

Comparing Measured Agile Software Development Metrics Using an Agile Model-Based Software Engineering Approach versus Scrum Only


Abstract
:1. Introduction
2. Background
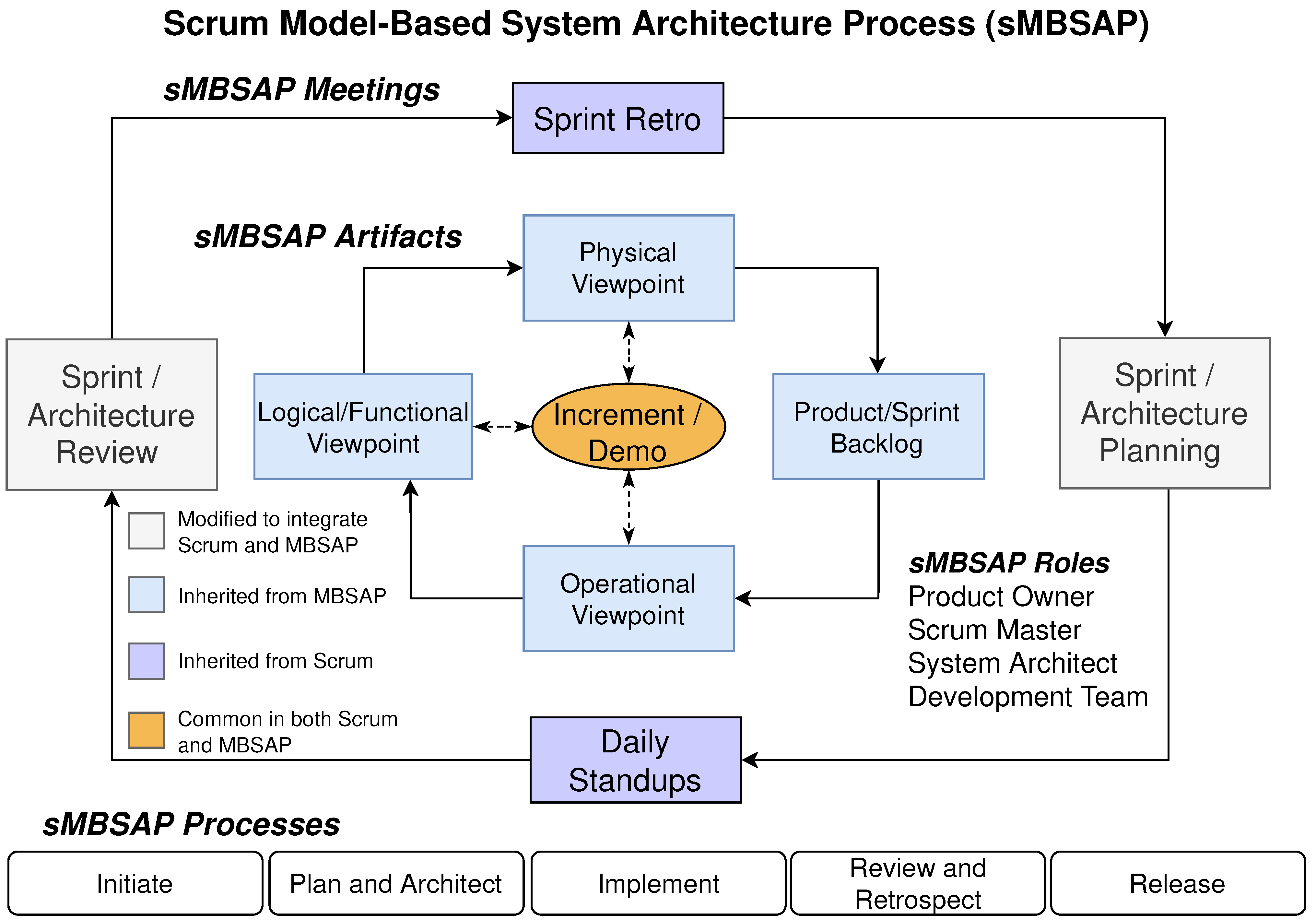
2.1. Scrum and Agile MBSE Methods
2.2. Reliability of Estimation
2.3. Productivity
2.4. Defect Rate
2.5. Research Purpose
Comparing sMBSAP and scrum, are there measurable benefits to software development performance when using one approach over the other?
3. Research Methods
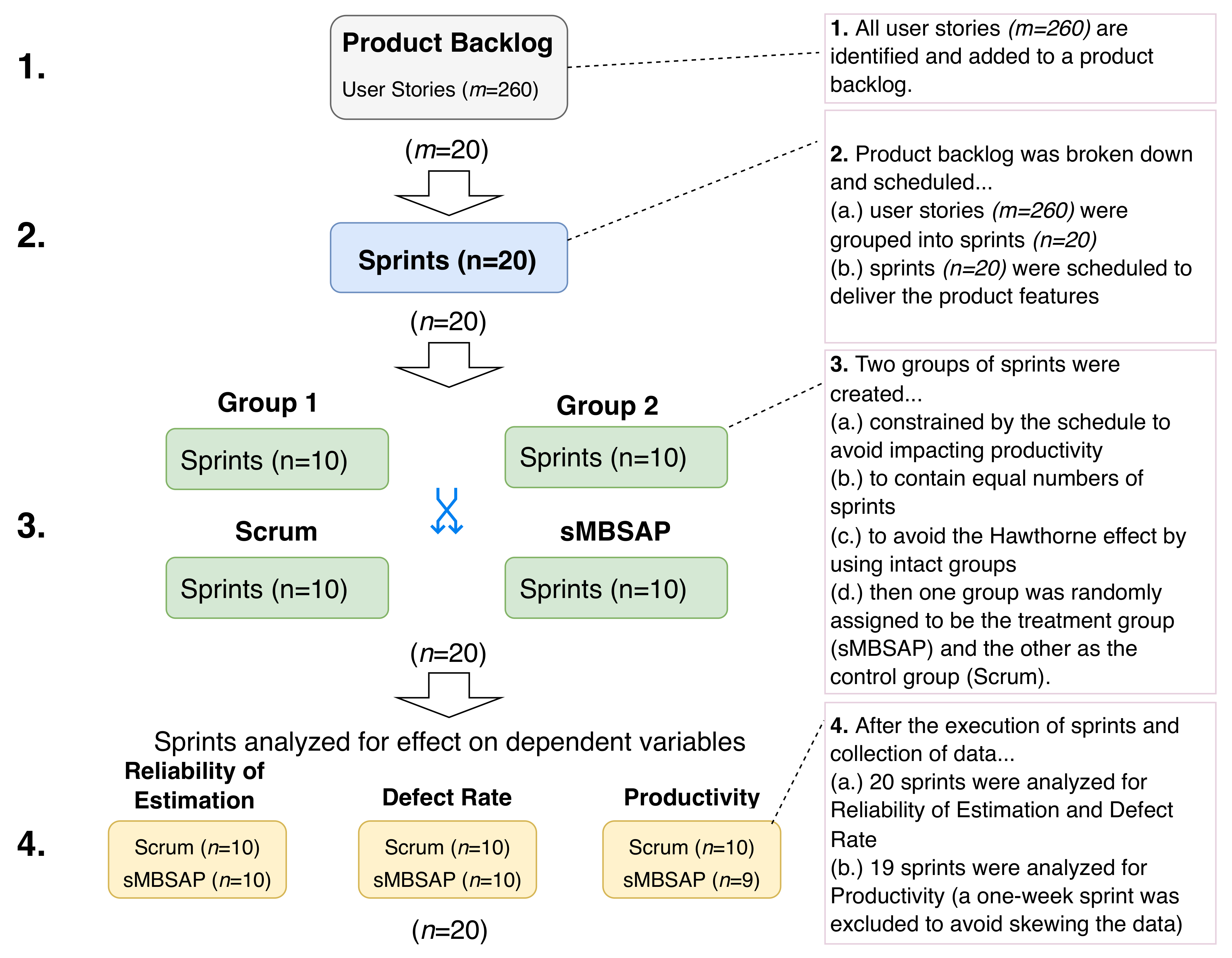
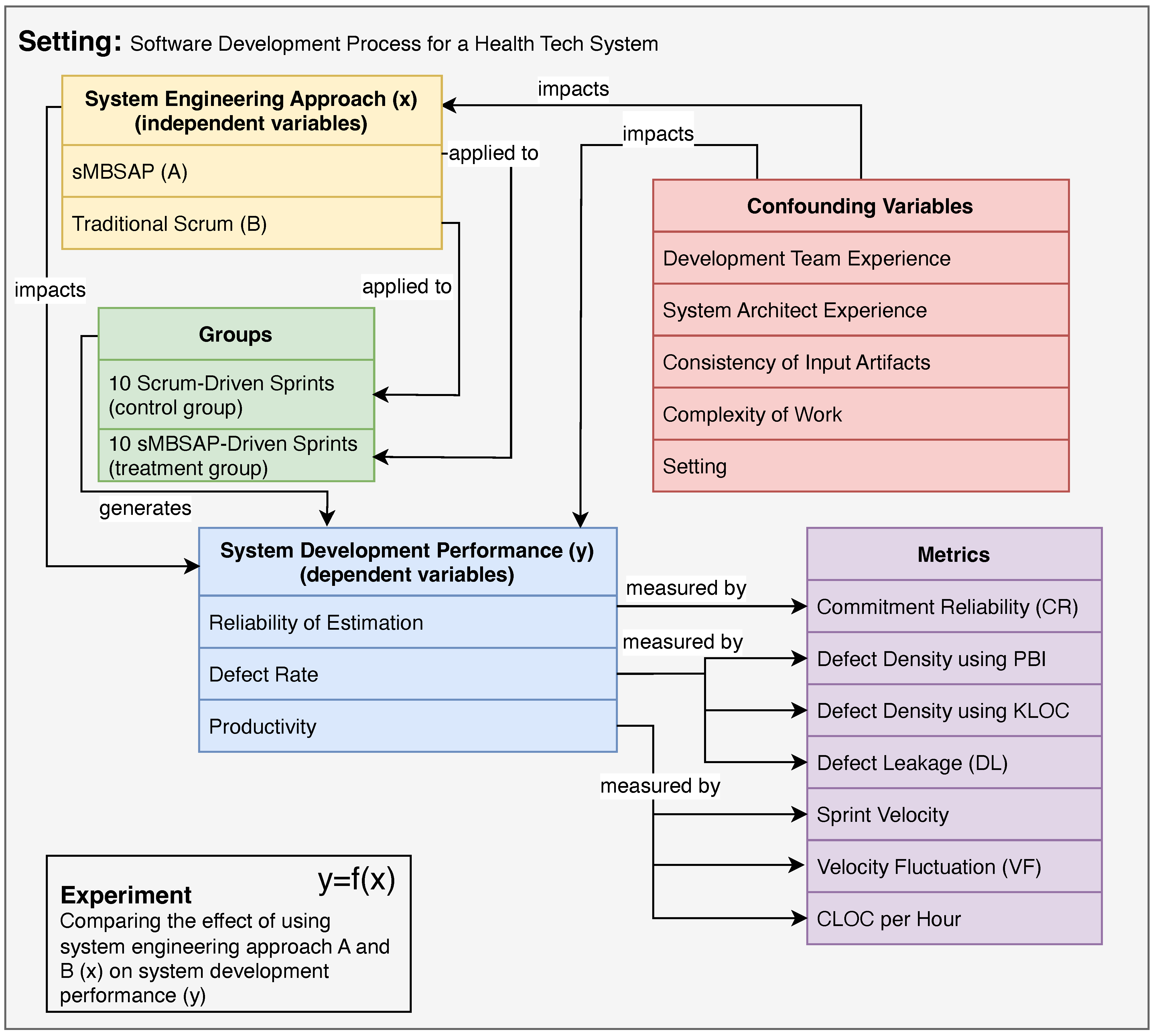
3.1. Experimental Design
3.2. Techniques and Procedures
3.2.1. Step 1: Plan Experiment
3.2.2. Step 2: Identify the Metrics for Software Development Performance
Metrics for Reliability of Estimation
Metrics for Productivity
Metrics for Defect Rate
3.2.3. Step 3: Execute Scrum and sMBSAP Drive Sprints (Scrum and sMBSAP Phases)
3.2.4. Step 4: Collect System Development Performance Data
3.2.5. Step 5: Analyze Data and Compare Results
3.3. Quality of the Research Design
3.3.1. Minimizing Threats to Reliability
3.3.2. Minimizing Threats to Validity
- Selection bias: In this study, some selection bias was introduced by the fact that sprints were chosen to be in one group or the other based on the scheduling of the sprints. The product development team thought it would be counterproductive to execute one sprint using one approach and the following related sprints with the other approach. Although this non-random assignment is considered a threat to internal validity, the benefit of it is that it mitigated the risk of impacting the product development team momentum, which, if occurred, would have affected the productivity measures. Further details on the steps followed to apply random assignment of the intact groups are provided in Section 3.1.
- Testing effect: Two measures were taken to address this threat. First, having a control group that was executed with scrum helped guard against this threat, since the sprints of the control group were equally subject to the same effect. Second, the researcher did not share with the product development team the details of the study or the specific variables under investigation.
