3.1. Kinect and CMU Graphics Lab Skeletons
This section describes the two data structures, Kinect and CMU Graphics Lab data, used in this work to represent the human body. The Kinect captures, in real time, a set of joints that represent a simplified model of the human body (skeleton). The CMU dataset provides various movements of the human body that must be processed in order to obtain the segments of the skeleton.
Kinect was one of the first low-cost sensors, launched by Microsoft, capable of capturing the movement of the user to interact with video games and other applications. It consists of an RGB camera, a set of microphones, and a depth sensor [
22].
Microsoft has released two versions, called “Kinect v1” and “Kinect v2”.
Table 1 describes the hardware characteristics of the two versions of Kinect.
Although Kinect has its own software development kit (SDK) (v1 and v2), in this work a different one is used, developed by 3DiVi Inc (Walnut, California, United States) called Nuitrack v0.29.0, compatible with both versions of Kinect and other depth sensors, for example, Orbbec Astra S, Asus Xtion Pro, Asus Xtion 2, and Intel RealSense.
Nuitrack represents the human body with a skeleton made up of 17 joints (
Figure 1). Each joint is given its position and rotation in relation to a global referential. The SDK represents each joint through a structure made up of various joint attributes. If the joint is occluded, there is a parameter (confidence) that is set to zero, which gives us prior knowledge of the status of the joint.
The motion capture dataset of CMU [
8] consists of a set of motion captures organized by categories and actors. Each actor contains a set of movements with their description. The captures are made using 12 infrared cameras (Vicon MX-40) capable of capturing images at 4 megapixels and 120 Hz, although not all the movements were captured at this frequency. The actor contains 41 markers that will be used to determine their skeleton during the recording.
Along with the markers, this dataset provides the movement of the skeleton in ASF/AMC format defined by the Acclaim group [
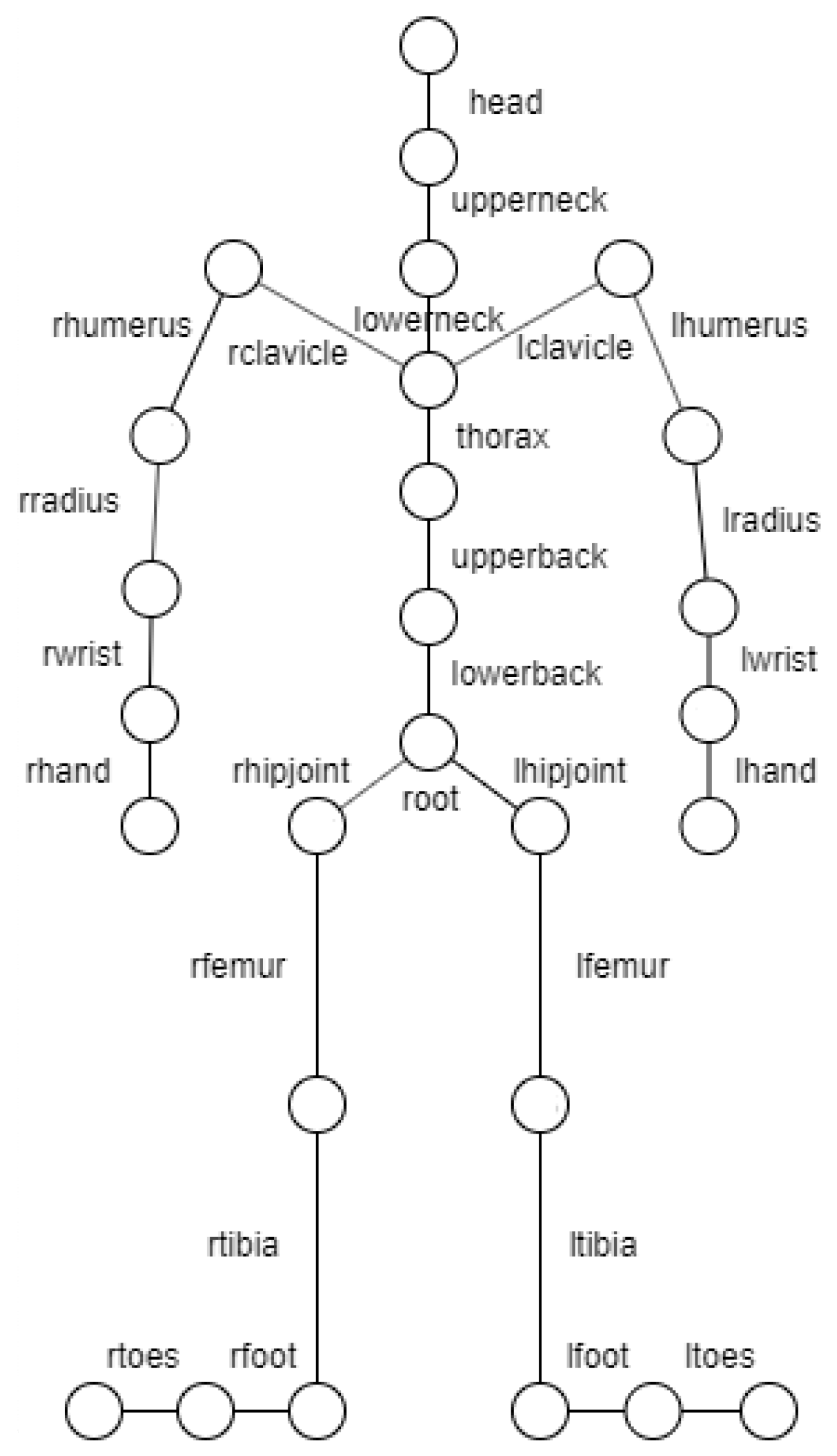
23]. This format consists of two files, Acclaim Skeleton File (ASF) and Acclaim Motion Capture data (AMC). The first contains information about the skeleton and the second about its movement in each frame. The skeleton is defined by a hierarchy of segments, as shown in
