
Operating Room Usage Time Estimation with Machine Learning Models



Abstract
:1. Introduction
1.1. Background
1.2. Previous Studies
1.3. Aim of This Study
2. Materials and Methods
2.1. Data Source
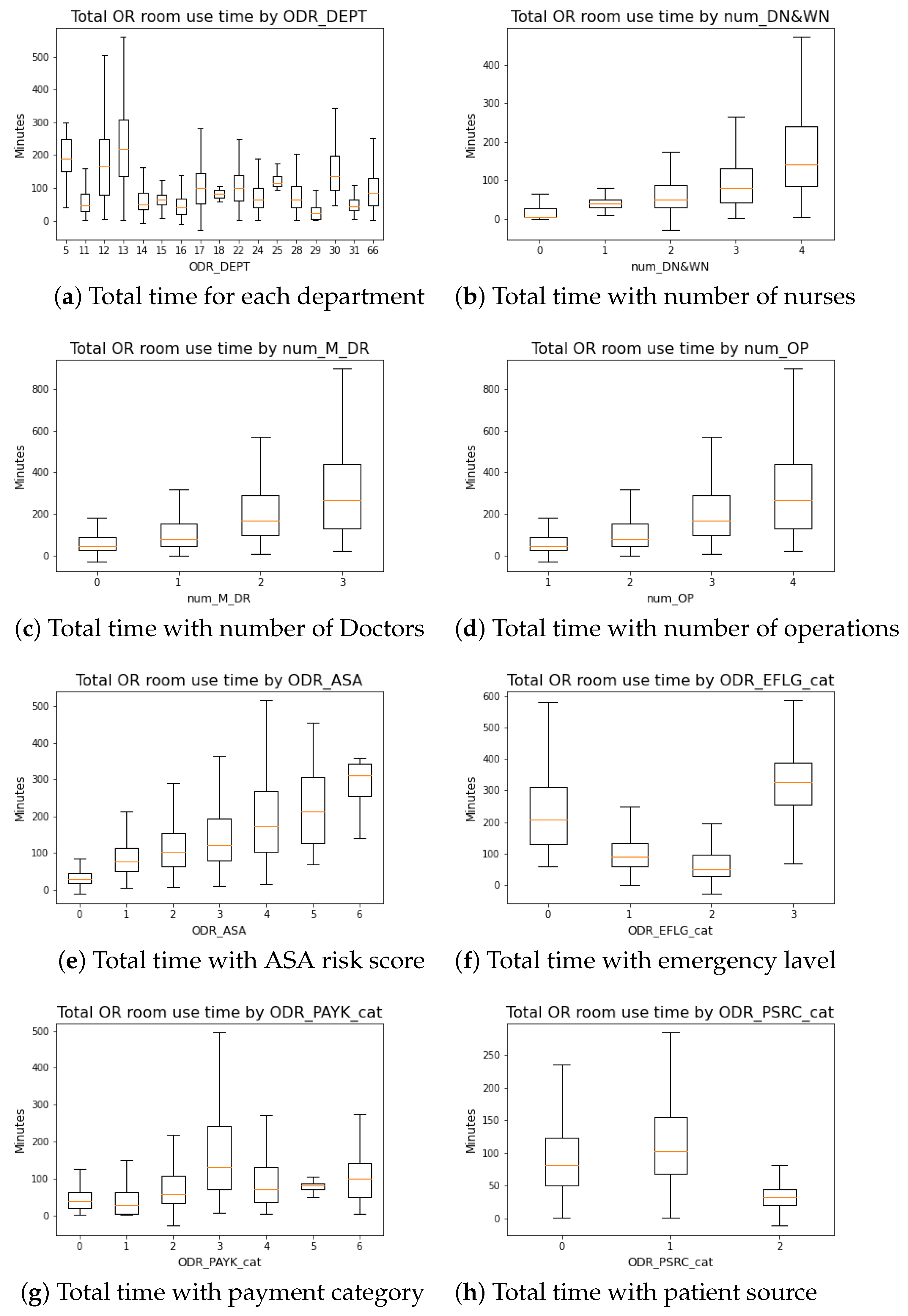
2.2. Data Preprocessing
- ODR_DEPT: Department’s ID;
- ODR_WOUD: Patient’s wound cleanness;
- ODR_ASA: Patient’s anesthesia risk;
- num_M_DR: Total number of doctors will be partaking the surgery;
- num_DN&WN: Total number of nurses (scrub nurse and circulation nurse) will be partaking in the surgery;
- num_OP: Total number of planned procedures;
- Day_since_last: Number of days since patient’s last surgery;
- ODR_PAYK_cat: Patient payment category (Health insurance status);
- ODR_PSRC_cat: Patient source category (Inpatient, Outpatient, Emergency room );
- ODR_EFLG_cat: Category (if it is emergency surgery);
- ODR_OP_1_cat: Procedures id of the first procedure to be performed;
- ODR_OP_2_cat: Procedures id of the second procedure to be performed;
- ODR_OP_3_cat: Procedures id of the third procedure to be performed;
- ODR_OP_4_cat: Procedures id of the forth procedure to be performed;
- ODR_Total_time: Total time (in minutes) spent in OR room.
