
A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism


Abstract
1. Introduction
- ⮚
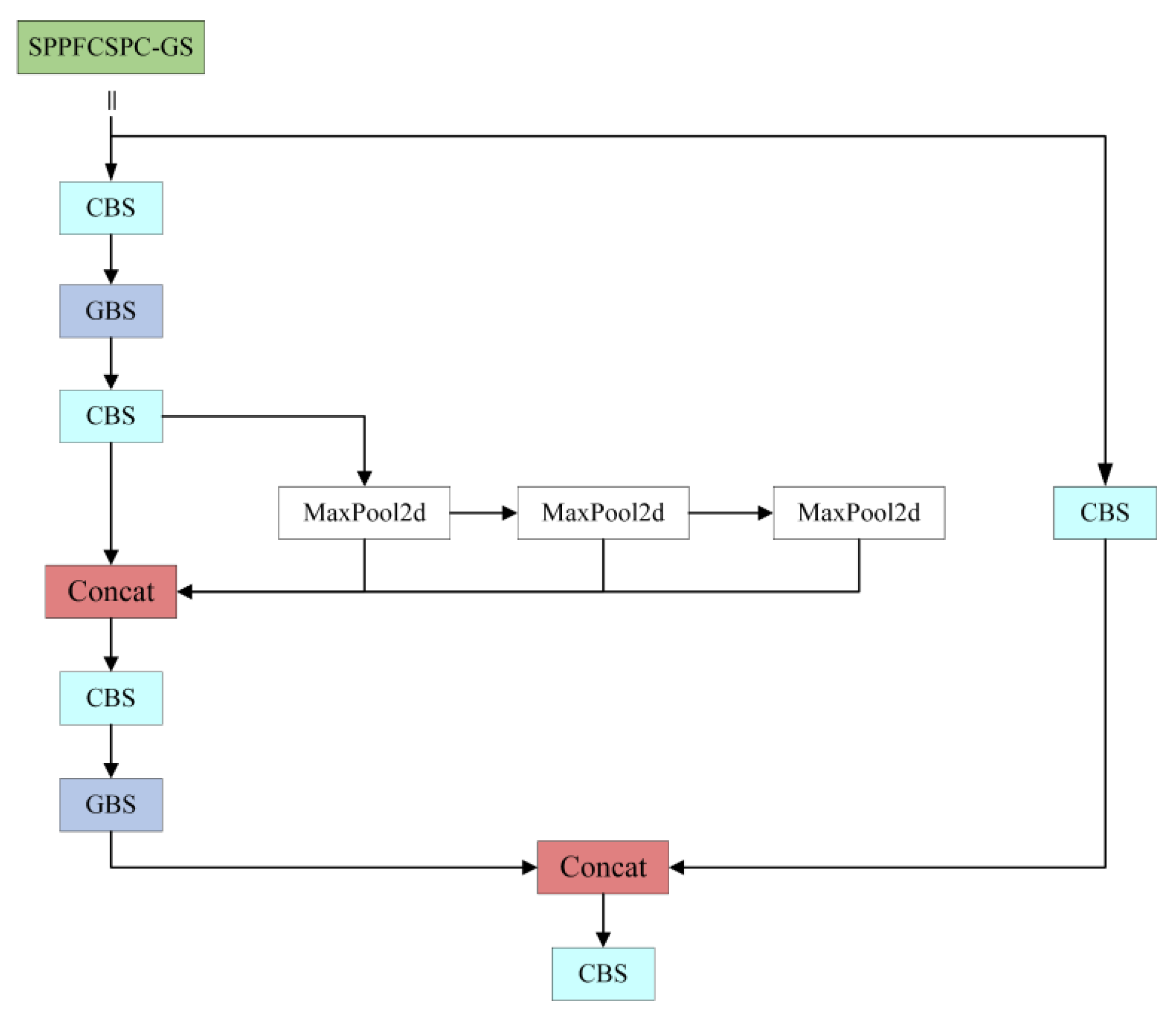
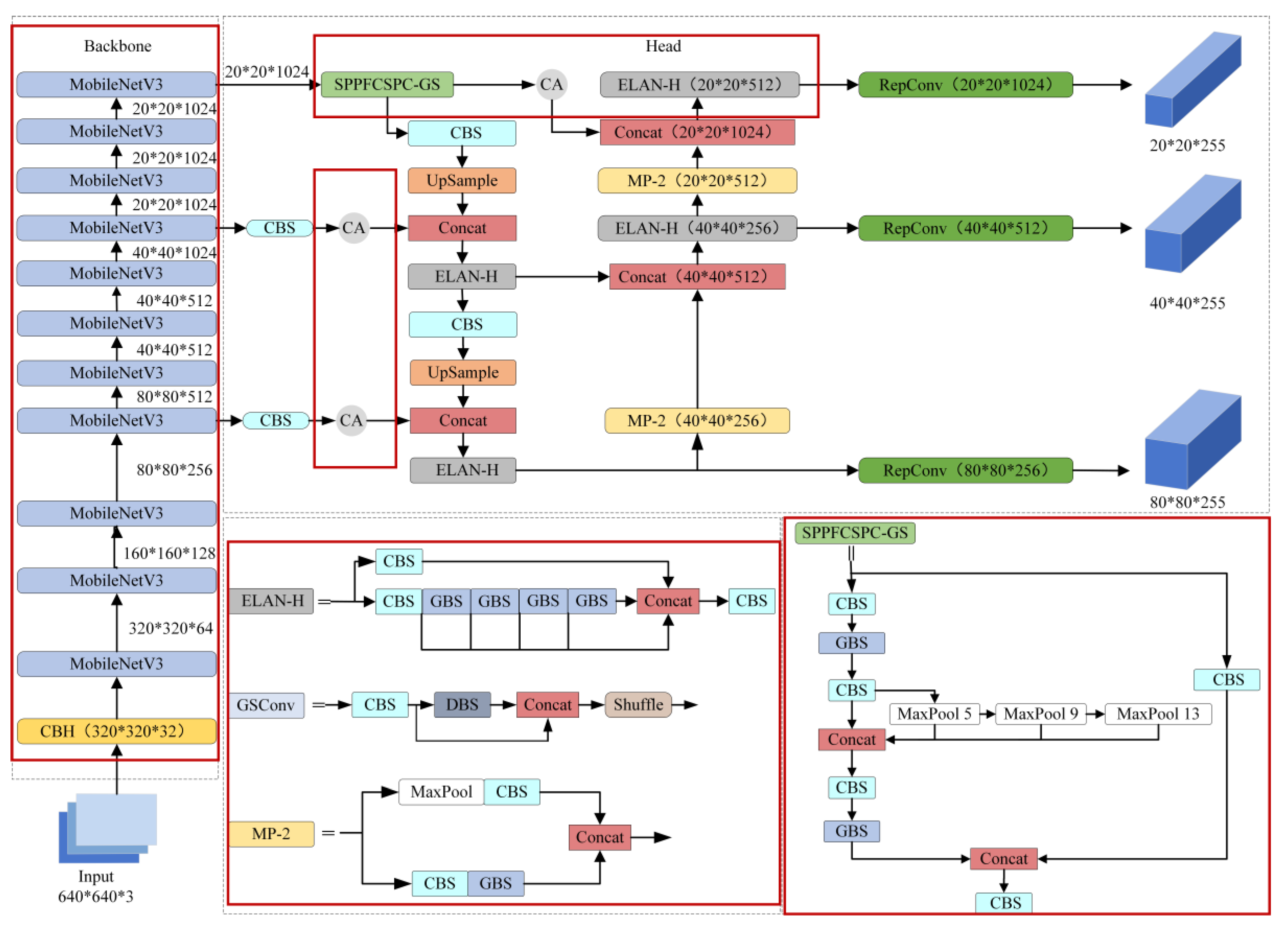
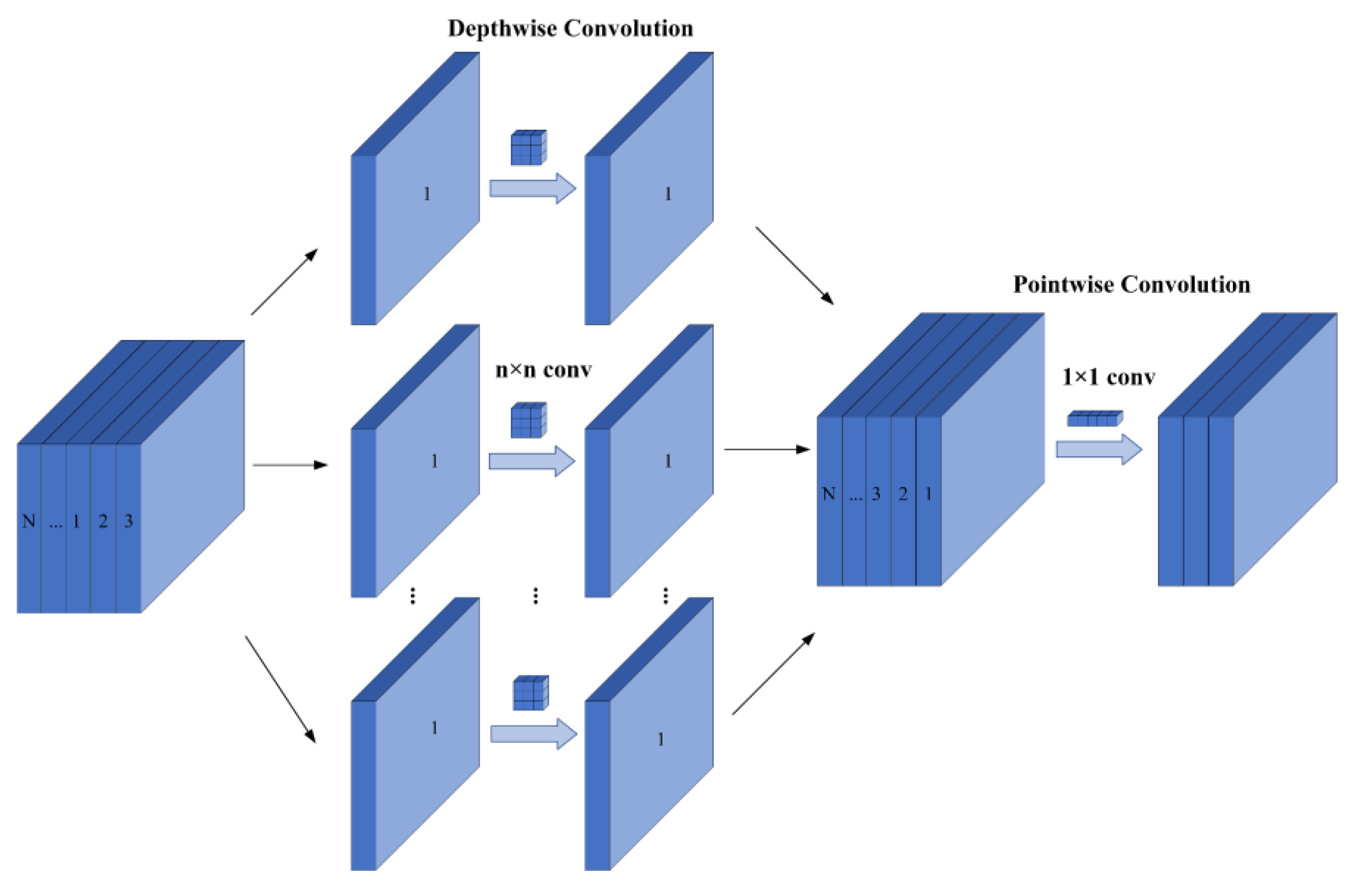
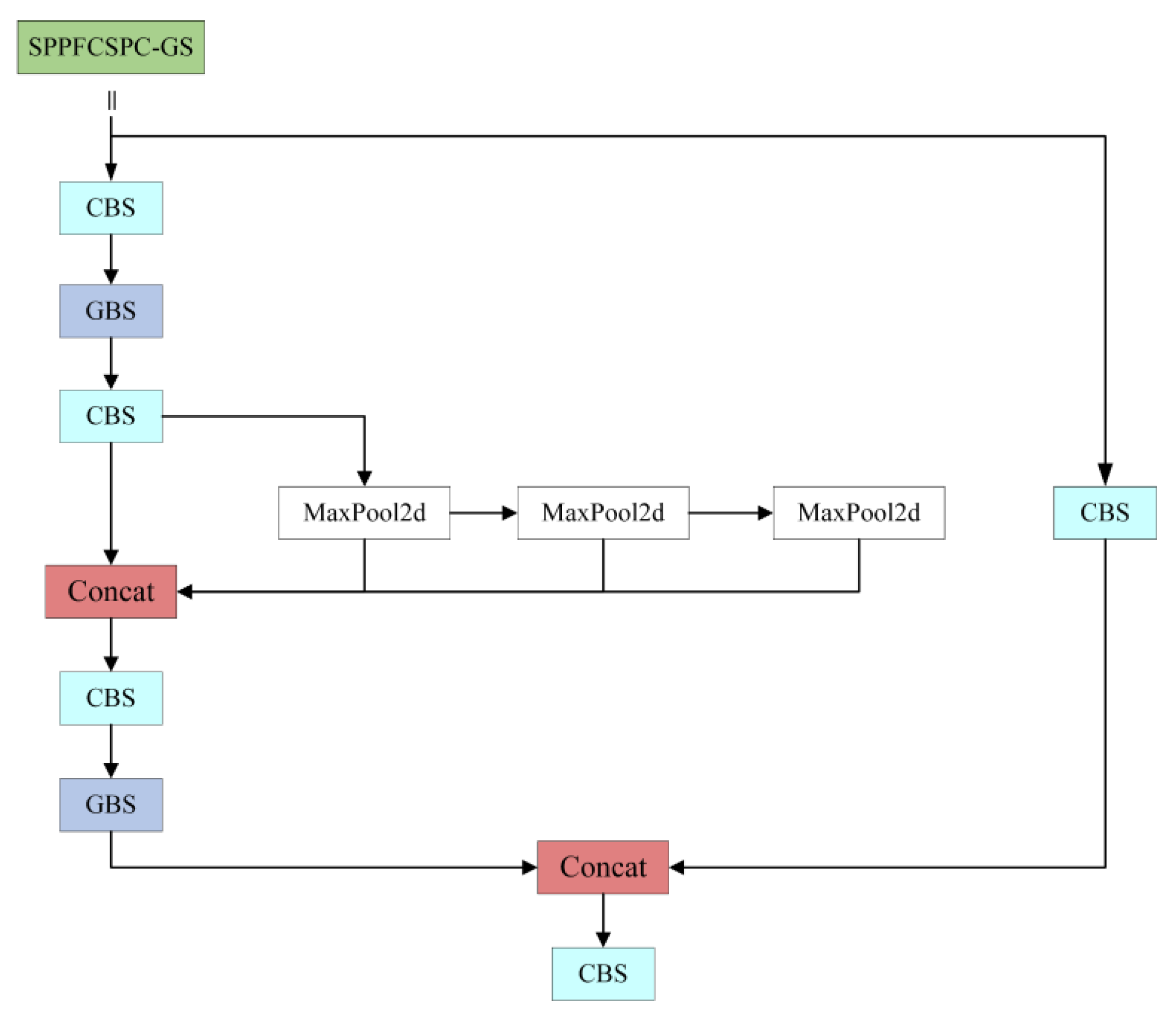
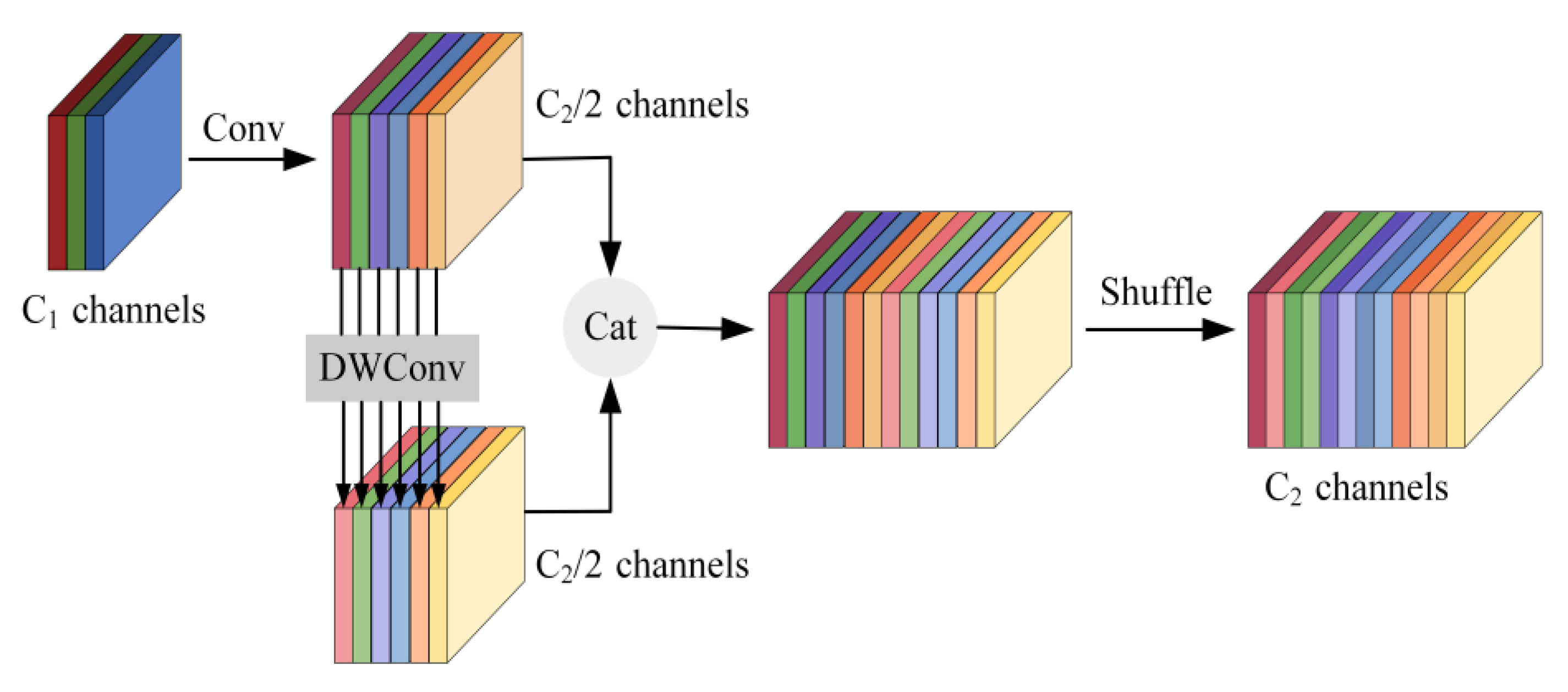
- Lightweight Modules: This paper employs the lightweight MobileNetV3 architecture to replace the backbone network of YOLOv7 and modifies the spatial pyramid parallel pooling structure to serial pooling to speed up the detection rate. Furthermore, inspired by the Generalized Sparse Convolution (GSConv) module, it utilizes GSConv to replace the standard convolution in the neck network. This neck network, in combination with the Spatial Pyramid Pooling Fast Cross-Stage Partial Channel (SPPFCSPC) module, forms the SPPCSPC-GS module, aiming to reduce the number of parameters in the model.
