Abstract
Multimorbidity refers to the coexistence of two or more chronic diseases in one person. Therefore, patients with multimorbidity have multiple and special care needs. However, in practice it is difficult to meet these needs because the organizational processes of current healthcare systems tend to be tailored to a single disease. To improve clinical decision making and patient care in multimorbidity, a radical change in the problem-solving approach to medical research and treatment is needed. In addition to the traditional reductionist approach, we propose interactive research supported by artificial intelligence (AI) and advanced big data analytics. Such research approach, when applied to data routinely collected in healthcare settings, provides an integrated platform for research tasks related to multimorbidity. This may include, for example, prediction, correlation, and classification problems based on multiple interaction factors. However, to realize the idea of this paradigm shift in multimorbidity research, the optimization, standardization, and most importantly, the integration of electronic health data into a common national and international research infrastructure is needed. Ultimately, there is a need for the integration and implementation of efficient AI approaches, particularly deep learning, into clinical routine directly within the workflows of the medical professionals.
1. Introduction
Societies in industrialized countries worldwide are facing an increasing burden of chronic diseases, including type 2 diabetes, cardiovascular and neurodegenerative diseases, and various cancers. This negative trend is the result of an aging population and the prevalence of “modern” lifestyles, such as the consumption of industrially processed foods, predominantly sedentary work, and increasing chronic psychological stress, which are known to accelerate aging and the development of age-related diseases [1,2].
Chronic diseases in the same person rarely appear as a single disease; instead, two or more diseases coexist, which is called multimorbidity [3]. Patients with multimorbidity raise a concern of both policymakers and healthcare providers because of the complex care needs, which requires various healthcare providers and services to deliver care for these patients [4]. The general practitioners (GPs) are faced with the demanding task of integrating different recommendations and prescriptions of these multiple providers [5].
Moreover, current clinical guidelines are disease-oriented, further complicating decision making for these patients [6]. Even recommendations for managing single diseases for these patients may be uncertain because patients with multimorbidity are usually excluded from clinical trials. The delivery of care and the patient self-management may be constrained by complicated medication regimens and information burden [5]. Recommendations that are given to a patient for several single diseases may be mutually conflicting and produce harm rather than good [7].
Multimorbidity has been shown to have a significant negative impact on patient outcomes, and not all patients with multimorbidity have the same risk for adverse outcomes. It has been shown to depend on the number of comorbidities, but also on certain combinations of diseases that a person has [8]. Some disease combinations occur randomly, as some diseases are very common in the population, such as hypertension, while other diseases tend to accumulate [9]. Disease clustering is usually based on common pathophysiology, as evident from the common appearance of cardio-metabolic and vascular disorders, although in some cases, causes are less clear [10]. However, the classical methods of measuring multimorbidity that have been used in epidemiologic surveys and are based on counting diseases are not adequate to capture reliable pre-existing conditions. [11,12].
There is no knowledge base to adequately address multimorbidity problems in terms of patient-centered solutions in predicting specific outcomes and determining personalized treatments [13,14]. This is due to the fact, that no methodological framework has been developed that adequately manages the complexity of multimorbidity. To clarify what we mean by complexity, we illustrate it in the following examples.
Typically, in an older population (>60), when the number of chronic diseases increases, the prevalence of mental disorders, such as anxiety and depression, also increases [15,16]. Somatic and mental disorders are not wholly distinct, as these two share some common mechanisms, such as in associations of mental disorders with cardio-metabolic and chronic pain conditions [17,18,19]. The significance of these findings lies in the demonstrated adverse effects of mental disorders on the course of chronic somatic diseases and on health outcomes, which may justify actively seeking these disorders in older, multimorbid patients in primary care settings [20,21,22].
Another feature of aging and multimorbidity is the presence of health conditions beyond the traditional diagnostic label that can negatively affect the quality of life and functional abilities of older people [23,24]. Of these conditions, which include disorders including walking difficulties, vision and hearing loss, impaired balance, dizziness, predispositions for falls, incontinence, chronic pain, and delirium, cognitive impairment and frailty, have attracted the most attention of researchers due to the proven impact of these disorders on important adverse outcomes, such as dementia, disabilities, and ultimately death [23,25]. Frailty is defined as the state of decreased homeostatic reserves in multiple physiologic systems, presented with symptoms of shrinking, slowness, and weakness, and can be considered as the final common pathway in the development of multimorbidity [25,26]. Cognitive impairment is a highly prevalent disorder in the elderly, and its progression towards dementia is increased in persons with cardiovascular disorders, especially when there is comorbidity with depression [27]. The disabling effect on health is highest in cases where there is a coexistence of frailty with cognitive impairment [28].
The examples described above illustrate the complex relationships that exist in older people between somatic illnesses and psychological, cognitive, and functional impairments. The degree of complexity is even greater when the effects of treatments are included in the consideration of multimorbidity. In addition to beneficial effects, pharmacologic treatment, especially when given for multiple indications, can also be counterproductive because of unpredictable drug-disease interactions. Indeed, many symptoms and functional limitations in the elderly are the result of pharmacological treatments [24].
Understanding this complexity proves challenging, as the study of patients with multimorbidity must go beyond the scope of well-defined categories, such as disease labels. Because classical statistical methods cannot provide an adequate framework for stratifying these patients, there is a need for a more comprehensive research framework [14].
One possible solution seems to lie in the AI approaches of machine learning (ML) and Big Data (BD) technologies, which have already provided fruitful results in solving complex problems in many other areas of human activity, such as industry, finance, and marketing [29,30].
The purpose of this review is to summarize the limitations of current approaches to data analysis and to present the potential and shortcomings of alternative methods in multimorbidity research. The recently published paper by Hassaine et al. provided an in-depth analysis of methodological advances in identifying multimorbidity-associated patterns hidden in data sequences in electronic health records (eHRs) and methods for tracking the time courses of these patterns [31]. On the contrary, in fact, because our overview shows what the problem of multimorbidity research looks like in the eyes of medical professionals.
Consequently, this paper aims to increase the understanding of medical laypersons of the essential ML/BD research approaches and provides some tips on how to overcome barriers to broader implementation of these methods in multimorbidity research, with the ultimate goal of improving the quality of medical practice. The authors reflect on these issues based on their work experiences and emphasize the need for closer collaboration between medical experts and data scientists throughout the complex problem-solving process, from problem definition to data and method selection to interpretation of research results.
2. The Time for the Paradigm Change in Research on Multimorbidity
In the classical research approach of the medical field, the scope of research questions is limited to those for which answers can be provided within the set of well-defined statistical methods. Data analysis is driven by the well-defined hypothesis to be proven or rejected (a hypothesis-driven approach). The prerequisite for this approach is a well-documented knowledge base and a data set collected according to strict protocols [32].
The multiple regression models (MLR) of classical statistics, as essential tools for making predictions, are methods per se, i.e., the structure of the model is predetermined and remains fixed during the modeling process [30]. The MLR models are based on the assumptions of the independence of the input variables, linearity between dependent and independent variables, normality of the residuals (proposing the balanced data distribution), and the absence of endogenous (confounding) variables [33]. The strong rules on which the models rely, limit the scope of research questions and the types of data that can be used for analysis. For example, these models are not suitable for problems that do not fit the linear models or utilize a large number of variables [34]. Only classical statistical methods are not enough to address multimorbidity questions, where components are mutually interrelated within the complex network. So, the components’ emerging properties, not only the component number and the structure, maybe a critical determinant of the outcome.
Suppose we want the theoretical paradigm shift in research on multimorbidity to reach the level of a practical implementation. In this case, we need to change the approach to problem solving in medical research [35].
In addition to the classical, reductionist approach, which dominates scientific reasoning today, the approach from the aspect of the complex systems should be used as a complementary one when studying phenomena associated with chronic diseases and multimorbidity.
The scientific reasoning that relies on the paradigm of reductionism states that the cause-effect relationships in the real world can be described by a limited set of logical rules and static mathematical models [36]. This concept assumes that the system, to be understood, should be broken into its components, and then analysed. Scientific reasoning relies on durable logic and clear hypotheses, which excludes contradictions or uncertainties.
However, biological systems behave like complex systems [37]. In a complex system, its property emerges through interactions of its components. The distinct phenomena that arise from these interactions include: spontaneous order (self-organisation), non-linear relationships (change in one entity does not correspond with constant change in the other entity), redundancy (the existence of several complementary pathways), feedback loops (a chain of cause-and-effect that makes not possible a conclusion on the causal relationships), and a high level of adaptability (functionality). It is always important to note that many diverse modalities contribute to a decision [38].
Based on research in molecular science and epidemiological observations, the evidence is growing to allow for an integrated view on aging and the development of chronic diseases and multimorbidity. This process can be represented by a range of trajectories that differ in dynamics of chronic diseases and functional impairment accumulation over time [39]. The person’s position at the trajectory is influenced by the interplay of inner and outer factors, including genetics, environmental, social, and lifestyle factors, and the dynamics of their change over time.
This view can be placed within the concept of complexity in biological systems, according to which aging is the process of progressive disruption in the multiple communication channels, which otherwise connect organs, control systems, and regulatory loops, allowing for information to flow between them [40]. The disruption in these communication channels is associated with a decline in the body’s functional capabilities and the dispersion of phenotypes, in the form of the appearance of aging diseases, disabilities, and frailty [36,40]. Although being heterogeneous, older people are yet significantly like each other due to overlapping disorders.
The adoption of scientific reasoning from the aspect of the complex systems is expected to improve our ability to make conclusions on phenomena associated with multimorbidity, despite the lack of knowledge on relationships that exist between the components of the system. This type of thinking takes multiple elements into account when making conclusions and operates with the terms “chance/probability”, rather than “causality/determination” [36]. In searching for ways and methods for solving complex problems, pieces of different theories, mixed methodologies, and interdisciplinary approaches can be used together [36]. The choice of methods is a great part of the researcher’s responsibility and depends on his/her knowledge and intuition (and is, to some extent, subjective).
