Machine Learning-Based Predictive Modeling of Postpartum Depression



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Participants
2.2. Target Variable for Predictive Modeling: Postpartum Depression
2.3. Machine Learning Methods for Predictive Modeling
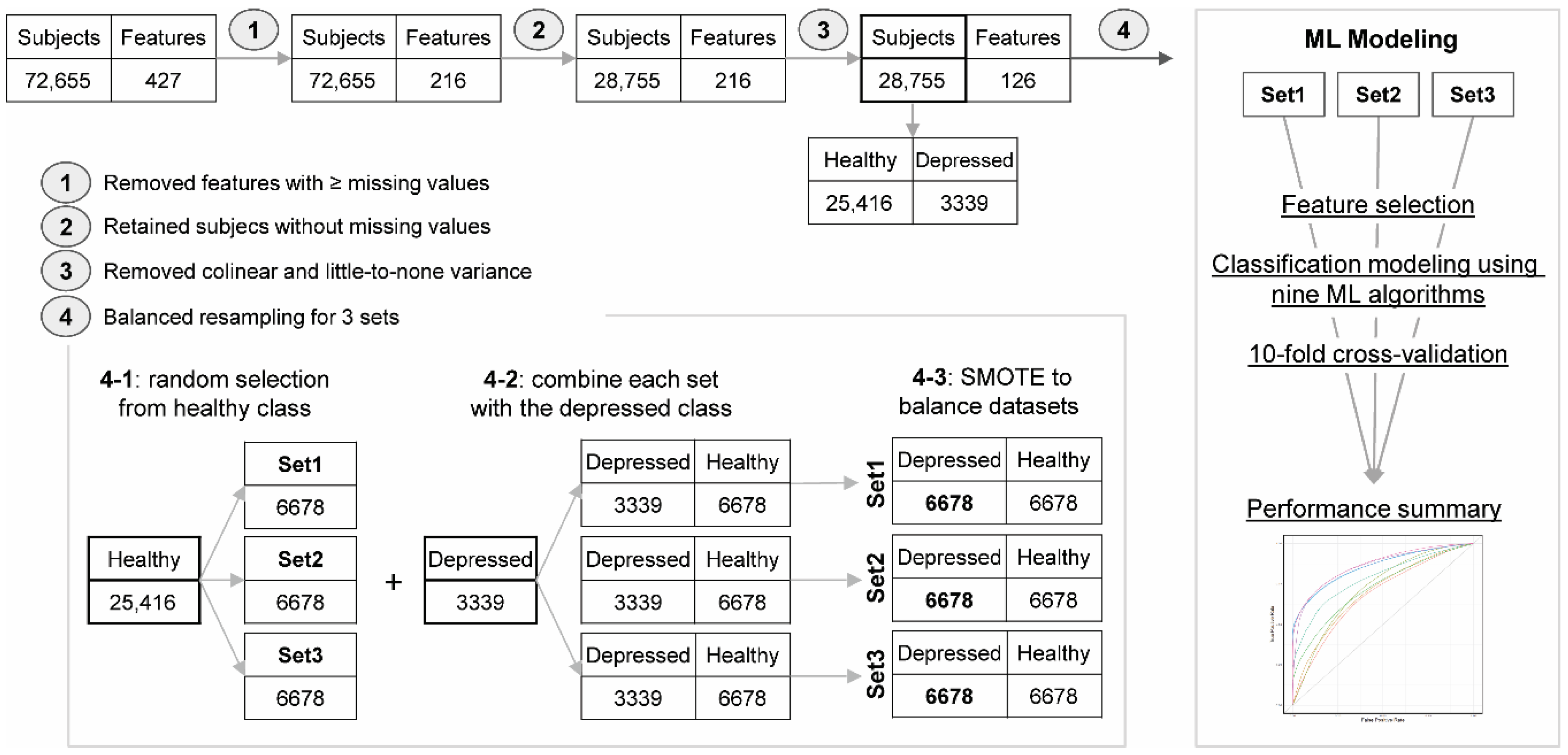
2.3.1. Resampling to Address Group Imbalance
2.3.2. Feature Selection (Inputs for Predictive Modeling: Maternal and Paternal Factors)
2.3.3. Classification Modeling
2.4. Statistical Analyses
2.5. Ethical Approval
3. Results
3.1. Maternal Demographics and Lifestyle Factors
3.2. Association of Maternal Demographics and Lifestyle Factors with Postpartum Depression
