1. Introduction
Endangered languages are an important part of the world’s cultural heritage. Preservation of endangered languages may require speech recording, processing, and automatic recognition. Since the early days of modern computer science, automatic speech recognition (ASR) has been one of the biggest and hardest challenges in the field that requires huge volumes of speech data [
1]. Over the years, a large majority of research conducted in this area focused on the most widely spoken languages, such as English, French, Mandarin Chinese, etc. [
2,
3]. Large corpora of speech data such as Librispeech [
4] for English and AISHELL-1 [
5] for Mandarin are available. End-to-end platforms for ASR and other speech-related tasks (speech-to-text apps, voice command interfaces, etc.) have been developed [
6,
7].
However, the so-called under-resourced languages have less speakers and, correspondingly, there are less spoken language resources available for the research [
8]. One example is the Lithuanian language, one of the Baltic languages with about 3.2 million speakers, which received very little attention from researchers. This was partially due to complicated language structure, free order of words in a sentence, scarcity of linguistic data, as well as historical reasons. Therefore, the methods and models developed for other languages such as English cannot be directly adopted for Lithuanian, and the demand for an automated speech recognition (ASR) system capable of processing Lithuanian language still exists.
Recent developments in the automatic speech recognition field, mainly fueled by the advancements made by deep learning methods, have shown impressive results even for under-resourced languages [
9,
10]. Based on these results we believe that the state-of-the-art deep learning methods can be used to create a high accuracy ASR system for the Lithuanian language.
Recognition of isolated speech has been investigated by several researchers. Lipeika et al. [
11] created a dynamic time warping (DTW)-based system, capable of understanding more than 12 different phrases. The system uses hidden Markov models (HMM) rather than deep learning and achieved an accuracy of 56.67%. Raškinis et. al [
12] proposed an HMM-based ASR system based on Mel frequency cepstral coefficients (MFCC). With only 60.6 min of annotated speech, the authors have managed to achieve lower than a 20% word error rate (WER) in isolated speech experiments. Several years later a hybrid HMM-artificial neural network (ANN) method, proposed by Filipovič et al. [
13], used a hybrid HMM/ANN architecture based on a fully connected three-layer perceptron trained by stochastic back-propagation, and managed to achieve lower than a 13.3% WER with the same dataset. Dovydaitis and Rudžionis [
14] used HMM with deep neural networks. Using Mel-frequency cepstral coefficient (MFCC) features, they achieved 96% accuracy of a subset of samples from Lithuanian native speakers’ database LIEPA. Ivanovas and Navakauskas [
15] used finite impulse response and lattice-ladder multilayer perceptron (MLP) network with 8 hidden layers for speaker identification. Korvel et al. [
16] employed the convolutional neural network (CNN) on the 2D audio signal feature maps derived from spectrograms, linear and Mel-scale cepstrograms, and chromatograms, achieving an f-score of 0.99 for a small 111-word dataset. Finally, Salimbajevs and Kapociute-Dzikiene [
17] employed a system based on an open-source Kaldi toolkit for training of time-delay deep neural network (TDNN) models [
18] and iVectors for adaptation of speakers [
19], and achieved an f-score of 99.1%.
Several studies have been done in recognition of speech transmitted over telephony networks. For instance, Šilingas et al. [
20] presented their investigation of using various phoneme sets for acoustic modeling of the Lithuanian speech applied to continuous speech recognition based on HMM models. Lipeika and Laurinčiukaitė [
21] presented an ASR system based on phonemes and syllables capable of achieving 56.67% recognition accuracy. Inspired by their success they proposed an updated model, that used phonemes, syllables, and words that could achieve 58.06% accuracy [
22]. Lileikytė et al. [
23] found that an effective speech transcription system for Lithuanian broadcast data capable of achieving 18.3% WER can be built by using a combination of unsupervised and semi-supervised training methods such as a deep neural network with a bottleneck layer. An ASR system, designed for Estonian language, was retrained to solve a Lithuanian speech recognition task [
24]. The system, first, trained a speaker-adaptive GMM model, which was later used for generating state-level alignments for training the time-delay neural network (TDNN) with six hidden layers. With just 84 h of annotated speech, their system achieved 85.3% recognition accuracy. An automatic speech recognition system focusing on conversational telephone speech achieved 42.4% WER [
25]. Another ASR system for telephone speech managed to reduce WER set by the aforementioned study down to 48.3% [
26].
