Abstract
This paper aims to solve the multi-objective operating planning problem in the radioactive environment. First, a more complicated radiation dose model is constructed, considering difficulty levels at each operating point. Based on this model, the multi-objective operating planning problem is converted to a variant traveling salesman problem (VTSP). Second, with respect to this issue, a novel combinatorial algorithm framework, namely hyper-parameter adaptive genetic algorithm (HPAGA), integrating bio-inspired optimization with reinforcement learning, is proposed, which allows for adaptive adjustment of the hyperparameters of GA so as to obtain optimal solutions efficiently. Third, comparative studies demonstrate the superior performance of the proposed HPAGA against classical evolutionary algorithms for various TSP instances. Additionally, a case study in the simulated radioactive environment implies the potential application of HPAGA in the future.
1. Introduction
Nuclear energy has been widely applied in various developed countries, as well as in several developing countries, including China [1]. In this situation, a growing number of humans, robots, and other agents are employed to operate the nuclear facilities, which might increase the risk of nuclear exposure [2]. Although nuclear protective equipment can prevent agents from a large amount of radiation dose, it is harmful to human health and robot stability and reliability to work in the radioactive environment [3]. Therefore, with respect to the path planning problem in the radiation environment, one of the crucial goals is to provide an optimal path traversing all the operating points eventually with the lowest cumulative radiation dose [4]. Note that the traversing issue is defined as a multi-objective operating planning problem, which is distinct from the multi-objective optimization problem.
In overhauling or accident response scenarios, people or robots should traverse all the operating points and then return to the origin. Therefore, how to determine an operating sequence with the minimal radiation dose, namely the multi-objective operating planning problem, is important as well for the path planning process. Note that the aforementioned issue is similar to a standard traveling salesman problem (TSP). Wang et al. proposed an improved particle swarm optimization combined with a chaos optimization algorithm to cut the effective radiation dose when agents traverse over all the nodes [5]. Xie et al. combined the improved ACO algorithm and chaos optimization algorithm to solve the multi-objective inspection path-planning problem [6]. Although both methods are demonstrated to be effective in radiation path planning, the multi-objective operating planning problem can be modeled in a more complex way by taking the task difficulty at each operating point, i.e., the operating time, into consideration to be closer to reality. Compared to the classic TSP, the cost between two operating points is not just a simple Euclidean distance but a compound metric including cumulative dose and the consumed operating time. Therefore, the multi-objective operating planning problem can be modeled as a variant of the traveling salesman problem (VTSP).
This paper aims to solve the multi-objective operating planning problem; one primary part is path planning in the radiation environment considering multiple operating points with different operating difficulty levels and multiple radiation sources of different dose rates. Further, a modified genetic algorithm (GA) associated with reinforcement learning (RL), namely the hyper-parameter adaptive genetic algorithm (HPAGA), is provided to solve the radiation VTSP more efficiently. In practical terms, this proposed methodology will prevent people and robots from excessive radiation doses, holding considerable importance, especially as the nuclear power industry construction continues to develop rapidly.
There are three primary contributions listed as follows:
- A more complicated multi-objective operating planning problem model in the radiation environment is constructed compared to [6]. Specifically, this model considers the operating difficulty level at each operating point ignored entirely in [6], which influences the time to complete each operating task and then the cumulative radiation dose. Therefore, this newly constructed model is closer to the engineering practice.
- A combinatorial algorithm framework consisting of the bio-inspired optimal algorithm and reinforcement learning is provided, where the hyper-parameters of GA, including crossover probability, mutation probability, and population size, can be adjusted by the RL during the iterative process in order to solve the VTSP more efficiently.
- Comparative tests between the proposed HPAGA and several classical evolutionary computing algorithms in terms of solving different TSP instances with diverse scales are conducted to demonstrate the superior performance of the proposed hybrid algorithm.
The rest of this paper is organized as follows: Section 2 gives a brief overview of the related work. The model of the multi-objective operating planning problem in the radiation environment is constructed in Section 3. The combinatorial algorithm framework is described in Section 4. A series of comparative experiments between the proposed method and other classical methods are recorded in Section 5. Besides, a case study in a simulated nuclear facilities inspection task is conducted in Section 6. Finally, the conclusion and future work is expounded in Section 7.
2. Related Work
Recently, plentiful path planning and operating planning methods have been proposed for radiation environments to minimize cumulative radiation doses during overhauling or accident response stages [7]. Graph searching, as a typical method for path planning, has been employed for radioactive environments. Liu et al. proposed an A* algorithm to plan the walking path with a minimum dose. Similarly, several sampling-based exploration methods have been utilized in the path planning with reducing radiation dose [8]. Chao et al. proposed a grid-based rapidly exploring random tree star (RRT*) method to prevent workers from nuclear exposure as much as possible [9]. Evolutionary computing algorithms and their variants are widely used to solve this issue. For instance, Zhang et al. proposed a hybrid algorithm consisting of an improved ant colony optimization (ACO), A* algorithm, and particle swarm optimization [2,10]. Meanwhile, Lee et al. provided a conflict-based search approach for multi-agents to find respective optimal paths in the radiation environment [11]. The aforementioned methods aim at finding an optimal path from the start point to the destination point neglecting the possible multiple operating points.
Different from the aforementioned planning issues in the radiation environment, this paper focuses on the multi-objective operating panning problem, which is regarded as a VTSP. Note that TSP is a typical combinatorial optimization problem, which belongs to the NP-hard problem [12]. To solve TSP, related algorithms can be roughly classified into three categories, i.e., exact algorithms, heuristic algorithms, and bio-inspired optimization algorithms [13]. Applegate et al. proposed the concord algorithm via modeling TSP as mixed-integer programming problems, where a branch-and-cut algorithm is utilized to solve it [14]. This is one of the best exact solvers to our best knowledge [15]. Meanwhile, LKH-3 is a state-of-art heuristic algorithm for solving TSP, which involves the thinking of local search and k-opt operators to reduce the exploration space [16]. However, both the exact solvers and the heuristic methods are time-consuming to obtain satisfactory solutions. In contrast, bio-inspired optimization algorithms, such as the representative of approximate algorithms, can obtain accepted solutions of TSP with a short running time. There is GA [17,18], wolf search algorithm [19], rat swarm optimizer [20], and so on for solving TSP. Thereinto, GA is a popular optimization technique that mimics the process of natural selection [21]. However, it is difficult to effectively set up the hyper-parameters including crossover probability, mutation probability, the amount of population, and so on [22]. Recently, several hybrid algorithms combined with evolutionary computing algorithms and reinforcement learning have been provided to solve NP-hard problems [23,24]. Inspired by the creative idea of the hybrid algorithm [25], reinforcement learning is employed to adjust the hyper-parameters of GA according to the fitness of the population so as to speed up convergence and avoid the local minimum in this paper.
3. Problem Formulation
3.1. Radiation Dose Model
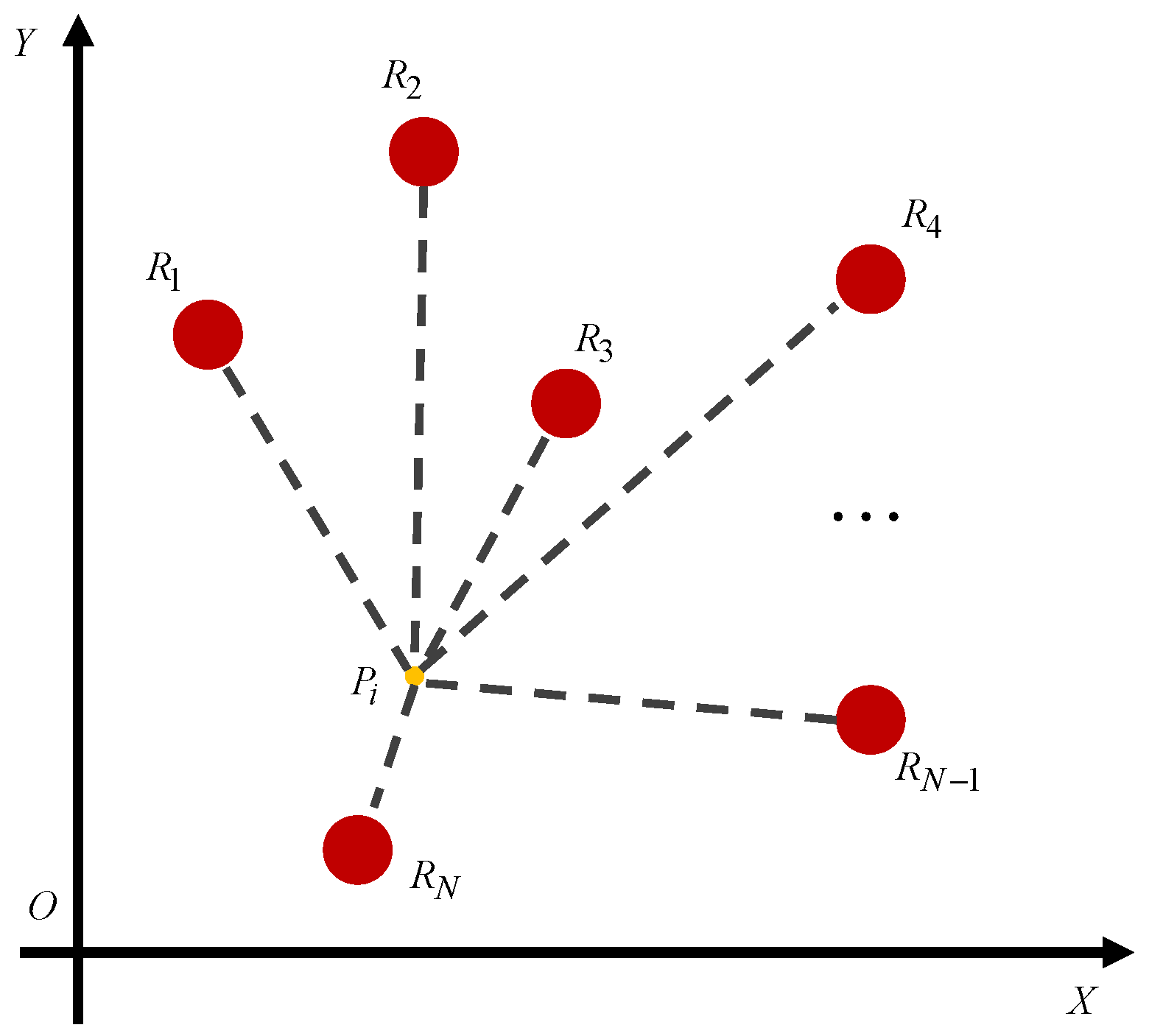
In the radioactive environment, suppose that there are N radiation sources with different dose rates, represented by , located in the plane as shown in Figure 1. The radiation dose rate derived from each radiation source is inversely proportional to the square of the distance. Therefore, the dose rate of a certain point suffering from multiple radiation sources is obtained as
where denotes the distance between points and .