3.3. Prediction Modeling
3.3.1. Feature Selection for Modeling
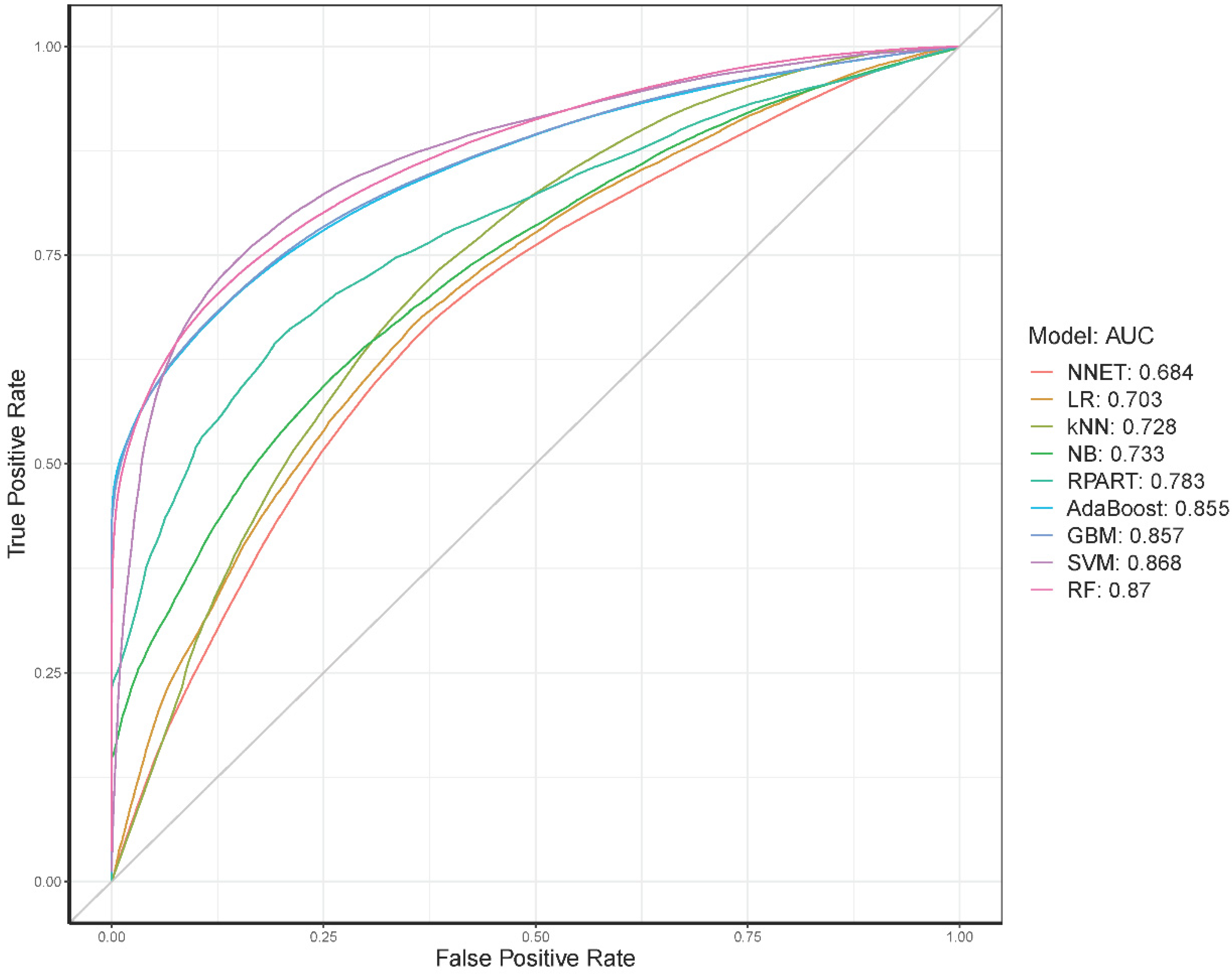
3.3.2. Performance Evaluation of Classification Models
3.4. Important Features Ranked by Each ML Algorithm
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pearlstein, T.; Howard, M.; Salisbury, A.; Zlotnick, C. Postpartum depression. Am. J. Obstet. Gynecol. 2009, 200, 357–364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- World Health Organization. Maternal Mental Health. Available online: http://www.who.int/mental_health/maternal-child/maternal_mental_health/en/ (accessed on 1 September 2020).
