Convolutional Neural Networks Applications in Sensing and Imaging: Architectures, Insight, Visualization, Transparency
Share This Topical Collection
Editor
 Prof. Dr. Stefanos Kollias
Prof. Dr. Stefanos Kollias
Prof. Dr. Stefanos Kollias
E-Mail
Website1
Website2
Collection Editor
School of Computer Science, University of Lincoln, Lincoln LN6 7TS, UK
Interests: image and video processing, analysis, coding, storage, retrieval; multimedia systems; computer graphics and virtual reality; artificial intelligence; neural networks; human–computer interaction; medical imaging
Special Issues, Collections and Topics in MDPI journals
Topical Collection Information
Dear Colleagues,
Convolutional neural networks (CNNs) have been largely used in computer vision applications in the last few years. New applications in sensing and imaging are targeted in this Special Issue, with a focus on the use of CNN architectures that advance the current state of the art, leading to improved performance in the considered scenarios, while providing transparency in, the visualization of or insight into the decision-making procedure. Using 2D or 3D CNNs, as well as extensions such as global local models, attention mechanisms and the exploitation of features that are the most prominent for the provided decisions are only some indicative topics of interest. Any application field can be considered, involving, for example, classification, prediction, regression, or anomaly detection problems.
The topic is part of the "Machine/Deep Learning and Artificial Intelligence in Sensing and Imaging" scope of Sensors. It is also related to the following scopes: "Signal Processing, Data Fusion and Deep Learning in Sensor Systems", "Human–Computer Interaction", "Localization and Object Tracking" and "Action Recognition".
Prof. Dr. Stefanos Kollias
Collection Editor
Manuscript Submission Information
Manuscripts should be submitted online at www.mdpi.com by registering and logging in to this website. Once you are registered, click here to go to the submission form. All submissions that pass pre-check are peer-reviewed. Accepted papers will be published continuously in the journal (as soon as accepted) and will be listed together on the collection website. Research articles, review articles as well as short communications are invited. For planned papers, a title and short abstract (about 250 words) can be sent to the Editorial Office for assessment.
Submitted manuscripts should not have been published previously, nor be under consideration for publication elsewhere (except conference proceedings papers). All manuscripts are thoroughly refereed through a single-blind peer-review process. A guide for authors and other relevant information for submission of manuscripts is available on the Instructions for Authors page. Sensors is an international peer-reviewed open access semimonthly journal published by MDPI.
Please visit the Instructions for Authors page before submitting a manuscript.
The Article Processing Charge (APC) for publication in this open access journal is 2600 CHF (Swiss Francs).
Submitted papers should be well formatted and use good English. Authors may use MDPI's
English editing service prior to publication or during author revisions.
Keywords
- convolutional neural networks
- sensing
- imaging
- learning
- classification
- prediction
- recognition
- transparency
- visualization
- datasets
Published Papers (17 papers)
Open AccessReview
An Extensive Study of Convolutional Neural Networks: Applications in Computer Vision for Improved Robotics Perceptions
by
Ravi Raj and Andrzej Kos
Cited by 32 | Viewed by 12459
Abstract
Convolutional neural networks (CNNs), a type of artificial neural network (ANN) in the deep learning (DL) domain, have gained popularity in several computer vision applications and are attracting research in other fields, including robotic perception. CNNs are developed to autonomously and effectively acquire
[...] Read more.
Convolutional neural networks (CNNs), a type of artificial neural network (ANN) in the deep learning (DL) domain, have gained popularity in several computer vision applications and are attracting research in other fields, including robotic perception. CNNs are developed to autonomously and effectively acquire spatial patterns of characteristics using backpropagation, leveraging an array of elements, including convolutional layers, pooling layers, and fully connected layers. Current reviews predominantly emphasize CNNs’ applications in various contexts, neglecting a comprehensive perspective on CNNs and failing to address certain recently presented new ideas, including robotic perception. This review paper presents an overview of the fundamental principles of CNNs and their applications in diverse computer vision tasks for robotic perception while addressing the corresponding challenges and future prospects for the domain of computer vision in improved robotic perception. This paper addresses the history, basic concepts, working principles, applications, and the most important components of CNNs. Understanding the concepts, benefits, and constraints associated with CNNs is crucial for exploiting their possibilities in robotic perception, with the aim of enhancing robotic performance and intelligence.
Full article
►▼
Show Figures
Open AccessArticle
Application of Reinforcement Learning Methods Combining Graph Neural Networks and Self-Attention Mechanisms in Supply Chain Route Optimization
by
Yang Wang and Xiaoxiang Liang
Cited by 21 | Viewed by 9145
Abstract
Optimizing transportation routes to improve delivery efficiency and resource utilization in dynamic supply chain scenarios is a challenging task. Traditional route optimization methods often struggle with complex supply chain network structures and dynamic changes, which require a more efficient and flexible solution. This
[...] Read more.
Optimizing transportation routes to improve delivery efficiency and resource utilization in dynamic supply chain scenarios is a challenging task. Traditional route optimization methods often struggle with complex supply chain network structures and dynamic changes, which require a more efficient and flexible solution. This study proposes a method that integrates Graph Neural Networks (GNNs), self-attention mechanisms, and meta-reinforcement learning (Meta-RL) in order to address route optimization in supply chains. The goal is to develop a path planning method that excels in both static and dynamic environments. First, GNNs model the supply chain network, converting node and edge features into high-dimensional graph representations in order to capture local and global network information. Next, a Transformer-based strategy network captures global dependencies, optimizing path planning. Finally, Meta-RL enables rapid strategy adaptation to dynamic changes (e.g., new demand points or route disruptions) with minimal sample support. Experiments on multiple supply chain datasets show that our method improves path planning quality by about 7%, compared to traditional methods, achieving a path coverage of 92.29%. Ablation studies reveal that the on-time delivery rate improves by nearly 30% over the baseline model. These results demonstrate that the proposed method not only optimizes routes but also significantly enhances the overall efficiency and robustness of supply chain networks. This research provides an efficient route optimization framework applicable to complex supply chain management and other scheduling fields, offering new insights and technical solutions for future research and applications.
Full article
►▼
Show Figures
Open AccessArticle
Gaze Zone Classification for Driving Studies Using YOLOv8 Image Classification
by
Frouke Hermens, Wim Anker and Charmaine Noten
Cited by 1 | Viewed by 2732
Abstract
Gaze zone detection involves estimating where drivers look in terms of broad categories (e.g., left mirror, speedometer, rear mirror). We here specifically focus on the automatic annotation of gaze zones in the context of road safety research, where the system can be tuned
[...] Read more.
Gaze zone detection involves estimating where drivers look in terms of broad categories (e.g., left mirror, speedometer, rear mirror). We here specifically focus on the automatic annotation of gaze zones in the context of road safety research, where the system can be tuned to specific drivers and driving conditions, so that an easy to use but accurate system may be obtained. We show with an existing dataset of eye region crops (nine gaze zones) and two newly collected datasets (12 and 10 gaze zones) that image classification with YOLOv8, which has a simple command line interface, achieves near-perfect accuracy without any pre-processing of the images, as long as a model is trained on the driver and conditions for which annotation is required (such as whether the drivers wear glasses or sunglasses). We also present two apps to collect the training images and to train and apply the YOLOv8 models. Future research will need to explore how well the method extends to real driving conditions, which may be more variable and more difficult to annotate for ground truth labels.
Full article
►▼
Show Figures
Open AccessArticle
A Comparison Study of Deep Learning Methodologies for Music Emotion Recognition
by
Pedro Lima Louro, Hugo Redinho, Ricardo Malheiro, Rui Pedro Paiva and Renato Panda
Cited by 14 | Viewed by 5933
Abstract
Classical machine learning techniques have dominated Music Emotion Recognition. However, improvements have slowed down due to the complex and time-consuming task of handcrafting new emotionally relevant audio features. Deep learning methods have recently gained popularity in the field because of their ability to
[...] Read more.
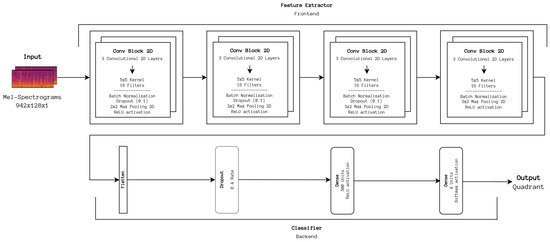
Classical machine learning techniques have dominated Music Emotion Recognition. However, improvements have slowed down due to the complex and time-consuming task of handcrafting new emotionally relevant audio features. Deep learning methods have recently gained popularity in the field because of their ability to automatically learn relevant features from spectral representations of songs, eliminating such necessity. Nonetheless, there are limitations, such as the need for large amounts of quality labeled data, a common problem in MER research. To understand the effectiveness of these techniques, a comparison study using various classical machine learning and deep learning methods was conducted. The results showed that using an ensemble of a Dense Neural Network and a Convolutional Neural Network architecture resulted in a state-of-the-art 80.20% F1 score, an improvement of around 5% considering the best baseline results, concluding that future research should take advantage of both paradigms, that is, combining handcrafted features with feature learning.
Full article
►▼
Show Figures
Open AccessArticle
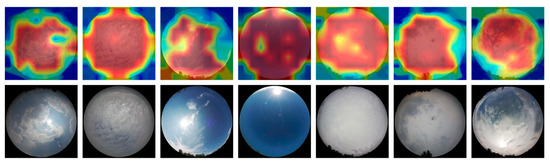
CloudDenseNet: Lightweight Ground-Based Cloud Classification Method for Large-Scale Datasets Based on Reconstructed DenseNet
by
Sheng Li, Min Wang, Shuo Sun, Jia Wu and Zhihao Zhuang
Cited by 10 | Viewed by 5798
Abstract
Cloud observation serves as the fundamental bedrock for acquiring comprehensive cloud-related information. The categorization of distinct ground-based clouds holds profound implications within the meteorological domain, boasting significant applications. Deep learning has substantially improved ground-based cloud classification, with automated feature extraction being simpler and
[...] Read more.