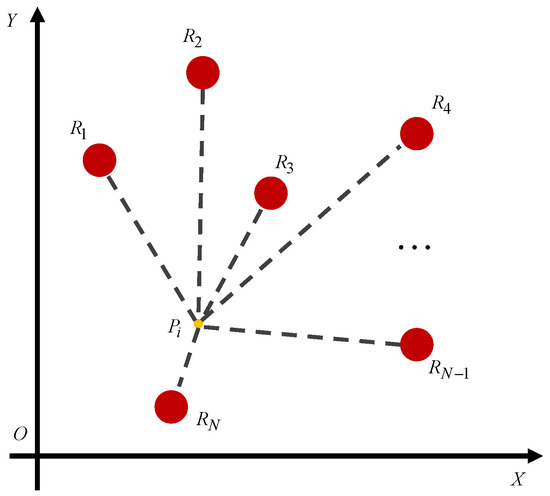
Figure 1.
A certain point is infected by the multiple radiation sources.
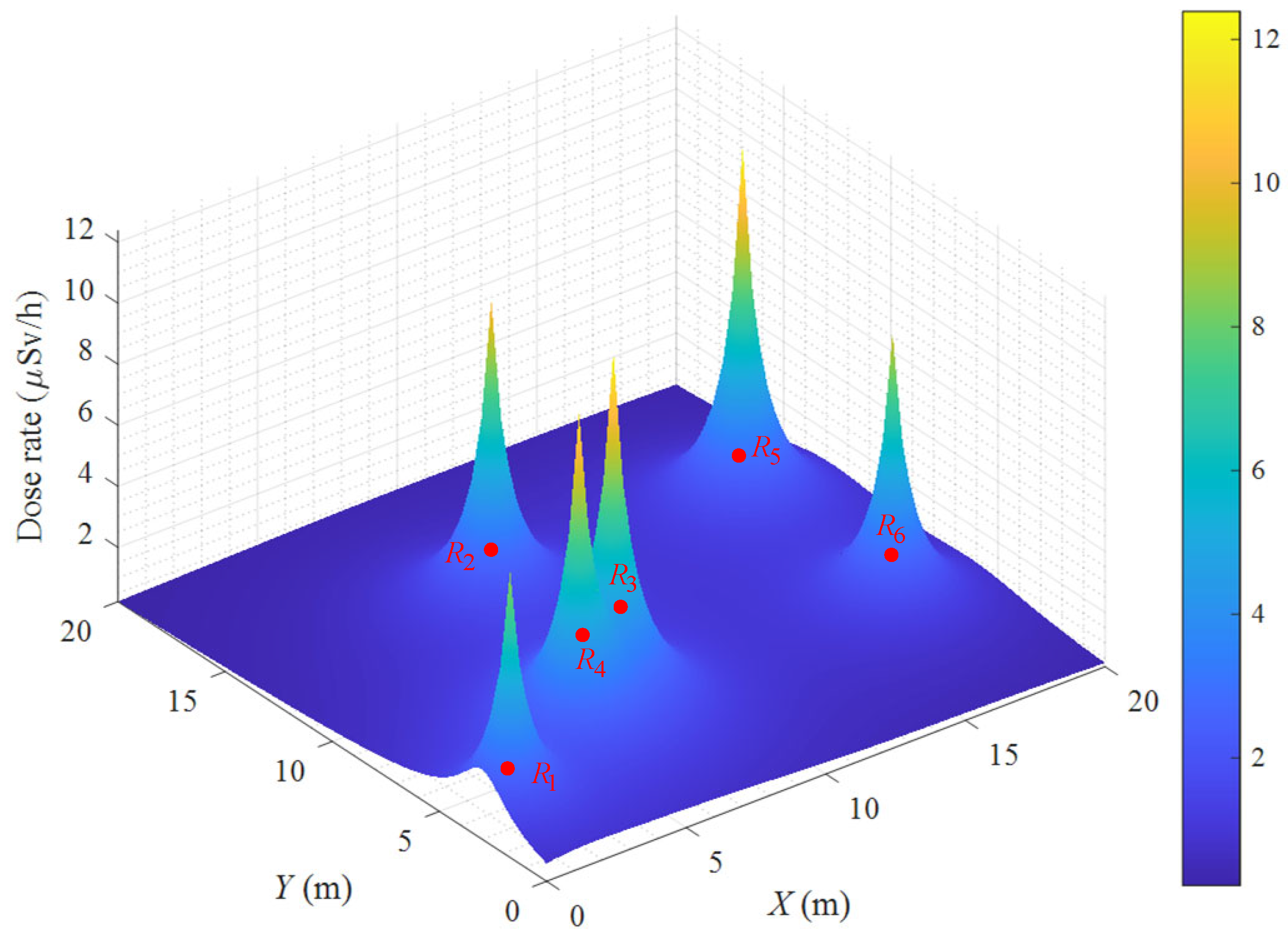
The cumulative dose is the crucial reason for causing the harmfulness to people and robots, which is related to the exposure time. With respect to the multi-objective operating planning problem in the radioactive environment, the cumulative dose between two operating points and consists of primary two parts, namely the locomotion cumulative dose and the operating stay cumulative dose, which is expressed by
where means the locomotion cumulative dose between and , and denotes the operating stay cumulative dose at . The radiation dose rate map with six radiation sources is intuitively illustrated in Figure 2.
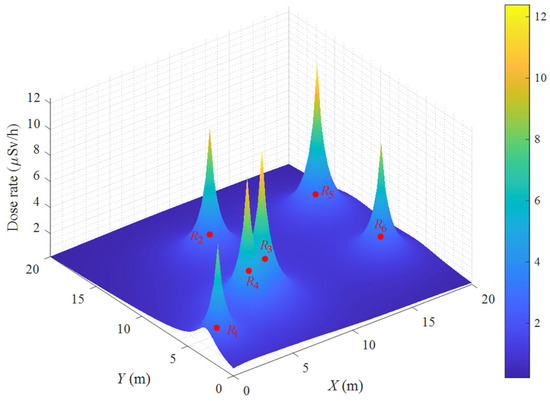
Figure 2.
The radiation dose rate map.