- Changes to the causal relationship due to variations in the implementation within the same approach: During the execution of both groups of sprints, no variations were observed.
- Interactions of causal relationships with settings: This factor considers the setting in which the cause–effect relationship is measured, thus jeopardizing external validity [91]. The researcher believes that the experimental setting was similar to most development projects after COVID-19, in which team members work and collaborate remotely. However, the research acknowledges that conducting this experiment in other settings would provide further insights into this factor.
- Interactions of causal relationships with outcomes: This outcome refers to the fact that a cause–effect relationship may exist for one outcome (e.g., more accurate commitment reliability) but not for another seemingly related outcome (e.g., productivity) [92]. The researcher studied the impact of the two approaches on three outcomes. The established causal relation has not been extended from one outcome to another without data collection and measurement, which gives a fuller picture of the treatment’s total impact.
- The reactive or interactive effect of testing [76]: Given that this quasi-experiment is a posttest only, this factor does not apply to this experiment.
3.3.3. Minimizing Threats to Statistical Conclusion Validity
- Given that the two groups of sprints were not assembled randomly, due to scheduling constraints, the two groups were considered non-equivalent (pre-existing groups). The schedule has been found to play a role in the assignment of subjects to experimental groups in other quasi-experiments in software engineering [95]. In such cases, researchers suggest assigning the treatment to one of the pre-existing (intact) groups or to the other randomly [76,77]. This approach has been borrowed and implemented by researchers in various fields [96], including software engineering [95], and it has also been implemented in this experiment. Therefore, the assumption of the random assignment of intact groups was tenable.