The idea to use speech recognizers designed for foreign languages was investigated by several authors. Results presented in [
27] and [
28] indicate that while it is possible to use foreign language models for Lithuanian speech annotation, their application is limited and does no guarantee good results. Rudžionis et al. [
29] concluded that the ASR system for the Spanish language is the most suitable for Lithuanian speech recognition. Although Spanish ASR does not surpass Lithuanian ASR, the authors suggested that these two systems could be used in a hybrid ASR system to increase recognition accuracy. Finally, Rasymas and Rudžionis [
30] suggested to combine Russian, English, and Dutch recognizers to recognize Lithuanian language commands using a neural network. Such combination allowed to achieve 4.92% improvement in accuracy over a single recognizer.
Studies focusing on exploring phoneme extraction methods have been conducted by [
31] and [
32]. In [
33] authors presented their efforts to create the Lithuanian speech database LTDIGITS. Vaičiūnas et al. [
34] investigated the idea of improving statistical language models by interpolating them with complex n-gram models derived by performing word clustering and morphological decomposition.
Several studies have addressed the problem of ASR of Slavic languages. Karpov et al. [
35] employed n-grams and used statistical and syntactical analysis to build a language model for Russian speech recognition. Later, Kipyatkova and Karpov [
36] constructed artificial neural network (ANN) models and performed linear interpolation of ANN models with the trigram Russian model. Jadczyk [
37] used feature concatenation and model fusion with MFCC features and the hidden Markov model (HMM) modeling technique for Polish speech recognition. Pakoci et al. [
38] used the n-gram model for tuning sequence-trained long short-term memory (LSTM)-based deep neural network for Serbian.
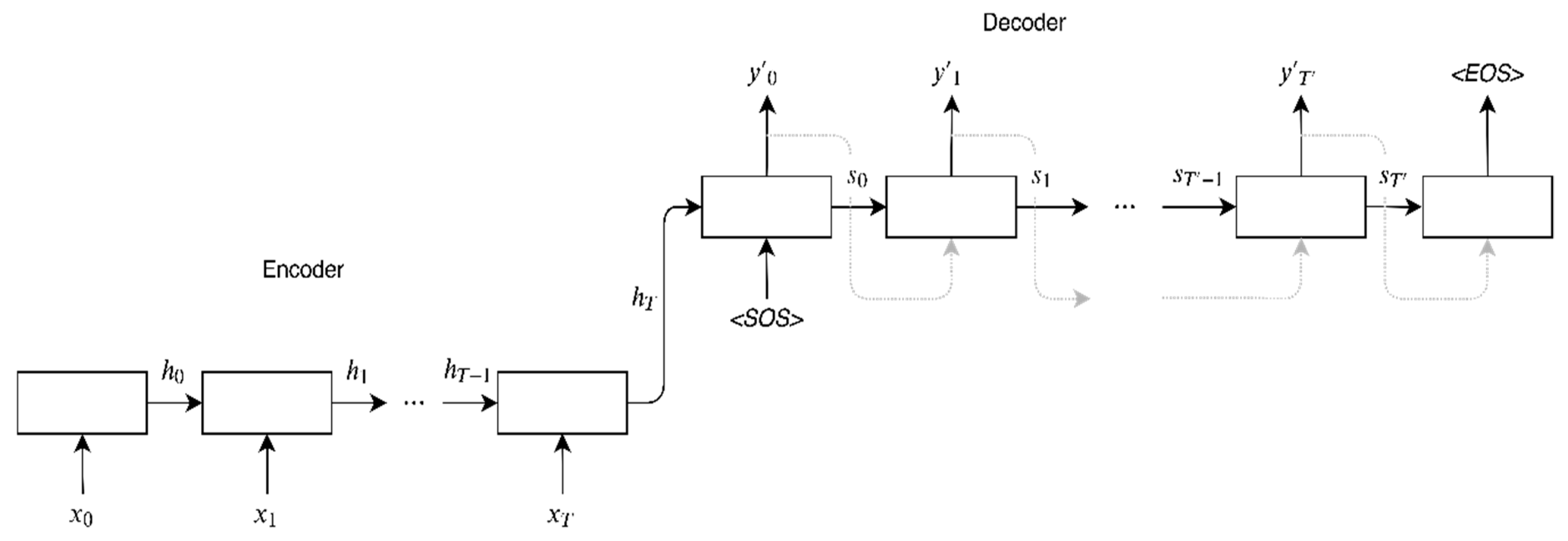
Sequential graphemes and phonemes can be assigned to a categorical data type. The set of unique meanings of phonemes (and graphemes) is known in advance and defined during the process of extracting phoneme sequences and depends on the language of the dataset. Before transmitting categorical data into a statistical model, it is common to process it using one-hot encoding. Sutskever et al. [
39] introduced the sequence to sequence model for machine translation. LSTM cells were used for the encoder and decoder parts of the model. Another model is an encoder–decoder type model with Luong et al. [
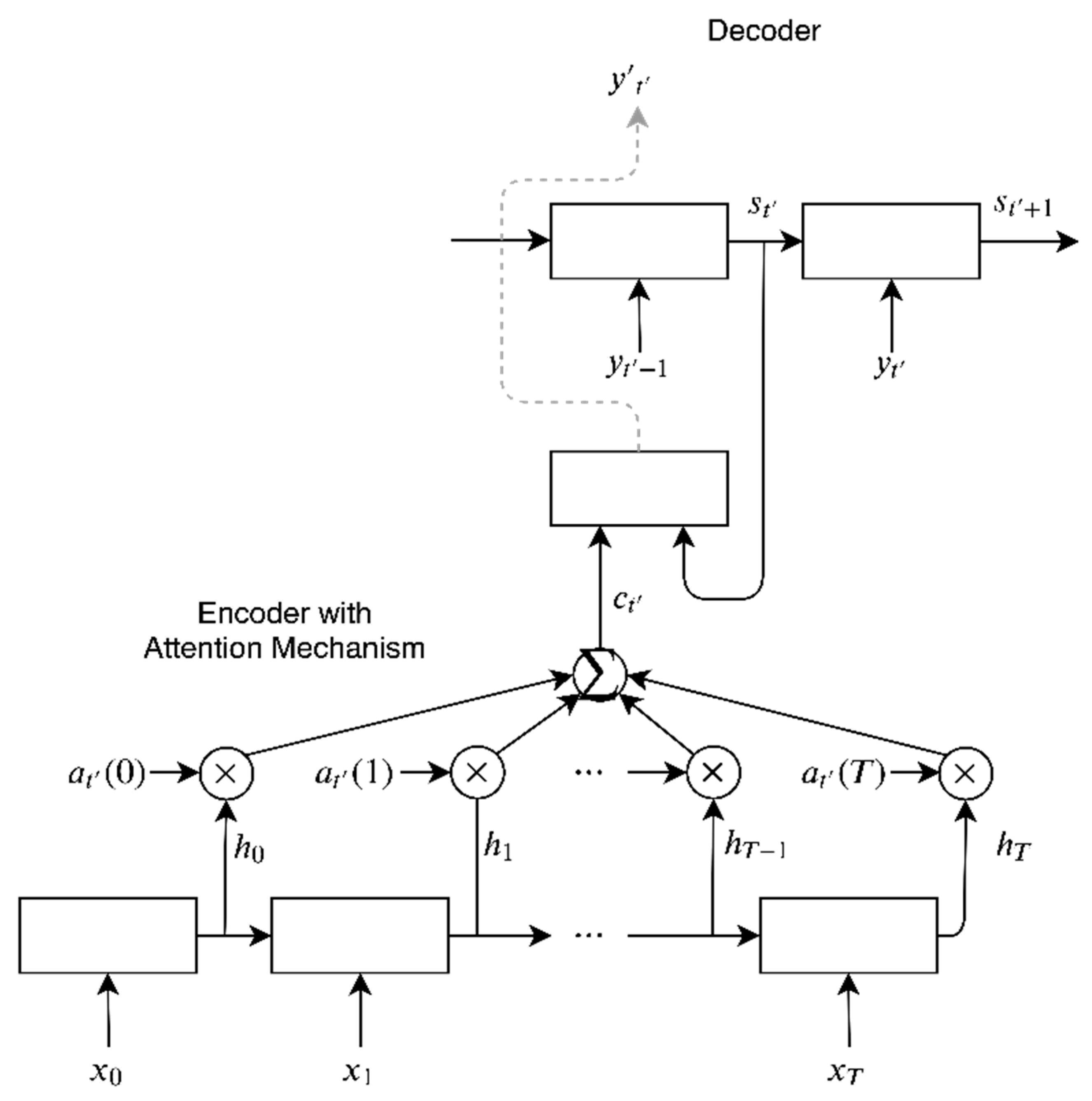
40] who proposed a focus mechanism and bidirectional LSTM cell layers in the encoded and decoded portions. This type of model is called the attention model.