2.3. Methods
3. Results
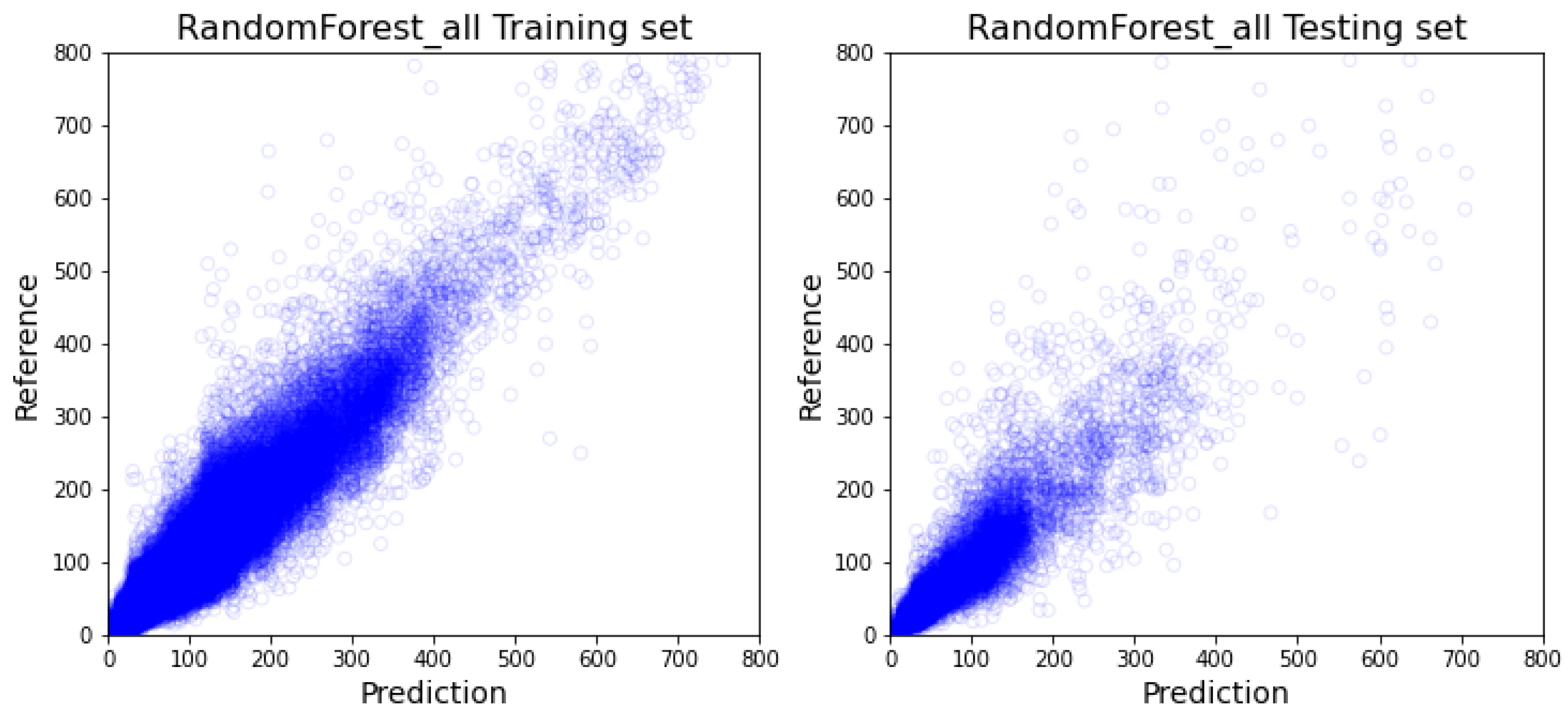
3.1. All-Inclusive Model Results
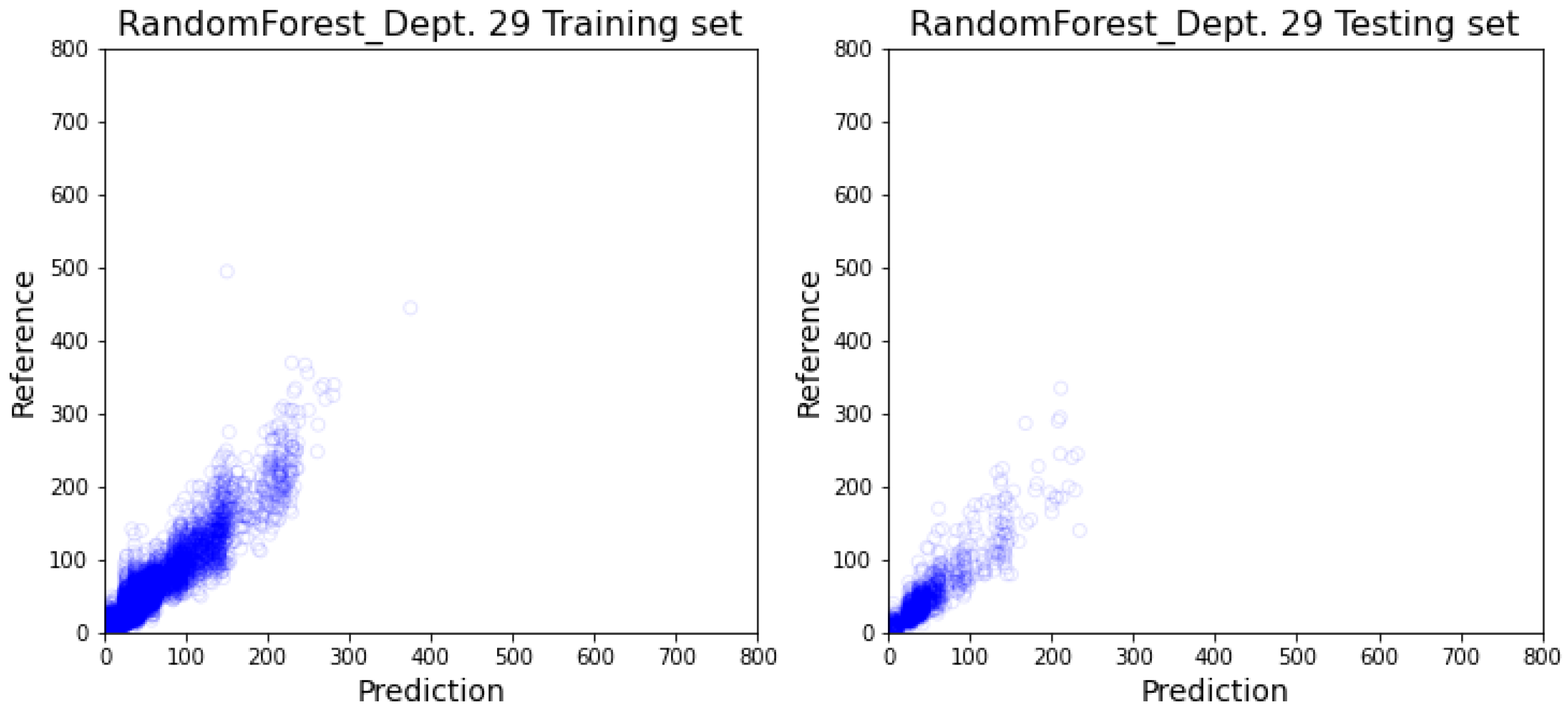
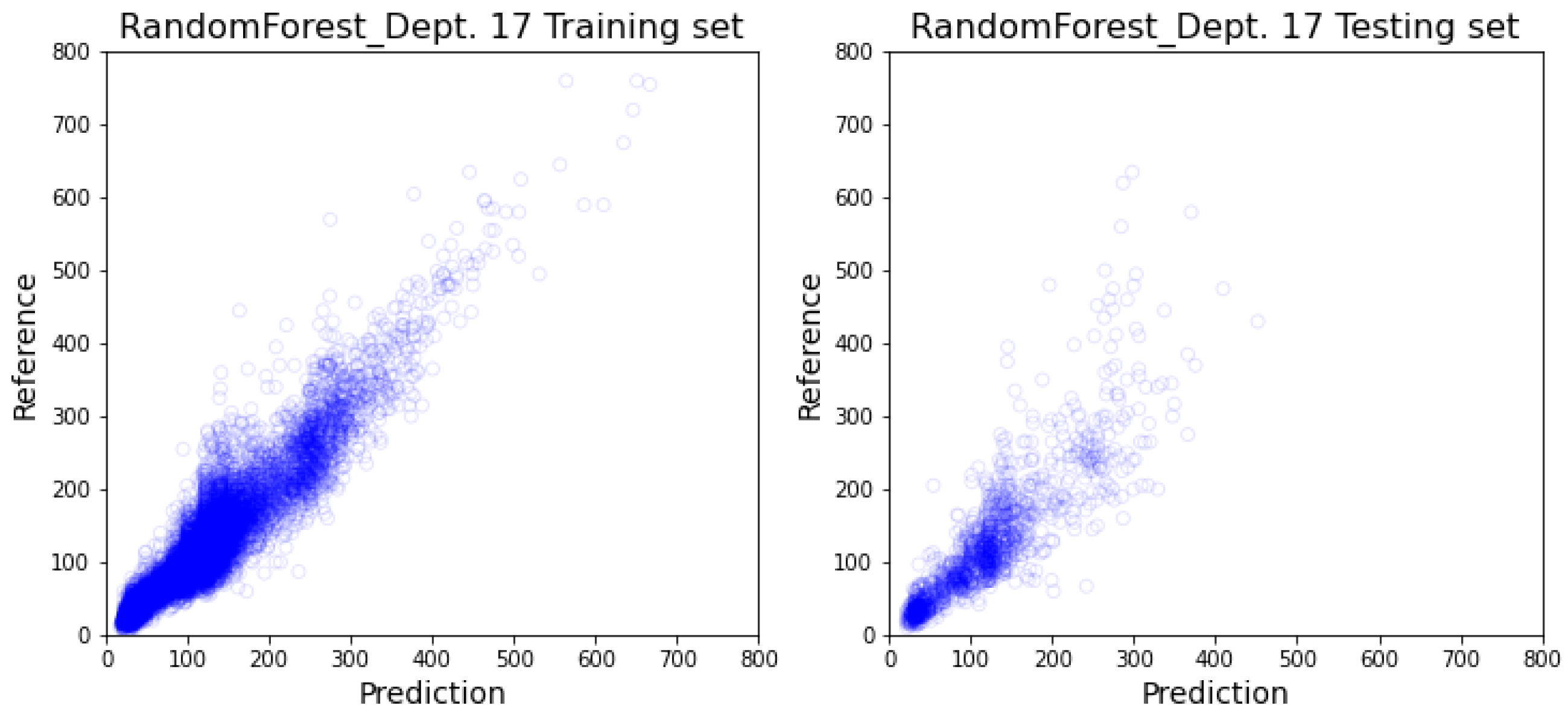
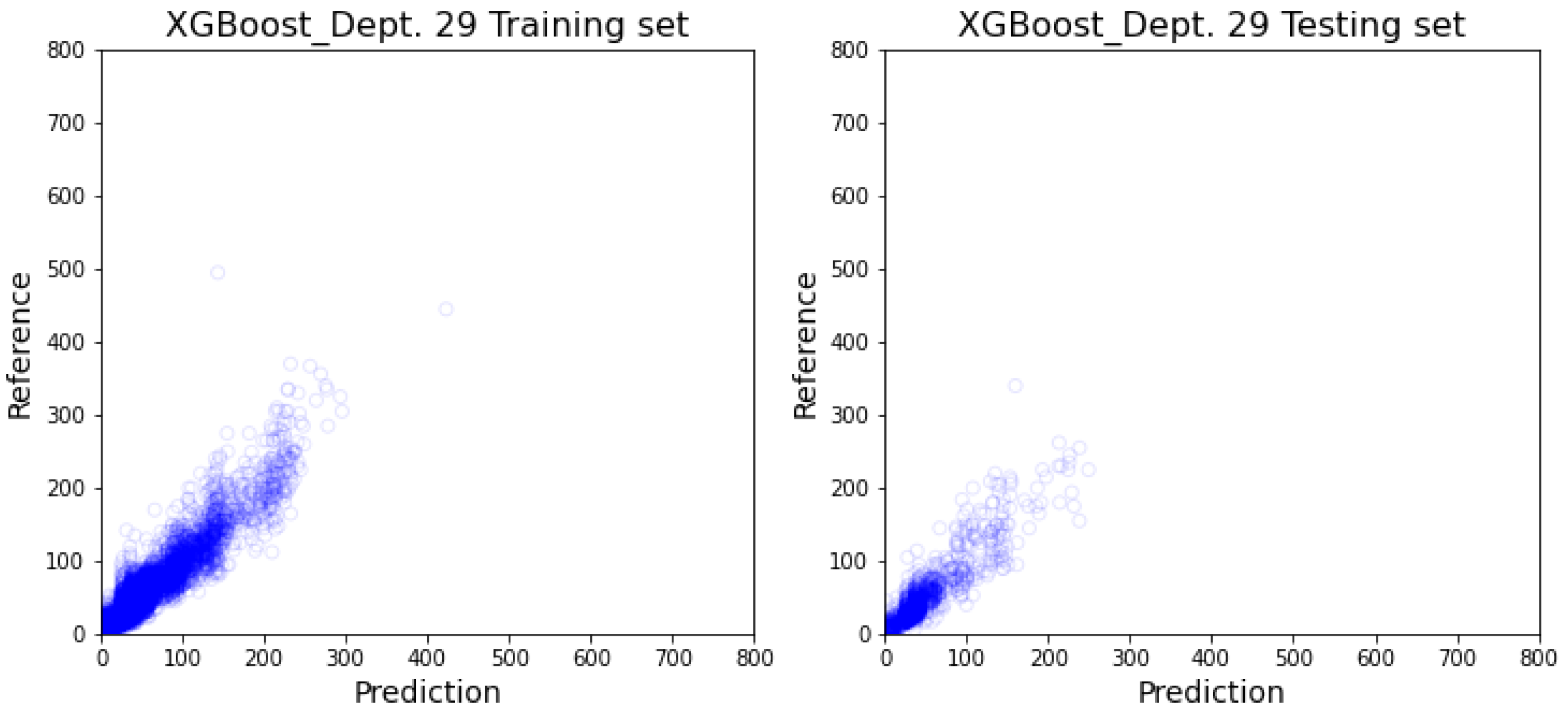
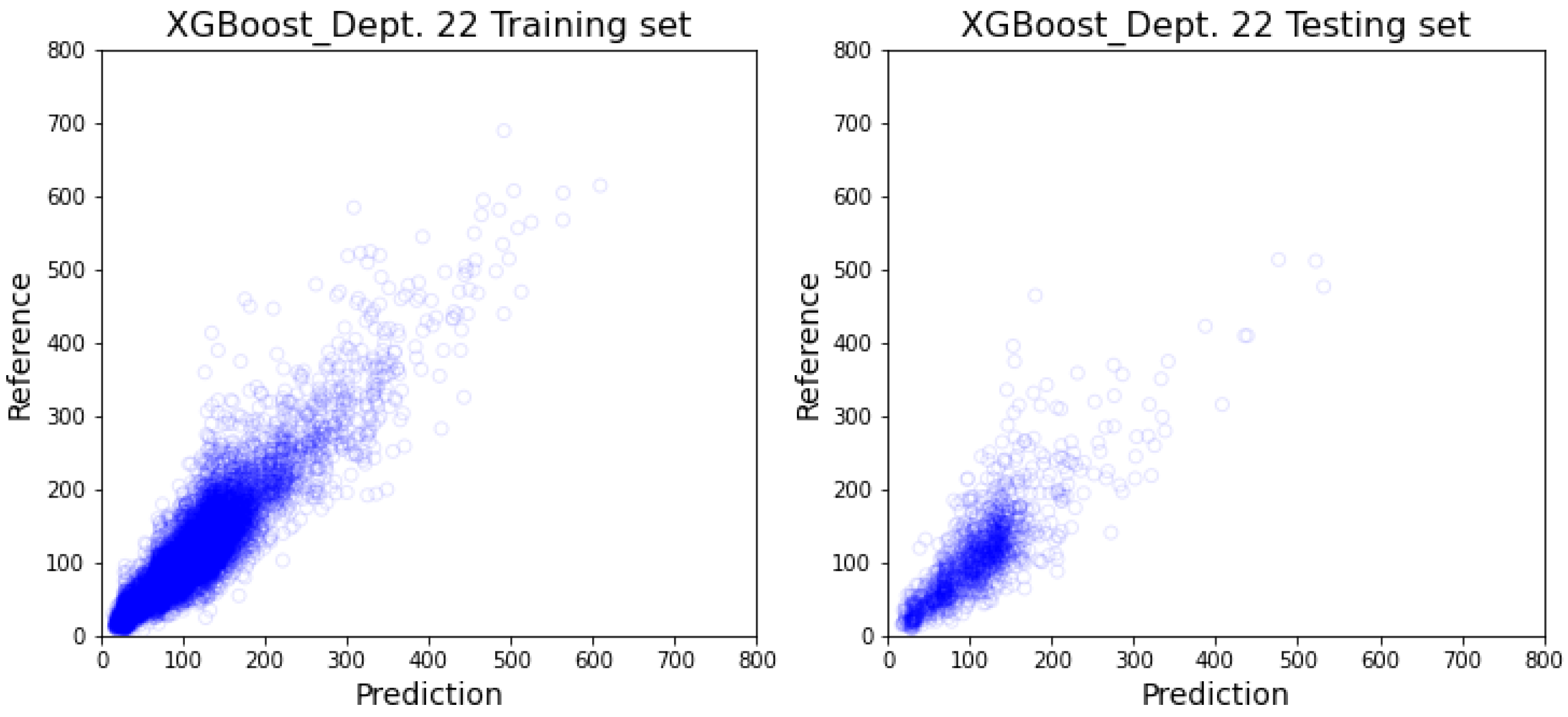
3.2. Department-Specific Model Results
4. Discussion
4.1. Comparative Study
4.2. Prediction Result’s Impact
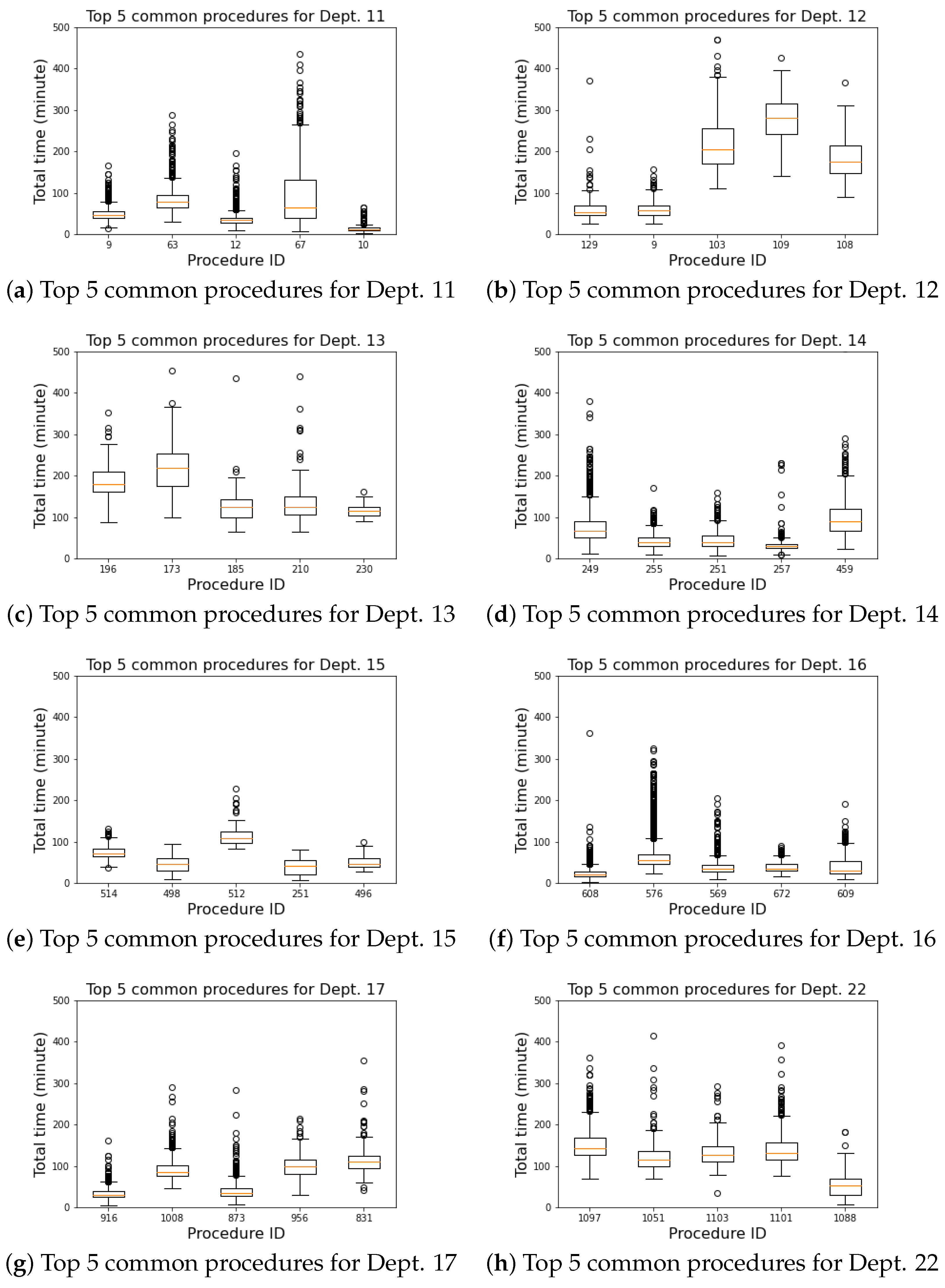
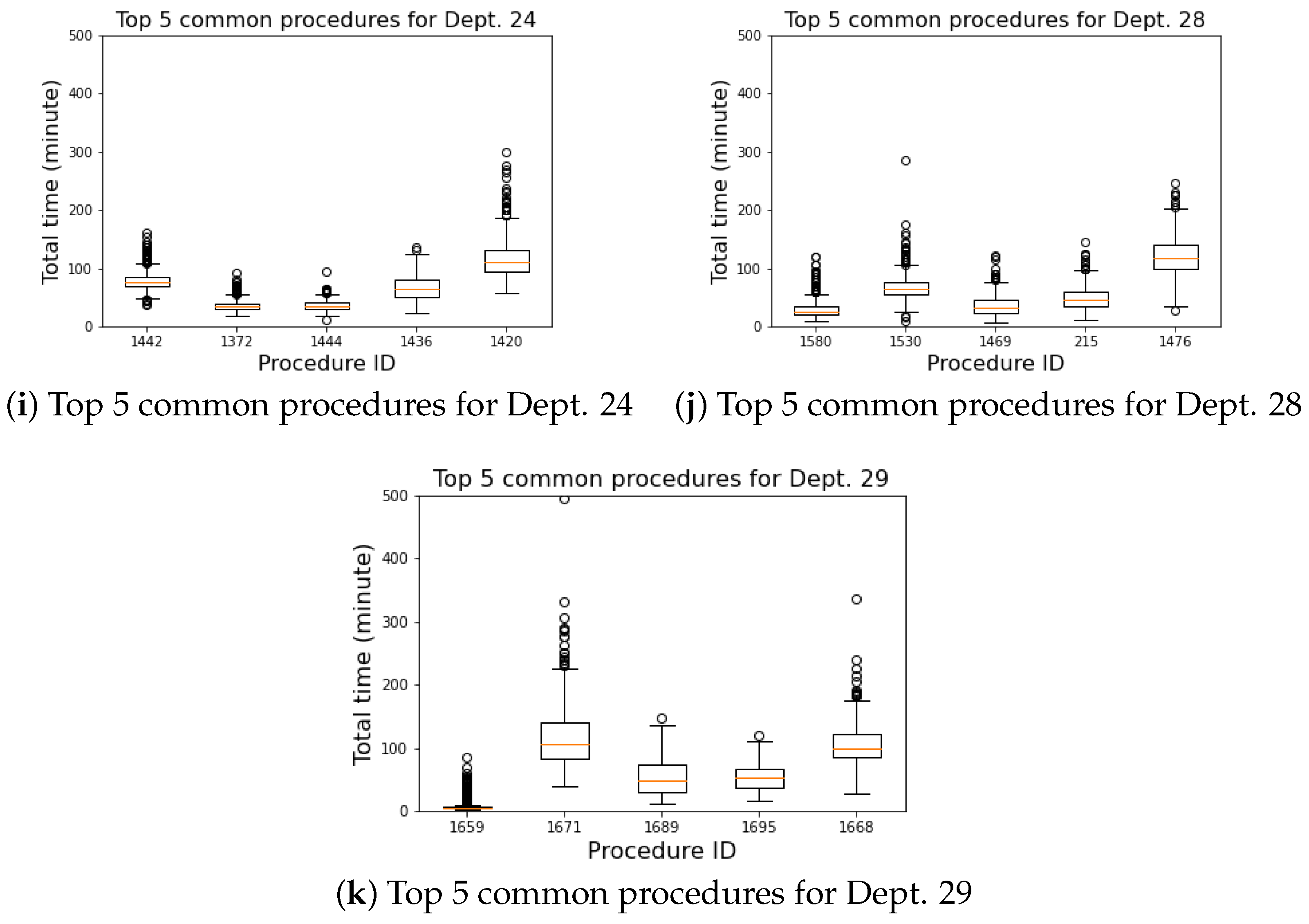
4.3. Commonly Performed Procedures
4.4. Practical Usage
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Column Namea | Descriptions |
|---|---|
| ODR_LOGN | Surgery serial number |
| ODR_CHRT | Chart Number |
| ODR_TXDT | Date |
| ODR_OPRM | Operating Room ID |
| ODR_DEPT | Department |
| ODR_PSRC | Patient Source (O: Outpatient, I: Inpatient, E: Emergency room) |
| ODR_BDNO | Bed number |
| ODR_EFLG | Emergency Surgery |
| ODR_IPNO | Inpatient Number |
| ODR_AS_D | Anesthesia Start (date) |
| ODR_AS_T | Anesthesia Start (time) |
| ODR_AE_D | Anesthesia End(date) |
| ODR_AE_T | Anesthesia End(time) |
| ODR_IN_D | Enter OR room (date) |
| ODR_IN_T | Enter OR room (time) |
| ODR_OS_D | Operation Start (date) |
| ODR_OS_T | Operation Start (time) |
| ODR_OE_D | Operation End (date) |
| ODR_OE_T | Operation End (time) |
| ODR_OT_D | Exit OR room (date) |
| ODR_OT_T | Exit OR room (time) |
| ODR_OP_1 ∼ODR_OP_4 | Operating procedure type’s IDs |
| ODR_KF_2 ∼ODR_KF_4 | N/A |
| ODR_SK_2 ∼ODR_SK_4 | N/A |
| ODR_M_DR | Main Doctor |
| ODR_DN_1 | scrub nurse 1 |
| ODR_DN_2 | scrub nurse 2 |
| ODR_WN_1 | circulation nurse 1 |
| ODR_WN_2 | circulation nurse 2 |
| ODR_AD_1 ∼ODR_AD_4 | N/A |
| ODR_PAYK | Payment category (01- Self-Pay, 30-Health insurance) |
| ODR_OPID | Operation ID |
| ODR_ANAM | Anesthesia methods |
| ODR_AN_D | Anesthesiologist (Doctor) |
| ODR_INDR | Anesthesia assessment Doctor |
| ODR_ASA | Anesthesia risk1∼5 (low∼high) |