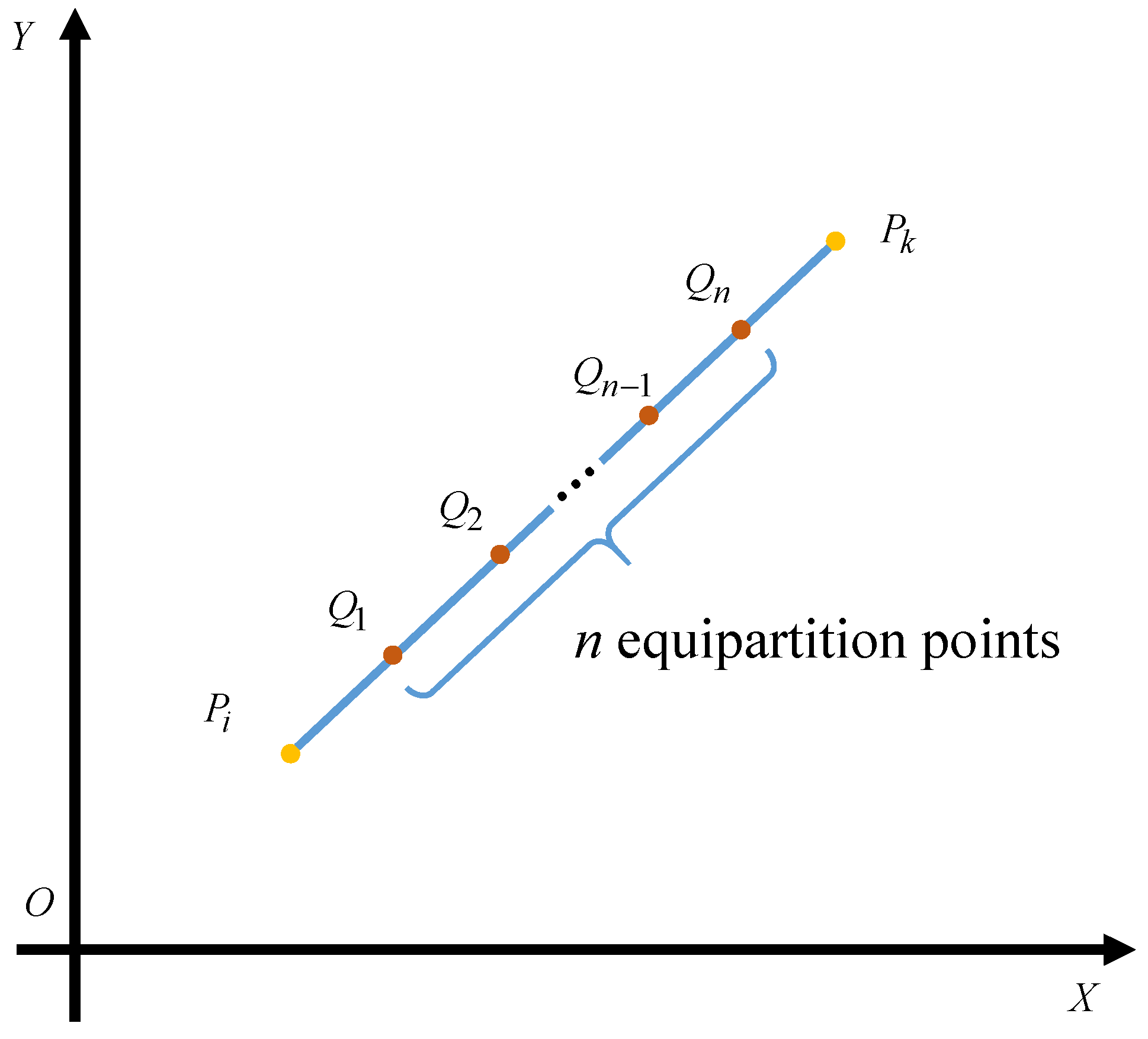
Concretely, the locomotion cumulative dose is generated during the locomotion from one operating point to the next operating point, which can be calculated by
where n is the resolution factor representing the number of the equipartition points as shown in Figure 3. Besides, v denotes the velocity of the agent, which is a constant in this paper.
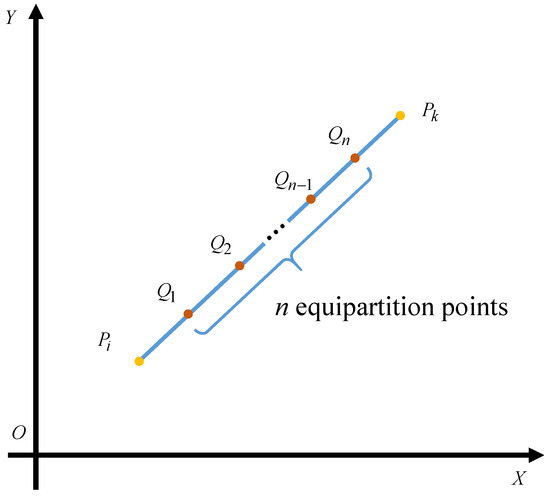
Figure 3.
The computing method for cumulative radiation dose between two points.
Meanwhile, the operating stay cumulative dose is derived by
where represents the cost time during operating at which is related to the difficulty of the operating task. Note that the radiation dose model is more complex than [6], for the operating difficulty is taken into consideration when computing the cumulative dose.
3.2. VTSP Formulation
In this paper, the multi-objective operating planning problem in the radiation environment is modeled as a variant TSP, where the Euclidean distance between any two nodes is replaced by the cumulative radiation dose. Similar to the typical TSP, the purpose is to find a traversing sequence of operating points with the minimum cumulative radiation dose, where the agent should launch from the origin, pass through every operating point only once, and finally return to the origin.
Suppose that there are K operating points in the radioactive scenario, the traversing sequence is defined as
where means the origin point. Then, the total cumulative radiation dose during the whole process is described as
where denotes the total cumulative dose related to a certain sequence . Furthermore, the optimal sequence with the minimal cumulative dose is obtained by
where exchanging the order of operating points can promote the total cumulative dose to approach the optimal.
So far, the radiation dose model for the multi-objective operating planning problem has been formulated. In the next content, the proposed HPAGA will be introduced to solve this VTSP in an effective way.
4. Proposed HPAGA
4.1. Algorithm Framework
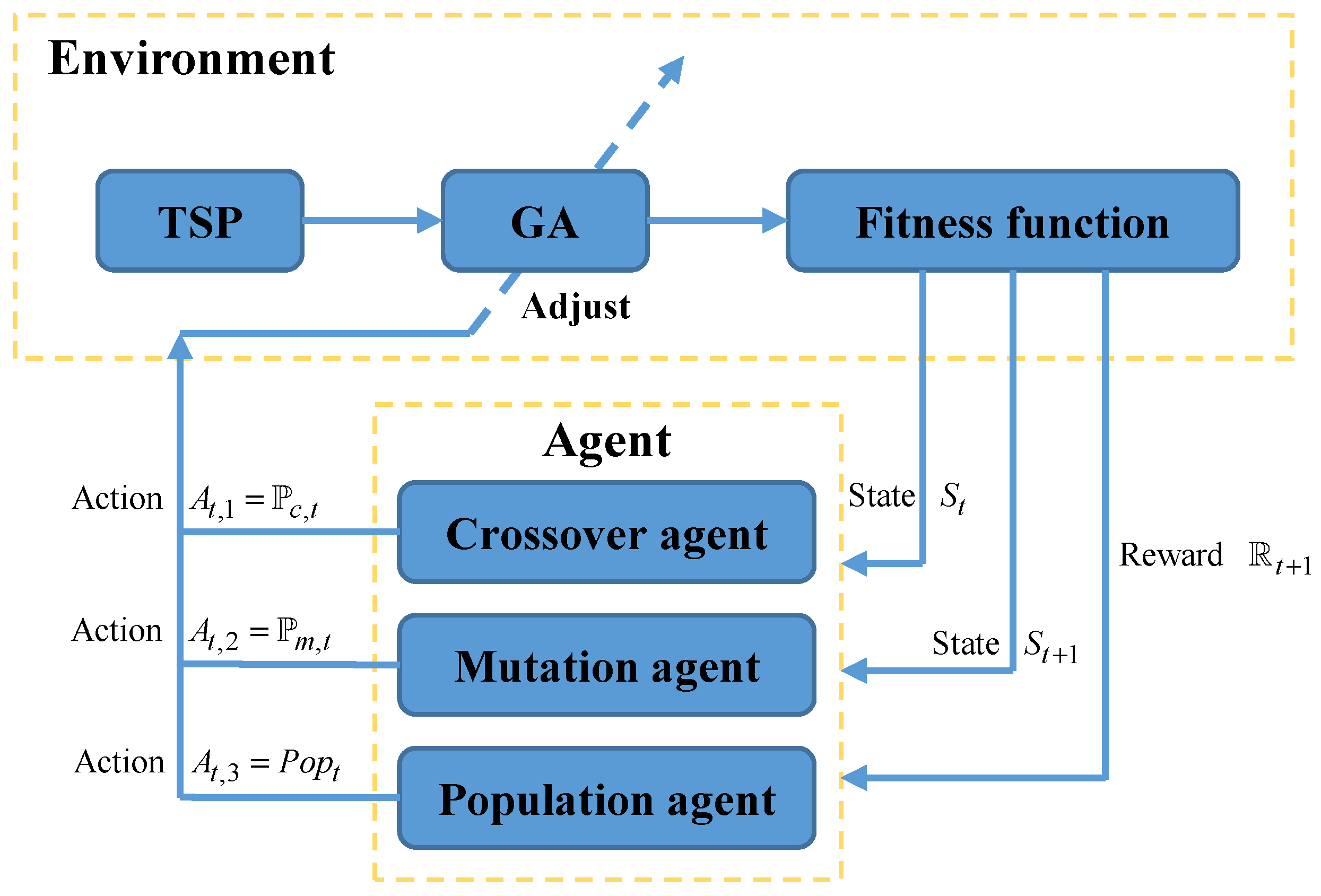
HPAGA is a combinatorial optimization algorithm based on the genetic algorithm and reinforcement learning, which can be utilized to solve the TSP and VTSP problems. It mainly consists of two parts, i.e., GA and RL based on Q-learning. Specifically, the hybrid algorithm possesses satisfactory search capability by virtue of the evolution pattern of the genetic algorithm and is able to dynamically adjust the crucial three hyper-parameters of the genetic algorithm including crossover rate, mutation rate, and population size by use of the reinforcement learning. This adaptive mechanism promotes HPAGA to find the optimal path during the search process more quickly and effectively. Note that the proposed algorithm framework is shown in Figure 4. There are three sub-agents in terms of crossover agent, mutation agent, and population agent, which are responsible for adjusting crossover rate , mutation rate , and population size of GA, respectively. The reinforcement learning process of HPAGA can be divided into five steps as follows:
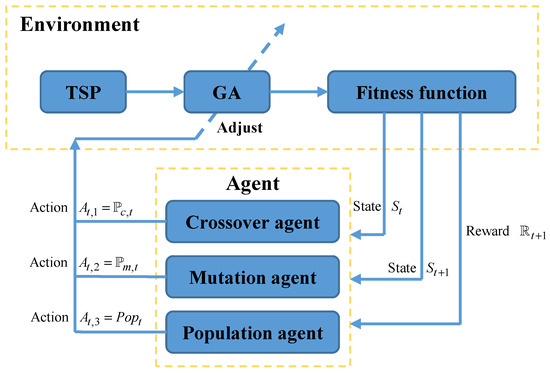
Figure 4.