- The assumption of independence suggests that the data are gathered from groups that are independent of one another [87,97]. In this experiment, special consideration was given to the sequence of the sprint implementation to better ensure that the independence assumption held for the observations within each group. The independence assumption for the t-test refers to the independence of the individual observations within each group rather than the interdependencies between sprints. To best satisfy this assumption, each observation should be unconditionally unrelated and independent of the others in terms of data collection or measurement. Violations of the independence assumption, such as having repeated measures or correlated observations, can lead to biased or incorrect results when using the independent t-test. As an example from the context of this experiment, the number of defects observed in Sprint 6 (a scrum-driven sprint) was independent of that observed in Sprint 7 (also a scrum-driven sprint), and it was also independent of that observed in Sprint 9 (an sMBSAP-driven sprint). A higher or lower number of defects in Sprint 6 had no relationship to the number of defects in Sprints 7 or 8, although there was a schedule interdependency between the three sprints. In summary, while the sprints may have had scheduling dependencies, given that the observations within each group were generally independent of each other, the assumption of independence was tenable for the independent t-test.
- The dependent variables must be continuous and measured at the interval or ratio scale in order to satisfy the level of measurement assumption for the independent t-test. The level of measurement assumption also requires a categorically independent variable with two groups: one treatment and one control [87]. The type of data collected (ratio scale and interval data) and having had two groups satisfied this assumption.