| ODR_IRFG | N/A |
| ODR_IDFC | N/A |
| ODR_OPAG | N/A |
| ODR_FAID | N/A |
| ODR_DEAD | N/A |
| ODR_SAT1 ∼ODR_SAT5 | N/A |
| ODR_ANS1 ∼ODR_ANS5 | N/A |
| ODR_M_D2 | Assistant Doctors 2 ∼4 |
| ODR_PKN1 ∼ODR_PKN5 | N/A |
| ODR_TIM1 ∼ODR_TIM5 | N/A |
| ODR_CHRF | N/A |
| ODR_SPKD | N/A |
| ODR_ORMT | N/A |
| ODR_ANMT | N/A |
| ODR_ANT1 ∼ODR_ANT3 | Anesthesia method’s notes |
| ODR_WOUD | Wound cleanness: 1: clean 2: cleaned contaminated 3: contaminated 4: dirty |
| ODR_ITE1 ∼ODR_ITE4 | N/A |
| ODR_NPRO | N/A |
| ODR_PC01 ∼ODR_PC20 | N/A |
| ODR_PRDG | Operating procedure name |
| ODR_FIND | Finding |
| ODR_OPF | Finding during procedure |
| ODR_OPP | Operating procedure |
| ODR_PODG | Post-operation diagnosis |


















References
- Diwakar, G. Surgical Suites’ Operations Management. Prod. Oper. Manag. 2007, 16, 689–700. [Google Scholar] [CrossRef]
- Childers, C.P.; Maggard-Gibbons, M. Understanding Costs of Care in the Operating Room. JAMA Surg. 2018, 153, e176233. [Google Scholar] [CrossRef] [PubMed]
- Abedini, A.; Li, W.; Ye, H. An Optimization Model for Operating Room Scheduling to Reduce Blocking Across the Perioperative Process. Procedia Manuf. 2017, 10, 60–70. [Google Scholar] [CrossRef]
- Dexter, F.; Macario, A.; Traub, R.D.; Hopwood, M.; Lubarsky, D.A. An Operating Room Scheduling Strategy to Maximize the Use of Operating Room Block Time. Anesth. Analg. 1999, 89, 7–20. [Google Scholar] [CrossRef]
- Overdyk, F.J.; Harvey, S.C.; Fishman, R.L.; Shippey, F. Successful Strategies for Improving Operating Room Efficiency at Academic Institutions. Anesth. Analg. 1998, 86, 896–906. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.J.; Ding, J.; Guzzo, T.J. Improving Operating Room Efficiency. Curr. Urol. Rep. 2019, 20, 28. [Google Scholar] [CrossRef]
- Davila, M.P. A Methodology for Scheduling Operating Rooms Under Uncertainty. Ph.D. Thesis, University of South Florida, Tampa, FL, USA, 2013. [Google Scholar]