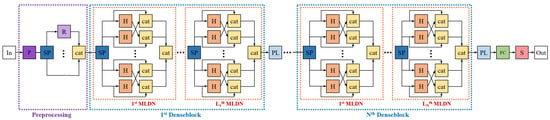
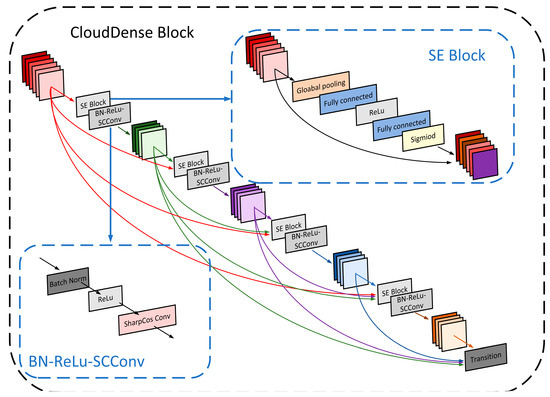
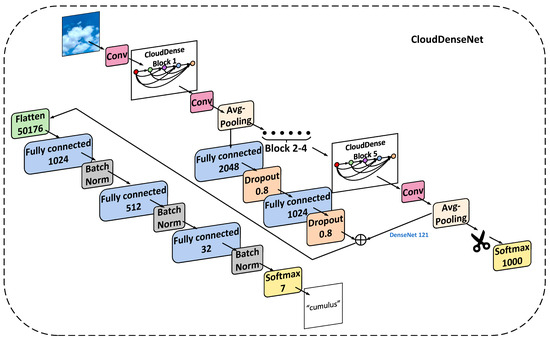
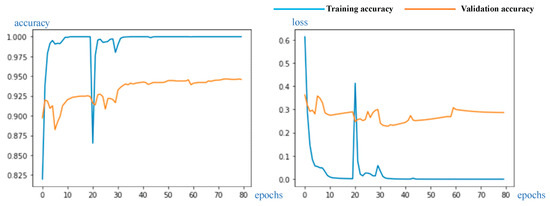
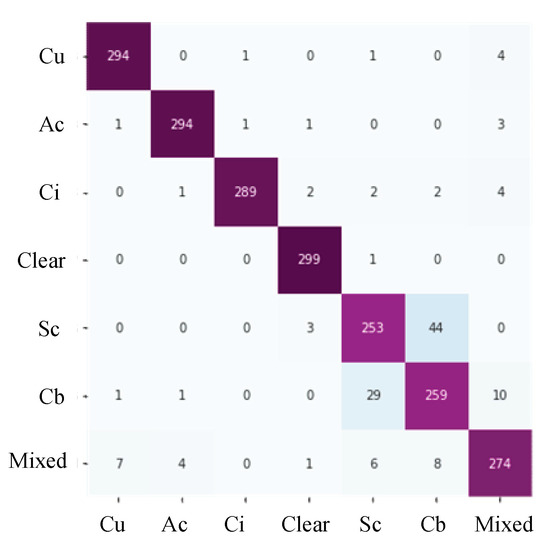
Cloud observation serves as the fundamental bedrock for acquiring comprehensive cloud-related information. The categorization of distinct ground-based clouds holds profound implications within the meteorological domain, boasting significant applications. Deep learning has substantially improved ground-based cloud classification, with automated feature extraction being simpler and far more accurate than using traditional methods. A reengineering of the DenseNet architecture has given rise to an innovative cloud classification method denoted as CloudDenseNet. A novel CloudDense Block has been meticulously crafted to amplify channel attention and elevate the salient features pertinent to cloud classification endeavors. The lightweight CloudDenseNet structure is designed meticulously according to the distinctive characteristics of ground-based clouds and the intricacies of large-scale diverse datasets, which amplifies the generalization ability and elevates the recognition accuracy of the network. The optimal parameter is obtained by combining transfer learning with designed numerous experiments, which significantly enhances the network training efficiency and expedites the process. The methodology achieves an impressive 93.43% accuracy on the large-scale diverse dataset, surpassing numerous published methods. This attests to the substantial potential of the CloudDenseNet architecture for integration into ground-based cloud classification tasks.
Full article
►▼
Show Figures
Open AccessArticle
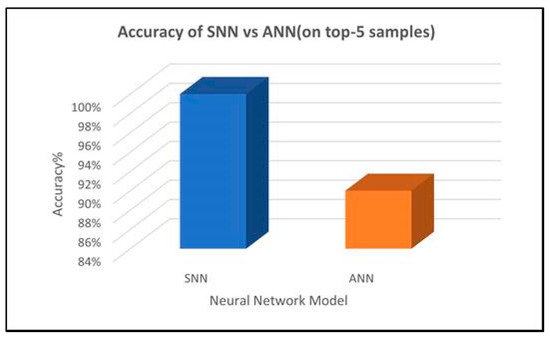
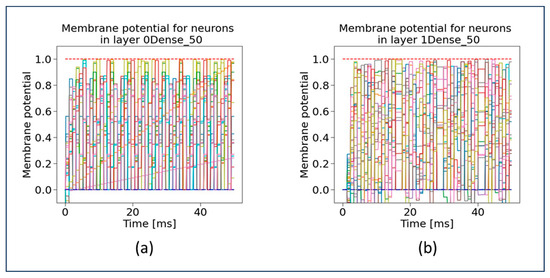
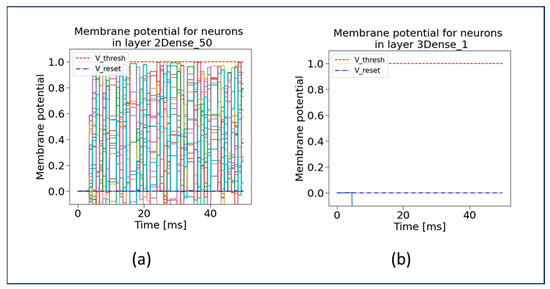
Neuromorphic Sentiment Analysis Using Spiking Neural Networks
by
Raghavendra K. Chunduri and Darshika G. Perera
Cited by 15 | Viewed by 7133
Abstract
Over the past decade, the artificial neural networks domain has seen a considerable embracement of deep neural networks among many applications. However, deep neural networks are typically computationally complex and consume high power, hindering their applicability for resource-constrained applications, such as self-driving vehicles,
[...] Read more.
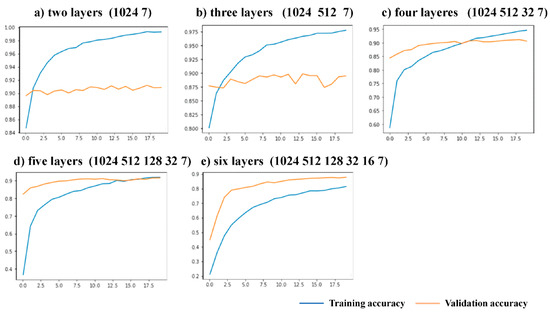
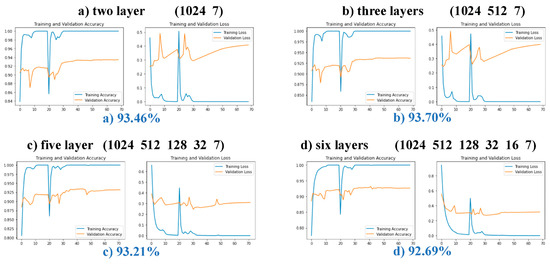
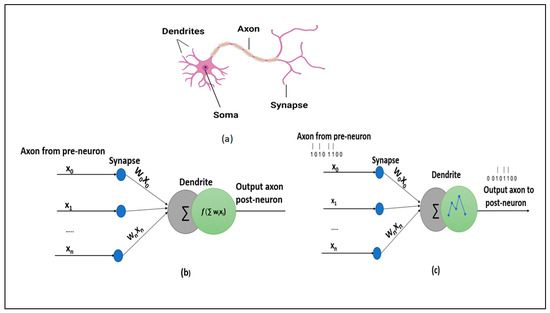
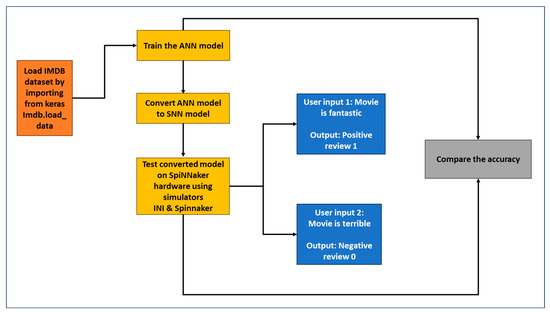
Over the past decade, the artificial neural networks domain has seen a considerable embracement of deep neural networks among many applications. However, deep neural networks are typically computationally complex and consume high power, hindering their applicability for resource-constrained applications, such as self-driving vehicles, drones, and robotics. Spiking neural networks, often employed to bridge the gap between machine learning and neuroscience fields, are considered a promising solution for resource-constrained applications. Since deploying spiking neural networks on traditional von-Newman architectures requires significant processing time and high power, typically, neuromorphic hardware is created to execute spiking neural networks. The objective of neuromorphic devices is to mimic the distinctive functionalities of the human brain in terms of energy efficiency, computational power, and robust learning. Furthermore, natural language processing, a machine learning technique, has been widely utilized to aid machines in comprehending human language. However, natural language processing techniques cannot also be deployed efficiently on traditional computing platforms. In this research work, we strive to enhance the natural language processing traits/abilities by harnessing and integrating the SNNs traits, as well as deploying the integrated solution on neuromorphic hardware, efficiently and effectively. To facilitate this endeavor, we propose a novel, unique, and efficient sentiment analysis model created using a large-scale SNN model on SpiNNaker neuromorphic hardware that responds to user inputs. SpiNNaker neuromorphic hardware typically can simulate large spiking neural networks in real time and consumes low power. We initially create an artificial neural networks model, and then train the model using an Internet Movie Database (IMDB) dataset. Next, the pre-trained artificial neural networks model is converted into our proposed spiking neural networks model, called a spiking sentiment analysis (SSA) model. Our SSA model using SpiNNaker, called SSA-SpiNNaker, is created in such a way to respond to user inputs with a positive or negative response. Our proposed SSA-SpiNNaker model achieves 100% accuracy and only consumes 3970 Joules of energy, while processing around 10,000 words and predicting a positive/negative review. Our experimental results and analysis demonstrate that by leveraging the parallel and distributed capabilities of SpiNNaker, our proposed SSA-SpiNNaker model achieves better performance compared to artificial neural networks models. Our investigation into existing works revealed that no similar models exist in the published literature, demonstrating the uniqueness of our proposed model. Our proposed work would offer a synergy between SNNs and NLP within the neuromorphic computing domain, in order to address many challenges in this domain, including computational complexity and power consumption. Our proposed model would not only enhance the capabilities of sentiment analysis but also contribute to the advancement of brain-inspired computing. Our proposed model could be utilized in other resource-constrained and low-power applications, such as robotics, autonomous, and smart systems.