- The assumption of normality for each set of system performance data, where the mean was calculated and was visually evaluated, involved the following: first, we used a boxplot to eliminate outliers; then, we used a bar chart; finally, we statistically calculated the data using the normality test [86].
- Levene’s test was used to assess the argument that there is no difference in the variance of data between groups. A statistically significant value () denotes that the assumption has not been satisfied and that the variance between groups is significantly different. Equal variance was not assumed when Levene’s test was significant. Similarly, an equal variance was assumed when Levene’s test was not significant () [98].
4. Results and Discussion
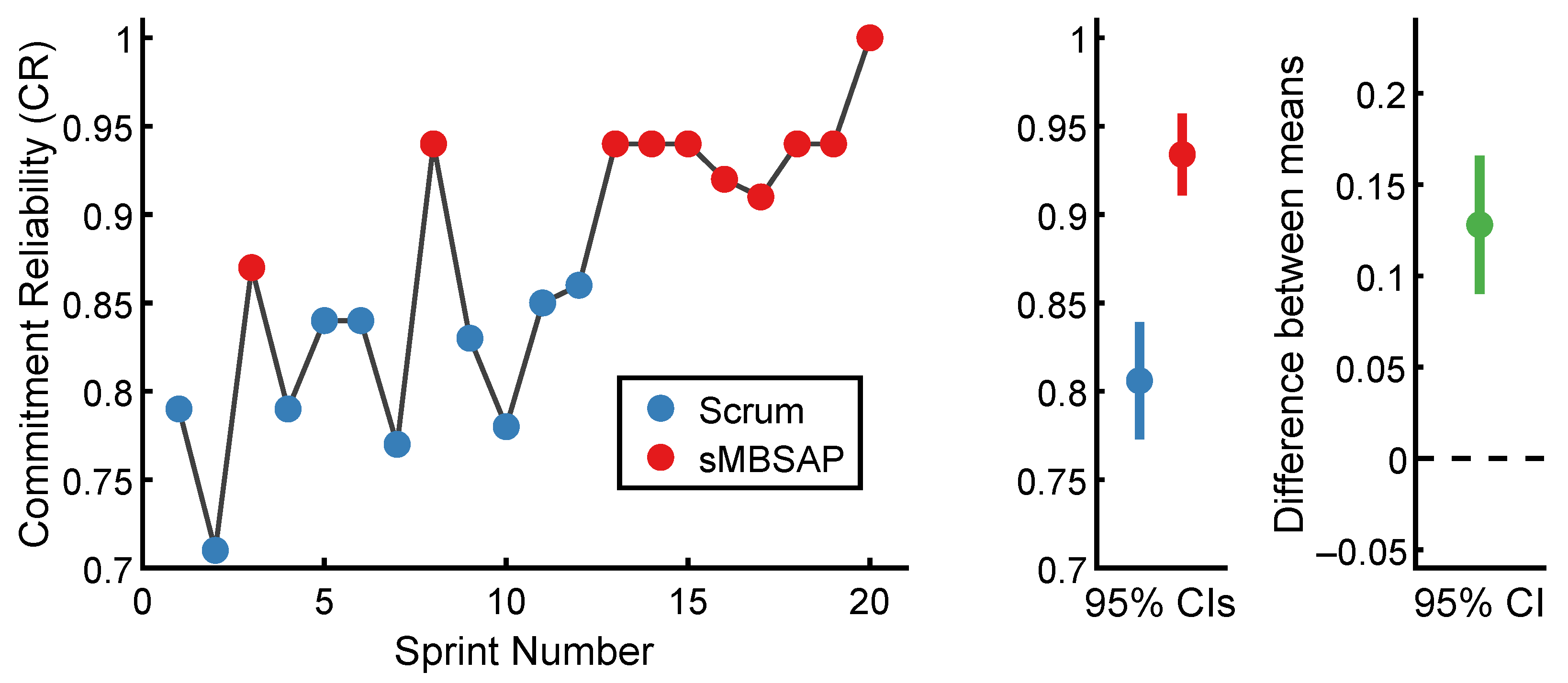
4.1. Reliability of Estimation Results
Commitment Reliability (CR) Comparison
4.2. Productivity Results
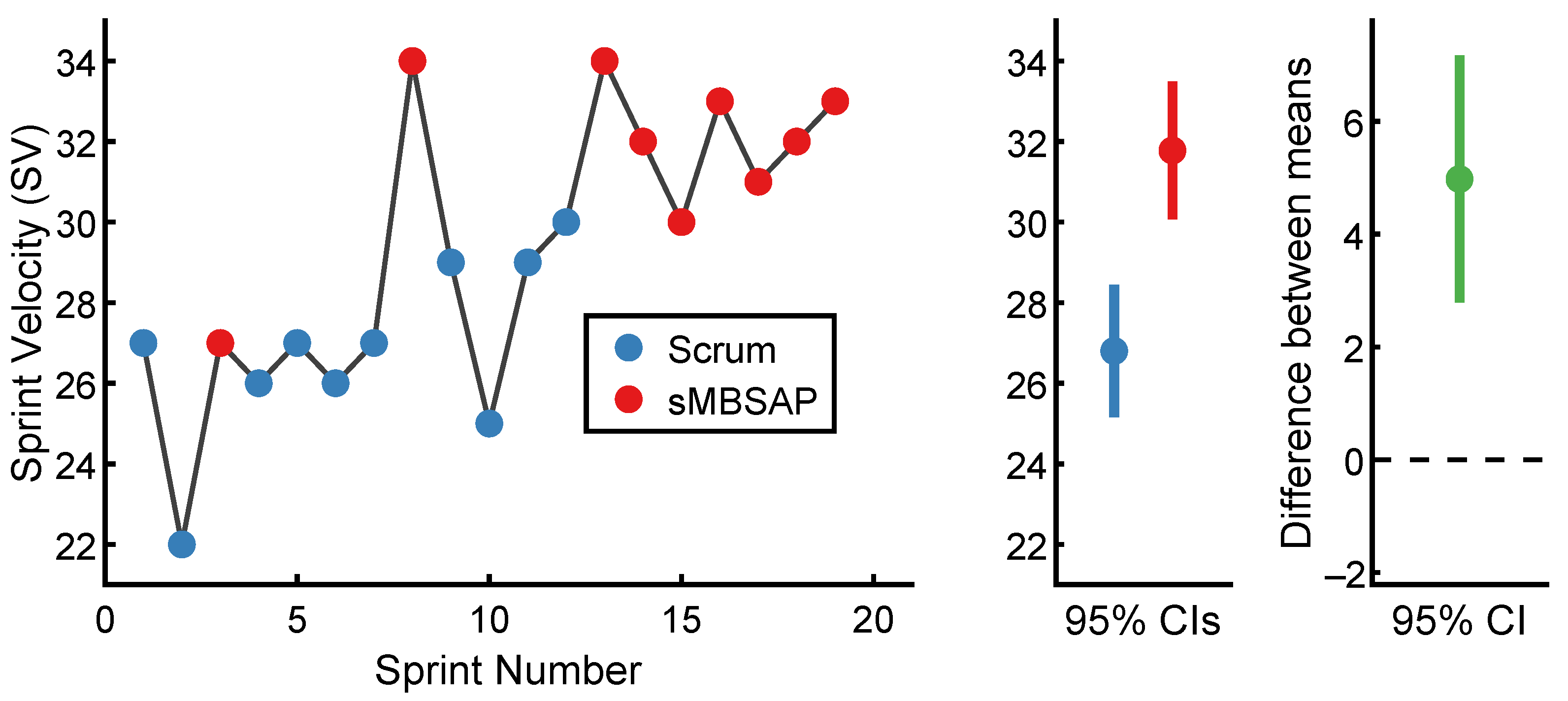
4.2.1. Sprint Velocity (SV) Comparison
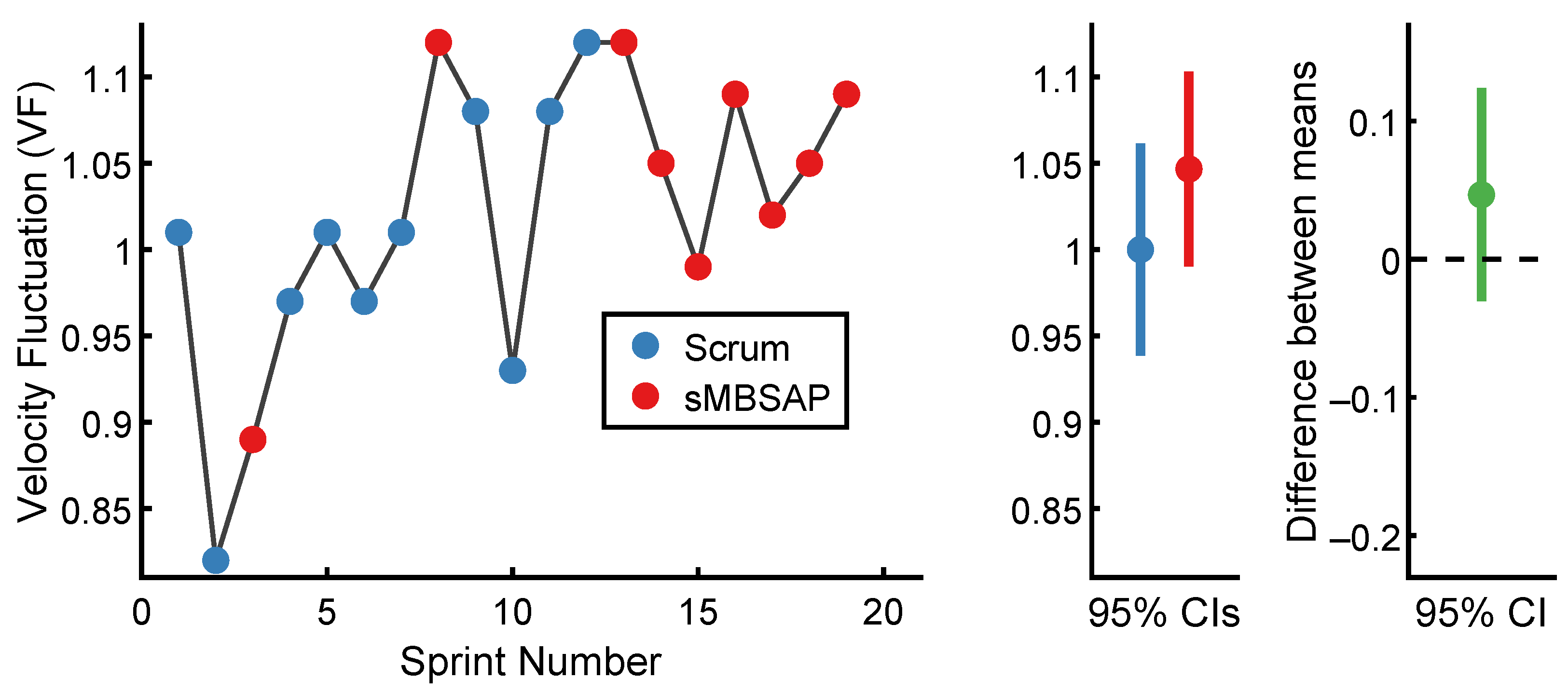
4.2.2. Velocity Fluctuation (VF) Comparison
4.2.3. Count of Lines of Code (CLOC) per Hour Comparison
4.3. Defect Rate Results
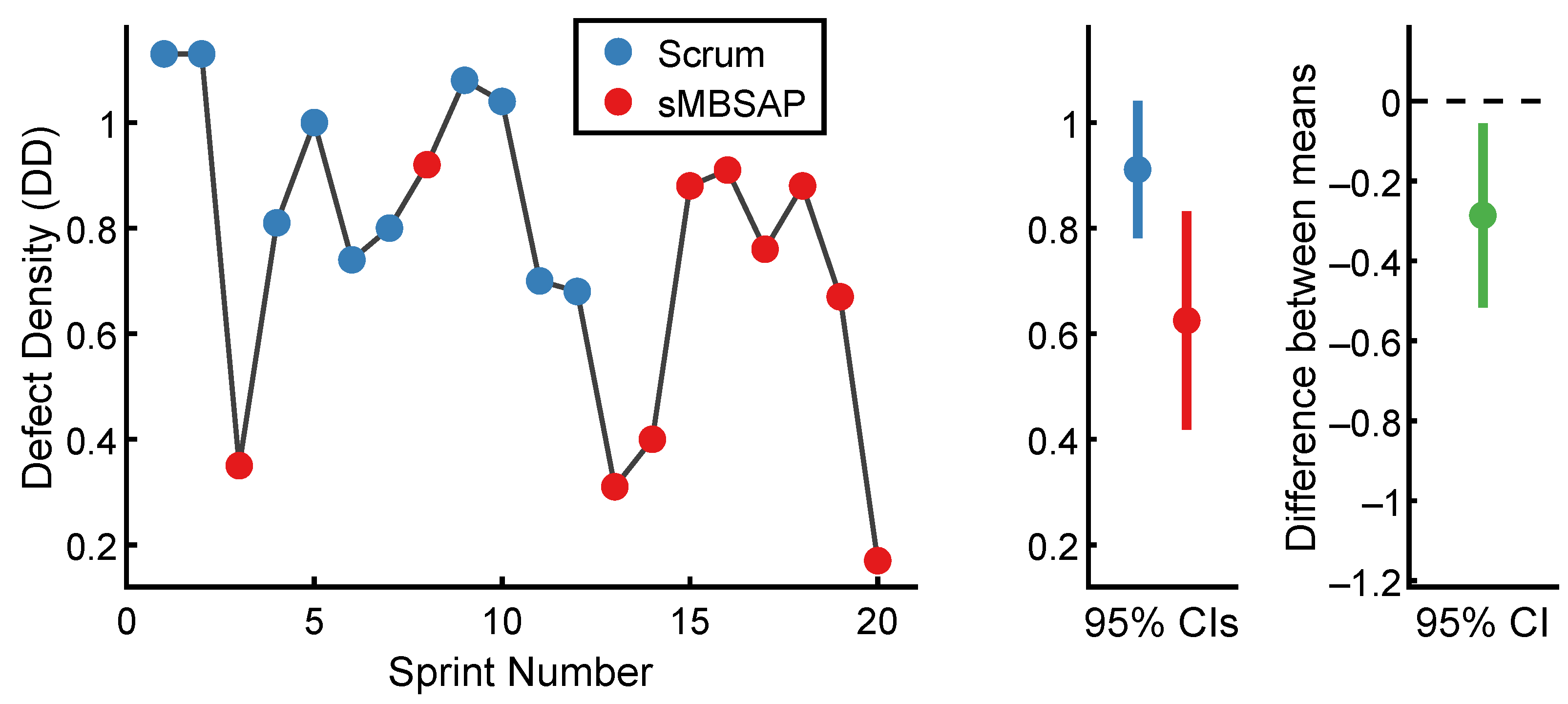
4.3.1. Defect Density (Using PBI) Comparison
4.3.2. Defect Density (within KLOC) Comparison
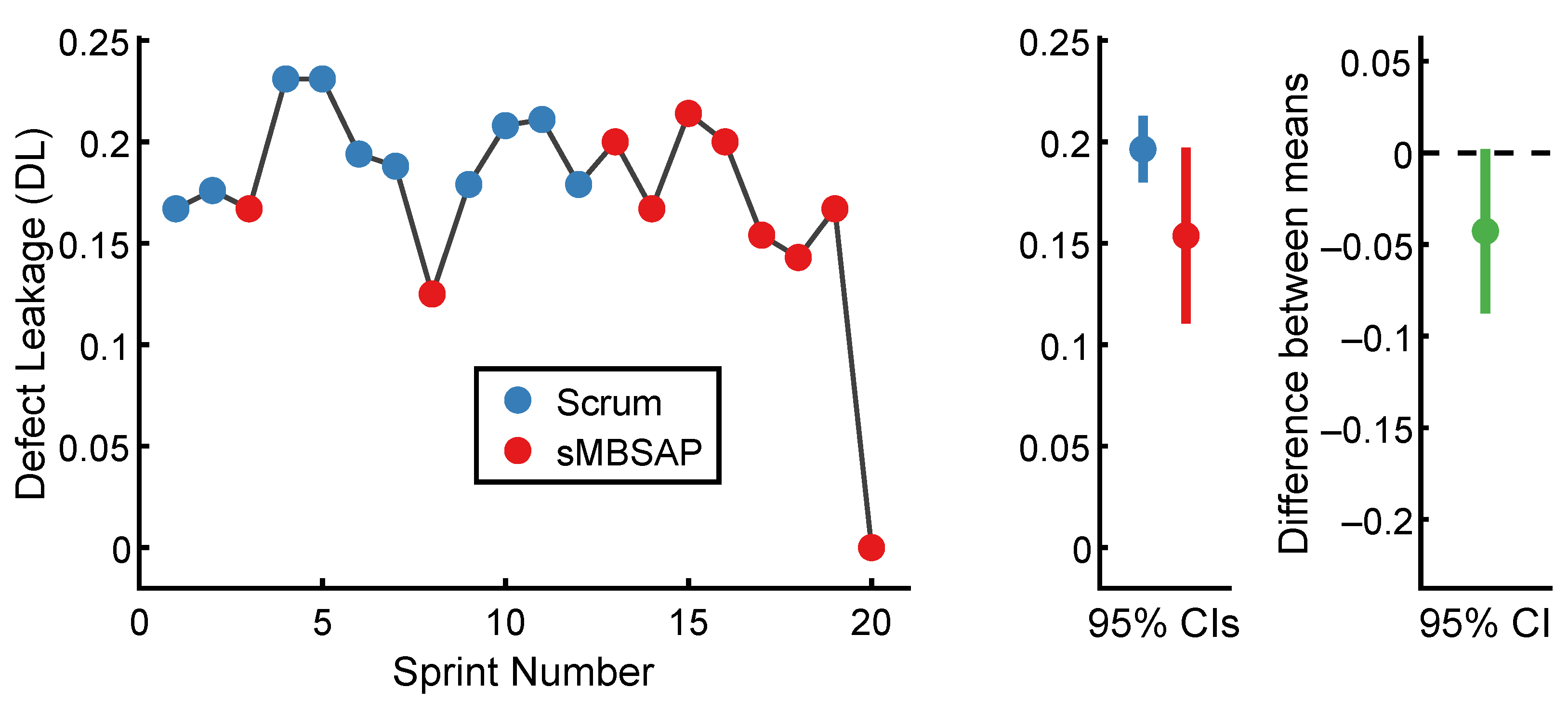
4.3.3. Defect Leakage Comparisons
4.3.4. Other Observations
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Count of Lines of Code | |
| Commitment Reliability | |
| DBSE | Document-Based Systems Engineering |
| Defect Density | |
| Defect Leakage | |
| EV | Earned Value |