The framework of HPAGA.
- Step 1: The agent obtains the current state from GA by calculating the population fitness in a designed way. The regulation of the state space formulation will be expatiated in the following passage.
- Step 2: HPAGA selects and executes the corresponding action according to the action selection policy in reinforcement learning and then adjusts the crossover rate, mutation rate, and population size of the current GA.
- Step 3: Execute the GA with the updated crossover rate, mutation rate, and population size to reach the new state .
- Step 4: Calculate the reward from state to state . The reward estimation method will be introduced in the following passage.
- Step 5: Update knowledge of the agent according to states , , reward , and action selection policy by Q-learning.
Through a certain number of reinforcement learning iterations, continuously obtaining states, executing actions, receiving reward feedback, and improving policies, HPAGA optimizes the crossover rate, mutation rate, and population size based on past learning experience to elevate the efficiency of GA.
4.2. Genetic Algorithm
GA imitates the process of selection, crossover, and mutation in biological evolution, and searches different solutions through continuous evolution to find the individual with the highest fitness.
For each individual of the VTSP problem, it is an operating point sequence as
where represents the starting point, denotes the operating point, and means the population size.
The initial population is generated randomly through the initialization module, and each individual represents a feasible operating route. The generated routes are accomplished by randomly shuffling the operating point order. This process ensures that the population contains a considerable number of random routes, providing abundant individuals for subsequent optimization processes.
The objective of the VTSP problem is to find the lowest cumulative dose operating sequence for the human or robot. The fitness is determined by calculating the cumulative dose corresponding to each individual. The formula for calculating the fitness , i.e., the reciprocal of the summation of the cumulative dose corresponding to each individual, is derived by
It is significant to choose an effective crossover operator when solving the VTSP problem. According to the reference [26], the sequential constructive crossover (SCX) operator is utilized to improve the traditional GA. The advantage of the SCX operator is that the generated offspring individuals can relatively retain the high-quality information in the parent individuals, such as superior operating point order and lower cumulative dose, which reduces the possibility of generating unreasonable offspring paths.
4.3. Multi-Parameter Adaptive Reinforcement Learning
The reinforcement learning algorithm based on Q-learning is a value-based learning method, which aims to enable agents to learn how to make optimal behavioral decisions in specific environments. The Q-learning algorithm mainly includes several key concepts, i.e., Q-value table, state, action, reward, and policy.
The Q-value table is utilized to record the Q-values learned by the agent, where each row represents a state, each column represents an action, and all values in the initial Q-value table are zero. The Q-value represents the benefit of selecting the corresponding action based on the current state. The Q-value can be calculated based on the current state , the next state , the selected current action , the next prospective action , and the next reward , which is expressed as
where represents the Q-value of selecting action under state , represents the learning rate, represents the reward obtained from state to state , is the discount factor, and represents the maximum Q-value in the row of state in the Q-value table.
With respect to the proposed HPAGA, the state of the agent consists of three factors including the relative fitness of the current population’s best individuals , the relative average fitness of the population , and the relative diversity of the population . Therefore, the state for HPAGA is defined as
where the sub-states are described as
Note that represents the i th individual of the initial generation, denotes the i th individual of p th generation, represents all individuals of the initial generation, represents all individuals of p th generation, is the population size of p th generation, and represents the population size of the initial generation. Besides, , , and are positive weights which adjust the importance of three different fitness factors and meet . For example, in the proposed HPAGA, the weights are set to be , , and , respectively.
According to the aforementioned state calculation regulation, the state space will be continuous. In order to ensure a constructible Q-table and a satisfactory convergence speed, the state space is designedly converted to a discrete one. Concretely, the state space is divided into a certain number of intervals. If the value of belongs to one interval, will be assigned by the characteristic value of this interval. For instance, the state space is divided into 20 intervals. When , ; when , ; until , .
With respect to the action space, the ranges of crossover rate, mutation rate, and population size are divided into a certain number of intervals so as to construct the discrete actions for each agent. The range of crossover rate is from to , the range of mutation rate is from to , and the range of population size is from 50 to 500. Note that the number of intervals can be chosen according to the performance of the algorithm or experiences.
The state transition reward function is designed specifically for each reinforcement learning agent based on the best individual fitness and the population’s average fitness. Therefore, the reward function for the crossover agent is constructed by
The reward function for the mutation agent is designed by
Besides, the reward function for the population agent is a weighted combination of and as
In this paper, the -greedy strategy is adopted to select actions. The agent selects the action with the best Q-value via a probability of based on known information and selects exploration with a probability of , namely, a random action. The action selection strategy is expressed as
where is a threshold value.
5. Experimental Results
In this section, experiments on different conventional TSP instances are conducted to verify the superiority of the proposed HPAGA.
5.1. Experimental Setup
The test instances in this study are chosen from the widely-used TSP instance library TSPLIB [27]. To demonstrate the effectiveness of our algorithm on datasets of different scales, six instances with different scales, namely att48, berlin52, st70, eil76, gr96, and eil101, are selected. Note that all of them utilize the two-dimensional Euclidean distance metric. With respect to the software and hardware configurations, Python version 3.7.16 is employed for this experiment, and the experimental computer consists of an Intel Core i5-9300H processor, 8 GB of RAM, and Windows 10 operating system.
An overly large population size can result in an unmanageable computational load, while a too-small population may suffer from insufficient diversity. To strike a balance, the initial population size for this task is arbitrarily set at 1000. Too low a crossover rate hinders the proper inheritance of beneficial genes, whereas an excessively high mutation rate can compromise population quality. Consequently, based on empirical observations, the initial crossover rate is set at and the initial mutation rate at for this task. Drawing from reference [28], the corresponding reinforcement learning parameters are established with a learning rate of , a discount rate of , and a greedy rate of , aiming to foster a synergy between exploration and exploitation for effective and optimized learning.
5.2. Ablation Experiment
To verify the effectiveness of the HPAGA in adjusting different hyper-parameters of GA, the ablation experiment is conducted. A comparative study is executed among HPAGA, HPAGA_c (only dynamically adjusting the crossover rate), HPAGA_m (only dynamically adjusting the mutation rate), HPAGA_p (only dynamically adjusting the population size), HPAGA_cm (dynamically adjusting both the crossover and mutation rates), and GA (without applying RL). Each method runs 30 independent epochs with 1000 generations in each epoch on the aforementioned four selected instances. To ensure a fair comparison, the initial population of each dataset was generated with the same random seed so as to produce convincing results.
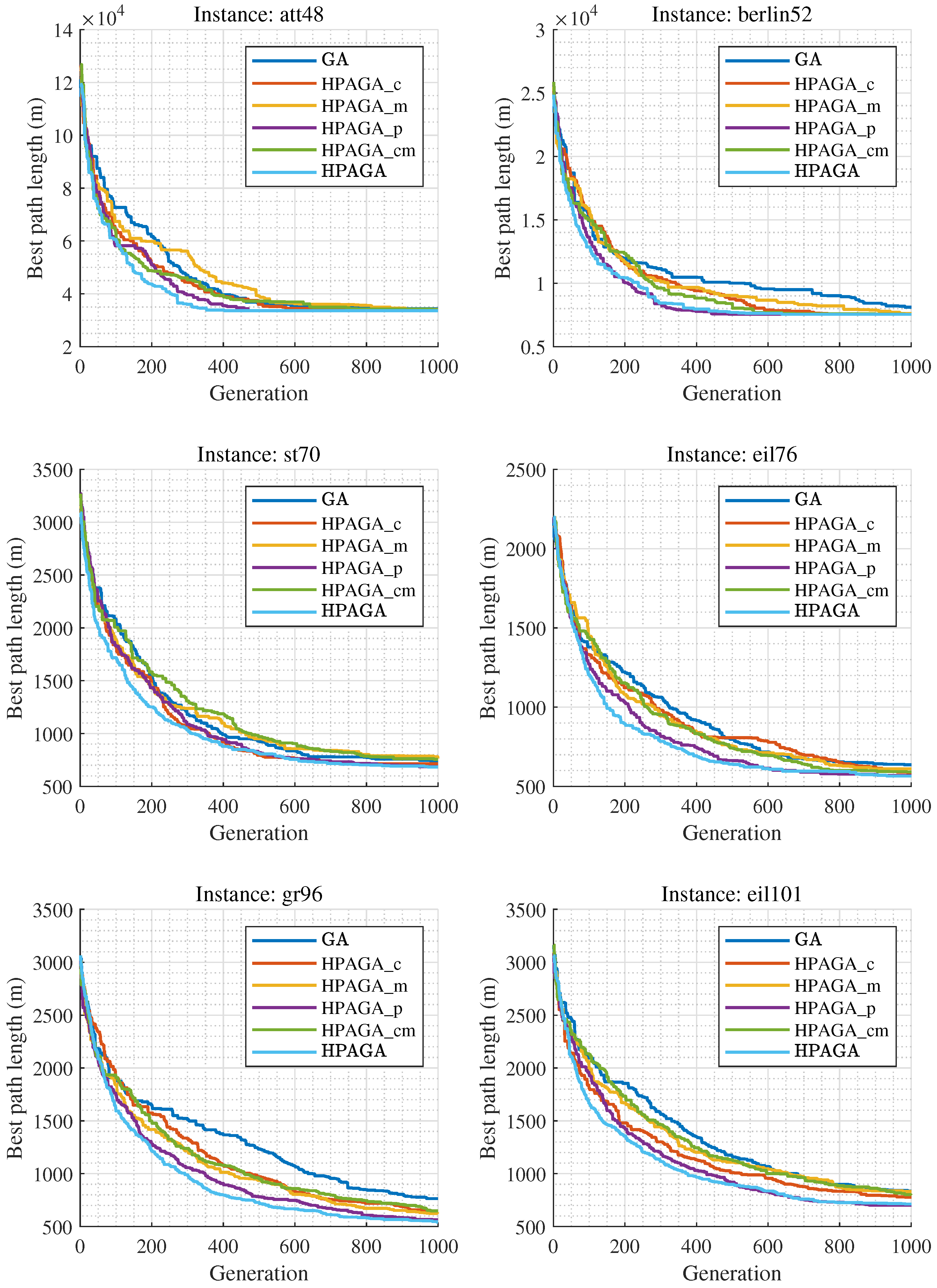
Table 1 shows the results of each method on the four TSP instances. Note that the words Best, Worst, and Mean represent the minimum, maximum, and average cost of the traveling salesman in 30 independent epochs for each algorithm, respectively. Std represents the standard deviation of these 30 independent epochs. Num_c represents the number of crossover operations, and Num_m represents the number of mutation operations for the corresponding algorithm. Figure 5 shows the convergence curves of the best solutions obtained by the six different algorithms on four TSP datasets over 1000 generations in 30 independent epochs. The discussion of the ablation study is expounded from five aspects:

Table 1.