Full article
►▼
Show Figures
Open AccessArticle
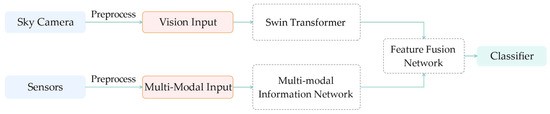
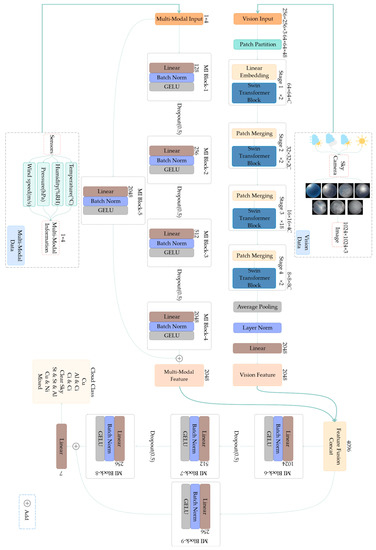
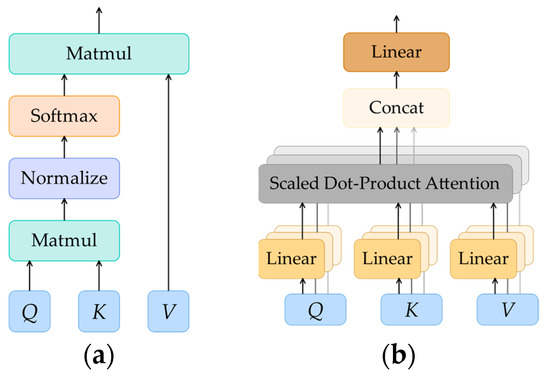
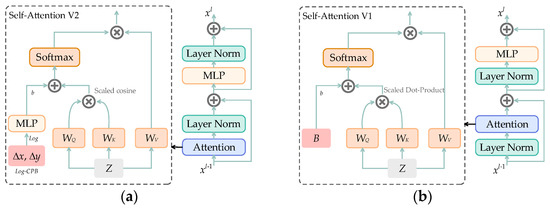
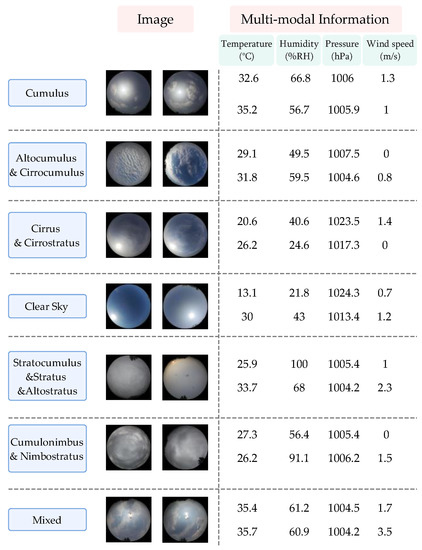
MMST: A Multi-Modal Ground-Based Cloud Image Classification Method
by
Liang Wei, Tingting Zhu, Yiren Guo and Chao Ni
Cited by 6 | Viewed by 3063
Abstract
In recent years, convolutional neural networks have been in the leading position for ground-based cloud image classification tasks. However, this approach introduces too much inductive bias, fails to perform global modeling, and gradually tends to saturate the performance effect of convolutional neural network
[...] Read more.
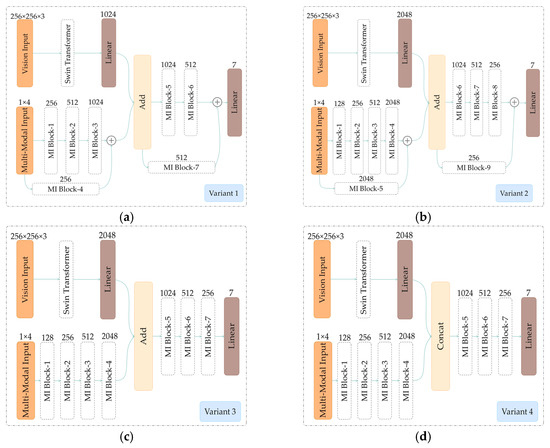
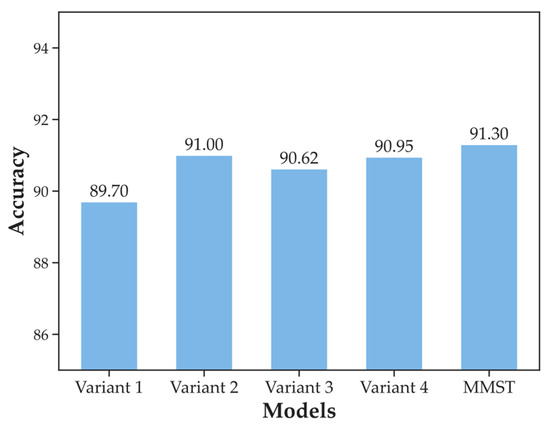
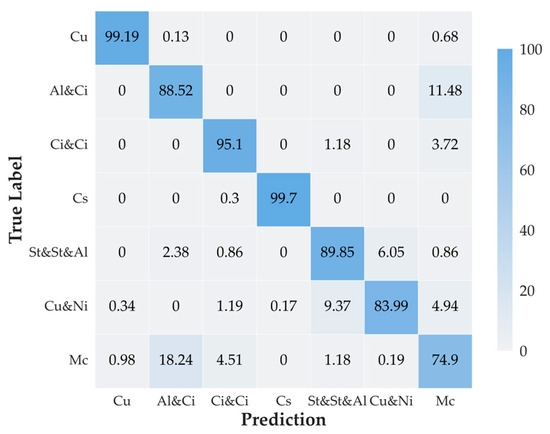
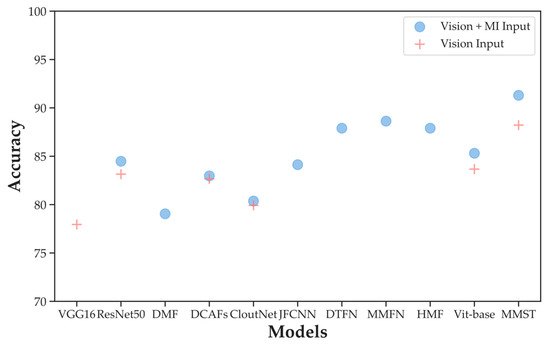
In recent years, convolutional neural networks have been in the leading position for ground-based cloud image classification tasks. However, this approach introduces too much inductive bias, fails to perform global modeling, and gradually tends to saturate the performance effect of convolutional neural network models as the amount of data increases. In this paper, we propose a novel method for ground-based cloud image recognition based on the multi-modal Swin Transformer (MMST), which discards the idea of using convolution to extract visual features and mainly consists of an attention mechanism module and linear layers. The Swin Transformer, the visual backbone network of MMST, enables the model to achieve better performance in downstream tasks through pre-trained weights obtained from the large-scale dataset ImageNet and can significantly shorten the transfer learning time. At the same time, the multi-modal information fusion network uses multiple linear layers and a residual structure to thoroughly learn multi-modal features, further improving the model’s performance. MMST is evaluated on the multi-modal ground-based cloud public data set MGCD. Compared with the state-of-art methods, the classification accuracy rate reaches 91.30%, which verifies its validity in ground-based cloud image classification and proves that in ground-based cloud image recognition, models based on the Transformer architecture can also achieve better results.
