SyrAgri: A Recommender System for Agriculture in Mali



Abstract
:1. Introduction
2. Problem Statement and Research Questions
- How to guide the cultivators on the cultivation techniques?
- How to guide farmers on the choice of seed varieties?
- How to guide farmers to choose soil types, seasons for a crop?
- How to inform farmers about crop rotation?
3. Background
3.1. Recommender Systems
- Estimates: also called notes, they express users’ opinions on various items and are often represented by triplets (user; items; note). The set of triples (user; item; note) forms what is called the notes matrix. The couples (user; item) where the user did not give a score for the item are unknown values in the matrix. Table 1 shows an example of a rating matrix for 4 users and 4 films. Values marked as “?” indicate that the user has not given a notice [12].
- Demographic data: it refers to information such user’s as age, sex, country, education, etc. [13]. This type of data is generally difficult to obtain and is normally collected explicitly.
3.2. Classification of Recommender Systems
3.2.1. Content-Based Approaches
3.2.2. Approaches Based on Collaborative Filtering
3.2.3. Hybrid Approaches
- Weighted: the score obtained by each of the two techniques is combined into a single result.
- Switching: the system switches between the two recommendation techniques depending on the situation.
- Mixed: the lists of recommendations from the two techniques are merged into a single list.
- Feature combination: the data from the two techniques are combined and transmitted to a single recommendation algorithm.
- Feature augmentation: the result of one technique is used as input to the other technique.
- Cascade: in this type of hybridization, a recommendation technique is used to produce a first classification of candidate items and then a second technique refines the list of recommendations.
- Definition of a meta level: this method is analogous to the method by increasing properties but it is the learned model which is used as input to the second technique and not the list result of the recommendations
4. Research Method
- Design of a recommender system for farmers
