
Efficacy of Artificial-Intelligence-Driven Differential-Diagnosis List on the Diagnostic Accuracy of Physicians: An Open-Label Randomized Controlled Study



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Study Participants
2.3. Materials
2.4. Interventions
2.5. Data Collection
2.6. Outcomes
2.7. Sample Size
2.8. Randomization
2.9. Statistical Methods
3. Results
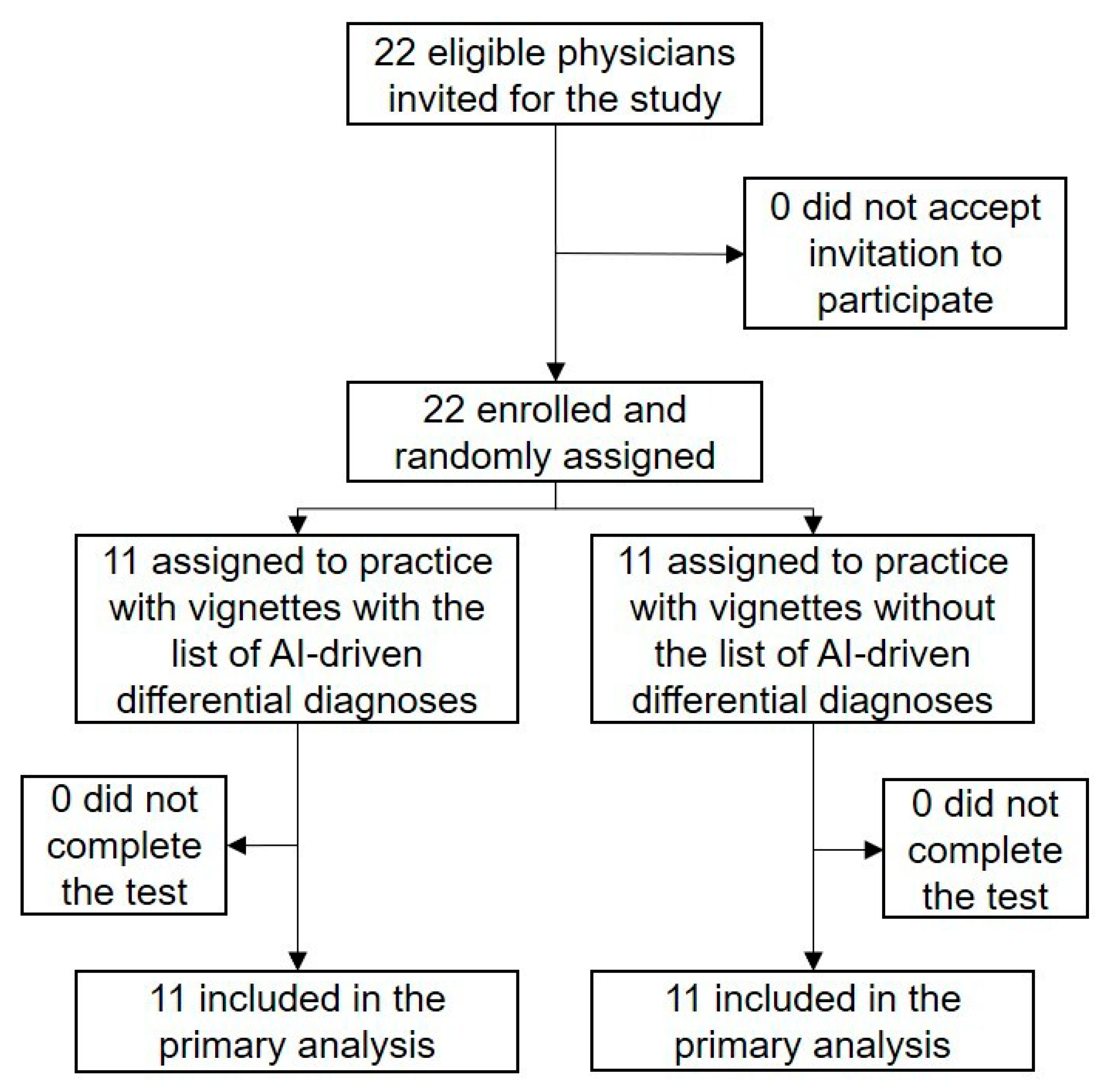
3.1. Participant Flow
3.2. Primary Outcome
3.3. Secondary Outcomes
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Tehrani, A.S.S.; Lee, H.; Mathews, S.C.; Shore, A.; Makary, M.A.; Pronovost, P.J.; Newman-Toker, D.E. 25-Year summary of US malpractice claims for diagnostic errors 1986–2010: An analysis from the National Practitioner Data Bank. BMJ Qual. Saf. 2013, 22, 672–680. [Google Scholar] [CrossRef]
- Watari, T.; Tokuda, Y.; Mitsuhashi, S.; Otuki, K.; Kono, K.; Nagai, N.; Onigata, K.; Kanda, H. Factors and impact of physicians’ diagnostic errors in malpractice claims in Japan. PLoS ONE 2020, 15, e0237145. [Google Scholar] [CrossRef] [PubMed]
- Singh, H.; Meyer, A.N.D.; Thomas, E.J. The frequency of diagnostic errors in outpatient care: Estimations from three large observational studies involving US adult populations. BMJ Qual. Saf. 2014, 23, 727–731. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kravet, S.; Bhatnagar, M.; Dwyer, M.; Kjaer, K.; Evanko, J.; Singh, H. Prioritizing Patient Safety Efforts in Office Practice Settings. J. Patient Saf. 2019, 15, e98–e101. [Google Scholar] [CrossRef]
- Matulis, J.C.; Kok, S.N.; Dankbar, E.C.; Majka, A.J. A survey of outpatient Internal Medicine clinician perceptions of diagnostic error. Diagn. Berl. Ger. 2020, 7, 107–114. [Google Scholar] [CrossRef] [PubMed]
- Coughlan, J.J.; Mullins, C.F.; Kiernan, T.J. Diagnosing, fast and slow. Postgrad Med. J. 2020. [Google Scholar] [CrossRef] [PubMed]
- Blease, C.; Kharko, A.; Locher, C.; DesRoches, C.M.; Mandl, K.D. US primary care in 2029: A Delphi survey on the impact of machine learning. PLoS ONE 2020, 15. [Google Scholar] [CrossRef]
- Semigran, H.L.; Linder, J.A.; Gidengil, C.; Mehrotra, A. Evaluation of symptom checkers for self diagnosis and triage: Audit study. BMJ 2015, 351, h3480. [Google Scholar] [CrossRef] [Green Version]
- Semigran, H.L.; Levine, D.M.; Nundy, S.; Mehrotra, A. Comparison of Physician and Computer Diagnostic Accuracy. JAMA Intern. Med. 2016, 176, 1860–1861. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, S.; Mehl, A.; Baluch, A.; Cawley, C.; Challiner, J.; Fraser, H.; Millen, E.; Montazeri, M.; Multmeier, J.; Pick, F.; et al. How accurate are digital symptom assessment apps for suggesting conditions and urgency advice? A clinical vignettes comparison to GPs. BMJ Open 2020, 10, e040269. [Google Scholar] [CrossRef] [PubMed]