Full article
►▼
Show Figures
Open AccessArticle
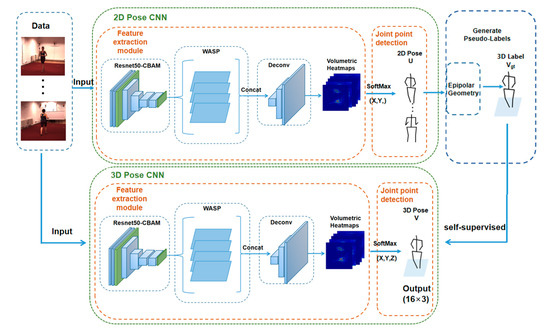
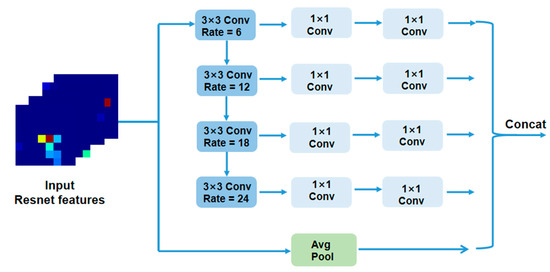
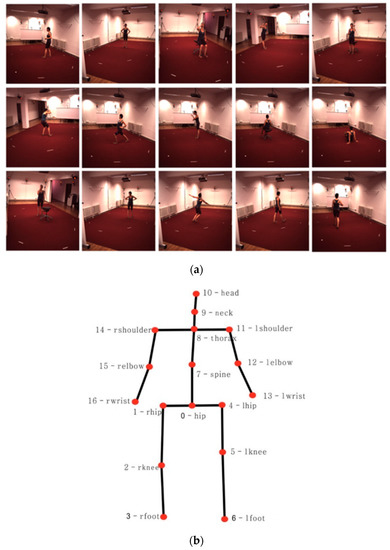
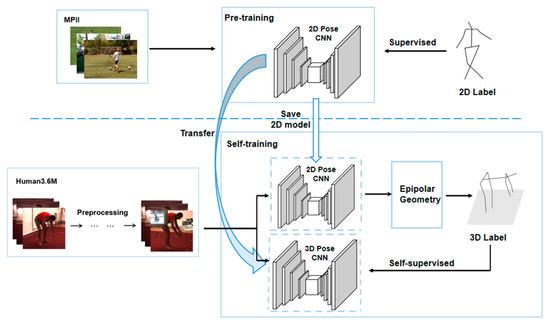
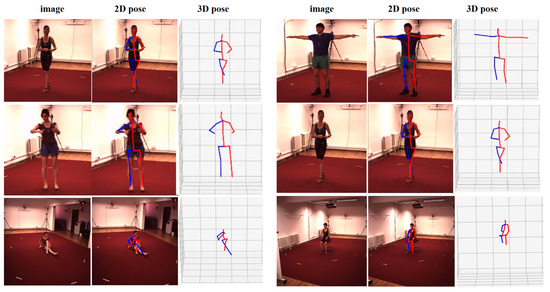
Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision
by
Wenxia Bao, Zhongyu Ma, Dong Liang, Xianjun Yang and Tao Niu
Cited by 12 | Viewed by 7637
Abstract
The accurate estimation of a 3D human pose is of great importance in many fields, such as human–computer interaction, motion recognition and automatic driving. In view of the difficulty of obtaining 3D ground truth labels for a dataset of 3D pose estimation techniques,
[...] Read more.
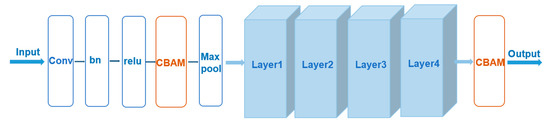
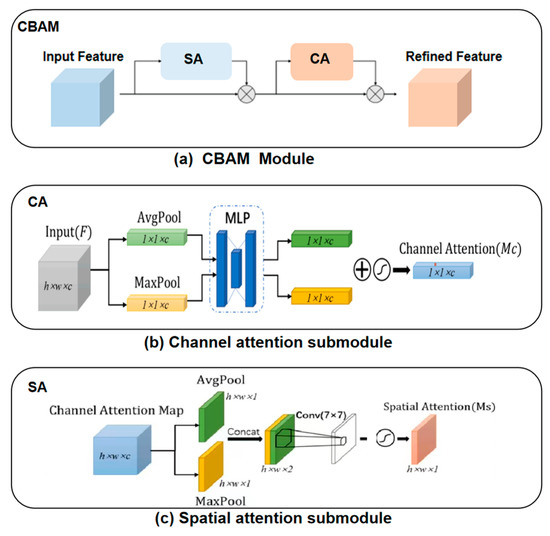
The accurate estimation of a 3D human pose is of great importance in many fields, such as human–computer interaction, motion recognition and automatic driving. In view of the difficulty of obtaining 3D ground truth labels for a dataset of 3D pose estimation techniques, we take 2D images as the research object in this paper, and propose a self-supervised 3D pose estimation model called Pose ResNet. ResNet50 is used as the basic network for extract features. First, a convolutional block attention module (CBAM) was introduced to refine selection of significant pixels. Then, a waterfall atrous spatial pooling (WASP) module is used to capture multi-scale contextual information from the extracted features to increase the receptive field. Finally, the features are input into a deconvolution network to acquire the volume heat map, which is later processed by a soft argmax function to obtain the coordinates of the joints. In addition to the two learning strategies of transfer learning and synthetic occlusion, a self-supervised training method is also used in this model, in which the 3D labels are constructed by the epipolar geometry transformation to supervise the training of the network. Without the need for 3D ground truths for the dataset, accurate estimation of the 3D human pose can be realized from a single 2D image. The results show that the mean per joint position error (MPJPE) is 74.6 mm without the need for 3D ground truth labels. Compared with other approaches, the proposed method achieves better results.
Full article
►▼
Show Figures
Open AccessArticle
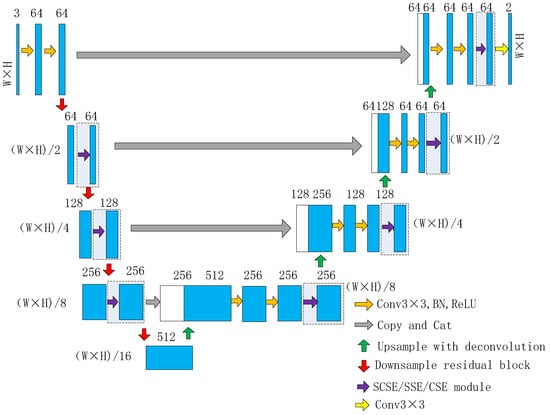
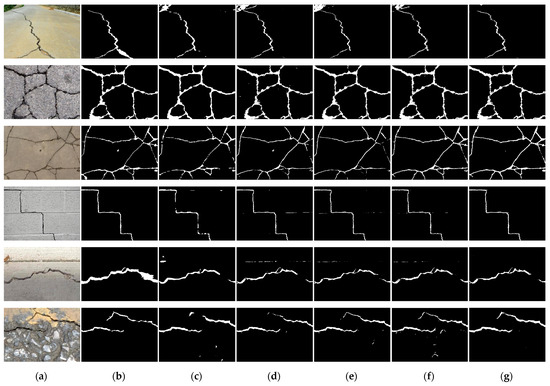
RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation
by
Gui Yu, Juming Dong, Yihang Wang and Xinglin Zhou
Cited by 80 | Viewed by 9754
Abstract
Automatic crack detection is always a challenging task due to the inherent complex backgrounds, uneven illumination, irregular patterns, and various types of noise interference. In this paper, we proposed a U-shaped encoder–decoder semantic segmentation network combining Unet and Resnet for pixel-level pavement crack
[...] Read more.
Automatic crack detection is always a challenging task due to the inherent complex backgrounds, uneven illumination, irregular patterns, and various types of noise interference. In this paper, we proposed a U-shaped encoder–decoder semantic segmentation network combining Unet and Resnet for pixel-level pavement crack image segmentation, which is called RUC-Net. We introduced the spatial-channel squeeze and excitation (scSE) attention module to improve the detection effect and used the focal loss function to deal with the class imbalance problem in the pavement crack segmentation task. We evaluated our methods using three public datasets, CFD, Crack500, and DeepCrack, and all achieved superior results to those of FCN, Unet, and SegNet. In addition, taking the CFD dataset as an example, we performed ablation studies and compared the differences of various scSE modules and their combinations in improving the performance of crack detection.
Full article
►▼
Show Figures
Open AccessArticle
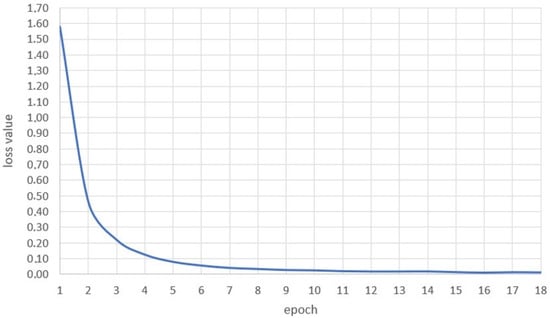
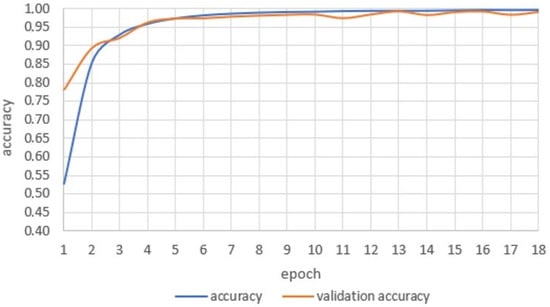
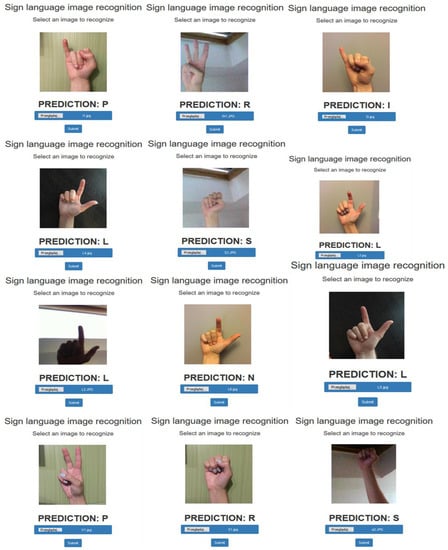
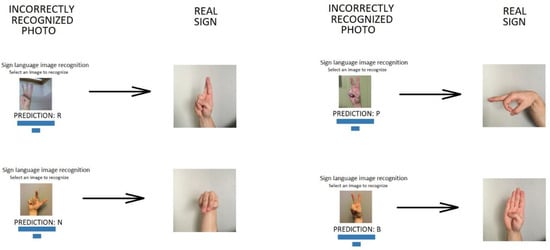
Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network
by
Kamil Kozyra, Karolina Trzyniec, Ernest Popardowski and Maria Stachurska
Cited by 7 | Viewed by 5078
Abstract
This paper presents the development and implementation of an application that recognizes American Sign Language signs with the use of deep learning algorithms based on convolutional neural network architectures. The project implementation includes the development of a training set, the preparation of a
[...] Read more.
