

Combining the Classification and Pharmacophore Approaches to Understand Homogeneous Olfactory Perceptions at Peripheral Level: Focus on Two Aroma Mixtures

Abstract
:
1. Introduction
- An odor blending, which results from a configural processing of the mixture and occurs when the perceived odor is a new odor that differs from those of the odorants in the mixture;
- A complete overshadowing (or masking) when the odor of only one of the components of the mixture is recognized.
2. Results
2.1. Overview of the Dataset
2.2. Dimensions Reduction and Clustering
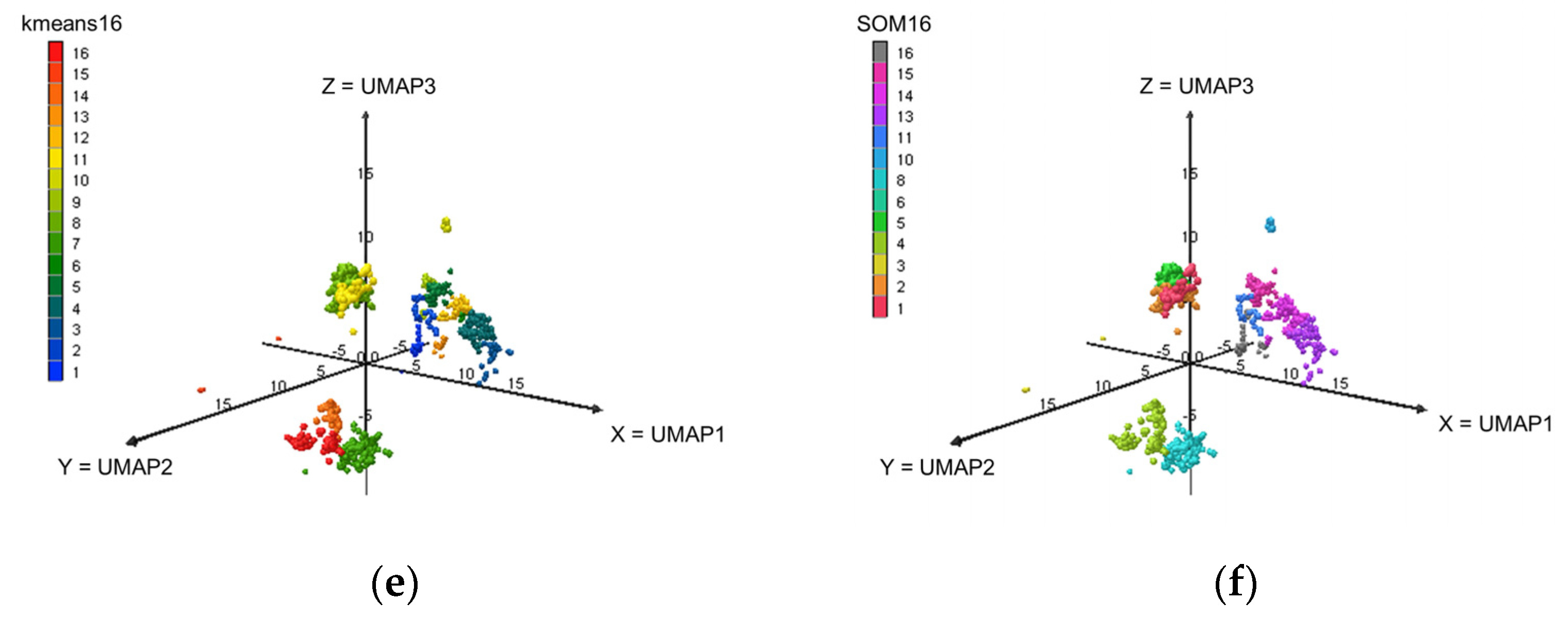
2.2.1. Dimensions Reduction
2.2.2. Clustering
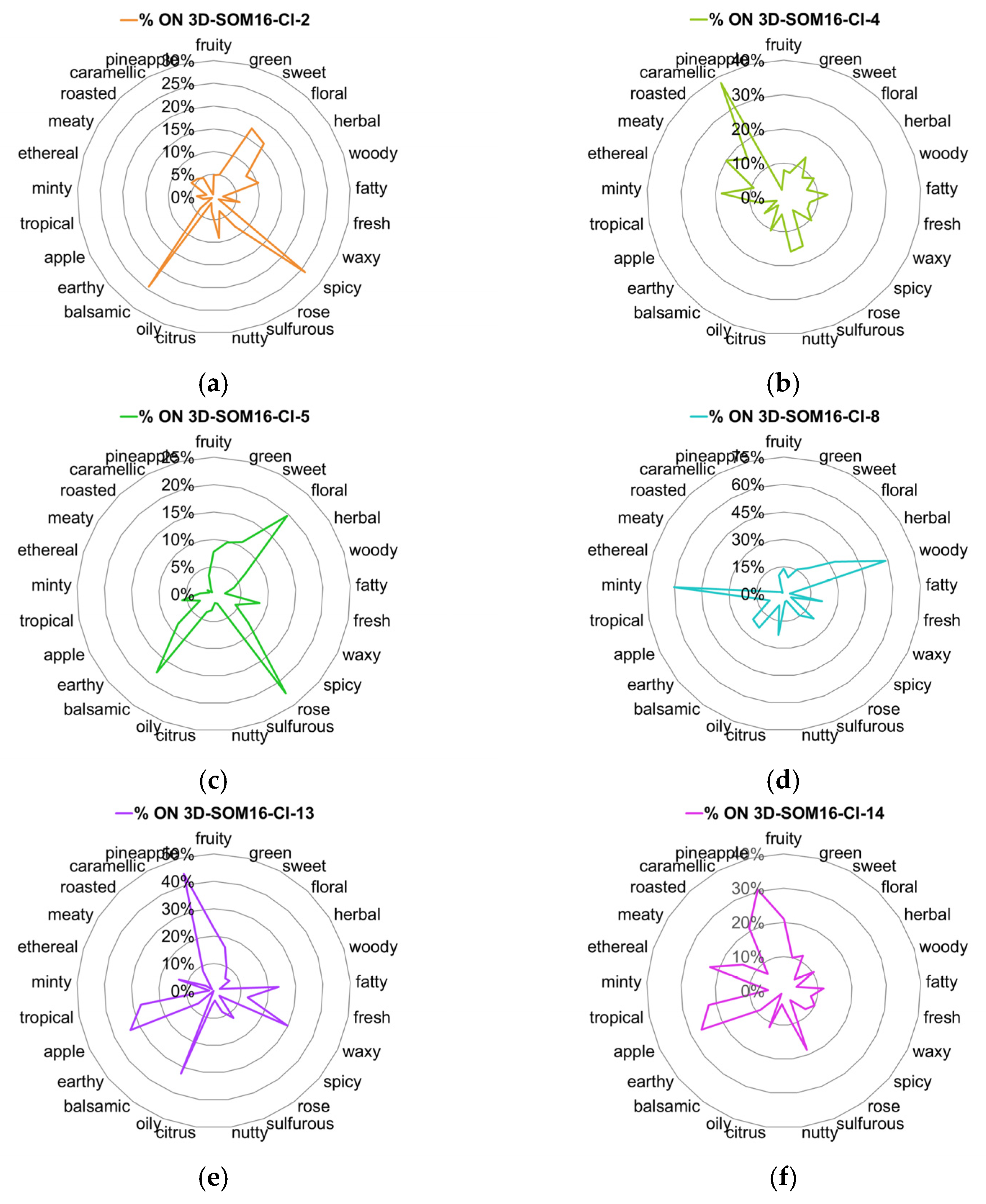
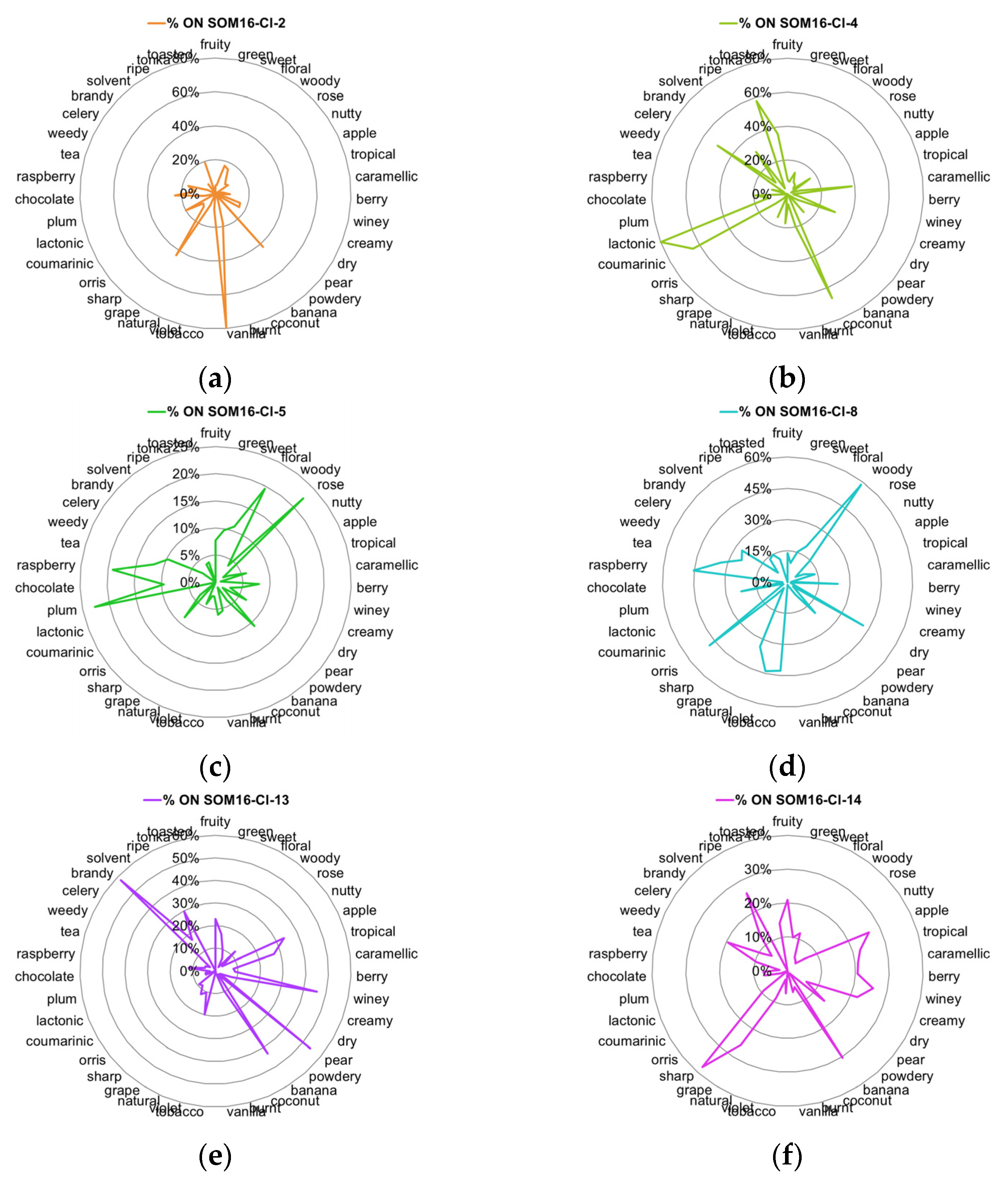