- Dennis, C.-L.; McQueen, K. The relationship between infant-feeding outcomes and postpartum depression: A qualitative systematic review. Pediatrics 2009, 123, e736–e751. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moehler, E.; Brunner, R.; Wiebel, A.; Reck, C.; Resch, F. Maternal depressive symptoms in the postnatal period are associated with long-term impairment of mother–child bonding. Arch. Womens Ment. Health 2006, 9, 273–278. [Google Scholar] [CrossRef] [PubMed]
- O’Higgins, M.; Roberts, I.S.J.; Glover, V.; Taylor, A. Mother-child bonding at 1 year; associations with symptoms of postnatal depression and bonding in the first few weeks. Arch. Womens Ment. Health 2013, 16, 381–389. [Google Scholar] [CrossRef] [PubMed]
- Murray, L.; Cooper, P.J. Effects of postnatal depression on infant development. Arch. Dis. Child. 1997, 77, 99–101. [Google Scholar] [CrossRef] [Green Version]
- Bloch, M.; Rotenberg, N.; Koren, D.; Klein, E. Risk factors for early postpartum depressive symptoms. Gen. Hosp. Psychiatry 2006, 28, 3–8. [Google Scholar] [CrossRef]
- Séguin, L.; Potvin, L.; St-Denis, M.; Loiselle, J. Depressive symptoms in the late postpartum among low socioeconomic status women. Birth 1999, 26, 157–163. [Google Scholar] [CrossRef]
- Beck, C.T. Predictors of postpartum depression: An update. Nurs. Res. 2001, 50, 275–285. [Google Scholar] [CrossRef] [Green Version]
- Boyce, P.M.; Todd, A.L. Increased risk of postnatal depression after emergency caesarean section. Med. J. Aust. 1992, 157, 172–174. [Google Scholar] [CrossRef]
- Cheng, D.; Schwarz, E.B.; Douglas, E.; Horon, I. Unintended pregnancy and associated maternal preconception, prenatal and postpartum behaviors. Contraception 2009, 79, 194–198. [Google Scholar] [CrossRef]
- Stone, S.L.; Diop, H.; Declercq, E.; Cabral, H.J.; Fox, M.P.; Wise, L.A. Stressful events during pregnancy and postpartum depressive symptoms. J. Womens Health (Larchmt) 2015, 24, 384–393. [Google Scholar] [CrossRef] [Green Version]
- Anderson, C.; Cacola, P. Implications of Preterm Birth for Maternal Mental Health and Infant Development. MCN Am. J. Matern. Child. Nurs. 2017, 42, 108–114. [Google Scholar] [CrossRef]
- Worachartcheewan, A.; Nantasenamat, C.; Isarankura-Na-Ayudhya, C.; Pidetcha, P.; Prachayasittikul, V. Identification of metabolic syndrome using decision tree analysis. Diabetes Res. Clin. Pract. 2010, 90, e15–e18. [Google Scholar] [CrossRef]
- Chen, M.; Hao, Y.; Hwang, K.; Wang, L.; Wang, L. Disease prediction by machine learning over big data from healthcare communities. IEEE Access 2017, 5, 8869–8879. [Google Scholar] [CrossRef]
- Austin, P.C.; Tu, J.V.; Ho, J.E.; Levy, D.; Lee, D.S. Using methods from the data-mining and machine-learning literature for disease classification and prediction: A case study examining classification of heart failure subtypes. J. Clin. Epidemiol. 2013, 66, 398–407. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Shen, D. Multi-modal multi-task learning for joint prediction of multiple regression and classification variables in Alzheimer’s disease. NeuroImage 2012, 59, 895–907. [Google Scholar] [CrossRef] [Green Version]
- Nunes, A.P.; Phipps, M.G. Postpartum depression in adolescent and adult mothers: Comparing prenatal risk factors and predictive models. Matern Child. Health J. 2013, 17, 1071–1079. [Google Scholar] [CrossRef]
- Division of Reproductive Health; National Center for Chronic Disease Prevention and Health Promotion. PRAMS Methodology. Available online: https://www.cdc.gov/prams/methodology.htm#n4 (accessed on 5 September 2019).
