Software 2025, 4(4), 31; https://doi.org/10.3390/software4040031 - 3 Dec 2025
Abstract
►
Show Figures
Organizations increasingly rely on Agile software development to navigate the complexities of digital transformation. Agile emphasizes flexibility, empowerment, and emergent design, yet large-scale initiatives often extend beyond single teams to include multiple subsidiaries, business units, and regulatory stakeholders. In such contexts, team-level mechanisms
[...] Read more.
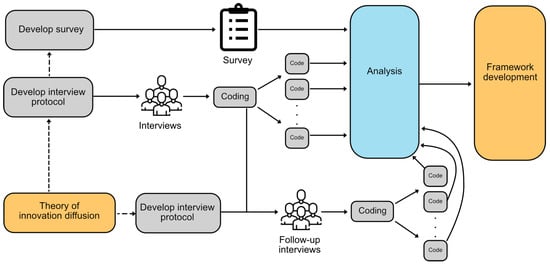
Organizations increasingly rely on Agile software development to navigate the complexities of digital transformation. Agile emphasizes flexibility, empowerment, and emergent design, yet large-scale initiatives often extend beyond single teams to include multiple subsidiaries, business units, and regulatory stakeholders. In such contexts, team-level mechanisms such as retrospectives, backlog refinement, and planning events may prove insufficient to achieve alignment across diverse perspectives, organizational boundaries, and compliance requirements. To address this limitation, this paper introduces a complementary framework and a supporting software tool that enable systematic cross-stakeholder alignment. Rather than replacing Agile practices, the framework enhances them by capturing heterogeneous stakeholder views, surfacing tacit knowledge, and systematically reconciling differences into a shared alignment artifact. The methodology combines individual Functional Resonance Analysis Method (FRAM)-based process modeling, iterative harmonization, and an evidence-supported selection mechanism driven by quantifiable performance indicators, all operationalized through a prototype tool. The approach was evaluated in a real industrial case study within the regulated gaming sector, involving practitioners from both a parent company and a subsidiary. The results show that the methodology effectively revealed misalignments among stakeholders’ respective views of the development process, supported structured negotiation to reconcile these differences, and produced a consolidated process model that improved transparency and alignment across organizational boundaries. The study demonstrates the practical viability of the methodology and its value as a complementary mechanism that strengthens Agile ways of working in complex, multi-stakeholder environments.
Full article

Figure 1




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}