The results of the ablation experiment.
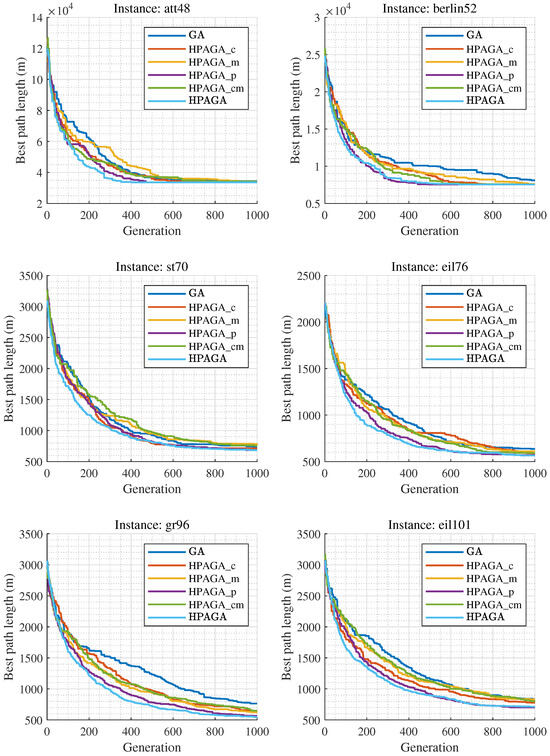
Figure 5.
Convergence curves of the six methods in the ablation experiments.
- Analyzing the comparative results of HPAGA_c and GA, HPAGA_c obtains lower average costs than GA all over the four instances, with fewer crossover operations. This indicates that dynamically adjusting the crossover rate alone can propagate superior genes and improve the overall fitness of the population, then enhancing the performance of GA.
- Based on the comparative results of HPAGA_m and GA on the four instances, HPAGA_m accomplishes lower minimum costs than GA on att48, berlin52, and eil101 instances, with a fewer number of mutation operations. However, on the st70 instance, HPAGA_m’s minimum and average costs are worse than GA’s. This implies that dynamically adjusting the mutation rate alone can increase population diversity and enhance genetic algorithm performance, but it can also have potentially negative effects due to the influence of mutated individuals in the population.
- Reviewing the comparative results of HPAGA_p and GA, HPAGA_p acquires lower minimum and average costs than GA in all instances, which demonstrates that the population size agent is effective in improving the classical GA.
- Examining the results of HPAGA_cm, HPAGA_cm realizes lower minimum and average costs than GA, with fewer crossover and mutation operations. Compared to HPAGA_m, HPAGA_cm reaches a better balance while dynamically adjusting both crossover and mutation rates, promoting population diversity and mitigating the potential negative effects of mutated individuals by propagating superior genes.
- Among all the comparative algorithms, HPAGA achieves the best performance in most comparative indicators, including the lowest costs and the smallest standard deviation. Note that Figure 5 demonstrates that HPAGA also has the fastest convergence speed.
The ablation study adheres to the principle of variable control. The GA backbones in the experiment have equivalent performance in solving the TSP. Therefore, it is evident that the RL component significantly enhances the TSP-solving performance.
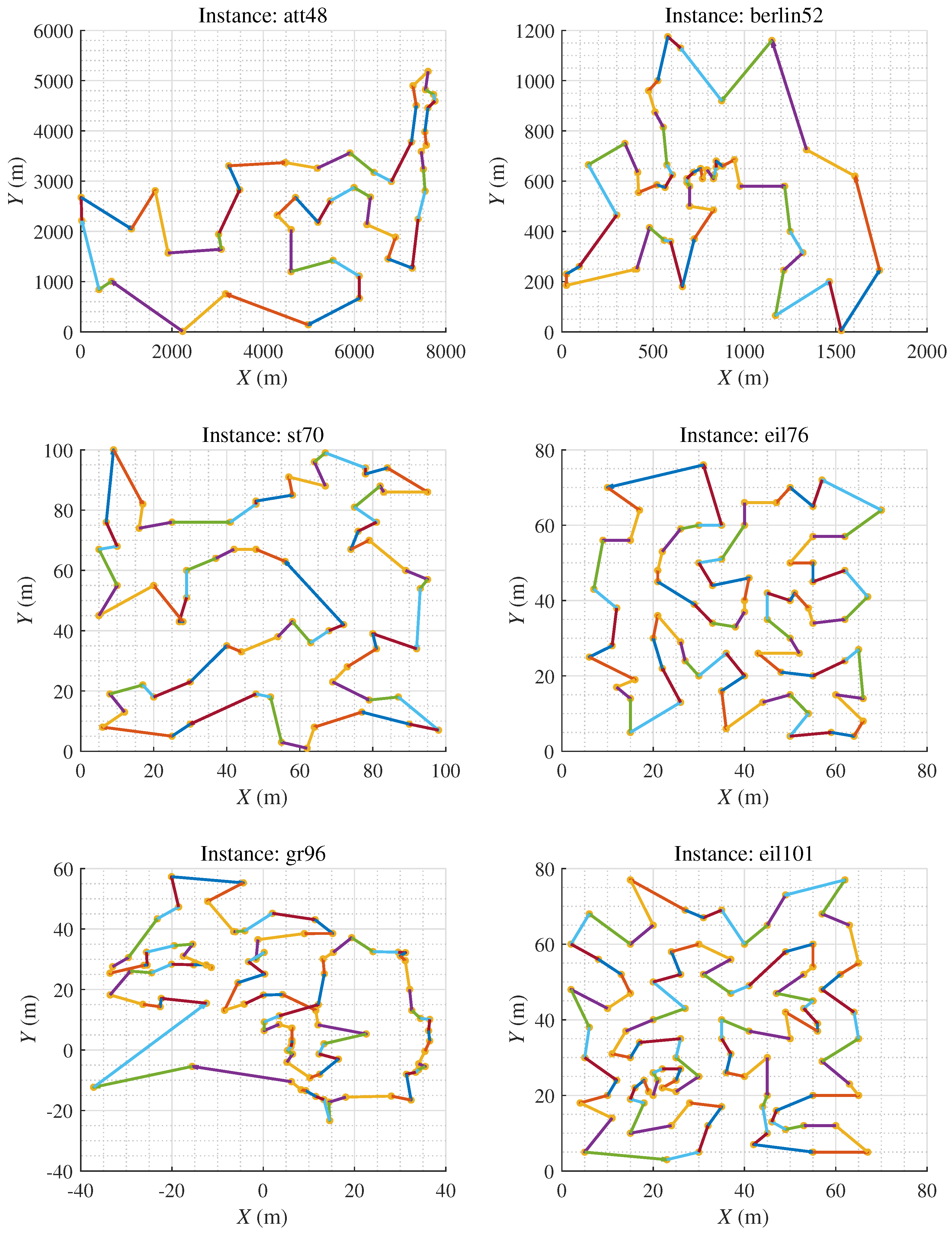
According to the ablation experiment, it is concluded that in the case of fixed population size, dynamically adjusting the crossover and mutation rates via reinforcement learning strategy assists the hybrid algorithm in obtaining better results than classical GA with fewer genetic operations. In a situation of dynamic adjustments to population size, the appending crossover agent and mutation agent help HPAGA realize comparable or better results than HPAGA_p with fewer genetic operations in the majority of instances. In summary, the comprehensive dynamic adjustment mechanism of HPAGA is the most effective, which significantly improves the performance and stability of GA. As shown in Figure 6, it is demonstrated that in virtue of the proposed HPAGA, the computed path is feasible and basically optimal intuitively.