- Kostopoulou, O.; Rosen, A.; Round, T.; Wright, E.; Douiri, A.; Delaney, B. Early diagnostic suggestions improve accuracy of GPs: A randomised controlled trial using computer-simulated patients. Br. J. Gen. Pract. 2015, 65, e49–e54. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Berry, A.C.; Berry, N.A.; Wang, B.; Mulekar, M.S.; Melvin, A.; Battiola, R.J.; Bulacan, F.K.; Berry, B.B. Symptom checkers versus doctors: A prospective, head-to-head comparison for cough. Clin. Respir. J. 2020, 14, 413–415. [Google Scholar] [CrossRef]
- Cahan, A.; Cimino, J.J. A Learning Health Care System Using Computer-Aided Diagnosis. J. Med. Internet Res. 2017, 19, e54. [Google Scholar] [CrossRef] [PubMed]
- Almario, C.V.; Chey, W.; Kaung, A.; Whitman, C.; Fuller, G.; Reid, M.; Nguyen, K.; Bolus, R.; Dennis, B.; Encarnacion, R.; et al. Computer-Generated vs. Physician-Documented History of Present Illness (HPI): Results of a Blinded Comparison. Am. J. Gastroenterol. 2015, 110, 170–179. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harada, Y.; Shimizu, T. Impact of a Commercial Artificial Intelligence-Driven Patient Self-Assessment Solution on Waiting Times at General Internal Medicine Outpatient Departments: Retrospective Study. JMIR Med. Inform. 2020, 8, e21056. [Google Scholar] [CrossRef] [PubMed]
- Schwitzguebel, A.J.-P.; Jeckelmann, C.; Gavinio, R.; Levallois, C.; Benaïm, C.; Spechbach, H. Differential Diagnosis Assessment in Ambulatory Care with an Automated Medical History–Taking Device: Pilot Randomized Controlled Trial. JMIR Med. Inform. 2019, 7, e14044. [Google Scholar] [CrossRef] [Green Version]
- Sujan, M.; Furniss, D.; Grundy, K.; Grundy, H.; Nelson, D.; Elliott, M.; White, S.; Habli, I.; Reynolds, N. Human factors challenges for the safe use of artificial intelligence in patient care. BMJ Health Care Inform. 2019, 26. [Google Scholar] [CrossRef] [Green Version]
- Grissinger, M. Understanding Human Over-Reliance on Technology. P T Peer Rev. J. Formul. Manag. 2019, 44, 320–375. [Google Scholar]
- Friedman, C.P.; Elstein, A.S.; Wolf, F.M.; Murphy, G.C.; Franz, T.M.; Heckerling, P.S.; Fine, P.L.; Miller, T.M.; Abraham, V. Enhancement of clinicians’ diagnostic reasoning by computer-based consultation: A multisite study of 2 systems. JAMA 1999, 282, 1851–1856. [Google Scholar] [CrossRef] [Green Version]
- Mamede, S.; De Carvalho-Filho, M.A.; De Faria, R.M.D.; Franci, D.; Nunes, M.D.P.T.; Ribeiro, L.M.C.; Biegelmeyer, J.; Zwaan, L.; Schmidt, H.G. ‘Immunising’ physicians against availability bias in diagnostic reasoning: A randomised controlled experiment. BMJ Qual. Saf. 2020, 29, 550–559. [Google Scholar] [CrossRef] [Green Version]
- Krupat, E.; Wormwood, J.; Schwartzstein, R.M.; Richards, J.B. Avoiding premature closure and reaching diagnostic accuracy: Some key predictive factors. Med. Educ. 2017, 51, 1127–1137. [Google Scholar] [CrossRef] [PubMed]
