “Birth-and-Death” Process. Ann. Math. Statist. 1948, 19, 1–15. [Google Scholar] [CrossRef]
- Hagen, O.; Stadler, T. TreeSimGM: Simulating phylogenetic trees under general Bellman–Harris models with lineage-specific shifts of speciation and extinction in R. Methods Ecol. Evol. 2018, 9, 754–760. [Google Scholar] [CrossRef]
- Höhna, S.; May, M.R.; Moore, B.R. TESS: An R package for efficiently simulating phylogenetic trees and performing Bayesian inference of lineage diversification rates. Bioinformatics 2016, 32, 789–791. [Google Scholar] [CrossRef]
- Louca, S. Simulating trees with millions of species. Bioinformatics 2020, 36, 2907–2908. [Google Scholar] [CrossRef]
- Felsenstein, J. Inferring Phylogenies; Sinauer Associates: Sunderland, MA, USA, 2004. [Google Scholar]
- Yang, Z. Computational Molecular Evolution; Oxford Series in Ecology and Evolution; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Rambaut, A.; Grassly, N.C. Seq-Gen: An application for the Monte Carlo simulation of DNA sequence evolution along phylogenetic trees. Comput. Appl. Biosci. 1997, 13, 235–238. [Google Scholar] [CrossRef]
- Cartwright, R.A. DNA assembly with gaps (Dawg): Simulating sequence evolution. Bioinformatics 2005, 21, iii31–iii38. [Google Scholar] [CrossRef]
- Fletcher, W.; Yang, Z. INDELible: A Flexible Simulator of Biological Sequence Evolution. Mol. Biol. Evol. 2009, 26, 1879–1888. [Google Scholar] [CrossRef] [PubMed]
- Ly-Trong, N.; Naser-Khdour, S.; Lanfear, R.; Minh, B.Q. AliSim: A Fast and Versatile Phylogenetic Sequence Simulator for the Genomic Era. Mol. Biol. Evol. 2022, 39, msac092. [Google Scholar] [CrossRef] [PubMed]
- Spielman, S.J.; Wilke, C.O. Pyvolve: A Flexible Python Module for Simulating Sequences along Phylogenies. PLoS ONE 2015, 10, e0139047. [Google Scholar] [CrossRef]
- Rusin, L.Y.; Lyubetskaya, E.; Gorbunov, K.Y.; Lyubetsky, V. Reconciliation of gene and species trees. BioMed Res. Int. 2014, 2014, 642089. [Google Scholar] [CrossRef] [PubMed]
- Altenhoff, A.M.; Glover, N.M.; Dessimoz, C. Inferring Orthology and Paralogy. In Evolutionary Genomics; Anisimova, M., Ed.; Springer: New York, NY, USA, 2019; Volume 1910, pp. 149–175. [Google Scholar] [CrossRef]
- Sjöstrand, J.; Arvestad, L.; Lagergren, J.; Sennblad, B. GenPhyloData: Realistic simulation of gene family evolution. BMC Bioinform. 2013, 14, 209. [Google Scholar] [CrossRef]
- Davín, A.A.; Tricou, T.; Tannier, E.; de Vienne, D.M.; Szöllosi, G.J. Zombi: A phylogenetic simulator of trees, genomes and sequences that accounts for dead linages. Bioinformatics 2020, 36, 1286–1288. [Google Scholar] [CrossRef]
- Dalquen, D.A.; Anisimova, M.; Gonnet, G.H.; Dessimoz, C. ALF—A Simulation Framework for Genome Evolution. Mol. Biol. Evol. 2012, 29, 1115–1123. [Google Scholar] [CrossRef]
- Gonnet, G.H.; Hallett, M.T.; Korostensky, C.; Bernardin, L. Darwin v. 2.0: An interpreted computer language for the biosciences. Bioinformatics 2000, 16, 101–103. [Google Scholar] [CrossRef]
- Yue, J.X.; Liti, G. simuG: A general-purpose genome simulator. Bioinformatics 2019, 35, 4442–4444. [Google Scholar] [CrossRef]
- Price, A.; Gibas, C. Simulome: A genome sequence and variant simulator. Bioinformatics 2017, 33, 1876–1878. [Google Scholar] [CrossRef]
- Pattnaik, S.; Gupta, S.; Rao, A.A.; Panda, B. SInC: An accurate and fast error-model based simulator for SNPs, Indels and CNVs coupled with a read generator for short-read sequence data. BMC Bioinform. 2014, 15, 40. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Jin, L.; Leebens-Mack, J.H.; Sankoff, D. Validation of Automated Chromosome Recovery in the Reconstruction of Ancestral Gene Order. Algorithms 2021, 14, 160. [Google Scholar] [CrossRef]