2.3. Distribution of Odor Notes within Clusters
- the relative frequency of every odor notes compared to its frequency in the database (Equation (1));
- the relative frequency of odorants carrying each odor note compared to the number of molecules in the considered cluster (Equation (2)).
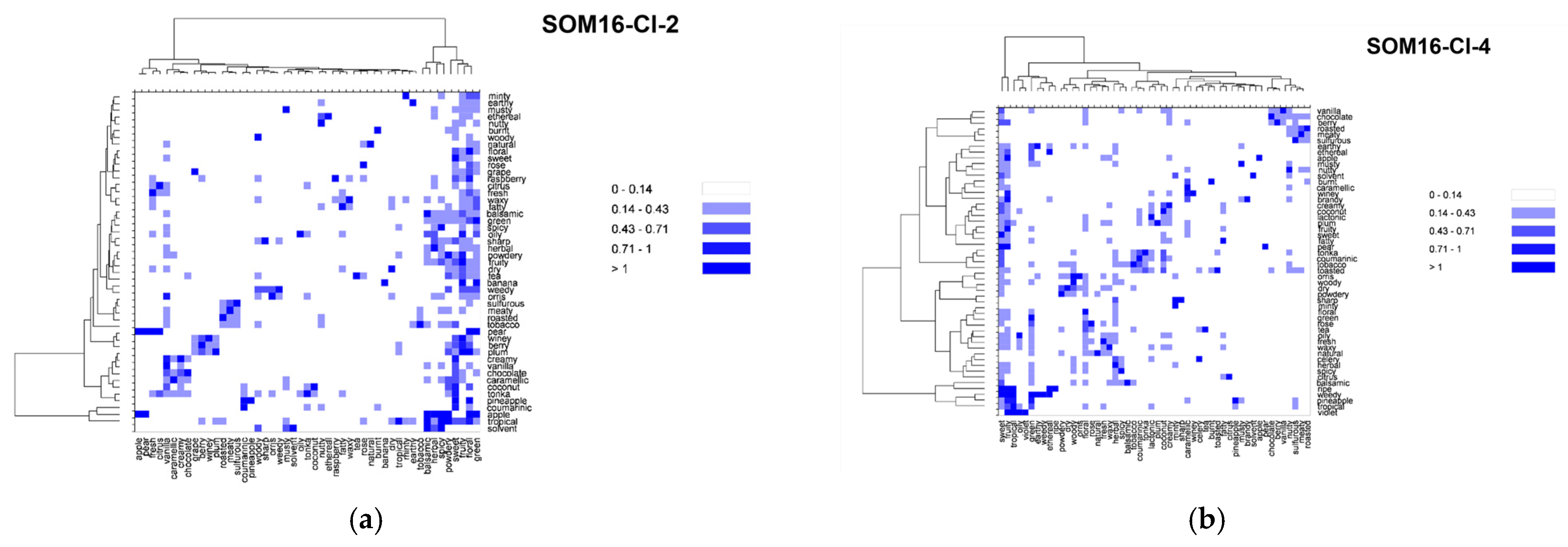
2.4. Co-Occurrences of Odor Notes across the Clusters SOM16
2.5. Selection of Subsets of Odorants Based on Odor Profiles
- If in these first criteria, more than 10 molecules were selected, we again selected these molecules in which the percentage of noncommon odor notes was the smallest;
- If there was still a need to restrict the number of molecules selected, we selected the molecules that had the highest percentage of common odor notes.