This paper presents the development and implementation of an application that recognizes American Sign Language signs with the use of deep learning algorithms based on convolutional neural network architectures. The project implementation includes the development of a training set, the preparation of a module that converts photos to a form readable by the artificial neural network, the selection of the appropriate neural network architecture and the development of the model. The neural network undergoes a learning process, and its results are verified accordingly. An internet application that allows recognition of sign language based on a sign from any photo taken by the user is implemented, and its results are analyzed. The network effectiveness ratio reaches 99% for the training set. Nevertheless, conclusions and recommendations are formulated to improve the operation of the application.
Full article
►▼
Show Figures
Open AccessArticle
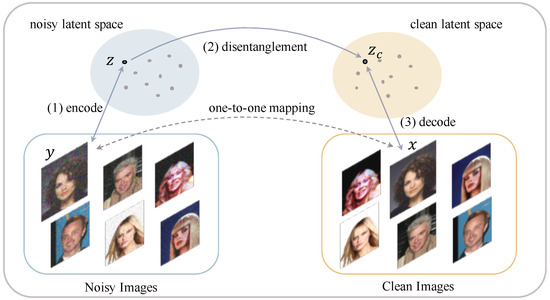
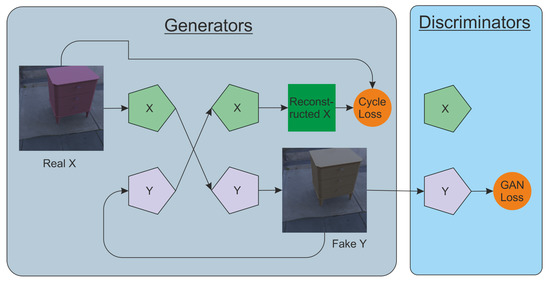
Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network
by
Yang Liu, Saeed Anwar, Zhenyue Qin, Pan Ji, Sabrina Caldwell and Tom Gedeon
Cited by 10 | Viewed by 5360
Abstract
The prevalent convolutional neural network (CNN)-based image denoising methods extract features of images to restore the clean ground truth, achieving high denoising accuracy. However, these methods may ignore the underlying distribution of clean images, inducing distortions or artifacts in denoising results. This paper
[...] Read more.
The prevalent convolutional neural network (CNN)-based image denoising methods extract features of images to restore the clean ground truth, achieving high denoising accuracy. However, these methods may ignore the underlying distribution of clean images, inducing distortions or artifacts in denoising results. This paper proposes a new perspective to treat image denoising as a distribution learning and disentangling task. Since the noisy image distribution can be viewed as a joint distribution of clean images and noise, the denoised images can be obtained via manipulating the latent representations to the clean counterpart. This paper also provides a distribution-learning-based denoising framework. Following this framework, we present an invertible denoising network, FDN, without any assumptions on either clean or noise distributions, as well as a distribution disentanglement method. FDN learns the distribution of noisy images, which is different from the previous CNN-based discriminative mapping. Experimental results demonstrate FDN’s capacity to remove synthetic additive white Gaussian noise (AWGN) on both category-specific and remote sensing images. Furthermore, the performance of FDN surpasses that of previously published methods in real image denoising with fewer parameters and faster speed.
Full article
►▼
Show Figures
Open AccessArticle
Image Synthesis Pipeline for CNN-Based Sensing Systems
by
Vladimir Frolov, Boris Faizov, Vlad Shakhuro, Vadim Sanzharov, Anton Konushin, Vladimir Galaktionov and Alexey Voloboy
Cited by 15 | Viewed by 4650
Abstract
The rapid development of machine learning technologies in recent years has led to the emergence of CNN-based sensors or ML-enabled smart sensor systems, which are intensively used in medical analytics, unmanned driving of cars, Earth sensing, etc. In practice, the accuracy of CNN-based
[...] Read more.
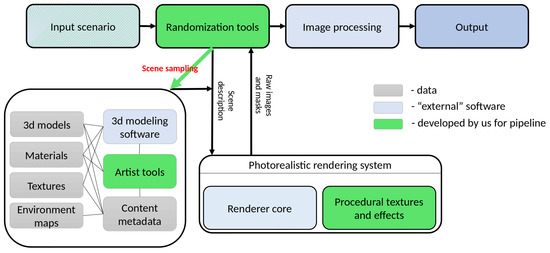
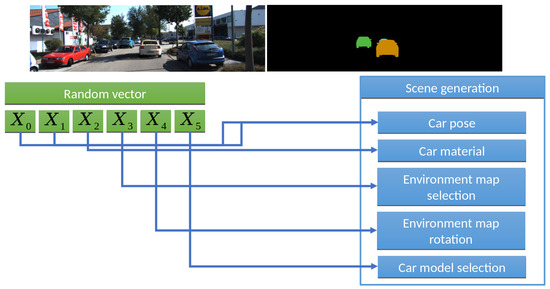
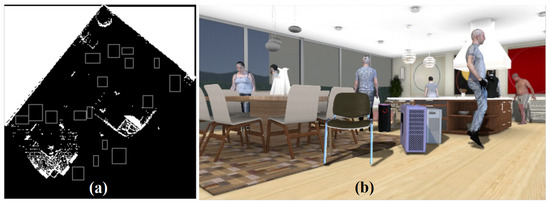
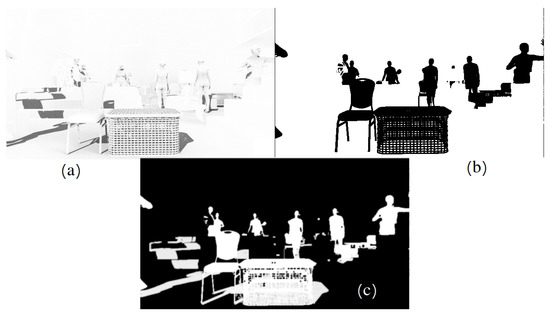
The rapid development of machine learning technologies in recent years has led to the emergence of CNN-based sensors or ML-enabled smart sensor systems, which are intensively used in medical analytics, unmanned driving of cars, Earth sensing, etc. In practice, the accuracy of CNN-based sensors is highly dependent on the quality of the training datasets. The preparation of such datasets faces two fundamental challenges: data quantity and data quality. In this paper, we propose an approach aimed to solve both of these problems and investigate its efficiency. Our solution improves training datasets and validates it in several different applications: object classification and detection, depth buffer reconstruction, panoptic segmentation. We present a pipeline for image dataset augmentation by synthesis with computer graphics and generative neural networks approaches. Our solution is well-controlled and allows us to generate datasets in a reproducible manner with the desired distribution of features which is essential to conduct specific experiments in computer vision. We developed a content creation pipeline targeted to create realistic image sequences with highly variable content. Our technique allows rendering of a single 3D object or 3D scene in a variety of ways, including changing of geometry, materials and lighting. By using synthetic data in training, we have improved the accuracy of CNN-based sensors compared to using only real-life data.
Full article
►▼
Show Figures
Open AccessArticle
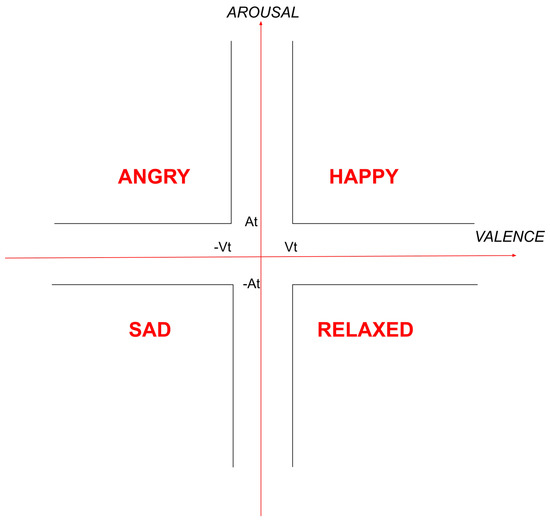
Multi-Modal Song Mood Detection with Deep Learning
by
Konstantinos Pyrovolakis, Paraskevi Tzouveli and Giorgos Stamou
Cited by 37 | Viewed by 9127
Abstract
The production and consumption of music in the contemporary era results in big data generation and creates new needs for automated and more effective management of these data. Automated music mood detection constitutes an active task in the field of MIR (Music Information
[...] Read more.