Figure 2, where the root point represents the waist and is defined on a global coordinate axis. Each segment is represented by a line connecting two circles. The complete model is composed of 31 joints but in the figure only 27 joints are represented. It is missing the right and left finger joints and also the left and right thumb joints. The data used do not include them.
The ASF file displays information about the skeleton in a given initial pose. This file describes the direction, length, axis, degrees of freedom of each segment, and the limits of rotation. The root point is an exception for which only the initial position and orientation is given, which is reflected in the position of the entire skeleton in global space.
The AMC file contains the movement for the skeleton defined in the ASF file. Each frame describes the rotation of each segment in relation to the respective axis defined in the ASF file. In order for the skeleton to move in space, the position of the root segment is indicated.
The poses of the skeleton at each time instant are generated from the ASF and AMC files. These poses are made up of defined segments by their rotation and global position. The rotations from the AMC file are applied to the initial skeleton defined by the ASF, obtaining the rotation and global position of each segment at a given time.
In addition to the attributes taken directly from the ASF file, there are others that will be calculated during the movement update, namely:
Position: position of the end of the segment in the global coordinate system;
Rotation: current rotation, from the AMC file;
C: rotation matrix made up of “axis”;
: inverse C matrix;
M: global transformation matrix (rotation);
: global rotation, defined by a , of the segment.
The process begins by analyzing the ASF file, defining a total of 31 segments. The initial positions are determined from this file. The position of the segment is defined by the end point of the segment. This point is calculated from the sum of the direction vector with a magnitude equal to the length of the segment and the position of the “parent” segment. This calculation is performed according to the hierarchy; therefore, the “parent” segment has already been determined. After calculating the positions of all the segments, the initial pose of the skeleton is obtained.
To determine the positions of the segments in the next frames, the skeleton hierarchy is traversed, starting at the root element and, for each one, the respective rotations from the AMC file are applied to the direction vectors and the position calculation is repeated.