2.6. Pharmacophore Study
- From groups based on the mixture components and containing at least two molecules of the mixtures;
- From each molecule component of the mixtures: each molecule is, in fact, an ensemble of its conformers (energy range of 21 kJ/mol) and was denoted “M-c”, where M is the molecule, and c symbolizes conformers;
- From the subsets of molecules selected in the SOM16 clusters: the subsets of various molecules were named by the initial of the referred molecule followed by the initial “s” (for subset). For example, the vanillin subset selected on the basis of the odorant profile was named “V-s”.
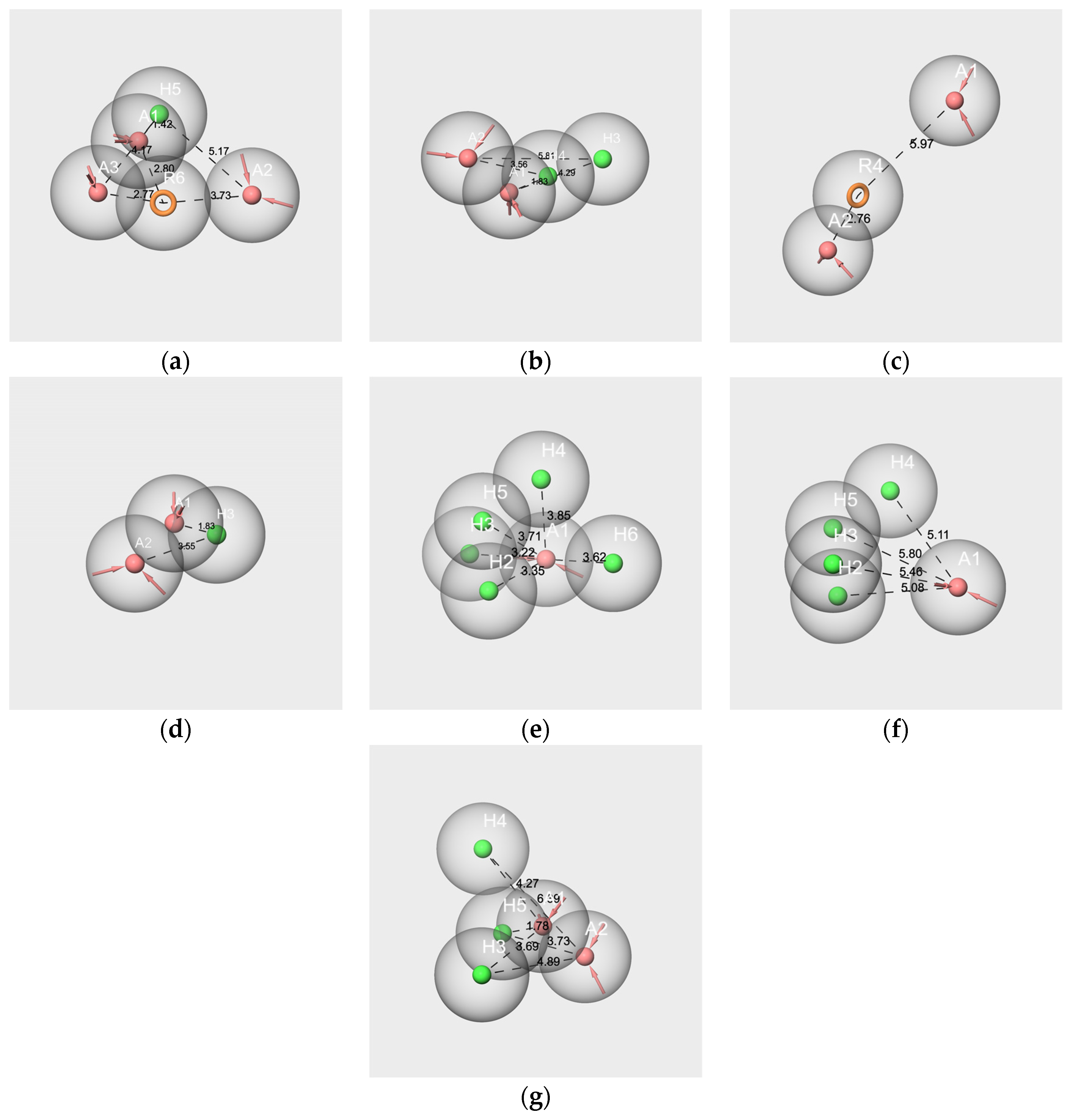
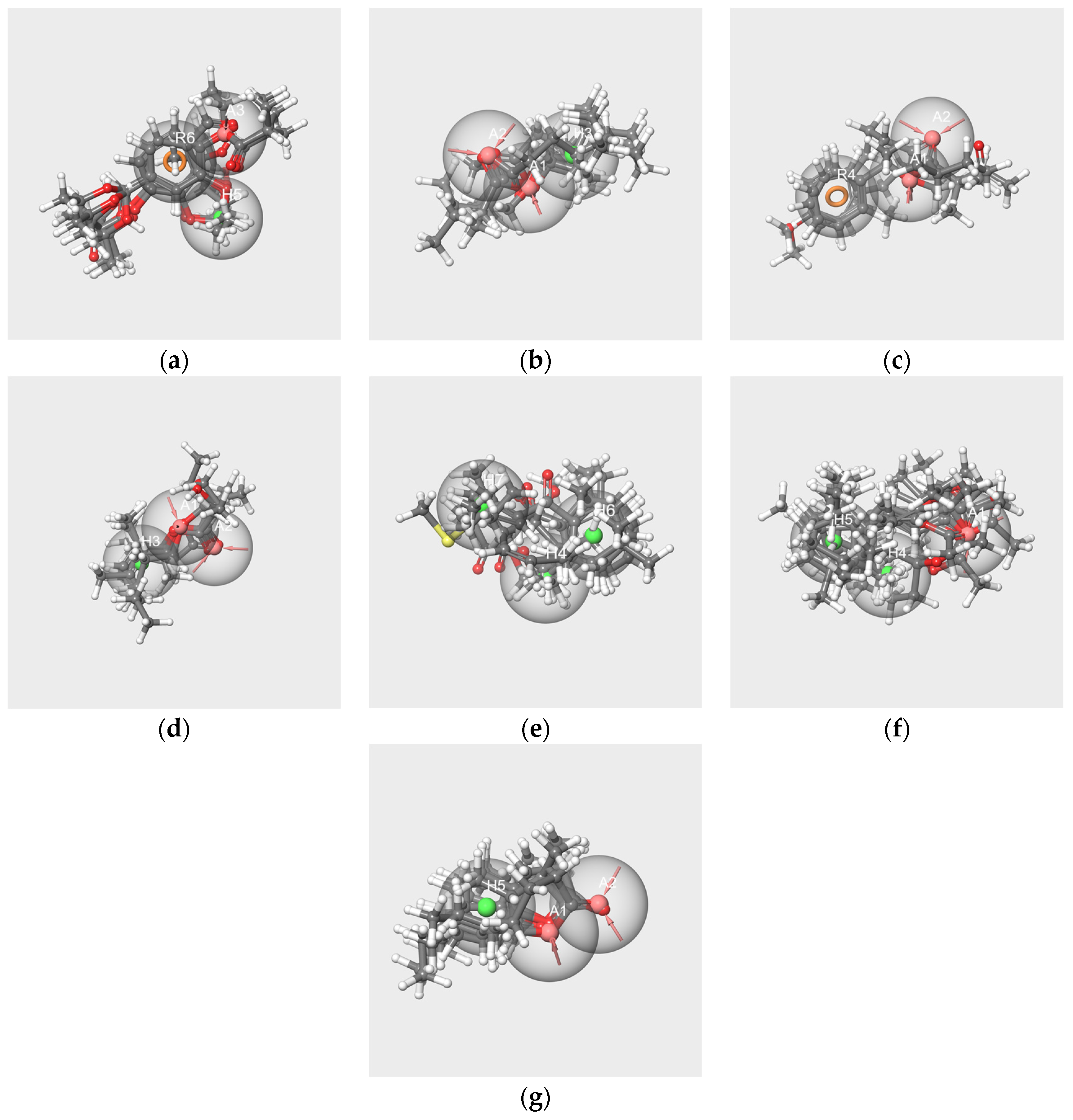
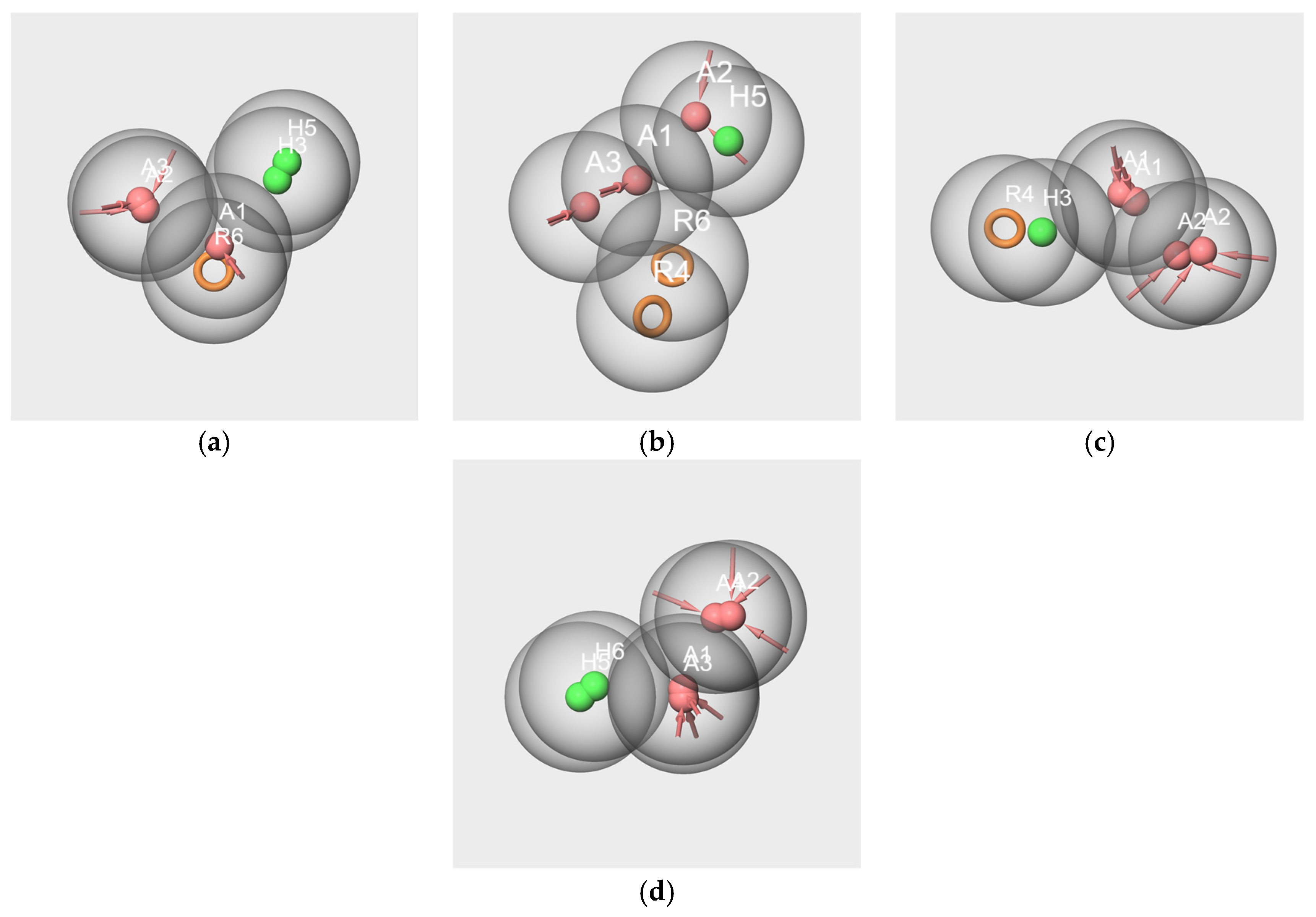
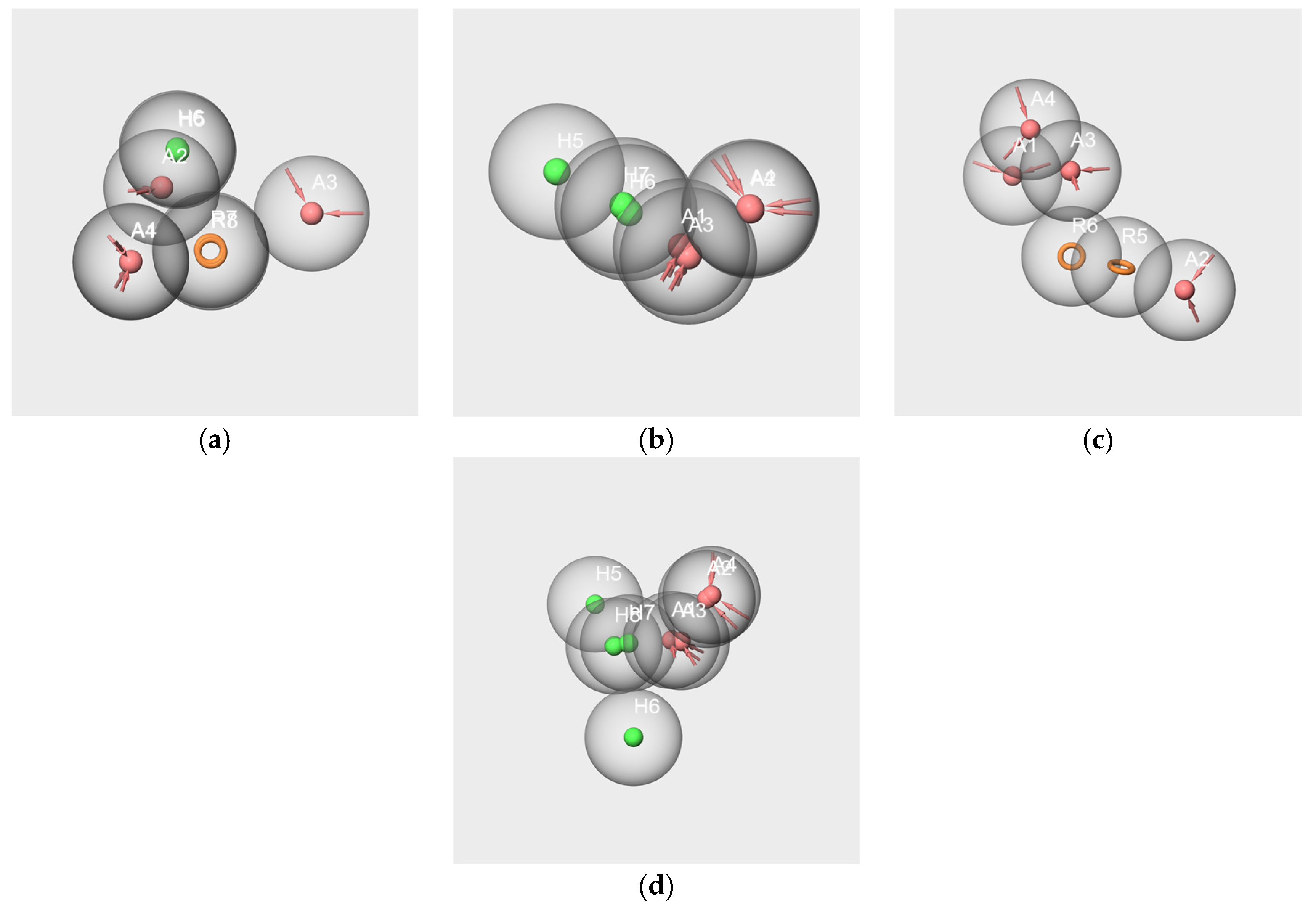
2.6.1. Pharmacophores Generated from Subsets Composed of Components of the Mixtures