- Evaluate and compare it to expert recommendation results
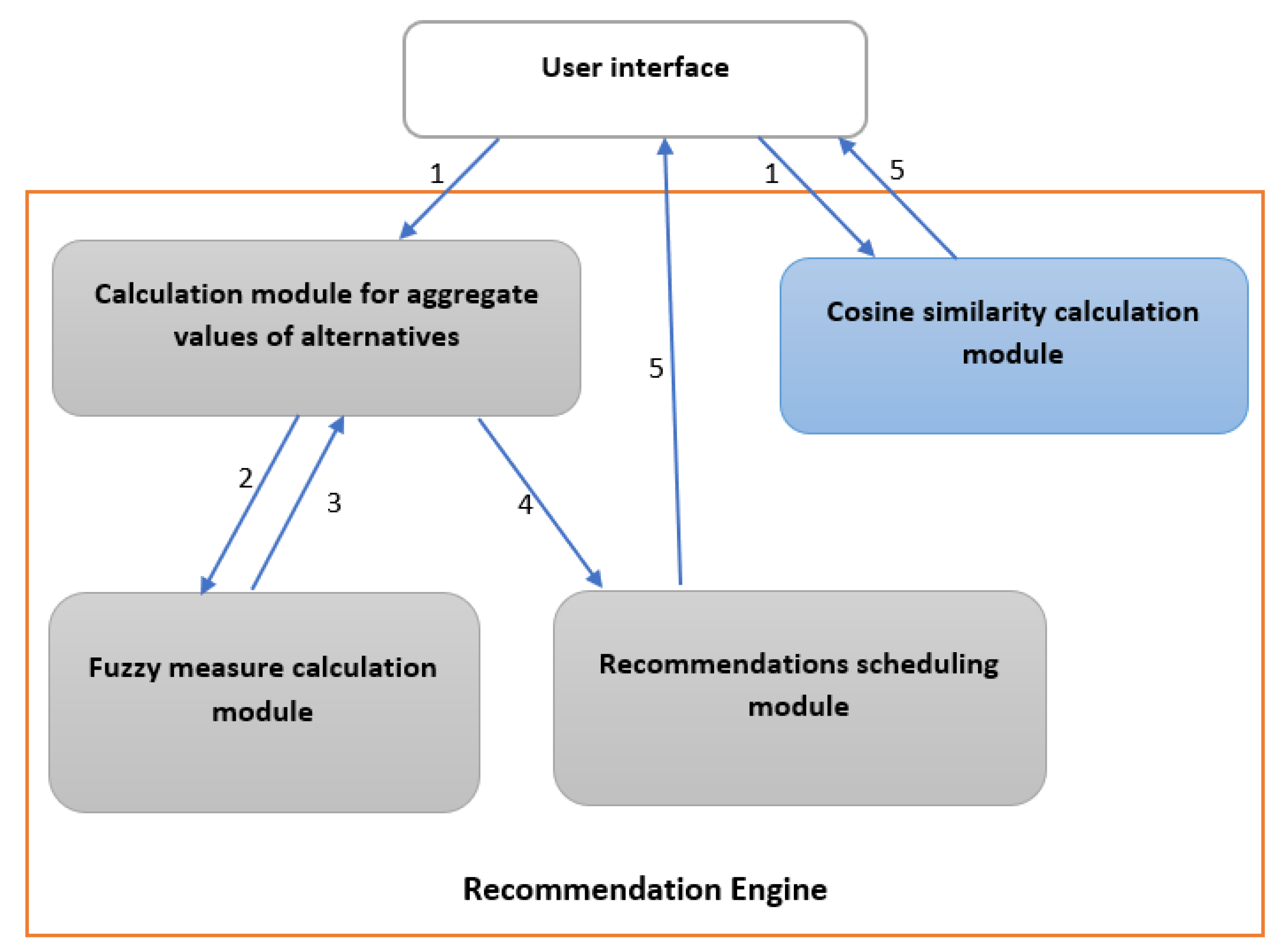
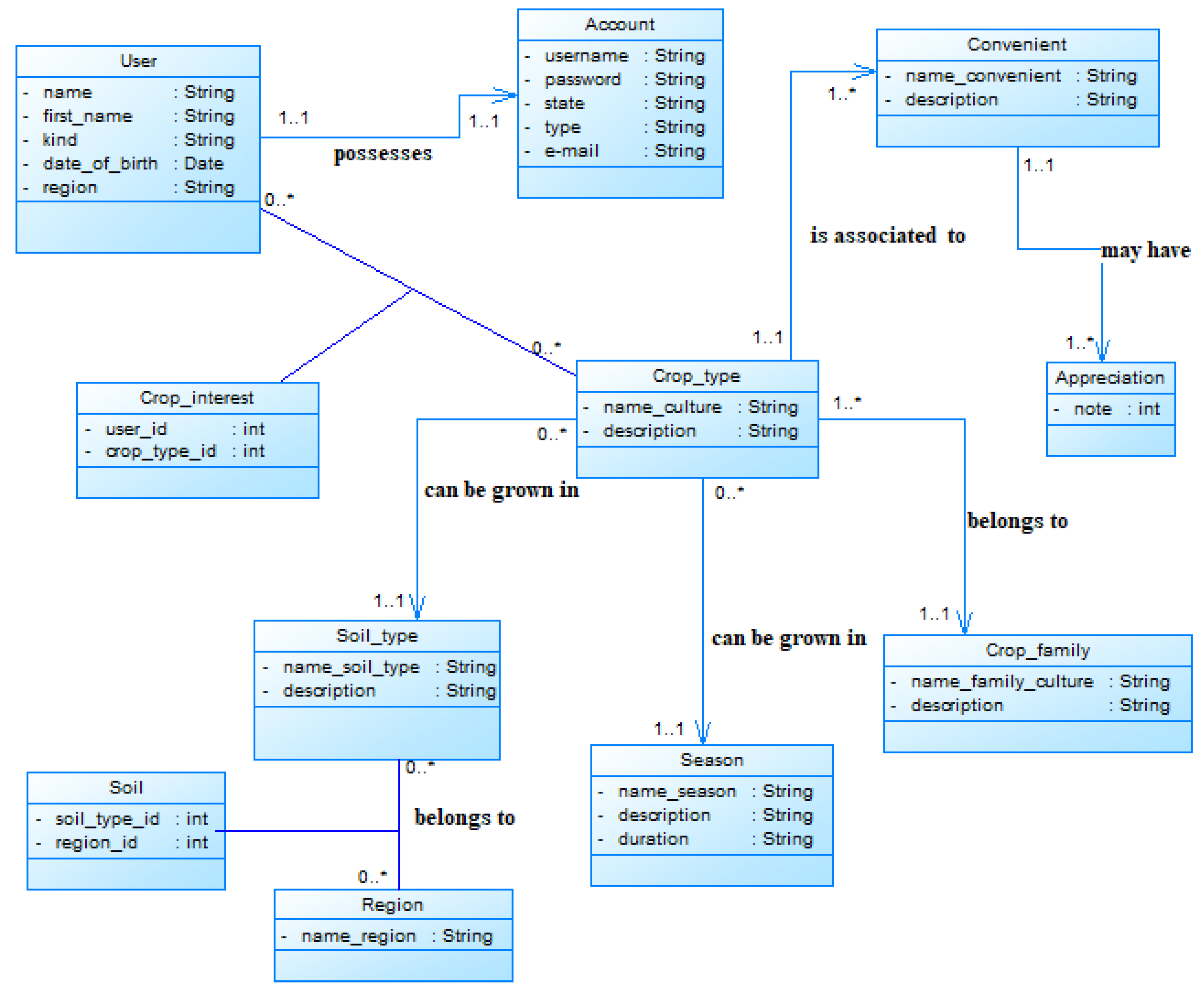
4.1. SyrAgri Overview
- First scenario: to recommend crops that may interest a user. This recommendation is made based on the location provided by user. If no crop in the system matches the user’s location, the recommendation will be based on users who come from the same location as him/her.
- Second scenario: to recommend crops similar to what interests the user. For example, a user interested in growing millet may be recommended to grow sorghum since both crops are grown on the same type of soil (semi-sandy, sandy.). So (s)he can receive guides on sorghum practices.
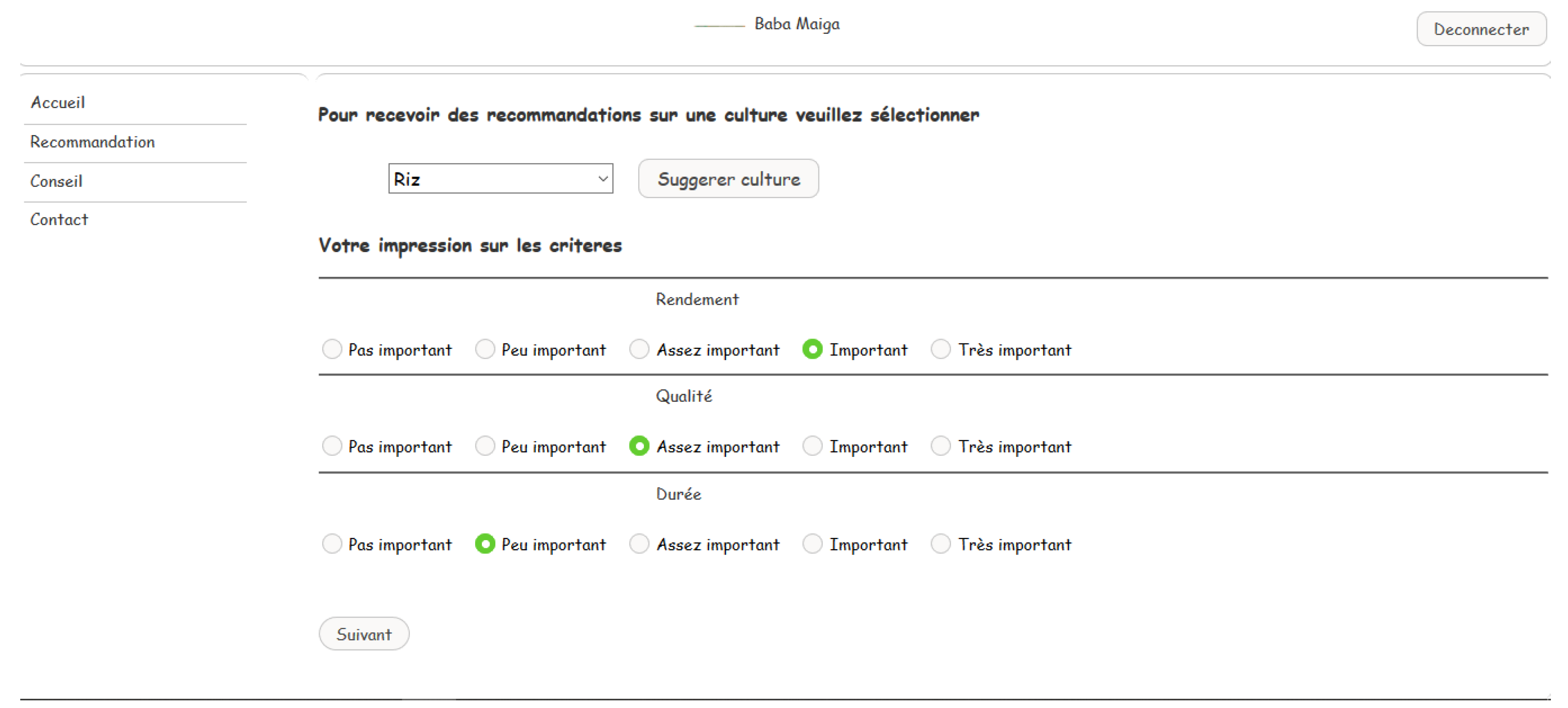
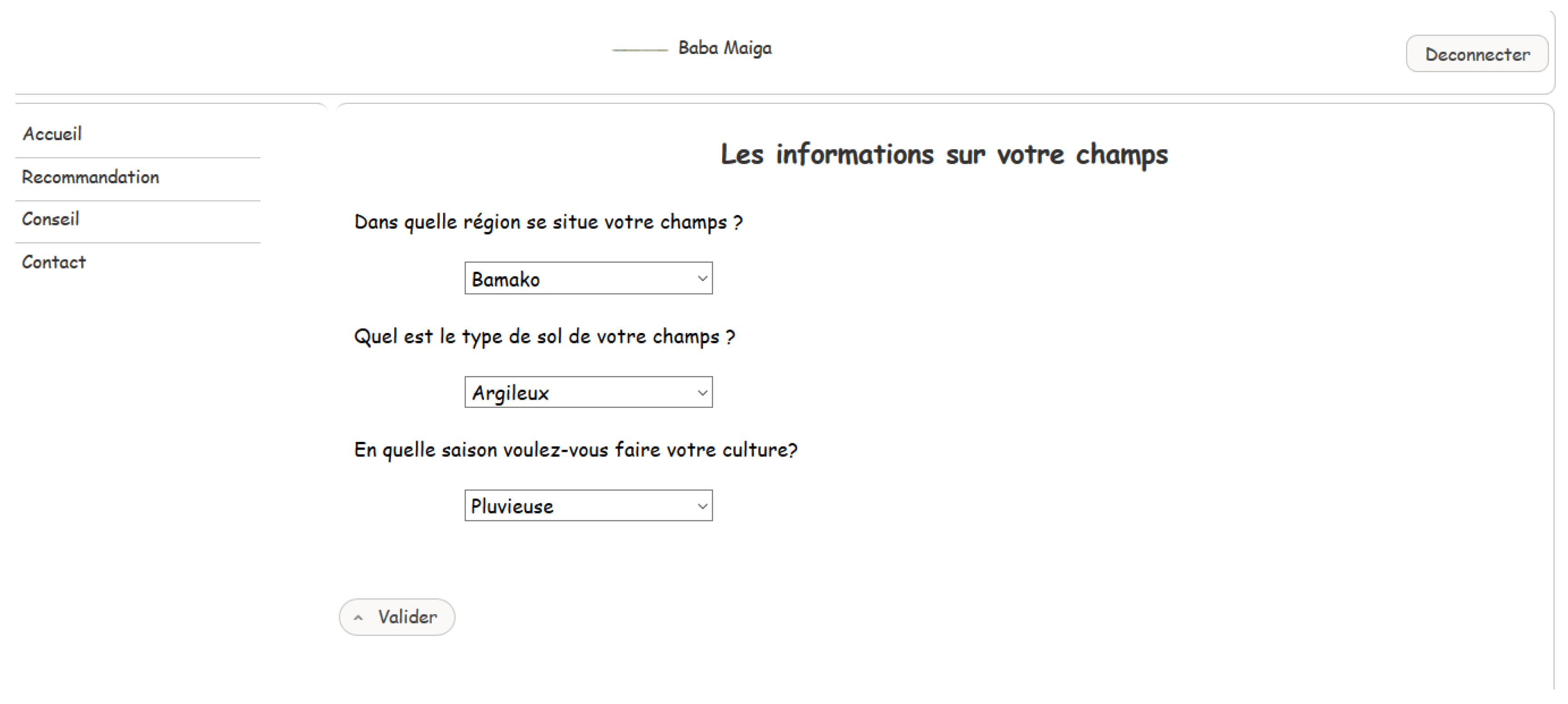
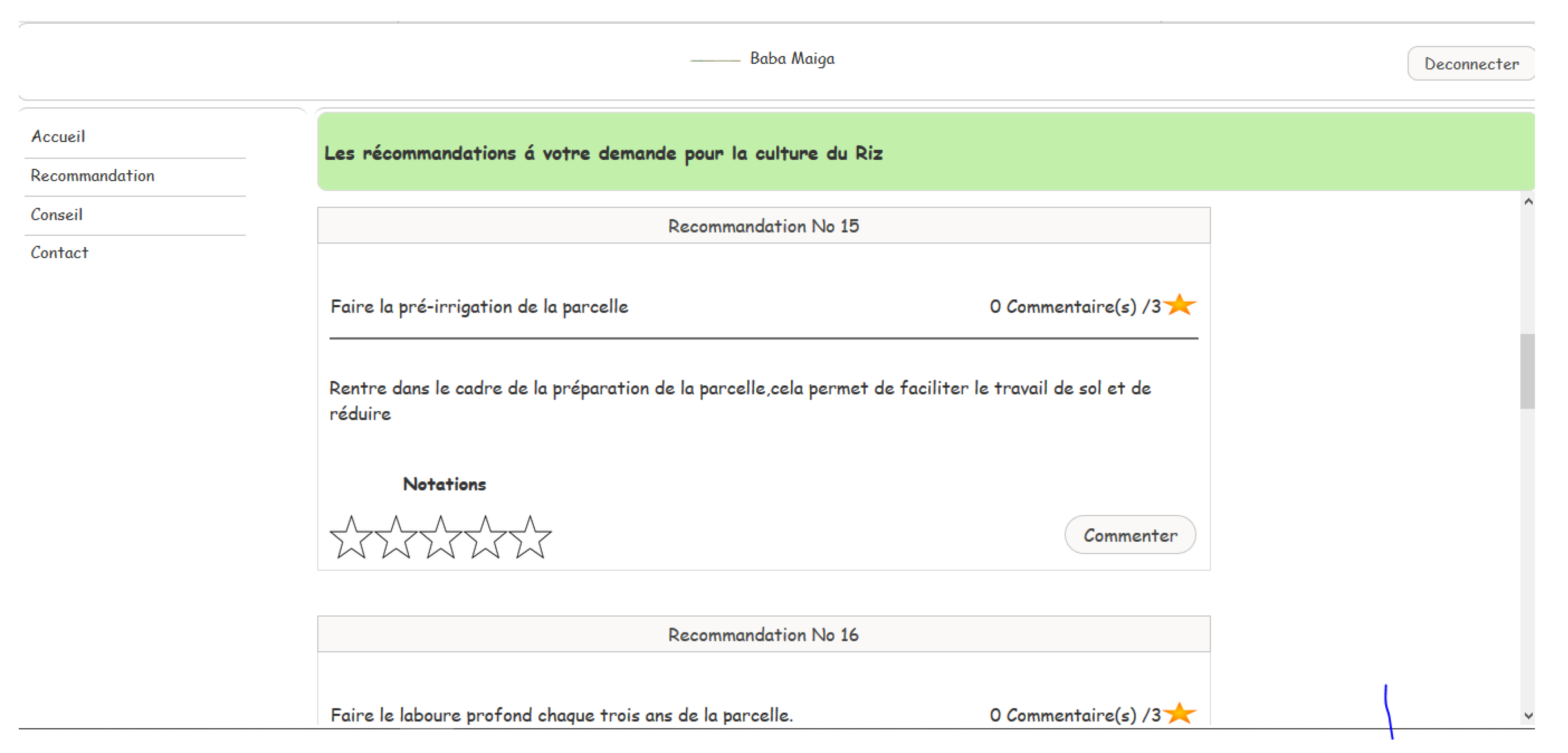
- Third scenario: to get recommendations related to a chosen crop, to get evaluation based on preference criteria (yield, quality, life cycle of the crop), the growing location, the type of soil and the growing season.