To our knowledge, no prior studies have examined the task of Lithuanian ASR directly from the phoneme sequences. This problem poses an interesting challenge as the same phoneme (or a group of them) can represent different graphemes. Furthermore, processing long phoneme sequence is a complicated task, because the pauses between uttered words depend solely on the talking speed of speakers. On regular ASR systems, this task would be carried out by pronunciation and language models. However, the creation of these models is complicated work requiring a lot of linguistic resources. The phoneme-based ASR system would not only be much simpler, it would also allow to use the existing acoustic models. We also believe that such a system would be appropriate for a Lithuanian language, as there exists a strong connection between phonological and morphological forms of words in the Lithuanian language.
3. Experiments and Results
3.1. Dataset
Speech corpus that we used to train and evaluate models contains 86 h of annotated Lithuanian speech (406 k words) from the Lithuanian speech corpora LIEPA [
49]. It is composed of short commands, single word utterances, and even long sentences. There were 248 female and 128 male speakers, 83% of this group aged 15 to 22 yrs. The original phoneme system was MBROLA, all records were in 22 kHz, 16-bit mono format. The audio data were automatically processed to extract sequences of phonemes from raw audio files. Vocabularies of phonemes and graphemes consisted of 91 different phonemes and 61 distinct graphemes, respectively.
The characteristics of datasets by phoneme length used are summarized in
Table 1. When measured by their phoneme sequence lengths most recordings are relatively short (<10 phonemes), although there are some very long recordings (up to 573 phonemes). The data in our corpus exhibits strong correlation between phoneme and grapheme sequence lengths (Pearson coefficient of 0.997), however not all sequence pairs have an equal length.
For our experiments, we split our corpus into 3 datasets: training dataset (60% of data, ~52 h of speech, 244,860 words), validation dataset (10% of data, ~26 h of speech, 40,841 words), and testing dataset (30% of data, ~9 h of speech, 120,387 words). We used the validation dataset to find the most appropriate hyperparameters and evaluated models on testing dataset to find how well these models generalize the unknown/unseen data.
To test to what extent encoder–decoder models can be used to perform automatic Lithuanian speech recognition, we decided to test selected models in isolated speech and long phrase recognition tasks.
3.2. Isolated Speech Experiments
The first experiment was done to check if the models can find a mapping between phoneme sequences and their corresponding grapheme sequences. For this experiment we isolated every word (and its phoneme and grapheme sequences) in the training, validation, and testing datasets. We then trained our models using words from the training dataset and used the validation dataset to find the most appropriate hyperparameters. The models were trained using Adam optimization [
50] with a learning rate of 0.01. To speed up training, we used the teacher-forcing method and applied a gradient clipping to keep the gradients of artificial neural networks between −5 and +5. We used batches of 32 sequences and made sure that all sequences were roughly the same length by bucketing sequences into buckets by their lengths, so that lengths of sequences in each bucket would not differ by more than 4. Finally, we used one-hot encoding to encode phonemes and graphemes as categorical variables.
To find the hyperparameters of the best performing model we tested several different configurations. More specifically, we trained 16 different models, which differed in the number of LSTM layers (from 2 to 5) and number of LSTM cells per layer (32, 64, 128, or 256).
The results of this experiment are presented in
Table 2 and
Table 3. We found that the best performing encoder–decoder model without attention mechanism had 2 LSTM layers with 128 LSTM cells per layer in encoder and decoder parts (
Seq2Seq-2x128). Our best performing model with an attention mechanism had 2 LSTM layers with 64 bidirectional LSTM cells (
Attention-2x64). Furthermore, we found, that when trained with reversed sequences, models perform slightly better. We have not found any benefits of using dropout even with deeper, wider networks.
The encoder–decoder models can learn to map phoneme sequences to their corresponding grapheme sequences, i.e., recognize uttered words solely from their phoneme sequences. Furthermore, it can achieve high recognition accuracy (>99%). Interestingly, we found that both the sequence–sequence and attention models behave similarly on all datasets.