- O’Hara, M.W.; Stuart, S.; Watson, D.; Dietz, P.M.; Farr, S.L.; D’Angelo, D. Brief scales to detect postpartum depression and anxiety symptoms. J. Womens Health (Larchmt) 2012, 21, 1237–1243. [Google Scholar] [CrossRef]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V. Data mining for imbalanced datasets: An overview. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin, Germany, 2009; pp. 875–886. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Kira, K.; Rendell, L.A. The Feature Selection Problem: Traditional Methods and a New Algorithm; AAAI: Menlo Park, CA, USA, 1992; pp. 129–134. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S; Springer: Berlin, Germany, 2002. [Google Scholar]
- Beck, C.T. Revision of the postpartum depression predictors inventory. J. Obs. Gynecol. Neonatal. Nurs. 2002, 31, 394–402. [Google Scholar] [CrossRef]
- Ko, J.Y.; Rockhill, K.M.; Tong, V.T.; Morrow, B.; Farr, S.L. Trends in Postpartum Depressive Symptoms—27 States, 2004, 2008, and 2012. Mmwr. Morb. Mortal. Wkly. Rep. 2017, 66, 153–158. [Google Scholar] [CrossRef] [Green Version]
- LaCoursiere, D.Y.; Baksh, L.; Bloebaum, L.; Varner, M.W. Maternal body mass index and self-reported postpartum depressive symptoms. Matern Child. Health J. 2006, 10, 385–390. [Google Scholar] [CrossRef] [PubMed]
- Shakeel, N.; Richardsen, K.R.; Martinsen, E.W.; Eberhard-Gran, M.; Slinning, K.; Jenum, A.K. Physical activity in pregnancy and postpartum depressive symptoms in a multiethnic cohort. J. Affect. Disord. 2018, 236, 93–100. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.H.; Tronick, E. Rates and predictors of postpartum depression by race and ethnicity: Results from the 2004 to 2007 New York City PRAMS survey (Pregnancy Risk Assessment Monitoring System). Matern. Child Health J. 2013, 17, 1599–1610. [Google Scholar] [CrossRef]
- Noh, E. Asian American women and suicide: Problems of responsibility and healing. Women Ther. 2007, 30, 87–107. [Google Scholar]
- Patel, V.; Rodrigues, M.; DeSouza, N. Gender, poverty, and postnatal depression: A study of mothers in Goa, India. Am. J. Psychiatry 2002, 159, 43–47. [Google Scholar] [CrossRef]
- Xie, R.-H.; He, G.; Koszycki, D.; Walker, M.; Wen, S.W. Fetal sex, social support, and postpartum depression. Can. J. Psychiatry 2009, 54, 750–756. [Google Scholar] [CrossRef] [Green Version]
- Xie, R.H.; He, G.; Koszycki, D.; Walker, M.; Wen, S.W. Prenatal social support, postnatal social support, and postpartum depression. Ann. Epidemiol. 2009, 19, 637–643. [Google Scholar] [CrossRef] [PubMed]
- Xie, R.; Liao, S.; Xie, H.; Guo, Y.; Walker, M.; Wen, S. Infant sex, family support and postpartum depression in a Chinese cohort. J. Epidemiol. Community Health 2011, 65, 722–726. [Google Scholar] [CrossRef] [PubMed]
- Horowitz, J.A.; Goodman, J.H. Identifying and treating postpartum depression. J. Obs. Gynecol. Neonatal. Nurs 2005, 34, 264–273. [Google Scholar] [CrossRef] [Green Version]
