Cholera Risk: A Machine Learning Approach Applied to Essential Climate Variables



Abstract
:1. Introduction
2. Materials and Methods
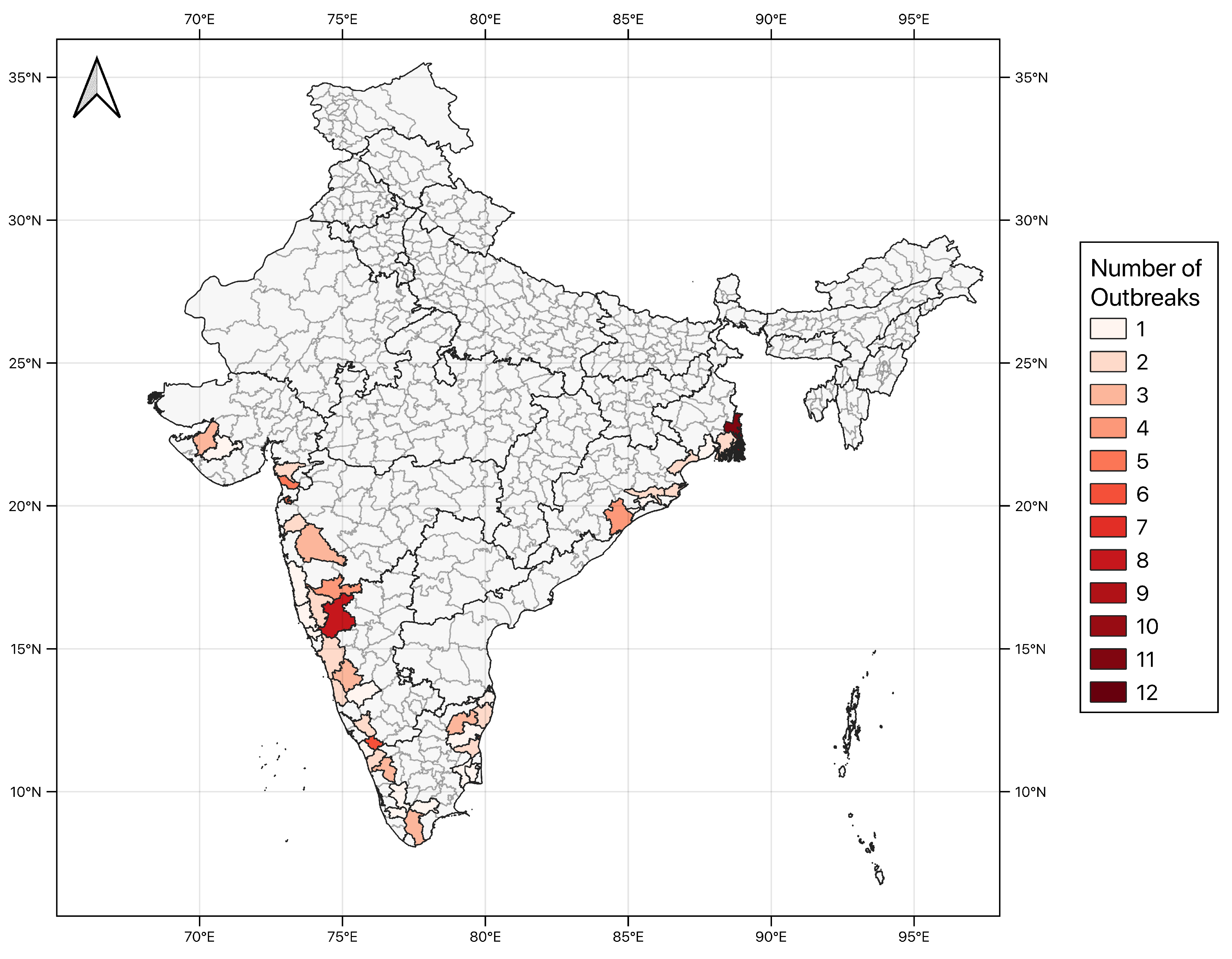
2.1. Surveillance Data of Cholera Outbreaks
2.2. Essential Climate Variables
2.3. Model Development
3. Results
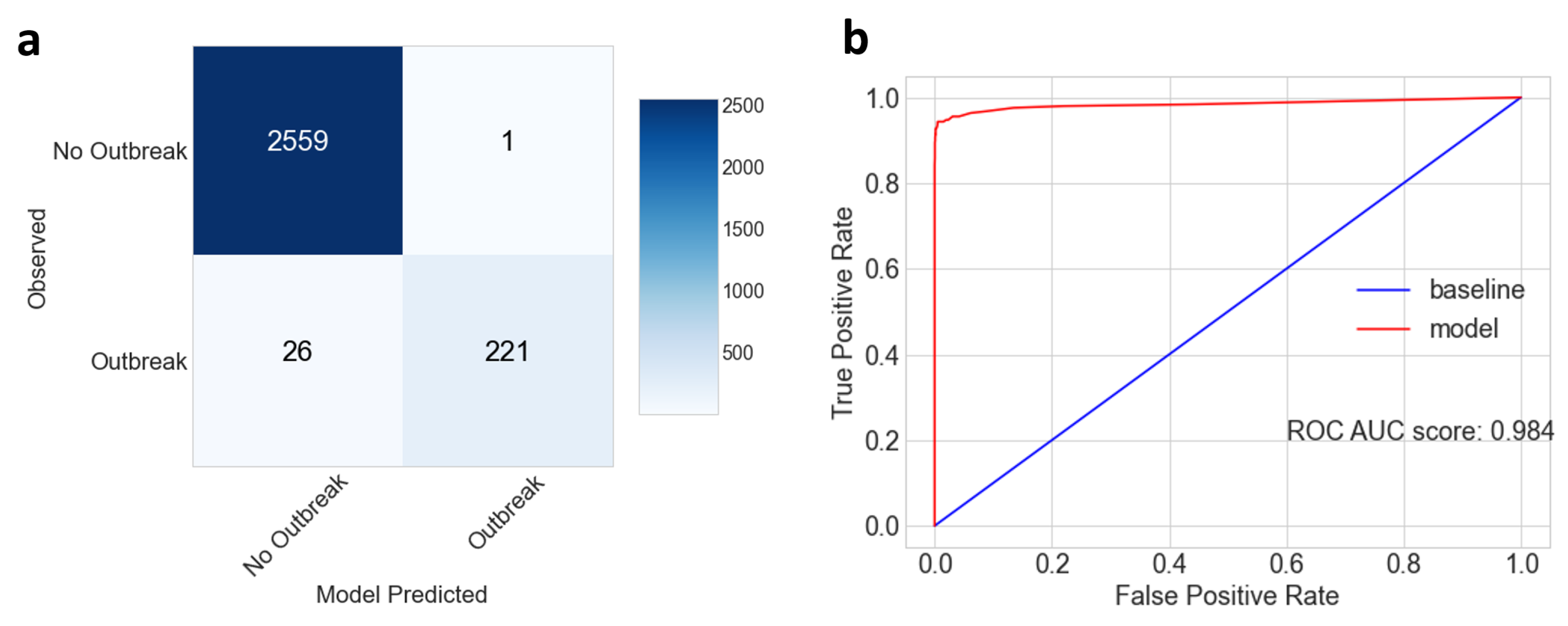
3.1. Random Forest Model Development
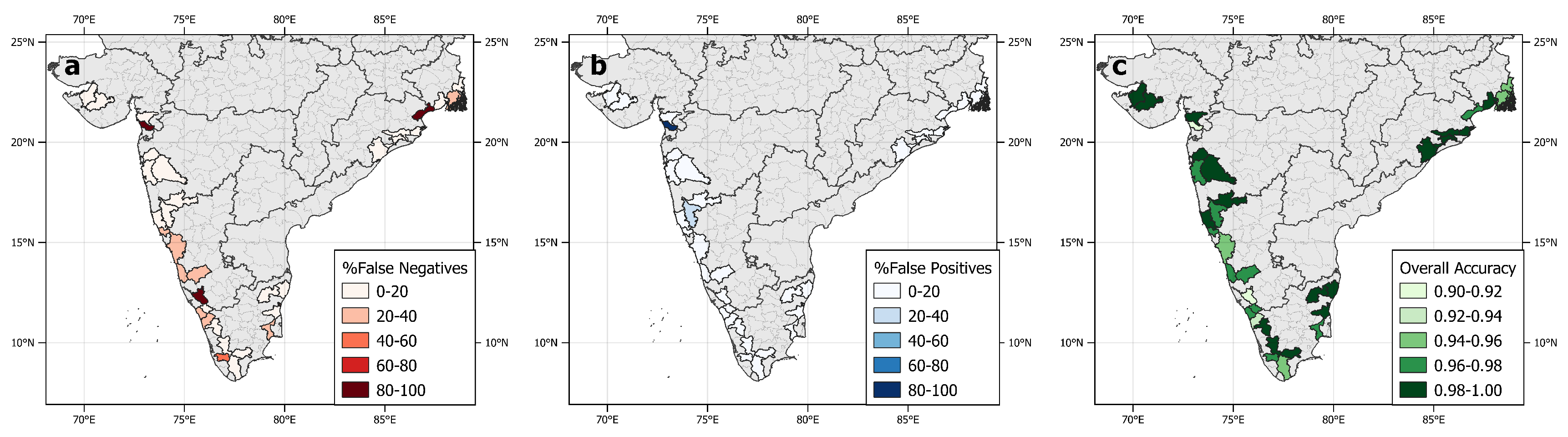
3.2. Individual District Testing
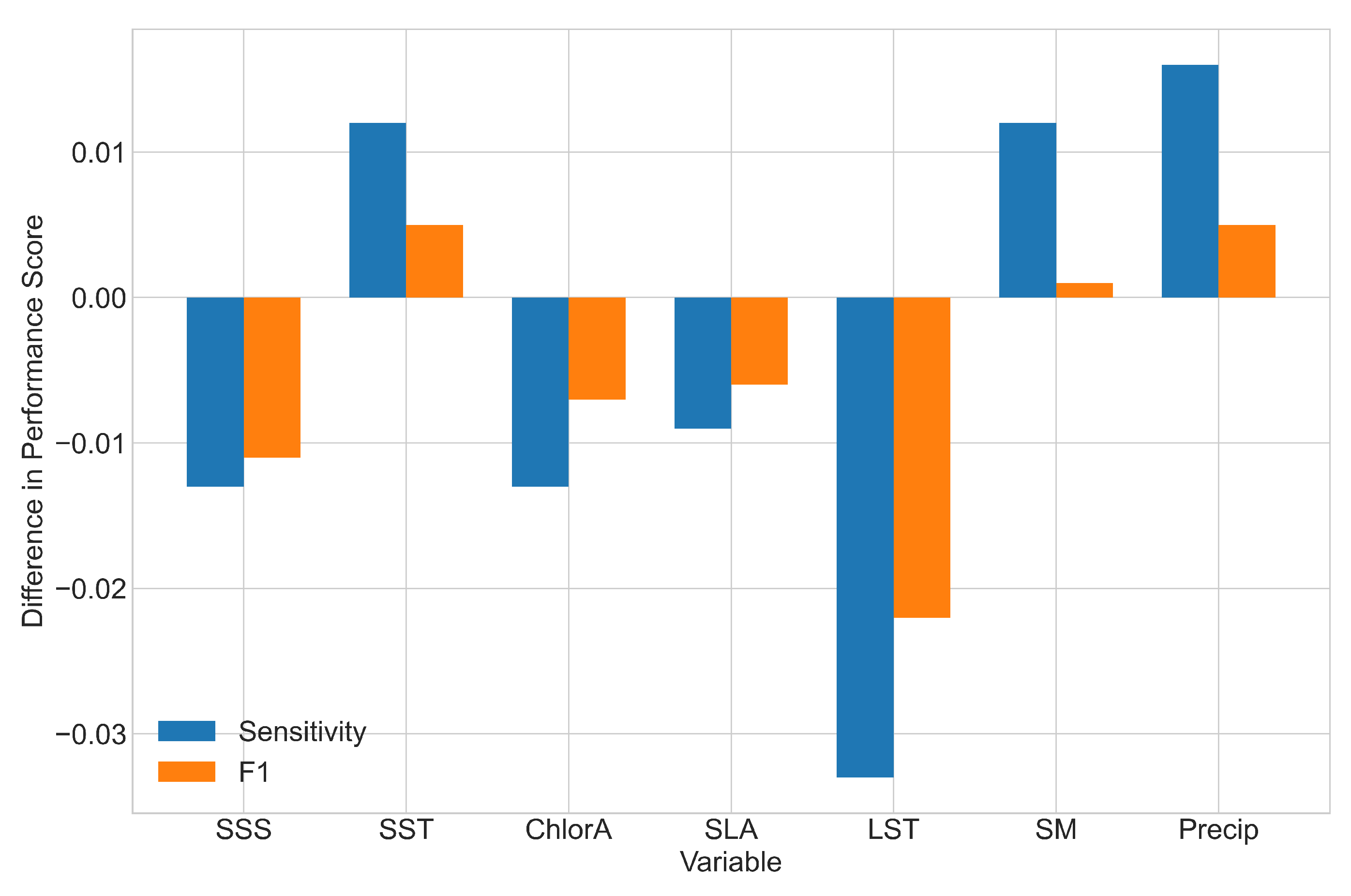
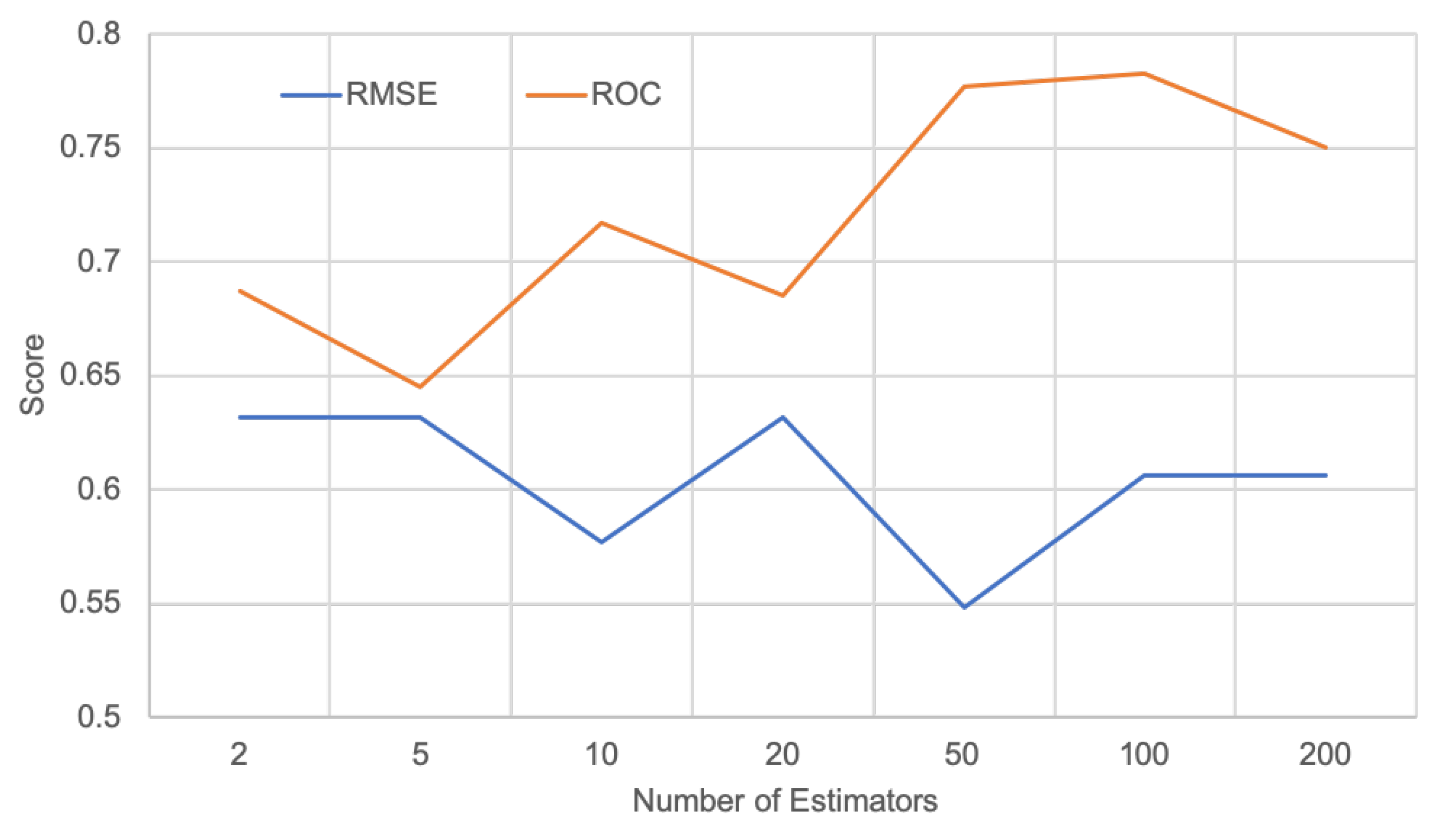
3.3. Sensitivity Analyses
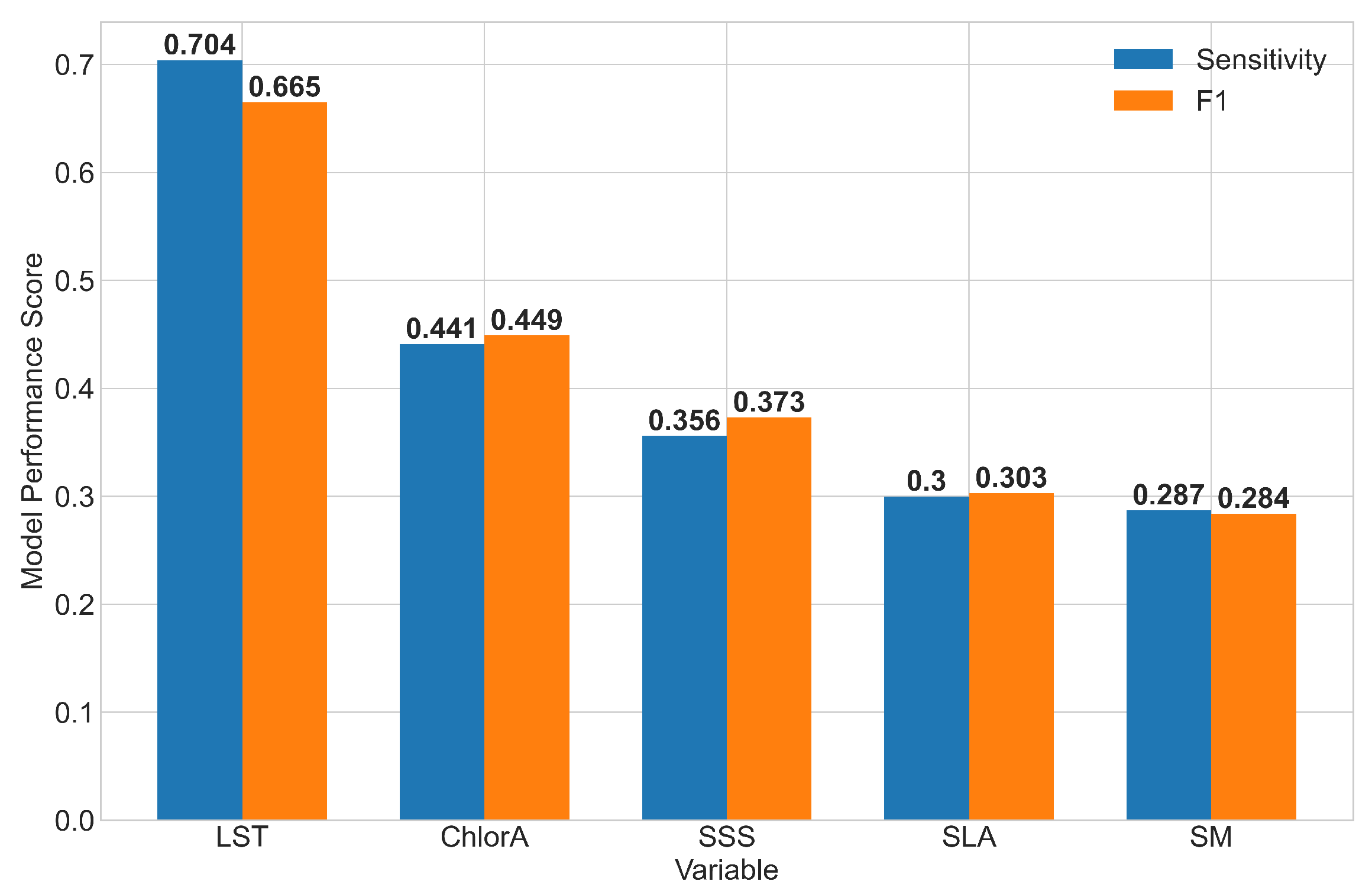
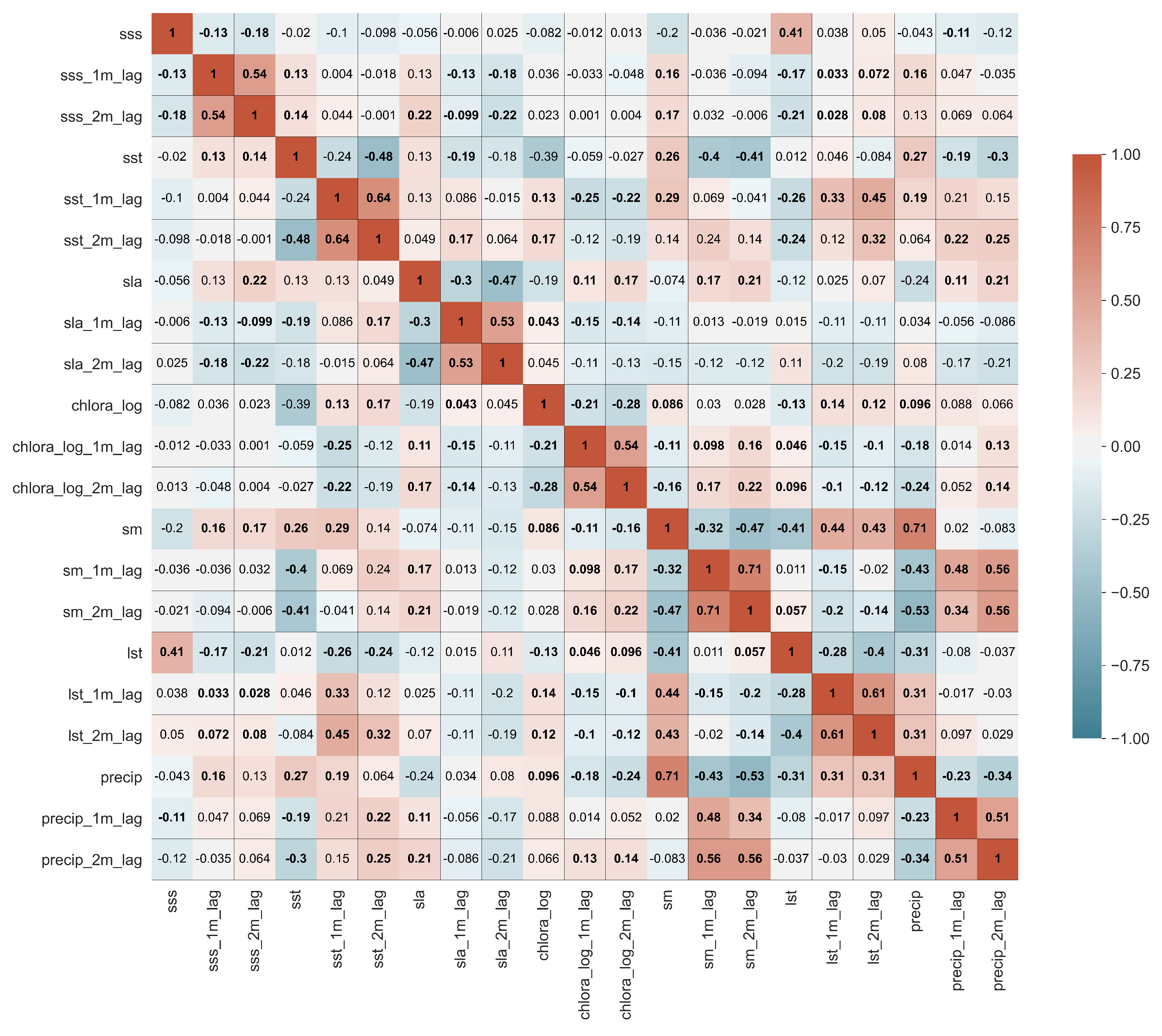
3.3.1. Individual ECVs
3.3.2. Oversampling Ratios
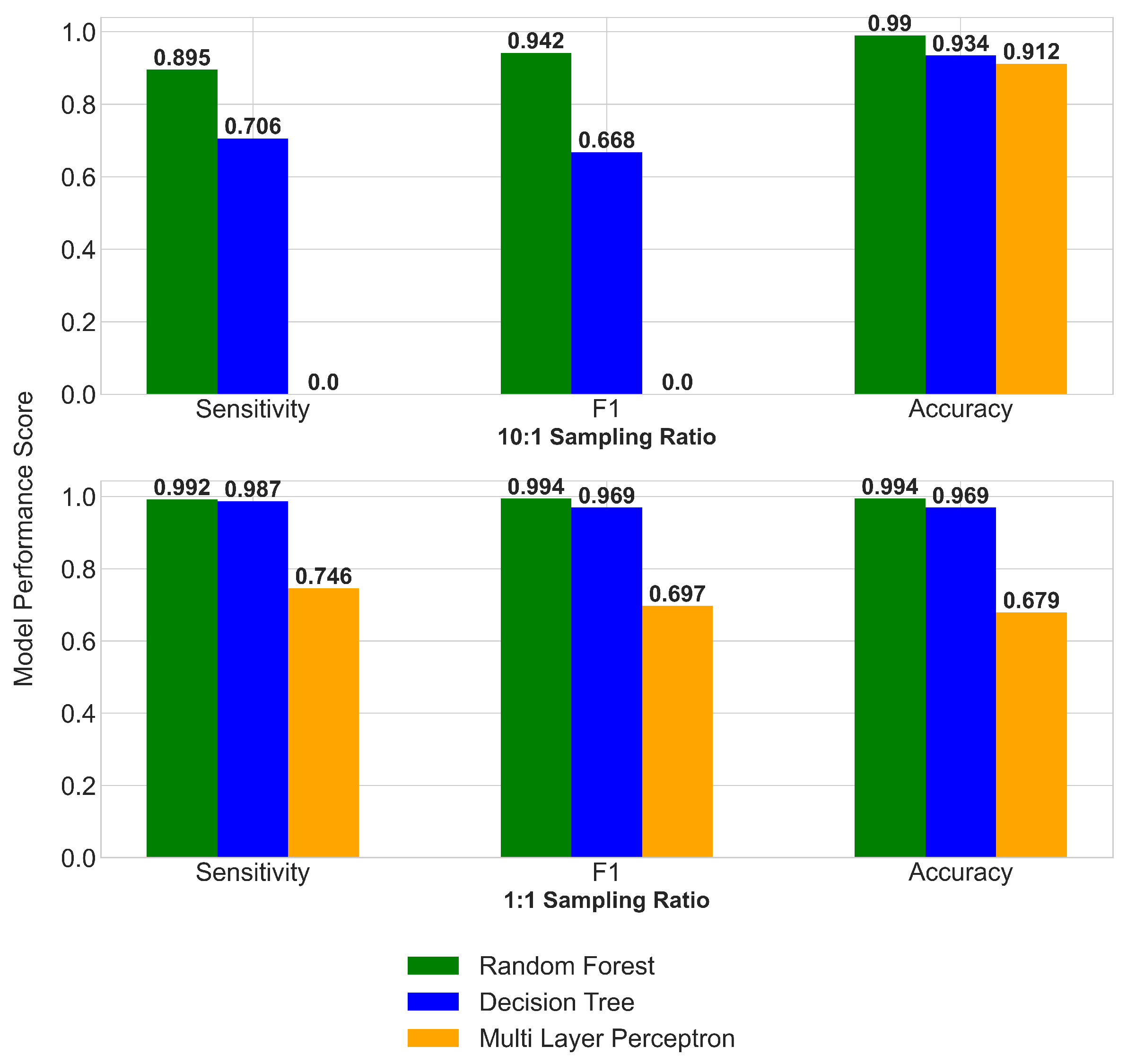
3.3.3. Machine Learning Method (ML)
4. Discussion
4.1. Usage of Remotely-Sensed ECVs for Cholera-Outbreak Risk Analyses
4.2. Machine Learning Techniques for Cholera Risk
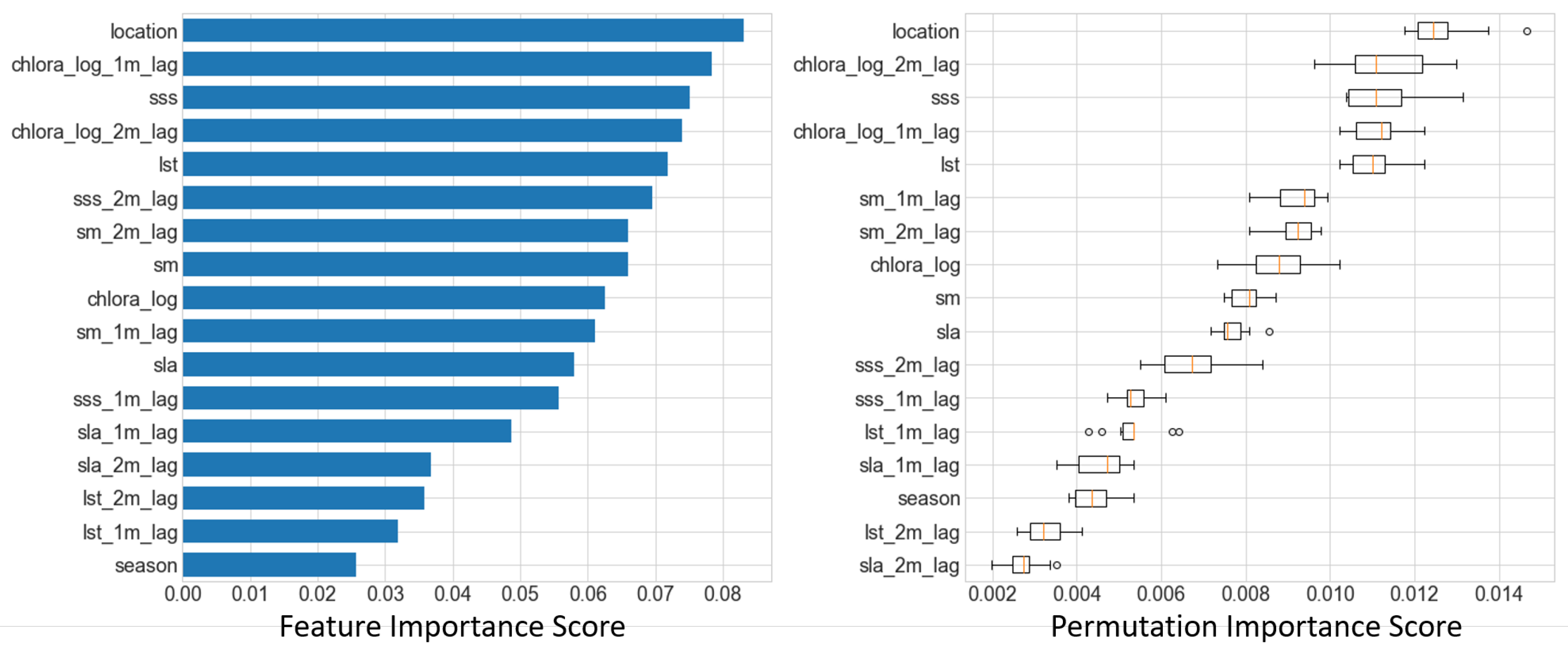
4.3. RF Model Feature Performance Analyses
4.4. Study Limitations and Opportunities
4.4.1. Metrics of Model Accuracy
4.4.2. Epidemiological Records of Cholera Outbreaks
4.4.3. Socio-Economic Conditions and Seasonal Extremes
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 1 m | 1 month lagged value |
| 2 m | 2 month lagged value |
| CCI | Climate Change Initiative |
| Chlora | Chlorophyll-a Concentration |
| ECV | Essential Climate Variable |
| ESA | European Space Agency |