4.2. Implementation
4.2.1. Choquet’s Integral
- Mathematical formula of Choquet’s integral:The integral of Choquet of compared to a capacity in N is defined by: (x) = , where is a permutation in N such as ,={ (i),..., (n)}, for i ∈ N, and =⌀.
- Algorithm for integral of Choquet:After calculating the fuzzy measure using the Kappalab package, we can calculate the overall score of each alternative (here the agricultural practices) in order to obtain a final ranking of alternatives. Algorithm 1 displays the algorithm used to implement the integral of Choquet.
| Algorithm 1: Choquet’s integral |
 |
4.2.2. Similarity Cosine
5. Evaluation
5.1. Functional Tests
5.2. Qualitative Tests
Methodology
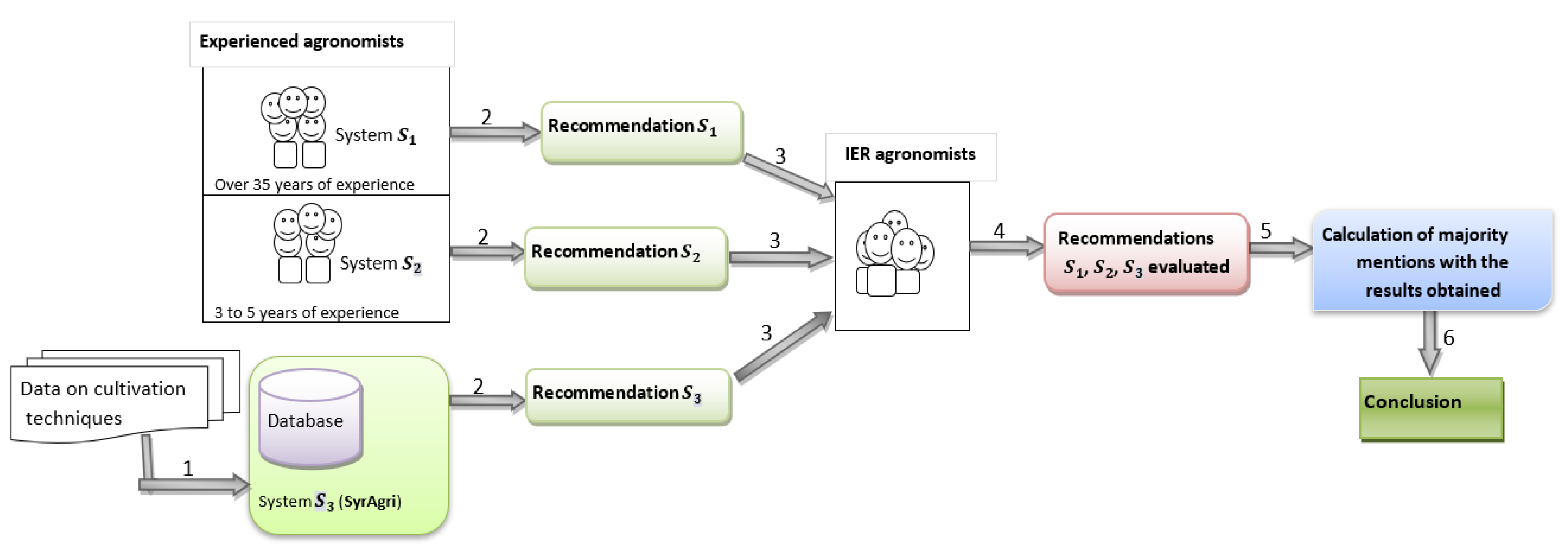
- Data collection on cultivation techniquesFor the collection of data on cultivation techniques, we proceeded in two different ways:
- -
- Collection of data through technical sheets on crops obtained from the malian Institute of Rural Economy (IER) and the Malian Ministry of Agriculture in order to populate the SyrAgri system database (see steps 1 and 2 of Figure 2).
- -
- Data collection from experienced agronomists (agronomic data) through a form. It made it possible to make a comparative study of cultivation techniques in order to qualitatively assess the SyrAgri system (steps 3 and 4 of Figure 2).
- Targeted agronomistsFor the filling of the forms we targeted ten (10) agronomists divided into two equitable groups: agronomists with more than 35 years of experience and agronomists with 3 to 5 years of experience.This choice of two groups of agronomists is not fortuitous because it allowed us to obtain older data (technical and agricultural practices) from the first group and recent and ones from the second group.
- Analysis and synthesis of the collected data
5.3. Assessment Tools
- Table of the mentions expressed on systems (, , )In Table 2, the columns represent expressed mentions (Excellent, Very-Good, Good, Fairly Good, Fair, Insufficient, To reject) and on the lines we have the three systems ((, , ).