- Rasmussen, M.D.; Kellis, M. Unified modeling of gene duplication, loss, and coalescence using a locus tree. Genome Res. 2012, 22, 755–765. [Google Scholar] [CrossRef] [PubMed]
- Yule, G.U. A mathematical theory of evolution, based on the conclusions of Dr. J. C. Willis, F. R. S. Phil. Trans. R. Soc. Lond. B 1924, 213, 21–87. [Google Scholar] [CrossRef]
- Maddison, W. Reconstructing character evolution on polytomous cladograms. Cladistics 1989, 5, 365–377. [Google Scholar] [CrossRef] [PubMed]
- DeSalle, R.; Absher, R.; Amato, G. Speciation and phylogenetic resolution. Trends Ecol. Evol. 1994, 9, 297–298. [Google Scholar] [CrossRef]
- Walsh, H.E.; Kidd, M.G.; Moum, T.; Friesen, V.L. Polytomies and the power of phylogenetic inference. Evolution 1999, 53, 932–937. [Google Scholar] [CrossRef] [PubMed]
- Lafond, M.; Chauve, C.; Dondi, R.; El-Mabrouk, N. Polytomy refinement for the correction of dubious duplications in gene trees. Bioinformatics 2014, 30, i519–i526. [Google Scholar] [CrossRef]
- Larridon, I.; Villaverde, T.; Zuntini, A.R.; Pokorny, L.; Brewer, G.E.; Epitawalage, N.; Fairlie, I.; Hahn, M.; Kim, J.; Maguilla, E.; et al. Tackling Rapid Radiations with Targeted Sequencing. Front. Plant Sci. 2020, 10, 1655. [Google Scholar] [CrossRef]
- Kliman, R.M.; Andolfatto, P.; Coyne, J.A.; Depaulis, F.; Kreitman, M.; Berry, A.J.; McCarter, J.; Wakeley, J.; Hey, J. The population genetics of the origin and divergence of the Drosophila simulans complex species. Genetics 2000, 156, 1913–1931. [Google Scholar] [CrossRef]
- Takahashi, K.; Terai, Y.; Nishida, M.; Okada, N. Phylogenetic relationships and ancient incomplete lineage sorting among cichlid fishes in Lake Tanganyika as revealed by analysis of the insertion of retroposons. Mol. Biol. Evol. 2001, 18, 2057–2066. [Google Scholar] [CrossRef] [PubMed]
- Sayyari, E.; Mirarab, S. Testing for Polytomies in Phylogenetic Species Trees Using Quartet Frequencies. Genes 2018, 9, 132. [Google Scholar] [CrossRef] [PubMed]
- Liao, D. Concerted Evolution: Molecular Mechanisms and Biological Implications. Am. J. Hum. Genet. 1999, 64, 24–30. [Google Scholar] [CrossRef] [PubMed]
- Hanada, K.; Tezuka, A.; Nozawa, M.; Suzuki, Y.; Sugano, S.; Nagano, A.J.; Ito, M.; Morinaga, S.I. Functional divergence of duplicate genes several million years after gene duplication in Arabidopsis. DNA Res. 2018, 25, 327–339. [Google Scholar] [CrossRef]
- Koonin, E.V. How Many Genes Can Make a Cell: The Minimal-Gene-Set Concept. Annu. Rev. Genom. Hum. Genet. 2000, 1, 99–116. [Google Scholar] [CrossRef] [PubMed]
- Rancati, G.; Moffat, J.; Typas, A.; Pavelka, N. Emerging and evolving concepts in gene essentiality. Nat. Rev. Genet. 2018, 19, 34–49. [Google Scholar] [CrossRef]
- Thomas, C.M.; Nielsen, K.M. Mechanisms of, and barriers to, horizontal gene transfer between bacteria. Nat. Rev. Microbiol. 2005, 3, 711–721. [Google Scholar] [CrossRef]
- Choi, S.C.; Rasmussen, M.D.; Hubisz, M.J.; Gronau, I.; Stanhope, M.J.; Siepel, A. Replacing and Additive Horizontal Gene Transfer in Streptococcus. Mol. Biol. Evol. 2012, 29, 3309–3320. [Google Scholar] [CrossRef]
- Khayi, S.; Blin, P.; Pédron, J.; Chong, T.M.; Chan, K.G.; Moumni, M.; Hélias, V.; Van Gijsegem, F.; Faure, D. Population genomics reveals additive and replacing horizontal gene transfers in the emerging pathogen Dickeya solani. BMC Genom. 2015, 16, 788. [Google Scholar] [CrossRef]