3. The Machine Learning/Big Data Approaches and Challenges in Research on Chronic Diseases and Multimorbidity
Due to the invention of new technologies in medicine and healthcare, in the last decades, such as digital imaging techniques and molecular biology diagnostics, and to the establishment of patient registries and electronic HRs in many countries in Europe and wider, there has been a rapid growth in data quantity and complexity, in both medical research and clinical practice. It made the classical research approach no more sufficient to meet the challenges of the data analysis. The methods and techniques from ML/BD of AI approaches have been emerging to provide alternative solutions [29,30] (Table 1).

Table 1.
Descriptions of the key terms in Machine Learning and Big Data AI research approaches [41,42,43,44,45].
This alternative research approach has on disposition a broad range of analytical tools which application is a part of the knowledge discovery (KD) multi-step protocol of data analysis, in which the step “pattern extraction in data” precedes the step “evaluation of the knowledge base”, this data analytical approach being called “a data-driven approach” [41,42].
Algorithms and tools from this research approach have been compiled from different analytical fields, including mathematics, statistics, and computer science, to let the computers analyze datasets that are large in volume, require a high-velocity analysis, and shows a high level of diversity and complexity (high-level dimensionality, complex relationships, and other complications) (Table 2) [41,42,43,44].
Table 2.
The list of methods in Machine Learning/Big Data-AI research approach [31,41,42,46].
The ML/BD analytical approach enables challenging the paradigm shift in medical science and healthcare towards precision medicine [45].
The typical representation of the association rule is IF X THEN Y, where X, Y are subsets from a whole set of items [47]. ARM represents a popular mining method because of its easily interpretable results as a set of rules. TARs express that a set of items tends to appear along with another set of items in the same transactions, in a specific time frame [48].
LR is a method of modelling the probability of an outcome that can only have two values [49]. It aims to find the best fitting model describing the relationship between the dichotomous variable (dependent variable–it contains data coded as 1/0, TRUE/FALSE, yes/no, etc.) and asset of independent variables.
NB requires a small number of training data to estimate the parameters necessary for classification [50]. It uses the probabilities of each attribute belonging to each class to make a prediction. NB simplifies the calculation of probabilities by assuming that the probability of each attribute belonging to a given class value is independent of all other attributes. To make a prediction, it calculates the probabilities of the instance belonging to each class and selects the class value with the highest probability.
DTs is a flowchart-like tree structure, where each non-leaf node represents a test on an attribute, each branch represents an outcome of the test, and leaf nodes represent target classes or class distributions, see Figure 1. Each DTs algorithm uses its own splitting criteria like information gain or Ginni-index to create branches and leaves [51]. In the case of the new record, this goes through the branches based on related conditions and finishes in the leaf node, after which no further branching is possible. And this leaf node determines a target class for the new record with relevant accuracy or other metrics.
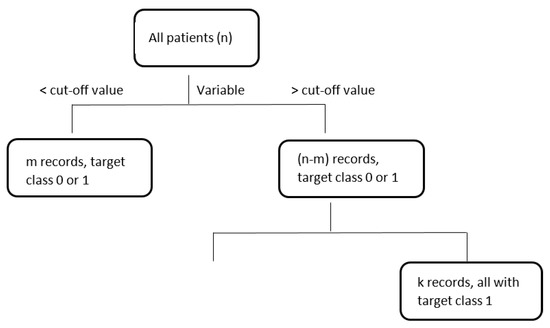
Figure 1.
An example of decision tree.
RF model consists of a collection of tree-structured classifiers. It uses a bagging method, i.e., it contains the randomly sampled subsets of the training data, fitting a model to these smaller data sets, and aggregating the predictions [52]. An out-of-bag-error is used as an estimate of the generalization error.
SVM plots each record as a point in n-dimensional space (where n is a number of input variables) [53]. The value of each variable represents an ordinate. Then, SVM performs classification by finding a hyperplane distinguishing the two target classes very well, see Figure 2. This algorithm is not suitable for the larger datasets because of a long training time.
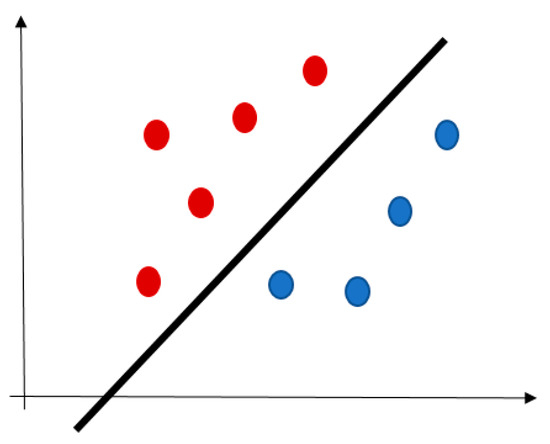
Figure 2.
An example of SVM hyperplane (red and blue points are the training records).
Neural networks are a computational model inspired by biological neural networks, which is based on a large collection of simple connected units called artificial neurons, see Figure 3. We will use this method if we do not want to know the decision mechanism. They work like a black box, i.e., we know the model is some non-linear combination of some neurons, each of which is some non-linear combination of some other neurons, but it is near impossible to say what each neuron is doing [54]. This approach is opposite to the DT or SVM.
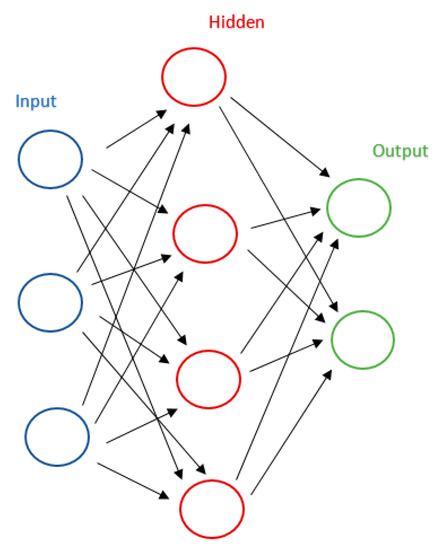
Figure 3.
An example of three-layers neural networks.
A cluster is a collection of data that describes objects like each other but dissimilar to objects in different clusters, see Figure 4. The K-mean algorithm aims to partition a set of objects into k clusters so that the resulting intra-cluster similarity is high and the inter-cluster similarity is low [55]. The intra-cluster similarity is measured with the mean value of distances between the objects in the cluster, which can be considered as the cluster’s centre.
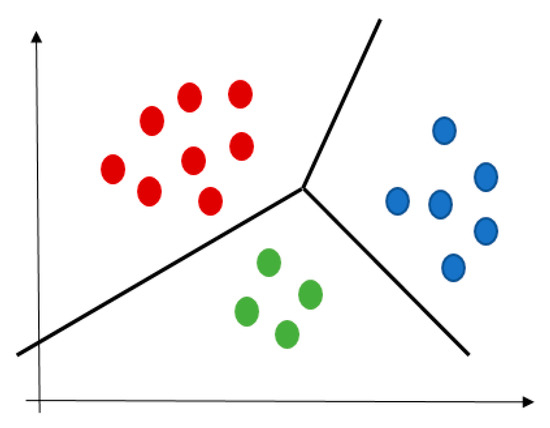
Figure 4.
An example of clustering result, individual colors represent different clusters.
KNN is commonly based on the Euclidean distance between a test sample and the specified training samples [56]. The output is a class membership, i.e., the record is classified by a majority vote of its neighbors, with the record being assigned to the class most common among its k-nearest neighbors, see Figure 5. A user specifies the parameter k.
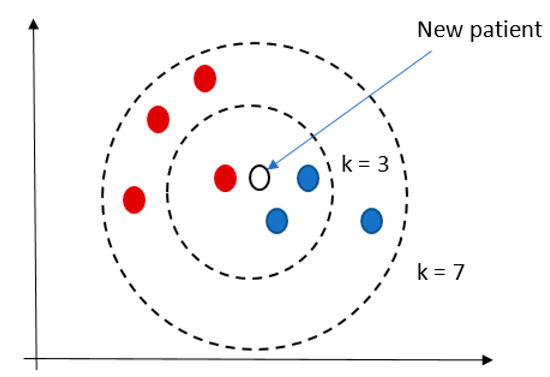
Figure 5.
An example of KNN result.
PC analysis allows a visualization of the data set in order to reduce the dimensionality of multivariate data to two or three principal components with minimal loss of information [57]. These components correspond to a linear combination of the originals and represent the data’s maximum variance direction.
SOMs are representative of NN used for dimensionality reduction. This method is based on UNV learning to produce a low-dimensional, discretized representation of the training samples’ input space [58]. Its representation is called a map and uses a neighborhood function to preserve the topological properties of the input space, see Figure 6.
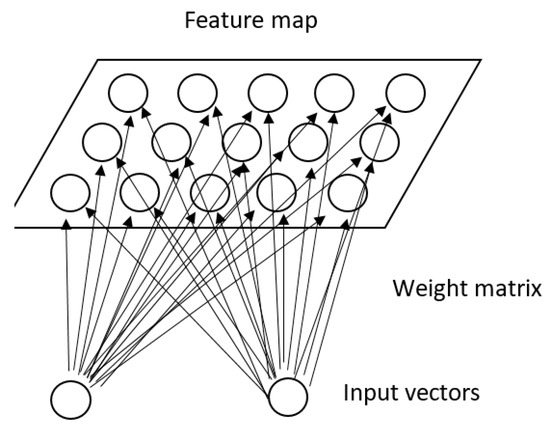
Figure 6.
An example of SOM.
LCA is a statistical method for identifying unmeasured class membership among subjects using categorical and/or continuous observed variables [59].