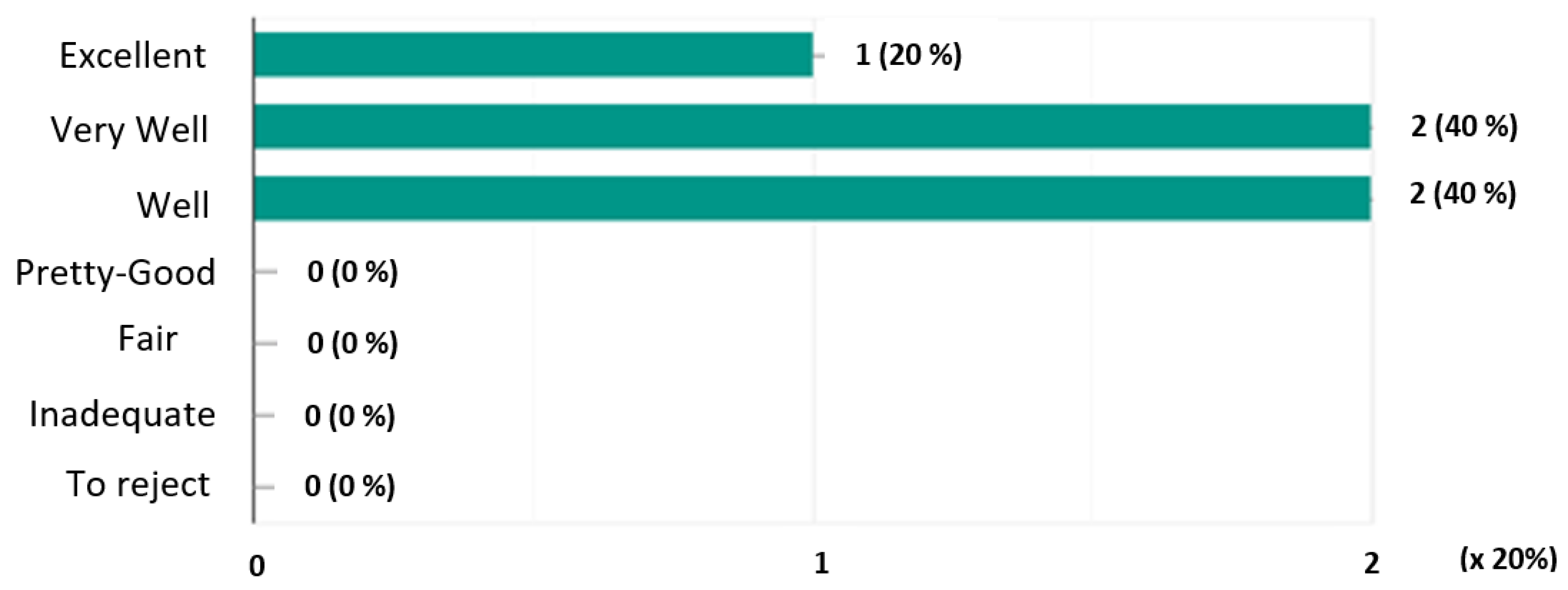
- Graphs of the mentions expressed:Here we graphically represent the mentions expressed for each system. On the ordinate axis are represented the mentions and on the abscissa axis the number of votes allocated multiplied by 20% (scale considered).In Figure 3, we note that the system obtained a single mention “Pretty Good” (20%), three mentions “Fair” (60%) and a single mention “Inadequate” (20%).Figure 4 shows that the system received a single “Well” rating of 20%, three “Fairly Good” ratings (60%) and a single “Fair” rating (20%).In Figure 5, we see that the system has obtained a single mention “Excellent” or 20%, two mentions “Very good” (40%) and two mentions “Well” (40%).
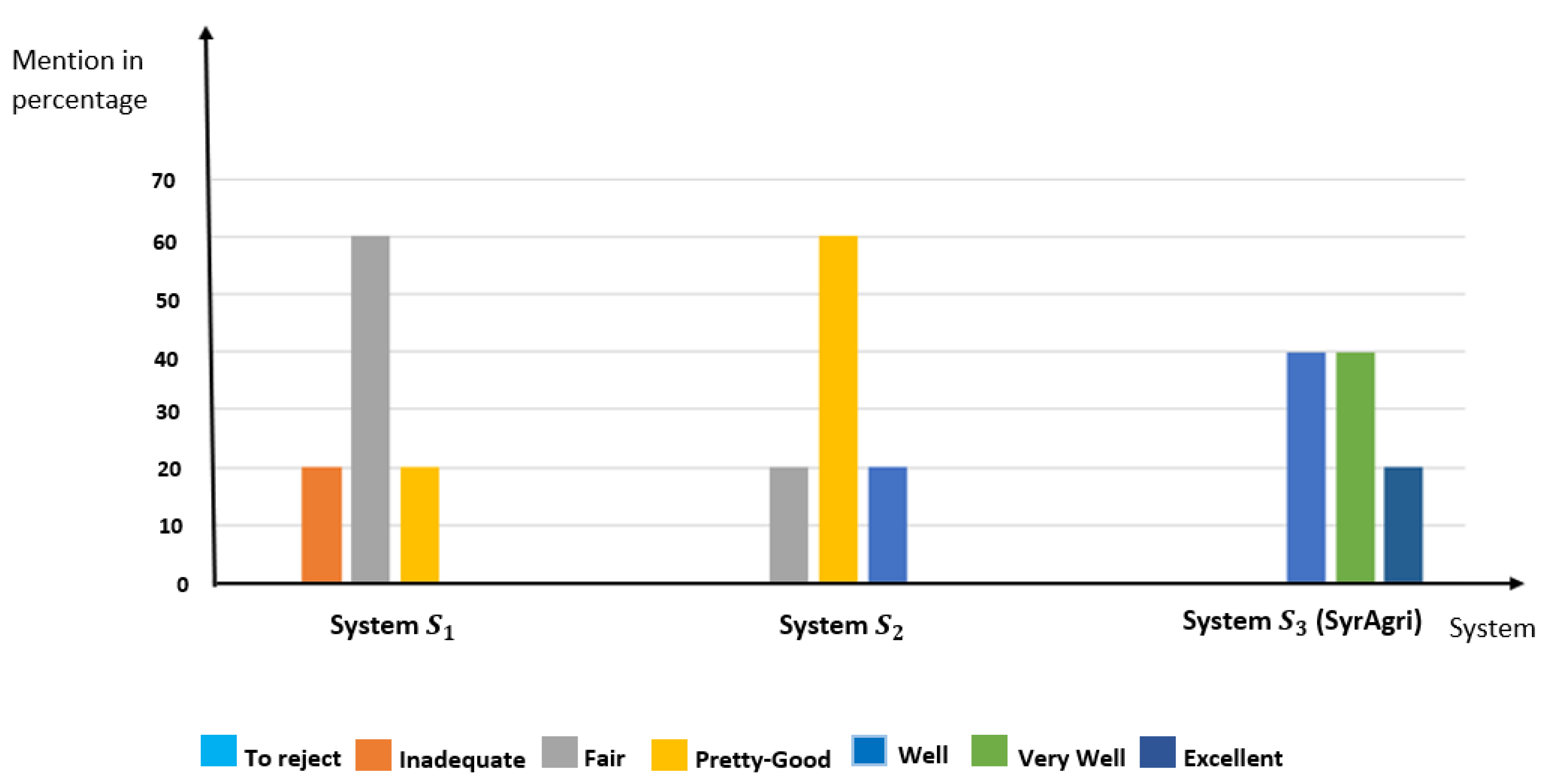
- Calculating majority mentionsConsidering Table 2, the mentions ’Excellent’, ’Very-Well’, Good’, ’Pretty-Good’, ’Fair’ and ’To reject’ and let the majority mention of a system. The majority mention of a system in Table 2 is obtained as follows: (1) We check if the percentage value of the first column of the table is greater than or equal to 50%, then the mention of this column corresponds to the majority mention of the system otherwise we go to step 2; (2) We do the one-to-one sum of the values in percentages of the columns of the table from the left to the right (i.e., from the largest mention E to the smallest ’R’) until obtain at the level of a column a percentage greater than or equal to 50%. The mention of this column will then be considered as the majority mention of the system.Consequently, the majority of the , and systems are as follows:= 0% E+ 0% T+ 0% B+ 20% A+ 60% P = 80% (≥ 50%).= 0% E+ 0% T+ 20% B+ 60% A = 80% (≥ 50%).= 20% E+ 40% T = 60% (≥ 50%).In conclusion, the majority mentions of the systems () are Fair, Pretty-Good and Very well respectively as indicated in Table 3.