| IDSP | Integrated Disease Surveillance Programme |
| LST | Land Surface Temperature |
| ML | Machine Learning |
| Portable Document Format | |
| Precip | Total Precipitation |
| RF | Random Forest |
| SLA | Sea Level Anomaly |
| SM | Soil Moisture |
| SSS | Sea Surface Salinity |
| SST | Sea Surface Temperature |
Appendix A




References
- Chowdhury, F.R.; Nur, Z.; Hassan, N.; von Seidlein, L.; Dunachie, S. Pandemics, pathogenicity and changing molecular epidemiology of cholera in the era of global warming. Ann. Clin. Microbiol. Antimicrob. 2017, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vezzulli, L.; Pruzzo, C.; Huq, A.; Colwell, R.R. Environmental reservoirs of Vibrio cholerae and their role in cholera. Environ. Microbiol. Rep. 2010, 2, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Lutz, C.; Erken, M.; Noorian, P.; Sun, S.; McDougald, D. Environmental reservoirs and mechanisms of persistence of Vibrio cholerae. Front. Microbiol. 2013, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Racault, M.F.; Abdulaziz, A.; George, G.; Menon, N.; C, J.; Punathil, M.; McConville, K.; Loveday, B.; Platt, T.; Sathyendranath, S.; et al. Environmental Reservoirs of Vibrio cholerae: Challenges and Opportunities for Ocean-Color Remote Sensing. Remote Sens. 2019, 11, 2763. [Google Scholar] [CrossRef] [Green Version]