- ⮚
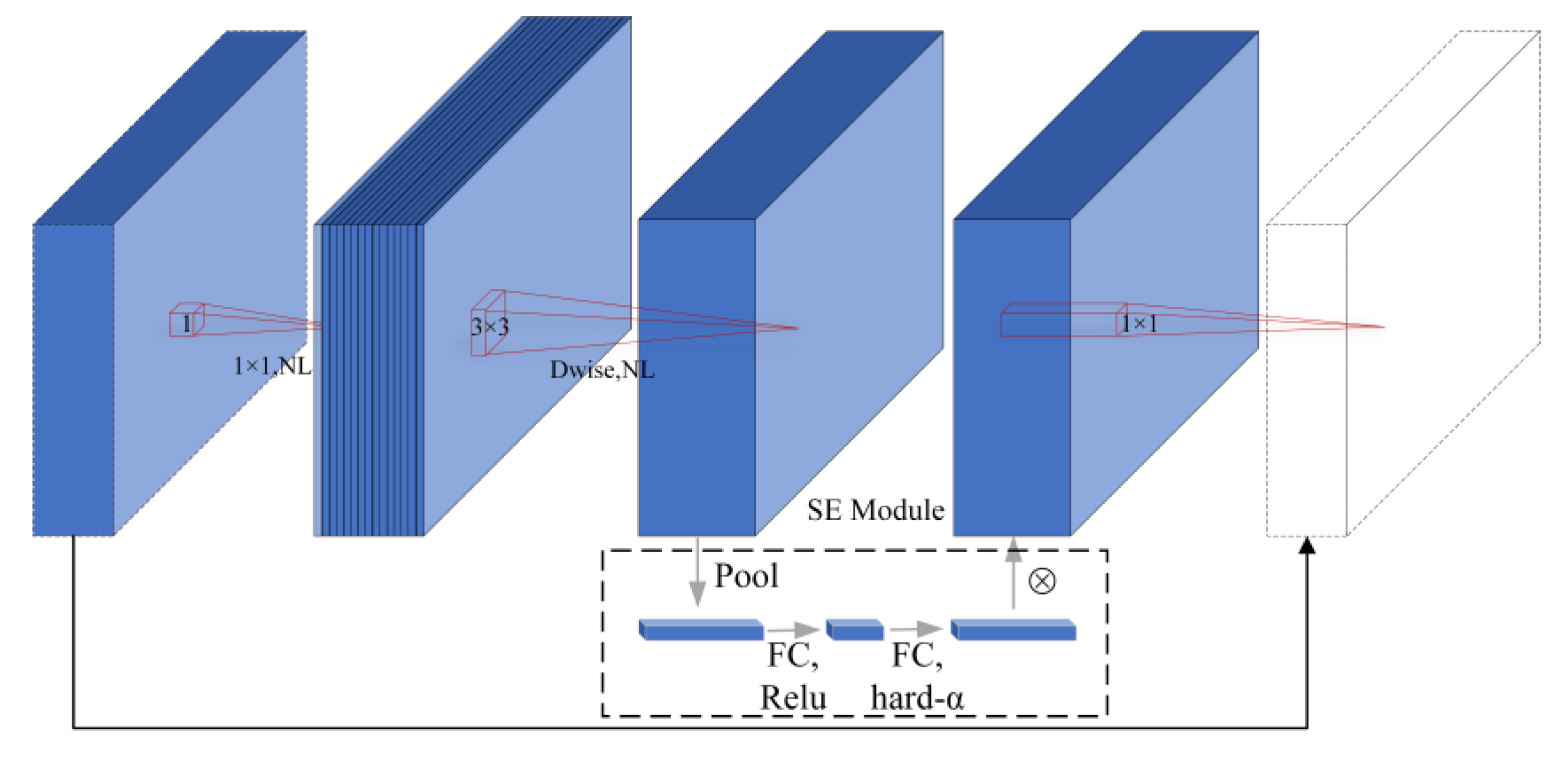
- Attention Mechanisms Module: Aiming at the problem of decreasing feature extraction ability after the model is lightweighted, this paper enhances the detection accuracy of the model without substantially escalating the number of parameters by incorporating the coordinate attention (CA) mechanism in different feature layers.
- ⮚
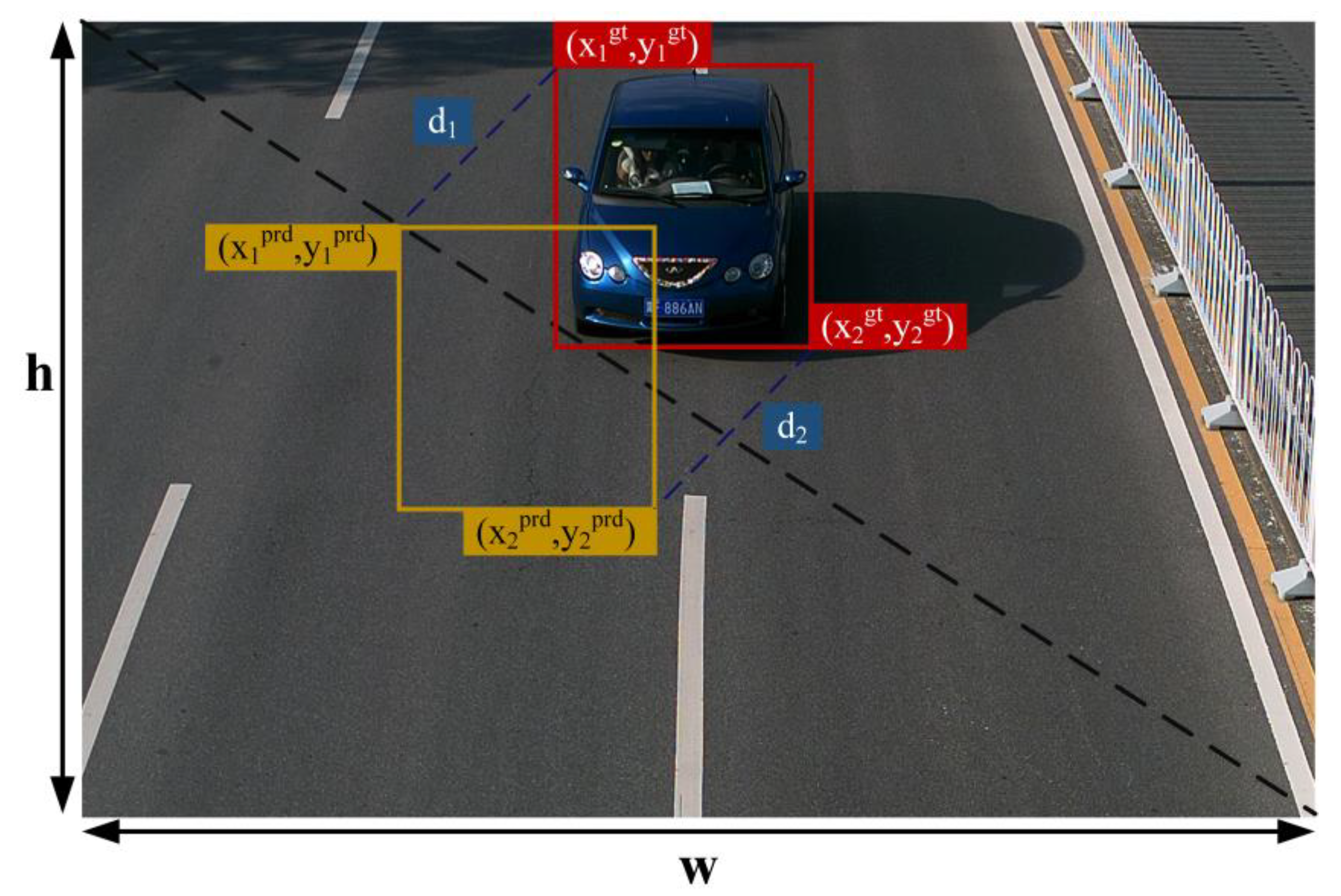
- Minimum Point Distance Intersection over Union (MPDIoU) Loss Function: In order to refine the detection speed of the model and reduce the bounding-box regression loss, the initial complete intersection over union (CIoU) loss function is substituted with the MPDIoU loss function.