As the AMC rotations are represented in relation to the ASF “axis”, while the direction vector is represented in the global coordinate system, it is necessary to create a global transformation matrix M that transforms these rotations to the same axis system as the direction vector. In the end, a set of poses is obtained (the skeleton of the human body) made up of 31 segments, each with information about its rotation and position in a global coordinate system.
The objectives of the two acquisition systems are different. The CMU Graphics Lab system, equipped with 12 infrared cameras, is used to build a large database with sequences of human body movements, and given its accuracy, has an associated ground truth. The aim of this work is to use CMU datasets to train a network to denoise the sequences acquired by the Kinect. These sequences contain the natural noise of the acquisition process, which is not estimated in this work. Therefore, there is no ground truth for the Kinect sequences and it is expected that the denoising process can only minimize the impact of occlusion noise.
3.2. Kinect Poses Denoising System
The Kinect sensor can be used to replicate the movement of the human body in a virtual character, for example, for virtual/augmented reality games. However, the occurrence of occlusions, i.e., parts of the body that the camera does not detect, is common, reducing the user experience. To analyze the occurrence of occlusions, a study was carried out with 33,000 poses captured by the Kinect sensor.
Figure 3 shows a histogram of the occurrences of static poses for different occlusion values. It can be seen that 16% of the poses have occlusions, ranging from 1 to 6 occlusions per pose. This problem could be mitigated by using a system that can detect the occluded poses of the human body and predict the correct poses.
The aim of this work is to correct the poses of the human body captured by the Kinect using machine learning techniques, in particular deep neural networks. Therefore, the proposed model is based on a ResNet architecture. This type of method requires a large amount of training data. Thus, the network must be trained with a training set identical to the Kinect data, i.e., a set of 17 well-positioned joints containing the position and rotation. In the research carried out during the development of this work, no database was found with movements captured by Kinect and its meta-information suitable for the objectives of this work. To overcome this difficulty, the dataset provided by CMU Graphics Lab is used. These data differ from the Kinect data in the way they are captured (sensors setup) and also in the model used to represent the human body (skeleton). For this reason, the proposed model includes a block for adapting the CMU data to Kinect data.
The approach developed in this work is represented by the block diagram shown in
Figure 4. It begins with the process of transforming the skeleton defined by the CMU dataset to the Kinect skeleton.
The next block is related to the pre-processing of the data to avoid having to deal with skeletons of different sizes. Additionally, the global coordinates of the joints are transformed to the waist reference point (“waist” joint), reducing the number of joints configurations to one configuration per pose; i.e., whatever the position of the skeleton in the global reference frame, the joints for a given pose always have similar values.
The neural network implemented processes the poses individually, i.e., it has no temporal knowledge of the animation; therefore, jitter is likely to appear in the sequence of the returned poses. To combat this problem, the Savitzky–Golay [
24] filter is applied to the output of the network, which smooths out the movement.
Finally, the inverse conversion of the pre-processing block is carried out in order to obtain the poses under the initial conditions.
3.2.1. Adapting the CMU Skeleton to Kinect
After obtaining a pose from the CMU dataset, the first step is to convert the segments to joints, making the skeleton a set of joints rather than segments. This conversion is achieved by going through the segment hierarchy. It is important to note the hierarchical model of movement in the human body. For example, in the relationship between the humerus segment and the elbow joint, the position of this joint is defined by the position of the humerus segment, but its rotation must affect the next joint, i.e., it is defined by the rotation of the “child” segment which, in this case, is the radius segment.
Then, only the joints similar to the Kinect skeleton are selected and the rest are removed. In
Figure 5, the numbered joints in the CMU skeleton have been selected to represent the Kinect joints with their number.
