2.1. Hidden Markov Model
The Hidden Markov Model (HMM) is a statistical Markov model in which a Markov chain with unobserved (hidden) states is used to represent the system being modeled. This model, originally developed by Leonard E. Baum and his coworkers, is an improvement to conventional Markov models [
39]. In a conventional Markov model (like a Markov chain), the state of a system to be modeled can be observed and the state transition probabilities are the only parameters to be estimated when the structure of the Markov model is developed and calibrated. In a Hidden Markov Model, the state is not directly visible, but the output, derived from the state, can be observed. Each state is estimated with a probability distribution over the possible outputs. Therefore, within the Markov chain, the sequence of outputs generated by an HMM gives some information about the sequence of hidden states [
40].
An HMM can be described by the following characteristics:
N,
M,
A,
B and
π.
N is the number of possible hidden states in the model. Each individual state can be denoted as , i.e., 1 ≤ I ≤ N. And the state symbol at time t is defined as qt.
M is the number of observable symbols per state , i.e., 1 ≤ k ≤ M. And the observation symbol at time t is denoted as Ot.
The state transition probability distribution
is denoted as:
where
aij representing the transition probability from state
Si to state
Sj, have the following two constraints:
and
The constraint indicates that the state Si can reach any other state Sj in one step.
The observation probability distribution
can be indicated as:
where
bj(k) represents the probability of the state value
j at time
t with the observation symbol
vk.
The initial state probability distribution
, where
πi are the probabilities of
Si being the initial state in a state sequence.
An HMM model can be described by the specification of N, M, A, B and π. At first, the initial distribution π shows the initial state. Then the new state can be obtained by the state transition probability distribution A. Finally, the observation value is given according to the observation probability distribution B.
There are several methods that can be used to estimate N, M, A, B and π. The primary methods are the supervised learning algorithm and the unsupervised learning algorithm. The supervised learning algorithm is an MLE method which uses observation sequence and its corresponding state sequence data. This method manually labels the training data and thus its workload is relatively large. Though the process is complicated, its results are closer to the actual situation because the results are obtained based on a large number of statistical data. The unsupervised learning algorithm, on the other hand, is a Forward–Backward algorithm that uses observation sequence. This method first randomly sets the initial value of the model parameters () and then continuously updates λ and calculates the expectation to maximize .
Among all the unsupervised learning algorithms, an iterative procedure known as the Baum-Welch (B-W) algorithm is widely used [
39]. It searches for an optimal solution based on expectation maximization [
39,
41]. The B-W algorithm estimates the model parameter
using the forward variable
and backward variable
to find updated values of
,
and
.
where
is the probability of being in state
Si and
Sj at time
t and
t + 1, respectively, given the observation sequence
O and the model parameters
λ.
is the partial observation sequence
given state
Si at time
t.
represents the remainder of the observation sequence
given state
Sj at time
t + 1.
where
defines the probability of being in state
Si at time
t given the observation sequence
O and the model parameters
λ. And then, parameters can be updated as follows [
34,
40]:
where
represents the expected frequency in state
Si at time
t (
t = 1).
where
T is the number of observations in the sequence.
is the expected number of transitions from state
Si to
Sj.
is the expected number of transitions from state
Si.
where the numerator is the expected number of times in state
j and observing symbol
vk. The denominator is the expected number of times in state
j.
Based on the above updating procedures, the new parameter can be obtained. The final optimal value of the parameter is acquired by iteratively using in place of λ and repeating updating estimation calculations.
2.2. Hidden Markov Driving Model
Driver behavior is affected by internal factors (e.g., drivers’ attributes, physical and psychological conditions, and perceptions and reactions to environment changes) and external factors (interferences of other vehicles, traffic controls, and weather conditions). Under such complex conditions, drivers’ decision-making processes can hardly be tracked. In this study, an HMM model is applied to describe driving behaviors of drivers when they approach intersections, which is entitled a Hidden Markov Driving Model (HMDM). This model assumes that drivers’ preferences under certain traffic conditions are fairly consistent and their resulting behaviors can be observed and derived from their previous actions. Based on the assumption, it’s possible to predict driver behaviors based on vehicles’ dynamic data and drivers’ previous performance using HMDM.
A hidden Markov chain with the HMDM is used to represent stochastic states of driver behaviors and the transition from states in one step to the states in the following step. And the probability of a state at a certain moment depends only on its accurate previous state. According to early research, driver behavior is assumed to be statistically consistent when facing certain levels of conflicts within a certain population [
33]. However, drivers’ intentions cannot be observed during the driving process. Therefore, the HMM is employed to capture drivers’ intentions from several recorded sequences of the vehicle movement. The model can be used to depict drivers’ behaviors when they approach intersections. The hidden states can be estimated as the intentions of drivers (e.g., accelerate, decelerate, maintain speed, and stop), and the observation sequences can be vehicles’ dynamic data, such as the speed, headway, and acceleration. Specifically, the observed states statistically depend on the hidden states. The task of driver behavior estimation is to explore drivers’ decisions based on the observed dynamic data. The objective of the Hidden Markov Driving Model is to model the relationship between the continuous observations made by the vehicles and the discrete states representing drivers’ decisions that produced these observations.