2. Materials and Methods
2.1. YOLOV7 Network Structure
2.2. YOLOV7 Improvements
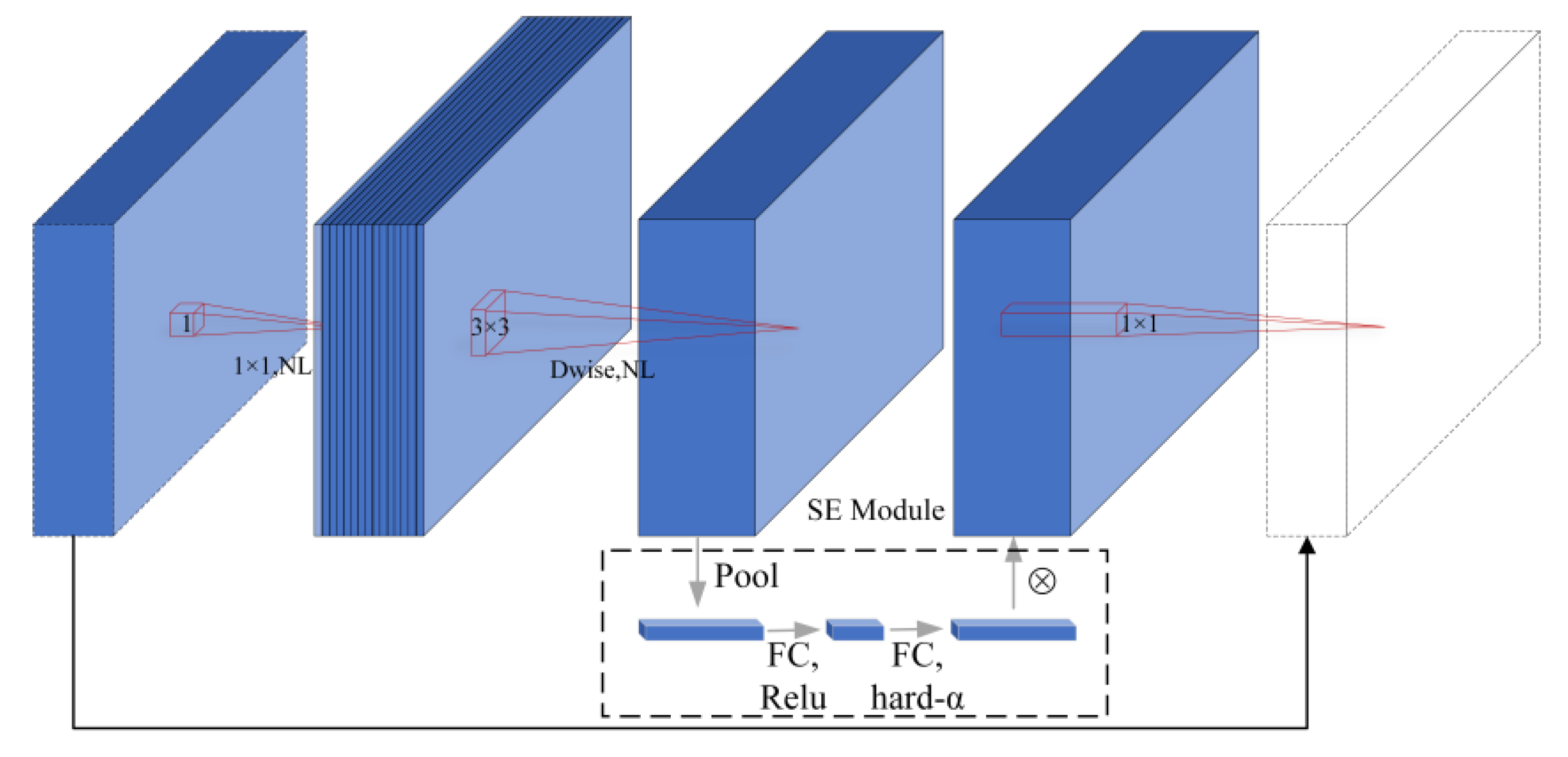
2.2.1. Lightweight MobileNetV3 Module
2.2.2. SPPFCSPC-GS Module
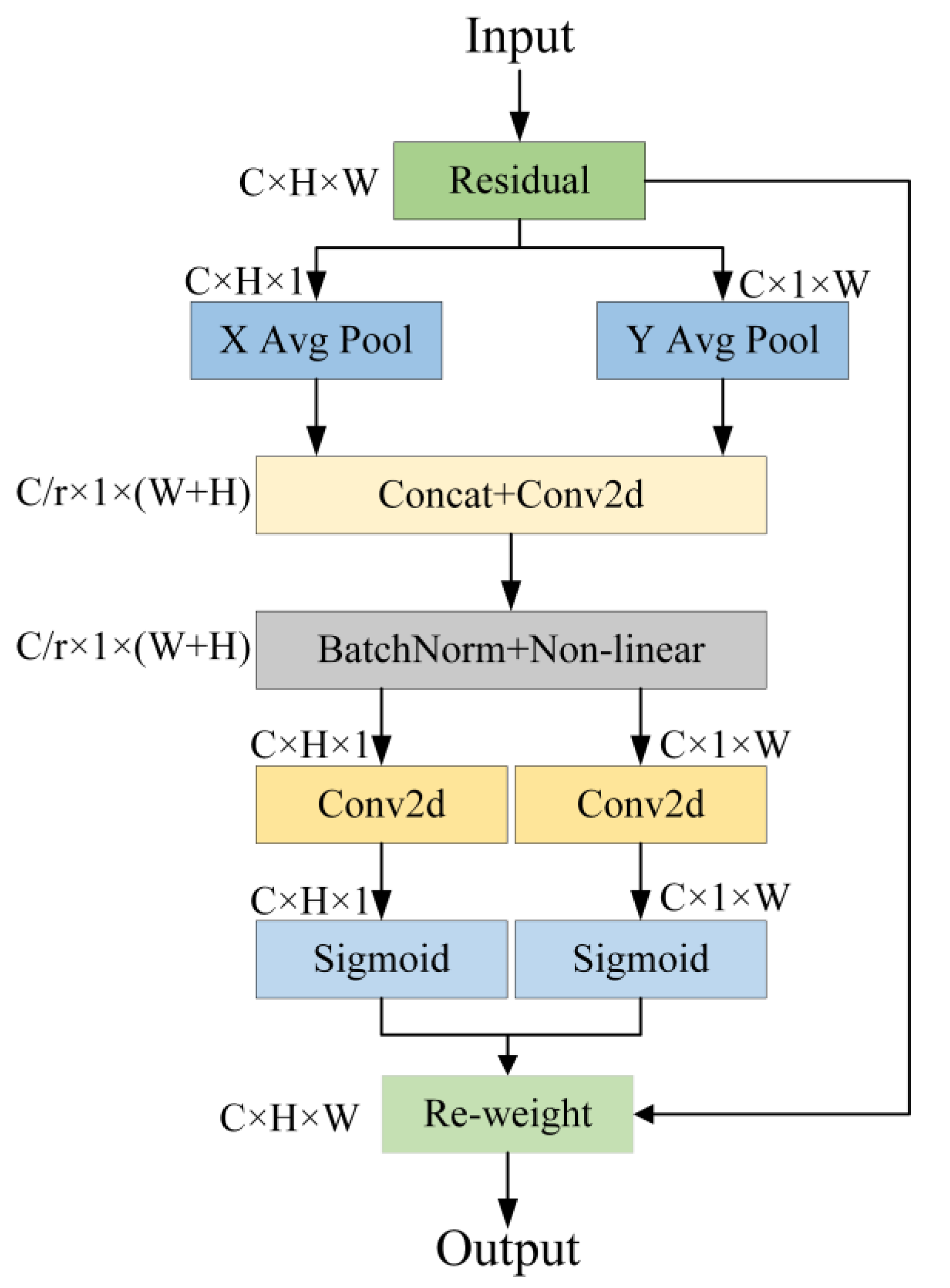
2.2.3. CA Module
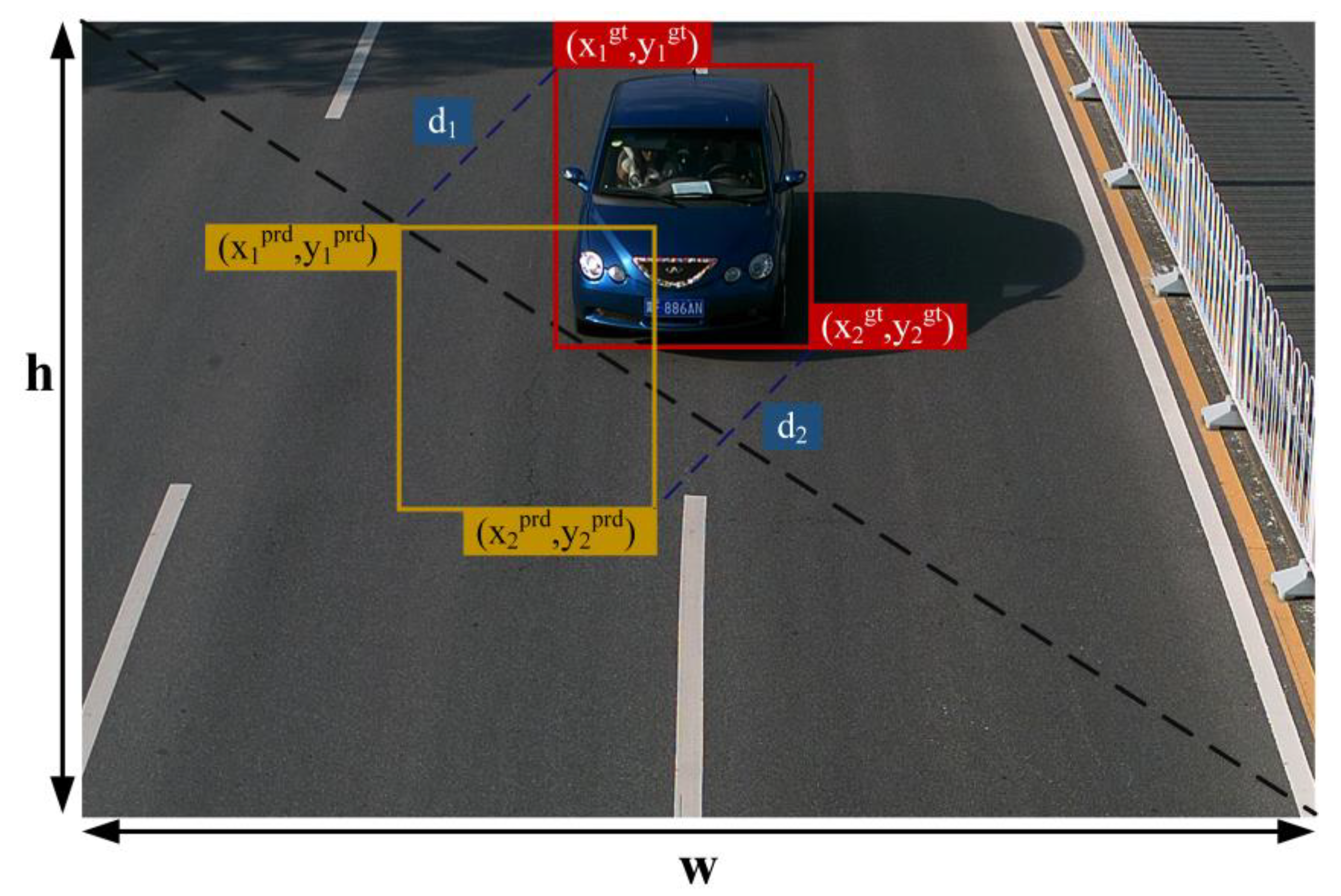
2.2.4. MPDIoU Loss Function
3. Experiment
3.1. Dataset
3.2. Experimental Environment
3.3. Evaluation Metrics
4. Experimental Results and Analysis
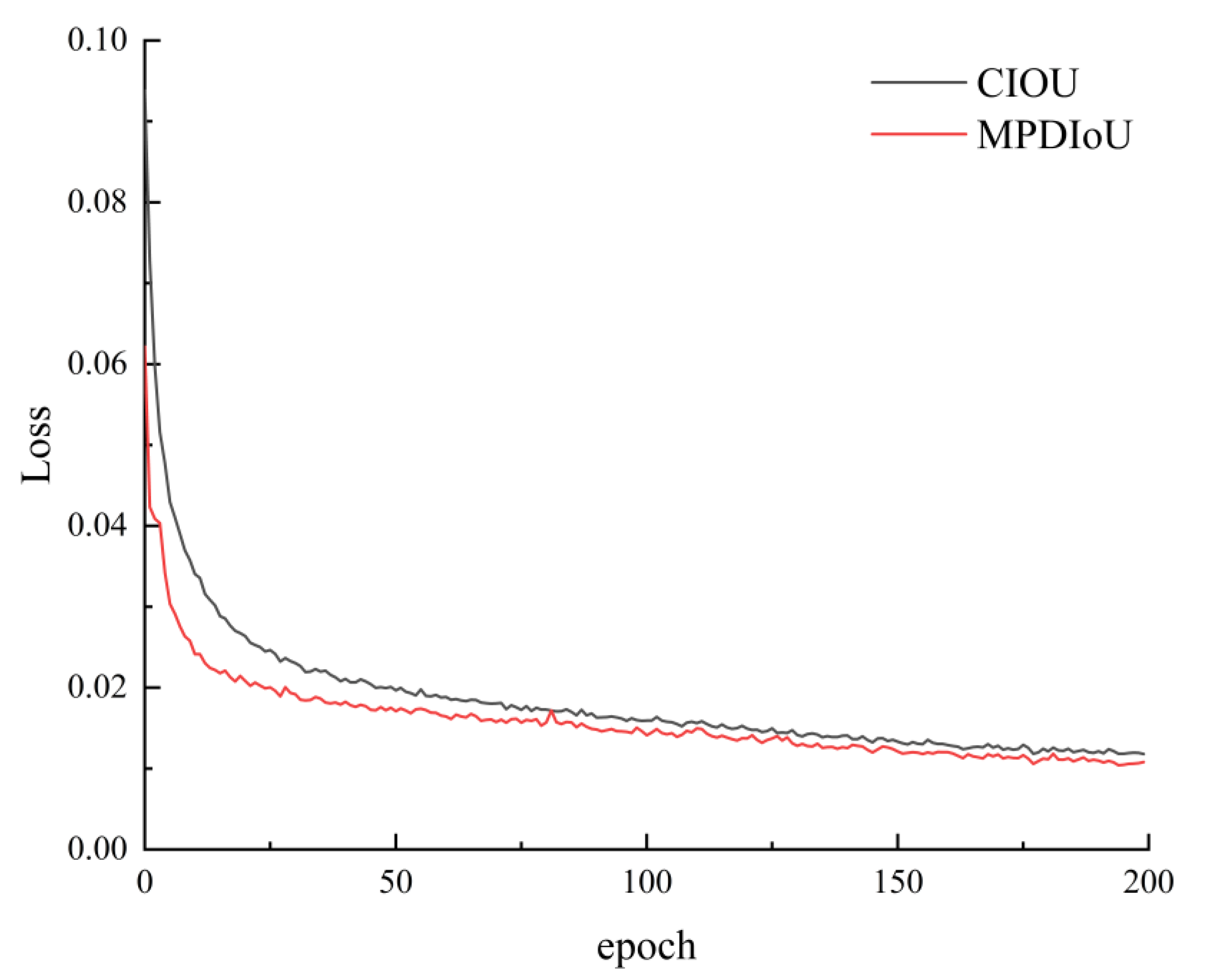
4.1. Experimental Analysis of Adding the MPDIoU Loss Function
4.2. Experimental Analysis of Improved Feature Pyramid Networks
4.3. Overall Analysis
4.3.1. Ablation Experiments
4.3.2. Comparison Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ITS | Intelligent Traffic System |
| SSD | Single-Shot MultiBox Detector |
| YOLO | You Only Look Once |
| YOLOv7 | You Only Look Once version 7 |
| GSConv | Generalized-Sparse Convolution |
| CA | Coordinate Attention |
| MPDIoU | Minimum Point Distance Intersection over Union |
| CIoU | Complete Intersection over Union |
| SPP | Spatial Pyramid Pooling |
| REPcon | Reparameterized convolution |
| SPPF | Spatial Pyramid Pooling-Fast |
| SPPFCSPC | Spatial Pyramid Pooling Fast Cross-Stage Partial Channel |
| SPPFCSPC-GS | Spatial Pyramid Pooling Fast Cross-Stage Partial Channel-Generalized Sparse Convolution |
| CNN | Convolutional Neural Network |
| SE | Squeeze and Excite |
| DW | Depthwise |
| PW | Pointwise |
| CBAM | Convolutional Block Attention Module |
| DIoU | Distance Intersection over Union |
| P | Precision |
| R | Recall |
| mAP | mean Average Precision |
| FPS | Frames Per Second |
| SGD | Stochastic Gradient Descent |
References
- Azhar, A.; Rubab, S.; Khan, M.M.; Bangash, Y.A.; Alshehri, M.D.; Illahi, F.; Bashir, A.K. Detection and prediction of traffic accidents using deep learning techniques. Clust. Comput. 2023, 26, 477–493. [Google Scholar] [CrossRef]
- Liu, Z.; Han, W.; Xu, H.; Gong, K.; Zeng, Q.; Zhao, X. Research on vehicle detection based on improved yolox_s. Sci. Rep. 2023, 13, 23081. [Google Scholar] [CrossRef] [PubMed]
- Xiong, C.; Yu, A.; Yuan, S.; Gao, X. Vehicle detection algorithm based on lightweight yolox. Signal Image Video Process. 2023, 17, 1793–1800. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Q.; Gou, C.; Lu, Q.; Li, X. Transformer-based vehicle detection for surveillance images. J. Electron. Imaging 2022, 31, 051602. [Google Scholar] [CrossRef]