- Pharmacophores generated from the subsets based on the “Red Cordial” mixture
- 2.
- Pharmacophores generated from the subset WL/IA-s
2.6.2. Pharmacophore Generated from the Conformers of Each Single Molecule Component of the RC Mixture and WL/IA Masking
2.6.3. Pharmacophores from the Subsets of Molecules Having Similar Odor Profiles
2.6.4. Pharmacophore Comparisons
- The hypotheses generated from the molecules: hyp-V-c, hyp-IA-c, F, and hyp-WL-c;
- The hypotheses generated from the subsets of molecules having odor profiles similar to those of components of the mixtures: hyp-V-s, hyp-IA-s, hyp-F-s, and hyp-WL-s;
- The hypothesis of each molecule with the hypothesis generated from the subset of similar odor profiles.
3. Discussion
4. Materials and Methods
4.1. Description of the Dataset and Molecules of Interest
4.2. Fingerprint Generation, Dimension Reduction and Clustering
4.3. Construction of Pharmacophores
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Appendix A
Appendix A.1. Classification at Level L4
- In area Aa: 1547 elements constitute the clusters k-means4-Cl-3 and SOM4-Cl-3.
- In area Ab: 1569 elements constitute the clusters k-means4-Cl-4 and SOM4-Cl-2.
- The area Ac encloses the following clusters: k-means4-Cl-1 (932 elements), k-means4-Cl-2 (1617elements), SOM4-Cl-1 (1612) and SOM4-Cl-4 (937 elements).
Appendix A.2. Classification at Level L9
- k-means9-Cl-3 (394 elements), k-means9-Cl-4 (575 elements), k-means9-Cl-8 (569 elements);
- SOM9-Cl-7 (933 elements) and SOM9-Cl-8 (605 elements).
- To the clusters k-means9-Cl-1 (377 elements), k-means9-Cl-5 (1249 elements) and k-means9-Cl-9 (917 elements);
- To the clusters SOM9-Cl-2 (377 elements), SOM9-Cl-1 (1248 elements) and SOM9-Cl-3 (918 elements).