- Histogram with vertical rectangles of the mentions expressed for three systems
5.4. Discussion
5.4.1. Interpretation
5.4.2. Contribution
5.5. Limitations and Perspectives
- Enrich the database with more technical data on crops: This will allow us to have several types of crops and a large number of recommendations on agricultural techniques.
- Develop new functionalities: recommendation on rainfall, generation of crop statistics in relation to regions of the country.
- Extend the system for livestock.
6. Conclusions
- Registration of a user;
- Authentication of a user;
- The registration of a crop;
- The registration of an agricultural practice;
- The suggestion of a crop;
- The recommendation of a crop similar to another;
- The recommendation of agricultural techniques for a given crop;
- The rating of a recommendation.
- Information on crop rotation.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

Appendix B






Appendix C
- a.
- Which geographic regions do you recommend for this crop?
- Region 1:
- Region 2:
- Region 3:
- Etc:
- b.
- What are the growing seasons?
- Season 1:
- Season 2:
- Season 3:
- Etc:
- c.
- What types of soil do you reccommend?
- Type 1:
- Type 2:
- Type 3:
- Etc:
- d.
- What types of seeds do you reccommend?
- Type 1:
- Type 2:
- Type 3:
- Etc:
- e.
- What are the site preparation actions that you recommend?
- Action 1:
- Action 2:
- Action 3:
- Etc:
- f.
- What measures do you recommend for soil fertilization?
- Measure 1:
- Measure 2:
- Measure 3:
- Etc:
- g.
- When and how do we sow?
- Period:
- Action:
- h.
- What are the appropriate maintenance actions for the following periods?

- i.
- When should we harvest?
- j.
- How should we harvest?
- Action 1:
- Action 2:
- Action 3:
- Etc:
- Rice:
- Corn
- Cowpea:
- Okra:
- Sorghum:
Appendix D

{kind=link}
{kind=link}
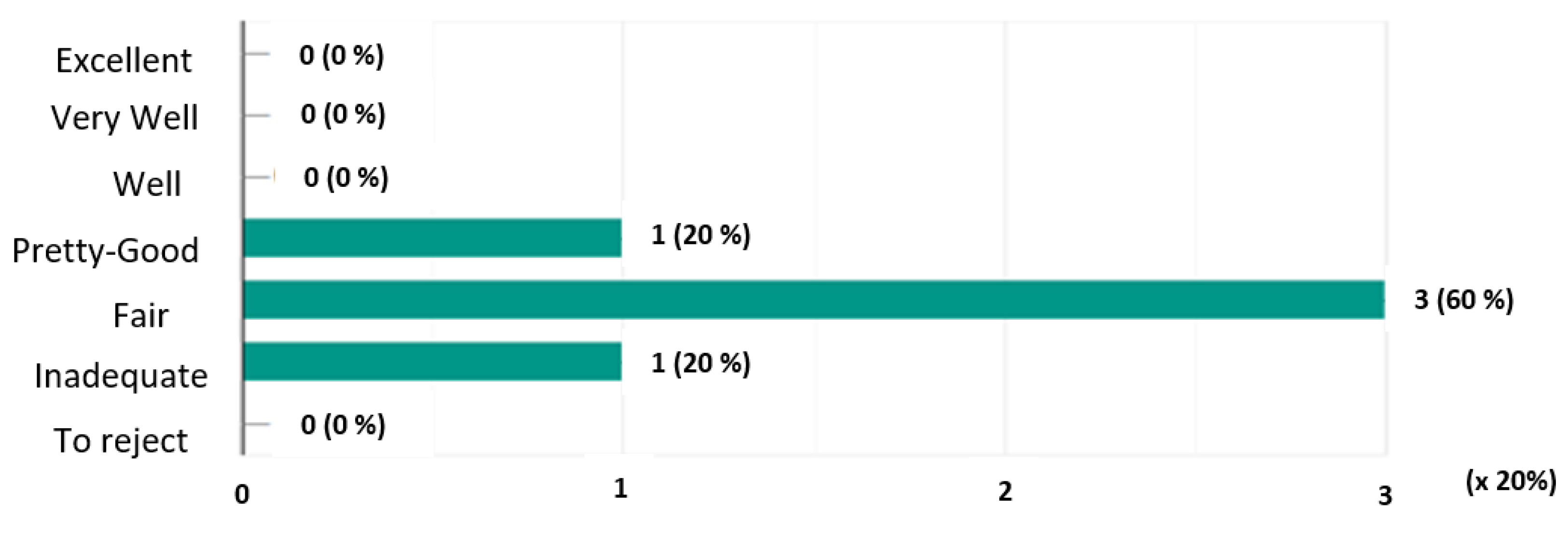{kind=link}
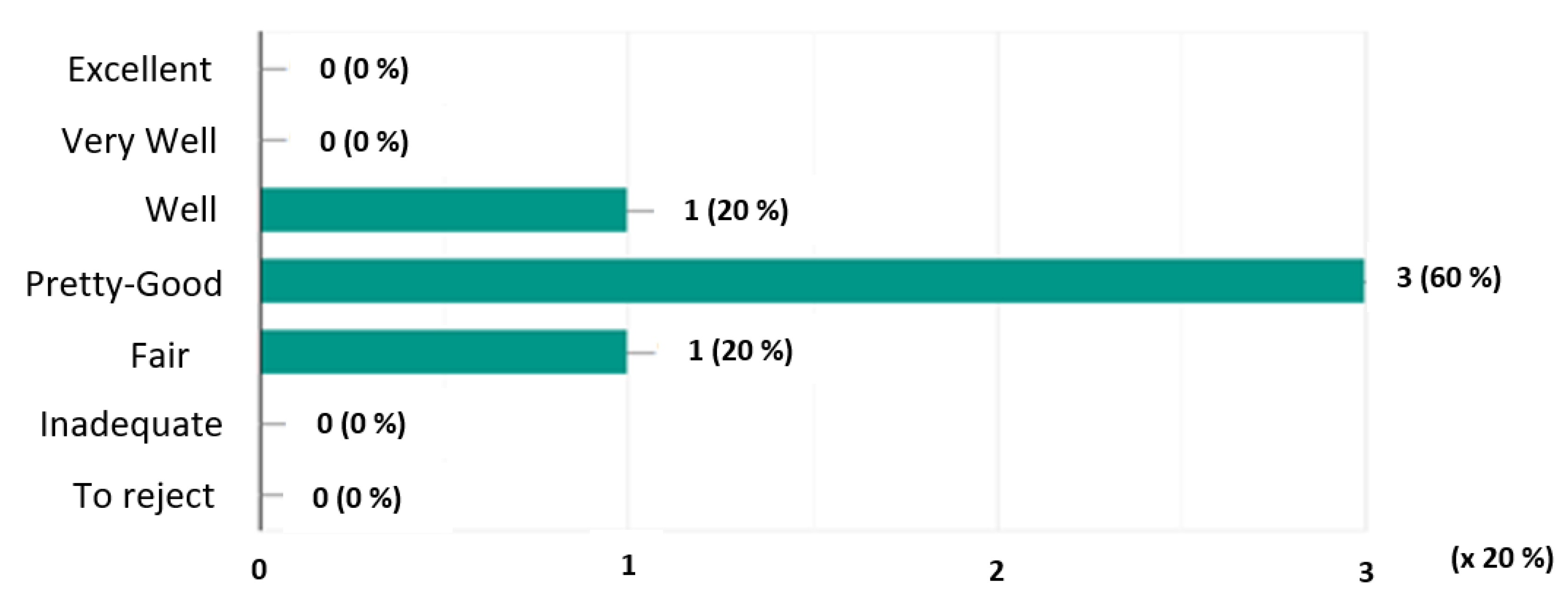{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System S1 | System S2 | System S3 | Interpretations | |
|---|---|---|---|---|
| Growing region | Ségou | Ségou | Ségou | |
| Growing season | Rainy saison | Rainy saison | Rainy saison | |
| Type of soil | Clay soil | Clay soil | Clay soil | |
| Seed varieties | Gambiaka, Neureka, ADNY. | ADNY, Kogoni, Neureka, Gambiaka. | ADNY-11 (6 t/ha, 120 days), Gambiaka (5 t/ha, 160 days), Telimani (7 t/ha 115 to 125 days), Neureka, Kogoni-91-1. | |
| Ground preparation actions | Complete plowing of the field. Harrow of the field, Putting in mud and finally leveling. | Clean the plot if necessary; Plow to a depth of 10–15 cm after irrigation; Harrow / spray then mud. | Complete plowing the land (10 to 15 cm deep), Leveling, Establishment of a nursery (plowing, leveling, maintenance) An adequate irrigation and drainage network to ensure water control. | |
| Soil fertilization actions | Add organic manure (cattle manure, waste) before plowing; Harrow of the field, Putting in mud and finally leveling. | Addition of 20–30 t/ha of organic manure well decomposed before plowing; Addition of 100 kg/ha of DAP or 100 kg/ha of cereal complex; Add 200 kg/ha of urea divided into two applications (15 days apart), the first of which at the start of tillering. | Add 250 kg/ha of ground manure at the time of plowing. Add 100 kg/ha of DAP immediately after sowing and 200 kg/ha of emergent urea. | |
| Sowing actions | Establishment of a nursery: The nursery sowing is done on the fly and to cover with a layer of 0.5 cm of straw to conserve the humidity of the environment. Harrow of the field, Transplanting: it is done in line with a transplanting density of 0.20 m × 0.20 m and the number of plant / poquet is from 2 to 3 plants without prickling. | Beginning of June or Mid- June: it can be done indirectly (the nursery) on the fly with a density between 30-80 kg of seeds per ha. End of June: Transplanting is done 20 to 25 days after the online nursery due to 1 to 2 plants per poquet. The distance between the lines varies between 20–40 cm. | Nursery location: Choose a sunny location close to the bedding plot and the water point. Nursery preparation: Plowing (7 ares per ha to transplant) followed by harrowing then the making of 10 m × 1 m boards independent of each other. Seeds: 60 kg to be pregerminated +120 g of fungicide before sowing in the nursery. Nursery seedlings: On the fly and cover with a layer of 0.5 cm of straw to conserve the humidity of the environment. | |