- de Magny, G.C.; Murtugudde, R.; Sapiano, M.R.P.; Nizam, A.; Brown, C.W.; Busalacchi, A.J.; Yunus, M.; Nair, G.B.; Gil, A.I.; Lanata, C.F.; et al. Environmental signatures associated with cholera epidemics. Proc. Natl. Acad. Sci. USA 2008, 105, 17676–17681. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Lin, H.; Wang, X.; Austin, B. Significance of Vibrio species in the marine organic carbon cycle—A review. Sci. China Earth Sci. 2018, 61, 1357–1368. [Google Scholar] [CrossRef]
- Sharma, N.C.; Mandal, P.K.; Dhillon, R.; Jain, M. Changing profile of Vibrio cholerae O1, O139 in Delhi & its periphery (2003–2005). Indian J. Med. Res. 2007, 125, 633–640. [Google Scholar]
- Ali, M.; Nelson, A.R.; Lopez, A.L.; Sack, D.A. Updated Global Burden of Cholera in Endemic Countries. PLoS Negl.Trop. Dis. 2015, 9. [Google Scholar] [CrossRef] [Green Version]
- World Health Organisation. Cholera Cases Reported to WHO by Year and by Continent. Available online: https://www.who.int/gho/epidemic_diseases/cholera/en/ (accessed on 28 September 2020).
- Ahmad, H. Bangladesh coastal zone management status and future trends. J. Coast. Zone Manag. 2019, 22, 1–7. [Google Scholar]
- Registrar General of India, Ministry of Home Affairs, Government of India. Census (2011), Primary Census Abstracts. Available online: http://www.censusindia.gov.in/2011census/PCA/pcahighlights/pedata (accessed on 6 October 2020).