- Kordi, M.; Kundu, S.; Bansal, M.S. On Inferring Additive and Replacing Horizontal Gene Transfers Through Phylogenetic Reconciliation. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Niagara Falls, NY, USA, 7–10 September 2019; pp. 514–523. [Google Scholar] [CrossRef]
- Eppley, J.M.; Tyson, G.W.; Getz, W.M.; Banfield, J.F. Genetic exchange across a species boundary in the archaeal genus ferroplasma. Genetics 2007, 177, 407–416. [Google Scholar] [CrossRef]
- Williams, D.; Gogarten, J.P.; Papke, R.T. Quantifying homologous replacement of loci between haloarchaeal species. Genome Biol. Evol. 2012, 4, 1223–1244. [Google Scholar] [CrossRef] [PubMed]
- Zuckerkandl, E.; Pauling, L.B. Molecular disease, evolution, and genic heterogeneity. In Horizons in Biochemistry; Kasha, M., Pullman, B., Eds.; Academic Press: New York, NY, USA, 1962; pp. 189–225. [Google Scholar]
- Kawahara, Y.; Imanishi, T. A genome-wide survey of changes in protein evolutionary rates across four closely related species of Saccharomyces sensu stricto group. BMC Evol. Biol. 2007, 7, 9. [Google Scholar] [CrossRef] [PubMed]
- Martin, A.P.; Palumbi, S.R. Body size, metabolic rate, generation time, and the molecular clock. Proc. Natl. Acad. Sci. USA 1993, 90, 4087–4091. [Google Scholar] [CrossRef]
- Gillooly, J.F.; Allen, A.P.; West, G.B.; Brown, J.H. The Rate of DNA Evolution: Effects of Body Size and Temperature on the Molecular Clock. Proc. Natl. Acad. Sci. USA 2005, 102, 140–145. [Google Scholar] [CrossRef]
- Innan, H.; Kondrashov, F. The evolution of gene duplications: Classifying and distinguishing between models. Nat. Rev. Genet. 2010, 11, 97–108. [Google Scholar] [CrossRef]
- Lepage, T.; Bryant, D.; Philippe, H.; Lartillot, N. A General Comparison of Relaxed Molecular Clock Models. Mol. Biol. Evol. 2007, 24, 2669–2680. [Google Scholar] [CrossRef]
- Kishino, H.; Thorne, J.L.; Bruno, W.J. Performance of a Divergence Time Estimation Method under a Probabilistic Model of Rate Evolution. Mol. Biol. Evol. 2001, 18, 352–361. [Google Scholar] [CrossRef]
- Yang, Z. Molecular Evolution: A Statistical Approach, 1st ed.; Oxford University Press: Oxford, UK; New York, NY, USA, 2014. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Gillespie, D.T. Exact stochastic simulation of coupled chemical reactions. J. Phys. Chem. 1977, 81, 2340–2361. [Google Scholar] [CrossRef]
- Jukes, T.H.; Cantor, C.R. Evolution of Protein Molecules. In Mammalian Protein Metabolism; Elsevier: Amsterdam, The Netherlands, 1969; pp. 21–132. [Google Scholar] [CrossRef]
- Kimura, M. A Simple Method for Estimating Evolutionary Rates of Base Substitutions through Comparative Studies of Nucleotide Sequences. J. Mol. Evol. 1980, 16, 111–120. [Google Scholar] [CrossRef]
- Tavaré, S. Some Probabilistic and Statistical Problems in the Analysis of DNA Sequences. Lect. Math. Life Sci. 1986, 17, 57–86. [Google Scholar]
- Dayhoff, M.; Schwartz, R. A Model for Evolutionary Change in Proteins. In Atlas of Protein Sequence and Structure; National Biomedical Research Foundation: Washington, DC, USA, 1978; pp. 345–352. [Google Scholar]
- Henikoff, S.; Henikoff, J.G. Amino Acid Substitution Matrices from Protein Blocks. Proc. Natl. Acad. Sci. USA 1992, 89, 10915–10919. [Google Scholar] [CrossRef] [PubMed]
- Jones, D.T.; Taylor, W.R.; Thornton, J.M. The Rapid Generation of Mutation Data Matrices from Protein Sequences. Bioinformatics 1992, 8, 275–282. [Google Scholar] [CrossRef] [PubMed]