| Sowing actions | Nursery manure: 1 to 2 wheelbarrows of farmyard manure for 10 m and 250 g for 10 m of super triple or potassium chloride on the fly, preferably as background manure. Number of plants per poquet:2 3 to plants without prickling. Transplant density: 0.20 m × 0.20 m. | |||
| Field maintenance actions | Weeding: Do weeding (manual, chemical mechanical) or herbicide fifteen days after sowing. 250 g for 10 m of super triple or potassium chloride on the fly, preferably as background manure. Irrigation: On the 15th day of weeding, put in water (main- taining the water slide at 5–10 cm cube depending on the height of the plants). | 2-3 days after transplanting, relining preherbicide. 20–25 days after transplanting: Dismantling of the plants, transplanting 1 to 2 plants per pocket (if necessary) 15 days after transplanting, do the 1st weeding and the first slice of urea plus the whole DAP At the time of the initiation of the panicles, make the contribution of the 2nd slice of urea. In case of attack of diseases or insects phytosanitary treatment. | Maintenance: 2 weeding including the second 15 days after the first (manual, chemical mechanics), and phytosanitary treatments on request. Irrigation: 20,000 m3 on average with a blade of water equal to a third of the size of the plant with each supply. Empty 2 to 3 days to the 15th day for weeding, fertilizing and aerating the soil. | |
| Harvest periods | When the ears begin to have a golden color and become dry and hard to the touch. | Harvest at 2/3 of maturity, that is to say when the seeds become hard and are no longer milky. | Harvesting should take place at a time when the grains have a suitable moisture level so that they do not break. This corresponds to a period of 30 to 40 days after heading, depending on the variety. | |
| Harvest actions | Harvesting is done by fossil or using the harvester. | Harvesting can be manual with a sickle or mechanical with the combine harvester, binder harvester. The sheaves are dried 3 to 4 days on the ground before hilling. | Harvesting can be done mechanically with a combine harvester, a baler harvester or manually with a sickle 30 to 50 cm below the panicle so as not to get tired. The sheaves are dried 3 to 4 days on the ground before threshing. | |
| Similar crops | Wheat, Corn. | Sugar cane, Wheat, Corn. | Wheat, Corn, Sorghum, Mil. |

References
- SPCECSA. Politique foncière agricole du Mali. Rapport Technique, Secretariat Permanent du Comité Exécutif National du Conseil Supérieur de l’agriculture; Ministère de l’Agriculture et de l’Elevage du Mali: Bamako, Mali, 2014.
- FAO. Le rôle du Secteur Agricole dans L’expansion Économique et du Développement des PMA; Rapport technique; Food and Agricultural Organization of the United Nations (FAO): Rome, Italy, 2014. [Google Scholar]
- Bellman, R. Artificial Intelligence: Can Computers Think? Boyd & Fraser Computer Science Series; Boyd & Fraser Publishing Company: California, CA, USA, 1978. [Google Scholar]
- Gupta, N.; Khosravy, M.; Patel, N.; Dey, N.; Gupta, S.; Darbari, H.; Gonzalez Crespo, R. Economic data analytic AI technique on IoT edge devices for health monitoring of agriculture machines. Appl. Intell. 2020, 50. [Google Scholar] [CrossRef]
- Gupta, N.; Gupta, S.; Khosravy, M.; Dey, N.; Joshi, N.; Crespo, R.; Patel, N. Economic IoT Strategy: The Future Technology for Health Monitoring and Diagnostic of Agriculture Vehicles. J. Intell. Manuf. 2020, IP, 1–11. [Google Scholar] [CrossRef]
- Iqbal, M. YouTube Revenue and Usage Statistics (2020). Available online: https://www.businessofapps.com/data/youtube-statistics (accessed on 7 May 2020).
