Algorithm for Producing Rankings Based on Expert Surveys



Abstract
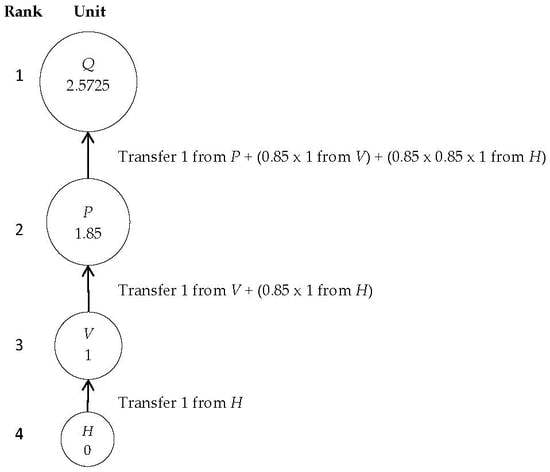
1. Introduction
2. Basics of SSRR
3. Lessons Learned from the Public Brainpower Ranking
- A cut-off point was selected for the self-assessed competence of the experts, and only those assessments that were above that point were included.
- The country that was most often rated as No. 1 among all experts was identified. This was not necessarily going to be the top country in the final ranking; it was just a starting point.
- The three countries most often placed directly below and above this country were identified. Each of these countries formed a dyad with the first country.
- For each of those dyads, it was calculated which of the two countries was most often placed higher than the other.
- If two countries were placed above each other the same number of times, the sum of the experts’ competence on the two countries was calculated, and the country which the experts had most competence on was placed highest.
- If the two countries still had the same number of points, the analysis was expanded to include the top 15 countries by competence rank. If they were still equal, the input was expanded to include all of the countries ranked.
- On this basis, it was worked out which country was No. 2.
- Then country No. 2 was subjected to the same treatment as country No. 1.
- Next, the same was repeated for the resulting country No. 3 and onwards until all countries were subsumed into the ranking.
4. Challenges
5. Link Analysis as a Basis for Ranking
6. Building an Automated Algorithm
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Algorithm Code
<?php
header(’Content-Type:text/html; charset=utf-8’);
$units = array();
$experts = array();
$ranking = array();
$segments = array();
if(($handle = fopen(’data.csv’, ’r’)) !== false) {
while(($data = fgetcsv($handle, 0, ",")) !== false)
{
$units[[] = $data[0 ];
$experts[[] = $data[1];
$ranking[[] = $data[2];
unset($data);
}
fclose($handle);
}
foreach (array_unique($experts) as $e) {
$segments[$e] = array();
}
foreach ($units as $k => $v) {
$segments[$experts[$k]][$v] = array($ranking[$k]);
}
foreach ($segments as $k => $v) {
asort($v);
$segments[$k] = $v;
}
$units = array_values(array_unique($units));
function findChildren($parent, $unit, $children, $level) {
global $segments;
$generation = array();
foreach($segments as $pool) {
if (isset($pool[$unit])) {
$unitRank = $pool[$unit][0];
foreach($pool as $pk => $pv) {
if ($pk != $parent
&& $pv[0] > $unitRank
&& !isset($children[$pk])) {
$children[$pk] = 1 * pow(0.85, $level);
$generation[[] = $pk;
}
}
}
}
if (sizeof($generation) > 0) {
$level++;
foreach($generation as $child) {
$children = findChildren($parent, $child, $children, $level);
}
}
return $children;
}
$rank = array();
foreach($units as $unit) {
$children = array();
$rank[$unit] = round(array_sum(findChildren($unit, $unit, $children, 0)), 5) * 100000;
}
arsort($rank);
$result = array();
foreach ($rank as $k => $v) { $result[$v][[] = $k; }
$numberOfSegments = sizeof($segments);
$numberOfUnits = sizeof($units);
$notice = false;
echo "<h4>Ranking for " . $numberOfUnits . " units in " . $numberOfSegments . " segments:</h4>";
echo "<ol>";
foreach ($result as $k => $v) {
if ( sizeof($v) > 1) {
$notice = true;
echo "<li>";
foreach($v as $vk => $vv){