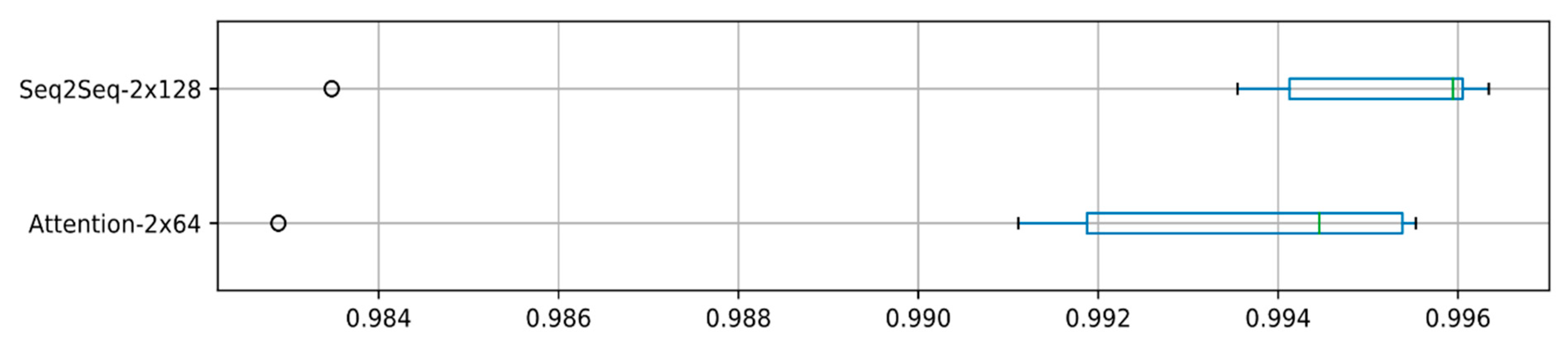
To get a more accurate estimate of model performance and to ensure that our models do not suffer from sampling-bias, which may have occurred while splitting the original corpus into 3 datasets, we chose to train and test our models using 10-fold cross-validation. The cross-validation results, as presented in
Figure 3, confirm that that both the
Seq2Seq-2x128 and
Attention-2x64 models can attain high accuracy (>99%). A relatively small spread around median accuracy proves that models do not overfit. Therefore, we claim that the encoder–decoder models generalize well and can learn to map phoneme sequences to grapheme sequences.
With the longer learning time of ANN, it can be seen that the loss function decreases steadily during the learning process, but the error with the verification dataset begins to increase over time. To avoid this, we use an early stopping strategy, which does not choose the final model parameters obtained at the end of the learning process, but the parameters with which the model has reached the minimum value of the loss function with the verification dataset.
We also evaluated the two best models using the Levenshtein distance metric (see
Table 4). Low values of mean and median Levenshtein distance metric confirm that the
Seq2Seq-2x128 and
Attention-2x64 models can recognize words well and the errors are rare.
3.3. Recognition of Long Phrases
The second experiment was performed to investigate how well these models could be applied to recognition of long phrases. This is a much more demanding task, as it requires the model not only to learn a mapping between phoneme and grapheme sequences, but also to be able to distinguish which part of a phoneme sequence belongs to which word, i.e., to find beginnings and endings of the words. For this experiment, we sampled sequences from the original datasets by taking every combination of consecutive words in the recording, for example, in an utterance of 3 words we created 6 different sequences: . The phoneme and grapheme sequences corresponding to these words were merged together. The spaces were added to the grapheme sequences to mark the word boundaries. The resulting sequences were filtered by their lengths to create 6 different dataset groups. Each dataset group was bounded by the longest sequence of phoneme in that group.
We used models from previous experiment (Seq2Seq-2x128 and Attention-2x64) and trained them on each dataset group in order to find (a) whether models can learn to distinguish words when there is more than one word in the utterance; (b) how sequence length affects performance of our models. As in the previous experiment, we used the Adam optimization, however, this time we lowered the learning rate to 0.001. We trained our models using reversed sequences and clipped the gradients using threshold −5 and +5. Each model was trained for 20 epochs with early stopping.
The results of our experiment are presented in
Table 5 and
Table 6.
Table 5 shows that models can achieve high accuracy even when trained with phoneme sequences from multiple words. The best accuracy was achieved by
Seq2Seq-2x128 (0.990) and
Attention-2x64 (0.992).