Graph-based DM is typically applied on databases represented as graphs and mines topological substructures embedded in the data [60]. The goal is not only extracting the structure but identify potential interesting substructures.
NLP represents the automatic handling of natural human languages like speech or text that gives computers or robots the ability to understand the human languages, e.g., disease prediction based on the health records or patient’s speech [61].
NMF and its extension called NTF are emerging methods to decompose a nonnegative data matrix into a product of lower-rank nonnegative matrices or tensors (i.e., multiway arrays) [62]. The results are sparse and easily interpretable.
The algorithms of ML/BD techniques applied to the dataset must often learn about the data structure to obtain the model that is yielding the optimal description of the data, which makes them distinct from the rigorous MLR models of the classical statistics [32,33]. In addition, the ML/BD-AI research approach allows for a wider scope of research questions by allowing methods to adapt to the research question. It is likely to bring clinical studies into the real-world scenario, in which population heterogeneity is not an obstacle for performing research [29,43]. Yet, the critical point that makes the ML/BD-AI research approach favorable for studying multimorbidity, over the classical statistical methods is the ability of this approach to revealing the latent spaces and time trends in the data, irrespective of the data structure. The complex data structure in problems associated with multimorbidity arises from multiple and overlapping disorders and causing factors, external sociodemographic and internal biological, and poorly understood mechanisms that drive the dynamics between them (Table 3) [41,45,63].
Table 3.
The arguments to use the Machine Learning/Big Data-AI approaches in research on multimorbidity [29,30,45].
A tendency of ML procedures for automatization is likely to diminish the role of a medical expert in the analytic process. However, it is not valid. This role is important because most medical domain problems are challenging and cannot be solved solely by applying the automated process of data analysis and without the medical expert’s guidance [64].
The majority of studies performed so far have faced some of the concepts of the ML/BD research approach, such as, i.e., the use of the large datasets to generate the alternative models (compared to those that are used in clinical practice), personalized adjustment of the guidelines’ recommendations, and the use of a combination of data sources to discover new biomarkers or to identify unknown mechanisms. These studies have yet to stay within the framework of the theory of reductionism, focusing on studying single diseases, whereas an integrated approach that on the contrary, would be more suitable to cope with the complexity of multimorbidity has stayed out of the scope. Many of these studies were shown useful in narrowing questions associated with multimorbidity and in creating new hypotheses, but they are not sufficient to answer the questions related to clustering of multiple diseases, which otherwise would be necessary to establish the efficient prevention and management strategies to cure people with multimorbidity.
Some of the questions that would be of interest for practicing doctors to be provided by the answers, include: which patients with multiple comorbidities are at risk for which specific outcomes, and which ones would benefit from which treatments; which risk factors and pathophysiology disorders refer to which patient groups, and which mechanisms are responsible for patient transition from one trajectory to another?
The most prevalent topics were those related to early diagnosis, personalized treatment, and prediction of outcomes of some chronic diseases, such as cancer, diabetes, and Alzheimer’s dementia. These diseases are known for their serious outcomes and are associated with many comorbidities so that by themselves, they are characterized with a high level of complexity. With the recent invention of high throughput (-omics) techniques in the medical domain that were thought to realize personalized patient care, the ML/BD analytical methods have received an additional stimulus for development.
In a review paper focusing on the current methods for cancer risk and recurrence prediction, Richtera and Khoshgoftaara discussed methodological concerns associated with the modelling process [65]. The authors emphasize the value of the structured data that is widely available in eHRs and national registries, such as clinical, social, and behavioral data, for modelling cancer prediction and prognosis at the population level. The molecular medicine data, such as data from genomics and proteomics, could be useful in determining personalized treatments but is not feasible for population screening. Techniques used in the models, either statistical method, are the cox proportional hazard regression model and the risk survival analysis, or ML methods, like SVM, ANNs, DTs, and RF. Most often, however, a combination of methods is used to achieve a valid prediction model. The data analyst should work closely with the domain expert in determining which type of models works best for which research problem.
In the paper specifically focused on using ML methods for cancer prediction and prognosis, Kourou et al. emphasized the ability of ML tools, like SVM, DTs, ANNs, and BNs, for detecting the key features from the large and yet unexplored input space in order to provide the accurate predictive models that can be used in everyday practice [46]. By the selection of new features used from an unknown input space, these models could enlarge the knowledge of factors that may influence cancer development and progression. This way, these models could fuel further research. A similar idea stayed behind the study of Rajan and Prakash [66]. These authors developed the ANN model for early diagnosis of lung cancer using the information on behavioral and social risk factors and symptoms, rather than on images and laboratory findings, making this model broadly accessible. This approach is valuable from the practical perspective, knowing that lung cancer is a leading cancer cause of death. There are no blood biomarkers or some simple methods that could be used for screening in the population.
Similar methodological issues burden the modelling procedures associated with the diagnosis and progression of diabetes type 2. In Zou et al., the emphasis is put on the importance of data pre-processing and reduction methods, and on the model generalization methods, as prerequisites for creating accurate ML models for diabetes diagnosis prediction [67]. Without the participation of a medical expert, who is able to define the research problem exactly define the research problem, there is a threat that the modelling procedure will serve merely as a confirmatory analysis of the applied ML method, without any detachment made from the existing knowledge. In the study of Sacchi et al., on the contrary, the problem was tackled on diabetes as a chronic disease, which progression over time is associated with accumulation of complications, and for which, the prediction is challenging to perform [68]. In this study, information was used on changes over time in medication prescription rates, together with a time series analysis, to the model prediction of chronic diabetic complications. How prediction of diabetes complications can be difficult when numerous variables interact in a complex and non-linear manner, and throughout the disease process, it was illustrated in the study of Yousefi L, et al. [69]. An intriguing issue is how to cope with the complex biological structure and dynamics of change over time. To solving this task, it would require complicated methods and modelling procedures. The authors stated that the best way to cope with this complexity is by dividing patients into smaller, more homogeneous phenotypic subgroups. They compared these fixed (latent) phenotypes with temporal changes of clusters consisting of the association rules. However, the results of this hybrid methodology are challenging for interpretation in the real-life context. Without the knowledgeable domain expert’s input, such procedures might turn into endless and meaningless mining over the data streams.
Our research group has long-term experience in applying ML methods for solving complex clinical tasks associated with chronic aging diseases. Our studies provide a confirmation that in medical research, there are often conditions for small dataset studies. This appears when there is a need to perform research at the institutional level, or when eHRs are not transformed into a modality for research, or when the size of the dataset is constrained by the complexity and high cost of large-scale experiments [70]. The ideal platforms for exploratory studies represent all the properties of the investigated populations. In line with this approach, small studies require that participants be described with multiple features [71,72].
From the perspective of our own experience, we can state that close collaboration and a good mutual understanding between the medical expert and the data analyst is necessary throughout the entire process of data analysis, from data collection (selection), methods selection to the interpretation of the results, and in any case of problem-solving tasks [73]. We can also state with confidence that there is a need for using several analytical methods in most tasks, where data visualization techniques can substantially improve understanding of the results. Yet by combining and integrating all results within the common context, we can achieve a more comprehensive view of the problem of interest [74].
Our work that was focused on discovering the health status components that determine older primary care patients with multimorbidity who responded poorly to influenza vaccination can be considered a pioneer work in approaching the problem of complexity of multimorbidity [75]. By learning through our own work, we have realized that the clinical context’s high dimensionality in older people with multiple comorbidities, due to phenomena such as multiple relationships, non-linearity, and overlapping between disorders, makes the difficult division of individuals into clearly separated groups. In this case, and if the clinical endpoint is a binary label (positive vs. negative disease or procedure outcomes), methods should be used for patient phenotyping that is robust and does not require strong assumptions on the distributions and interdependence of the predictors, such as, i.e., ANNs [76]. The high dimensionality of the data can be reduced by using some of the subspace analysis techniques, such as “subspace clustering”, complemented with the visual exploration methods [77]. The recent developments in constructing different DL methods for feature extraction from eHR data have shown successful inpatient phenotyping and outperforms the classical feature extraction algorithms [78]. When using these techniques, the challenging issue is interpretation of the results, as the analyst may choose between several model options. Different parameter settings may result in different model sets. Besides, various reasons may cause the outcome, and the domain expert should discuss the reliability of the results.
The ML/BD-AI approaches also have disadvantages, which makes the barriers for the direct implementation into clinical practice of the research results obtained by using these approaches (Table 4) [79,80,81,82].
Table 4.
Disadvantages in using the Machine Learning/Big Data-AI approaches in research on multimorbidity [14,78,79,80,81,82].
4. Current State and Future Perspective in Using Machine Learning/Big Data Analytics in Research on Multimorbidity
4.1. New Approaches in Multimorbidity Research Associated with Patterns and Clusters
The ML/BD methods in multimorbidity research have firstly been used in epidemiologic surveys in order to reduce the large number of disease combinations, as obtained by numbering disease dyads and triads, and to try to unify the disease patterns between the studies, by learning on the spontaneous disease gathering [10,83]. Different methods have been used, including logistic regression analysis, hierarchical clustering methods, such as LCA, and exploratory factor analysis, whereas the data sources included eHRs, national registries, and questionnaires filled out by primary care physicians [84,85,86]. Overall, and as the comparative method analysis has recently confirmed, multimorbidity patterns, although some overlap can be observed due to domination of the frequent diseases in the multimorbidity patterns, vary depending on the spectrum of diseases, investigated population, and the method of analysis, indicating the need for study design standardization [87]. Based on the results of this study, it is suggested that the factorization methods are better to use for describing comorbidity relationships, and that clustering methods are more useful as exploratory studies, when performing in a depth analysis. ARM is typically used to investigate disease associations and explore common patterns [88,89,90]. The tree-based approach produces results that allow an identification of specific combinations of chronic conditions or syndromes [91,92].