Appendix A.3. Classification at Level L16

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k-means16 ∩ SOM16 | Number of Elements |
|---|---|
| k-means16-Cl-8 ∩ SOM16-Cl-2 | 499 |
| k-means16-Cl-8 ∩ SOM16-Cl-5 | 400 |
| k-means16-Cl-8 ∩ SOM16-Cl-6 | 130 |
| k-means16-Cl-11 ∩ SOM16-Cl-1 | 430 |
| k-means16-Cl-11 ∩ SOM16-Cl-2 | 88 |
| Clusters in Area Ac | Number of Elements |
|---|---|
| k-means16-Cl-1 | 185 |
| k-means16-Cl-2 | 248 |
| k-means16-Cl-3 | 250 |
| k-means16-Cl-4 | 608 |
| k-means16-Cl-5 | 302 |
| k-means16-Cl-6 | 146 |
| k-means16-Cl-9 | 266 |
| k-means16-Cl-10 | 145 |
| k-means16-Cl-12 | 270 |
| k-means16-Cl-13 | 123 |
| SOM16-Cl-10 | 145 |
| SOM16-Cl-11 | 252 |
| SOM16-Cl-13 | 629 |
| SOM16-Cl-14 | 686 |
| SOM16-Cl-15 | 496 |
| SOM16-Cl-16 | 335 |
| k-means16 ∩ SOM16 | Number of Elements |
|---|---|
| k-means16-Cl-1 ∩ SOM16-Cl-16 | 185 |
| k-means16-Cl-2 ∩ SOM16-Cl-11 | 248 |
| k-means16-Cl-3 ∩ SOM16-Cl-13 | 250 |
| k-means16-Cl-4 ∩ SOM16-Cl-13 | 379 |
| k-means16-Cl-4 ∩ SOM16-Cl-14 | 229 |
| k-means16-Cl-5 ∩ SOM16-Cl-11 | 4 |
| k-means16-Cl-5 ∩ SOM16-Cl-15 | 298 |
| k-means16-Cl-6 ∩ SOM16-Cl-14 | 146 |
| k-means16-Cl-9 ∩ SOM16-Cl-15 | 197 |
| k-means16-Cl-9 ∩ SOM16-Cl-16 | 69 |
| k-means16-Cl-10 ∩ SOM16-Cl-10 | 145 |
| k-means16-Cl-12 ∩ SOM16-Cl-14 | 269 |
| k-means16-Cl-12 ∩ SOM16-Cl-15 | 1 |
| k-means16-Cl-13 ∩ SOM16-Cl-14 | 42 |
| k-means16-Cl-13 ∩ SOM16-Cl-16 | 81 |
References
- Murthy, V.N. Olfactory Maps in the Brain. Annu. Rev. Neurosci. 2011, 34, 233–258. [Google Scholar] [CrossRef] [PubMed]
- Buck, L.B. Information coding in the vertebrate olfactory system. Annu. Rev. Neurosci. 1996, 19, 517–544. [Google Scholar] [CrossRef]
- Malnic, B.; Hirono, J.; Sato, T.; Buck, L.B. Combinatorial receptor codes for odors. Cell 1999, 96, 713–723. [Google Scholar] [CrossRef] [PubMed]
- Touhara, K. Odor discrimination by G protein-coupled olfactory receptors. Microsc. Res. Tech. 2002, 58, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Mainland, J.D.; Li, Y.R.; Zhou, T.; Liu, W.L.L.; Matsunami, H. Human olfactory receptor responses to odorants. Sci. Data 2015, 2, 150002. [Google Scholar] [CrossRef]
- Peterlin, Z.; Firestein, S.; Rogers, M.E. The state of the art of odorant receptor deorphanization: A report from the orphanage. J. Gen. Physiol. 2014, 143, 527–542. [Google Scholar] [CrossRef]
- Thomas-Danguin, T.; Sinding, C.; Romagny, S.; El Mountassir, F.; Atanasova, B.; Le Berre, E.; Le Bon, A.-M.; Coureaud, G. The perception of odor objects in everyday life: A review on the processing of odor mixtures. Front. Psychol. 2014, 5, 504. [Google Scholar] [CrossRef]
- Berglund, B.; Berglund, U.; Lindvall, T. Psychological processing of odor mixtures. Psychol. Rev. 1976, 83, 432–441. [Google Scholar] [CrossRef]
- Kay, L.M.; Crk, T.; Thorngate, J. A Redefinition of Odor Mixture Quality. Behav. Neurosci. 2005, 119, 726–733. [Google Scholar] [CrossRef]
- Genva, M.; Kemene, T.K.; Deleu, M.; Lins, L.; Fauconnier, M.L. Is It Possible to Predict the Odor of a Molecule on the Basis of its Structure? Int. J. Mol. Sci. 2019, 20, 3018. [Google Scholar] [CrossRef]
- Keller, A.; Gerkin, R.C.; Guan, Y.F.; Dhurandhar, A.; Turu, G.; Szalai, B.; Mainland, J.D.; Ihara, Y.; Yu, C.W.; Wolfinger, R.; et al. Predicting human olfactory perception from chemical features of odor molecules. Science 2017, 355, 820–826. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.Y.; Zhang, K.; Lin, D.R.; Zhu, Y.; Chen, C.; He, L.; Guo, X.S.; Chen, K.X.; Wang, R.X.; Liu, Z.Z.; et al. Artificial intelligence deciphers codes for color and odor perceptions based on large-scale chemoinformatic data. GigaScience 2020, 9, giaa011. [Google Scholar] [CrossRef] [PubMed]
- Gerkin, R.C. Parsing Sage and Rosemary in Time: The Machine Learning Race to Crack Olfactory Perception. Chem. Senses 2021, 46, bjab020. [Google Scholar] [CrossRef]
- Rugard, M.; Jaylet, T.; Taboureau, O.; Tromelin, A.; Audouze, K. Smell compounds classification using UMAP to increase knowledge of odors and molecular structures linkages. PLoS ONE 2021, 16, e0252486. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Kumar, R.; Ranjta, S.; Varadwaj, P.K. SMILES to Smell: Decoding the Structure-Odor Relationship of Chemical Compounds Using the Deep Neural Network Approach. J. Chem. Inf. Model. 2021, 61, 676–688. [Google Scholar] [CrossRef]
- Achebouche, R.; Tromelin, A.; Audouze, K.; Taboureau, O. Application of artificial intelligence to decode the relationships between smell, olfactory receptors and small molecules. Sci. Rep. 2022, 12, 18817. [Google Scholar] [CrossRef]
- Saini, K.; Ramanathan, V. Predicting odor from molecular structure: A multi-label classification approach. Sci. Rep. 2022, 12, 13863. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Q.L.; Ma, M.Y.; Xu, J. Decoding Structure-Odor Relationship Based on Hypergraph Neural Network and Deep Attentional Factorization Machine. Appl. Sci. 2022, 12, 8777. [Google Scholar] [CrossRef]
- Leach, A.R.; Gillet, V.J.; Lewis, R.A.; Taylor, R. Three-Dimensional Pharmacophore Methods in Drug Discovery. J. Med. Chem. 2010, 53, 539–558. [Google Scholar] [CrossRef]
- Wermuth, G.; Ganellin, C.R.; Lindberg, P.; Mitscher, L.A. Glossary of terms used in medicinal chemistry (IUPAC Recommendations 1998). Pure Appl. Chem. 1998, 70, 1129–1143. [Google Scholar] [CrossRef]
- Gund, P. Evolution of the pharmacophore concept in pharmaceutical research. In Pharmacophore Perception, Development and Use in Drug Design; Güner, O.F., Ed.; International University Line: La Jolla, CA, USA, 2000; pp. 3–12. [Google Scholar]
- Yang, S.Y. Pharmacophore modeling and applications in drug discovery: Challenges and recent advances. Drug Discov. Today 2010, 15, 444–450. [Google Scholar] [CrossRef] [PubMed]
- Tromelin, A.; Koensgen, F.; Audouze, K.; Guichard, E.; Thomas-Danguin, T. Exploring the Characteristics of an Aroma-Blending Mixture by Investigating the Network of Shared Odors and the Molecular Features of Their Related Odorants. Molecules 2020, 25, 3032. [Google Scholar] [CrossRef] [PubMed]
- Atanasova, B.; Thomas-Danguin, T.; Langlois, D.; Nicklaus, S.; Etievant, P. Perceptual interactions between fruity and woody notes of wine. Flavour. Fragr. J. 2004, 19, 476–482. [Google Scholar] [CrossRef]
- Le Berre, E.; Jarmuzek, E.; Béno, N.; Etiévant, P.; Prescott, J.; Thomas-Danguin, T. Learning Influences the Perception of Odor Mixtures. Chem. Percept. 2010, 3, 156–166. [Google Scholar] [CrossRef]
- Chaput, M.A.; El Mountassir, F.; Atanasova, B.; Thomas-Danguin, T.; Le Bon, A.M.; Perrut, A.; Ferry, B.; Duchamp-Viret, P. Interactions of odorants with olfactory receptors and receptor neurons match the perceptual dynamics observed for woody and fruity odorant mixtures. Eur. J. Neurosci. 2012, 35, 584–597. [Google Scholar] [CrossRef] [PubMed]
- Sinding, C.; Thomas-Danguin, T.; Chambault, A.; Béno, N.; Dosne, T.; Chabanet, C.; Schaal, B.; Coureaud, G. Rabbit Neonates and Human Adults Perceive a Blending 6-Component Odor Mixture in a Comparable Manner. PLoS ONE 2013, 8, e53534. [Google Scholar] [CrossRef]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Dixon, S.L.; Smondyrev, A.M.; Knoll, E.H.; Rao, S.N.; Shaw, D.E.; Friesner, R.A. PHASE: A new engine for pharmacophore perception, 3D QSAR model development, and 3D database screening: 1. Methodology and preliminary results. J. Comput. Aided Mol. Des. 2006, 20, 647–671. [Google Scholar] [CrossRef]
- Arctander, S. Perfume and Flavor Chemicals (Aroma Chemicals) Volumes 1 and 2; Allured Publishing Corporation: Carol Stream, IL, USA, 1969. [Google Scholar]
- Leffingwell Flavor-Base, 10th ed. Available online: http://www.leffingwell.com/flavbase.htm (accessed on 10 April 2023).