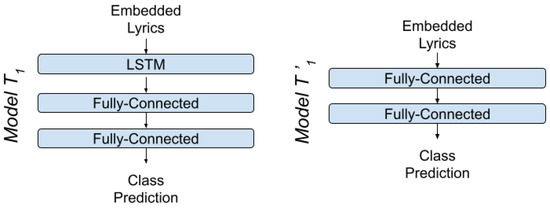
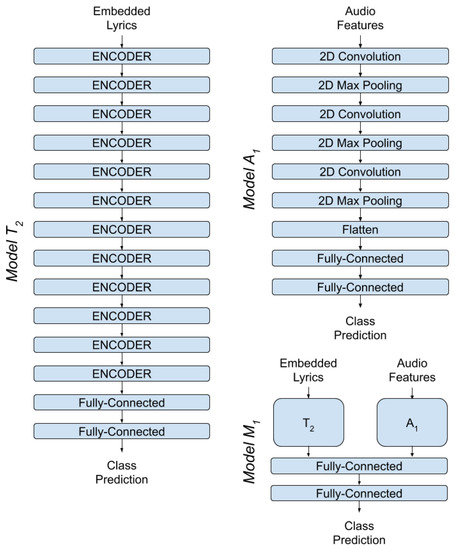
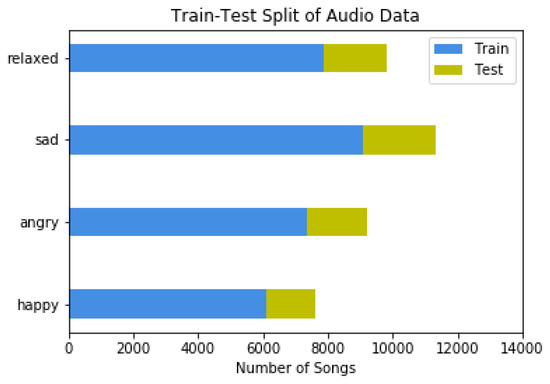
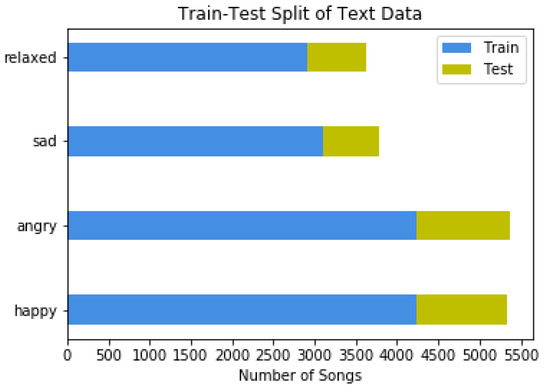
The production and consumption of music in the contemporary era results in big data generation and creates new needs for automated and more effective management of these data. Automated music mood detection constitutes an active task in the field of MIR (Music Information Retrieval). The first approach to correlating music and mood was made in 1990 by Gordon Burner who researched the way that musical emotion affects marketing. In 2016, Lidy and Schiner trained a CNN for the task of genre and mood classification based on audio. In 2018, Delbouys et al. developed a multi-modal Deep Learning system combining CNN and LSTM architectures and concluded that multi-modal approaches overcome single channel models. This work will examine and compare single channel and multi-modal approaches for the task of music mood detection applying Deep Learning architectures. Our first approach tries to utilize the audio signal and the lyrics of a musical track separately, while the second approach applies a uniform multi-modal analysis to classify the given data into mood classes. The available data we will use to train and evaluate our models comes from the MoodyLyrics dataset, which includes 2000 song titles with labels from four mood classes, {happy, angry, sad, relaxed}. The result of this work leads to a uniform prediction of the mood that represents a music track and has usage in many applications.
Full article
►▼
Show Figures
Open AccessArticle
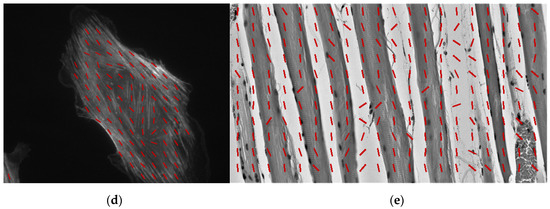
A Convolutional Neural Networks-Based Approach for Texture Directionality Detection
by
Marcin Kociołek, Michał Kozłowski and Antonio Cardone
Cited by 8 | Viewed by 4216
Abstract
The perceived texture directionality is an important, not fully explored image characteristic. In many applications texture directionality detection is of fundamental importance. Several approaches have been proposed, such as the fast Fourier-based method. We recently proposed a method based on the interpolated grey-level
[...] Read more.
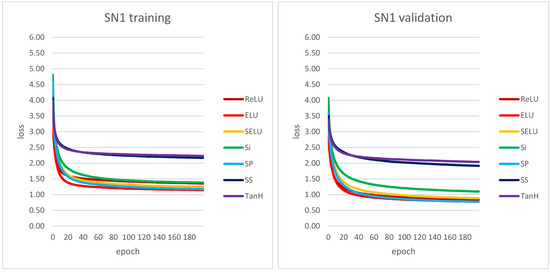
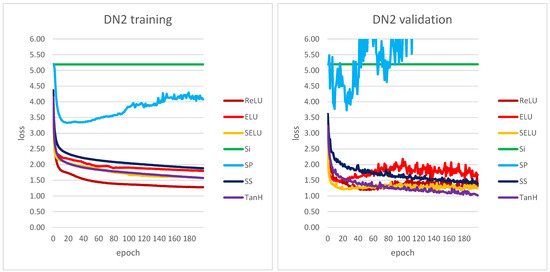
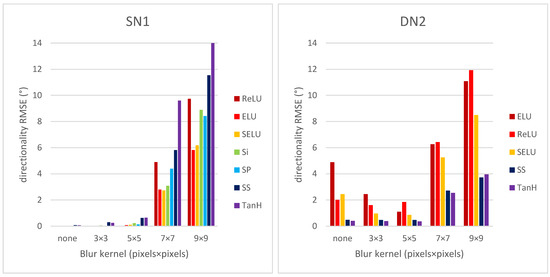
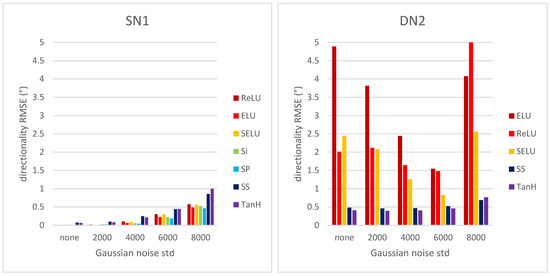
The perceived texture directionality is an important, not fully explored image characteristic. In many applications texture directionality detection is of fundamental importance. Several approaches have been proposed, such as the fast Fourier-based method. We recently proposed a method based on the interpolated grey-level co-occurrence matrix (iGLCM), robust to image blur and noise but slower than the Fourier-based method. Here we test the applicability of convolutional neural networks (CNNs) to texture directionality detection. To obtain the large amount of training data required, we built a training dataset consisting of synthetic textures with known directionality and varying perturbation levels. Subsequently, we defined and tested shallow and deep CNN architectures. We present the test results focusing on the CNN architectures and their robustness with respect to image perturbations. We identify the best performing CNN architecture, and compare it with the iGLCM, the Fourier and the local gradient orientation methods. We find that the accuracy of CNN is lower, yet comparable to the iGLCM, and it outperforms the other two methods. As expected, the CNN method shows the highest computing speed. Finally, we demonstrate the best performing CNN on real-life images. Visual analysis suggests that the learned patterns generalize to real-life image data. Hence, CNNs represent a promising approach for texture directionality detection, warranting further investigation.