| Thousands (Kilo) of Lines of Code | |
| M | Arithmetic Mean |
| MBSAP | Model-Based System Architecture Process |
| MBSE | Model-Based Software Engineering |
| N | Number of Samples |
| PBI | Product Backlog Items |
| ROI | Return-On-Investment |
| Standard Deviation | |
| sMBSAP | Scrum Model-Based System Architecture Process |
| Story Points | |
| Sprint Velocity | |
| Velocity Fluctuation |
References
- Tohidi, H. The role of risk management in IT systems of organizations. Procedia Comput. Sci. 2011, 3, 881–887. [Google Scholar] [CrossRef] [Green Version]
- Standish Group. CHAOS Report 2020; Technical Report; Standish Group: Boston, MA, USA, 2020. [Google Scholar]
- Altahtooh, U.A.; Emsley, M.W. Is a Challenged Project One of the Final Outcomes for an IT Project? In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 4296–4304. [Google Scholar] [CrossRef]
- Muganda Ochara, N.; Kandiri, J.; Johnson, R. Influence processes of implementation effectiveness in challenged information technology projects in Africa. Inf. Technol. People 2014, 27, 318–340. [Google Scholar] [CrossRef]
- Yeo, K.T. Critical failure factors in information system projects. Int. J. Proj. Manag. 2022, 20, 241–246. [Google Scholar] [CrossRef]
- Bloch, M.; Blumberg, S.; Laartz, J. Delivering large-scale IT projects on time, on budget, and on value. Harv. Bus. Rev. 2012, 5, 2–7. [Google Scholar]
- Flyvbjerg, B.; Budzier, A. Why Your IT Project May Be Riskier Than You Think. Harv. Bus. Rev. 2011, 89, 23–25. [Google Scholar] [CrossRef]
- Eadicicco, L.; Peckham, M.; Pullen, J.P.; Fitzpatrick, A. Time The 20 Most Successful Tech Failures of All Time. Time. 2017. Available online: https://time.com/4704250/most-successful-technology-tech-failures-gadgets-flops-bombs-fails/ (accessed on 15 September 2019).