- Xiang, W.; Yin, J.; Lim, G. An ant colony optimization approach for solving an operating room surgery scheduling problem. Comput. Ind. Eng. 2015, 85, 335–345. [Google Scholar] [CrossRef]
- Rahimi, I.; Gandomi, A.H. A Comprehensive Review and Analysis of Operating Room and Surgery Scheduling. Arch. Comput. Methods Eng. 2020, 28, 1667–1688. [Google Scholar] [CrossRef]
- Pham, D.N.; Klinkert, A. Surgical case scheduling as a generalized job shop scheduling problem. Eur. J. Oper. Res. 2008, 185, 1011–1025. [Google Scholar] [CrossRef]
- Cardoen, B.; Demeulemeester, E.; Beliën, J. Operating room planning and scheduling: A literature review. Eur. J. Oper. Res. 2010, 201, 921–932. [Google Scholar] [CrossRef]
- Denton, B.T.; Miller, A.J.; Balasubramanian, H.J.; Huschka, T.R. Optimal Allocation of Surgery Blocks to Operating Rooms Under Uncertainty. Oper. Res. 2010, 58, 802–816. [Google Scholar] [CrossRef]
- Fügener, A.; Hans, E.W.; Kolisch, R.; Kortbeek, N.; Vanberkel, P.T. Master surgery scheduling with consideration of multiple downstream units. Eur. J. Oper. Res. 2014, 239, 227–236. [Google Scholar] [CrossRef]
- Shehadeh, K.S.; Padman, R. A distributionally robust optimization approach for stochastic elective surgery scheduling with limited intensive care unit capacity. Eur. J. Oper. Res. 2021, 290, 901–913. [Google Scholar] [CrossRef]
- Rozario, D. Can machine learning optimize the efficiency of the operating room in the era of COVID-19? Can. J. Surg. 2020, 63, E527–E529. [Google Scholar] [CrossRef]
- Jiao, Y.; Xue, B.; Lu, C.; Avidan, M.S.; Kannampallil, T. Continuous real-time prediction of surgical case duration using a modular artificial neural network. Br. J. Anaesth. 2022, 128, 829–837. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Chen, X.; Liu, W.; Shih, P.C.; Bao, J. Automatic Surgery and Anesthesia Emergence Duration Prediction Using Artificial Neural Networks. J. Healthc. Eng. 2022, 2022, 2921775. [Google Scholar] [CrossRef] [PubMed]