Full article
►▼
Show Figures
Open AccessArticle
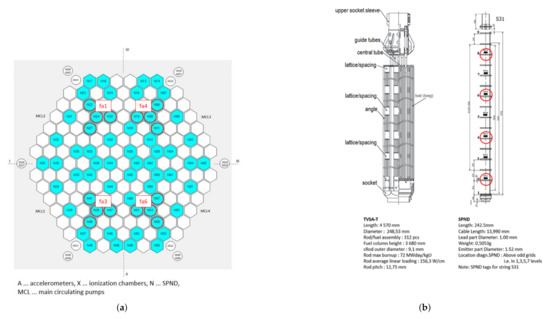
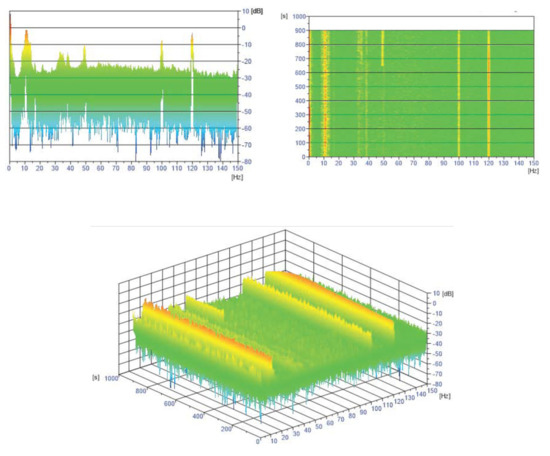
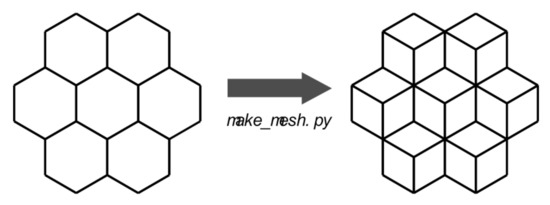
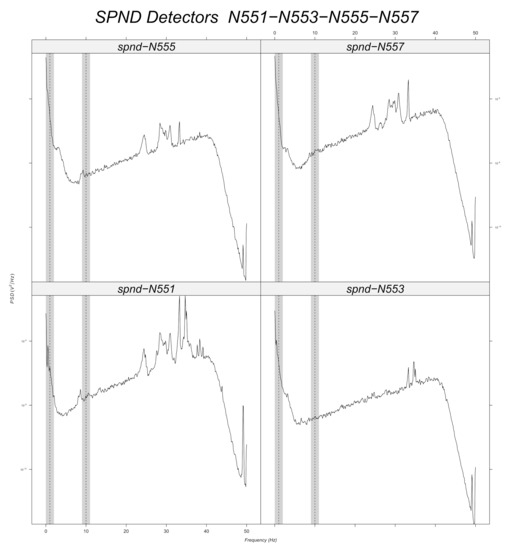
Localizing Perturbations in Pressurized Water Reactors Using One-Dimensional Deep Convolutional Neural Networks
by
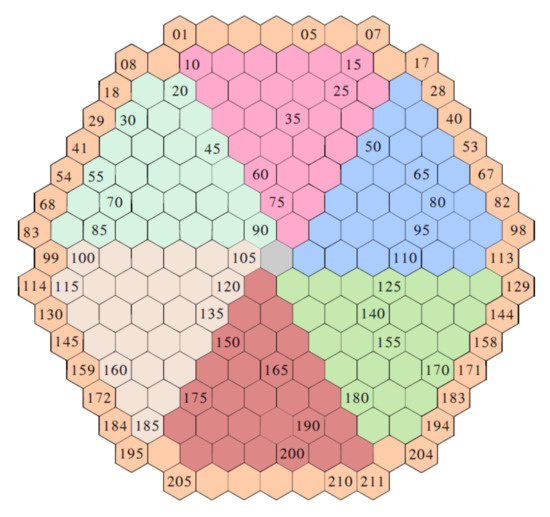
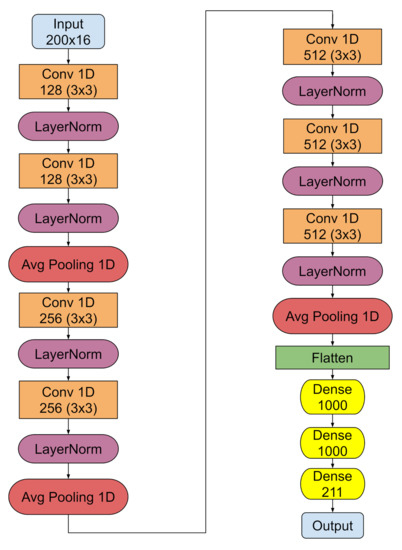
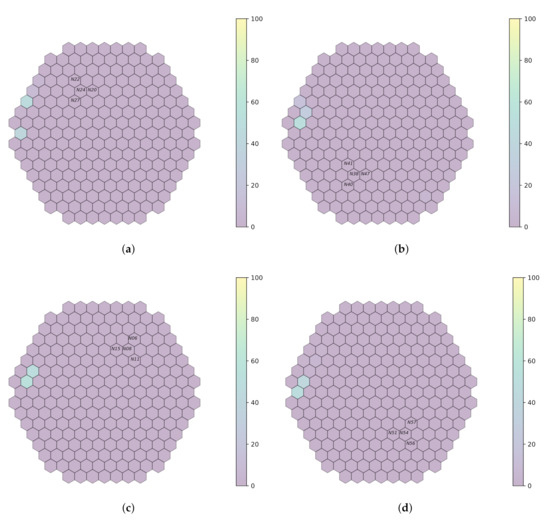
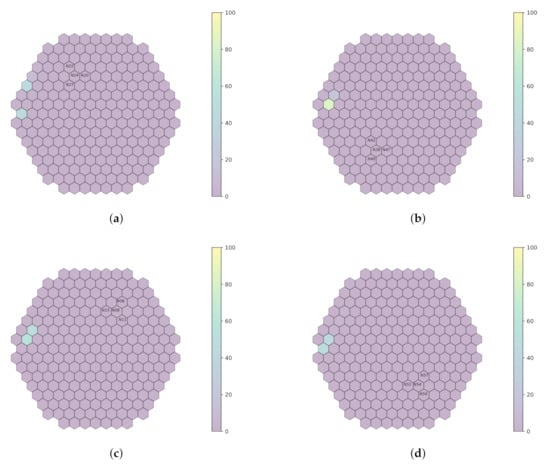
Laurent Pantera, Petr Stulík, Antoni Vidal-Ferràndiz, Amanda Carreño, Damián Ginestar, George Ioannou, Thanos Tasakos, Georgios Alexandridis and Andreas Stafylopatis
Cited by 5 | Viewed by 4385
Abstract
This work outlines an approach for localizing anomalies in nuclear reactor cores during their steady state operation, employing deep, one-dimensional, convolutional neural networks. Anomalies are characterized by the application of perturbation diagnostic techniques, based on the analysis of the so-called “neutron-noise” signals: that
[...] Read more.
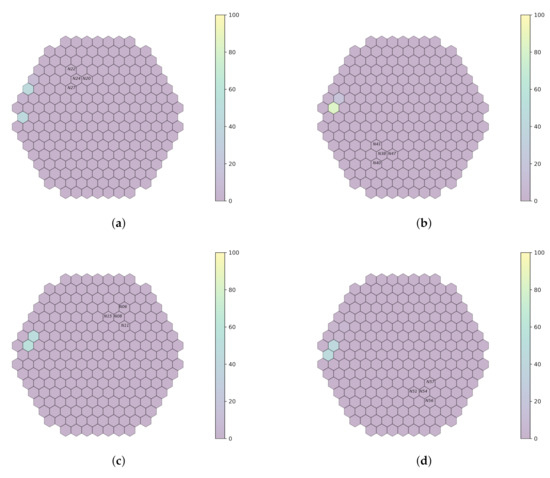
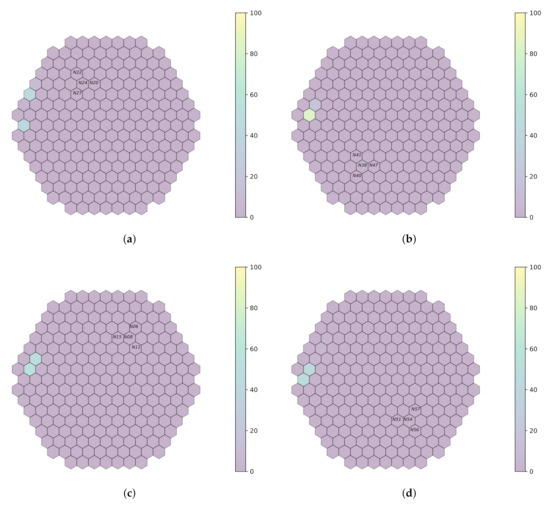
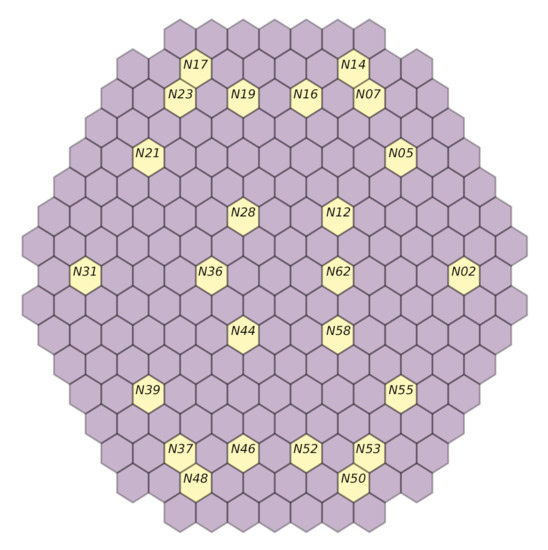
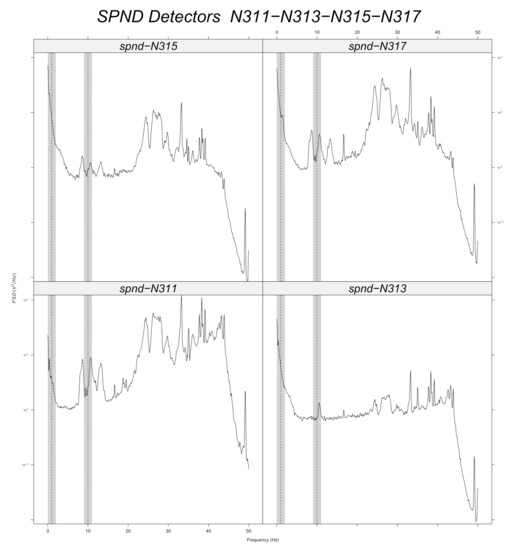
This work outlines an approach for localizing anomalies in nuclear reactor cores during their steady state operation, employing deep, one-dimensional, convolutional neural networks. Anomalies are characterized by the application of perturbation diagnostic techniques, based on the analysis of the so-called “neutron-noise” signals: that is, fluctuations of the neutron flux around the mean value observed in a steady-state power level. The proposed methodology is comprised of three steps: initially, certain reactor core perturbations scenarios are simulated in software, creating the respective perturbation datasets, which are specific to a given reactor geometry; then, the said datasets are used to train deep learning models that learn to identify and locate the given perturbations within the nuclear reactor core; lastly, the models are tested on actual plant measurements. The overall methodology is validated on hexagonal, pre-Konvoi, pressurized water, and VVER-1000 type nuclear reactors. The simulated data are generated by the FEMFFUSION code, which is extended in order to deal with the hexagonal geometry in the time and frequency domains. The examined perturbations are absorbers of variable strength, and the trained models are tested on actual plant data acquired by the in-core detectors of the Temelín VVER-1000 Power Plant in the Czech Republic. The whole approach is realized in the framework of Euratom’s CORTEX project.