- Martin, J. Rapid Application Development; Macmillan Publishing Co., Inc.: New York, NY, USA, 1991. [Google Scholar]
- Ambler, S. The Agile Unified Process (Aup). 2005. Available online: http://www.ambysoft.com/unifiedprocess/agileUP.html (accessed on 10 March 2023).
- Turner, R. Toward Agile systems engineering processes. J. Def. Softw. Eng. 2007, 11–15. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=b807d8efe4acd265187a98357b19c063b5a9ad5e (accessed on 15 April 2020).
- Schwaber, K. Scrum development process. In Business Object Design And Implementation; OOPSLA ’95 Workshop Proceedings, Austin, TX, USA, 16 October 1995; Springer: Berlin/Heidelberg, Germany, 1997; pp. 117–134. [Google Scholar]
- Akif, R.; Majeed, H. Issues and challenges in Scrum implementation. Int. J. Sci. Eng. Res. 2012, 3, 1–4. [Google Scholar]
- Cardozo, E.S.F.; Araújo Neto, J.B.F.; Barza, A.; França, A.C.C.; da Silva, F.Q.B. Scrum and productivity in software projects: A systematic literature review. In Proceedings of the International Conference on Evaluation and Assessment in Software Engineering, Keele, UK, 12–13 April 2010. [Google Scholar] [CrossRef]
- Lehman, T.; Sharma, A. Software development as a service: Agile experiences. In Proceedings of the 2011 Annual SRII Global Conference, San Jose, CA, USA, 29 March–2 April 2011; pp. 749–758. [Google Scholar]
- ISO/IEC/IEEE 15288:2023; Systems and Software Engineering—System Life Cycle Processes. ISO, IEC, and IEEE: Geneva, Switzerland, 2023. [CrossRef]
- Dove, R.; Schindel, W. Agility in Systems Engineering—Findings from Recent Studies; Working Paper; Paradigm Shift International and ICTT System Sciences: 2017. Available online: http://www.parshift.com/s/ASELCM-AgilityInSE-RecentFindings.pdf (accessed on 12 April 2020).
- Henderson, K.; Salado, A. Value and benefits of model-based systems engineering (MBSE): Evidence from the literature. Syst. Eng. 2021, 24, 51–66. [Google Scholar] [CrossRef]
- Douglass, B.P. Agile Model-Based Systems Engineering Cookbook, 1st ed.; Packt Publishing: Birmingham, UK, 2021. [Google Scholar]
- Salehi, V.; Wang, S. Munich Agile MBSE concept (MAGIC). Int. Conf. Eng. Des. 2019, 1, 3701–3710. [Google Scholar] [CrossRef] [Green Version]
- Riesener, M.; Doelle, C.; Perau, S.; Lossie, P.; Schuh, G. Methodology for iterative system modeling in Agile product development. Procedia CIRP 2021, 100, 439–444. [Google Scholar] [CrossRef]
- Bott, M.; Mesmer, B. An analysis of theories supporting Agile Scrum and the use of Scrum in systems engineering. Eng. Manag. J. 2020, 32, 76–85. [Google Scholar] [CrossRef]
- Ciampa, P.D.; Nagel, B. Accelerating the development of complex systems in aeronautics via MBSE and MDAO: A roadmap to agility. In Proceedings of the AIAA AVIATION Forum and Exposition, Number AIAA 2021-3056. Virtual Event, 2–6 August 2021. [Google Scholar] [CrossRef]
- Huss, M.; Herber, D.R.; Borky, J.M. An Agile model-based software engineering approach illustrated through the development of a health technology system. Software 2023, 2, 234–257. [Google Scholar] [CrossRef]
- Borky, J.M.; Bradley, T.H. Effective Model-Based Systems Engineering; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Schwaber, K. Agile Project Management with Scrum; Microsoft Press: Redmond, WA, USA, 2004. [Google Scholar]
- Anand, R.V.; Dinakaran, M. Issues in Scrum Agile development principles and practices in software development. Indian J. Sci. Technol. 2015, 8, 1–5. [Google Scholar] [CrossRef]
- Brambilla, M.; Cabot, J.; Wimmer, M. Model-Driven Software Engineering in Practice; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Bonnet, S.; Voirin, J.L.; Normand, V.; Exertier, D. Implementing the MBSE cultural change: Organization, coaching and lessons learned. In Proceedings of the INCOSE International Symposium, Seattle, WA, USA, 13–16 July 2015; Volume 25, pp. 508–523. [Google Scholar] [CrossRef]
- Azhar, D.; Mendes, E.; Riddle, P. A systematic review of web resource estimation. In Proceedings of the International Conference on Predictive Models in Software Engineering, Lund, Sweden, 21–22 September 2012; pp. 49–58. [Google Scholar] [CrossRef]
- Jorgensen, M.; Shepperd, M. A systematic review of software development cost estimation studies. IEEE Trans. Softw. Eng. 2006, 33, 33–53. [Google Scholar] [CrossRef] [Green Version]
- Molokken, K.; Jorgensen, M. A review of software surveys on software effort estimation. In Proceedings of the International Symposium on Empirical Software Engineering, Rome, Italy, 30 September–1 October 2003; pp. 223–230. [Google Scholar] [CrossRef]
- Wen, J.; Li, S.; Lin, Z.; Hu, Y.; Huang, C. Systematic literature review of machine learning based software development effort estimation models. Inf. Softw. Technol. 2012, 54, 41–59. [Google Scholar] [CrossRef]
- Cohn, M. Agile Estimating and Planning; Pearson Education: Harlow, UK, 2005. [Google Scholar]
- Grenning, J. Planning Poker or How to Avoid Analysis Paralysis While Release Planning; White Paper; Renaissance Software Consulting: Hawthorn Woods, IL, USA, 2002. [Google Scholar]
- Mahnič, V.; Hovelja, T. On using planning poker for estimating user stories. J. Syst. Softw. 2012, 85, 2086–2095. [Google Scholar] [CrossRef]
- Dalton, J. Planning Poker. In Great Big Agile; Springer: Berlin/Heidelberg, Germany, 2019; pp. 203–204. [Google Scholar] [CrossRef]
- Haugen, N.C. An empirical study of using planning poker for user story estimation. In Proceedings of the AGILE, Minneapolis, MN, USA, 23–28 July 2006. [Google Scholar] [CrossRef]
- Moløkken-Østvold, K.; Haugen, N.C.; Benestad, H.C. Using planning poker for combining expert estimates in software projects. J. Syst. Softw. 2008, 81, 2106–2117. [Google Scholar] [CrossRef]
- Molokken-Østvold, K.; Haugen, N.C. Combining estimates with planning poker–An empirical study. In Proceedings of the Australian Software Engineering Conference, Melbourne, Australia, 10–13 April 2007; pp. 349–358. [Google Scholar] [CrossRef]
- Moløkken-Østvold, K.; Jørgensen, M.; Tanilkan, S.S.; Gallis, H.; Lien, A.C.; Hove, S.W. A survey on software estimation in the Norwegian industry. In Proceedings of the International Symposium on Software Metrics, Chicago, IL, USA, 11–17 September 2004; pp. 208–219. [Google Scholar] [CrossRef]
- Tiwari, M. Understanding Scrum Metrics and KPIs. Online, 2019. Medium. Available online: https://medium.com/@techiemanoj4/understanding-scrum-metrics-and-kpis-fcf56833d488 (accessed on 12 April 2020).