- Brummelte, S.; Galea, L.A. Depression during pregnancy and postpartum: Contribution of stress and ovarian hormones. Prog Neuropsychopharmacol. Biol. Psychiatry 2010, 34, 766–776. [Google Scholar] [CrossRef] [PubMed]
- Parker, K.J.; Schatzberg, A.F.; Lyons, D.M. Neuroendocrine aspects of hypercortisolism in major depression. Horm. Behav. 2003, 43, 60–66. [Google Scholar] [CrossRef]
- Offenbacher, S.; Lieff, S.; Boggess, K.; Murtha, A.; Madianos, P.; Champagne, C.; McKaig, R.; Jared, H.; Mauriello, S.; Auten, R., Jr. Maternal periodontitis and prematurity. Part I: Obstetric outcome of prematurity and growth restriction. Ann. Periodontol. 2001, 6, 164–174. [Google Scholar] [CrossRef]
- López, N.J.; Smith, P.C.; Gutierrez, J. Higher risk of preterm birth and low birth weight in women with periodontal disease. J. Dent. Res. 2002, 81, 58–63. [Google Scholar] [CrossRef]
- Tortajada, S.; García-Gomez, J.M.; Vicente, J.; Sanjuán, J.; de Frutos, R.; Martín-Santos, R.; García-Esteve, L.; Gornemann, I.; Gutiérrez-Zotes, A.; Canellas, F. Prediction of postpartum depression using multilayer perceptrons and pruning. Methods Inf. Med. 2009, 48, 291–298. [Google Scholar]
- Hosseinifard, B.; Moradi, M.H.; Rostami, R. Classifying depression patients and normal subjects using machine learning techniques and nonlinear features from EEG signal. Comput. Methods Programs Biomed. 2013, 109, 339–345. [Google Scholar] [CrossRef]
- Jiménez-Serrano, S.; Tortajada, S.; García-Gómez, J.M. A Mobile Health Application to Predict Postpartum Depression Based on Machine Learning. Telemed. E-Health 2015, 21, 567–574. [Google Scholar]
- Centers for Disease Control and Prevention (CDC); Division of Reproductive Health; National Center for Chronic Disease Prevention and Health Promotion. PRAMS Methodology. Available online: https://www.cdc.gov/prams/methodology.htm (accessed on 5 February 2020).
- Centers for Disease Control and Prevention (CDC); Division of Reproductive Health; National Center for Chronic Disease Prevention and Health Promotion. What is PRAMS? Available online: https://www.cdc.gov/prams/index.htm (accessed on 5 February 2020).
- Li, C.; Friedman, B.; Conwell, Y.; Fiscella, K. Validity of the Patient Health Questionnaire 2 (PHQ-2) in identifying major depression in older people. J. Am. Geriatr. Soc. 2007, 55, 596–602. [Google Scholar] [CrossRef] [PubMed]
- Association, A.P. Patient Health Questionnaire (PHQ-9 & PHQ-2) Construct: Depressive Symptoms. Available online: https://www.apa.org/pi/about/publications/caregivers/practice-settings/assessment/tools/patient-health (accessed on 1 September 2020).
- Zhang, H.; Ni, W.; Li, J.; Zhang, J. Artificial Intelligence–Based Traditional Chinese Medicine Assistive Diagnostic System: Validation Study. JMIR Med. Inf. 2020, 8, e17608. [Google Scholar] [CrossRef] [PubMed]
- Kirmayer, L.J. Cultural variations in the clinical presentation of depression and anxiety: Implications for diagnosis and treatment. J. Clin. Psychiatry 2001, 62, 22–30. [Google Scholar] [PubMed]



{kind=link}
{kind=link}