Our research group used non-hierarchical (k-means) and hierarchical (LCA) cluster analyses in the pilot exploratory study, aimed at getting some insights into the mechanisms that might have stayed behind the clustering of physical frailty and cognitive impairment–the two major aging entropy states [93,94]. We had firstly targeted these functional disorders, and then provided descriptions of the identified clusters by assessing differences in diagnoses of chronic diseases and other clinical and socio-demographic variables, by means of phenotyping the heterogeneous patients at risk for these outcomes. On the contrary, the expert author group from Italy, had performed the disease-based clusters, and then assessed differences in clinical and functional status of individuals in the clusters, such providing some insights into the mechanisms underlying disease clustering [95]. These authors applied the fuzzy c-means algorithm as a clustering method, also known as “the soft clustering method” [96]. This method is more scalable than the classical “hard clustering methods”, as uses the distribution of probabilities, rather than the level of similarity, among the objects (features or individuals), as the basis for assigning a membership to the clusters.
Over the past few years, there is an increasing trend in using methods of DL and data from eHRs for the tasks such as patient phenotyping, disease feature detection or classification, and clinical outcomes prediction based on longitudinal sequences of events, that are expected to improve solving tasks associated with multimorbidity [78,97]. Many developments in DL are used for mapping reliable concepts in raw or minimally-processed data in eHRs (embedding techniques), including textual medical notes, which concepts are then used for temporal sequencing and predicting the outcomes [41,98]. For example, Meng et al. used information on lines of therapy for cancer patients from the large insurance claim dataset to identify treatment pathways. These authors created an algorithm to derive a patient-level lines of therapy and aggregated this information via clustering and data visualization methods, to derive temporal phenotypes and support disease progression prediction [99]. Zhao et al. applied a modified non-negative tensor-factorization approach (a technique used for discovering latent object variables in image analysis) on eHRs data in order to identify phenotypic subtypes in patients at risk for cardiovascular disease. By combining ARM with the estimated risk of each subtype for the development of cardiovascular disease, these authors could identify some previously unknown phenotypes [100]. Nguyen et al. developed a modified convolutional neural network (CNN) model for predicting the probability of hospital readmission, based on medical history information used as a sequence of concepts [101]. Choi et al. developed a modified recurrent neural network (RNN) model for predicting diagnoses and medication prescriptions in the subsequent visits [102]. Although these case studies were aimed at facing the complexity of chronic diseases, they still hardly cope with the complexity of multimorbidity.
Some techniques from the reinforcement learning framework are used to provide to physicians the data-driven decision support for the treatment options that will likely to optimally prevent disease worsening, based on predicting future health states by using longitudinal sequences from eHRs [103].
A general trend, nowadays, in assessing multimorbidity, is to move from disease-only to multi-modal presentation of phenotypes, including also information on medications, laboratory findings and functional health status, in addition to disease labels, in order to achieve better understanding of disease pathways. To meet this challenge, new algorithms and matrices have been developed, with improved capabilities to handle large and multi-modal datasets, and to extract hidden information from them, as presented in the recent review paper of Hassaine et al. [31]. The major innovations include a shift from static to probabilistic implementations of basic ML methods, that allows a shift from qualitative descriptive to quantitative test methods, and developments in “deep phenotyping”. The latter term indicates efforts for establishing features of patient subgroups that are comprehensive enough to be stable across the layers of the complex data structures, and during the phenotype’s progression or the generation of new disease connections [104].
The presentation of temporal dynamics of multiple interactions inherent to multimorbidity is a special challenge for data scientists as it requires more sophisticated algorithms and a multi-step analytics, that go beyond a case-control classification and the use of linear regression analysis to show its progression over time [105,106,107]. The study designs for learning about temporal dynamics of this complexity are still poorly developed and are maintained within the framework of unsupervised learning (an outcome is not known) and disease-disease relationships [31,107]. Although data scientists have an absolute authority in building these sophisticated data analytics, without incorporation of domain knowledge in creation of the research task and evaluation of the interpretability of the performed analytics, the real-life usability of these innovations will be questionable [104]. When considering questions associated with multimorbidity, it may require inference to be made under the conditions of uncertainty and incomplete and contradicting knowledge. Methods different from traditional ML, such as the argumentation theory, can better perform in learning such tasks [108,109]. For these new models, the knowledge of the domain expert might be critical for fulfilling the research task.
4.2. The Ways to Improve Implementation of Machine Learning/Big Data Approaches in Research on Multimorbidity
Examples that follow reveal some essential potentials of the ML/BD analytics in the healthcare domain, including the possibility of finding new concepts from routinely collected data to support diagnosis and even improve disease classification, as well as the possibility of using unstructured data, such as the plain text, or images, that otherwise could not be impossible. Automatization, a feature representation without the need for manual efforts and ad hoc input by an expert, is another possibility. Finally, ML/BD analytics is possible in linking eHRs from different platforms and healthcare settings.
Liang et al. constructed a clinical decision support system so that they applied a DL model (a modified version of deep belief network) to extract general concepts from the medical notes (unsupervised task) used from the outpatient clinic and hospital eHRs [110]. The original datasets were combinations of unstructured data (written symptoms and signs in the plain text) and structured data (laboratory data and socio-demographic data). After the network of the DL model had been trained to obtain features from the original (raw) data, the network parameters of the DL model (weights) were tuned in a supervised manner by using SVM as a classical classification model. The extracted features (encoded by the hidden layers of DL model) were further modelled to fit the target outcome measures. Those were diagnoses of some common diseases encoded according to the international classification.
Many similar projects can be found in the recent literature, where authors used either the disease-specific registries or eHRs, and either time-sequential or cross-sectional patterns, to model patient features to support/predict diagnosis disease activity. Norgeot et al. applied a longitudinal deep learning model to model structured data (indicating medications, laboratories, patient demographics and disease activity) from two large hospital registries of patients with rheumatoid arthritis, to predict disease activity at the next visit [111]. By comparing the models’ performances from the two settings, it is possible to assess the quality of care and evaluate the model interoperability. The aggregated eHRs of about 700,000 patient records from the Mount Sinai data warehouse were used to perform unsupervised patient representation models. The models were evaluated by assessing the probability of patients developing certain diseases [112].
The presented examples demonstrate a high potential of the ML/BD research approach in improving diagnosis and prognosis for single chronic diseases, which otherwise may be complicated and labor-intensive procedures. However, the design of these studies still does not capture the full range complexity of multimorbidity, because single diseases are used as target variables and because of the lack of patient division into subgroups that could more specifically reflect differences in developmental disease stages.
The design of the study of Peng et al. is closer to this concept [113]. The authors used the Taiwanese national health insurance research database to develop the ML (a random forest method) cumulative deficit frailty index (a data-driven approach) and compare it to the conventional index for which the selection of features is based on expert opinion (a hypothesis-driven approach) [114]. What is interesting in this study is that authors stratified patients in several groups according to the risk for important adverse outcomes, such as all-cause mortality, hospitalizations, and intensive unit care admissions, using survival analyses (the Kaplan-Meier survival curves and Cox models); classical statistical methods. This study’s design is coherent with the integrated theory of aging, proposing aging as the subsequent decline in functional capabilities of older individuals due to disruption in physiological connections and the dispersion of phenotypes [39,40].
Like the idea of this study, our research group assumes that, when studying multimorbidity problems, the multi-modal data that describe patients with many aspects should create the input of classification or prediction models. That measures of health status functional decline, rather than disease labels, should be used as the outcome measures [93,94]. In line with the paradigm of complex thinking, the authors in this study used a combination of well-proven methods, prioritizing the problem-solving task over the assessment of new techniques.
Managing treatment recommendations for patients with multimorbidity is a difficult problem due to complex disease and medication dependencies. Zhang et al. proposed an algorithm to decompose the treatment recommendation into a sequential decision-making process while automatically determining the appropriate number of medications based on reinforcement learning [115] (RL). It removes 99.8% of adverse drug interactions in the recommended treatment sets. Zheng et al. trained an RL prescription algorithm recommending a treatment regimen optimizing patients’ cumulative health outcomes using their individual characteristics and medical history. In general, the application of RL in healthcare is focused mainly on treatment recommendation problem. However, in practice, it is quite unpractical to identify relevant outcomes for every performed action during the medical process.
Also, challenging, in older persons with multimorbidity, is the problem of predicting medical risks. This question has been traditionally answered by experienced clinicians, who have seen many patients and are familiar with clinical guidelines, or by linear prediction models with well-defined risk factors. Both strategies being more suitable in the context of a single disease than in the context of multimorbidity [6]. Pham et coll. presented an advanced temporal architecture based on using a deep dynamic neural network method for predicting disease progression, recommended interventions, and hospital admissions, based on medical history information [116]. The authors solved important problems in predicting future risks based on temporal sequences used from eHRs, such as long- and short-term dependency between changes in health status, irregular timing and episodic recording of episodes of care, and interactions between interventions and disease progression. This solution is still insufficient to handle the complexity of multimorbidity, as it uses only coded features from eHRs (diagnoses, procedures, and medications) and targets single diseases’ progression. In the study of Hassaine et al., it was shown, using the matrix factorization method, how disease clusters progress over time, forming multimorbidity networks. An interpretation of the results is questionable, as the real clinical utility is not easy to see [107].
The research group from Catalonia has been engaged in defining multimorbidity patterns in a large elderly (≥65 years) population from primary care, using data from Information System for Research in Primary Care (SIDIAP) [117,118,119]. Primary care setting, where older patients with chronic medical conditions regularly encounter and where information on their health history and different aspects of care are routinely collected in eHRs, represents a unique point for longitudinal analysis of multimorbidity patterns. In the recent cross-sectional study (2019) they used a fuzzy cluster analysis (allows individuals to be linked simultaneously to multiple clusters, that is more consistent with clinical experience than other approaches) to identify multimorbidity clusters, and obtained something different clusters than in an older study (2012), where they used a combination of multiple correspondence analysis (for categorical variables) and k-means clustering (for numerical variables) to identify clusters [117,118]. In this older study, the authors followed the obtained clusters for six years and showed that the initially defined clusters are relatively stable on change over time (as determined by the number and % of patients retained in the cluster at the end of the follow-up period).