- Smart, J. To transform to have agility, dont do a capital A, capital T Agile transformation. IEEE Softw. 2018, 35, 56–60. [Google Scholar] [CrossRef]
- Khanzadi, M.; Shahbazi, M.M.; Taghaddos, H. Forecasting schedule reliability using the reliability of agents’ promises. Asian J. Civ. Eng. 2018, 19, 949–962. [Google Scholar] [CrossRef]
- Chen, C.; Housley, S.; Sprague, P.; Goodlad, P. Introducing lean into the UK Highways Agency’s supply chain. Proc. Inst. Civ. Eng.-Civ. Eng. 2012, 165, 34–39. [Google Scholar] [CrossRef]
- Wagner, S.; Ruhe, M. A systematic review of productivity factors in software development. arXiv 2018, arXiv:1801.06475. [Google Scholar] [CrossRef]
- Maxwell, K.; Forselius, P. Benchmarking software development productivity. IEEE Softw. 2000, 17, 80–88. [Google Scholar] [CrossRef] [Green Version]
- Brodbeck, F.C. Produktivität und Qualität in Software-Projekten: Psychologische Analyse und Optimierung von Arbeitsprozessen in der Software-Entwicklung; Oldenbourg: München, Germany, 1994. [Google Scholar]
- Kitchenham, B.; Mendes, E. Software productivity measurement using multiple size measures. IEEE Trans. Softw. Eng. 2004, 30, 1023–1035. [Google Scholar] [CrossRef]
- Huijgens, H.; Solingen, R.v. A replicated study on correlating agile team velocity measured in function and story points. In Proceedings of the International Workshop on Emerging Trends in Software Metrics, Hyderabad, India, 3 June 2014; pp. 30–36. [Google Scholar] [CrossRef]
- Alleman, G.B.; Henderson, M.; Seggelke, R. Making Agile development work in a government contracting environment-measuring velocity with earned value. In Proceedings of the Agile Development Conference, Salt Lake City, UT, USA, 25–28 June 2003; pp. 114–119. [Google Scholar] [CrossRef]
- Javdani, T.; Zulzalil, H.; Ghani, A.A.A.; Sultan, A.B.M.; Parizi, R.M. On the current measurement practices in Agile software development. arXiv 2013, arXiv:1301.5964. [Google Scholar] [CrossRef]
- Kupiainen, E.; Mäntylä, M.V.; Itkonen, J. Using metrics in Agile and lean software development–a systematic literature review of industrial studies. Inf. Softw. Technol. 2015, 62, 143–163. [Google Scholar] [CrossRef]
- Killalea, T. Velocity in software engineering. Commun. ACM 2019, 62, 44–47. [Google Scholar] [CrossRef]
- Sharma, S.; Kumar, D.; Fayad, M.E. An impact assessment of Agile ceremonies on sprint velocity under Agile software development. In Proceedings of the International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions), Noida, India, 3–4 September 2021. [Google Scholar] [CrossRef]
- Albero Pomar, F.; Calvo-Manzano, J.A.; Caballero, E.; Arcilla-Cobián, M. Understanding sprint velocity fluctuations for improved project plans with Scrum: A case study. J. Softw. Evol. Process. 2014, 26, 776–783. [Google Scholar] [CrossRef] [Green Version]
- IEEE Std 610 12; IEEE Standard Glossary of Software Engineering Terminology. IEEE: New York, NY, USA, 1990. [CrossRef]
- Tripathy, P.; Naik, K. Software Testing and Quality Assurance: Theory and Practice; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- McDonald, M.; Musson, R.; Smith, R. The Practical Guide to Defect Prevention; Microsoft Press: Hong Kong, China, 2007. [Google Scholar]
- Jones, C.; Bonsignour, O. The Economics of Software Quality; Addison-Wesley Professional: Boston, MA, USA, 2011. [Google Scholar]
- Boehm, B. Get ready for Agile methods, with care. Computer 2002, 35, 64–69. [Google Scholar] [CrossRef] [Green Version]
- Boehm, B.; Basili, V.R. Top 10 list [software development]. Computer 2001, 34, 135–137. [Google Scholar] [CrossRef]
- Song, Q.; Jia, Z.; Shepperd, M.; Ying, S.; Liu, J. A general software defect-proneness prediction framework. IEEE Trans. Softw. Eng. 2010, 37, 356–370. [Google Scholar] [CrossRef] [Green Version]
- Mohagheghi, P.; Conradi, R.; Killi, O.M.; Schwarz, H. An empirical study of software reuse vs. defect-density and stability. In Proceedings of the International Conference on Software Engineering, Beijing, China, 30 September 2004; pp. 282–291. [Google Scholar] [CrossRef] [Green Version]
- Nagappan, N.; Ball, T. Use of relative code churn measures to predict system defect density. In Proceedings of the International Conference on Software Engineering, St. Louis, MO, USA, 15–21 May 2005; pp. 284–292. [Google Scholar] [CrossRef]
- Shah, S.M.A.; Morisio, M.; Torchiano, M. An overview of software defect density: A scoping study. In Proceedings of the Asia-Pacific Software Engineering Conference, Hong Kong, China, 4–7 December 2012; Volume 1, pp. 406–415. [Google Scholar] [CrossRef]
- Mijumbi, R.; Okumoto, K.; Asthana, A.; Meekel, J. Recent advances in software reliability assurance. In Proceedings of the IEEE International Symposium on Software Reliability Engineering Workshops, Memphis, TN, USA, 15–18 October 2018; pp. 77–82. [Google Scholar] [CrossRef]
- Fehlmann, T.M.; Kranich, E. Measuring defects in a six sigma context. In Proceedings of the International Conference on Lean Six Sigma, Durgapur, India, 9–11 January 2014. [Google Scholar]
- Li, J.; Moe, N.B.; Dybå, T. Transition from a plan-driven process to Scrum: A longitudinal case study on software quality. In Proceedings of the ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, Bolzano-Bozen, Italy, 16–17 September 2010. [Google Scholar] [CrossRef]
- Collofello, J.S.; Yang, Z.; Tvedt, J.D.; Merrill, D.; Rus, I. Modeling software testing processes. In Proceedings of the IEEE Fifteenth Annual International Phoenix Conference on Computers and Communications, Scottsdale, AZ, USA, 27–29 March 1996; pp. 289–293. [Google Scholar] [CrossRef] [Green Version]
- Jacob, P.M.; Prasanna, M. A comparative analysis on black box testing strategies. In Proceedings of the International Conference on Information Science, Dublin, Ireland, 11–14 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Rawat, M.S.; Dubey, S.K. Software defect prediction models for quality improvement: A literature study. Int. J. Comput. Sci. Issues 2012, 9, 288–296. [Google Scholar]
- Vashisht, V.; Lal, M.; Sureshchandar, G.S. A framework for software defect prediction using neural networks. J. Softw. Eng. Appl. 2015, 8, 384–394. [Google Scholar] [CrossRef]
- Carroll, E.R.; Malins, R.J. Systematic Literature Review: HOW Is Model-Based Systems Engineering Justified? Technical Report SAND2016-2607; Sandia National Laboratories: Albuquerque, NM, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Friedenthal, S.; Moore, A.; Steiner, R. A Practical Guide to SysML; Morgan Kaufmann: San Francisco, CA, USA, 2014. [Google Scholar] [CrossRef]
- Campbell, D.T.; Stanley, J.C. Experimental and Quasi-Experimental Designs for Research; Houghton Mifflin Company: Boston, MA, USA, 1963. [Google Scholar]
- Reichardt, C.S. Quasi-Experimentation: A Guide to Design and Analysis; Guilford Publications: New York, NY, USA, 2019. [Google Scholar]
- Schwartz, D.; Fischhoff, B.; Krishnamurti, T.; Sowell, F. The Hawthorne effect and energy awareness. Proc. Natl. Acad. Sci. USA 2013, 110, 15242–15246. [Google Scholar] [CrossRef]
- Satpathy, T.; et al. A Guide to the Scrum Body of Knowledge (SBOK™ Guide), 3rd ed.; SCRUMstudy: Avondale, AZ, USA, 2016. [Google Scholar]
- Buffardi, K.; Robb, C.; Rahn, D. Learning agile with tech startup software engineering projects. In Proceedings of the ACM Conference on Innovation and Technology in Computer Science Education, Bologna, Italy, 3–5 July 2017; pp. 28–33. [Google Scholar] [CrossRef]
- Ghezzi, A.; Cavallo, A. Agile business model innovation in digital entrepreneurship: Lean startup approaches. J. Bus. Res. 2020, 110, 519–537. [Google Scholar] [CrossRef]
- Kuchta, D. Combination of the earned value method and the Agile approach—A case study of a production system implementation. In Proceedings of the Intelligent Systems in Production Engineering and Maintenance, Wroclaw, Poland, 17–18 September 2018; pp. 87–96. [Google Scholar] [CrossRef]
- Tamrakar, R.; Jørgensen, M. Does the use of Fibonacci numbers in planning poker affect effort estimates? In Proceedings of the International Conference on Evaluation & Assessment in Software Engineering, Ciudad Real, Spain, 14–15 May 2012. [Google Scholar] [CrossRef] [Green Version]
- ClickUp™. Available online: https://www.clickup.com (accessed on 28 February 2023).