- Eijkemans, M.C.; van Houdenhoven, M.; Nguyen, T.; Boersma, E.; Steyerberg, E.; Kazemier, G. Predicting the Unpredictable: A New Prediction Model for Operating Room Times Using Individual Characteristics and the Surgeon’s Estimate. Anesthesiology 2010, 112, 41–49. [Google Scholar] [CrossRef] [PubMed]
- Edelman, E.R.; van Kuijk, S.M.J.; Hamaekers, A.E.W.; de Korte, M.J.M.; van Merode, G.G.; Buhre, W.F.F.A. Improving the Prediction of Total Surgical Procedure Time Using Linear Regression Modeling. Front. Med. 2017, 4, 85. [Google Scholar] [CrossRef] [PubMed]
- Bartek, M.A.; Saxena, R.C.; Solomon, S.; Fong, C.T.; Behara, L.D.; Venigandla, R.; Velagapudi, K.; Lang, J.D.; Nair, B.G. Improving Operating Room Efficiency: Machine Learning Approach to Predict Case-Time Duration. J. Am. Coll. Surg. 2019, 229, 346–354.e3. [Google Scholar] [CrossRef] [PubMed]
- Abbou, B.; Tal, O.; Frenkel, G.; Rubin, R.; Rappoport, N. Optimizing Operation Room Utilization-A Prediction Model. Big Data Cogn. Comput. 2022, 6, 76. [Google Scholar] [CrossRef]
- Bandi, C.; Gupta, D. Operating room staffing and scheduling. Manuf. Serv. Oper. Manag. 2020, 22, 958–974. [Google Scholar] [CrossRef]
- Li, F.; Gupta, D.; Potthoff, S. Improving operating room schedules. Health Care Manag. Sci. 2016, 19, 261–278. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, A.; Ali, H. Modeling patient preference in an operating room scheduling problem. Oper. Res. Health Care 2020, 25, 100257. [Google Scholar] [CrossRef]