- Mujinwari (In Japanese). Available online: http://autoassign.mujinwari.biz/ (accessed on 19 February 2021).
- Van den Berge, K.; Mamede, S.; Van Gog, T.; Romijn, J.A.; Van Guldener, C.; Van Saase, J.L.; Rikers, R.M. Accepting diagnostic suggestions by residents: A potential cause of diagnostic error in medicine. Teach. Learn. Med. 2012, 24, 149–154. [Google Scholar] [CrossRef] [PubMed]
- Van den Berge, K.; Mamede, S.; Van Gog, T.; Van Saase, J.; Rikers, R. Consistency in diagnostic suggestions does not influence the tendency to accept them. Can. Med. Educ. J. 2012, 3, e98–e106. [Google Scholar] [CrossRef] [PubMed]
- Singh, H.; Giardina, T.D.; Meyer, A.N.D.; Forjuoh, S.N.; Reis, M.D.; Thomas, E.J. Types and origins of diagnostic errors in primary care settings. JAMA Intern. Med. 2013, 173, 418–425. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
| Order | Case Description | Diagnosis | Included in AI-Driven Top 10 List of Differential Diagnosis |
|---|---|---|---|
| 1 | 73-year-old female Fever and cough | Pneumonia | No |
| 2 | 38-year-old male Thirst and frequent urination | Diabetes mellites (Type 2) | Yes (ranked first) |
| 3 | 90-year-old female Constipation, pedal edema, and appetite loss | Heart failure | No |
| 4 | 84-year-old female Cough, wheeze, and hemoptysis | Asthma | Yes (ranked first) |
| 5 | 53-year-old male Lower abdominal pain and fever | Diverticulitis | No |
| 6 | 68-year-old male Cough, diarrhea, and appetite loss | Subacute myocardial infarction | No |
| 7 | 44-year-old male Abdominal pain | Pancreatitis (alcoholic) | Yes (ranked eighth) |
| 8 | 81-year-old female Appetite loss, arthralgia, and low-grade fever | Pyelonephritis | No |
| 9 | 73-year-old female Epigastric pain | Pancreatitis (autoimmune) | No |
| 10 | 20-year-old male Pain in the heart, arms, and neck | Myocarditis | Yes (ranked fifth) |
| 11 | 30-year-old female Chest pain | Pneumothorax | No |
| 12 | 71-year-old female Dyspnea and epigastric discomfort | Heart failure | Yes (ranked fourth) |
| 13 | 20-year-old male Sore throat, swelling of the throat, feeling of oppression in the throat | Peritonsillar abscess | Yes (ranked first) |
| 14 | 49-year-old female Cough and fever | Pneumonia (atypical) | Yes (ranked ninth) |
| 15 | 53-year-old male Malaise, frequent urination, and fatigue | Hyperosmolar hyperglycemic state | No |
| 16 | 63-year-old male Hematochezia | Ischemic colitis | Yes (ranked first) |
| With AI-Driven Differential-Diagnosis List | Without AI-Driven Differential-Diagnosis List | p Value | |
|---|---|---|---|
| Age (years), median (25–75th percentile) | 30 (28–33) | 30 (28–36) | 0.95 |
| Sex | 0.41 1 | ||
| male | 7/11 (63.6%) | 9/11 (81.8%) | |
| female | 4/11 (36.4%) | 2/11 (18.2%) | |
| Post graduate year, median (25–75th percentile) | 3 (2–8) | 4 (3–10) | 0.49 |
| Experience | >0.99 1 | ||
| intern | 3/11 (27.2%) | 2/11 (18.2%) | |