- Powerbi™. Available online: https://powerbi.microsoft.com/en-us/ (accessed on 28 February 2023).
- Das, K.R.; Imon, A. A brief review of tests for normality. Am. J. Theor. Appl. Stat. 2016, 5, 5–12. [Google Scholar] [CrossRef] [Green Version]
- Rovai, A.P.; Baker, J.D.; Ponton, M.K. Social Science Research Design and Statistics; Watertree Press: Long Beach, CA, USA, 2013. [Google Scholar]
- Rasch, D.; Teuscher, F.; Guiard, V. How robust are tests for two independent samples? J. Stat. Plan. Inference 2007, 137, 2706–2720. [Google Scholar] [CrossRef]
- Prism™. Available online: https://www.graphpad.com/ (accessed on 28 February 2023).
- Saunders, M.; Lewis, P.; Thornhill, A. Research Methods, 8th ed.; Pearson Education: Upper Saddle River, NJ, USA, 2019. [Google Scholar]
- Cook, T.D.; Reichardt, C.S. Qualitative and Quantitative Methods in Evaluation Research; Sage Publications: Thousand Oaks, CA, USA, 1979. [Google Scholar]
- Matthay, E.C.; Glymour, M.M. A graphical catalog of threats to validity: Linking social science with epidemiology. Epidemiology 2020, 31, 376–384. [Google Scholar] [CrossRef]
- Howell, D.C. Chi-square test: Analysis of contingency tables. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 250–252. [Google Scholar] [CrossRef]
- Field, A. Discovering Statistics Using IBM SPSS Statistics; Sage: Thousand Oaks, CA, USA, 2013. [Google Scholar]
- Kampenes, V.B.; Dybå, T.; Hannay, J.E.; Sjøberg, D.I. A systematic review of quasi-experiments in software engineering. Inf. Softw. Technol. 2009, 51, 71–82. [Google Scholar] [CrossRef]
- Gall, M.D.; Gall, J.P.; Borg, W.R. Educational Research: An Introduction; Pearson: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Field, A.P. Is the meta-analysis of correlation coefficients accurate when population correlations vary? Psychol. Methods 2005, 10, 444–467. [Google Scholar] [CrossRef] [Green Version]
- Gastwirth, J.L.; Gel, Y.R.; Miao, W. The impact of Levene’s test of equality of variances on statistical theory and practice. Stat. Sci. 2009, 24, 343–360. [Google Scholar] [CrossRef] [Green Version]
- Schmider, E.; Ziegler, M.; Danay, E.; Beyer, L.; Bühner, M. Is it really robust? Methodology 2010, 6, 147–151. [Google Scholar] [CrossRef]
- Microsoft 365. Available online: https://www.office.com (accessed on 28 February 2023).
- Diagrams.net. Draw.io. Available online: https://draw.io (accessed on 28 February 2023).
- Sparx Systems. Enterprise Architect 15.2 User Guide. Available online: https://sparxsystems.com/enterprise_architect_user_guide/15.2 (accessed on 28 February 2023).
- Porru, S.; Pinna, A.; Marchesi, M.; Tonelli, R. Blockchain-oriented software engineering: Challenges and new directions. In Proceedings of the 2017 IEEE/ACM 39th International Conference On Software Engineering Companion (ICSE-C), Buenos Aires, Argentina, 20–28 May 2017; pp. 169–171. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | M | Skew | Kurtosis | ||
|---|---|---|---|---|---|
| Scrum | 10 | 0.81 | 0.046 | −0.861 | 0.45 |
| sMBSAP | 10 | 0.93 | 0.032 | -0.041 | 2.83 |
| N | M | Skew | Kurtosis | ||
|---|---|---|---|---|---|
| Scrum | 10 | 26.8 | 2.3 | −0.7 | 1.10 |
| sMBSAP | 9 | 31.8 | 2.2 | −1.3 | 1.83 |
| N | M | Skew | Kurtosis | ||
|---|---|---|---|---|---|
| Scrum | 10 | 1.00 | 0.08 | −0.75 | 1.16 |
| sMBSAP | 9 | 1.05 | 0.07 | −1.26 | 1.71 |
| N | M | Skew | Kurtosis | ||
|---|---|---|---|---|---|
| Scrum | 10 | 0.91 | 0.18 | −0.009 | −2.02 |
| sMBSAP | 10 | 0.63 | 0.29 | −0.42 | −1.7 |
| N | M | Skew | Kurtosis | ||
|---|---|---|---|---|---|
| Scrum | 10 | 0.20 | 0.02 | 0.57 | −1.13 |
| sMBSAP | 10 | 0.15 | 0.06 | −2.09 | 5.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huss, M.; Herber, D.R.; Borky, J.M. Comparing Measured Agile Software Development Metrics Using an Agile Model-Based Software Engineering Approach versus Scrum Only. Software 2023, 2, 310-331. https://doi.org/10.3390/software2030015
Huss M, Herber DR, Borky JM. Comparing Measured Agile Software Development Metrics Using an Agile Model-Based Software Engineering Approach versus Scrum Only. Software. 2023; 2(3):310-331. https://doi.org/10.3390/software2030015
Chicago/Turabian StyleHuss, Moe, Daniel R. Herber, and John M. Borky. 2023. "Comparing Measured Agile Software Development Metrics Using an Agile Model-Based Software Engineering Approach versus Scrum Only" Software 2, no. 3: 310-331. https://doi.org/10.3390/software2030015