| No Postpartum Depression (n = 25,416) | Postpartum Depression (n = 3339) | ||||
|---|---|---|---|---|---|
| n | Wt’d % | n | Wt’d % | p-Value | |
| Maternal Age (years) | |||||
| ≤19 | 1332 | 3.8 | 354 | 9.2 | <0.0001 |
| 20–29 | 13,012 | 50.7 | 1867 | 56.7 | |
| 30–39 | 10,341 | 42.6 | 1045 | 31.7 | |
| ≥40 | 731 | 2.9 | 73 | 2.4 | |
| Maternal Race/Ethnicity | |||||
| American Indian or Alaskan Native | 897 | 1.0 | 156 | 1.9 | <0.0001 |
| Asian | 1743 | 5.0 | 234 | 5.6 | |
| Black | 2834 | 9.4 | 570 | 13.4 | |
| Hawaiian | 396 | 0.4 | 36 | 0.3 | |
| White or other non-white | 18,487 | 81.9 | 2170 | 75.9 | |
| Mixed race | 1059 | 2.4 | 173 | 3.0 | |
| Maternal Education | |||||
| 0–12 years | 8059 | 28.1 | 1559 | 42.3 | <0.0001 |
| 13–15 years | 7654 | 29.3 | 1057 | 32.6 | |
| ≥16 years | 9703 | 42.6 | 723 | 25.1 | |
| Marital Status | |||||
| Married | 16,843 | 70.0 | 1613 | 51.2 | <0.0001 |
| Other | 8573 | 30.0 | 1726 | 48.8 | |
| Number of Previous Live Births | |||||
| 0 | 11,106 | 42.6 | 1410 | 43.1 | 0.3415 |
| 1 | 7946 | 33.0 | 992 | 31.2 | |
| ≥2 | 6364 | 24.3 | 937 | 25.7 | |
| Small for Gestational Age Based on 10th Percentile | |||||
| Yes | 3829 | 8.7 | 628 | 12.4 | <0.0001 |
| No | 21,587 | 91.3 | 2711 | 87.6 | |
| Pre-pregnancy Exercise 3+ Days | |||||
| No | 12,504 | 49.0 | 1892 | 55.3 | <0.0001 |
| Yes | 12,912 | 51.0 | 1447 | 44.7 | |
| Depression Before Pregnancy | |||||
| No | 23,227 | 92.2 | 2474 | 76.3 | <0.0001 |
| Yes | 2189 | 7.8 | 865 | 23.7 | |
| Drinking 3 Months Before Pregnancy | |||||
| No | 10,157 | 36.6 | 1452 | 41.0 | 0.0018 |
| Yes | 15,259 | 63.4 | 1887 | 59.0 | |
| Changing Smoking Last 3 Months of Pregnancy & Postpartum Period | |||||
| Nonsmoker | 21,588 | 86.5 | 2377 | 75.4 | <0.0001 |
| Smoker who quit | 229 | 0.7 | 46 | 1.1 | |
| Number of cigarettes reduced | 110 | 0.4 | 43 | 1.6 | |
| Number of cigarettes same/more | 2271 | 7.7 | 593 | 14.1 | |
| Nonsmoker resumed | 1218 | 4.7 | 280 | 7.9 | |
| Maternal Pre-pregnancy BMI (kg/m2) | |||||
| Underweight (≤18.5) | 1044 | 3.5 | 200 | 5.4 | <0.0001 |
| Normal (18.5–25) | 12,648 | 51.9 | 1440 | 45.4 | |
| Overweight (25–30) | 6131 | 24.0 | 823 | 24.8 | |
| Obese (≥30) | 5593 | 20.6 | 876 | 24.3 | |
| OR | (95% CI) | |
|---|---|---|
| Maternal Age (years) | ||
| ≤19 | 1.50 * | (1.07–2.09) |
| 20–29 | 1.00 | |
| 30–39 | 0.91 | (0.77–1.07) |
| ≥40 | 0.96 | (0.62–1.50) |
| Maternal Race/Ethnicity | ||
| American Indian or Alaskan Native | 1.53 | (0.93–2.50) |
| Asian | 1.26 | (0.78–2.02) |
| Black | 1.24 | (0.82–1.87) |
| Hawaiian | 1.03 | (0.16–6.76) |
| White or other non-white | 1.00 | |
| Mixed race | 1.30 | (0.87–1.93) |
| Maternal Education | ||
| 0–12 years | 1.59 * | (1.27–2.00) |
| 13–15 years | 1.45 * | (1.19–1.77) |
| ≥16 years | 1.00 | |
| Marital Status | ||
| Married | 1.00 | |
| Other | 1.52 * | (1.27–1.83) |
| Number of Previous Live Births | ||
| 0 | 1.00 | |
| 1 | 0.95 | (0.80–1.14) |
| ≥2 | 1.05 | (0.86–1.29) |
| Small for Gestational Age Based on 10th Percentile | ||
| Yes | 1.37 * | (1.11–1.69) |
| No | 1.00 | |