- Ge, D.-Y.; Yao, X.-F.; Xiang, W.-J.; Chen, Y.-P. Vehicle detection and tracking based on video image processing in intelligent transportation system. Neural Comput. Appl. 2023, 35, 2197–2209. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F. Hybrid cascade structure for license plate detection in large visual surveillance scenes. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2122–2135. [Google Scholar] [CrossRef]
- Wang, Z.; Zhan, J.; Duan, C.; Guan, X.; Yang, K. Vehicle detection in severe weather based on pseudo-visual search and hog–lbp feature fusion. Proc. Inst. Mech. Eng. Part D J. Automob. Eng. 2021, 236, 1607–1618. [Google Scholar] [CrossRef]
- Guo, Q.; Liu, N.; Wang, Z.; Sun, Y. Review of Deep Learning Based Object Detection Algorithms. J. Detect. Control 2023, 45, 10–20+26. [Google Scholar]
- Ke, X.; Zhang, Y. Fine-grained vehicle type detection and recognition based on dense attention network. Neurocomputing 2020, 399, 247–257. [Google Scholar] [CrossRef]
- Gu, Y.; Li, Z.; Yang, F.; Zhao, W.; Zhu, B.; Guo, Y.; Lv, Y.; Jiao, G. Infrared Vehicle Detection Algorithm with Complex Background Based on Improved Faster R-CNN. Laser Infrared 2022, 52, 614–619. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, M.; Zhao, J. Lightweight Vehicle Detection Network Fusing Feature Pyramid and Channel Attention. Foreign Electron. Meas. Technol. 2023, 42, 41–48. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10781–10790. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, W.; Shen, C.; Huang, Y. Vision-Based On-Road Nighttime Vehicle Detection and Tracking Using Improved HOG Features. Sensors 2024, 24, 1590. [Google Scholar] [CrossRef] [PubMed]
- Mao, Z.; Wang, Y.; Wang, X.; Shen, J. Vehicle Video Surveillance and Analysis System for the Expressway. J. Xidian Univ. 2021, 48, 178–189. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, S.; Wang, P.; Li, K.; Song, Z.; Zheng, Q.; Li, Y.; He, Q. Lightweight Vehicle Detection Based on Improved YOLOv5s. Sensors 2024, 24, 1182. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Lambert-Garcia, R.; Getley, A.C.M.; Kim, K.; Bhagavath, S.; Majkut, M.; Rack, A.; Lee, P.D.; Leung, C.L.A. AM-SegNet for additive manufacturing in situ X-ray image segmentation and feature quantification. Virtual Phys. Prototyp. 2024, 19, e2325572. [Google Scholar] [CrossRef]
- Chen, L.; Ding, Q.; Zou, Q.; Chen, Z.; Li, L. DenseLightNet: A Light-Weight Vehicle Detection Network for Autonomous Driving. IEEE Trans. Ind. Electron. 2020, 67, 10600–10609. [Google Scholar] [CrossRef]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on yolov5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, Y. Improved YOLOv8 Multi-Scale and Lightweight Vehicle Object Detection Algorithm. Comput. Eng. Appl. 2024, 60, 129–137. [Google Scholar] [CrossRef]