- Sanz, G.; Thomas-Danguin, T.; Hamdani, E.H.; Le Poupon, C.; Briand, L.; Pernollet, J.C.; Guichard, E.; Tromelin, A. Relationships Between Molecular Structure and Perceived Odor Quality of Ligands for a Human Olfactory Receptor. Chem. Senses 2008, 33, 639–653. [Google Scholar] [CrossRef]
- Launay, G.; Teletchea, S.; Wade, F.; Pajot-Augy, E.; Gibrat, J.F.; Sanz, G. Automatic modeling of mammalian olfactory receptors and docking of odorants. Protein Eng. Des. Sel. 2012, 25, 377–386. [Google Scholar] [CrossRef]
- Charlier, L.; Topin, J.; Ronin, C.; Kim, S.K.; Goddard, W.A.; Efremov, R.; Golebiowski, J. How broadly tuned olfactory receptors equally recognize their agonists. Human OR1G1 as a test case. Cell. Mol. Life Sci. 2012, 69, 4205–4213. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.K.; Goddard, W.A. Predicted 3D structures of olfactory receptors with details of odorant binding to OR1G1. J. Comput. Aided Mol. Des. 2014, 28, 1175–1190. [Google Scholar] [CrossRef] [PubMed]
- Belhassan, A.; Zaki, H.; Chtita, S.; Benlyas, M.; Lakhlifi, T.; Bouachrine, M. Study of interactions between odorant molecules and the hOR1G1 olfactory receptor by molecular modeling. Egypt. J. Ear Nose Throat Allied Sci. 2017, 18, 257–265. [Google Scholar] [CrossRef]
- Fukutani, Y.; Abe, M.; Saito, H.; Eguchi, R.; Tazawa, T.; de March, C.A.; Yohda, M.; Matsunami, H. Antagonistic interactions between odorants alter human odor perception. bioRxiv 2022. [Google Scholar] [CrossRef]
- Zak, J.D.; Reddy, G.; Vergassola, M.; Murthy, V.N. Antagonistic odor interactions in olfactory sensory neurons are widespread in freely breathing mice. Nat. Commun. 2020, 11, 3350. [Google Scholar] [CrossRef]
- Inagaki, S.; Iwata, R.; Iwamoto, M.; Imai, T. Widespread Inhibition, Antagonism, and Synergy in Mouse Olfactory Sensory Neurons In Vivo. Cell Rep. 2020, 31, 107814. [Google Scholar] [CrossRef]
- Xu, L.; Li, W.Z.; Voleti, V.; Zou, D.J.; Hillman, E.M.C.; Firestein, S. Widespread receptor-driven modulation in peripheral olfactory coding. Science 2020, 368, eaaz5390. [Google Scholar] [CrossRef]
- de March, C.A.; Titlow, W.B.; Sengoku, T.; Breheny, P.; Matsunami, H.; McClintock, T.S. Modulation of the combinatorial code of odorant receptor response patterns in odorant mixtures. Mol. Cell. Neurosci. 2020, 104, 103469. [Google Scholar] [CrossRef]
- Zarzo, M.; Stanton, D.T. Understanding the underlying dimensions in perfumers’ odor perception space as a basis for developing meaningful odor maps. Atten. Percept. Psychophys. 2009, 71, 225–247. [Google Scholar] [CrossRef]
- The Good Scents Company. Available online: http://www.thegoodscentscompany.com (accessed on 10 April 2023).
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 10 April 2023).
- Kohonen, T. The self-organizing map. Neurocomputing 1998, 21, 1–6. [Google Scholar] [CrossRef]
- Wehrens, R.; Buydens, L.M.C. Self- and super-organizing maps in R: The kohonen package. J. Stat. Softw. 2007, 21, 1–19. [Google Scholar] [CrossRef]
- Mingoti, S.A.; Lima, J.O. Comparing SOM neural network with Fuzzy c-means, K-means and traditional hierarchical clustering algorithms. Eur. J. Oper. Res. 2006, 174, 1742–1759. [Google Scholar] [CrossRef]
- Rodriguez, M.Z.; Comin, C.H.; Casanova, D.; Bruno, O.M.; Amancio, D.R.; Costa, L.D.; Rodrigues, F.A. Clustering algorithms: A comparative approach. PLoS ONE 2019, 14, e0210236. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.D.; Clauset, A.; Harris, R.; Bayram, E.; Santago, P.; Schmitt, J.D. Supervised self-organizing maps in drug discovery. 1. Robust behavior with overdetermined data sets. J. Chem. Inf. Model. 2005, 45, 1749–1758. [Google Scholar] [CrossRef] [PubMed]
- Kaushik, M.; Mathur, B. Comparative study of K-means and hierarchical clustering techniques. Int. J. Softw. Hardw. Res. Eng. 2014, 2, 93–98. [Google Scholar]
- Kohonen, T. Essentials of the self-organizing map. Neural Netw. 2013, 37, 52–65. [Google Scholar] [CrossRef]
- Kelley, L.A.; Gardner, S.P.; Sutcliffe, M.J. An automated approach for clustering an ensemble of NMR-derived protein structures into conformationally related subfamilies. Protein Eng. 1996, 9, 1063–1065. [Google Scholar] [CrossRef]
- Addinsoft XLSTAT Statistical and Data Analysis Solution. Paris, France. Available online: https://www.xlstat.com (accessed on 10 April 2023).