echo (0 == $vk) ? "<span style=’color: red;’>" . $vv . "</span>" : " | <span style=’color: red;’>" . $vv . "</span>";
}
echo "</li>";
} else {
echo "<li><span>" . $v[0] . "</span></li>";
}
}
echo "</ol>";
if ($notice) {
echo "<h2>Notice:</h2><hr><p>The above list contains units with equal ranking (colored red). These units have the same position in the final list. Please, consider providing extra data with ranking of these units relative to each other.</p><hr>";
}
?>
References
- Aspinall, W. A route to more tractable expert advice. Nature 2010, 463, 294–295. [Google Scholar] [CrossRef] [PubMed]
- Beddow, R. Fighting Corruption, Demanding Justice: Impact Report; Transparency International: Berlin, Germany, 2015; ISBN 978-3-943497-88-5. [Google Scholar]
- Lambsdorff, J.G. The methodology of the TI Corruption Perceptions Index. Transparency International and University of Passau. 2006. Available online: https://www.transparency.org/files/content/tool/2006_CPI_LongMethodology_EN.pdf (accessed on 9 November 2018).
- Treisman, D. What have we learned about the causes of corruption from ten years of cross-national empirical research? Annu. Rev. Political Sci. 2007, 10, 211–244. [Google Scholar] [CrossRef]
- Langfeldt, L. Decision-Making in Expert Panels Evaluating Research: Constraints, Processes and Bias; NIFU: Oslo, Norway, 2002; ISBN 82-7218-465-6. [Google Scholar]
- Steenbergen, M.R.; Marks, G. Evaluating expert judgments. Eur. J. Political Res. 2007, 46, 347–366. [Google Scholar] [CrossRef]
- Serenko, A.; Bontis, N. A critical evaluation of expert survey-based journal rankings: The role of personal research interests. J. Assoc. Inf. Sci. Technol. 2018, 69, 749–752. [Google Scholar] [CrossRef]
- Wilhelm, G.P. International validation of the Corruption Perceptions Index: Implications for business ethics and entrepreneurship education. J. Bus. Ethics 2002, 35, 177–189. [Google Scholar] [CrossRef]
- Maestas, C. Expert surveys as a measurement tool: Challenges and new frontiers. In The Oxford Handbook of Polling and Survey Methods; Atkenson, L.R., Alvarez, R.M., Eds.; Oxford University Press: Oxford, UK, 2016; pp. 13–26. [Google Scholar] [CrossRef]
- Marquardt, K.L.; Pemstein, D. IRT models for expert-coded panel data. Political Anal. 2018, 26, 431–456. [Google Scholar] [CrossRef]
- Tofallis, C. Add or multiply? A tutorial on ranking and choosing with multiple criteria. INFORMS Trans. Educ. 2014, 14, 109–119. [Google Scholar] [CrossRef]
- Mukhametzyanov, I.; Pamucar, D. A sensitivity analysis in MCDM problems: A statistical approach. Decis. Mak. Appl. Manag. Eng. 2018, 1, 51–80. [Google Scholar] [CrossRef]
- Sremac, S.; Stević, Ž.; Pamučar, D.; Arsić, M.; Matić, B. Evaluation of a Third-Party Logistics (3PL) Provider Using a Rough SWARA–WASPAS Model Based on a New Rough Dombi Aggregator. Symmetry 2018, 10, 305. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Liu, F.; Aiwu, G.; Lukovac, V.; Vukic, M. A multicriteria model for the selection of the transport service provider: A single valued neutrosophic DEMATEL multicriteria model. Decis. Mak. Appl. Manag. Eng. 2018, 1, 121–130. [Google Scholar] [CrossRef]
- Overland, I. (Ed.) Lonely minds: Natural resource governance without input from society. In Public Brainpower: Civil Society and Natural Resource Management; Palgrave: Cham, Switzerland, 2018; pp. 387–407. ISBN 978-3-319-60626-2. Available online: https://www.academia.edu/35377095 (accessed on 30 June 2018).