Table 6 indicates that models can reach very low WER values. Interestingly, few configurations (e.g.,
Seq2Seq-2x128 model was trained with dataset, where the longest phoneme sequence is 28 phonemes long, while
Attention-2x64 model was trained with the longest phoneme sequence of 20 phonemes) show very large differences between validation and testing accuracy metrics. The same pattern can be observed in the WER results.
Our results indicate that models cannot only map phonemes to corresponding sequences of graphemes, but also learn to find word boundaries and distinguish words in these sequences. The encoder–decoder models can be used as a viable option for speech recognition from phone sequences.
Interestingly, we can observe that the models trained on a dataset, where the longest phoneme sequence is just 8 phonemes, perform much worse than the models which were trained with longer sequences. While it is unclear, what causes models to underperform with short sequences, we speculate that this might be due to a much smaller training dataset.
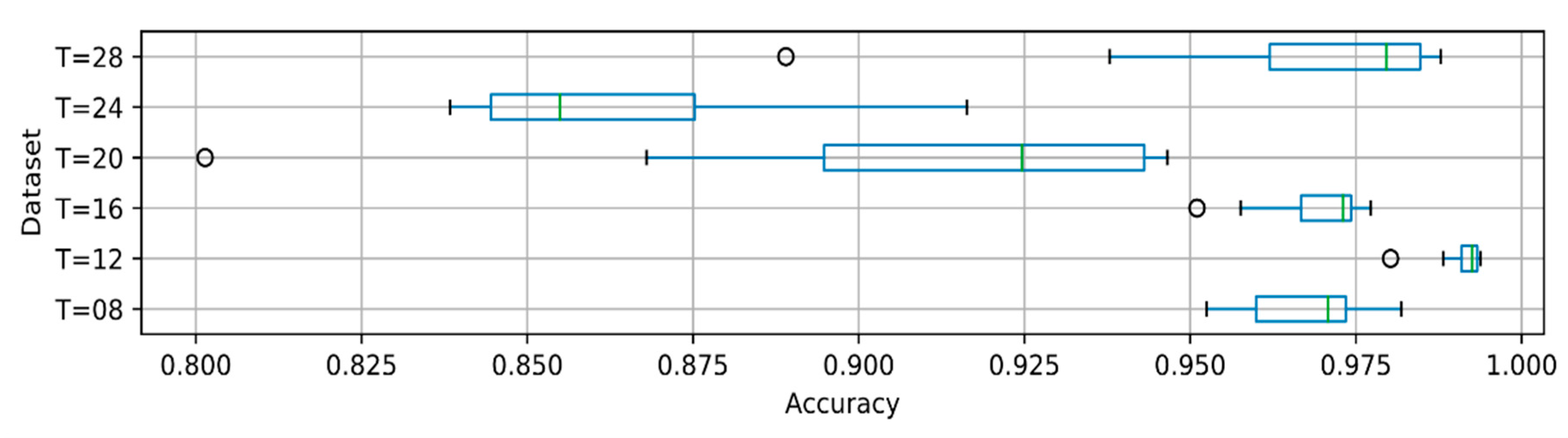
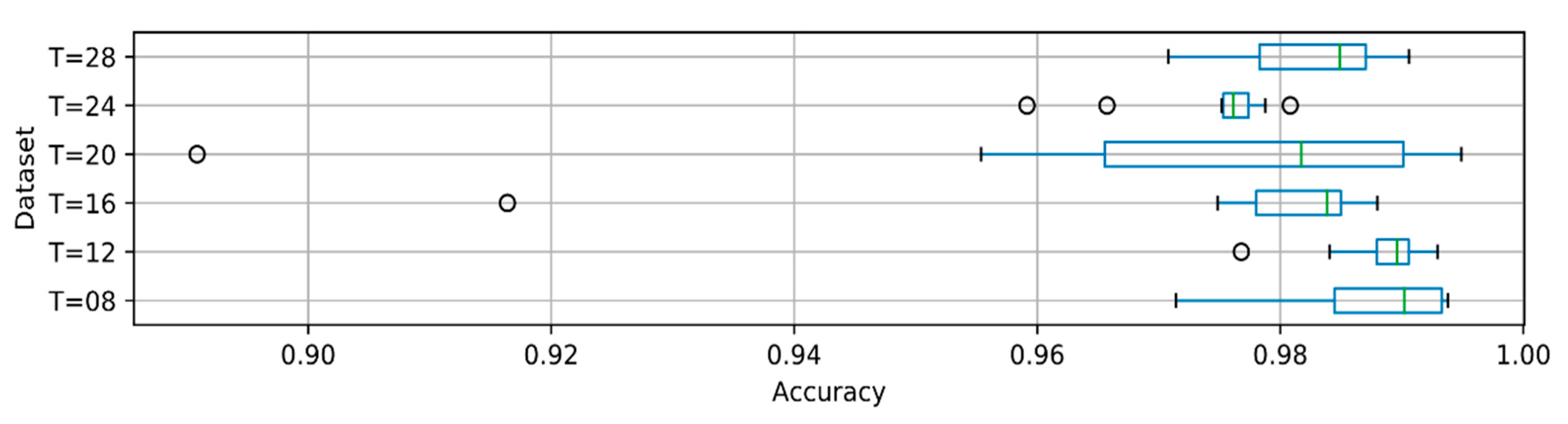
As with isolated speech experiments, we tested the performance of our models using 10-fold cross-validation. The cross-validation results are presented in
Figure 4 and
Figure 5.