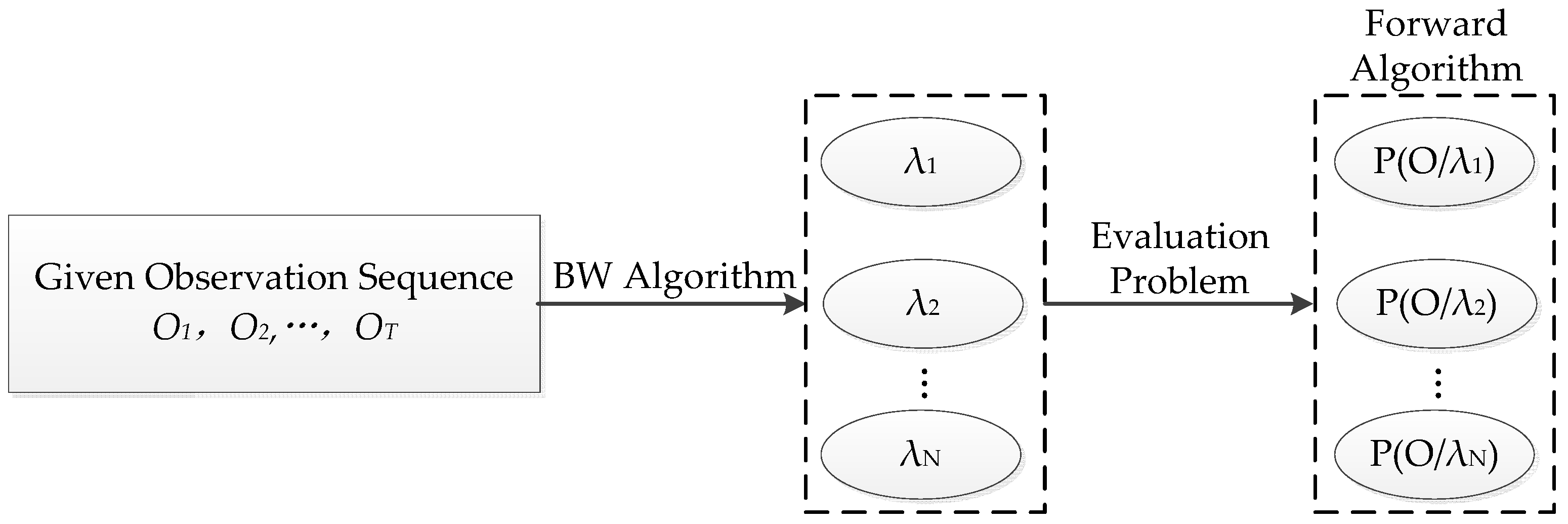
For real-word applications, there are three basic problems to solve: evaluation, decoding, and learning problems.
Evaluation: Given observation sequence and model , how to calculate the probability .
Decoding: Given observation sequence and model, how to find the optimal hidden state sequence in a meaningful case.
Learning: Given observation sequence, how to adjust the model parameters to maximize the possibility .
The solutions to these problems are the Forward–Backward algorithm, the Viterbi algorithm, and the Baum-Welch algorithm [
40,
42].
Therefore, after training the basic HMM using the B-W algorithm, evaluation and decoding problems are solved to model stochastic driver behavior. The details are as follows:
1. Evaluation Problem
The evaluation problem refers to the situation; under the conditions that a model
and a sequence of observation
(vehicles’ dynamic data such as the speed, headway, and acceleration) are given, how to efficiently compute the possibility that the observed sequence is produced by the given model
, using the Forward algorithm. The illustration of this problem is shown in
Figure 1.
First define the forward variable
as:
where
is the partial observation sequence
given state
Si at time
t.
Based on the calculated possibility, the stability and the risk of driver behavior approaching intersections, especially in the dilemma zone, can be determined. Specifically, the stability of driver behavior is represented by the 2-norm of the observation probability matrix B and the risk of driver behavior is calculated by risk index , where xjk represents the corresponding probability of dangerous situations.
2. Decoding Problem
Based on the given model
and a sequence of observation
O (vehicles’ dynamic data such as the speed, headway, and acceleration), how to find the “optimal” state sequence
Q. There are several criteria. For example, the optimal state sequence can be defined as a state sequence in which the states
qt are chosen when they are individually most likely to occur. However, this could still result in an invalid state sequence [
40].
Therefore, in this study, we adopt another criterion that is also widely used. Its main purpose is to find the single best state sequence. The single best state sequence particularly refers to maximizing the possibility using dynamic programming, which is also called the Viterbi algorithm.
First define the forward variable
as:
where
is the highest probability along a single sequence at time
t, which accounts for the first
t observations and ends at state
Si. And define
to record the state sequence.
Step 4. State sequence backtracking:







{kind=link}
{kind=link}
{kind=link}
{kind=link}