In their most recent study, this group of authors at baseline used a cross-sectional design and a fuzzy cluster analysis to identify multimorbidity patterns, and then modelled longitudinal trajectories of multimorbidity patterns with a Hidden Markov Model (an approximation for solving complex ML and reinforcement learning problems when, i.e., there is a need for modelling transition across multimorbidity patterns and mortality risk), with some additional algorithms used for linking the inter cluster transition probabilities with the initial cluster probabilities [119]. The authors’ estimated a five-year survival rates for multimorbidity patterns with Cox regression models. Additional variables, indicating socio-demographics and the number of medications and visits, were used to analyse the pathophysiology background of disease clustering and the cluster temporal evolution. The multimorbidity trajectories were shown generally stable over time, which makes a basis for on-time targeting specific multimorbidity patterns with preventive measures.
The Catalonian research group’s presented studies are more clinically sound than most others and give some directions for the population management of multimorbidity. A major complaint is that functional impairments, such as frailty, are not included in the analysis, while it is known that frailty status may significantly change disease presentation and mortality risk [120]. Moreover, information on laboratory tests and body shape measures, as we showed in our work, may provide additional information for disease severity stratification due to the progressive nature of chronic diseases [93,94].
That the number and type of chronic diseases implicate the level of physical and overall functioning over time and with advancing age, was shown in the studies of Stenholm et al. and Vetrano et al. [105,121]. Modelling the temporal transitions of disease clusters with the decline in older persons’ functional capabilities with multimorbidity jointly, is a further challenge in modelling the multimorbidity complexity.
The studies mentioned above have revealed some puzzling situations that burden the actual research on multimorbidity. The problem has its clinical science perspective and the data science perspective. Concerning the clinical side of the problem, a significant concern is the lack of consensus on the definition of multimorbidity and the variable scope of diseases (or other disorders) used to create the clusters [122]. The heterogeneity of cluster identification methods further contributes to the variability of multimorbidity patterns that can be found in various studies [123]. Only a few studies on the temporal evolution of multimorbidity patterns are insufficient to guide future study designs.
On the data science side, the problem lies in the rapid advancement of ML/BD algorithms with ever improving modeling performance, which makes it enormously difficult to compare studies and further delays the implementation of research results [124]. Moreover, variations in datasets, and a range of ML/BD methods that are available for analysis of the same task, may cause variations of the results, and investigators often simultaneously apply several methods to compare their efficiency [125]. Despite the undoubted benefit to research, routinely collected data from eHRs have been established primarily for administrative and clinical trial purposes, making these data potentially inadequate for proposed research [126,127]. Data from eHRs also suffer from shortcomings such as data incompleteness, irregular sampling, and data imbalance, which need alternative methods in the evaluation of machine learning algorithms for medical classification and diagnostic testing [128]. Data scientists are developing various pre-processing and dimensionality reduction methods and approaches to overcome these shortcomings [129]. For solving complex tasks, data scientists use a combination of methods or create complicated protocols, which differ inefficiency to one another. Although there is a tendency for the absolute automatization of the analytic process, which aims to reduce the manual efforts, without the influence of the domain expert in all phases of data analysis, the obtained results may be too complicated, puzzling, and practically useless [97,104].
In trying to solve these problems, consensus groups should be formed among medical experts as well as data scientists and AI experts who, each on his or her own side, would move things forward. By working together in interdisciplinary teams, these expert groups could facilitate the validation and standardization of methods and the establishment of common research protocols, like the process of developing clinical guidelines. The creation of a list of well-defined research questions or target outcomes by medical experts is a prerequisite for identifying patient risk groups, modeling data from electronic health records, and creating the most appropriate care plans. Population health management would be more meaningful than it is today if an efficient and less time-consuming process for assessing risk for older, multimorbid patients in primary care were established and continuously improved. To participate more competently in this process, physicians, especially general practitioners, who are the first to encounter multimorbid patients and have the greatest responsibility for data collection in primary care physicians’ eHRs, should receive more training in the capabilities of ML/BD techniques and quantitative methods for data analysis [130].
5. Conclusions
Population-based health management for older people (≥60 years) is inadequate. This is largely because the delivery of personalized care and preventive interventions is limited by the inadequacies of traditional research designs and data analysis methods. This large segment of the population is characterized by increasing complexity of chronic diseases and multimorbidity (two or more chronic diseases in the same person). An alternative research approach based on ML/BD methods has emerged as a real alternative with high potential to address the problems associated with multimorbidity. These problems include, for example, phenotyping of patients and risk stratification based on modeling of multiple interrelated traits that overlap between individuals. Further, identifying patterns of chronic health conditions in the population, as well as tracking progression as health conditions worsen over time in individuals with multiple health conditions. The challenges that need to be addressed to successfully implement this research approach into routine clinical practice mainly relate to the need to establish better coordination between medical experts and data scientists, AI researchers, and IT experts to implement common and validated research protocols tested in real-world conditions and to build a true interdisciplinary knowledge base. From this growing knowledge base, consisting of case studies solving various problems arising from clinical practice, it will be possible in the future to develop new interdisciplinary-based guidelines and recommendations for the management of multimorbidity.
Author Contributions
The article was prepared, written, edited, and finished by all the authors collectively. All authors have read and agreed to the published version of the manuscript.
Funding
The work was supported by The Slovak Research and Development Agency under grants no. APVV-16-0213 and APVV-17-0550. Parts of this work have received funding from the Austrian Science Fund (FWF) through project P-32554 “A reference model of explainable Artificial Intelligence for the Medical Domain”.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Acknowledgments
We thank the organization CNPQ (Brazilian National Council for Scientific and Technological Development). This entity provided support that was invaluable to our research.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ogura, S.; Jakovljevic, M.M. Editorial, Global population aging—Health care, social and economic consequences. Front. Public Health 2018, 6, 335. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Urbanization and Health. Bull. World Health Org. 2010, 88, 241–320. [Google Scholar]
- Barnett, K.; Mercer, S.W.; Norbury, M.; Watt, G.; Wyke, S.; Guthrie, B. Epidemiology of multimorbidity and implications for health care, research and medical education, A cross-sectional study. Lancet 2012, 38, 37–43. [Google Scholar] [CrossRef]
- Sevick, M.A.; Trauth, J.; Ling, B.S.; Anderson, R.T.; Piatt, G.A.; Kilbourne, A.M.; Goodman, R.M. Patients with complex chronic diseases, perspectives on supporting self-management. J. Gen. Intern. Med. 2007, 22, 438–444. [Google Scholar] [CrossRef] [PubMed]
- Wallace, E.; Salisbury, C.; Guthrie, B.; Lewis, C.; Fahey, T.; Smith, S.M. Managing patients with multimorbidity in primary care. BMJ 2015, 350, h176. [Google Scholar] [CrossRef] [PubMed]