- Iliou, T.; Anagnostopoulos, C.N.; Nerantzaki, M.; Anastassopoulos, G. A Novel Machine Learning Data Preprocessing Method for Enhancing Classification Algorithms Performance. In Proceedings of the EANN ’15: 16th International Conference on Engineering Applications of Neural Networks (INNS), Rhodes Island, Greece, 25–28 September 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Miao, S.d.; Li, S.q.; Zheng, X.y.; Wang, R.t.; Li, J.; Ding, S.s.; Ma, J.f. Missing Data Interpolation of Alzheimer’s Disease Based on Column-by-Column Mixed Mode. Complexity 2021, 2021, 3541516. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD ’16: 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Gurney, K. An Introduction to Neural Networks; CRC Press: Boca Raton, FL, USA, 2014; pp. 13–16. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Clarke, W.L.; Cox, D.; Gonder-Frederick, L.A.; Carter, W.; Pohl, S.L. Evaluating Clinical Accuracy of Systems for Self-Monitoring of Blood Glucose. Diabetes Care 1987, 10, 622–628. [Google Scholar] [CrossRef]
- Wu, A.; Brovman, E.; Whang, E.; Ehrenfeld, J.; Urman, R. The Impact of Overestimations of Surgical Control Times Across Multiple Specialties on Medical Systems. J. Med. Syst. 2016, 40, 95. [Google Scholar] [CrossRef] [PubMed]






| Dept. | Sample Count | Doctors | Nurses | Unique OPs |
|---|---|---|---|---|
| 16 | 21,968 | 58 | 182 | 367 |
| 29 | 20,476 | 52 | 169 | 266 |
| 14 | 14,763 | 52 | 185 | 602 |
| 17 | 13,566 | 72 | 179 | 652 |
| 22 | 13,338 | 60 | 178 | 674 |
| 24 | 12,410 | 69 | 185 | 279 |
| 11 | 9874 | 39 | 175 | 123 |
| 28 | 7670 | 46 | 168 | 448 |
| 13 | 4017 | 43 | 170 | 213 |
| 15 | 1965 | 8 | 155 | 141 |
| 12 | 1800 | 34 | 164 | 176 |
| 66 | 635 | 25 | 141 | 136 |
| 31 | 521 | 6 | 113 | 22 |
| 30 | 454 | 26 | 130 | 155 |
| 5 | 13 | 4 | 29 | 7 |
| 25 | 4 | 2 | 12 | 4 |
| 18 | 2 | 2 | 6 | 3 |
| All | 123,476 | 158 | 202 | 1916 |
| Method | RMSE | MAPE | MAE | ||
|---|---|---|---|---|---|
| (min) | (%) | (min) | (%) | ||
| XGBoost | 37.2 | 31 | 21.05 | 0.72 | 25 |
| Random Forest | 36.0 | 29 | 20.49 | 0.76 | 26 |
| ANN | 47.6 | 45 | 20.14 | 0.64 | 26 |