Full article
►▼
Show Figures
Open AccessArticle
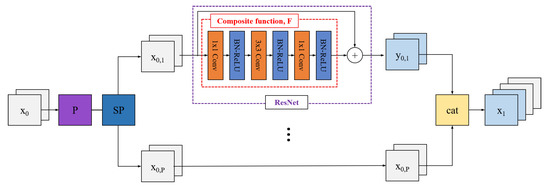
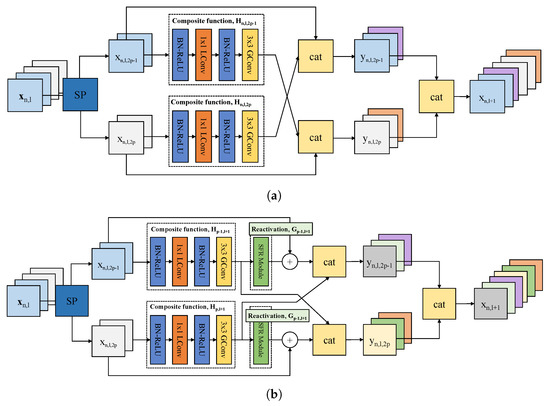
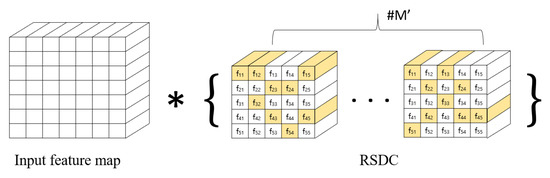
Multipath Lightweight Deep Network Using Randomly Selected Dilated Convolution
by
Sangun Park and Dong Eui Chang
Cited by 4 | Viewed by 2778
Abstract
Robot vision is an essential research field that enables machines to perform various tasks by classifying/detecting/segmenting objects as humans do. The classification accuracy of machine learning algorithms already exceeds that of a well-trained human, and the results are rather saturated. Hence, in recent
[...] Read more.
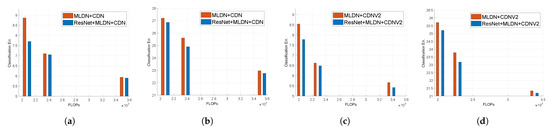
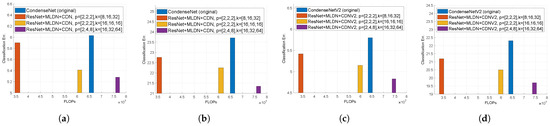
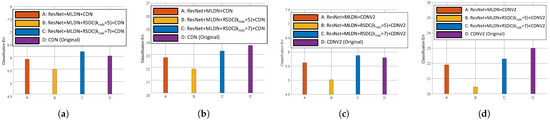
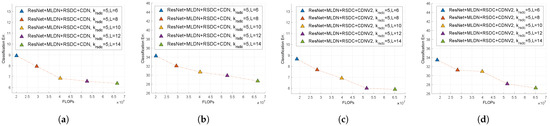
Robot vision is an essential research field that enables machines to perform various tasks by classifying/detecting/segmenting objects as humans do. The classification accuracy of machine learning algorithms already exceeds that of a well-trained human, and the results are rather saturated. Hence, in recent years, many studies have been conducted in the direction of reducing the weight of the model and applying it to mobile devices. For this purpose, we propose a multipath lightweight deep network using randomly selected dilated convolutions. The proposed network consists of two sets of multipath networks (minimum 2, maximum 8), where the output feature maps of one path are concatenated with the input feature maps of the other path so that the features are reusable and abundant. We also replace the
standard convolution of each path with a randomly selected dilated convolution, which has the effect of increasing the receptive field. The proposed network lowers the number of floating point operations (FLOPs) and parameters by more than 50% and the classification error by 0.8% as compared to the state-of-the-art. We show that the proposed network is efficient.
Full article
►▼
Show Figures
Open AccessCommunication
Deep Learning Based Prediction on Greenhouse Crop Yield Combined TCN and RNN
by
Liyun Gong, Miao Yu, Shouyong Jiang, Vassilis Cutsuridis and Simon Pearson
Cited by 127 | Viewed by 12627
Abstract
Currently, greenhouses are widely applied for plant growth, and environmental parameters can also be controlled in the modern greenhouse to guarantee the maximum crop yield. In order to optimally control greenhouses’ environmental parameters, one indispensable requirement is to accurately predict crop yields based
[...] Read more.
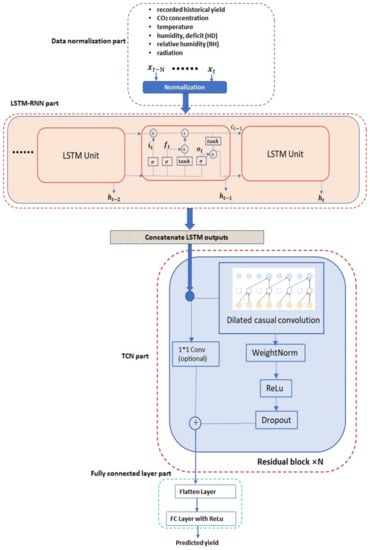
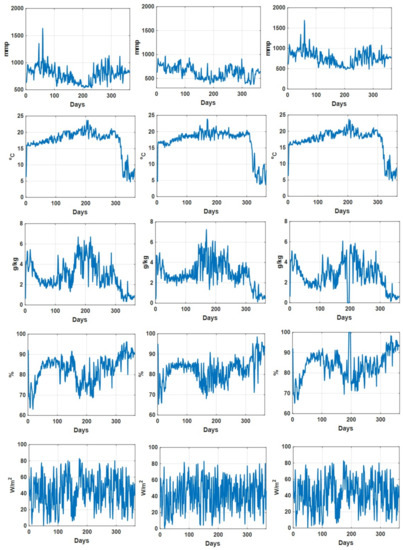
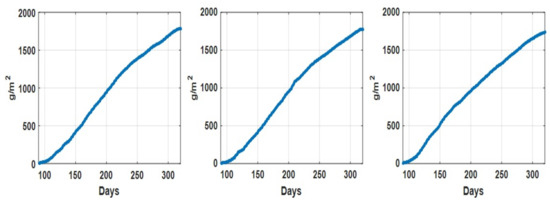
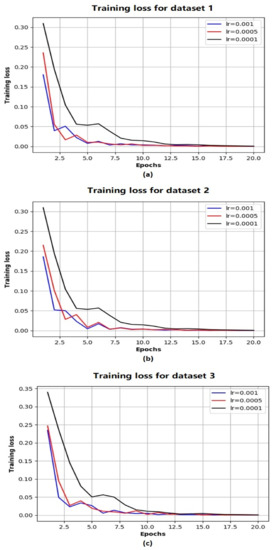
Currently, greenhouses are widely applied for plant growth, and environmental parameters can also be controlled in the modern greenhouse to guarantee the maximum crop yield. In order to optimally control greenhouses’ environmental parameters, one indispensable requirement is to accurately predict crop yields based on given environmental parameter settings. In addition, crop yield forecasting in greenhouses plays an important role in greenhouse farming planning and management, which allows cultivators and farmers to utilize the yield prediction results to make knowledgeable management and financial decisions. It is thus important to accurately predict the crop yield in a greenhouse considering the benefits that can be brought by accurate greenhouse crop yield prediction. In this work, we have developed a new greenhouse crop yield prediction technique, by combining two state-of-the-arts networks for temporal sequence processing—temporal convolutional network (TCN) and recurrent neural network (RNN). Comprehensive evaluations of the proposed algorithm have been made on multiple datasets obtained from multiple real greenhouse sites for tomato growing. Based on a statistical analysis of the root mean square errors (RMSEs) between the predicted and actual crop yields, it is shown that the proposed approach achieves more accurate yield prediction performance than both traditional machine learning methods and other classical deep neural networks. Moreover, the experimental study also shows that the historical yield information is the most important factor for accurately predicting future crop yields.
Full article
►▼
Show Figures














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
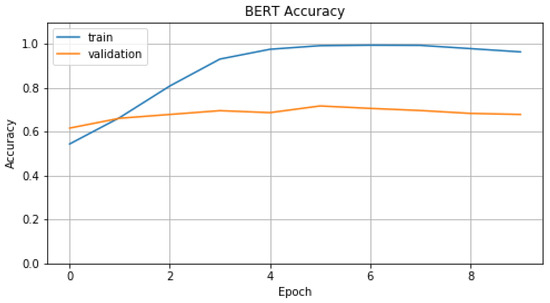{kind=link}
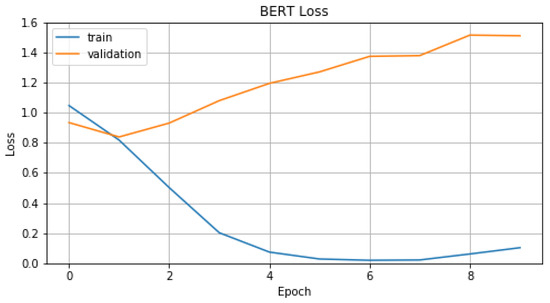{kind=link}
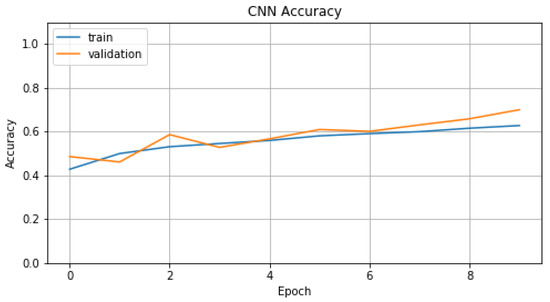{kind=link}
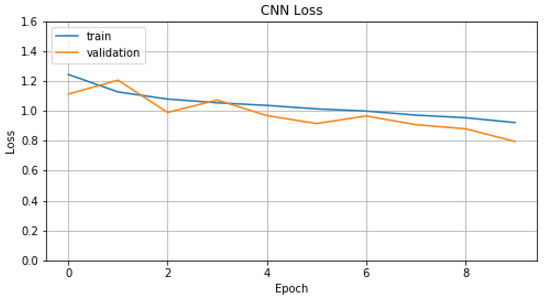{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}