- Boyd, C.; Smith, C.D.; Masoudi, F.A.; Blaum, C.S.; Dodson, J.A.; Green, A.R.; Kelley, A.; Matlock, D.; Ouellet, J.; Rich, M.W.; et al. Decision making for older adults with multiple chronic conditions, Executive Summary for the American Geriatrics Society Guiding Principles on the Care of Older Adults With Multimorbidity. J. Am. Geriatr. Soc. 2019, 67, 665–673. [Google Scholar] [CrossRef] [PubMed]
- Heleno, B.; Silvério-Rodrigues, D. Multimorbidity and the challenge to deliver personalised and meaningful health care. Port. J. Public Health 2019, 37, I–III. [Google Scholar] [CrossRef]
- Onder, G.; Palmer, K.; Navickas, R.; Jurevičienė, E.; Mammarella, F.; Strandzheva, M.; Mannucci, P.; Pecorelli, S.; Marengoni, A. Time to face the challenge of multimorbidity. A European perspective from the joint action on chronic diseases and promoting healthy ageing across the life cycle (JA-CHRODIS). Eur. J. Intern. Med. 2015, 26, 157–159. [Google Scholar] [CrossRef]
- Gijsen, R.; Hoeymans, N.; Schellevis, F.G.; Ruwaard, D.; Satariano, W.A.; van den Bos, G.A. Causes and consequences of comorbidity. A review. J. Clin. Epidemiol. 2001, 54, 661–674. [Google Scholar] [CrossRef]
- Sinnige, J.; Braspenning, J.; Schellevis, F.; Stirbu-Wagner, I.; Westert, G.; Korevaar, J. The prevalence of disease clusters in older adults with multiple chronic diseases—A systematic literature review. PLoS ONE 2013, 8, e79641. [Google Scholar] [CrossRef]
- De Vries, N.M.; Staal, J.B.; van Ravensberg, C.D.; Hobbelen, J.S.M.; Olde Rikkert, M.G.M.; Nijhuis-van der Sanden, N.W.G. Outcome instruments to measure frailty: A systematic review. Ageing Res. Rev. 2011, 10, 104–114. [Google Scholar] [CrossRef] [PubMed]
- Stirland, L.E.; González-Saavedra, L.; Mullin, D.S.; Muniz-Terrera, D. Measuring multimorbidity beyond counting diseases, systematic review of community and population studies and guide to index choice. BMJ 2020, 368, m127. [Google Scholar] [CrossRef]
- Muth, C.; Blom, J.W.; Smith, S.M.; Johnell, K.; Gonzalez-Gonzalez, A.I.; Nguyen, T.S.; Brueckle, M.S.; Cesari, M.; Tinetti, M.E.; Valderas, J.M. Evidence supporting the best clinical management of patients with multimorbidity and polypharmacy, a systematic guideline review and expert consensus. J. Intern. Med. 2019, 285, 272–288. [Google Scholar] [CrossRef] [PubMed]
- Fröhlich, H.; Balling, R.; Beerenwinkel, N.; Kohlbacher, O.; Kumar, S.; Lengauer, L.; Maathuis, M.H.; Moreau, Y.; Murphy, S.A.; Przytycka, T.M.; et al. From hype to reality: Data science enabling personalized medicine. BMC Med. 2018, 16, 150. [Google Scholar] [CrossRef] [PubMed]
- Read, J.R.; Sharpe, L.; Modini, M.; Dear, B.F. Multimorbidity and depression, A systematic review and meta-analysis. J. Affect. Dis 2017, 221, 36–46. [Google Scholar] [CrossRef] [PubMed]
- Gould, C.E.; O’Hara, R.; Goldstein, M.K.; Beaudreau, S.A. Multimorbidity is associated with anxiety in older adults in the Health and Retirement Study. Int J. Geriatr. Psychiatry 2016, 31, 1105–1115. [Google Scholar] [CrossRef]
- Kohrt, B.A.; Griffith, J.L.; Patel, V. Chronic pain and mental health, integrated solutions for global problems. Pain 2018, 159, S85–S90. [Google Scholar] [CrossRef]
- Jank, R.; Gallee, A.; Boeckle, M.; Fiegl, S.; Pieh, C. Chronic pain and sleep disorders in primary care. Pain Res. Treat. 2017, 2, 9081802. [Google Scholar] [CrossRef] [PubMed]
- Alexopoulos, G.S. The vascular depression hypothesis, 10 years later. Biol. Psychiatry 2006, 60, 1304–1305. [Google Scholar] [CrossRef]
- Valiengo, L.C.; Stella, F.; Forlenza, O.V. Mood disorders in the elderly, prevalence, functional impact, and management challenges. Neuropsychiatr. Dis. Treat. 2016, 12, 2105–2114. [Google Scholar]
- Moussavi, S.; Chatterji, S.; Verdes, E.; Tandon, A.; Patel, V.; Ustun, B. Depression, chronic diseases, and decrements in health, Results from the World Health Surveys. Lancet 2007, 370, 851–858. [Google Scholar] [CrossRef]
- Fiske, A.; Wetherell, J.L.; Gatz, M. Depression in older adults. Annu Rev. Clin. Psychol 2009, 5, 363–389. [Google Scholar] [CrossRef]
- Inouye, S.K.; Studenski, S.; Tinetti, M.E.; Kuchel, G.A. Geriatric syndromes, clinical, research and policy implications of a core geriatric concept. J. Am. Geriatr. Soc. 2007, 55, 780–791. [Google Scholar] [CrossRef] [PubMed]
- Calderόn-Larrañaga, A. Multimorbidity and functional impairment—Bidirectional interplay, synergistic effects and common pathways. J. Intern. Med. 2019, 285, 255–271. [Google Scholar] [CrossRef]
- Fried, L.P.; Qian-Li, X.; Cappola, A.R.; Ferucci, L.; Chaves, P.; Varadhan, R.; Guralnik, J.M.; Leng, S.X.; Semba, R.D.; Walston, J.D.; et al. Nonlinear multisystem physiological dysregulation associated with frailty in older women, Implications for etiology and treatment. J. Gerontol. A Biol. Sci. Med. Sci. 2009, 64, 1049–1057. [Google Scholar] [CrossRef]
- Hanlon, P.; Nicholl, B.I.; Jani, B.D.; Lee, D.; McQueenie, R.; Mair, F.S. Frailty and pre-frailty in middle-aged and older adults and its association with multimorbidity and mortality, A prospective analyses of 493 737 UK biobank participants. Lancet Public Health 2018, 3, e323–e332. [Google Scholar] [CrossRef]
- Rusanen, M.; Kivipelto, M.; Levälahti, E.; Laatikainen, T.; Tuomilehto, J.; Soininen, H.; Ngandu, T. Heart diseases and long-term risk of dementia and Alzheimer’s disease, a population-based CAIDE study. J. Alzheimers Dis 2014, 42, 183–191. [Google Scholar] [CrossRef] [PubMed]
- Canavelli, M.; Cesati, M.; van Kan, G.A. Frailty and cognitive decline, how do they relate? Curr. Opin. Clin. Nutr. Metab. Care 2015, 18, 43–50. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare, promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef]
- Lee, C.H.; Yoon, H.J. Medical big data, promise and challenges. Kidney Res. Clin. Pract. 2017, 36, 3–11. [Google Scholar] [CrossRef]
- Hassaine, A.; Salimi-Khorshidi, G.; Canoy, D.; Rahimi, K. Untangling the complexity of multimorbidity with machine learning. Mech. Ageing Dev. 2020, 190, 111325. [Google Scholar] [CrossRef] [PubMed]
- Hand, D.J. Statistics and data mining, intersecting disciplines. SIGKDD Explor. 1999, 1, 16–19. [Google Scholar] [CrossRef]
- Johnson, J.L. Probability and Statistics for Computer Science; Whiley: New York, NY, USA, 2011. [Google Scholar]
- Steyerberg, E.W.; van der Ploeg, T.; Van Calster, B. Risk prediction with machine learning and regression methods, risk prediction with machine learning and regression methods. Biom. J. 2014, 56, 601–606. [Google Scholar] [CrossRef]
- Trtica Majnaric, L. Complex thinking and Big Data. CPQ Neurol. Psychol. 2018, 2, 1–4. [Google Scholar]
- Morin, E. Complex thinking for a complex world—About reductionism, disjunction and systemism. Systema 2014, 2. [Google Scholar]
- Goldberger, A.L.; Peng, C.K.; Lipsitz, L.A. What is physiologic complexity and how does it change with aging and disease? Neurobiol. Aging 2002, 23, 23–26. [Google Scholar] [CrossRef]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards Multi-Modal Causability with Graph Neural Networks enabling Information Fusion for explainable AI. Inf. Fusion 2001, 71, 28–37. [Google Scholar] [CrossRef]
- Franceschi, C.; Garagnani, P.; Morsiani, C.; Conte, M.; Santoro, A.; Grignolio, A.; Monti, D.; Capri, M.; Savioli, S. The continuum of aging and age-related diseases, common mechanisms but different rates. Front. Med. 2018, 5, 61. [Google Scholar] [CrossRef] [PubMed]
- Lipsitz, L.A. Physiological complexity, aging and the path to frailty. Sci. Aging Knowl. Environ. 2004, 200, 16. [Google Scholar] [CrossRef]
- Sidey-Gibbons, J.; Sidey-Gibbons, C. Machine learning in medicine, a practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef]
- Lan, K.; Wang, D.; Fong, S.; Liu, L.; Wong, K.K.L.; Dey, N. A survey of data mining and deep learning in bioinformatics. J. Med. Syst. 2018, 42, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Bellazzi, R. Big data and biomedical informatics, a challenging opportunity. Yearb. Med. Inform. 2014, 9, 8–13. [Google Scholar] [CrossRef]
- Moawad, N.G.; Elkhalil, J.; Klebanoff, J.S. Augmented Realities, Artificial Intelligence, and Machine Learning: Clinical Implications and How Technology Is Shaping the Future of Medicine. J. Clin. Med. 2020, 9, 3811. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.Y.; Cheng, C.W.; Kaddi, C.D.; Venugopalan, J.; Hoffman, R.; Wang, M.D. Omic and electronic health record Big Data analytics for Precision Medicine. IEEE Trans. Biomed. Eng. 2017, 64, 263–273. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Ale, J.M.; Rossi, G.H. An Approach to Discovering Temporal Association Rules. In Proceedings of the 2000 ACM Symposium on Applied Computing, San Antonio, TX, USA, 19–21 March 2000; pp. 294–300. [Google Scholar]
- Tolles, J.; Meurer, W.J. Logistic Regression Relating Patient Characteristics to Outcomes. JAMA 2016, 316, 533–534. [Google Scholar] [CrossRef]
- Hand, D.J.; Yu, K. Idiot’s Bayes-not so stupid after all? Int. Stat. Rev. 2001, 69, 385–399. [Google Scholar]