For each human body movement sequence from the CMU dataset, the conversion is performed and the data are saved in a CSV file. The CSV file consists of the joint name, the components of the position (
) and rotation (quaternions), and the frame number. Concerning the quaternions, the “transforms3d” library is used to support the calculations for this unit. This library handles quaternions in the format (
), which is different from the Kinect and the Unity game engine (tool used to reproduce the human movement) convention (
). To convert to the desired format, the “
w” channel is moved to last and the “
y” and “
z” coordinates are inverted:
The mapping from the CMU skeleton onto the Kinect skeleton is a transformation between a more complete model with 31 joints to 17 joints from the Nuitrack model (Kinect). This simplification can introduce potential limitations in capturing certain movements or body configurations, increasing the diversity of noise that can be considered in the models. For the sake of simplicity, this problem is considered to be modeled by the noise associated with displacements, as described in
Section 3.2.4.
3.2.2. Data Pre-Processing
To improve the DNN’s performance, the poses must be represented in a local coordinate system, always with the same origin point, to avoid distinguishing between poses that are the same but have different coordinates, i.e., each pose has a unique configuration. Therefore, the pre-processing functions convert the global coordinates of a given joint to a local coordinate system of a given origin; in this case the origin is the waist of the skeleton. Global and local transformation matrices are obtained to convert the poses to local and global coordinates.
The poses are scaled to normalize the height and to not have to deal with skeletons of different sizes, just different proportions. The scaling factor used is the average length of the segments,
, during the initial pose. For each pose, the joint hierarchy is traversed and the new positions given by Equation (
2) are calculated; where
is the position of the joint to be normalized,
the position of the “parent” joint, and
the normalized current position:
In other words, the normalized position will be the vector pointing from the “parent” joint to the joint to be normalized, divided by the average length of the segments.
The “waist” joint is the root of the hierarchy and, therefore, retains its original position. The joints should be traversed in a hierarchy, starting at the root, to ensure that the joints above it have their values updated. In the same way as the previous process, the average length of the segments should be saved for each movement in order to return to the original values.
Finally, the rotations are adjusted to ensure that the direction vectors between the parent joint and the child joint are aligned with the respective axis. In this way, the same configuration of rotations represents the same pose, whether in the dataset of CMU or in the data returned from Kinect.
Figure 6 illustrates an example where the rotation axes may not be aligned correctly. It is assumed that the direction vector of the “shoulder” joint should be aligned with the
x-axis, and in the initial pose the rotation is
, as in first diagram in the figure. There may be cases where other direction vectors have been defined during the motion capture, as shown in the second diagram in the figure, in which case, although the pose is visually the same, the angle will not be the same as the previous one and from the perspective of the neural network it will be a new pose. An offset must be applied to the rotation in such a way that the
x-axis coincides with the direction vector, as shown in the third diagram. After this, the rotation returns to the correct value.
The axis that must be aligned with the direction vectors depends on the type of joint. These axes have been defined as follows:
The right arm joints align the x-axis;
The left arm joints align the negative x-axis;
The joints from the waist to the head align the y-axis;
The joints of both legs align the negative y-axis.
The direction vector is given by the local position of the child joint; in the case of
Figure 6, the vector is the local position of “elbow”. To determine the angle of rotation, the position is projected onto the respective planes, for example, if the aim is to align the
x-axis then the point is projected onto the x–y plane to rotate in z and onto the x–z plane to rotate in y.
3.2.3. Deep Neural Network
The deep neural network block is used to eliminate noise from the poses captured by the Kinect. To achieve this, the original poses ground truth and the noisy ones are provided during the training phase, as illustrated in
Figure 7. At this phase, the network will update its parameters throughout the iterations in order to reconstruct the original poses from the noisy ones. A ResNet-type neural network [
25] is used.
3.2.4. Noise Function
The Kinect sensor captures pose information with two types of noise:
Occlusions: The joints move too far from the correct position because they are occluded by an object or part of the human body at the moment of capture.
Displacements: Small deviations of the joints from the correct position due to the sensitivity of the sensor and the environment in which it is located.
In order to simulate this noise in the network’s training data, a noise model is implemented. Occlusions and displacements are randomly generated, where the occlusions are chosen according to a variable with a uniform distribution and the displacements are based on a Gaussian distribution with zero mean and adjusted standard deviation.
The occluded joints take the position (0, 0, 0) and rotation (0, 0, 0, 1), while the displacements move slightly away from the original joint.