- Overland, I. (Ed.) Introduction: Civil society, public debate and natural resource management. In Public Brainpower: Civil Society and Natural Resource Management; Palgrave: Cham, Switzerland, 2018; pp. 1–22. ISBN 978-3-319-60626-2. Available online: https://www.researchgate.net/publication/320656629 (accessed on 17 July 2018).
- Borodin, A.; Roberts, G.O.; Rosenthal, J.S.; Tsaparas, P. Link analysis ranking: Algorithms, theory, and experiments. ACM Trans. Internet Technol. 2005, 5, 231–297. [Google Scholar] [CrossRef]
- Fu, H.H.; Lin, D.K.; Tsai, H.T. Damping factor in Google page ranking. Appl. Stoch. Models Bus. Ind. 2006, 22, 431–444. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Garg, R.; Mishra, P.K. Discussion on damping factor value in PageRank computation. Int. J. Intell. Syst. Appl. 2017, 9, 19–28. [Google Scholar] [CrossRef]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Harzing, A.W.; Reiche, B.S.; Pudelko, M. Challenges in international survey research: A review with illustrations and suggested solutions for best practice. Eur. J. Int. Manag. 2013, 7, 112–134. [Google Scholar] [CrossRef]
- Moy, P.; Murphy, J. Problems and prospects in survey research. J. Mass Commun. Q. 2016, 93, 16–37. [Google Scholar] [CrossRef]
- Thomas, D.I. Survey research: Some problems. Res. Sci. Educ. 1974, 4, 173–179. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Description |
|---|---|
| A | Excellent performance: strong evidence of original thinking; good organization; capacity to analyze and synthesize; superior grasp of subject matter with sound critical evaluations; evidence of extensive knowledge base; high level of motivation. |
| B | Good performance: evidence of grasp of subject matter; some evidence of critical capacity and analytical ability; reasonable understanding of relevant issues; regular attendances of classes; productive contribution to the discussion by sharing thoughts and questions that demonstrate familiarity with the material; interest in other students’ contributions. |
| C | Average performance: understanding of the subject matter; ability to develop solutions to simple problems in the material; acceptable but uninspired work, not seriously faulty but lacking style and vigor; meeting the basic requirements of preparedness and regular attendance; rare participation in class discussion. |
| D | Poor performance: inconsistency in attendance and preparation for classes; lack of participation in class discussions; absence of respect for the contributions of other students. |
| E | Inadequate performance: little or no evidence of understanding of the subject matter; weakness in critical and analytic skills; limited or irrelevant use of the literature. |
| Unit | Expert | Ranking |
|---|---|---|
| Q | I | 1 |
| P | I | 2 |
| P | II | 1 |
| H | II | 2 |
| P | III | 1 |
| D | III | 2 |
| V | III | 3 |
| D | IV | 1 |
| Q | IV | 2 |
| R | IV | 3 |
| V | V | 1 |
| R | V | 2 |
| Expert I | Expert II | Expert III | Expert IV | Expert V |
|---|---|---|---|---|
| Q | P | P | D | V |
| P | H | D | Q | R |
| V | R |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Overland, I.; Juraev, J. Algorithm for Producing Rankings Based on Expert Surveys. Algorithms 2019, 12, 19. https://doi.org/10.3390/a12010019
Overland I, Juraev J. Algorithm for Producing Rankings Based on Expert Surveys. Algorithms. 2019; 12(1):19. https://doi.org/10.3390/a12010019
Chicago/Turabian StyleOverland, Indra, and Javlon Juraev. 2019. "Algorithm for Producing Rankings Based on Expert Surveys" Algorithms 12, no. 1: 19. https://doi.org/10.3390/a12010019
APA StyleOverland, I., & Juraev, J. (2019). Algorithm for Producing Rankings Based on Expert Surveys. Algorithms, 12(1), 19. https://doi.org/10.3390/a12010019