- Sathyendranath, S.; Abdulaziz, A.; Menon, N.; George, G.; Evers-King, H.; Kulk, G.; Colwell, R.; Jutla, A.; Platt, T. Building Capacity and Resilience Against Diseases Transmitted via Water Under Climate Perturbations and Extreme Weather Stress. In Space Capacity Building in the XXI Century; Springer International Publishing: Cham, Switzerland, 2020; pp. 281–298. [Google Scholar] [CrossRef]
- Brewin, R.J.W.; Brewin, T.G.; Phillips, J.; Rose, S.; Abdulaziz, A.; Wimmer, W.; Sathyendranath, S.; Platt, T. A Printable Device for Measuring Clarity and Colour in Lake and Nearshore Waters. Sensors 2019, 19, 936. [Google Scholar] [CrossRef] [Green Version]
- Borbor-Córdova, M.J.; Pozo-Cajas, M.; Cedeno-Montesdeoca, A.; Mantilla Saltos, G.; Kislik, C.; Espinoza-Celi, M.E.; Lira, R.; Ruiz-Barzola, O.; Torres, G. Risk Perception of Coastal Communities and Authorities on Harmful Algal Blooms in Ecuador. Front. Mar. Sci. 2018, 5. [Google Scholar] [CrossRef]
- Khan, R.; Aldaach, H.; McDonald, C.; Alam, M.; Huq, A.; Gao, Y.; Akanda, A.S.; Colwell, R.; Jutla, A. Estimating cholera risk from an exploratory analysis of its association with satellite-derived land surface temperatures. Int. J. Remote. Sens. 2019, 40, 4898–4909. [Google Scholar] [CrossRef]
- Lipp, E.K.; Huq, A.; Colwell, R.R. Effects of Global Climate on Infectious Disease: The Cholera Model. Clin. Microbiol. Rev. 2002, 15, 757–770. [Google Scholar] [CrossRef] [Green Version]