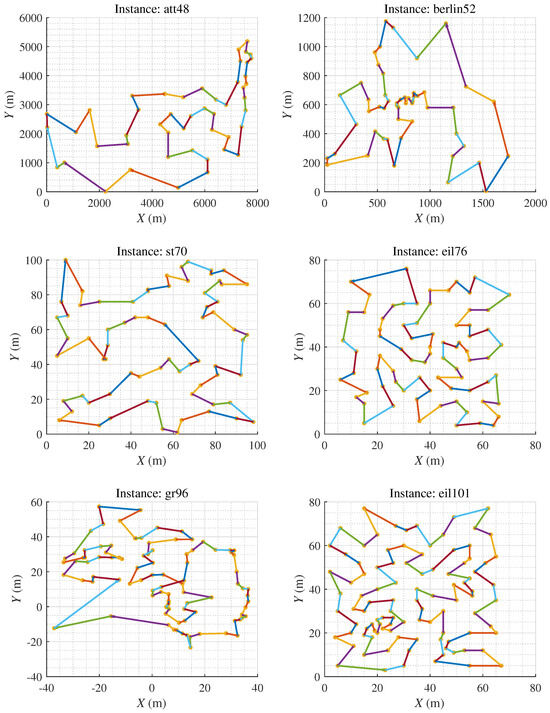
Figure 6.
The figure represents the minimum cost path obtained by our HPAGA method in 30 experimental trials.
5.3. Comparative Analysis
To verify the performance of the HPAGA algorithm, the comparative analysis of the optimization performance is conducted with several approximate algorithms including ACO, particle swarm optimization (PSO), black hole algorithm (BH), and dragonfly algorithm (DA). The comparative results are listed in Table 2. Note that the computed best solutions of the comparative algorithms source from [29], meanwhile, the configurations of the comparative algorithms are recorded in [30,31].
Table 2.
The comparative results of different methods.
Based on the comparative results, it can be concluded that the proposed HPAGA algorithm can bridge the remarkable gap between traditional GA algorithms and other evolutionary algorithms. The reason is that HPAGA is an adaptive algorithm involving population fitness, which promotes itself to adjust the parameters to keep on exploring the optimal solutions. However, when the city scale increases, the performance is limited by the number of learning iterations. In the future, more efficient learning tricks will be studied further to improve the capability of solving huge-scale problems.
5.4. Limitations
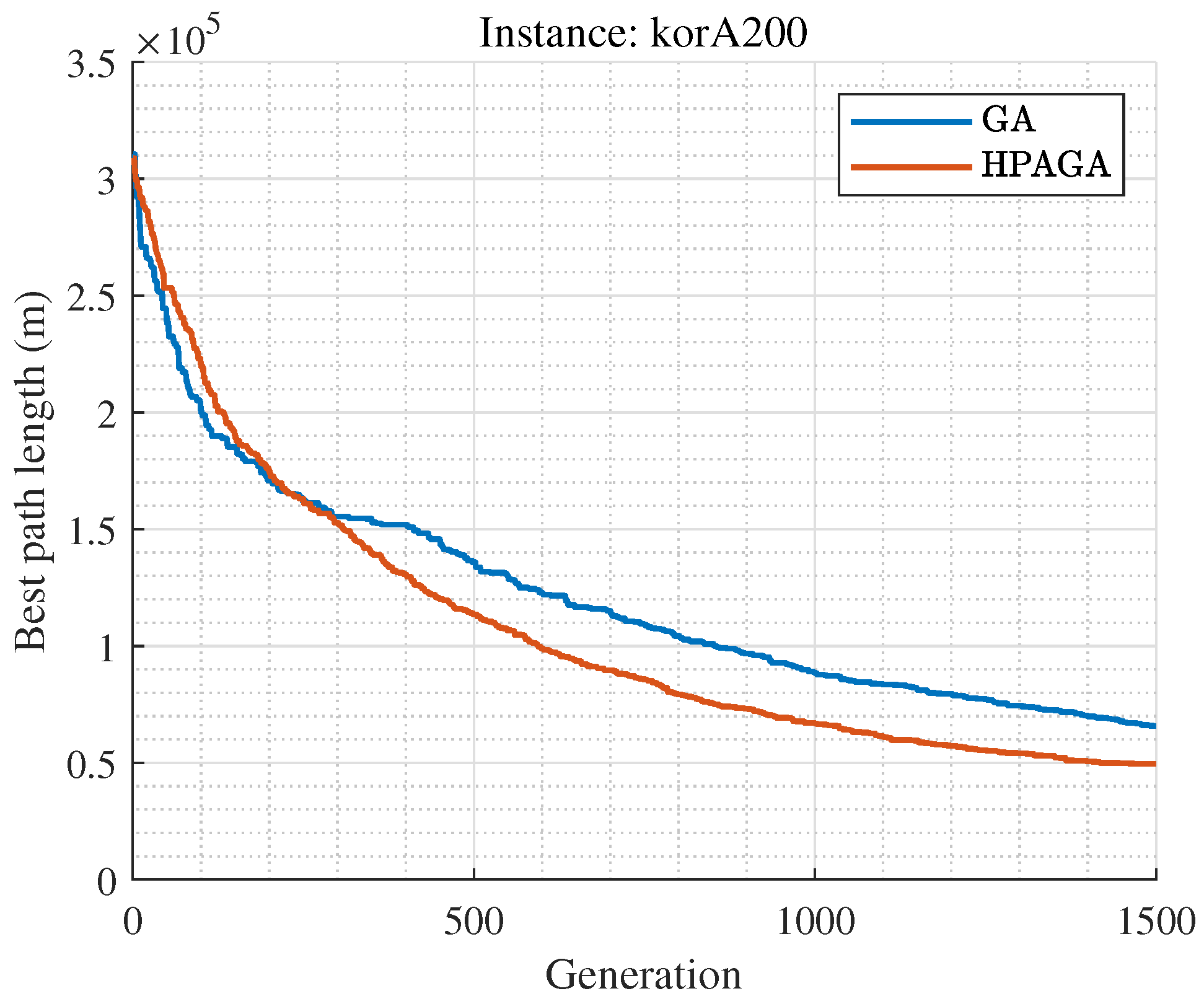
The HPAGA algorithm proposed in this manuscript performs well in terms of convergence on small-scale Traveling Salesman Problem datasets such as att48, berlin52, st70, eil76, st70, gr96, and eil101, during 1000 iterations of learning. With respect to the large-scale dataset, such as korA200, it is apparent that the performance of HPAGA is superior to the standard GA as shown in Figure 7. However, due to the limitation of the number of iterations, its convergence performance is suboptimal on large-scale datasets. It is shown that the HPAGA algorithm has not yet converged after approximately 1500 iterations on the korA200 dataset, with the fitness still decreasing. In the future, more effective learning techniques will be investigated to improve the capability of solving large-scale problems. Noticeably, the proposed HPAGA might not be the best performer among all the optimization algorithms to our best knowledge, but introduces a novel and valuable hybrid concept to enhance the existing algorithm.
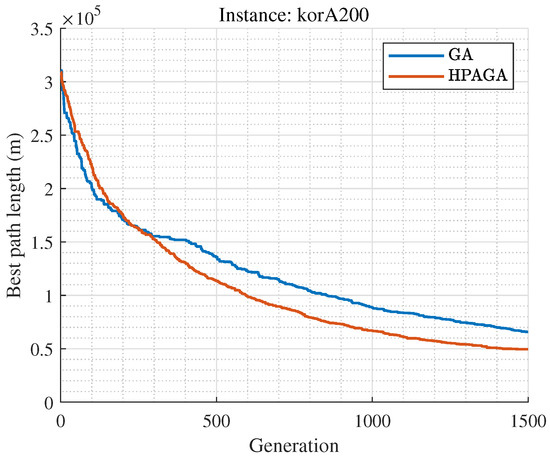
Figure 7.
Convergence curves of the GA and HPAGA for korA200.