- Murthy, K.S. Automatic construction of decision tress from data: A multidisciplinary survey. In Data Mining and Knowledge Discovery; Springer: Berlin/Heidelberg, Germany, 1997; pp. 345–389. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hornik, K. Approximation capabilities of multilayer feedforward networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Forgy, E.W. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 1965, 21, 768–769. [Google Scholar]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Kohonen, T. Self-Organized Formation of Topologically Correct Feature Maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Collins, L.M.; Lanza, S.T. Latent Class and Latent Transition Analysis: With Applications in the Social, Behavioral, and Health Sciences; Wiley: New York, NY, USA, 2010. [Google Scholar]
- Washio, T.; Motoda, H. State of the art of graph-based data mining. SIGKDD Exp. 2003, 5, 59–68. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef]
- Cichocki, A.; Mørup, M.; Smaragdis, P.; Wang, W.; Zdunek, R. Advances in Nonnegative Matrix and Tensor Factorization. Comput. Intell. Neurosci. 2008, 2008, 852187. [Google Scholar] [CrossRef]
- Griffith, L.E.; Gruneir, A.; Fisher, K.A.; Nicholson, K.; Panjwani, D.; Patterson, C.; Markle-Reid, M.; Ploeg, J.; Bierman, A.S.; Hogan, D.B.; et al. Key factors to consider when measuring multimorbidity. Results from an expert panel and online survey. J. Comorb. 2018, 8. [Google Scholar] [CrossRef] [PubMed]
- Holzinger, A. Interactive machine learning for health informatics, when do we need the human-in-the-loop? Brain Inform. 2016, 3, 119–131. [Google Scholar] [CrossRef]
- Richtera, A.N.; Khoshgoftaara, T.M. A review of statistical and machine learning methods for modeling cancer risk using structured clinical data. Artif. Intell. Med. 2018, 90, 1–14. [Google Scholar] [CrossRef]
- Rajan, J.R.; Prakash, J.J. Early diagnosis of lung cancer using a mining tool. In Proceedings of the National Conferenceon Architecture, Software systems and Green computing-2013(NCASG2013), Tamil Nadu, India, 3 May 2013. [Google Scholar]
- Zou, Q.; Qu, K.; Luo, Y.; Yin, D.; Ju, Y.; Tang, H. Predicting Diabetes Mellitus with Machine Learning techniques. Front. Genet. 2018, 9, 515. [Google Scholar] [CrossRef]
- Sacchi, L.; Dagliati, A.; Segagni, D.; Leporati, P.; Chiovato, L.; Bellazi, R. Improving risk-stratification of Diabetes complications using temporal data mining. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 31 March 2015; pp. 2131–2134. [Google Scholar]
- Yousefi, L.; Swift, S.; Arzaky, M.; Saachi, L.; Chiovato, L.; Tucker, A. Opening the black box, personalizing type 2 diabetes patients based on their latent phenotype and temporal associated complication rules. Comput. Intell. 2020, 1–39. [Google Scholar] [CrossRef]
- Shaikhina, T.; Khovanova, N. Handling limited datasets with neural networks in medical applications, a small-data approach. Artef. Intell. Med. 2017, 75, 51–63. [Google Scholar] [CrossRef] [PubMed]
- Babič, F.; Pusztová, L.; Trtica Majnarić, L. Mild Cognitive Impairment detection using Association Rules Mining. Acta Inform. Prag. 2020, 9, 92–107. [Google Scholar] [CrossRef]
- Babič, F.; Trtica Majnarić, L.; Lukáčová, A.; Paralič, J.; Holzinger, A. On patient’s characteristics extraction for metabolic syndrome diagnosis, Predictive modelling based on machine learning. Information Technology. In Bio- and Medical Informatics; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8649, pp. 118–132. [Google Scholar]
- Rokošná, J.; Babič, F.; Trtica-Majnaric, L.; Pusztová, L. Cooperation between data analysts and medical experts, A case study. In Proceedings of the International Cross-Domain Conference, CD-MAKE 2020, Dublin, Ireland, 25–28 August 2020; pp. 173–190. [Google Scholar]
- Šabanović, Š.; Majnaric Trtica, L.; Babič, F.; Vadovský, M.; Paralič, J.; Včev, A.; Holzinger, A. Metabolic syndrome in hypertensive women in the age of menopause, a case study on data from general practice electronic health records. BMC Med. Inform. Decis. Mak. 2018, 18, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Majnaric Trtica, L.; Vitale, B. Systems biology as a conceptual framework for research in family medicine, use in predicting response to influenza vaccination. Prim. Health Care Res. Develop 2011, 12, 310–321. [Google Scholar] [CrossRef]
- Majnarić Trtica, L.; Babič, F.; Bosnić, Z.; Zekić-Sušac, M.; Wittlinger, T. The use of Artificial Intelligence in assessing glucose variability in individuals with Diabetes type 2 from routine primary care data. Int. J. Diabetes Clin. Res. 2020, 7, 121. [Google Scholar]
- Hund, M.; Böhm, D.; Sturm, W.; Sedlmair, M.; Schreck, T.; Ullrich, T.; Keim, D.A.; Majnaric, L.T.; Holzinger, A. Visual analytics for concept exploration in subspaces of patient groups. Brain Inform. 2016, 3, 233–247. [Google Scholar] [CrossRef] [PubMed]
- Xiao, C.; Choi, E.; Sun, J. Opportunities and challenges in developing deep learning models using electronic health records data: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1419–1428. [Google Scholar] [CrossRef]
- Holder, L.B.; Haque, M.M.; Skinner, M.K. Machine learning for epigenetics and future medical applications. Epigenetics 2017, 12, 505–514. [Google Scholar] [CrossRef] [PubMed]
- Shah, P.; Kendall, F.; Khozin, S.; Goosen, R.; Hu, J.; Laramie, J.; Ringel, M.; Schork, N. Artificial intelligence and machine learning in clinical development: A translational perspective. NPJ Digit. Med. 2019, 2, 69. [Google Scholar] [CrossRef]
- Alyass, A.; Turcotte, M.; Meyre, D. From big data analysis to personalized medicine for all: Challenges and opportunities. BMC Med. Genom. 2015, 8, 33. [Google Scholar] [CrossRef] [PubMed]
- Krittanawong, C.; Bomback, A.S.; Baber, U.; Bangalore, S.; Messerli, F.H.; Tang, W.H.W. Future Direction for Using Artificial Intelligence to Predict and Manage Hypertension. Curr. Hypertens Rep. 2018, 20, 75. [Google Scholar] [CrossRef] [PubMed]
- van den Bussche, H.; Koller, D.; Kolonko, T.; Hansen, H.; Wegscheider, K.; Glaeske, G.; von Leitner, E.C.; Schäfer, I.; Schön, G. Which chronic diseases and disease combinations are specific to multimorbidity in the elderly? Results of a claims data based cross-sectional study in Germany. BMC Public Health 2011, 11, 101. [Google Scholar] [CrossRef] [PubMed]
- Larsen, B.F.; Pedersen, H.M.; Friis, K.; Glümer, C.; Lasgaard, M. Latent class analysis of multimorbidity and the relationship to socio-demographic factors and health-related quality of life. A national population-based study of 162,283 Danish adults. PLoS ONE 2017, 12, e0169426. [Google Scholar] [CrossRef]
- Van Oostrom, S.H.; Picavet, H.S.J.; van Gelder, B.M.; Lemmens, L.C.; Hoeymans, N.; Verheij, R.A.; Schellevis, F.G.; Baan, B.A. Multimorbidity and comorbidity in the Dutch population—data from general practices. BMC Public Health 2012, 12, 715. [Google Scholar] [CrossRef] [PubMed]
- Déruaz-Luyet, A.; N’Goran, A.A.; Senn, N.; Bodenmann, R.; Pasquier, O.; Widmer, D.; Tandjung, R.; Rosemann, T.; Frey, P.; Streit, S. Multimorbidity and patterns of chronic conditions in a primary care population in Switzerland, a cross-sectional study. BMJ Open 2017, 7, e013664. [Google Scholar] [CrossRef] [PubMed]
- Roso-Llorach, A.; Violán, C.; Foguet-Boreu, Q.; Rodriguez-Blanco, T.; Pons-Vigués, M.; Pujol-Ribera, E.; Valderas, J.M. Comparative analysis of methods for identifying multimorbidity patterns, a study of ‘real-world’ data. BMJ Open 2018, 8, e018986. [Google Scholar] [CrossRef] [PubMed]
- Hernández, B.; Reilly, R.B.; Kenny, R.A. Investigation of multimorbidity and prevalent disease combinations in older Irish adults using network analysis and association rules. Sci. Rep. 2019, 9, 14567. [Google Scholar] [CrossRef]
- Yao, S.S.; Cao, G.Y.; Han, L.; Chen, Z.; Huang, Z.; Gong, P.; Hu, Y.; Xu, B. Prevalence and patterns of multimorbidity in a nationally representative sample of older Chinese: Results from CHARLS. J. Gerontol. 2020, 75, 1974–1980. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Kim, H.; Jeong, H.; Noh, Y. Patterns of Multimorbidity in Adults: An Association Rules Analysis Using the Korea Health Panel. Int. J. Environ. Res. Public Health 2020, 17, 2618. [Google Scholar] [CrossRef]
- Schiltz, N.K.; Warner, D.F.; Sun, J. Identifying specific combinations of multimorbidity that contribute to health care resource utilization: An analytic approach. Med. Care. 2017, 55, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Pedro, M.C.; Mercedes, M.P.; Ramón, L.H.; Borja, M.R. Subjective memory complaints in elderly: Relationship with health status, multimorbidity, medications, and use of services in a population-based study. Int. Psychogeriatr. 2016, 28, 1903–1916. [Google Scholar] [CrossRef] [PubMed]
- Bekić, S.; Babič, F.; Filipčić, I.; Majnarić Trtica, L. Clustering of mental and physical comorbidity and the risk of frailty in patients aged 60 years or more in primary care. Med. Sci. Monit. 2019, 25, 6820–6835. [Google Scholar] [CrossRef]
- Majnarić Trtica, L.; Bekić, S.; Babič, F.; Pusztová, Ľ.; Paralič, J. Cluster Analysis of the Associations among Physical Frailty, Cognitive Impairment and Mental Disorders. Med. Sci. Monit. 2020, 26, e924281. [Google Scholar]