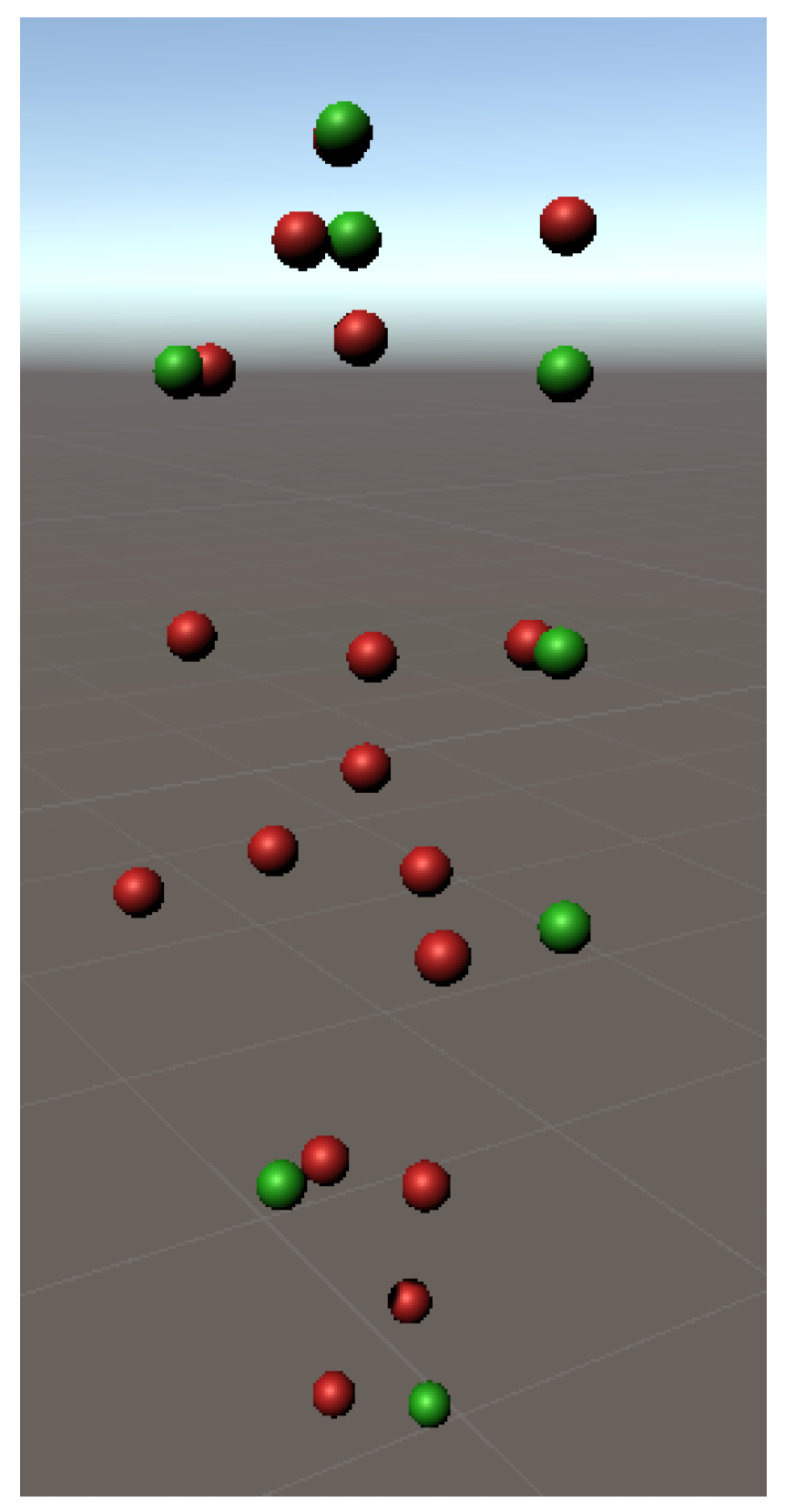
Figure 8 and
Figure 9 illustrate examples of the two types of noise, where the corrupted joints are shown in red and the ground truth in green. In
Figure 8, the red joint that should overlap the green one has been moved to the origin (0, 0, 0) to simulate an occlusion, and in
Figure 9, the red joints suffer some deviations to represent displacements.