6. Case Study in Simulated Radioactive Scenario
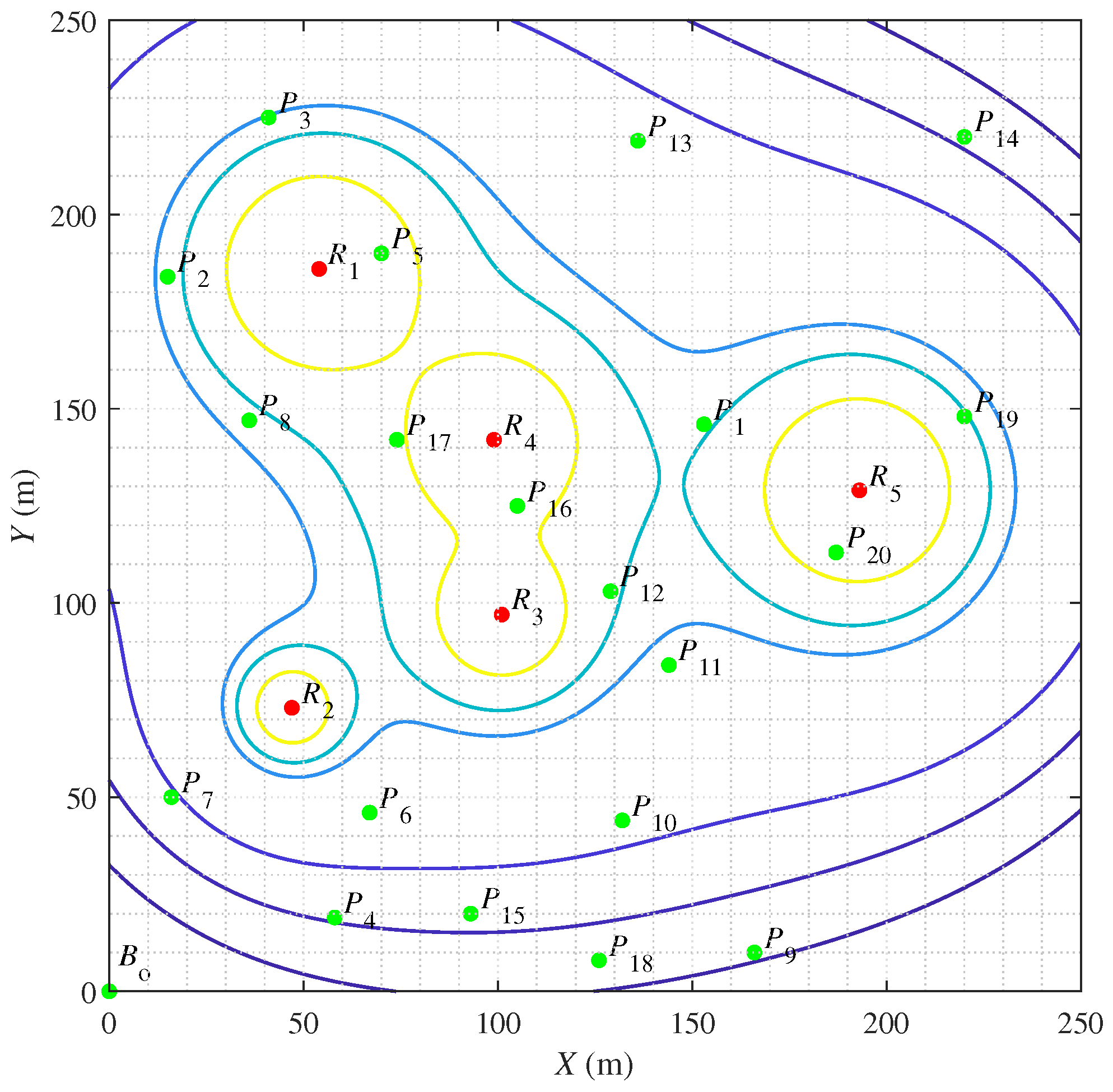
In this paper, a case study in the simulated radioactive environment is conducted to demonstrate the feasibility of the proposed HPAGA for the multi-objective operating planning problem. The configuration of the simulated environment is illustrated in Figure 8. Suppose that there are five radiation sources with the radiation dose rate of , , , , and , respectively, dispersedly located at the coordinates of , , , , and . Note that the contour lines represent the positions with the same value of radiation dose rate. The number of operating points is set as 20. It is different from [6] that the operating difficulty of each operating point is taken into consideration, which is measured by the number of hours consumed at each point. Besides, at is the starting point. The parameters of these twenty operating points are listed in Table 3. The cumulative dose matrix is defined to describe the cumulative dose between any two points. The value of each element of the cumulative dose matrix in this case is computed according to (3). Apparently, on account of the operating difficulty, the cumulative dose matrix is asymmetric. The case study becomes an asymmetric VTSP.
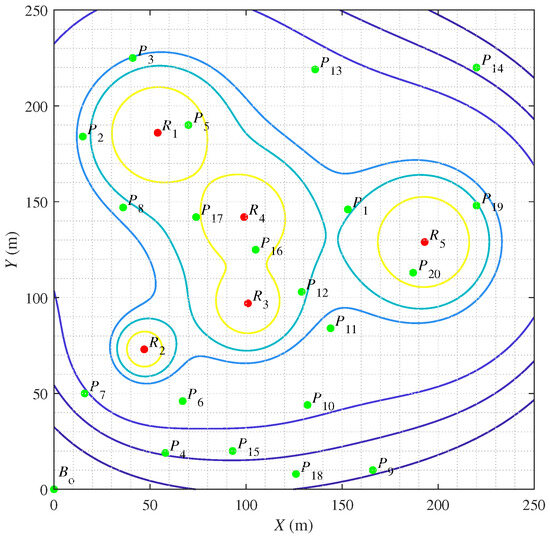
Figure 8.
The configuration of the simulated radioactive environment.
Table 3.
The configuration parameters of the operating points.
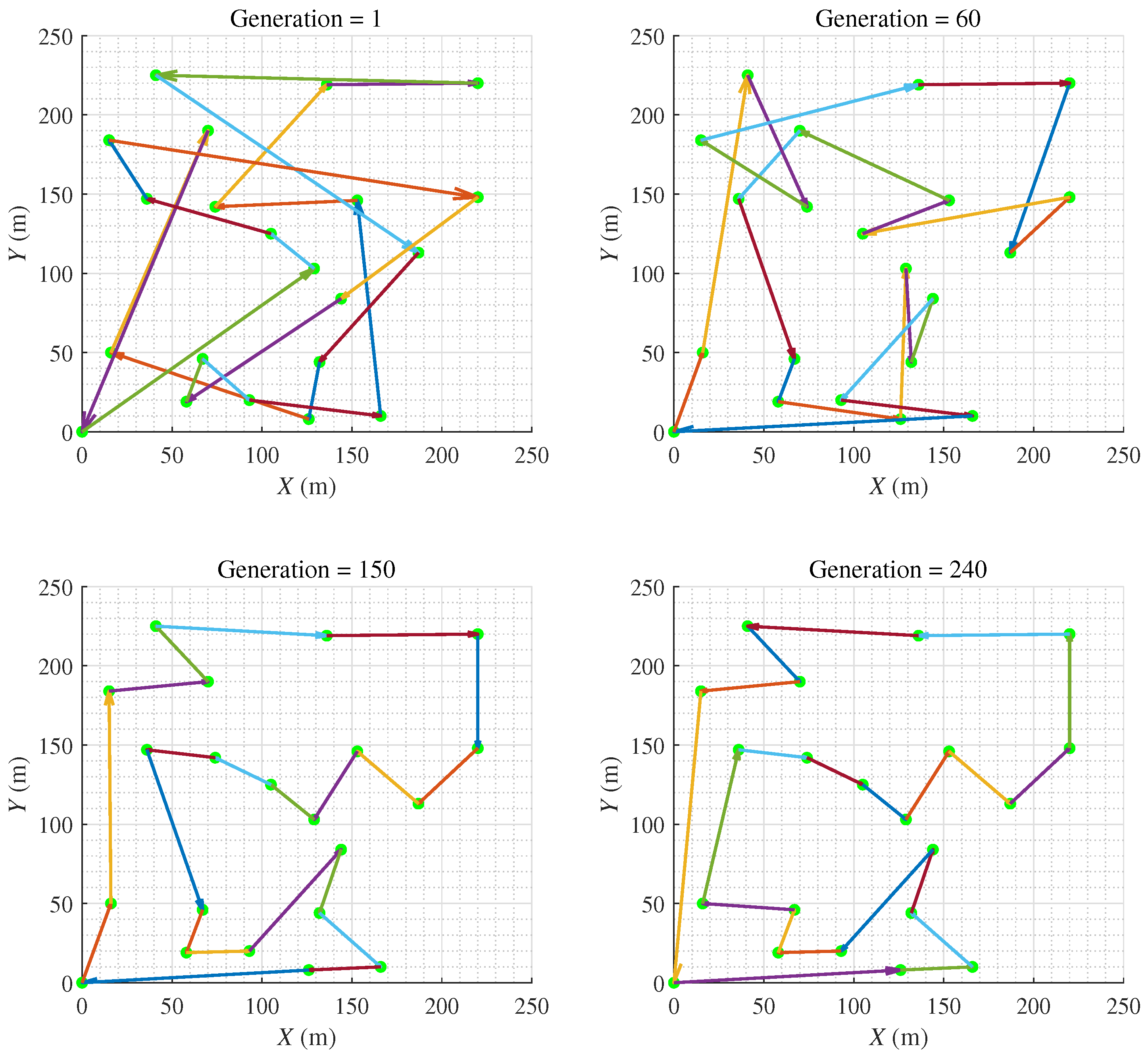
HPAGA is utilized to solve the asymmetric VTSP, the searching procedure for the optimal operating sequence with the increasing generations is exhibited in Figure 9. Note that after the iteration of less than 240 generations, the algorithm has converged to an optimal solution. The results of this simulated case study demonstrate the effectiveness of the proposed HPAGA in solving the multi-objective operating planning problem in the radioactive environment.
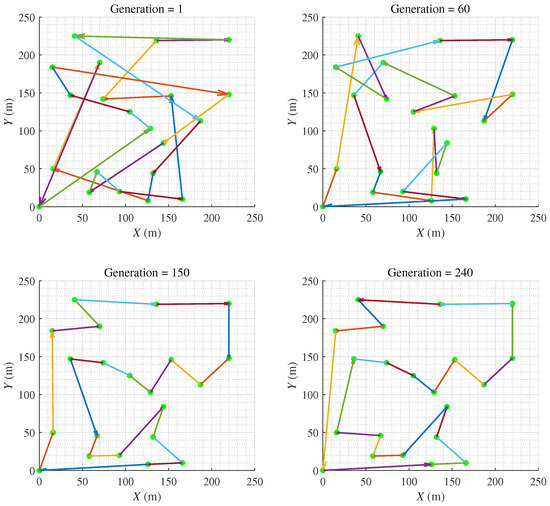
Figure 9.