- Idir, B. Un Système de Recommandation Contextuel et Composite Pour la Visite Personnalisée de Sites Culturels. Ph.D. Thesis, Universite de Technologie de Compiegne, Compiegne, France, 2017. [Google Scholar]
- Robin, B. Hybrid Recommender Systems: Survey and Experiments. User Model. -User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- ROPPA. Dix ans après la déclaration de Maputo sur l’agriculture et la sécurité alimentaire: Une évaluation du Progrès au Mali; Technical Report; Réseau des Organisations Paysannes et des Producteurs Agricoles de l’Afrique de l’Ouest (ROPPA): Ouagadougou, Burkina Faso, 2017. [Google Scholar]
- Rich, E. User Modeling via Stereotypes. Cogn. Sci. 1979, 3, 329–354. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Recommender Systems; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef] [Green Version]
- Sharda, N. Visual Travel Recommender Systems, Social Communities, and User Interface Design; IGI Global: Hershey, PA, USA, 2010. [Google Scholar] [CrossRef]
- Manolis, V. Analysis of Recommender Systems’ Algorithms. In Proceedings of the 6th Hellenic European Conference on Computer Mathematics and its Applications (HERCMA), Athens, Greece, 7 July 2003. [Google Scholar]
- Hosseini, S.; Yin, H.; Zhou, X.; Sadiq, S. Leveraging Multi-aspect Time-related Influence in Location Recommendation. World Wide Web 2017, 22. [Google Scholar] [CrossRef] [Green Version]
- Shahabi, C.; Banaei-Kashani, F.; Chen, Y.-S.; McLeod, D. Yoda: An Accurate and Scalable Web-Based Recommendation System. In Cooperative Information Systems (CoopIS 2001); Batini, C., Giunchiglia, F., Giorgini, P., Mecella, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 418–432. [Google Scholar] [CrossRef] [Green Version]
- Balabanović, M.; Shoham, Y. Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Béchet, N. Etat de l’art sur les Systèmes de Recommandation. 2012. Available online: http://people.irisa.fr/Nicolas.Bechet/Publications/EtatArt.pdf (accessed on 10 May 2020).
- Lops, P.; de Gemmis, M.; Semeraro, G. Content-based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P., Eds.; Springer: Boston, MA, USA, 2011; pp. 73–105. [Google Scholar] [CrossRef]
- Doré, T. Note de lecture de “Vers des agricultures doublement performantes pour concilier compétitivité et respect de l’environnement”, rapport de M. Guillou et al. au Ministre en charge de l’agriculture. Agron. Environ. Sociétés 2013, 3, 167–168. [Google Scholar]
- Negre, E. Systèmes de Recommandation: Introduction; Systèmes d’information avancés, ISTE Editions: Londres, Royaume-Uni, 2015. [Google Scholar]
- Karampiperis, P.; Koukourikos, A.; Stoitsis, G. Collaborative Filtering Recommendation of Educational Content in Social Environments Utilizing Sentiment Analysis Techniques. In Recommender Systems for Technology Enhanced Learning: Research Trends and Applications; Manouselis, N., Drachsler, H., Verbert, K., Santos, O., Eds.; Springer: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Jannach, D.; Zanker, M.; Felfering, A.; Friedrich, G. Recommender Systems: An Introduction; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Meryem, K. Système de recommandation des services web sémantiques. Master’s Thesis, Université Abou Bakr Belkaid, Tlemcen, Algérie, 2015. [Google Scholar]
- Benouaret, I. A Contextual and Composite Recommender System for the Personalization of Cultural Sites Visit. Ph.D. Thesis, Université de Technologie de Compiègne, Compiègne, France, 2017. [Google Scholar]
- Fomba, S. Décision Multicritère: Un système de recommandation pour le choix de l’opérateur d’agrégation. Ph.D. Thesis, Université de Toulouse, Toulouse, France, July 2018. [Google Scholar]
- de Micheaux, P.L.; Drouilhet, R.; Liquet, B. Le logiciel R: Maîtriser le Langage, Effectuer des Analyses Statistiques; Springer-Verlag: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Kovalenko, D. Selenium Design Patterns and Best Practices; Packt Publishing Ltd.: Birmingham, UK, 2014. [Google Scholar]
- Balinski, M.; Laraki, R. Majority Judgment: Measuring, Ranking, and Electing; MIT Press: Cambridge, MA, USA, 2011. [Google Scholar] [CrossRef]
- Balinski, M.; Laraki, R. Judge: Don’t Vote! Oper. Res. 2014, 62, 483–511. [Google Scholar] [CrossRef] [Green Version]






| Sanoudjè | Wari | Faro | TaaféFanga | |
|---|---|---|---|---|
| Hamidou | 4 | 3 | 2 | 4 |
| Awa | ? | 4 | 5 | 5 |
| Oumar | 2 | 2 | 4 | ? |
| Seydou | 3 | ? | 5 | 2 |
| Excellent | Very Well | Well | Pretty Good | Fair | Inadequate | To Reject | |
|---|---|---|---|---|---|---|---|
| 0 (0%) | 0 (0%) | 0 (0%) | 1 (20%) | 3 (60%) | 1 (20%) | 0 (0%) | |
| 0 (0%) | 0 (0%) | 1 (20%) | 3 (60%) | 1 (20%) | 0 (0%) | 0 (0%) | |
| 1 (20%) | 2 (40%) | 2 (40%) | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Majority Mention () | |
|---|---|
| System | Fair |
| System | Pretty Good |
| System | Very Well |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konaté, J.; Diarra, A.G.; Diarra, S.O.; Diallo, A. SyrAgri: A Recommender System for Agriculture in Mali. Information 2020, 11, 561. https://doi.org/10.3390/info11120561
Konaté J, Diarra AG, Diarra SO, Diallo A. SyrAgri: A Recommender System for Agriculture in Mali. Information. 2020; 11(12):561. https://doi.org/10.3390/info11120561
Chicago/Turabian StyleKonaté, Jacqueline, Amadou G. Diarra, Seydina O. Diarra, and Aminata Diallo. 2020. "SyrAgri: A Recommender System for Agriculture in Mali" Information 11, no. 12: 561. https://doi.org/10.3390/info11120561
APA StyleKonaté, J., Diarra, A. G., Diarra, S. O., & Diallo, A. (2020). SyrAgri: A Recommender System for Agriculture in Mali. Information, 11(12), 561. https://doi.org/10.3390/info11120561