- Van Drie, J. Pharmacophore Discovery—Lessons Learned. Curr. Pharm. Des. 2003, 9, 1649–1664. [Google Scholar] [CrossRef]
- Khedkar, S.; Malde, A.; Coutinho, E.; Srivastava, S. Pharmacophore Modeling in Drug Discovery and Development: An Overview. Med. Chem. 2007, 3, 187–197. [Google Scholar] [CrossRef]
- Schaller, D.; Šribar, D.; Noonan, T.; Deng, L.; Nguyen, T.N.; Pach, S.; Machalz, D.; Bermudez, M.; Wolber, G. Next generation 3D pharmacophore modeling. Wiley Interdiscip. Rev. Comput. Mol. Sci. 2020, 10, e1468. [Google Scholar] [CrossRef]





| Name | CAS | Odor Notes |
|---|---|---|
| Vanillin | 121-33-5 | Sweet; vanilla; creamy; chocolate |
| Isoamyl acetate 1 | 123-92-2 | Sweet; fruity; banana; solvent; pear |
| Frambinone | 5471-51-2 | Sweet; berry; raspberry; ripe; floral; fruity |
| Ethyl acetate | 141-78-6 | Ethereal; fruity; sweet; weedy; green; sharp; brandy; winey |
| beta-Damascenone | 23696-85-7 | Fruity; floral; apple; plum; tea; rose; tobacco; natural; grape; raspberry; sweet |
| beta-Ionone | 14901-07-6 | Floral; woody; sweet; fruity; berry; tropical; violet; raspberry; dry; powdery orris |
| Whiskey lactone | 39212-23-2 | Tonka; coumarinic; coconut; toasted; nutty; celery; burnt; woody; lactonic; maple 2; lovage 2 |
| Name | Area | k-means4 | k-means9 | k-means16 | SOM4 | SOM9 | SOM16 |
|---|---|---|---|---|---|---|---|
| Vanillin | Ab | 3 | 2 | 8 | 3 | 9 | 2 |
| Isoamyl acetate | Ac | 1 | 9 | 4 | 4 | 3 | 13 |
| Frambinone | Ab | 3 | 2 | 8 | 3 | 9 | 5 |
| Ethyl acetate | Ac | 1 | 9 | 4 | 4 | 3 | 14 |
| beta-Ionone | Aa | 4 | 8 | 7 | 2 | 7 | 8 |
| beta-Damascenone | Aa | 4 | 8 | 7 | 2 | 7 | 8 |
| Whiskey lactone | Aa | 4 | 4 | 16 | 2 | 8 | 4 |
| Cluster | Molecule of Interest | Molecule’s Subset with Similar Odor Profile |
|---|---|---|
| SOM16-Cl-2 | Vanillin | Vanillyl isobutyrate; vanillin propylene glycol acetal; ethyl vanillin isobutyrate; 1-Ethoxy-2-methoxybenzene; ortho-dimethyl hydroquinone; ethyl vanillin; vanillyl acetate; vanillylidene acetone; vanillin hexylene glycol acetal; ethyl vanillin hexylene glycol acetal; ethyl vanillin propylene glycol acetal |
| SOM16-Cl-4 | Whiskey lactone | 7-Methyltetrahydronaphthalenone; delta-Heptalactone; Menthofurolactone; Octahydrocoumarin; Laitone; Coconut naphthalenone; (R)-tonka furanone; (+/−)-dihydromint lactone |
| SOM16-Cl-5 | Frambinone | Anisyl isobutyrate; 4-hydroxyphenethyl alcohol; 4-(para-tolyl)-2-butanone; Tufurol acetate; 2-Methylbenzyl acetate; alpha-Methylbenzyl-propionate; Phenethyl-2-methylbutyrate; methyl 4-phenyl butyrate; benzyl acetoacetate |
| SOM16-Cl-8 | beta-Ionone | beta-ionyl acetate; alpha-ionol; alpha-ionyl acetate; 3-Methylcyclohexyl acetate; beta-Irone; Campholene-acetate; Nopyl-acetate; 4-dimethyl ionone |
| SOM16-Cl-8 | beta-Damascenone | plum damascone (high alpha); (Z)-alpha-damascone; Cyclohexylethyl isovalerate; Cyclohexylethyl valerate; 1-(3-(methyl thio)-butyryl)-2,6,6-trimethyl cyclohexene; 3-cyclohexene-1-carboxylic acid, 2,6,6-trimethyl-, methyl ester |
| SOM16-Cl-13 | Isoamyl acetate | 2-Methylbutyl-butyrate; hexyl acetate; isobutyl propionate; methyl butyrate; isopropyl propionate; methyl 4-methyl valerate; isoamyl butyrate; propyl acetate; butyl acetate; amyl acetate |
| SOM16-Cl-14 | Ethyl acetate | 2-Methylbut-2-enyl-formate; Isobutyl pyruvate; methyl acetate; methyl (E)-2-butenoate; ethyl 2-methyl butyrate; 2-methyl butyl propionate; isopropyl acetate; ethyl nitrite; hexyl lactate; methyl 3-hydroxybutyrate |
| Pair of Hypotheses | RMSD |
|---|---|
| hyp-V-c and hyp-IA-c | 0.5647 |
| hyp-V-c and hyp-F-c | - |
| hyp-IA-c and hyp-F-c | - |
| hyp-WL-c and hyp-IA-c | 0.1485 |
| hyp-V-s and hyp-IA-s | 0.5305 |
| hyp-V-s and hyp-F-s | 1.3647 |
| hyp-IA-s and hyp-F-s | 0.7449 |
| hyp-WL-s and hyp-IA-s | 0.3842 |
| hyp-V-c and hyp-V-s | 0.066 |
| hyp-IA-c and hyp-IA-s | 0.247 |
| hyp-F-c and hyp-F-s | - |
| hyp-WL-c and hyp-WL-s | 0.442 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rugard, M.; Audouze, K.; Tromelin, A. Combining the Classification and Pharmacophore Approaches to Understand Homogeneous Olfactory Perceptions at Peripheral Level: Focus on Two Aroma Mixtures. Molecules 2023, 28, 4028. https://doi.org/10.3390/molecules28104028
Rugard M, Audouze K, Tromelin A. Combining the Classification and Pharmacophore Approaches to Understand Homogeneous Olfactory Perceptions at Peripheral Level: Focus on Two Aroma Mixtures. Molecules. 2023; 28(10):4028. https://doi.org/10.3390/molecules28104028
Chicago/Turabian StyleRugard, Marylène, Karine Audouze, and Anne Tromelin. 2023. "Combining the Classification and Pharmacophore Approaches to Understand Homogeneous Olfactory Perceptions at Peripheral Level: Focus on Two Aroma Mixtures" Molecules 28, no. 10: 4028. https://doi.org/10.3390/molecules28104028