- Luo, Q.; Wang, J.; Gao, M.; He, Z.; Yang, Y.; Zhou, H. Multiple Mechanisms to Strengthen the Ability of YOLOv5s for Real-Time Identification of Vehicle Type. Electronics 2022, 11, 2586. [Google Scholar] [CrossRef]
- Li, C.; Wang, Y.; Liu, X. An Improved YOLOv7 Lightweight Detection Algorithm for Obscured Pedestrians. Sensors 2023, 23, 5912. [Google Scholar] [CrossRef] [PubMed]
- Deng, T.; Wu, Y. Simultaneous vehicle and lane detection via mobilenetv3 in car following scene. PLoS ONE 2022, 17, e0264551. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. Dc-spp-yolo: Dense connection and spatial pyramid pooling based yolo for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]
- Niu, C.; Song, Y.; Zhao, X. SE-Lightweight YOLO: Higher Accuracy in YOLO Detection for Vehicle Inspection. Appl. Sci. 2023, 13, 13052. [Google Scholar] [CrossRef]
- Zhao, X.; Song, Y. Improved Ship Detection with YOLOv8 Enhanced with MobileViT and GSConv. Electronics 2023, 12, 4666. [Google Scholar] [CrossRef]
- Xu, Z.; Hong, X.; Chen, T.; Yang, Z.; Shi, Y. Scale-aware squeeze-and-excitation for lightweight object detection. IEEE Robot. Autom. Lett. 2023, 8, 49–56. [Google Scholar] [CrossRef]
- Xu, H.; Lai, S.; Li, X.; Yang, Y. Cross-domain car detection model with integrated convolutional block attention mechanism. Image Vis. Comput. 2023, 140, 104834. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar] [CrossRef]
- Wang, X.; Song, J. Iciou: Improved loss based on complete intersection over union for bounding box regression. IEEE Access 2021, 9, 105686–105695. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020; pp. 12993–13000. [Google Scholar] [CrossRef]
- Siliang, M.; Yong, X. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar] [CrossRef]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle Type Classification Using a Semisupervised Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Kai, W.; Song, B.; Ling, X.; Hong, G.; Qing, M.; Qi, T. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar] [CrossRef]
- Joseph, R.; Ali, F. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 12 April 2021).
- Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; Ren, J. Rethinking Vision Transformers for Mobilenet Size and Speed. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16889–16900. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14420–14430. [Google Scholar]
- YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 January 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | SUV | Sedan | Microbus | Truck | Bus | Minivan |
| Number | 1392 | 5922 | 883 | 822 | 558 | 476 |
| Model | mAP/% | FPS | P | R | AP/% | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| SUV | Sedan | Microbus | Truck | Bus | Minivan | |||||
| CIoU | 97.9 | 78.7 | 95.3 | 96.2 | 97.3 | 99.4 | 97.2 | 95.3 | 98.7 | 99.4 |
| MPDIoU | 98.2 | 78.9 | 95.3 | 96.5 | 96.9 | 99.4 | 98.5 | 97.2 | 99.4 | 97.9 |
| Model | FPS | Parameters | mAP/% |
|---|---|---|---|
| SPPCSPC | 78.7 | 37,304,436 | 97.9 |
| SPPFCSPC | 83.7 | 31,521,894 | 97.6 |
| SPPFCSPC-GS | 83.5 | 27,954,886 | 97.8 |
| Model | MobileNetV3 | SPPFCSPC-GS | CA | MPDIoU | FPS | Parameters | mAP/% |
|---|---|---|---|---|---|---|---|
| YOLOv7 | 78.7 | 37,304,436 | 97.9 | ||||
| A | √ | 93.5 | 25,245,010 | 97.5 | |||
| B | √ | √ | 114.9 | 17,273,796 | 97.3 | ||
| C | √ | √ | √ | 106.4 | 17,623,636 | 97.6 | |
| D | √ | √ | √ | √ | 106.4 | 17,623,636 | 98.2 |
| Model | mAP/% | FPS | Parameters/M | AP/% | |||||
|---|---|---|---|---|---|---|---|---|---|
| SUV | Sedan | Microbus | Truck | Bus | Minivan | ||||
| CenterNet [36] | 95.3 | 29.5 | 125.2 | 96.6 | 98.8 | 88.6 | 99.6 | 92.1 | 96.5 |
| YOLOv3 [37] | 97.3 | 78.1 | 61.6 | 97.7 | 99.4 | 95.3 | 94.0 | 98.5 | 98.8 |
| YOLOv5m [38] | 94.3 | 89.3 | 25.1 | 88.6 | 98.2 | 97.2 | 94.0 | 99.5 | 88.5 |
| YOLOv7 [14] | 97.9 | 78.7 | 37.3 | 97.3 | 99.4 | 97.3 | 95.4 | 98.7 | 99.4 |
| EfficientFormerv2-YOLOv7 [39] | 97.8 | 89.6 | 25.9 | 97.9 | 99.3 | 96.9 | 94.4 | 99.0 | 99.2 |
| EfficientVitM0-YOLOv7 [40] | 97.7 | 67.3 | 24.8 | 97.8 | 99.4 | 96.8 | 94.5 | 98.7 | 99.2 |
| YOLOv8s [41] | 94.8 | 123.3 | 13.2 | 88.9 | 97.7 | 96.4 | 93.8 | 99.5 | 92.6 |
| Ours | 98.2 | 106.4 | 17.6 | 97.4 | 99.3 | 98.3 | 97.0 | 99.1 | 97.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, D.; Tu, Y.; Zhang, Z.; Ye, Z. A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism. Sensors 2024, 24, 2394. https://doi.org/10.3390/s24082394
Huang D, Tu Y, Zhang Z, Ye Z. A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism. Sensors. 2024; 24(8):2394. https://doi.org/10.3390/s24082394
Chicago/Turabian StyleHuang, Deqi, Yating Tu, Zhenhua Zhang, and Zikuang Ye. 2024. "A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism" Sensors 24, no. 8: 2394. https://doi.org/10.3390/s24082394
APA StyleHuang, D., Tu, Y., Zhang, Z., & Ye, Z. (2024). A Lightweight Vehicle Detection Method Fusing GSConv and Coordinate Attention Mechanism. Sensors, 24(8), 2394. https://doi.org/10.3390/s24082394