By comparing Seq2Seq-2x128 and Attention-2x64 results, we can see that the model with an attention mechanism (Attention-2x64) is much more stable with both shorter and longer sequences, as high recognition accuracy was achieved on almost all folds. The basic sequence–sequence encoder–decoder model, on the other hand, does not perform as well as the model with attention mechanism, and the results of each fold have more variability, as indicated by a larger interquartile range (see, e.g., sequences of T = 20 and T = 24).
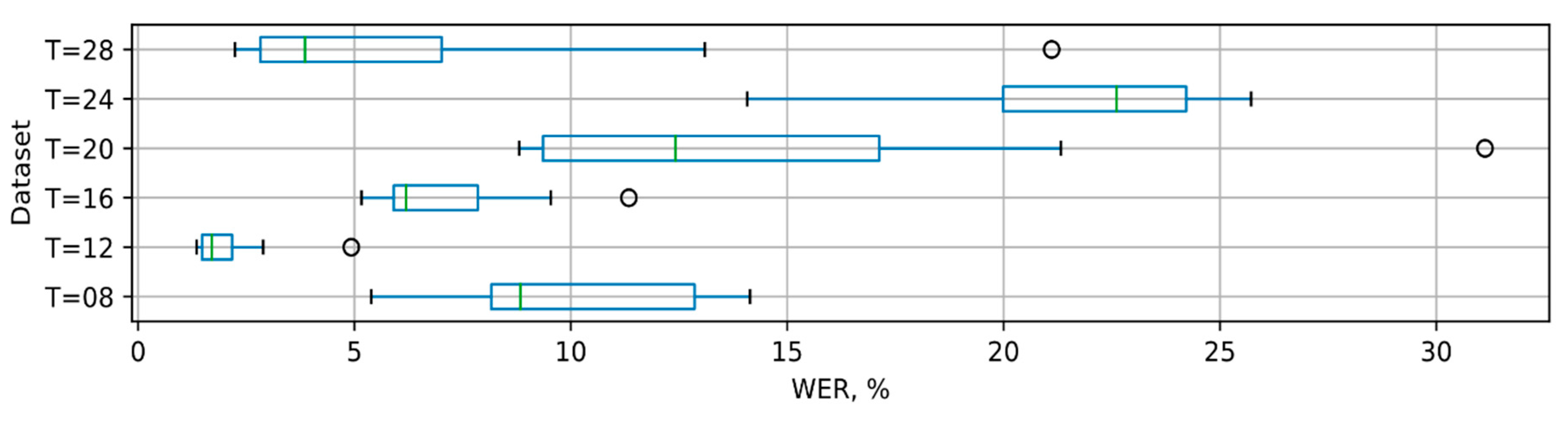
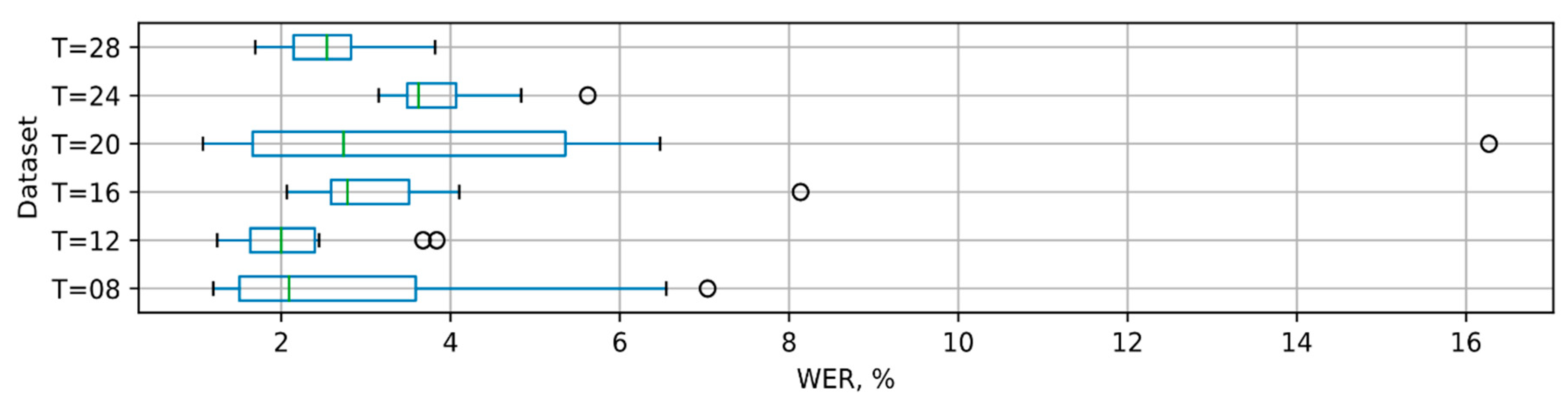
The WERs, of which models managed to achieve during cross-validation, are presented in
Figure 6 and
Figure 7. It is apparent that the
Seq2Seq-2x128 model is less stable, as compared to the attention-2x64 model with an attention mechanism, as indicated by higher interquartile range.
While in our experiments we limited phoneme sequences to 28 phonemes, we believe that larger encoder–decoder models can be used with even longer sequences.
4. Discussion
Although the field of automatic Lithuanian language recognition is not new, there are few ASR applications and related research in the field of Lithuanian language processing. The main reasons are the complexity of the Lithuanian language and the lack of linguistic data. The Lithuanian language has a complex pronunciation, a flexible word order and a rich vocabulary, while the spelling is supplemented with the Latin alphabet. Analyzing and comparing existing systems, solutions, and comparisons is not easy—the Lithuanian speech recognition systems differ not only in datasets used for training (phoneme formats, record quantities, their contents, etc.), but also in recognition methodologies and purposes used (some systems are limited to phoneme recognition in acoustic signals, others are able to work on recognizing individual words as well).