- Hermes, J.C.; Masumoto, Y.; Beal, L.M.; Roxy, M.K.; Vialard, J.; Andres, M.; Annamalai, H.; Behera, S.; D’Adamo, N.; Doi, T.; et al. A Sustained Ocean Observing System in the Indian Ocean for Climate Related Scientific Knowledge and Societal Needs. Front. Mar. Sci. 2019, 6. [Google Scholar] [CrossRef]
- Saji, N.H.; Goswami, B.N.; Vinayachandran, P.N.; Yamagata, T. A dipole mode in the tropical Indian Ocean. Nature 1999, 401, 360–363. [Google Scholar] [CrossRef] [PubMed]
- Ashok, K.; Guan, Z.; Yamagata, T. Impact of the Indian Ocean dipole on the relationship between the Indian monsoon rainfall and ENSO. Geophys. Res. Lett. 2001, 28, 4499–4502. [Google Scholar] [CrossRef] [Green Version]
- Ashok, K.; Guan, Z.; Yamagata, T. A Look at the Relationship between the ENSO and the Indian Ocean Dipole. J. Meteorol. Soc. Jpn. Ser. II 2003, 81, 41–56. [Google Scholar] [CrossRef] [Green Version]
- Ashok, K.; Yamagata, T. The El Niño with a difference. Nature 2009, 461, 481–484. [Google Scholar] [CrossRef]
- World Meteorological Organization (WMO); United Nations Educational, Scientific and Cultural Organization (UNESCO); United Nations Environment Programme (UNEP); International Council for Science, (ICSU); World Meteorological Organization (WMO). GCOS, 154. Systematic Observation Requirements for Satellite-Based Products for Climate Supplemental Details to the Satellite-Based component of the Implementation Plan for the Global Observing System for Climate in Support of the UNFCCC: 2011 Update; World Meteorological Organization: Geneva, Switzerland, 2011.