| resident | 4/11 (36.4%) | 4/11 (36.4%) | |
| attending physician | 4/11 (36.4%) | 5/11 (45.4%) | |
| Trust AI | 6/11 (54.5%) | 7/11 (63.6%) | 0.70 1 |
| With AI-Driven Differential-Diagnosis List | Without AI-Driven Differential-Diagnosis List | p Value | |
|---|---|---|---|
| Total | 101/176 (57.4%) | 99/176 (56.3%) | 0.91 |
| Sex | |||
| Male | 63/112 (56.3%) | 82/144 (56.9%) | >0.99 |
| Female | 38/64 (59.4%) | 17/32 (53.1%) | 0.72 |
| Experience | |||
| Intern | 23/48 (47.9%) | 12/32 (37.5%) | 0.49 |
| Resident | 40/64 (62.5%) | 41/64 (64.1%) | >0.99 |
| Attending physician | 38/64 (59.4%) | 46/80 (57.5%) | 0.95 |
| Trust in AI | |||
| Yes | 51/96 (53.1%) | 63/112 (56.3%) | 0.76 |
| No | 50/80 (62.5%) | 36/64 (56.3%) | 0.56 |
| Crude Odds Ratio (95% CI) | p Value | Adjusted Odds Ratio (95% CI) | p Value | |
|---|---|---|---|---|
| Male | 0.97 (0.61–1.56) | 0.91 | 0.66 (0.36–1.23) | 0.20 |
| Trust AI | 0.82 (0.53–1.26) | 0.36 | 1.12 (0.62–2.01) | 0.71 |
| Experience (reference: intern) | ||||
| Resident | 2.22 (1.25–3.92) | 0.01 | 3.35 (1.67–7.01) | 0.001 |
| Attending physician | 1.80 (1.04–3.13) | 0.04 | 2.84 (1.24–6.50) | 0.01 |
| With AI-driven differential-diagnosis list | 1.05 (0.69–1.60) | 0.83 | 1.10 (0.67–1.80) | 0.72 |
| Vignette including correct AI-driven differential diagnosis | 7.08 (4.39–11.42) | <0.001 | 7.68 (4.68–12.58) | <0.001 |
| Crude Odds Ratio (95% CI) | p Value | Adjusted Odds Ratio (95% CI) | p Value | |
|---|---|---|---|---|
| Male | 2.72 (0.97–7.62) | 0.06 | 6.25 (1.84–21.2) | 0.003 |
| Trust AI | 2.57 (1.02–6.48) | 0.04 | 1.03 (0.31–3.41) | 0.96 |
| Experience (reference: interns) | ||||
| Resident | 0.43 (0.16–1.15) | 0.09 | 0.20 (0.06–0.70) | 0.01 |
| Attending physician | 0.31 (0.11–0.90) | 0.03 | 0.14 (0.03–0.65) | 0.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harada, Y.; Katsukura, S.; Kawamura, R.; Shimizu, T. Efficacy of Artificial-Intelligence-Driven Differential-Diagnosis List on the Diagnostic Accuracy of Physicians: An Open-Label Randomized Controlled Study. Int. J. Environ. Res. Public Health 2021, 18, 2086. https://doi.org/10.3390/ijerph18042086
Harada Y, Katsukura S, Kawamura R, Shimizu T. Efficacy of Artificial-Intelligence-Driven Differential-Diagnosis List on the Diagnostic Accuracy of Physicians: An Open-Label Randomized Controlled Study. International Journal of Environmental Research and Public Health. 2021; 18(4):2086. https://doi.org/10.3390/ijerph18042086
Chicago/Turabian StyleHarada, Yukinori, Shinichi Katsukura, Ren Kawamura, and Taro Shimizu. 2021. "Efficacy of Artificial-Intelligence-Driven Differential-Diagnosis List on the Diagnostic Accuracy of Physicians: An Open-Label Randomized Controlled Study" International Journal of Environmental Research and Public Health 18, no. 4: 2086. https://doi.org/10.3390/ijerph18042086