Our algorithm provides a major impact in the implementation: The method does not require any heuristic loss functions, explicit phonetic representations, or assumptions of conditional independence, as in more traditional approaches. In classical automatic speech recognition systems, such phoneme sequence recognition is performed using a consonant pattern (dictionary), which allows words to be recognized by their phoneme sequences, and the resulting words are refined by the speech model during the decoding step. Building pronunciation and language models is a complex and lengthy process, especially for morphologically rich languages, and the resulting models do not guarantee good results for the ASR system. On the other hand, in speech recognition systems that perform the recognition from the beginning to the end of a signal unit, the concept of phonemes does not even exist because of their latent representation in the model.
Another positive impact is provided in the actual cost of resources needed to train the system (especially in comparison to the classic, HMM-based solutions), also in the partially simplified and easier to assemble language model (defined by our network structure), proving that it is possible to reach a usable recognition accuracy for languages with little, publicly available linguistic resources. Our method proves that a positive impact could be seen on most transcription-based operations, often typically consisting of long phrases. ASR systems such as the system proposed in this paper are based on the phoneme sequences processing, which is simpler than classical speech recognition systems and has the flexibility to use pre-existing acoustic models. Learning to use the phoneme sequences allows the ASR system to master not only the relationship between the graphemes and their corresponding phonemes or groups, but also to learn how to distinguish between individual words, i.e., to form a language model. The close relationship between phonetic and morphological forms of words in Lithuanian allow the proposed ASR system to achieve high speech recognition results.
Summarizing the results obtained during the experiment, it can be stated that the encoded–decoder-type models can effectively learn the relationship between phonemes and their corresponding grapheme sequences and can achieve very good results in the problem of automatic recognition of isolated words from Lithuanian phoneme sequences.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}