| Pre-pregnancy Exercise 3+ Days | ||
| No | 1.00 | |
| Yes | 0.97 | (0.84–1.13) |
| Depression Before Pregnancy | ||
| No | 1.00 | |
| Yes | 3.15 * | (2.60–3.80) |
| Drinking 3 Months Before Pregnancy | ||
| No | 1.00 | |
| Yes | 0.84 * | (0.72–0.99) |
| Changing Smoking Last 3 Months of Pregnancy & Postpartum Period | ||
| Nonsmoker | 1.00 | |
| Smoker who quit | 1.29 | (0.62–2.66) |
| Number of cigarettes reduced | 2.58 * | (1.06–6.29) |
| Number of cigarettes same/more | 1.12 | (0.87–1.44) |
| Nonsmoker resumed | 1.19 | (0.86–1.63) |
| Maternal Pre-pregnancy BMI (kg/m2) | ||
| Underweight (≤18.5) | 1.22 | (0.86–1.74) |
| Normal (18.5–25) | 1.00 | |
| Overweight (25–30) | 1.16 | (0.97–1.38) |
| Obese (≥30) | 1.20 | (0.99–1.45) |
| Model | AUC | Sensitivity | Specificity | Accuracy | Precision | F1 |
|---|---|---|---|---|---|---|
| RF | 0.884 | 0.732 | 0.865 | 0.791 | 0.839 | 0.776 |
| SVM | 0.864 | 0.791 | 0.788 | 0.789 | 0.789 | 0.789 |
| GBM | 0.859 | 0.695 | 0.868 | 0.781 | 0.839 | 0.760 |
| AdaBoost | 0.857 | 0.722 | 0.835 | 0.778 | 0.813 | 0.765 |
| NB | 0.793 | 0.578 | 0.853 | 0.675 | 0.709 | 0.647 |
| RPART | 0.789 | 0.658 | 0.807 | 0.731 | 0.772 | 0.708 |
| kNN | 0.776 | 0.925 | 0.455 | 0.641 | 0.593 | 0.715 |
| LR | 0.707 | 0.628 | 0.683 | 0.655 | 0.665 | 0.646 |
| NNET | 0.704 | 0.650 | 0.660 | 0.650 | 0.649 | 0.651 |
| Features | Frequency | RF Rank | GBM Rank | AdaBoost Rank | SVM Rank | Description |
|---|---|---|---|---|---|---|
| BF5WEEKS | 4 | 2 | 2 | 5 | 3 | Number of weeks spent breastfeeding the baby |
| BPG_DEPRS | 4 | 3 | 3 | 4 | 7 | Depression before pregnancy |
| MAT_AGE_NAPHSIS | 4 | 9 | 5 | 13 | 9 | Maternal age grouped |
| STRS_T_G | 4 | 1 | 1 | 1 | 1 | Total number of stresses during the 12 months before childbirth grouped |
| INCOME7 | 3 | 6 | 15 | NA | 2 | Total household income during the 12 months before childbirth |
| MAT_ED | 3 | 7 | 8 | NA | 4 | Maternal education |
| PRE_DEPR | 3 | NA | 12 | 19 | 16 | Pre-pregnancy check for depression/anxiety |
| PREG_TRY | 3 | NA | 6 | 6 | 17 | Trying to get pregnant |
| STRS_BIL | 3 | 12 | 7 | NA | 5 | Stress—couldn’t pay rent, mortgage, or other bills |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, D.; Lee, K.J.; Adeluwa, T.; Hur, J. Machine Learning-Based Predictive Modeling of Postpartum Depression. J. Clin. Med. 2020, 9, 2899. https://doi.org/10.3390/jcm9092899
Shin D, Lee KJ, Adeluwa T, Hur J. Machine Learning-Based Predictive Modeling of Postpartum Depression. Journal of Clinical Medicine. 2020; 9(9):2899. https://doi.org/10.3390/jcm9092899
Chicago/Turabian StyleShin, Dayeon, Kyung Ju Lee, Temidayo Adeluwa, and Junguk Hur. 2020. "Machine Learning-Based Predictive Modeling of Postpartum Depression" Journal of Clinical Medicine 9, no. 9: 2899. https://doi.org/10.3390/jcm9092899
APA StyleShin, D., Lee, K. J., Adeluwa, T., & Hur, J. (2020). Machine Learning-Based Predictive Modeling of Postpartum Depression. Journal of Clinical Medicine, 9(9), 2899. https://doi.org/10.3390/jcm9092899