| 1-d CNN | 48.6 | 47 | 27.57 | 0.63 | 19 |
| (a) Random Forest Model Results | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Dept. | RMSE | MAE | MAPE | ±10% * | ±10 min | ±5 min * | <10 min ** | <5 min ** | Sample_Count | |
| (min) | (min) | (%) | (%) | (%) | (%) | (%) | (%) | |||
| 16 | 26.58 | 14.51 | 30 | 0.72 | 24 | 59 | 33 | 77 | 60 | 21,968 |
| 29 | 11.74 | 6.81 | 29 | 0.87 | 27 | 80 | 60 | 91 | 77 | 20,476 |
| 14 | 38.00 | 21.63 | 31 | 0.64 | 24 | 44 | 24 | 67 | 55 | 14,763 |
| 17 | 42.51 | 26.80 | 24 | 0.66 | 28 | 34 | 18 | 63 | 53 | 13,566 |
| 22 | 38.42 | 24.84 | 26 | 0.48 | 29 | 34 | 19 | 62 | 52 | 13,338 |
| 24 | 20.43 | 13.72 | 19 | 0.79 | 34 | 52 | 28 | 73 | 58 | 12,410 |
| 11 | 32.33 | 18.81 | 30 | 0.85 | 27 | 48 | 28 | 68 | 55 | 9874 |
| 28 | 47.86 | 25.88 | 31 | 0.68 | 26 | 40 | 22 | 66 | 56 | 7670 |
| 13 | 74.73 | 49.76 | 24 | 0.47 | 33 | 17 | 09 | 52 | 48 | 4017 |
| 15 | 35.63 | 15.11 | 21 | −0.26 | 32 | 54 | 28 | 76 | 61 | 1965 |
| 12 | 62.21 | 43.15 | 28 | 0.67 | 24 | 22 | 10 | 53 | 45 | 1800 |
| Average (weighted) | 31.98 | 19.15 | 27 | 0.69 | 27 | 50 | 30 | 72 | 59 | 121,847 |
| (b) XGB Model Results | ||||||||||
| Dept. | RMSE | MAE | MAPE | ±10% * | ±10 min | ±5 min * | <10 min ** | <5 min ** | Sample_Count | |
| (min) | (min) | (%) | (%) | (%) | (%) | (%) | (%) | |||
| 16 | 29.94 | 14.65 | 30 | 0.66 | 23 | 60 | 35 | 79 | 62 | 21,968 |
| 29 | 13.20 | 7.42 | 32 | 0.85 | 27 | 78 | 56 | 90 | 76 | 20,476 |
| 14 | 32.30 | 19.98 | 30 | 0.68 | 23 | 43 | 23 | 68 | 56 | 14,763 |
| 17 | 39.77 | 24.55 | 24 | 0.70 | 30 | 37 | 19 | 64 | 54 | 13,566 |
| 22 | 35.32 | 23.70 | 25 | 0.62 | 30 | 33 | 18 | 62 | 54 | 13,338 |
| 24 | 22.34 | 14.01 | 19 | 0.76 | 36 | 54 | 28 | 74 | 58 | 12,410 |
| 11 | 33.48 | 19.10 | 28 | 0.87 | 25 | 46 | 25 | 71 | 58 | 9874 |
| 28 | 51.31 | 28.14 | 33 | 0.71 | 22 | 36 | 18 | 64 | 54 | 7670 |
| 13 | 65.05 | 45.95 | 23 | 0.64 | 30 | 21 | 12 | 55 | 51 | 4017 |