- Whelan, S.; Goldman, N. A General Empirical Model of Protein Evolution Derived from Multiple Protein Families Using a Maximum-Likelihood Approach. Mol. Biol. Evol. 2001, 18, 691–699. [Google Scholar] [CrossRef]
- Le, S.Q.; Gascuel, O. An Improved General Amino Acid Replacement Matrix. Mol. Biol. Evol. 2008, 25, 1307–1320. [Google Scholar] [CrossRef]
- Arenas, M. Trends in substitution models of molecular evolution. Front. Genet. 2015, 6, 319. [Google Scholar] [CrossRef]
- Del Amparo, R.; Arenas, M.A. Consequences of Substitution Model Selection on Protein Ancestral Sequence Reconstruction. Mol. Biol. Evol. 2022, 39, msac144. [Google Scholar] [CrossRef]
- Yang, Z. PAML: A Program Package for Phylogenetic Analysis by Maximum Likelihood. Bioinformatics 1997, 13, 555–556. [Google Scholar] [CrossRef]
- Chang, M.S.; Benner, S.A. Empirical Analysis of Protein Insertions and Deletions Determining Parameters for the Correct Placement of Gaps in Protein Sequence Alignments. J. Mol. Biol. 2004, 341, 617–631. [Google Scholar] [CrossRef]
- Yang, Z. Maximum-likelihood estimation of phylogeny from DNA sequences when substitution rates differ over sites. Mol. Biol. Evol. 1993, 10, 1396–1401. [Google Scholar] [CrossRef]
- Gu, X.; Fu, Y.X.; Li, W.H. Maximum likelihood estimation of the heterogeneity of substitution rate among nucleotide sites. Mol. Biol. Evol. 1995, 12, 546–557. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, H.A.; Strimmer, K.; Vingron, M.; von Haeseler, A. TREE-PUZZLE: Maximum likelihood phylogenetic analysis using quartets and parallel computing. Bioinformatics 2002, 18, 502–504. [Google Scholar] [CrossRef] [PubMed]
- Schaller, D.; Lafond, M.; Stadler, P.F.; Wieseke, N.; Hellmuth, M. Indirect Identification of Horizontal Gene Transfer. J. Math. Biol. 2021, 83, 10. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.H.; Lu, F.; Wang, Z.Y.; Zhong, F.; Hoover, J.; Mural, R. Using shared genomic synteny and shared protein functions to enhance the identification of orthologous gene pairs. Bioinformatics 2005, 21, 703–710. [Google Scholar] [CrossRef] [PubMed]
- Lechner, M.; Hernandez-Rosales, M.; Doerr, D.; Wieseke, N.; Thévenin, A.; Stoye, J.; Hartmann, R.K.; Prohaska, S.J.; Stadler, P.F. Orthology Detection Combining Clustering and Synteny for Very Large Datasets. PLoS ONE 2014, 9, e105015. [Google Scholar] [CrossRef]
- Dohmen, E.; Klasberg, S.; Bornberg-Bauer, E.; Perry, S.; Kemena, C. The modular nature of protein evolution: Domain rearrangement rates across eukaryotic life. BMC Evol. Biol. 2020, 20, 30. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition on | Function | Available Models | Innovation Option | Loss Branches |
|---|---|---|---|---|
| N | species_tree_n() | Yule, BDP, EBDP 1 | only for Yule 3 | (E)BDP |
| t | species_tree_age() | Yule, BDP, EBDP 2 | yes | (E)BDP |
| N and t | species_tree_n_age() | Yule, BDP | yes | no 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schaller, D.; Hellmuth, M.; Stadler, P.F. AsymmeTree: A Flexible Python Package for the Simulation of Complex Gene Family Histories. Software 2022, 1, 276-298. https://doi.org/10.3390/software1030013
Schaller D, Hellmuth M, Stadler PF. AsymmeTree: A Flexible Python Package for the Simulation of Complex Gene Family Histories. Software. 2022; 1(3):276-298. https://doi.org/10.3390/software1030013
Chicago/Turabian StyleSchaller, David, Marc Hellmuth, and Peter F. Stadler. 2022. "AsymmeTree: A Flexible Python Package for the Simulation of Complex Gene Family Histories" Software 1, no. 3: 276-298. https://doi.org/10.3390/software1030013