The evolutionary procedure of the HPAGA.
7. Conclusions and Future Work
This paper introduces a novel multi-objective operation planning model for radioactive environments, accounting for difficulty levels at each operating point to impact operation times and cumulative radiation dose. With respect to the newly designed radiation dose model, a hybrid algorithm framework is proposed that integrates bio-inspired optimization with reinforcement learning, enabling the dynamic adjustment of GA hyper-parameters for efficient VTSP solutions. Noticeably, comparative studies showcase the superior performance of HPAGA against classical evolutionary algorithms for various TSP cases. Furthermore, the case study in the simulated radioactive environment implies the application prospect of HPAGA.
In the future, more efficient learning tricks of the RL part and fresher ideas for hybrid algorithms will be investigated further. Besides, the improved algorithm will be applied to intelligent robots for real-world nuclear scenarios.
Author Contributions
Conceptualization, S.K. and F.W.; methodology, S.K.; software, H.L.; validation, S.K., J.S. and J.Y.; formal analysis, H.L. and W.Z.; investigation, F.W., W.Z. and J.W.; resources, J.Y.; data curation, H.L. and J.W.; writing—original draft preparation, S.K.; writing—review and editing, S.K.; visualization, S.K.; supervision, H.L.; project administration, J.Y.; funding acquisition, J.Y. and S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by Beijing Natural Science Foundation under Grant 4242038, in part by the National Natural Science Foundation of China under Grant 62203015, Grant 62233001, Grant 62203436, and Grant 62273351.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The data generated during the current study are available from the corresponding author upon reasonable request.
Conflicts of Interest
Author Fang Wu was employed by the company SPIC Nuclear Energy Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Rehm, T.E. Advanced nuclear energy: The safest and most renewable clean energy. Curr. Opin. Chem. Eng. 2023, 39, 100878. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, Y.; Luo, R.; Zou, S. Hybrid IACO-A*-PSO optimization algorithm for solving multiobjective path planning problem of mobile robot in radioactive environment. Prog. Nucl. Energy 2023, 159, 104651. [Google Scholar] [CrossRef]
- Pentreath, R.J. Radiological protection, radioecology, and the protection of animals in high-dose exposure situations. J. Environ. Radioact. 2023, 270, 107270. [Google Scholar] [CrossRef]
- Adibel, J.O.; Liu, Y.; Ayodeji, A.; Awodi, N.J. Path planning in nuclear facility decommissioning: Research status, challenges, and opportunities. Nucl. Eng. Technol. 2021, 53, 3505–3516. [Google Scholar] [CrossRef]
- Wang, Z.; Cai, J. The path-planning in radioactive environment of nuclear facilities using an improved particle swarm optimization algorithm. Nucl. Eng. Des. 2018, 326, 79–86. [Google Scholar] [CrossRef]
- Xie, X.; Tang, Z.; Cai, J. The multi-objective inspection path-planning in radioactive environment based on an improved ant colony optimization algorithm. Prog. Nucl. Energy 2022, 144, 104076. [Google Scholar] [CrossRef]
- Wu, Z.; Yin, Y.; Liu, J.; Zhang, D.; Chen, J.; Jiang, W. A novel path planning approach for mobile robot in radioactive environment based on improved deep Q network algorithm. Symmetry 2023, 15, 2048. [Google Scholar] [CrossRef]
- Liu, Y.; Li, M.; Xie, C.; Peng, M.; Wang, S.; Chao, N.; Liu, Z. Minimum dose method for walking-path planning of nuclear facilities. Ann. Nucl. Energy 2015, 83, 161–171. [Google Scholar] [CrossRef]
- Chao, N.; Liu, Y.; Xia, H.; Ayodeji, A.; Bai, L. Grid-based RRT* for minimum dose walking path-planning in complex radioactive environments. Ann. Nucl. Energy 2018, 115, 73–82. [Google Scholar] [CrossRef]
- Zhang, D.; Luo, R.; Yin, Y.; Zou, S. Multi-objective path planning for mobile robot in nuclear accident environment based on improved ant colony optimization with modified A*. Nucl. Eng. Technol. 2023, 55, 1838–1854. [Google Scholar] [CrossRef]
- Lee, M.; Jang, S.; Cho, W.; Lee, J.; Lee, C.; Kim, S.H. A proposal on multi-agent static path planning strategy for minimizing radiation dose. Nucl. Eng. Technol. 2024, 56, 92–99. [Google Scholar] [CrossRef]
- Helsgaun, K. An effective implementation of the Lin-Kernighan traveling salesman heuristic. Eur. J. Oper. Res. 2000, 126, 106–130. [Google Scholar] [CrossRef]
- Toaza, B.; Esztergár-Kiss, D. A review of metaheuristic algorithms for solving TSP-based scheduling optimization problems. Eur. J. Oper. Res. 2023, 148, 110908. [Google Scholar] [CrossRef]
- Applegate, D.L.; Bixby, R.E.; Chvatal, V.; Cook, W.J. The Traveling Salesman Problem: A Computational Study; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Pan, X.; Jin, Y.; Ding, Y.; Feng, M.; Zhao, L.; Song, L.; Bian, J. H-TSP: Hierarchically solving the large-scale travelling salesman problem. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Zheng, J.; He, K.; Zhou, J.; Jin, Y.; Li, C. Reinforced Lin–Kernighan–Helsgaun algorithms for the traveling salesman problems. Knowl.-Based Syst. 2023, 260, 110144. [Google Scholar] [CrossRef]
- Valdez, F.; Moreno, F.; Melin, P. A comparison of ACO, GA and SA for solving the TSP problem. Hybrid Intell. Syst. Control. Pattern Recognit. Med. 2020, 181–189. [Google Scholar]
- Bao, X.; Wang, G.; Xu, L.; Wang, Z. Solving the min-max clustered traveling salesmen problem based on genetic algorithm. Biomimetics 2023, 8, 238. [Google Scholar] [CrossRef] [PubMed]
- Panwar, K.; Deep, K. Transformation operators based grey wolf optimizer for travelling salesman problem. J. Comput. Sci. 2021, 55, 101454. [Google Scholar] [CrossRef]
- Mzili, T.; Mzili, I.; Riffi, M.E. Artificial rat optimization with decision-making: A bio-inspired metaheuristic algorithm for solving the traveling salesman problem. Decis. Mak. Appl. Manag. Eng. 2023, 6, 150–176. [Google Scholar] [CrossRef]
- Poornima, B.S.; Sarris, I.E.; Chandan, K.; Nagaraja, K.V.; Kumar, R.S.V.; Ben Ahmed, S. Evolutionary computing for the radiative–convective heat transfer of a wetted wavy fin using a genetic algorithm-based neural network. Biomimetics 2023, 8, 574. [Google Scholar] [CrossRef]
- Mahmoudinazlou, S.; Kwon, C. A hybrid genetic algorithm for the min–max multiple traveling salesman problem. Comput. Oper. Res. 2024, 162, 106455. [Google Scholar] [CrossRef]
- Zheng, J.; Zhong, J.; Chen, M.; He, K. A reinforced hybrid genetic algorithm for the traveling salesman problem. Comput. Oper. Res. 2023, 157, 106249. [Google Scholar] [CrossRef]
- Chen, R.; Yang, B.; Li, S.; Wang, S. A self-learning genetic algorithm based on reinforcement learning for flexible job-shop scheduling problem. Comput. Ind. Eng. 2020, 149, 106778. [Google Scholar] [CrossRef]
- Mazyavkina, N.; Sviridov, S.; Ivanov, S.; Burnaev, E. Reinforcement learning for combinatorial optimization: A survey. Comput. Oper. Res. 2021, 134, 105400. [Google Scholar] [CrossRef]
- Dou, X.; Yang, Q.; Gao, X.; Lu, Z.; Zhang, J. A comparative study on crossover operators of genetic algorithm for traveling salesman problem. In Proceedings of the 15th International Conference on Advanced Computational Intelligence (ICACI), Seoul, Republic of Korea, 6–9 May 2023. [Google Scholar]
- Reinelt, G. TSPLIB-A traveling salesman problem library. ORSA J. Comput. 1991, 3, 376–384. [Google Scholar] [CrossRef]
- Alipour, M.M.; Razavi, S.N.; Derakhshi, M.R.F.; Balafar, M.A. A hybrid algorithm using a genetic algorithm and multiagent reinforcement learning heuristic to solve the traveling salesman problem. Neural Comput. Appl. 2018, 30, 2935–2951. [Google Scholar] [CrossRef]
- Yasear, S.A.; Ku-Mahamud, K.R. Fine-tuning the ant colony system algorithm through Harris’s hawk optimizer for travelling salesman problem. Int. J. Intell. Eng. Syst. 2021, 14, 136–145. [Google Scholar] [CrossRef]
- Hammouri, A.I.; Samra, E.T.A.; Al-Betar, M.A.; Khalil, R.M.; Alasmer, Z.; Kanan, M. A dragonfly algorithm for solving traveling salesman problem. In Proceedings of the IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2018. [Google Scholar]
- Hatamlou, A. Solving travelling salesman problem using black hole algorithm. Soft Comput. 2018, 22, 8167–8175. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).