- Cash, B.A.; Rodó, X.; Kinter, J.L. Links between Tropical Pacific SST and Cholera Incidence in Bangladesh: Role of the Eastern and Central Tropical Pacific. J. Clim. 2008, 21, 4647–4663. [Google Scholar] [CrossRef]
- Lobitz, B.; Beck, L.; Huq, A.; Wood, B.; Fuchs, G.; Faruque, A.S.G.; Colwell, R. Climate and infectious disease: Use of remote sensing for detection of Vibrio cholerae by indirect measurement. Proc. Natl. Acad. Sci. USA 2000, 97, 1438–1443. [Google Scholar] [CrossRef] [Green Version]
- Montilla, R.; Chowdhury, M.A.; Huq, A.; Xu, B.; Colwell, R.R. Serogroup conversion of Vibrio cholerae non-O1 to Vibrio cholerae O1: Effect of growth state of cells, temperature, and salinity. Can. J. Microbiol. 1996, 42, 87–93. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Cao, C.; Wang, D.; Kan, B. Identifying Environmental Risk Factors of Cholera in a Coastal Area with Geospatial Technologies. Int. J. Environ. Res. Public Health 2015, 12, 354–370. [Google Scholar] [CrossRef] [PubMed]
- Kopprio, G.A.; Neogi, S.B.; Rashid, H.; Alonso, C.; Yamasaki, S.; Koch, B.P.; Gärdes, A.; Lara, R.J. Vibrio and Bacterial Communities Across a Pollution Gradient in the Bay of Bengal: Unraveling Their Biogeochemical Drivers. Front. Microbiol. 2020, 11, 594. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Colwell, R.R. Global Climate and Infectious Disease: The Cholera Paradigm*. Science 1996, 274, 2025–2031. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koelle, K.; Pascual, M.; Yunus, M. Pathogen adaptation to seasonal forcing and climate change. Proc. R. Soc. B Biol. Sci. 2005, 272, 971–977. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Islam, M.S.; Islam, M.S.; Mahmud, Z.H.; Cairncross, S.; Clemens, J.D.; Collins, A.E. Role of phytoplankton in maintaining endemicity and seasonality of cholera in Bangladesh. Trans. R. Soc. Trop. Med. Hyg. 2015, 109, 572–578. [Google Scholar] [CrossRef] [PubMed]
- Akanda, A.S.; Jutla, A.S.; Islam, S. Dual peak cholera transmission in Bengal Delta: A hydroclimatological explanation. Geophys. Res. Lett. 2009, 36. [Google Scholar] [CrossRef]
- Jutla, A.; Whitcombe, E.; Hasan, N.; Haley, B.; Akanda, A.; Huq, A.; Alam, M.; Sack, R.B.; Colwell, R. Environmental Factors Influencing Epidemic Cholera. Am. J. Trop. Med. Hyg. 2013, 89, 597–607. [Google Scholar] [CrossRef]
- Islam, M.S.; Sharker, M.A.Y.; Rheman, S.; Hossain, S.; Mahmud, Z.H.; Islam, M.S.; Uddin, A.M.K.; Yunus, M.; Osman, M.S.; Ernst, R.; et al. Effects of local climate variability on transmission dynamics of cholera in Matlab, Bangladesh. Trans. R. Soc. Trop. Med. Hyg. 2009, 103, 1165–1170. [Google Scholar] [CrossRef]
- Azman, A.S.; Lessler, J.; Luquero, F.J.; Bhuiyan, T.R.; Khan, A.I.; Chowdhury, F.; Kabir, A.; Gurwith, M.; Weil, A.A.; Harris, J.B.; et al. Estimating cholera incidence with cross-sectional serology. Sci. Transl. Med. 2019, 11. [Google Scholar] [CrossRef] [Green Version]
- Leo, J.; Luhanga, E.; Michael, K. Machine Learning Model for Imbalanced Cholera Dataset in Tanzania. Sci. World J. 2019, 2019, 9397578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- National Centre for Disease Control, Directorate General of Health Services. Integrated Disease Surveillance Programme. Available online: http://idsp.nic.in/ (accessed on 6 October 2020).
- University of California, Berkely. Global Administrative Areas. Digital Geospatial Data. 2020. Available online: http://www.gadm.org (accessed on 7 October 2020).
- Plummer, S.; Lecomte, P.; Doherty, M. The ESA Climate Change Initiative (CCI): A European contribution to the generation of the Global Climate Observing System. Remote Sens. Environ. 2017, 203, 2–8. [Google Scholar] [CrossRef]
- Merchant, C.J.; Embury, O.; Bulgin, C.E.; Block, T.; Corlett, G.K.; Fiedler, E.; Good, S.A.; Mittaz, J.; Rayner, N.A.; Berry, D.; et al. Satellite-based time-series of sea-surface temperature since 1981 for climate applications. Sci. Data 2019, 6, 223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reul, N.; Grodsky, S.; Arias, M.; Boutin, J.; Catany, R.; Chapron, B.; D’Amico, F.; Dinnat, E.; Donlon, C.; Fore, A.; et al. Sea surface salinity estimates from spaceborne L-band radiometers: An overview of the first decade of observation (2010–2019). Remote Sens. Environ. 2020, 242, 111769. [Google Scholar] [CrossRef]
- Legeais, J.F.; Ablain, M.; Zawadzki, L.; Zuo, H.; Johannessen, J.A.; Scharffenberg, M.G.; Fenoglio-Marc, L.; Fernandes, M.J.; Andersen, O.B.; Rudenko, S.; et al. An improved and homogeneous altimeter sea level record from the ESA Climate Change Initiative. Earth Syst. Sci. Data 2018, 10, 281–301. [Google Scholar] [CrossRef] [Green Version]
- Sathyendranath, S.; Brewin, R.J.W.; Brockmann, C.; Brotas, V.; Calton, B.; Chuprin, A.; Cipollini, P.; Couto, A.B.; Dingle, J.; Doerffer, R.; et al. An Ocean-Colour Time Series for Use in Climate Studies: The Experience of the Ocean-Colour Climate Change Initiative (OC-CCI). Sensors 2019, 19, 4285. [Google Scholar] [CrossRef] [Green Version]
- Dorigo, W.; Wagner, W.; Albergel, C.; Albrecht, F.; Balsamo, G.; Brocca, L.; Chung, D.; Ertl, M.; Forkel, M.; Gruber, A.; et al. ESA CCI Soil Moisture for improved Earth system understanding: State-of-the art and future directions. Remote Sens. Environ. 2017, 203, 185–215. [Google Scholar] [CrossRef]
- Gruber, A.; Dorigo, W.A.; Crow, W.; Wagner, W. Triple Collocation-Based Merging of Satellite Soil Moisture Retrievals. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 6780–6792. [Google Scholar] [CrossRef]
- Gruber, A.; Scanlon, T.; van der Schalie, R.; Wagner, W.; Dorigo, W. Evolution of the ESA CCI Soil Moisture climate data records and their underlying merging methodology. Earth Syst. Sci. Data 2019, 11, 717–739. [Google Scholar] [CrossRef] [Green Version]
- Ghent, D.; Veal, K.; Trent, T.; Dodd, E.; Sembhi, H.; Remedios, J. A New Approach to Defining Uncertainties for MODIS Land Surface Temperature. Remote Sens. 2019, 11, 1021. [Google Scholar] [CrossRef] [Green Version]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Hoyer, S.; Hamman, J. xarray: N-D labeled Arrays and Datasets in Python. J. Open Res. Softw. 2017, 5, 10. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K. Random Decision Forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; (ICDAR ’95). IEEE Computer Society: Washington, DC, USA, 1995; Volume 1, p. 278. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine Learning in Python. arXiv 2018, arXiv:1201.0490. [Google Scholar]
- Ong, J.; Liu, X.; Rajarethinam, J.; Kok, S.Y.; Liang, S.; Tang, C.S.; Cook, A.R.; Ng, L.C.; Yap, G. Mapping dengue risk in Singapore using Random Forest. PLoS Negl. Trop. Dis. 2018, 12, e0006587. [Google Scholar] [CrossRef] [Green Version]