| 15 | 35.50 | 15.55 | 22 | −0.24 | 30 | 52 | 24 | 73 | 59 | 1965 |
| 12 | 56.67 | 38.27 | 26 | 0.73 | 31 | 25 | 09 | 56 | 47 | 1800 |
| Average (weighted) | 31.60 | 18.71 | 28 | 0.71 | 27 | 50 | 30 | 73 | 60 | 121,847 |
| Approach | RMSE | MAPE | MAE | ±10% | |
|---|---|---|---|---|---|
| (min) | (%) | (min) | (%) | ||
| Linear Regression [18] | 48.64 | n/a | 31.3 | n/a | n/a |
| Ref. XGBoost [20] | n/a | 27 | n/a | 0.77 | 32 |
| Ref. Random Forest [20] | n/a | 39 | n/a | 0.93 | 23 |
| XGBoost-HY [21] | 36.64 | 35.16 | 21.52 | n/a | n/a |
| XGBoost-SH [21] | 40.26 | 35.11 | 25.23 | n/a | n/a |
| XGBoost - Department Specific (w) | 31.60 | 28 | 18.71 | 0.71 | 27 |
| Random Forest - Department Specific (w) | 31.98 | 27 | 19.15 | 0.69 | 27 |
| ANN - All inclusive | 47.6 | 45 | 20.14 | 0.64 | 26 |
| 1-d CNN - All inclusive | 48.6 | 47 | 28.77 | 0.65 | 17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, J.; Hsieh, C.-H.; Shih, Y.-N.; Wu, C.-C.; Singaravelan, A.; Hung, L.-P.; Hsu, J.-L. Operating Room Usage Time Estimation with Machine Learning Models. Healthcare 2022, 10, 1518. https://doi.org/10.3390/healthcare10081518
Chu J, Hsieh C-H, Shih Y-N, Wu C-C, Singaravelan A, Hung L-P, Hsu J-L. Operating Room Usage Time Estimation with Machine Learning Models. Healthcare. 2022; 10(8):1518. https://doi.org/10.3390/healthcare10081518
Chicago/Turabian StyleChu, Justin, Chung-Ho Hsieh, Yi-Nuo Shih, Chia-Chun Wu, Anandakumar Singaravelan, Lun-Ping Hung, and Jia-Lien Hsu. 2022. "Operating Room Usage Time Estimation with Machine Learning Models" Healthcare 10, no. 8: 1518. https://doi.org/10.3390/healthcare10081518
APA StyleChu, J., Hsieh, C.-H., Shih, Y.-N., Wu, C.-C., Singaravelan, A., Hung, L.-P., & Hsu, J.-L. (2022). Operating Room Usage Time Estimation with Machine Learning Models. Healthcare, 10(8), 1518. https://doi.org/10.3390/healthcare10081518