When a joint is occluded, it is necessary to eliminate the rotation of the “parent” joint, because the network uses the direction vector to determine the position of the occluded joint. In the case of Kinect, when there is an occlusion it is impossible to determine the exact rotation of the ‘parent’ without knowing the position of the ‘child’ joint, leaving an incorrect value. In this way, the network will return an incorrect position, which is why it is necessary, in both Kinect and CMU poses, to change the rotation of the parent joint to , so that the network learns to correct occlusions without knowing the direction vector.
3.2.5. Temporal Filter
The Savitzky–Golay filter [
24] smooths data, in order to improve accuracy without distorting the signal, by convolution with a polynomial function of degree
n. Given a set of points
, where
,
x is an independent variable and
y is the observed value, the result of the filter is a set of convolutions between the signal and the coefficients
, which depend on the length of the window
m and the polynomial defined:
3.3. Network Implementation
As described in
Section 3.2 and illustrated in
Figure 4 the proposed system starts with the processing of the CMU dataset. Then, poses are captured with Kinect using Unity. Following this, the pre-processing of these data is performed. As for the neural network, the system begins by organizing the data produced followed by the training of the network. In the tuning process, several parameters are studied, in which the results for different values and their interpretation are analyzed. During training, the cross-validation method is used to measure the performance of the model more accurately. The training set is divided into 10 folds and approximately 10% of the data is used for validation. Finally, the temporal filter is applied on the sequence of poses returned by the neural network.
The proposed method is implemented in Python using the libraries for data processing and the TensorFlow API [
26] to facilitate the implementation of the machine learning methods used. TensorFlow API has graphics processing unit (GPU) support, significantly speeding up the network training phase. TensorFlow supports other programming languages such as JavaScript and C#, ideal for developing applications in the Unity game engine, which in the context of this project is used to visualize poses in a more interactive way and detect problems that may occur.
The list of poses is made up of a set of joints which, in turn, are defined by their position (
) and rotation (
), represented by quaternions. Decomposing the pose, the following is obtained:
and
that is,
The fact that the “waist” joint is the origin, means that it always has the same value , so it can be removed, leaving a total of 16 joints. Therefore, the pose is defined by a vector of features.
The data for training the network (CMU poses) are pre-processed once and saved in the binary format. After loading all the training data, the order of the poses is shuffled so that the training and validation data are evenly distributed in terms of movement type (e.g., running or jumping), i.e., so that the two datasets do not contain just one movement type, as this would skew the results. A file is generated containing the original poses and three corrupted files with the different types of noise, keeping the order of the poses after the shuffle function. This avoids processing the data multiple times and guarantees the same conditions for all models.
In order to implement the ResNet architecture in TensorFlow in a modular way, a class structure was developed based on sequential blocks that facilitates model management (saving and loading previous models). In order to support different network architectures, a base class was created, which implements the general functionalities of the model. The “ResNetModel” class extends these functionalities and uses the “ResidualBlock” layers in the sequential model. The “SimpleModel” class follows the same approach but with dense layers provided by the API. The model settings are indicated in the “HyperParameters” class in order to group all the parameters in a single object. This structure allows for great abstraction in the network tuning phase. It can load previous models from the saved configurations and saved weights, even if “z-score” normalization is used because this is performed in the model itself, of the “CustomModel” type.
The ResNet architecture is made up of residual blocks which, in turn, contain one or more layers [
27]. The example of defining the residual blocks in [
6] is followed, each with a dense layer and a skip connection without additional layers. In this project, a similar architecture is implemented, excluding the markers and changing the number of residual blocks in each layer (dense layer). After testing different configurations, a ResNet of a residual block with a dense layer of 1000 neurons was obtained; shown in
Figure 10.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}