- Carvajal, T.M.; Viacrusis, K.M.; Hernandez, L.F.T.; Ho, H.T.; Amalin, D.M.; Watanabe, K. Machine learning methods reveal the temporal pattern of dengue incidence using meteorological factors in metropolitan Manila, Philippines. BMC Infect. Dis. 2018, 18, 183. [Google Scholar] [CrossRef]
- Masinde, M. Africa’s Malaria Epidemic Predictor: Application of Machine Learning on Malaria Incidence and Climate Data. In Proceedings of the 2020 the 4th International Conference on Compute and Data Analysis, San Jose, CA, USA, 9–12 March 2020; ACM: Silicon Valley, CA, USA, 2020; pp. 29–37. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15, 276. [Google Scholar] [CrossRef]
- Hashizume, M.; Faruque, A.; Terao, T.; Yunus, M.; Streatfield, K.; Yamamoto, T.; Moji, K. The Indian Ocean Dipole and Cholera Incidence in Bangladesh: A Time-Series Analysis. Environ. Health Perspect. 2011, 119, 239–244. [Google Scholar] [CrossRef] [Green Version]
- Mao, W.; Wang, J.; Xue, Z. An ELM-based model with sparse-weighting strategy for sequential data imbalance problem. Int. J. Mach. Learn. Cybern. 2017, 8, 1333–1345. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Bouma, M.J.; Pascual, M. Seasonal and interannual cycles of endemic cholera in Bengal 1891–1940 in relation to climate and geography. Hydrobiologia 2001, 460, 147–156. [Google Scholar] [CrossRef]
- Jutla, A.S.; Akanda, A.S.; Islam, S. Tracking Cholera in Coastal Regions using Satellite Observations. J. Am. Water Resour. Assoc. AWRA 2010, 46, 651–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Escobar, L.E.; Ryan, S.J.; Stewart-Ibarra, A.M.; Finkelstein, J.L.; King, C.A.; Qiao, H.; Polhemus, M.E. A global map of suitability for coastal Vibrio cholerae under current and future climate conditions. Acta Trop. 2015, 149, 202–211. [Google Scholar] [CrossRef] [PubMed]
- Baker-Austin, C.; Trinanes, J.A.; Taylor, N.G.H.; Hartnell, R.; Siitonen, A.; Martinez-Urtaza, J. Emerging Vibrio risk at high latitudes in response to ocean warming. Nat. Clim. Chang. 2013, 3, 73–77. [Google Scholar] [CrossRef]
- Kanungo, S.; Sah, B.; Lopez, A.; Sung, J.; Paisley, A.; Sur, D.; Clemens, J.; Nair, G.B. Cholera in India: An analysis of reports, 1997–2006. Bull. World Health Organ. 2010, 88, 185–191. [Google Scholar] [CrossRef]
- del Rio, S.; Lopez, V.; Benitez, J.M.; Herrera, F. On the use of MapReduce for imbalanced big data using Random Forest. Inf. Sci. 2014, 285, 112–137. [Google Scholar] [CrossRef]
- Ting, K.M. An instance-weighting method to induce cost-sensitive trees. IEEE Trans. Knowl. Data Eng. 2002, 14, 659–665. [Google Scholar] [CrossRef] [Green Version]
- Dittman, D.J.; Khoshgoftaar, T.M.; Napolitano, A. The Effect of Data Sampling When Using Random Forest on Imbalanced Bioinformatics Data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 457–463. [Google Scholar] [CrossRef]
- Donlon, C.; Berruti, B.; Buongiorno, A.; Ferreira, M.H.; Féménias, P.; Frerick, J.; Goryl, P.; Klein, U.; Laur, H.; Mavrocordatos, C.; et al. The Global Monitoring for Environment and Security (GMES) Sentinel-3 mission. Remote Sens. Environ. 2012, 120, 37–57. [Google Scholar] [CrossRef]
- Platt, T.; Sathyendranath, S. Oceanic Primary Production: Estimation by Remote Sensing at Local and Regional Scales. Science 1988, 241, 1613–1620. [Google Scholar] [CrossRef]
- Huq, A.; West, P.A.; Small, E.B.; Huq, M.I.; Colwell, R.R. Influence of water temperature, salinity, and pH on survival and growth of toxigenic Vibrio cholerae serovar 01 associated with live copepods in laboratory microcosms. Appl. Environ. Microbiol. 1984, 48, 420–424. [Google Scholar] [CrossRef] [Green Version]
- Wommack, K.E.; Colwell, R.R. Virioplankton: Viruses in aquatic ecosystems. Microbiol. Mol. Biol. Rev. MMBR 2000, 64, 69–114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huq, A.; Sack, R.B.; Nizam, A.; Longini, I.M.; Nair, G.B.; Ali, A.; Morris, J.G.; Khan, M.N.H.; Siddique, A.K.; Yunus, M.; et al. Critical Factors Influencing the Occurrence of Vibrio cholerae in the Environment of Bangladesh. Appl. Environ. Microbiol. 2005, 71, 4645–4654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kopprio, G.A.; Streitenberger, M.E.; Okuno, K.; Baldini, M.; Biancalana, F.; Fricke, A.; Martínez, A.; Neogi, S.B.; Koch, B.P.; Yamasaki, S.; et al. Biogeochemical and hydrological drivers of the dynamics of Vibrio species in two Patagonian estuaries. Sci. Total. Environ. 2017, 579, 646–656. [Google Scholar] [CrossRef] [PubMed]
- Pascual, M.; Rodó, X.; Ellner, S.P.; Colwell, R.; Bouma, M.J. Cholera Dynamics and El Niño-Southern Oscillation. Science 2000, 289, 1766–1769. [Google Scholar] [CrossRef] [Green Version]
- Reyburn, R.; Kim, D.R.; Emch, M.; Khatib, A.; von Seidlein, L.; Ali, M. Climate variability and the outbreaks of cholera in Zanzibar, East Africa: A time series analysis. Am. J. Trop. Med. Hyg. 2011, 84, 862–869. [Google Scholar] [CrossRef] [Green Version]
- Government of India. Healthy States Progressive India: Report on the Ranks of States and Union Territories; Technical report; Government of India: New Delhi, India, 2019.
- Gupta, S.S.; Bharati, K.; Sur, D.; Khera, A.; Ganguly, N.K.; Nair, G.B. Why is the oral cholera vaccine not considered an option for prevention of cholera in India? Analysis of possible reasons. Indian J. Med. Res. 2016, 143, 545–551. [Google Scholar] [CrossRef]
- Ganesan, D.; Gupta, S.S.; Legros, D. Cholera surveillance and estimation of burden of cholera. Vaccine 2020, 38, A13–A17. [Google Scholar] [CrossRef]
- Gupta, S.S.; Ganguly, N.K. Opportunities and challenges for cholera control in India. Vaccine 2020, 38, A25–A27. [Google Scholar] [CrossRef]
- Zuckerman, J.N.; Rombo, L.; Fisch, A. The true burden and risk of cholera: Implications for prevention and control. Lancet Infect. Dis. 2007, 7, 521–530. [Google Scholar] [CrossRef]
- Ali, M.; Gupta, S.S.; Arora, N.; Khasnobis, P.; Venkatesh, S.; Sur, D.; Nair, G.B.; Sack, D.A.; Ganguly, N.K. Identification of burden hotspots and risk factors for cholera in India: An observational study. PLoS ONE 2017, 12, e0183100. [Google Scholar] [CrossRef] [Green Version]
- STOP Cholera. Cholera Surveillance: Detecting and Reporting Cases; Technical report; Johns Hopkins Bloomberg School of Public Health: Baltimore, MD, USA, 2016. [Google Scholar]
- Mukhopadhyay, A.K.; Deb, A.K.; Chowdhury, G.; Debnath, F.; Samanta, P.; Saha, R.N.; Manna, B.; Bhattacharya, M.K.; Datta, D.; Okamoto, K.; et al. Post-monsoon waterlogging-associated upsurge of cholera cases in and around Kolkata metropolis, 2015. Epidemiol. Infect. 2019, 147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Centre for Science and Environment. CSE Draft Dossier: Health and Environment: Environment and Diseases; Water Pollution and Health: A Deadly Burden; Technical Report; Centre for Science and Environment: New Delhi, India, 2006.