- Marengoni, A.; Roso-Llorach, A.; Vetrano, D.L.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Violán, C.; Calderón-Larrañaga, A. Patterns of multimorbidity in a population-based cohort of older people, sociodemographic, lifestyle, clinical, and functional differences. J. Gerontol. A Biol. 2020, 75, 798–805. [Google Scholar] [CrossRef]
- Gambhir, S.; Malik, S.K.; Kumar, Y. Role of soft computing approaches in healthcare domain, A mini review. J. Med. Syst. 2016, 40, 287. [Google Scholar] [CrossRef] [PubMed]
- Shickel, B.; Tighe, P.J.; Bihorac, A.; Rashidi, P. Deep EHR: A Survey of Recent Advances in Deep Learning Techniques for Electronic Health Record (EHR) Analysis. IEEE J. Biomed. Health Inform. 2018, 22, 1589–1604. [Google Scholar] [CrossRef]
- Li, Y.; Rao, S.; Solares, J.R.A.; Hassaine, A.; Ramakrishnan, R.; Canoy, D.; Zhu, Y.; Rahimi, K.; Salimi-Khorshidi, G. BEHRT: Transformer for Electronic Health Records. Sci. Rep. 2020, 10, 7155. [Google Scholar] [CrossRef] [PubMed]
- Meng, W.; Ou, W.; Chandwani, S.; Chen, X.; Black, W.; Cai, Z. Temporal phenotyping by mining healthcare data to derive lines of therapy for cancer. J. Biomed. Inform. 2019, 100, 103335. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Zhang, Y.; Schlueter, D.J.; Wu, P.; Kerchberger, V.E.; Rosenbloom, S.E.; Wells, Q.S.; Feng, Q.; Denny, J.C.; Wie, W. Detecting time-evolving phenotypic topics via tensor factorization on electronic health records, cardiovascular disease case study. J. Biomed. Inform. 2019, 98, 103270. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, P.; Tran, T.; Wickramasinghe, N.; Venkatesh, S. A convolutional net for medical records. IEEE J. Biomed. Health Inform. 2016, 21, 22–30. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.; Schuetz, A.; Stewart, W.F.; Sun, J. Doctor AI, predicting clinical events via recurrent neural networks. Mach. Learn. Healthc. Conf. 2016, 56, 301–318. [Google Scholar]
- Jonsson, A. Deep Reinforcement Learning in Medicine. Kidney Dis. (Basel) 2019, 5, 18–22. [Google Scholar] [CrossRef]
- Weng, C.; Shah, N.H.; Hripcsak, G. Deep phenotyping, Embracing complexity and temporality-Towards scalability, portability, and interoperability. J. Biomed. Inform. 2020, 105, 103433. [Google Scholar] [CrossRef]
- Stenholm, S.; Westerlund, H.; Head, J.; Hyde, M.; Kawachi, I.; Pentti, J.; Kivimäki, M.; Vahtera, J. Comorbidity and functional trajectories from midlife to old age. J. Gerontol. A. Biol 2014, 70, 332–338. [Google Scholar] [CrossRef] [PubMed]
- Lappenschaar, M.; Hommersom, A.; Lucas, P.J.; Lagro, J.; Visscher, S.; Korevaar, J.C.; Schellevis, F.G. Multilevel temporal Bayesian networks can model longitudinal change in multimorbidity. J. Clin. Epidemiol. 2013, 66, 1405–1416. [Google Scholar] [CrossRef]
- Hassaine, A.; Canoy, D.; Ayala Solares, R.A.; Zhu, Y.; Rao, S.; Li, Y.; Zottoli, M.; Rahimi, K.; Salimi-Khorshidi, G. Learning multimorbidity patterns from electronic health records using non-negative matrix factorisation. J. Biomed. Inform. 2020, 112, 103606. [Google Scholar] [CrossRef]
- Akugizibwe, R.; Calderón-Larrañaga, A.; Roso-Llorach, A.; Onder, G.; Marengoni, A.; Zucchelli, A.; Rizzuto, D.; Vetrano, D.L. Multimorbidity Patterns and Unplanned Hospitalisation in a Cohort of Older Adults. J. Clin. Med. 2020, 9, 4001. [Google Scholar] [CrossRef]
- Rizzo, L.; Majnaric Trtica, L.; Dondio, P.; Longo, L. An investigation of Argumentation Theory for the prediction of survival in elderly using biomarkers. In Artificial Intelligence Applications and Innovations; Iliadis, L., Maglogiannis, I., Plagianakos, V., Eds.; Springer: Cham, Switzerland, 2018; Volume 519. [Google Scholar]
- Liang, Z.; Zhang, G.; Huang, J.X.; Hu, Q.V. Deep learning for healthcare decision making with EMRs. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Belfast, UK, 2–5 November 2014; pp. 556–559. [Google Scholar]
- Norgeot, B.; Glicksberg, B.S.; Trupin, L.; Lituiev, D.; Gianfrancesco, M.; Oskotsky, B.; Schmajuk, G.; Yazdany, J.; Butte, A.J. Assessment of a Deep Learning Model Based on Electronic Health Record Data to Forecast Clinical Outcomes in Patients with Rheumatoid Arthritis. JAMA Netw. Open 2019, 2, e190606. [Google Scholar] [CrossRef] [PubMed]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 17, 26094. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.N.; Hsiao, F.Y.; Lee, W.J.; Huang, S.T.; Chen, L.K. Comparisons Between Hypothesis- and Data-Driven Approaches for Multimorbidity Frailty Index: A Machine Learning Approach. J. Med. Internet Res. 2020, 22, e16213. [Google Scholar] [CrossRef]
- Searle, S.D.; Mitnitski, A.; Gahbauer, E.A.; Gill, T.M.; Rockwood, K. A standard procedure for creating a frailty index. BMC Geriatr. 2008, 8, 24. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, R.; Tang, J.; Stewart, W.F.; Sun, J. LEAP: Learning to prescribe effective and safe treatment combinations for multimorbidity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2017; pp. 1315–1324. [Google Scholar]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef]
- Violán, C.; Foguet-Boreu, Q.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Cabrera-Bean, M.; Formiga, F.; Valderas, J.M.; Roso-Llorach, A. Soft clustering using real-world data for the identification of multimorbidity patterns in an elderly population: Cross-sectional study in a Mediterranean population. BMJ Open 2019, 9, e029594. [Google Scholar]
- Prados-Torres, A.; Poblador-Plou, B.; Calderón-Larrañaga, A.; Gimeno-Feliu, L.A.; González-Rubio, F.; Poncel-Falcó, A.; Sicras-Mainar, A.; Alcalá-Nalvaiz, J.T. Multimorbidity patterns in primary care: Interactions among chronic diseases using factor analysis. PLoS ONE 2012, 7, e32190. [Google Scholar] [CrossRef] [PubMed]
- Violán, C.; Fernández-Bertolín, S.; Guisado-Clavero, M.; Foguet-Boreu, Q.; Valderas, J.M.; Manzano, J.V.; Roso-Lhorach, A.; Cabreara-Bean, M. Five-year trajectories of multimorbidity patterns in an elderly Mediterranean population using Hidden Markov Models. Sci Rep. 2020, 10, 16879. [Google Scholar] [CrossRef] [PubMed]
- Anker, D.; Santos-Eggimann, B.; Zwahlen, M.; Santschi, V.; Rodondi, N.; Wolfson, C.; Chiolero, A. Blood Pressure in Relation to Frailty in Older Adults: A Population-Based Study. J. Clin. Hypertens. 2019, 21, 1895–1904. [Google Scholar] [CrossRef]
- Vetrano, D.L.; Rizzuto, D.; Calderón-Larrañaga, A.; Onder, G.; Welmer, A.K.; Bernabei, R.; Marengoni, A.; Fratiglioni, L. Trajectories of functional decline in older adults with neuropsychiatric and cardiovascular multimorbidity: A Swedish cohort study. PLoS Med. 2018, 15, e1002503. [Google Scholar] [CrossRef] [PubMed]
- Calderón-Larrañaga, A.; Vetrano, D.L.; Onder, G.; Gimeno-Feliu, L.A.; Coscollar-Santaliestra, C.; Carfí, A.; Pisciotta, M.S.; Angleman, S.; Melis, R.J.F.; Santoni, G. Assessing and measuring chronic multimorbidity in the older population: A proposal for its operationalization. J. Gerontol. Ser. A Biol. Sci. Med. Sci. 2017, 72, 1417–1423. [Google Scholar] [CrossRef]
- Ng, S.K.; Tawiah, R.; Sawyer, M.; Scuffham, P. Patterns of multimorbid health conditions: A systematic review of analytical methods and comparison analysis. Int. J. Epidemiol. 2018, 47, 1687–1704. [Google Scholar] [CrossRef]
- Peterson, E.D. Machine Learning, predictive analytics, and clinical practice, Can the past inform the present? JAMA 2019, 322, 2283–2284. [Google Scholar] [CrossRef] [PubMed]
- Panicacci, S.; Donati, M.; Fanucci, L.; Bellin, I.; Profili, F.; Francesconi, P. Population Health Management Exploiting Machine Learning Algorithms to Identify High-Risk Patients. In Proceedings of the IEEE 31st International Symposium on Computer-Based Medical Systems (CBMS), Karlstad, Sweden, 18–21 June 2018; pp. 298–303. [Google Scholar]
- Boulton, C.; Wilkinson, M. Use of public datasets in the examination of multimorbidity, Opportunities and challenges. Mech. Aging Dev. 2020, 190, 111310. [Google Scholar] [CrossRef]
- Coorevits, P.; Sundgren, M.; Klein, G.O.; Bahr, A.; Claerhout, A.; Daniel, C.; Dugas, M.; Dupont, D.; Schmidt, A.; Singleton, P.; et al. Electronic health records, new opportunities for clinical research. J. Intern. Med. 2013, 274, 547–560. [Google Scholar] [CrossRef] [PubMed]
- Carrington, A.M.; Fieguth, P.W.; Qazi, H.; Holzinger, A.; Chen, H.H.; Mayr, F.; Manuel, D.G. A new concordant partial AUC and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med. Inform. Decis. Mak. 2020, 20, 1–12. [Google Scholar] [CrossRef]
- Hassler, A.P.; Menasalvas, E.; García-García, F.J.; Rodríguez-Mañas, L.; Holzinger, A. Importance of medical data preprocessing in predictive modeling and risk factor discovery for the frailty syndrome. BMC Med. Inform. Decis. Mak. 2019, 19, 33. [Google Scholar] [CrossRef] [PubMed]
- Lindsell, C.J.; Stead, W.W.; Johnson, K.B. Action-informed Artificial Intelligence-matching the algorithm to the problem. JAMA 2020, 323, 2141–2142. [Google Scholar] [CrossRef] [PubMed]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).