- Nkoko, D.B.; Giraudoux, P.; Plisnier, P.D.; Tinda, A.M.; Piarroux, M.; Sudre, B.; Horion, S.; Tamfum, J.J.M.; Ilunga, B.K.; Piarroux, R. Dynamics of Cholera Outbreaks in Great Lakes Region of Africa, 1978–2008-Volume 17, Number 11—November 2011-Emerging Infectious Diseases journal-CDC. Emerg. Infect. Dis. 2011. [Google Scholar] [CrossRef]
- Weill, F.X.; Domman, D.; Njamkepo, E.; Almesbahi, A.A.; Naji, M.; Nasher, S.S.; Rakesh, A.; Assiri, A.M.; Sharma, N.C.; Kariuki, S.; et al. Genomic insights into the 2016–2017 cholera epidemic in Yemen. Nature 2019, 565, 230–233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, R.; Anwar, R.; Akanda, S.; McDonald, M.D.; Huq, A.; Jutla, A.; Colwell, R. Assessment of Risk of Cholera in Haiti following Hurricane Matthew. Am. J. Trop. Med. Hyg. 2017, 97, 896–903. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
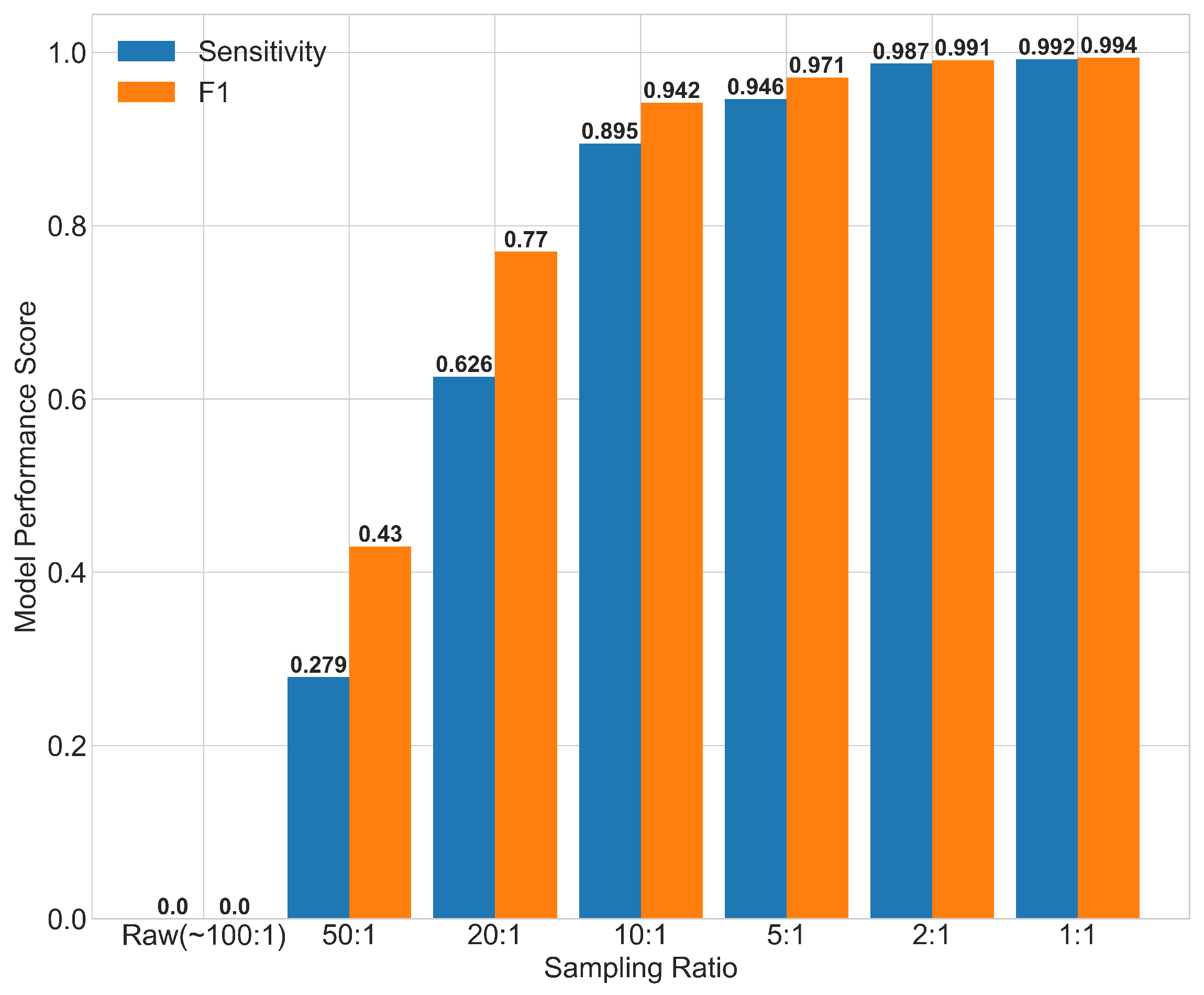{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Variable | Temporal Resolution | Spatial Resolution | Period | Reference | Source |
|---|---|---|---|---|---|---|
| CCI SST | Sea Surface Temperature (K) | Monthly | 0.05° | 2010–2018 | [39] | climate.esa.int |
| CCI Sea Surface Salinity | Sea Surface Salinity (psu) | 15 days | 25 km | 2010–2018 | [40] | climate.esa.int |
| CCI Sea Level | Sea Level Anomaly (m) | Monthly | 0.25° | 2010–2015 | [41] | climate.esa.int |
| CCI Ocean Colour | Chlorophyll-A Concentration (mg/m) | Monthly | 4 km | 2010–2018 | [42] | climate.esa.int |
| CCI Soil Moisture | Soil Moisture combined product (m/m) | Daily | 0.25° | 2010–2018 | [43,44,45] | climate.esa.int |
| CCI Land Surface Temperature | Average Day Land Surface Temperature (K) | Daily | 0.05° | 2010–2018 | [46] | climate.esa.int |
| ERA Interim | Synoptic Means of Total Precipitation (m) | Monthly | 0.75° | 2010–2018 | [47] | cds.climate.copernicus.eu |
| AVISO Altimetry | Sea Level Anomaly (m) | Monthly | 0.25° | 2016–2018 | AVISO+ | aviso.altimetry.fr |
| Test Data | Sensitivity | F1 Score | Accuracy |
|---|---|---|---|
| All seasons | 0.895 | 0.942 | 0.990 |
| Winter (JF) | 0.868 | 0.930 | 0.991 |
| Pre-monsoon (MAM) | 0.933 | 0.960 | 0.991 |
| Monsoon (JJAS) | 0.857 | 0.923 | 0.986 |
| Post-monsoon (OND) | 0.886 | 0.939 | 0.994 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Campbell, A.M.; Racault, M.-F.; Goult, S.; Laurenson, A. Cholera Risk: A Machine Learning Approach Applied to Essential Climate Variables. Int. J. Environ. Res. Public Health 2020, 17, 9378. https://doi.org/10.3390/ijerph17249378
Campbell AM, Racault M-F, Goult S, Laurenson A. Cholera Risk: A Machine Learning Approach Applied to Essential Climate Variables. International Journal of Environmental Research and Public Health. 2020; 17(24):9378. https://doi.org/10.3390/ijerph17249378
Chicago/Turabian StyleCampbell, Amy Marie, Marie-Fanny Racault, Stephen Goult, and Angus Laurenson. 2020. "Cholera Risk: A Machine Learning Approach Applied to Essential Climate Variables" International Journal of Environmental Research and Public Health 17, no. 24: 9378. https://doi.org/10.3390/ijerph17249378
APA StyleCampbell, A. M., Racault, M.-F., Goult, S., & Laurenson, A. (2020). Cholera Risk: A Machine Learning Approach Applied to Essential Climate Variables. International Journal of Environmental Research and Public Health, 17(24), 9378. https://doi.org/10.3390/ijerph17249378